计算机系统类课程群概念图自动构建研究
2023-07-16刘德喜陈雨婕刘宇星狄国强邱宝林廖国琼
刘德喜,陈雨婕,刘宇星,狄国强,邱宝林,廖国琼
(江西财经大学 信息管理学院,江西 南昌 330013)
0 引言
计算机人才培养强调的程序性开发能力正在转化为更重要的系统性设计能力,未来将会更关注学生掌握软硬件协同工作的能力以及解决复杂工程问题的能力。根据新工科专业系统能力培养改革与实践指导,突出系统化思想对于高校计算机专业教学和培养的重要影响。缺乏知识的整体性理解和系统的综合实践能力是现阶段课程体系下暴露出来的问题,需要建立新的计算机专业教学课程体系,重新规划计算机课程的重点内容和顺序设置。高校受有限的教学课时等条件制约,需要对专业课程设置、课程内容选择和课程之间的逻辑关系进行合理划分和组织,形成一个有序、互联的课程群落。系统类课程群的建设使专业知识框架更加合理和完善,带动整体教学水平进一步提高,使学生的素质和实践能力跃上新台阶。
计算机专业知识体系覆盖范围广,课程群中术语和知识内容繁杂,不同课程知识之间具有连续性,授课过程中,一些术语总是孤立讲授,未能与相关术语合理关联,无法构成专业学科级知识体系。构建专业课程群应从课程定位以及课程之间的逻辑关系出发,基于最根本的课程内容结合“系统观”思想,将专业知识点有机组织,有效指导教师的授课重点。通过融合和规划相关课程群的信息,合理安排术语的讲授顺序和逻辑,可以在有限的时间内帮助学生构建知识框架,形成系统能力。
本文以计算机系统类课程群为例,基于术语、定义抽取及图分析技术,自动完成课程群概念图构建,以更好地辅助教师教学,培养学生系统能力并构建完整的知识框架,从而推动教育信息化、智能化发展。
1 相关研究
1.1 计算机系统类课程群及其建设方法
计算机系统类课程群建设主要研究在系统能力培养要求下的相关课程设置、课程定位和课程之间的逻辑关系。国内各高校参照示范单位并基于本校师资等条件,建设适合自己的计算机类专业系统能力培养方式,提高学生适应新经济发展的整体素质和能力。
其中,清华大学提出分层、双向的系统能力培养课程体系建设新思路,借鉴国外著名高校,开设系统能力培养课程横纵向梳理知识体系,明确各层次教学内容,建立计算机系统层次间的联系,并辅以课程实验体系,逐级递进,以迭代的方式培养学生能力[1]。广东工业大学针对软硬件教学活动分离的现状,提出两者结合的计算机专业基础课程群实验教学模式,通过对“软”“硬”线课程内容协同优化,再总结和挖掘课程间的内在联系,结合教学方案构建课程群知识地图,通过关键路径发现先修、后修制约关系支撑教学[2]。桂林电子科技大学根据系统能力培养总目标及计算机系统各层次之间的关系,明确各课程教学目标,并构建“三横两纵”实践课程教学体系,从基础、专业和综合3个层次能力培养逐步过渡,和开设软、硬件课程实践环节两个角度,培养学生计算机系统综合开发能力[3]。北京航空航天大学以“三位一体”教学目标和“三工”教学准则,由传统建设模式转变为“以课程群为中心”的建设模式,精简非必要知识,重构整个课程群体系[4]。其他高校计算机院系也以“系统能力培养”为主线组建“系统能力培养课程群”,对教学内容依学生掌握程度进行分解和整合,挖掘不同课程的相似内容,实现整体化协作式教学[5-6]。
本文依据教材分析整个课程或课程群中的相关术语及其之间的内在关系,构建计算机系统类课程群中的概念图谱,辅助建设课程群。本文创新性地提出利用自动分析方法识别整个课程或课程群中的术语、定义,并确定核心术语以及它们之间的关联形成专业课程群概念图。该方法一方面可以改进现有研究在分析课程群概念关系上的主观性,同时还能从课程群全局或系统出发,勾勒出概念关系图,有利于帮助学生建立系统观。
1.2 课程概念图谱构建
课程概念图谱直观展示专业中的各个概念以及整合它们的关系网络,是课程群建设的重要内容。相关工作中,有的从授课内容出发,构建简略的教学知识图谱[7];有对庞大的知识点进行梳理和分割,构建分层拓扑的概念图谱[8]。这些方法中,主要根据对培养方案和教学大纲的研讨和论证完成对知识点的提炼。已有工作大都采用人工方式,受人力、时间等因素局限,往往只涉及单个课程,提炼的知识点数量也很有限,难以展示课程知识结构以及知识点之间的关系。
在教育领域,对知识图谱自动构建时,张勇等[9]以教学大纲和百度词条为基础,利用基于“自举”的知识点识别算法,以典型知识点词条为基础,逐步扩展收集学科相关的其他知识点词条,采取融合基于知识点上下文相似性和基于百度百科的点互信息策略构建知识点之间的关联性,从而构建面向教育信息化和智能化的学科知识图谱。黄超等[10]根据MOOC平台上的课程相关信息,进行课程术语挖掘和课程先后序学习,其中借助图的置信度传播算法进行课程术语抽取,使用基于课程大纲骨架的抽取算法确定术语的上下文关系。朱鹏等[11]以课程知识内容的Web文档资源为数据,构建基于课程知识图谱的课程知识导航服务平台,计算TF-IDF(Term Frequency-Inverse Document Frequency)和MI(Mutual Information)的权值,并结合相似度和细化度方法,科学地量化课程术语间的层次关系并完成课程知识图谱模式层的本体构建,利用DOM(Document Object Model)树完成课程知识图谱的知识实例抽取。
本文创新性地利用自然语言处理等技术,从专业课程的文本教材中自动抽取术语及其依赖关系,以指导课程群建设。创新点体现在:构建了面向计算机课程教材的语料库;结合规则、统计和深度学习方法,抽取教材中的专业术语及其定义,构建课程群概念图谱;利用图分析法对概念节点进行权重分析,识别核心概念。
2 课程群概念图谱构建
课程群概念图谱是基于术语节点之间的内在关系而形成的知识逻辑网络,其中每个节点由教材文本中自动抽取的术语知识点构成,并基于它们在文本中的逻辑关系自动搭建术语之间的联系。课程群概念图谱的结构化形式贴合专业课程群的知识体系和知识结构,可以帮助教师设计更高效的培养方案和教学计划,也可以帮助学生梳理知识点,形成系统观。
课程群概念图谱CNet(Concept Network)构建方案如图1所示。
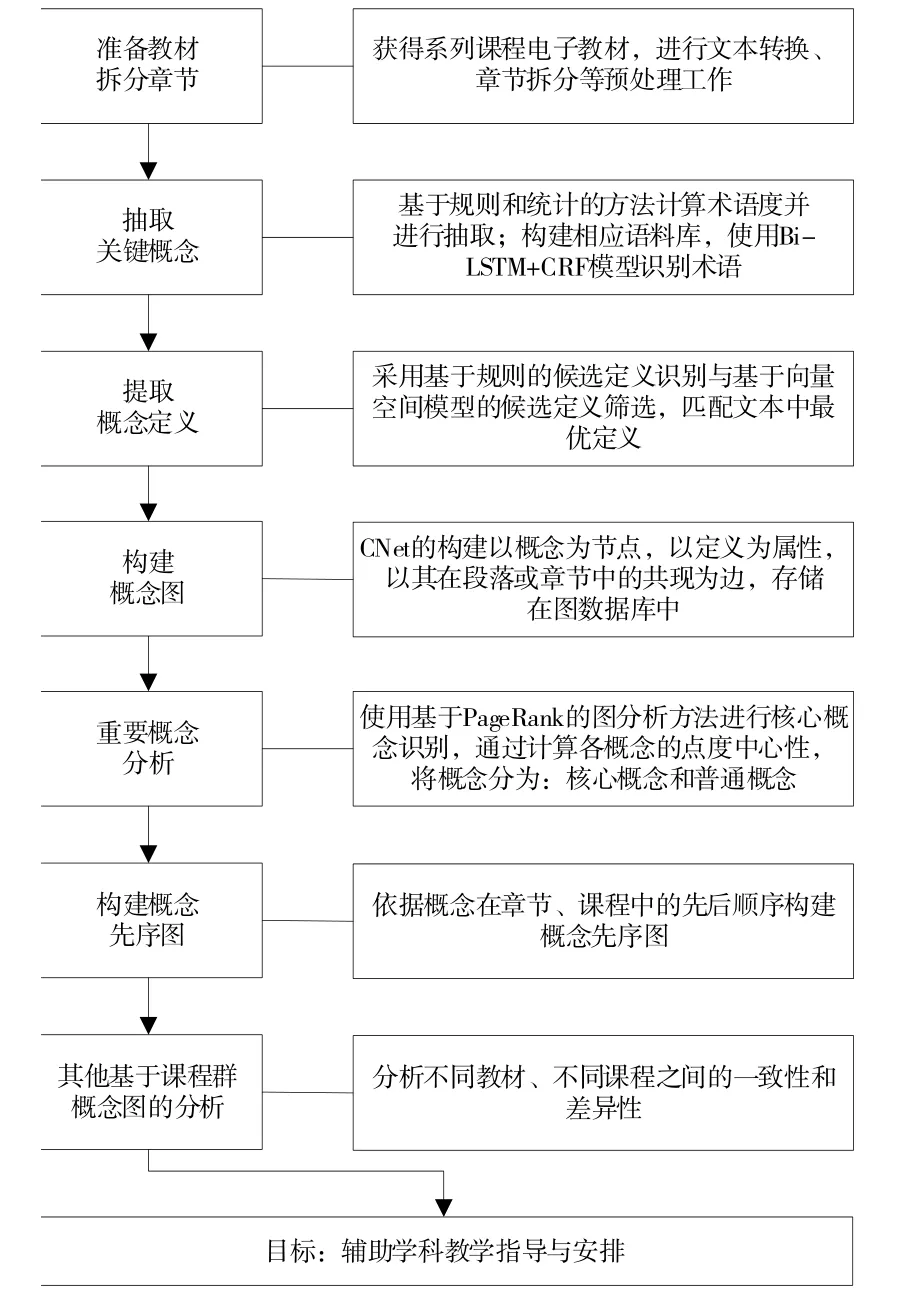
Fig.1 Construction plan of curriculum group CNet图1 课程群概念图谱CNet构建方案
2.1 术语抽取
术语抽取是构建课程群概念图CNet的基础,图谱中的节点由文本中抽取的重要术语构成。本文基于计算机专业系列教材,包括《操作系统》《计算机组成原理》《计算机网络》《数字逻辑》等不同课程的多部教材,采用基于规则方法和基于深度学习的方法。
2.1.1 基于规则和统计的术语抽取
将术语构词规则、术语长度、术语出现频率等因素作为词语术语性的衡量标准。为解决基础算法破坏术语构词完整性、领域性的问题,采用单词片拼接、语法规则库过滤、融合TF-IDF和C-value的算法等步骤进行基于规则和统计的术语抽取[12]。
首先对原始语料进行分词后得到单词片,由于通用词典分词会破坏术语完整性,对每个单词碎片与左右相邻片段进行拼接得到词串以还原术语的长度及单元性,其中根据计算机术语长度的最大值限制最大单词片拼接数为5。对词串串频进行统计,为能涵盖更多术语,将频数阈值定为能涵盖90%词串处的值,串频大于阈值的词串将作为候选术语。由此得到的候选术语更具单元性和领域性,同时该方法也可处理嵌套术语的问题,例如“操作系统”和“单道批操作系统”的频数同时大于阈值,则两者都将被提取。
单纯依靠单词片的拼接,会导致结果中存在不符合逻辑或不符合术语构词规则的短语。本文根据文本语料、实验结果和语言学特征,总结明显不能作为术语构词的词性规则,非术语构词规则如表1所示。

Table 1 Rules of non-term words表1 非术语构词规则
对候选术语进行词性标注,并根据规则库对不符合规则的候选术语进行过滤。但由于筛选后的结果中还包括普通常见词语、无意义的字串等。针对出现的问题,参考张静等[12]提出的IC-value计算公式,融合TF-IDF与C-value算法计算候选词的术语度。
C-value算法主要依据统计信息,考虑了术语长度和嵌套术语的影响,认为术语长度对C-value值起促进作用。对于嵌套术语,若嵌套词串出现的频数较高,则被嵌套串是术语的可能性就越小,即嵌套串词频对被嵌套串的值起消极作用。但C-value方法不能有效过滤一些出现频次很高的普通词汇,因此融合算法中加入TF-IDF算法中的逆文档频率,以降低高频次普通词汇的术语度值。
本文根据处理方式的不同,采用改进的融合算法,既考虑了术语长度和术语嵌套,又剔除掉常用的普通词汇,对候选术语a的术语度计算如式(1)所示。
其中,|a|表示候选术语a的长度即候选术语包含的字数,tf(x)表示x在文档集中出现的频次,df(a)表示候选术语a的文档频率,b是候选术语a的嵌套候选术语,Ta表示候选术语a的嵌套候选术语集合。
2.1.2 基于BiLSTM+CRF的术语识别模型
将术语识别转化为序列标注任务,构建训练集BiLSTM+CRF模型,并通过测试集考察模型对术语识别的效果。
计算机专业领域的术语范围较大,种类较多,选取教材文本作为语料,其包括常见的重要术语,本次研究的重点在于识别所有教学术语,为后续构建概念图做铺垫。由基于统计和规则的方法得到结果,经过人工筛选后作为初始词典,对教材中的字串打上“B”“I”“O”3种标签,分别代表术语的开头、术语的后续和非术语。
对教材每个章节均采用两轮标注,下文对具体任务内容进行介绍。第一轮标注:使用当前词典中所包含的术语,以章节为单位,进行第一轮标注,对得到的标注结果,进行人工审核和识别,并向计算机术语词典中添加未标注的新术语,进行更新。第二轮标注:依据更新后的教材术语词典对已进行第一轮标注的章节再次标注,并以句子为单位进行分割。
语料库涵盖计算机专业4门课程的教材文本,分别为:《操作系统》《计算机网络》《计算机组成原理》《数字逻辑》,共有效标注17 122个句子,其中《操作系统》6 036句、《计算机网络》6 962句、《计算机组成原理》3 814句、《数字逻辑》310句,平均每个句子包含4个术语,最多的包含26个术语,最少的情况为句子中没有术语,句子中术语字符占比平均值为0.07,最大值为0.23;语料中共包含4 426个术语,他们出现的频次为77 342次,其中《操作系统》30 392次、《计算机网络》30 815次、《计算机组成原理》14 758次、《数字逻辑》1 377次;术语的平均长度为6个字符,最大长度为49个字符,在词典中仅有一个,是“Internet-SecureAssociationandKeyManagementProtocol”,最小长度为1个字符。
BiLSTM+CRF模型通过神经网络自动学习字符的特征和字符间关系,再由条件随机场优化输出序列,达到自动学习识别术语的目标。双向长短期记忆网络适合处理长序列数据,其隐藏层节点不仅取决于当前输入的信息,还受前一时刻历史数据的影响,因此能够在处理整个序列数据时,不仅考虑单个词语,还能更好地利用每个词前后的双向语义特征信息。同时在长序列训练中,能够处理反向传播中出现的梯度消失和爆炸问题,有选择地记忆重要信息和忘记不重要信息。条件随机场可以学习标签之间的约束关系,根据输入的特征向量优化输出序列,防止不合法的标签情况。
2.2 术语定义提取
CNet抽取术语的定义作为概念图谱中节点的属性。术语定义提取包括两个阶段:基于规则的候选定义识别和基于向量空间模型的候选定义筛选。
受文献[13-15]的启发,结合对语料库中定义语句的特征分析,首先通过术语定位候选句式,即句子中的关键词被冒号引起来,或者后面接上了术语的英文形式。相应的规则表达式为:Term→[“|”|"]?+关键词+'[“|”|"]?((.*?))?
定义8条候选定义识别规则,即术语所在的句子如果符合以下规则,则该句子为术语的候选定义。其中,“句首号”表示出现在句子开头的符号,如句子开头、逗号、右括号、序号等;“句尾号”表示出现在句子结束或停顿的符号,如句子结尾、逗号、分号等。具体规则如表2所示。

Table 2 Extraction rules of term definition表2 术语定义抽取规则
对于某个术语,基于规则可能识别出多条候选定义,本文借助向量空间模型进行术语定义准确度排序,计算选定的术语和候选定义之间的相似度,据此筛选出最合适的术语定义[14]。向量空间模型(Vector-space models,VSM)用特征项及其相应权值代表文档信息,将文档表示为向量,通过向量计算文档之间的相似性。
给定候选术语定义句子S1,S2,S3,…,Sn,先对句子进行停用词过滤,将过滤后得到的词作为句子的特征项,再将候选术语定义句子视为一个集合,进行词频统计,挑选出前m个高频词语,构建高频词向量H=(<t1,w1>,<t2,w2>,…,<tm,wm>),t1,t2,…,tm为该术语定义的词语坐标系,w1,w2,…,wm为相应的词频,作为其坐标值。之后,针对每个候选句子,根据高频词向量的词语坐标,对其特征项进行词频统计,构建每个候选句子的向量S=(<t1,w1>,<t2,w2>,…,<t15,wm>)。计算每个句子向量与高频词向量的相似度,相似度最高的句子作为术语定义的最优选择。本文在每个章节中的术语定义筛选时,m设置为15。
本文的定义提取是在特定领域,对于一个特定术语而言,所需筛选的候选定义与选定的术语属于一个领域内的词语,可能会多次出现在不同的句子中,导致其IDF值较低,因此与传统TF-IDF权重不同,此处只以词频TF为权重。给定一个文档S=(<t1,w1>,<t2,w2>,…<ti,wi>,…,<t|D|,w|D|>),t1,t2,…,t|D|是一个由词表D张成的|D|维的坐标系,wi为词ti在S中的权重,即词频,则S可表示为向量<w1,w2,…,wi,…,w|D|)。同样地,视高频词集合为一个文本后,也可以表示为一个向量,记为H=<h1,h2,…,hi,…,h|D|)。H和S之间的相似度定义为两个向量的夹角余弦,如式(2)所示[14]。
3 实验与结果分析
3.1 数据集及实验设置
实验的数据集包括:汤小丹等编著的《计算机操作系统》(第三版)、左万利等编著的《计算机操作系统教程》(第四版)、任国林编著的《计算机组成原理》、唐朔飞编著的《计算机组成原理》、谢希仁编著的《计算机网络》(第7版)和陈光梦编著的《数字逻辑基础》。
数据集共包含16 352条标注语句,对全部语料按照15∶1:1的比例划分为训练集、验证集和测试集进行实验。为测试训练的模型是否能屏蔽上下文环境影响和是否具有发现新术语的能力。其中,新术语表示在训练数据中未出现过而在测试集中出现的术语,实验中使用《操作系统》《计算机网络》《计算机组成原理》3本教材某一版本构成训练集,并设置3个测试集,分别使用与上述3门课程教材相同(测试集1)、课程相同教材不同(测试集2)和课程不同(测试集3,《数字逻辑》教材)的测试数据。各数据集统计信息如表3所示。
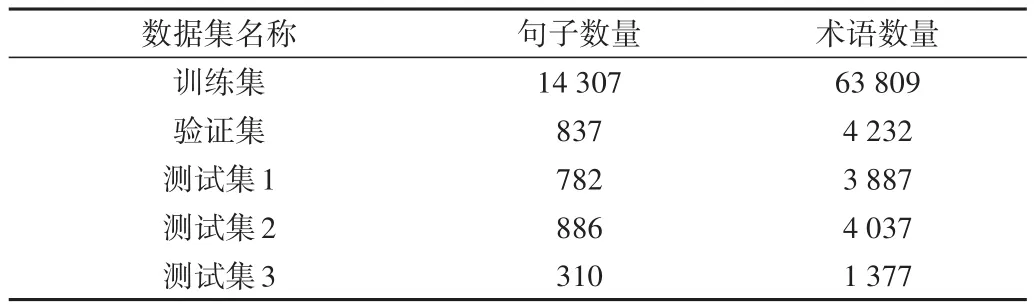
Table 3 Data set statistics表3 数据集统计
BiLSTM-CRF模型参数设置如表4所示。采用的字符向量维度为100维,字符LSTM的隐层大小为105维。使用随机梯度下降(SGD)算法训练模型,设置一个批次的样本数为10,迭代次数为50,学习率为0.001。

Table 4 Parameter settings表4 模型参数设置
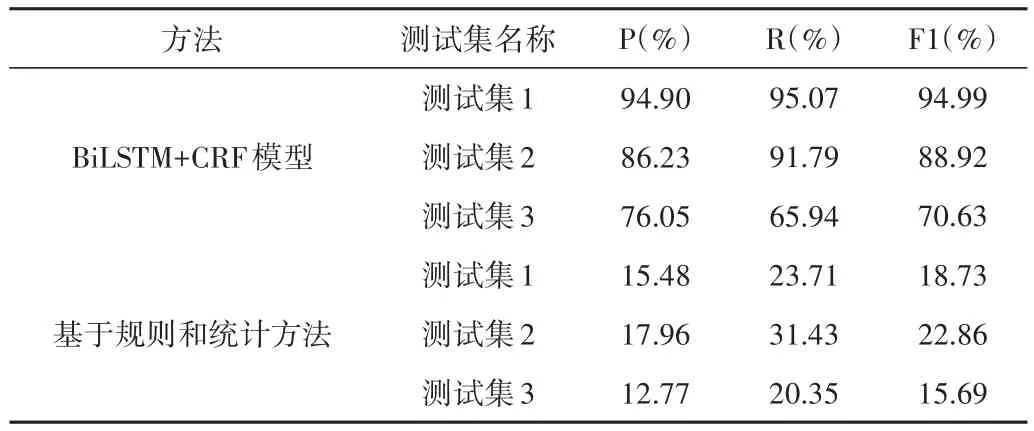
Table 5 Results of term recognition表5 术语识别结果
3.2 术语抽取实验结果
对抽取结果选取精确率(Precision)、召回率(Recall)和F1值(F-Measure)作为评估指标。根据计算公式得出两种方法在3个测试集上术语识别的对比结果。
对比BiLSTM+CRF模型在3个测试集上的表现:
测试集1与训练集来源于相同教材,具有相同的上下文环境和同领域的术语。因此,根据上表的结果显示,识别的效果在3个测试中最好,精确率和召回率都在95%左右,能够有效抽取大部分术语。
测试集2与训练集所属相同课程,但来自于不同作者的教材。相对于测试集1,其改变了上下文环境,但是术语种类大致相似。根据实验结果,精确率降低约10%,但召回率相差不多。模型在改变环境后,多识别出了一些非术语的词语,例如:“LAN与WAN”“字证书”“FTP服务器”……出现很多将多种术语连在一起识别成一个术语、多识别或少识别出一个完整术语的部分字符的情况,但是在正确术语的覆盖率上表现较好。
测试集3与训练集属于不同课程,因此大多数术语属于没有在训练时出现过,仅仅出现过少量多门课程共同的术语。测试集3的目的在于测试模型的新词发现能力。根据结果,模型识别出《数字逻辑》中199种新术语,包括“多输出逻辑函数”“组合逻辑电路”“同步时序逻辑电路”“SynchronousSequentialLogicCircuit”……但是整体召回率较低,存在识别错误的非术语词,例如:将“卡诺图简化逻辑函数”中的两个术语抽取成“图简化逻辑函数”“数字逻辑系统”只抽取了“字逻辑系统”……模型在识别新词方面还有待提高。
基于规则和统计的方法与BiLSTM+CRF模型相比,其准确率和召回率都相差较大,在候选术语频率统计阶段出现了较多低频术语被筛掉的情况。其中,测试集1中被筛掉的低频术语有216个,测试集2中被筛掉171个,测试集3中被筛掉67个,导致抽取效果不佳。
根据术语抽取结果,采用基于规则的候选定义识别与基于向量空间模型的候选定义筛选算法,对每个术语进行相应定义提取。实验结果显示,该方法在本文所给定的教材上有较好的抽取结果。基于规则匹配的方法具有良好的描述能力,而向量空间模型则考察了候选定义的相关性和重要性。
4 课程群概念图谱及应用
4.1 课程群概念图构建
CNet中共有4 426个节点,按所属科目添加了不同颜色的标签,节点属性展示了相应的定义。通过PageRank算法可将它们按照重要性划分为:普通术语和核心术语。按照专业术语在语料中的共现关系构建边,其中一般关系(CoInChapter)表示连接的两个节点在同一章节共现;紧密关系(CoInPara)表示连接的两个节点在同一段落中共现。最终,完成的课程群概念局部图展示如图2所示。
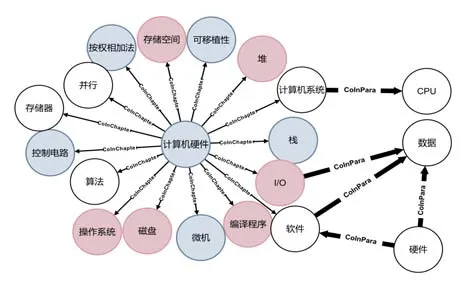
Fig.2 Partial display of curriculum group CNet图2 课程群局部概念图展示
4.2 核心术语分析
将课程群中的术语节点按重要性进行分类,可以帮助教师在课堂中有侧重性地加以讲解,加深学生术语学习印象。本文通过PageRank算法计算各术语的点度中心性,根据点度中心性的排序鉴定术语是否属于核心术语[16-17]。
PageRank算法中一个节点的重要性依据链接节点的数量和链接结点的权重,对每个链入节点经过递归算法计算,达到收敛后,即为该节点的PR值,如式(3)所示。
其中,PR(A)是节点A的PR值;节点Ti是指向A的所有结点中的某个结点;C(Tn)是结点Tn的出度,也即Tn指向其他节点的边的个数;d为阻尼系数,是指在任意时刻,用户到达某结点后并继续向后跳转的概率,通常d=0.85。
本文实验中设置迭代次数为20次,阻尼系数设置为0.85。对于概念图中的每个节点计算其PR值,并设定阈值0.5,将大于阈值的术语定为重要术语,小于阈值的定位为普通术语,在图谱中以不同节点加以区分。
4.3 课程群概念图谱应用
课程群概念图CNet旨在辅助课程群建设和教学。CNet融合和规划了相关课程的群体性信息,又保留了每门课程单个术语自身的信息,可以在以下方面辅助教与学。
(1)使用CNet辅助高校专业课程体系构建。CNet中术语节点之间的联系可以形成单门课程甚至整个专业的知识图谱,帮助分析章节内、课程内、课程间不同术语之间的关系,进而形成概念子图、概念社群,辅助课程群建设,合理安排课程设置,研究课程之间的逻辑关系。同时,也可以在培养方案设计时,恰当地划分各课程的边界,形成内容紧凑、衔接合理、分工明确的课程群。例如:存储管理中“段页式存储管理”“虚拟存储器”与存储系统中“高速缓冲存储器”“快表”以及“主存—辅存层次”之间的联系,如图3所示。
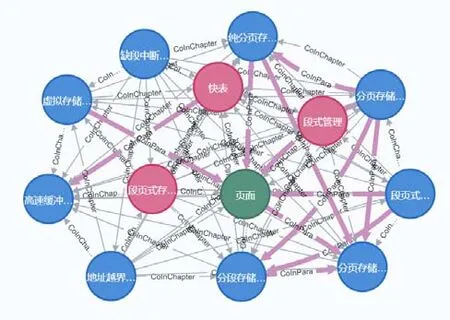
Fig.3 Sub-network of concept "storage management"图3 “存储管理”概念子图
(2)CNet可以同时为教师与学生双方服务。如果将课程学习的过程分为:预习阶段、课堂拓展阶段、课后复习阶段。在预习阶段,可以通过整个框架和核心术语对总体内容进行了解;课堂学习时,教师合理拓展关联性术语,进行巩固或延申讲解;对课程内容总结复习时,重点关注核心术语,并将相关知识串联,构建知识体系。利用概念图进行自适应学习,依据使用者对知识的掌握程度,构建学习画像,选择图谱中不同的概念子图、不同的学习路径,以提供个性化帮助,提高学习针对性。图4是在概念知识图谱基础上,针对“数据表示”这一知识点提取和调整后的概念子图,可以帮助学生了解各种数据表示方法之间的联系。
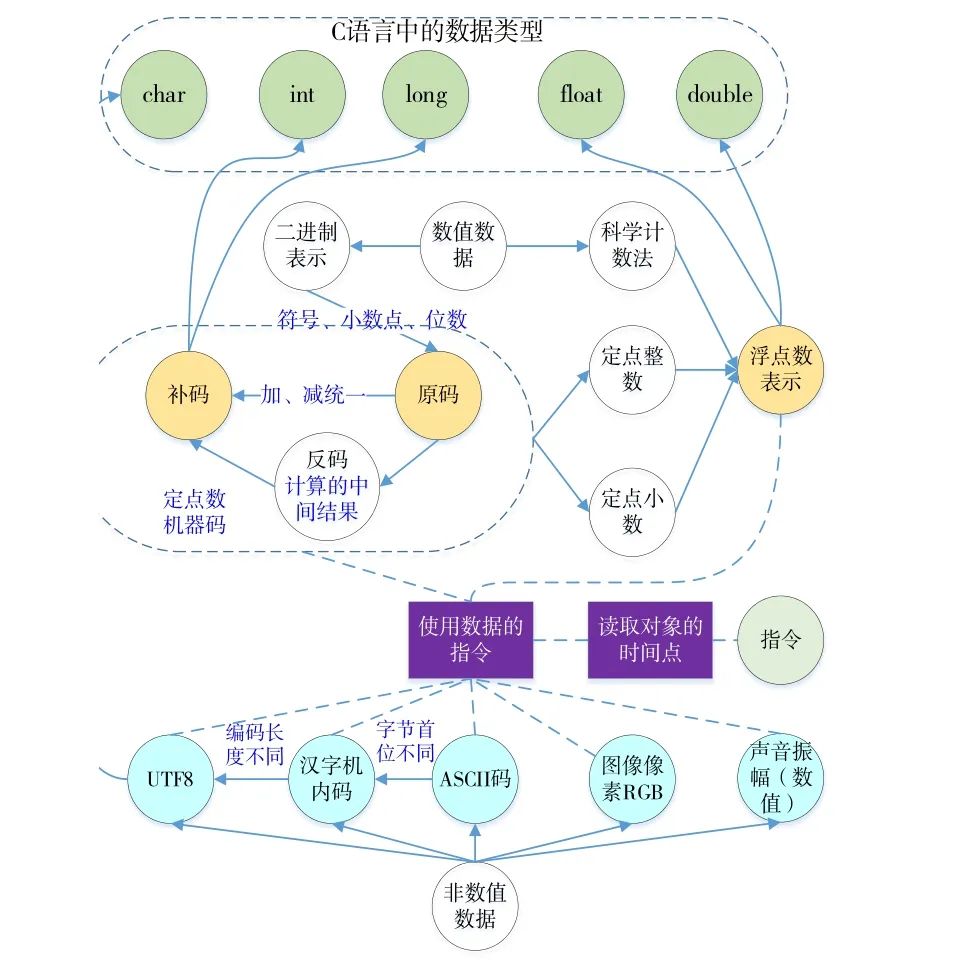
Fig.4 Sub-network of "data representation" knowledge point图4 “数据表示”知识点的概念子图
5 结语
在计算机专业系统能力培养时,课程内容的选择和课程术语的梳理是课程群建设和教学改革的重要基础,目前方法主要是基于任课教师的经验,缺乏定量分析,主观性较强。如何自动且有效地将各课程中的术语知识点有机组织起来,帮助教师在教与学时把握重点、理清关系,站在课程、课程群甚至整个专业的高度理解各个术语,提升系统观和系统能力,这是本文构建概念图谱的主要目的。本文通过文本分析、自然语言处理等技术实现课程群概念图谱构建,辅助教师和学生由点及面地理解知识点,架建知识框架,形成系统能力。
本文以计算机系统类课程群为例,详细阐述了课程群概念图谱构建的完整过程。首先,使用基于规则和统计的方法以及基于BiLSTM+CRF的模型,从教材文本中抽取用于构建图谱节点的关键术语;其次,通过基于规则匹配的术语定义识别算法和基于向量空间模型的定义筛选算法,从文本集中筛选最适合术语的定义作为相应节点的属性,以术语在段落中的共现和在小节中的共现作为关系紧密程度的区分,分别构建了紧密关系和普通关系两种边,在图谱中加以区分展示;第三,基于PageRank算法,分析概念图谱中术语的重要性,将术语分为重要术语和普通术语,并在图谱中区分显示;第四,选择高效的存储方法,将课程群概念图谱进行存储,用以辅助教学。
本研究是课程群概念图谱的初步探索,还有很多待改进之处,如计算机专业领域包含学科课程众多,目前只对4门主要课程进行语料库构建。后续工作中,可以继续添加新课程教材文本,以及进一步扩充语料库等。由于不同课程之间术语大多不同,本文的标注方法需要耗费大量人力,接下来可以进行方法的替换和更新,自动生成专业语料或者使用迁移学习更方便地构建语料库。此外,本文所使用的基础混合算法模型,在已学习的数据集上表现较好,而在更换上下文环境后以及进行新术语识别方面,还有待提高。可在基础算法上作进一步优化,例如:在词向量中加入子词单元、语言学特征、注意力机制、多维特征等,以提高模型适应性和识别能力。同时,由于教材文本的行文特点,其中存在大量口语化表达,从而导致抽取出的结果中出现同义术语的多种表述形式,而这样的同义术语应当在概念图中使用一个节点进行表示。后续应对抽取的术语进行同义词合并,进一步优化课程概念图的存储空间和查询效率。
