基于Vision Transformer Hashing的民族布艺图案哈希检索算法研究
2023-07-13韩雨萌段晓东
韩雨萌,宁 涛 ,段晓东,高 原
(大连民族大学 a.计算机科学与工程学院 b.大数据应用技术国家民委重点实验室,辽宁 大连 116650)
中国是一个拥有五十六个民族的统一多民族国家,在长期历史发展过程中,多民族文化共同组成了中华文化。在众多民族文化的灿烂结晶中,民族图案是不可或缺的宝贵非物质文化财富,它承载了一个民族发展的历史,是一个民族思想、历史、艺术和美学的综合体现。因此,认识和保护民族图案具有重要意义。许多学者进行了相关研究:如刘战东等,引进克隆算子对民族图案基元进行操作,并提出一种民族图案生成算法[1]。刘菲朵提出了一种改进的图案分割算法SGB,实现了交互式民族图案分割系统[2]。张志宇提出了一种基于深度学习的民族图案识别算法,能够提取较为高级的语义特征,且运算时间和运算精度都得到了提升[3]。
民族图案种类繁多、样式复杂,且其中往往蕴含着大量的深层语义,机器获取这些深层语义也往往是十分困难的,再加上相关数据集难以收集,相关研究较少,使得进行这项研究具有重要意义。苗族蜡染图案如图1,侗族织锦图案如图2。

图1 苗族蜡染·鸟头蝴蝶 图2 侗族织锦·八角花
图像检索研究自上世纪七十年代开始,已经经历了数十年的发展过程,其发展阶段从文本检索、内容检索、反馈检索一直到最近的特征检索。传统的图像检索即基于文本的检索存在很多问题,最主要的就是人工标注的成本太大,以及不能充分表达图像。随着基于内容的图像检索CBIR的提出与发展,文本检索的缺陷不断被避免,检索的效率和精度也不断得到提高。深度神经网络模型的提出和不断迭代更新,计算机视觉领域里,各种视觉技术都得到了滋润与发展。图像检索作为计算机视觉领域里的一个重要课题,也因此得以飞速发展。
1 相关工作
VIT(Vision Transformer)是一种将transformer运用在计算机视觉领域的模型,最初被应用在图像分类领域,这虽然不是transformer第一个被应用在计算机视觉领域所提出的模型,但因为其模型简单且效果好,可扩展性极佳,成为了transformer在计算机视觉领域的里程碑式模型。自从神经网络模型问世以来,计算机视觉领域的重点任务得到了飞速发展。
在传统的图像检索面临不够轻量级、抓取特征效率低、算法不够简单以及面对大型数据集检索效果不好等问题时,开始有人将神经网络运用在图像检索任务中,如邹凯提出了一种基于改进AlexNet的布料色卡图像检索方法,能够满足用户通过所构建模型快速和准确地检索所需布料色卡信息的要求[4]。王佳婧、金壮等提出了一种基于面部特征增强和CNN网络结构的民族人脸图像检索方法,并实现了多种图像检索模式结果的可视化[5]。而随着CNN网络结构的提出,各种其他不同的网络结构也在几年之内被接连提出,也接连地被应用到图像检索的领域,提出了一种基于CBAM-ResNet50的民国纸币图像检索方法,所提取的民国纸币图像特征具有更强的辨识度[6]。
VIT网络模型的提出,将图像检索研究又推向了新的高潮,Nouby等人提出的以VIT为主干网络的图像检索方法[7],将图像检索的精度进一步提升。
在图像检索技术蓬勃发展的大背景下,民族图案检索也作为图像检索领域的一个细分专业领域,逐渐被国内的学者关注,例如,闫龙泉提出了一种基于深度哈希的唐卡图像检索研究方法,利用ResNet50和SKNet结合了藏族特色艺术瑰宝唐卡的图案特征,将唐卡图像特征进行提取与聚合,经过多尺度对数变换和网络自主相关参数学习,使得唐卡图像效果得到了增强[8]。温雅利用EGBIS图像分割法和SURF算法设计了一种民族图案检索系统,能够实现对民族图案内容的检索功能[9]。邹悦利用ResNet50网络、字典学习与语义分析对苗族蜡染图案进行了研究,提出了一种基于内容的民族纹样图案识别检索方法[10]。但是综合来看,国外的诸多学者虽然也有研究民族图案,但其只集中在本国的民族图案,中国的民族图案具有鲜明的特点,所以其方法多不具有借鉴性。反观国内,由于民族图案数据集获取困难、特色性较强、图案内容复杂多样,只针对于民族图案的图像检索方法研究还比缺乏,现有的图案检索,多只专注于单民族单一种类图案进行检索,内容不够充实。
为了解决以上所述存在的问题,本文基于Vision Transformer网络结构,以哈希图像检索为检索框架,提出了针对于民族布艺图案的VTDSH哈希民族布艺图案检索方法。
2 数据集
由于题材特殊,以及涉及到非物质文化遗产保护和版权问题,网络上民族布艺图案数量较少,而实验所需要的关于这些民族布艺图案的语义和背景解释则更少,没有公开的大型民族布艺图案数据集。为了进行相关实验研究,我们自行进行了数据集的构建。
通过各种渠道获取民族布艺图案内容,并学习民族背景文化以求专业地解释各个图像的含义、进行标注。我们获得原始图像约一千五百张,由于民族布艺图案本身多被加工在布料和各种装饰物上,且一张图片内,往往杂糅了很多不同种类的数据,不符合直接作为数据集的要求,所以我们将这一千五百张图片进行了数据清洗、归一化处理以及图案内容分析,将图像进行了切割、填充等处理,将所有图案全部转换为256×256大小,并全部转换为RGB图像,最终得到了包含六类2 785张图片数据集如图3。这2 785张图片中,包含来自苗族、侗族、瑶族三个民族的蜡染、织锦图案,其中蜡染图像分为鱼类蜡染图像、鸟类蜡染图像和蝴蝶蜡染图像,织锦图案分为菱形织锦图像、人形织锦图像和八角花织锦图像,其中鱼类蜡染796张,鸟类蜡染607张,蝴蝶蜡染547张,菱形织锦477张,人形织锦60张,八角花织锦298张。

图3 民族图案数据集(部分)
3 VTDSH模型的提出
3.1 VIT模型结构
简单来说,Vision Transformer模型由Embedding层、Transformer Encoder和MLP Head三个模块。
Embedding层输入的是一个二维矩阵,即token序列[num_token,token_dim], token0-9都是向量,以VIT_B-16为例,每个token的向量长度为768,在输入Transformer Encoder之前构成。需要加上[class]token和Position Embedding,专门用于分类,与之前从图片中生成的tokens拼接在一起。
而Transformer Encoder则是将如图4所示的block堆叠多次,这之中包括Layer Norm、Multi-Head Attention、Dropout和MLP。
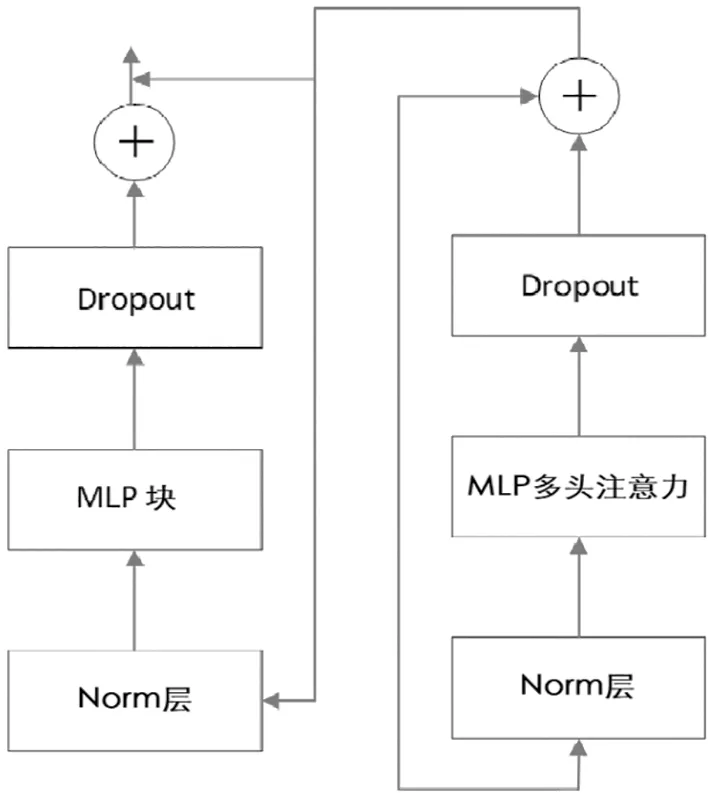
图4 Transformer 模组
3.2 深度监督哈希DSH
深度监督哈希,即Deep Supervised Hashing,是一种通过学习紧凑的二进制代码,以求在大规模数据集上高效进行图像检索的哈希方法,它以CNN架构为基础,将成对的图像(相似、不相似)作为训练输入,并鼓励每个图像的输出接近离散值(如±1),通过编码图像对的监督信息,并同时将输出进行正则化处理以近似所需要的离散值,新出现的查询图像将被输出量化为二进制码,可通过网络传播。
3.3 VTDSH模型的提出
VIT网络具有优良的性能,其体量小,运行速度快,而DSH中所运用的网络为简单的卷积神经网络,所以将DSH中的卷积神经网络替换成VIT网络,去掉VIT网络的头部,并对DSH算法进行参数调整。
整个模型的流程图如图5。
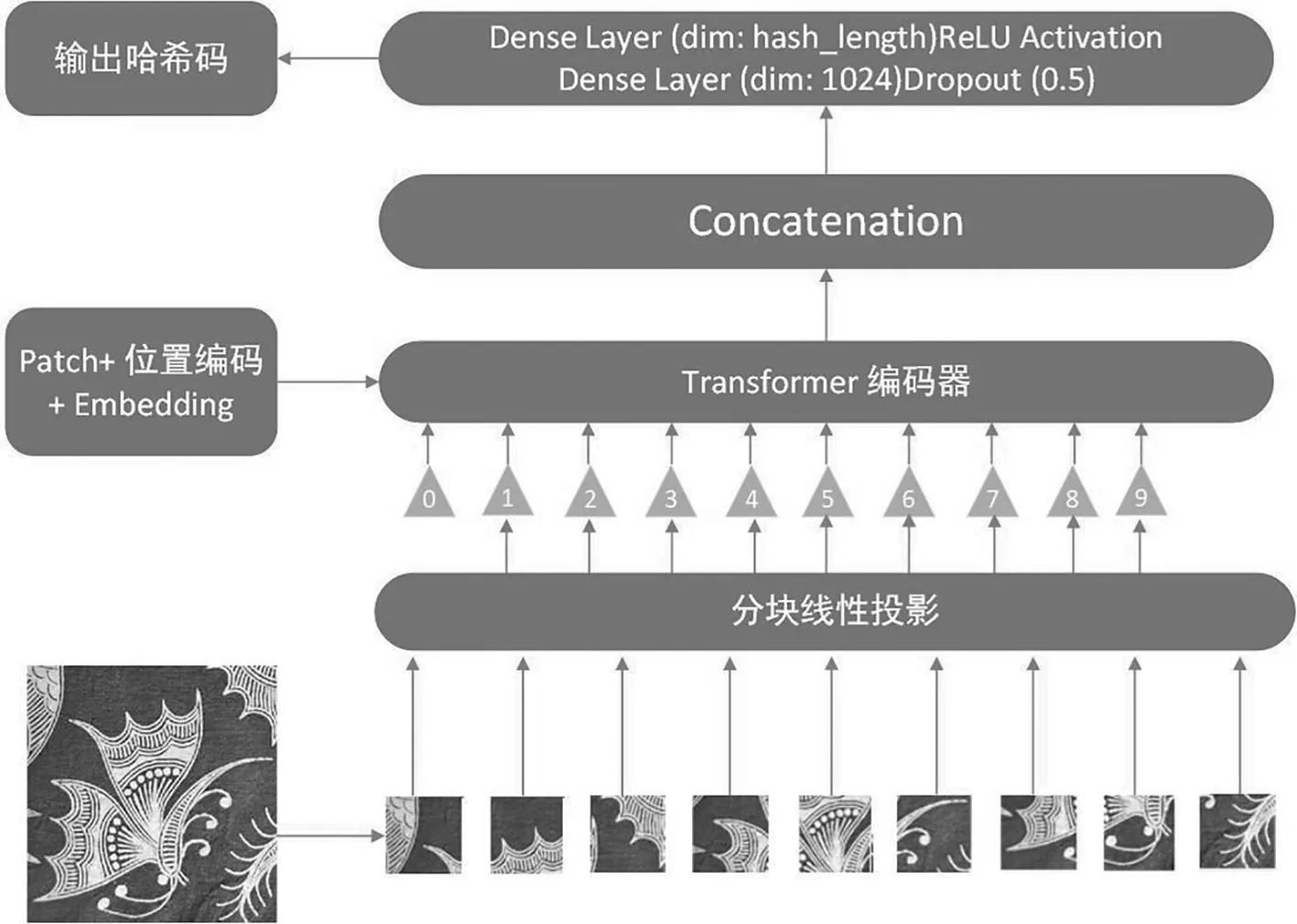
图5 VTDSH模型流程图
用VIT网络对图像的特征进行提取,利用DSH算法生成每一张图像的哈希码,哈希码长度各有不同,分为16、32、64,每一张图片的哈希码都是不同的,用此来分辨不同的图片,计算每一张图片哈希码之间的距离,距离越大说明图片越不相似,距离约小则越相似。
本方法中采用的损失函数为改进的对比损失函数,根据DSH图像检索方法的要求,要求相似图像的编码尽可能接近,而不同图像的编码尽可能远。所以,设一对图像I1,I2∈Ω,对应的网络输出为b1,b2∈{+1,-1}k,如果图像相似,则定义y=0,y=1。将图像的损失函数定义如下:
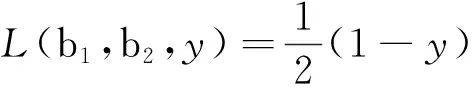
(1)
s.t.bj∈{+1,-1}k,j∈{1,2},α=0.1。
式中,Dh表示两个向量之间的汉明距离,m>0为边界阈值函数,当它们的汉明距离低于边界阈值m时,前项惩罚映射到不同二进制码的相似图像,后项惩罚映射到相似二进制码的不同图像。使用对比损失函数是为了符合本方法样本成对的特点,并且这种损失函数在降维中时,经过特征提取后,在特征空间中,两个样本仍然相似,原本不相似的样本,经过特征提取之后,两个样本仍然不相似。
4 实 验
实验中,本文在自建的民族布艺图案数据集minzudataset上划分训练集和测试集,训练集2 400张,测试集385张,每张图片重置大小为256×256,cropsize大小设置为224×224,训练中,网络的学习速率设置为0.000 1,迭代训练150个周期,每30个周期为一批次,每一个周期迭代训练2 400次,每一个batch设置大小为32,每30次训练计算一下平均精度,alpha值设置为0.1,将数据集在不同的网络模型。
首先使用不同的哈希算法对图像进行对比检索,将VIT的头部去掉,换成其它的哈希算法,并进行对比实验,实验结果见表1。其中16、32、64为散列码长度,DSH、CSQ、DPN、GreedyHash、HashNet、IDHN为深度哈希检索框架。
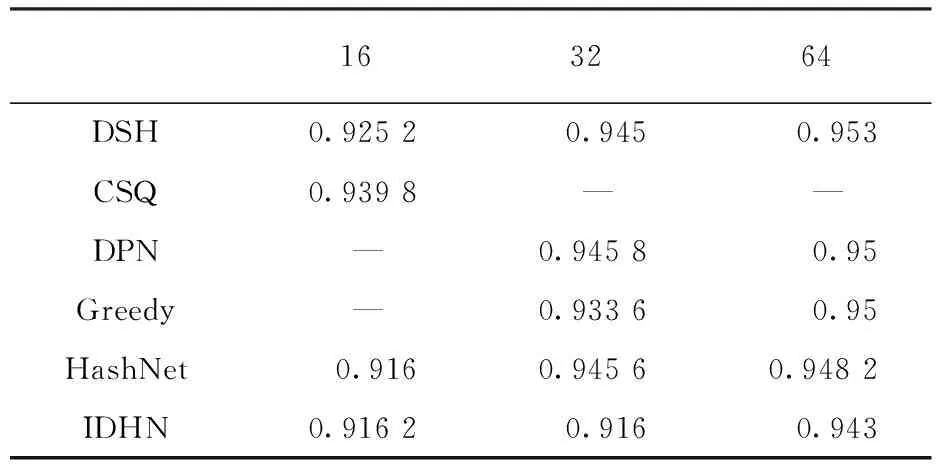
表1 不同检索方法下的平均mAP
从表1可以看出DSH在与VIT搭配时表现效果最好,mAP可以达到0.953。
将DSH放在不同的网络结构下继续进行检索实验,结果展示见表2。其中16、32、64为散列码长度。
从表2可以看出,在使用VIT网络为特征提取网络时效果最好,且在VIT16和VIT32模型时效果都为0.953,VTDSH模型的mAP在散列码位数为64时最高,比其他网络模型的平均mAP值要高,可以得出该模型有效且针对于民族布艺图案数据集有良好的图像检索性能。
5 结 语
提出了一种新的面向多民族多种图案的深度学习哈希图像检索方法,与传统的深度哈希图像检索方法相比,本文所提出的VIT-DSH方法使用VIT网络结构作为主干网络、DSH深度哈希为检索框架,通过实验证明本文的方法更快,针对于民族布艺图案数据集检索精度更高。
