洞庭湖湿地净初级生产力估算研究
2023-07-13张猛陈淑丹林辉刘洋张怀清
张猛,陈淑丹,林辉,刘洋,张怀清
1.中南林业科技大学 林业遥感信息工程研究中心,长沙 410004;
2.中南林业科技大学 林业遥感大数据与生态安全湖南省重点实验室,长沙 410004;
3.中南林业科技大学 南方森林资源经营与监测国家林业与草原局重点实验室,长沙 410004;
4.中国林业科学研究院资源信息研究所,北京 100091
1 引言
湿地是地球上重要的“碳库”之一(张猛 等,2017;Mao等,2020),在调节碳平衡以及维持全球气候稳定方面具有不可替代的作用(Cai等,2020;Ye 等,2019)。净初级生产力NPP(Net Primary Productivity)是单位时间和单位面积内植被通过光合作用固定的有机物质的净积累,是表征碳通量状况的重要指标(张猛和曾永年,2018;朱文泉等,2005)。由于持续的气候变化和人类活动,湿地大面积的消失和退化,因此,适时、准确地估算湿地NPP 对于湿地植被碳储量估算对湿地资源的可持续发展及区域碳循环具有重要的意义。
遥感影像覆盖范围广、重访周期短且获取成本低等特点,使得遥感数据结合估算模型成为NPP 反演的主要方法(Bao 等,2016;Shang 等,2018;Yu 等,2018;尹小君 等,2020)。早期湿地的NPP 遥感估算研究主要依靠低空间分辨率遥 感数 据(AVHHR,MODIS,SPOT Vegetation)(Bandaru 等,2013;Liu 等,2019),尽管其能准确的反映NPP 的时间变化,但遥感数据空间分辨率过低会导致NPP 估算结果的空间细节信息呈现不够,同时还会给NPP 精度验证带来困难。另外,由于气候变化和人为因素的持续干扰,湿地斑块破碎化越来越严重。因此,高时空分辨率的遥感数据对于湿地NPP 估算显得更为重要。目前的中高分辨率光学遥感影像数据源十分丰富,综合考虑数据的历史记录、可获取性、覆盖范围、空间分辨率及处理难易程度,Landsat 数据为长时间序列湿地NPP 估算的最佳遥感数据源(Long 等,2021)。然而受天气及重访周期的影响,时序Landsat 数据的获取受到限制。多源遥感时空融合方法的出现为获取时序Landsat 提供了契机,并有大量的研究利用时空融合技术来解决遥感影像的“时空矛盾”问题(Gao等,2006;Zhu等,2010;Wu等,2015;Zhao等,2018;Zhang等,2021)。总体而言,基于时空滤波器的融合框架STARFM(Spatial and Temporal Adaptive Reflectance Fusion Model)是 应用最为广泛的方法。尽管进行了不同方式的改进与应用,但基于时空滤波器的融合框架仍存在一些不足之处,如复杂的变化预测能力和预测模型的鲁棒性等(Cheng 等,2017)。Cheng 等(2017)提出的基于时空非局部滤波器的融合模型STNLFFM(Spatial and Temporal Nonlocal Filter-based Fusion Model)在增强预测能力和准确性方面较STARFM更有优势,尤其是针对于复杂多变的景观。然而,传统的时空融合算法需要对遥感影像进行下载、预处理与融合,面对大尺度、高时空遥感影像获取时,时间与运算成本会大大增加。遥感云计算平台GEE(Google Earth Engine)为海量遥感数据的存储、快速处理和分析提供了可能,改变了传统遥感数据的处理和分析模式,极大地提高了运算效率。因此,构建基于遥感云计算平台的时空融合算法,能够快速、有效地解决大尺度、时序密集型Landsat数据的获取问题。
光能利用效率模型CASA(Carnegie-Ames-Stanford Approach)是不同尺度NPP 建模和时空动态演变使用最广泛的模型之一(Potter 等,1993;Singh,2011;Yan等,2018;许静 等,2019;孙金珂 等,2020)。在CASA 模型中,NPP 由植被吸收的光合作用有效辐射(APAR)和光能利用效率(ε)的乘积得到(Mu 等,2013;Piao 等,2005)。CASA 模型中,估算ε需要确定不同植被类型理想条件下的最大光能利用率(εmax),再结合水分胁迫因子(W)与温度胁迫因子(T)得到实际光能利用率ε(Potter 等,1993;Piao 等,2005;Bao 等,2016)。一方面,确定不同类型的εmax,高精度的植被分布图十分关键。单一机器学习算法容易陷入局部最优解,未知样本的泛化能力较差,在不同分类场景中鲁棒性和稳定性稍显不足。卷积神经网络CNN(Convolutional Neural Networks)作为目前深度学习扩展研究最热门的算法之一,尽管CNN 在图像分类上由巨大的效率和精度优势,但其依赖于巨大的训练数据,同时训练过程复杂且耗时量大。集成学习通过多个基分类器及元分类器来预测最终结果,因此,其适用于各种场景的能力较强,分类准确率较高。目前Stacking 算法在集成学习模型(Boosting,Bagging,Stacking)中在分类任务中相对稳定,然而Stacking 算法的基分类器最优组合结构需要多次重复实验才能确定,当基分类器数量较多时,该过程将十分繁琐。因此,本文通过改进Stacking 算法并对湿地植被进行识别,以提高湿地植被分类精度和分类效率。
另一方面,CASA 模型中水分胁迫因子通常从单层预算土壤水分模型获得,但是复杂的模型结构和粗糙分辨率的栅格土壤参数数据会影响W和NPP 的估算精度(Mao 等,2014;Xiao 等,2004;Bao 等,2016)。陆表水体指数LSWI(Land Surface Water Index)代表叶片和冠层含水量以及土壤水分,已有的研究表明利用LSWI 可以较为准确地估算水分胁迫因子W(Xiao等,2004;Bao等,2016)。然而,Xiao 等(2004)计算出来的水分胁迫系数的取值范围为0(非常湿润)到1(极端干旱),与CASA 模型中水分胁迫因子的取值范围是0.5(在极端干旱条件下)到1(在非常潮湿的条件下)正好相反,Bao 等(2016)则对水分胁迫因子的范围进行了修正。利用LSWI 得到的水分胁迫因子不仅在空间上呈现出与NDVI 的一致性,而且还能准确的表达区域的水分胁迫。
基于此,本文以洞庭湖湿地为研究对象,采用遥感云平台下的时空融合算法便捷、准确地获得了时间序列Landsat 影像,解决了NPP 估算中高时空分辨影像缺失的问题;发展自适应Stacking 集成算法,并基于该算法获得高精度的湿地植被分布图和单个植被像元中的最大光能利用率;同时利用时序Landsat影像获得LSWI,并结合降水数据计算获得NPP 估算中所需的水分胁迫因子,最后驱动CASA 模型对洞庭湖湿地NPP进行估测。本研究结果以期为改善与提高湿地植被NPP 估算及碳储量研究提供有效的技术方法。
2 研究区与数据
2.1 研究区概况
本文选择的研究对象为洞庭湖区,位于长江中游地区的湖南省东北部,是中国重要的湿地分布区,也是中国重要的商品粮基地,对区域气候及可持续发展具有十分重要的意义。该区属亚热带季风气候,雨热条件十分优异,主要自然湿地植被类型包括苔草、芦苇,其他植被主要为林地及其他耕地上的轮值作物(Cai 等,2020;Zhang等,2020)。
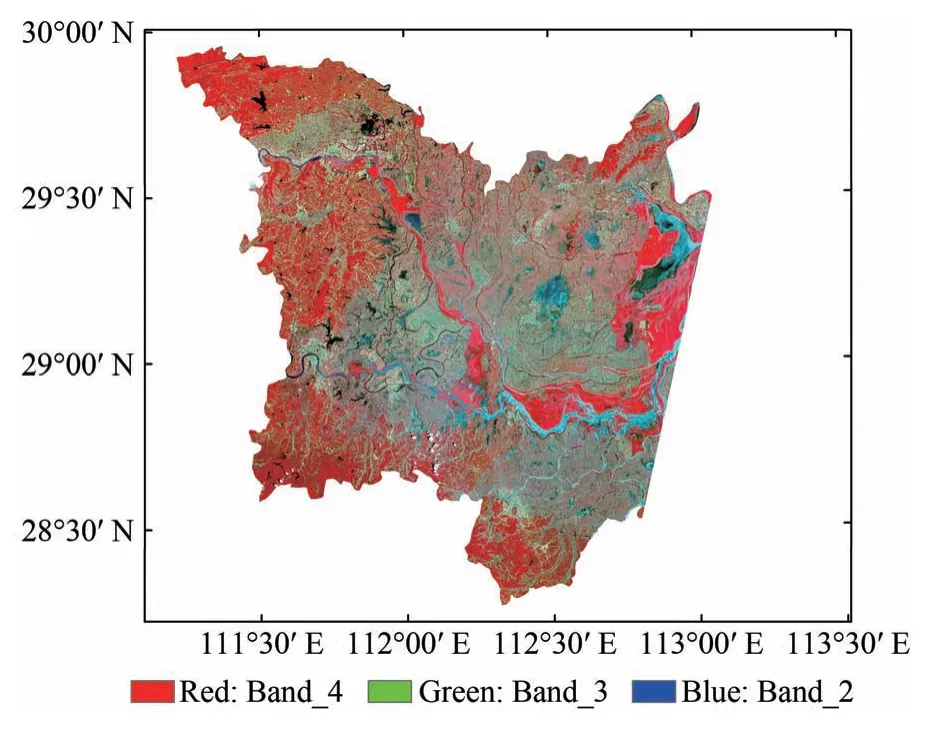
图1 研究区位置图Fig.1 Study area
2.2 数据及预处理
研究使用的遥感数据包括Landsat 8 OLI 多光谱影像和MOD09Q1 反射率产品,年份为2017 年,均下载于Google Earth Engine。所下载Landsat 8 OLI行列号为123/39、124/40,云量均小于5%,共12景。所需MOD09A1数据行列号为h28h06,时间段为1—12 月,共46 景。尽管MOD09A1 数据在合成过程中去除了一些气溶胶和云污染,但仍然存在着一些无效值,因此本文利用TIMESAT 软件包中的Savitzky-Golay 滤波算法对时序MOD09A1 进行滤波(Jönsson 和Eklundh,2004)。MOD09A1 数据的预处理还包括转投影(UTM,与Landsat 8 一致)、裁剪和与Landsat 8影像进行配准。
野外调查数据包括用于验证分类精度的调查数据和用于验证NPP 估算的生物量调查数据。用于验证分类精度的调查数据的采集时间为2017 年5 月,采用分层随机抽样方法进行采样,分别获得36 个苔草样本、40 个芦苇样本、42 个耕地样本、38 个林地样本、32 个湖泊/河流/库塘样本及30 个其他样本。用于验证NPP 估算的生物量样本采集时间为2017 年9—10 月,主要为苔草(22)、芦苇(24)以及两者的混合样本(25)。为与Landsat 影像像元相匹配,样地大小为30 m×30 m,内置5 个1 m×1 m 的小样方(位于大样方的对角线和中心位置)。在小样方内采集植被并烘干,然后基于碳含量将生物质的干重转换为碳的重量,本文使用的含碳量系数为0.475(Ye等,2019)。
气象数据主要为2017 年的月平均温度、降水及太阳辐射,均下载于中国气象数据网(http://data.cma.cn[2021-12-03])。这些数据来自于40 个气象站和20 个太阳辐射观测站。此外,本研究区域中的DEM(30 m)及其衍生数据(坡度、坡向)结合多元线性回归方法来将气象数据空间化。
其他辅助数据包括Google Earth 高分辨率影像、GF-1 多光谱影像(2017 年5 月)以及湖南省土地利用现状数据,主要用于辅助选取湿地分类样本。
3 研究方法
本文提出洞庭湖湿地NPP 估算方法的技术路线如图2,主要包括3 个部分:(1)利用遥感云平台下的时空融合算法获得时间序列的Landsat 8 多光谱影像,并基于光谱影像计算得到时间序列的Landsat 8 NDVI 与LSWI;(2)基于Landsat 8 数据集,利用自适应集成算法(Stacking)分类得到高精度的洞庭湖湿地植被分布图;(3)利用植被分布图确定每个植被像元的最大光能利用率(εmax),通过时序LSWI 与月平均气温得到水分胁迫因子和温度胁迫因子,同时结合太阳辐射与时序NDVI,并驱动CASA模型得到高时空分辨率的NPP。
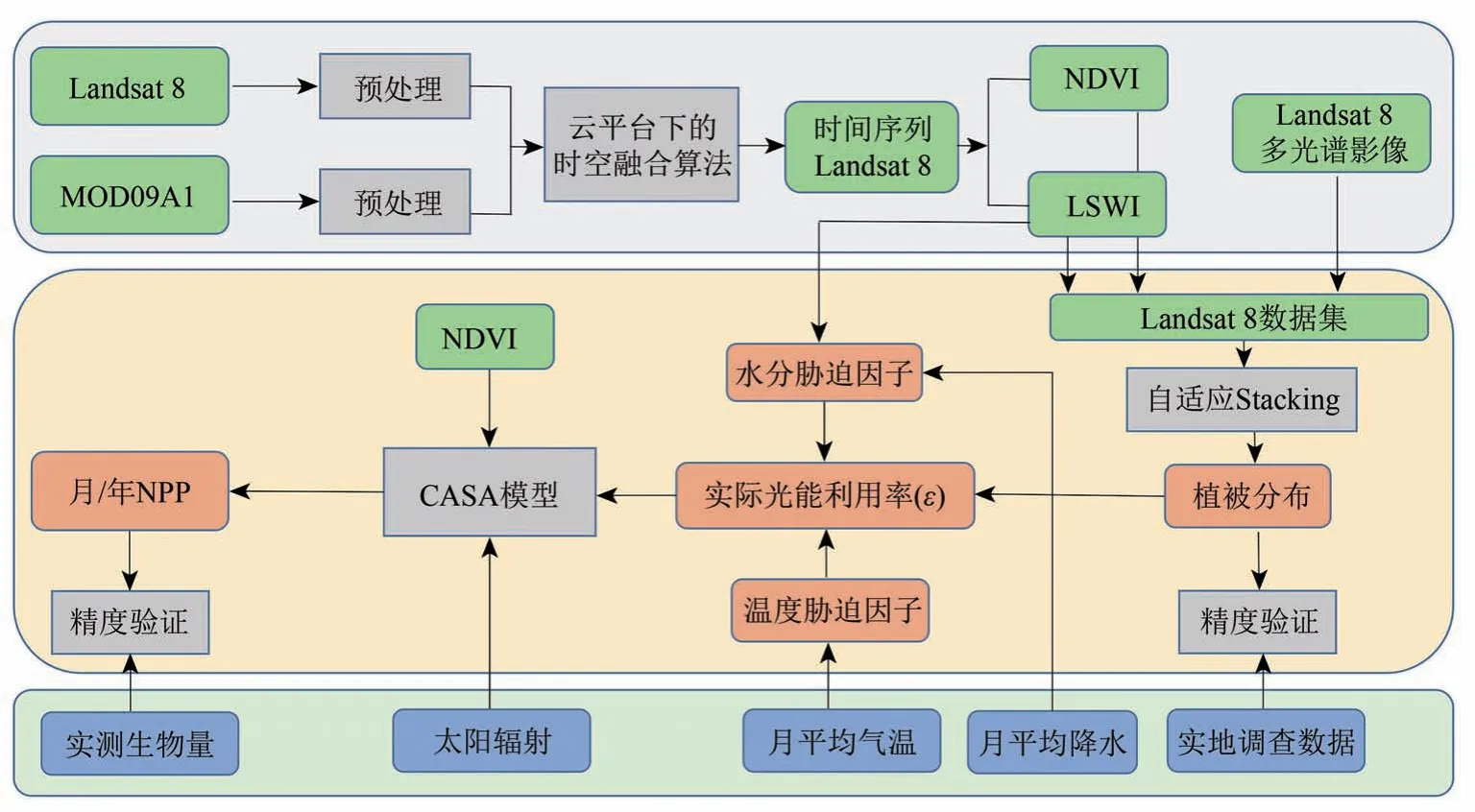
图2 技术路线图Fig.2 Flowchart
3.1 遥感云计算下的时空融合算法
本项目基于GEE 遥感云平台拟构建的时空融合算法,在解决运算量和运算时间成本高等问题的前提下,改进了异质性问题,当土地覆盖类型变动更复杂时,能够有效提高融合精度。该算法通过GEE 平台的Python 端接口实现,融合算法参考了Cheng 等(2017)提出的STNLFFM 时空融合模型,并在数据融合影像的选择上进行了改进,使得在选用所需融合影像时更加便捷,总体技术路线如图3。STNLFFM 与STARFM、ESTARFM 算法同属于基于时空滤波的数据融合方法,但在选取相似像元时,STNLFFM 采用非局域滤波算法(Cheng等,2017)。该算法不仅考虑与中心像元临近的像元,而且还考虑非中心像元的临近像元,因而使得STNLFFM 算法能充分利用遥感影像的融合信息,获取更多有用的相似像元信息。在STNLFFM算法中,每个目标像元预测的计算公式如下:
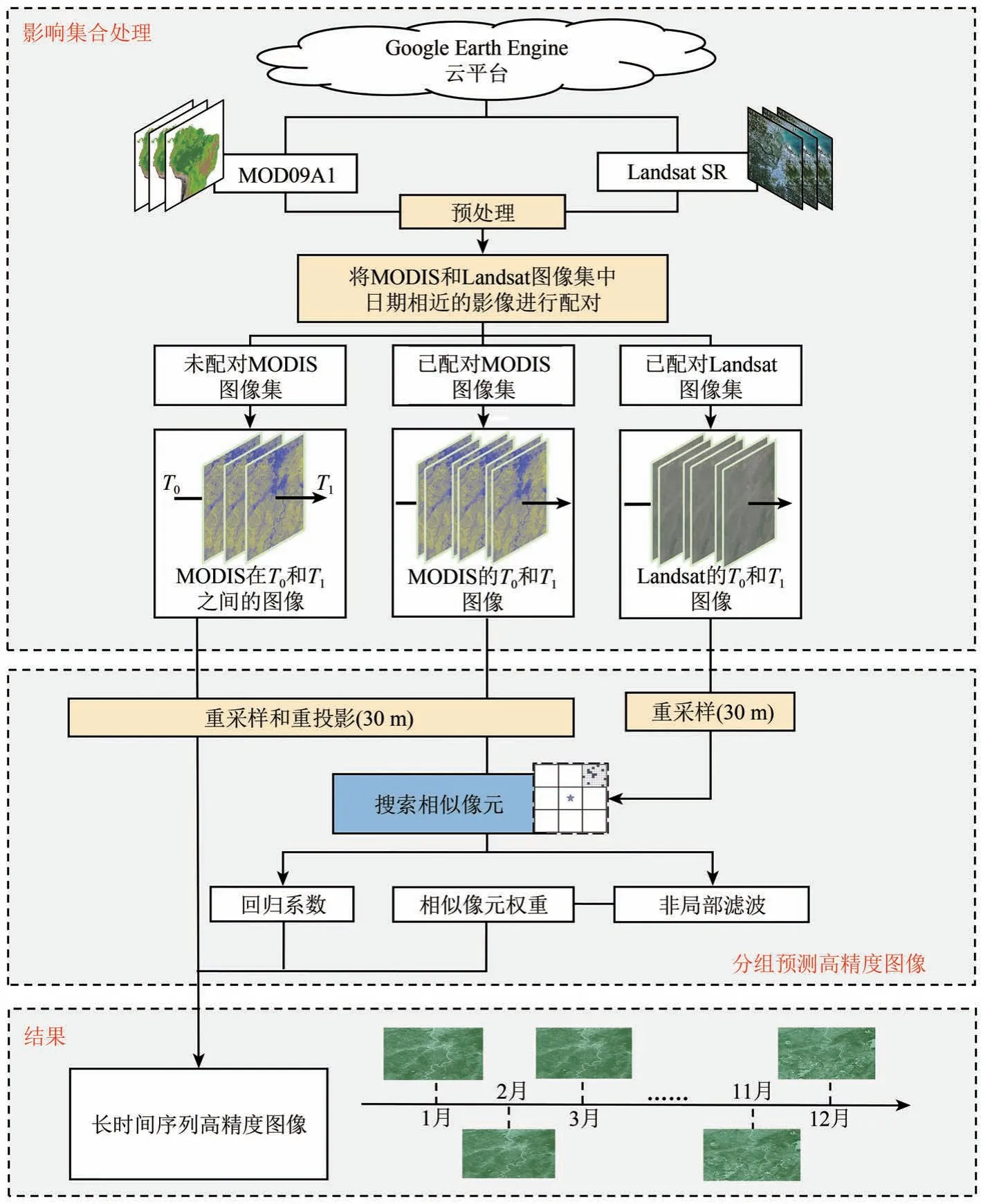
图3 遥感云计算下的时空融合算法流程Fig.3 Spatio-temporal fusion algorithm process under remote sensing cloud computing
式中,F(x,y,B,tp)是目标(预测)像元(x,y)在预测日期tp的精细分辨率反射率;M是基准日期的数目;N是图像中类似像元的数目,包括目标像素本身。(xi,yi)是第i个相似像元的位置,W(xi,yi,B,tk)是在基准日期tk处的高分辨率反射图像的第i个相似像元的权重。关于STNLFFM 与非局部滤波算法的更多细节信息与源代码可参考(Cheng 等,2017)。在融合过程中,选择基期影像的日期尽量与预测目标影像的日期接近。通过STNLFFM 算法,将2017 年46 期30 m 分辨率的反射率数据融合预测出来,并通过公式计算得到时序NDVI 与LWSI。同时,利用真实的Landsat 影像对融合得到的Landsat 影像进行精度验证,验证指标包括两者的决定系数(R2)、均方根误差(RMSE)及光谱角(SAM)。
3.2 基于自适应Stacking集成算法的湿地植被分类
准确的湿地植被分布图是湿地NPP 准确估算的一个重要的因素。在湿地植被分类方法,单一机器学习算法容易陷入局部最优解,未知样本的泛化能力较差。集成学习通过多个基分类器及元分类器来预测最终结果,因此,其适用于各种场景的能力较强,分类准确率较高(Zhang 等,2020;Cai 等,2020;Long 等,2021)。目前最流行的集成分类算法包括Boosting、Bagging 和Stacking,但Boosting 算法在实际情况下常会过分偏向一些难分的样例从而降低了算法的性能,而Bagging 算法对于稳定分类器的集成效果常常不是十分理想。因此,本文选择集成学习模型中在分类任务中对稳定性的分类器集成效果较好的集成学习Stacking 模型用于湿地分类研究(Cai 等,2020;Zhang 等,2020)。为进一步提高Stacking 算法的鲁棒性和泛化能力,本文在Stacking 算法的基础上,提出了自适应Stacking 算法(图4)。在自适应Stacking 算法中,首先确定了元分类器。以往的研究表明,使用泛化能力较强的机器算法(如RF(Random Forest))作为元分类器可以纠正多个机器算法对于训练集的偏置情况,并能够防止过拟合现象和提高预测性能。因此,在本研究中,RF算法被用作元分类器。然后,本文Stacking 集成学习的分类器组合模型第一层选择学习能力较强和差异性较大的算法作为基分类器以便于提升模型的预测效果,包括支持向量机SVM(Support Vector Machine)、RF、k-近邻kNN(k-NearestNeighbor)、逻辑回归LR(Logistic Regression)和朴素贝叶斯NB(Naïve Bayes)等机器学习算法。算法流程基本流程为:(1)输入训练数据集,让基分类器自由组合对训练数据集进行预测,并得到多个不同的新数据集;(2)通过元分类器(RF)对新的数据集进行再次预测,得到最终的预测结果。(3)通过精度验证,将精度最高的预测结果和最佳的基分类器组合进行输出和显示。
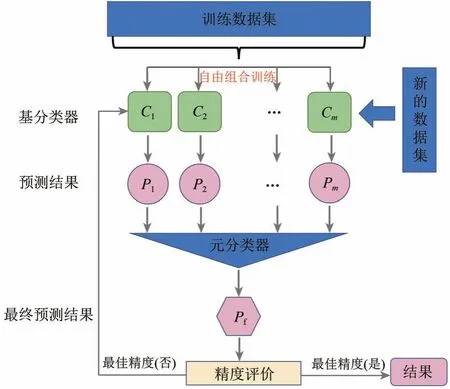
图4 自适应集成学习模型Fig.4 Adaptive stacking algorithm
由于洞庭湖湿地年内水文状况变化较大,为反映研究区湿地植被真实分布情况,本文选择了平水期(5月)的Landsat 8多光谱遥感影像、时间序列NDVI 和LSWI 数据用于湿地分类。基于《湿地公约》并结合遥感影像特征与洞庭湖区土地利用实际状况将遥感影像分为水体、苔草滩地、芦苇滩地、耕地、林地、建筑用地、其他。
3.3 基于改进CASA 模型的湿地高时空NPP 估算与验证
CASA 模型是Monteith(1972)提出的一种植被光合作用模型,其中植被的NPP可以用APAR和光能利用效率(ε)表示:
式中,PAR(x,t)为像元x在t月的太阳总辐射量,FPAR(x,t)为植被吸收光合作用的有效辐射,ɛ(x,t)为植被的实际光能利用率;f1(x,t)和f2(x,t)为低温和高温下的温度胁迫因子,W(x,t)为水分胁迫因子,ɛmax为理想条件下的植被最大光能利用率。
最大光能利用效率(ɛmax)受植物种类的影响,取决于生命形态(即草本或木质)和碳固存的代谢途径(C3或C4)。在本研究中,使用了Zhu等(2006)基于BIOME-BGG 模型人生成的ɛmax,该ɛmax更适合中国的植被状况,林地、芦苇、苔草以及耕地的最大光能利用率分别设置为0.692、0.429、0.542和0.542。
Xiao 等(2004)提出了植被光合作用模型(VPM)中的水分胁迫参数Wvpm,用于估算CASA模型中的每个像元的水分胁迫因子:
式中,Wvpm和LSWImax分别是植被光合作用模型中的水分胁迫因子和单个像元的最大LSWI(使用最大合成法MVC 方法计算得到)。然而,式(4)计算出来的Wvpm水分胁迫系数的取值范围为0(非常湿润)到1(极端干旱),与CASA模型中水分胁迫因子的取值范围是0.5(在极端干旱条件下)到1(在非常潮湿的条件下)正好相反。本文利用Bao等(2016)提出的水分胁迫因子修改算法和时序Landsat 影像得到的LSWI 指数计算水分胁迫因子W,这不仅增强了数据的准确性,也提高了数据的分辨率,具体计算公式如下:
根据Wu 和Chen(2012),将降水信息纳入生态系统模型可以提高植被生产力确定的预测性能。因此,可以通过将W与降水标量(ScaledP)相乘来生成最终的水分胁迫因子(WLSWI):
式中,Precipitation 和Precipitationmax代表空间降水的单个像元在生长季节内的月降水量和月最大降水量。
确定最大光能利用效率和水分胁迫系数后,本文应用CASA 模型估算洞庭湖湿地生态系统的NPP,估算过程中不需要更改模型中的PAR,FPAR 和两个温度胁迫因子的计算。利用从地上生物量数据得到的NPP 值来验证利用本文方法估算得到的NPP 结果,验证指标主要为两种数据之间的决定系数(R2)和均方根误差(RMSE)。
4 结果与分析
4.1 遥感影像融合结果及精度验证
本文选择了2017 年5 月23 日、10 月14 日的Landsat 8 与MOD09Q1 数据作为基期影像,融合了2017 年4 月21 日Landsat 8 影像,并选择了典型湿地分布区(芦苇、苔草)来显示和验证基于遥感云平台的融合算法预测结果的精度,包括影像光谱波段、以及在后续NPP 研究中需要用到的NDVI与LSWI 指数(图5)。从目视效果上,STNLFFM在利用基期Landsat 与MODIS 影像对来预测目标日期的Landsat 表现出较好的性能。在真彩色合成(红波段、绿波段及蓝波段)的情形下,从空间分布上看,融合Landsat影像与真实Landsat影像十分接近,除了小部分区域外。同时,基于融合影像计算得到的NDVI 与LSWI 指数与真实影像也差异很小。
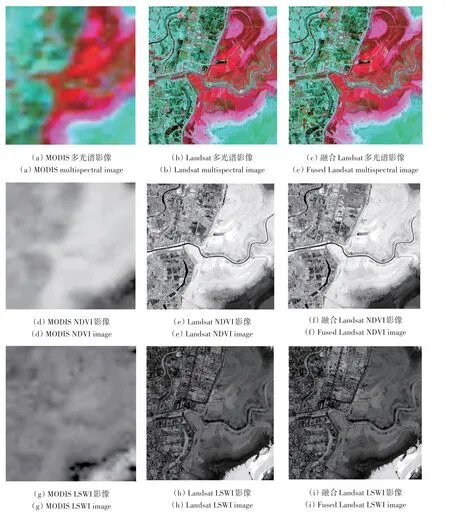
图5 MODIS影像、真实Landsat影像与融合Landsat影像Fig.5 MODIS,real Landsat and fusion Landsat images
同时,本文通过定量的方法来对融合的Landsat影像进行精度评价,融合Landsat与真实Landsat影像的相关系数、均方根误差及光谱角如表1。结果显示,融合影像与真实影像波段之间的决定系数(R2)均大于0.88,均方根误差(RMSE)均小于0.03,且光谱角(SAM)小于3,这表明融合得到的Landsat影像在光谱和空间上与真实的Landsat影像基本一致,融合效果较好,可以用于后续的湿地制图与NPP估算等研究。
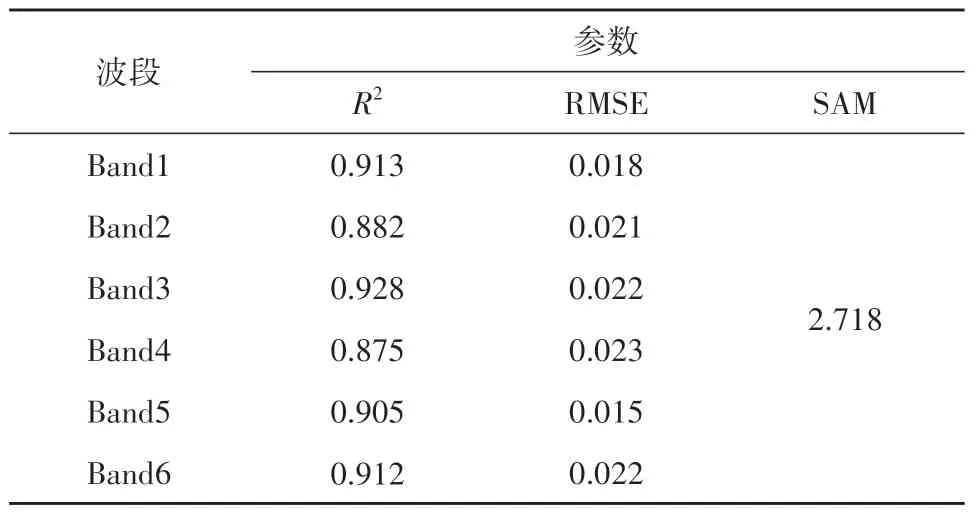
表1 融合Landsat与真实Landsat之间的决定系数(R2)、均方根误差及光谱角Table 1 Determination coefficient(R2),RMSE and SAM between fusion Landsat and real Landsat images
4.2 湿地植被分类图
利用自适应Stacking 算法得到的洞庭湖湿地植被分布图如图6 所示。苔草和芦苇是天然湿地植被,强烈依赖于水资源,因此,主要沿洞庭湖主体周围分布。耕地主要分布在研究区域的中部,那里河网密布且人类活动相对活跃。林地多分布于丘陵和山地,主要分布在研究区的四周。通过自适应集成算法中基分类器的自由组合和测试,最终算法选择的最优基分类器组合为SVM、kNN和RF,总体分类精度和Kappa 系数分布在90%和0.88 以上(图7)。此外,植被类型的用户精度和生产者精度分别在85%—92%和83%—91%。结果表明,自适应Stacking 算法能够较好的区分不同土地覆盖类型。
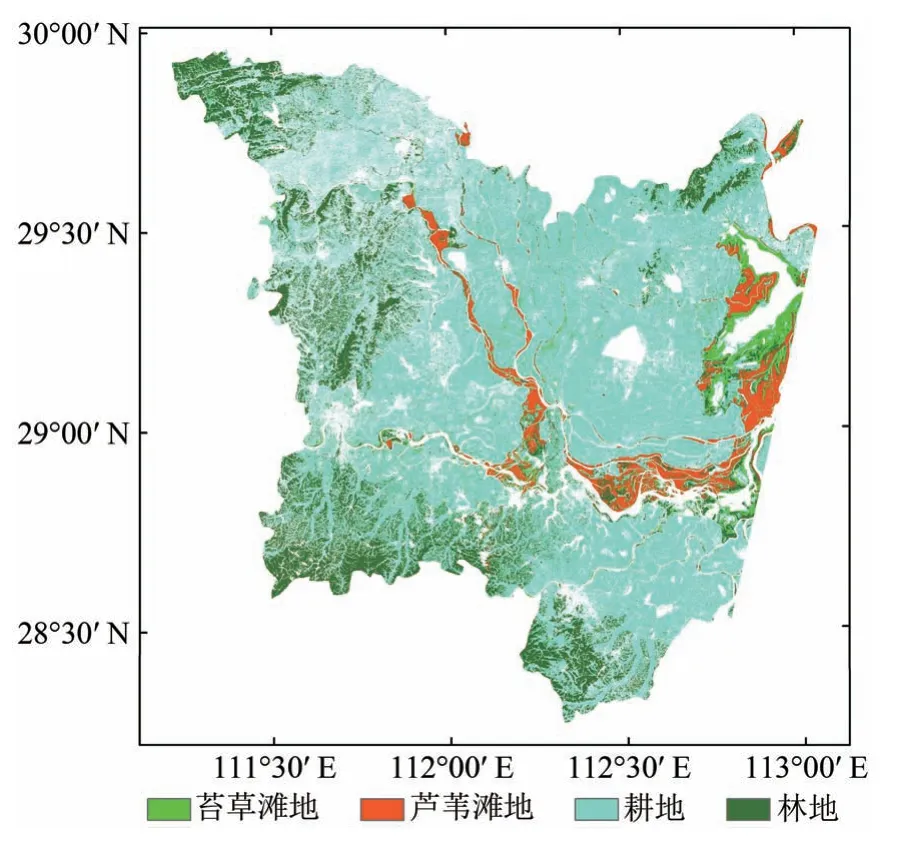
图6 基于自适应Stacking算法的洞庭湖湿地分布图Fig.6 Distribution map of Dongting Lake wetland based on adaptive Stacking algorithm
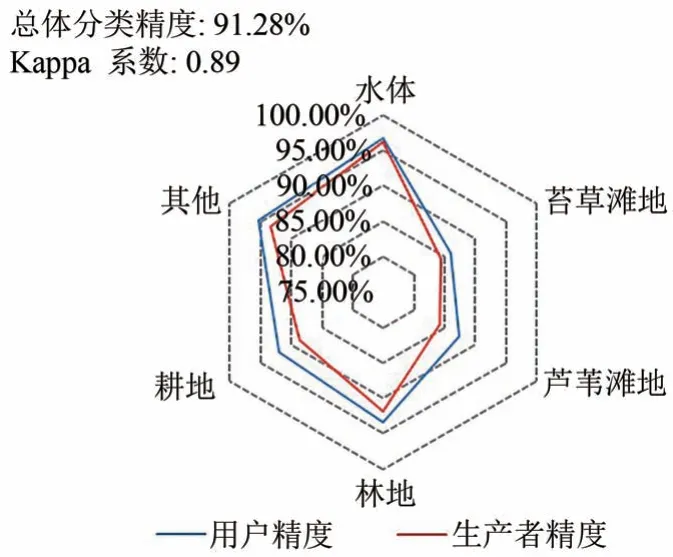
图7 基于自适应Stacking算法的湿地分布图分类精度Fig.7 Classification accuracy of wetland distribution map based on adaptive stacking algorithm
此外,本文对自适应Stacking 算法与其他传统机器分类方法得到植被分布图的精度进行了对比(图8)。结果表明,自适应Stacking 算法的分类精度明显高于传统单一分类算法(总体分类精度和Kappa 系数),表明该方法在识别复杂条件下的土地覆盖类型具有优势。由于湿地生态系统比较复杂,在分类中常常存在一些挑战,例如湿地植被类型之间以及湿地植被和其他植被之间的光谱混合。现有的机器学习算法具有不同的优点和缺点,因此,在单一数据集下往往难以得到满意的分类精度。本文提出的湿地分类方案在考虑植被光谱混合问题的同时,还利用集成学习结合了不同机器分类方法的优势,从而提高了湿地分类的准确性。
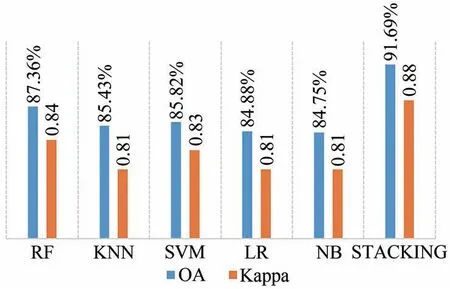
图8 传统机器分类方法与自适应Stacking算法的分类精度对比Fig.8 Comparison of classification accuracy between traditional machine classification method and adaptive Stacking algorithm
4.3 湿地NPP估算结果精度验证
在获得湿地植被分布图,确定NPP 估算中苔草、芦苇和林地最终的εmax,并使用修正后的CASA模型估算整个研究区的NPP。基于融合的Landsat NDVI 估算得到的NPP 具有较高的空间分辨率和详细的空间信息,显示了不同地类之间的细微差异(图9(a))。苔草,芦苇和耕地之间的差异非常明显,植被类型之间的界限也很明显。在洞庭湖区的中部,基本被水域覆盖,因此其NPP 接近于0。苔草和芦苇覆盖的地区,其年NPP 总量达到约300—500 g C/m2。由于人类活动的影响,研究区域的中部分布着大量耕地,NPP 总量大约在250—300 g C/m2。林地主要分布在研究区东部和南部,其年均NPP 总量约为893 g C/m2(图9(c))。本文利用地上生物量数据得出的NPP 实测值来验证模拟NPP的准确性。利用改进CASA 模型估算得到的NPP 和实测NPP 之间的相关系数为R2=0.85,两者之间的RMSE 为20.16 g C/m2(图9(b)),表现出显著的线性关系。因此,基于CASA 模型基于融合得到的Landsat 8 NDVI 与LSWI 数据的估算得到NPP 精度较好,可以适用于区域高时空NPP 的模拟与估算。
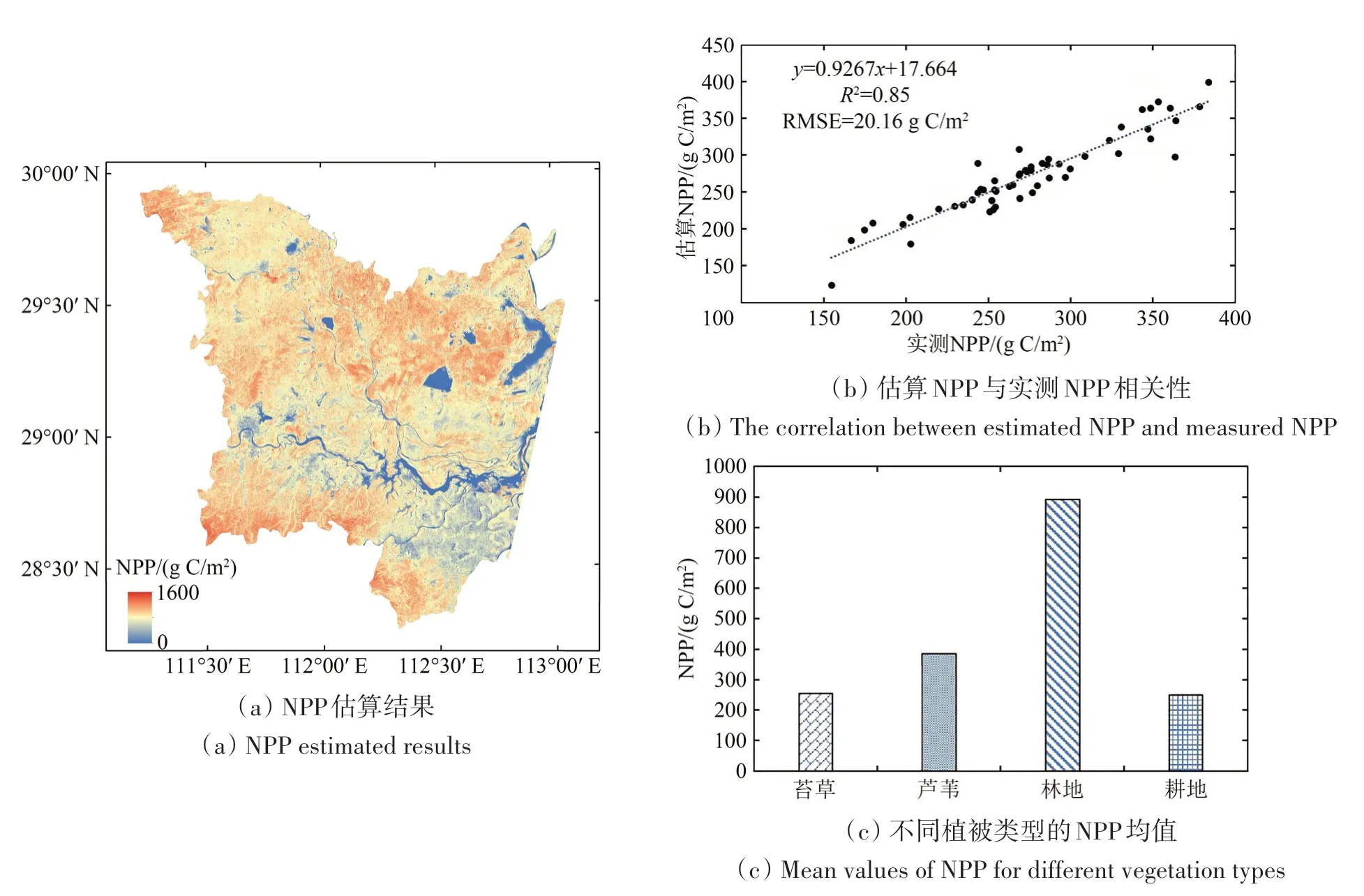
图9 洞庭湖湿地NPP估算结果及精度Fig.9 NPP estimation results and accuracy of Dongting Lake wetland
图10 显示了2017 年研究区月NPP 的空间分布和变化。3—11 月的NPP 表现出较大的时空变化,这对于湿地植被变化检测和监测具有重要的意义。由于研究区域四季分明,因此植被的生长随季节而变化。因此,研究区域的最大平均NPP 出现在8—9月。同时,估算结果显示的研究区东北部6—9月的NPP 平均值较小,主要原因是由于夏季和秋季降水量较大,苔草,芦苇甚至农作物大面积被淹没,导致相应遥感图像的NDVI 值降低的缘故。本文的NPP 估算方法有望为区域湿地碳储量和可持续发展等定量研究提供科学的数据支持。
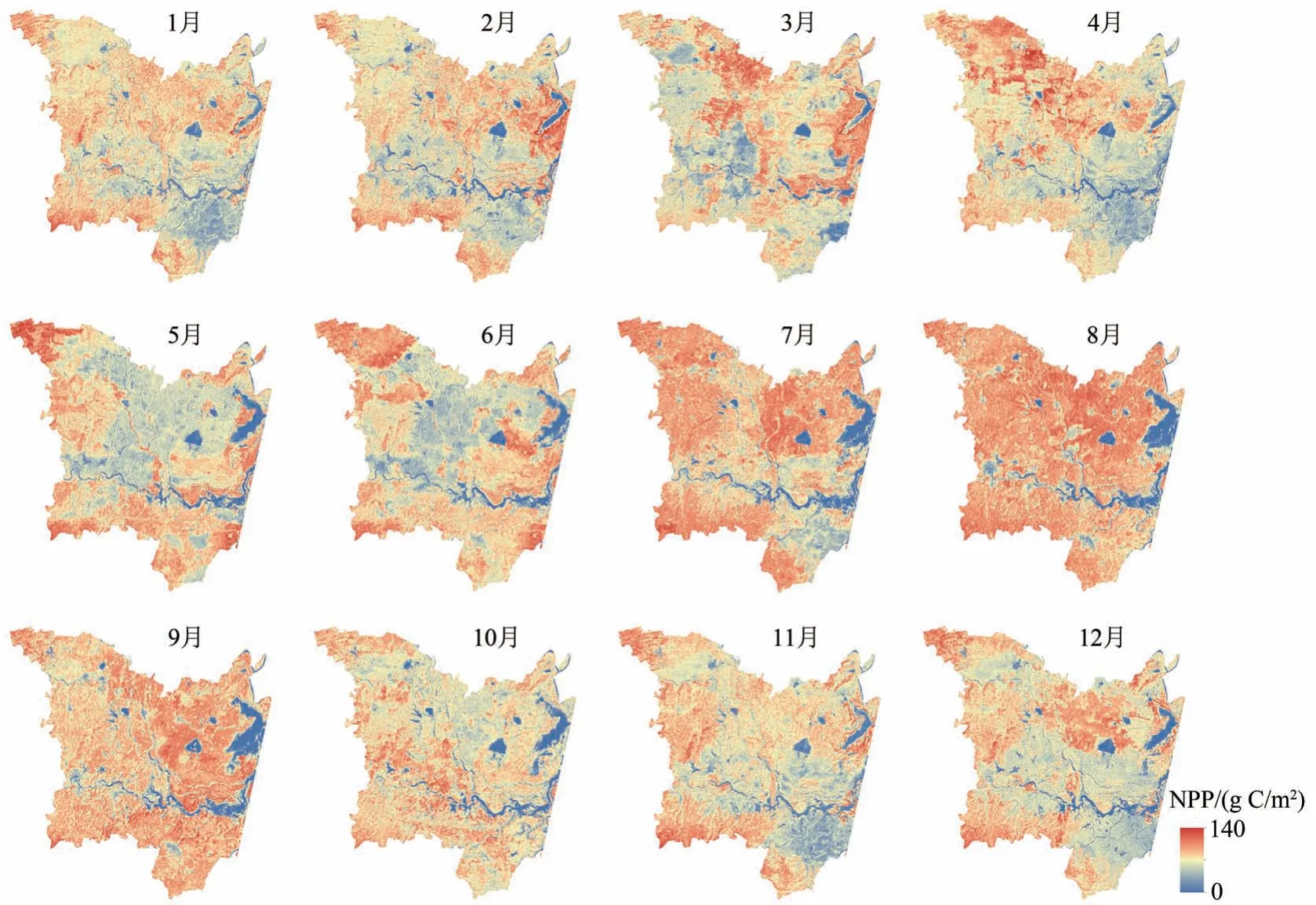
图10 洞庭湖湿地月NPP变化Fig.10 Monthly NPP change of Dongting Lake wetland
5 讨论
5.1 不同估算模型下NPP估算结果比较
为了验证本文修正CASA 模型在湿地NPP估算中的适用性,将修正CASA 模型估算的NPP结果与其他学者构建的CASA 模型估计的NPP结果进行了比较,包括CASA(Monteith,1972)、Zhu-CASA(Zhu 等,2005)和LSWI-CASA(Xiao 等,2004)。尽管不同CASA 模型下各种植被类型的NPP估算结果存在一些差异,本文修正CASA模型、CASA模型、Zhu-CASA 模型以及LSWI-CASA 模型估算得到的研究区NPP均值分别为450.89 g C/m2、463.92 g C/m2、446.31 g C/m2和459.51 g C/m2,但本文修正CASA模型模拟的NPP值与其他CASA 模拟的结果比较接近(表2)。同时,修正CASA模型估算得到的湿地(芦苇与苔草)NPP均值,与其他模型估算的结果也较为接近。此外,本文修正CASA 模型估算的NPP值与NPP 实测值之间表现出了最高的决定系数和最低的RMSE。误差的存在是不可避免的,但其本文修正CASA 模型估算的NPP值的误差在可接受的合理变化范围内,说明本研究中CASA 模型估算的NPP 具有较高的准确性和应用价值,可以作为区域湿地高时空分辨率NPP模拟与估算的参考数据。
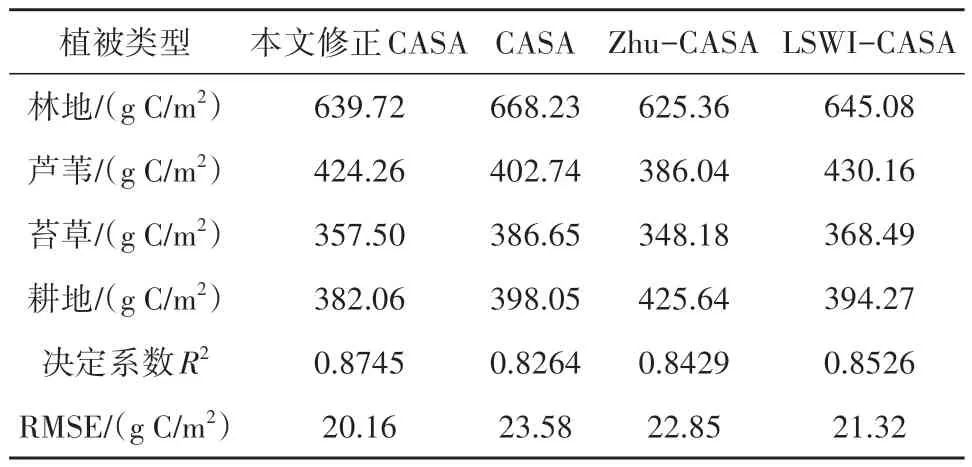
表2 不同CASA模型下的NPP估算结果比较Table 2 Comparison of NPP estimation results under different CASA models
5.2 本文方法的创新性与局限性
目前,利用高时空分辨率影像进行大范围湿地NPP 高精度估算的研究比较少。本文借助于遥感云平台下的时空融合技术,获得了高时空分辨率的NDVI和LSWI。基于CASA 模型的原理,结合植被分布图获得了获得了准确的植被最大光能利用率(εmax),并利用LSWI和降水数据,获得了与NDVI一致的空间分辨率的水胁迫因子(W)。结果表明,与其他CASA 模型相比,本文提出的改进CASA 模型模拟的NPP具有更高的估算精度。
在时空融合算法方面,本研究借助遥感云平台和STNLFFM 算法原理,构建了遥感云计算下的时空融合模型,面对大尺度、高时空遥感影像获取时,大大减少了时间与运算成本。同时,STNLFFM模型采用非局部滤波算法来选择相似像元,选择参考日期和预测日期之间的时间变化更接近目标像元的变化作为候选相似像元,相比于传统的STARFM 与ESTARFM 模型在预测精度上更有优势,尤其是复杂变化的景观。针对湿地这种动态性较强的地理景观,本文方法能够较为准确地抓住湿地随时间发生地变化,从而能对时序Landsat数据进行有效预测。植被分类算法方面,本文基于Stacking 算法框架,发展了自适应融合算法,提高分类精度的同时,增强了算法的鲁棒性。
尽管能够准确地呈现高时空分辨率NPP,但本文修正的CASA 模型存在着一定的局限性。利用基于云平台的时空融合数据能够在快速获取时序Landsat 影像,解决云雨地区的数据缺失问题。由于洞庭湖湿地的水文情况变化迅速且剧烈,加之混合像元的存在,在数据融合过程中难以捕捉到一些细微变化,在一定程度上会影响融合影像的质量与精度。相较于单一的机器学,本文提出的自适应集成学习有效提高了分类的精度和算法的鲁棒性。近年来,深度学习中的卷积神经网络在影像分类方面取得了突破,然而海量训练数据及标签的制作限制了其在大尺度土地利用分类上的应用。因此,利用卷积神经网络提取遥感影像深层次特征,再结合集成学习进行影像分类值得探讨。此外,本文构建的修正CASA 模型还需要在更大范围及其他生态系统中进一步地验证其估算NPP 的实用性和精度。
6 结论
针对区域高时空分辨率湿地NPP 估算研究相对薄弱,本研究基于遥感云平台下的时空融合技术获取了的时间序列Landsat数据,并修正的CASA模型估算了洞庭湖湿地高时空分辨率的NPP,解决了高时空分辨率湿地NPP 估算中的数据缺失问题以及估算精度不高的问题。结果显示,融合得到的Landsat 数据质量较好,与真实影像相关性较高。通过精度验证可知,湿地植被分布图分类精度高。另外,利用修正CASA 估算的NPP与实测的NPP具有较高的相关系数(R2=0.85)和较低的RMSE(20.16 g C/m2)。本文的研究结果以期为湿地遥感分类NPP 估算提供数据与技术支持。此外,本文利用光能利用率模型CASA 与NDVI 植被指数对湿地植被NPP 进行了估算,但模型和指数都存在对着饱和问题的欠考虑。后续研究将顾及饱和现象,构建新型植被指数和顾及光饱和的NPP 估算模型,拟进一步提高湿地植被NPP估算精度。