基于人脸表情识别的课堂质量分析*
2023-07-11戴海云
戴海云 张 明
(江苏科技大学计算机科学与工程学院 镇江 212003)
1 引言
目前将人脸表情识别作为课堂质量分析的研究还不够广泛。而且在现实中,课堂中往往缺乏老师与学生的沟通交流,只重视老师对课堂所教学的内容的同时,会忽视对课堂能给出直观感受的学生的反馈信息。虽然也有传统的课堂质量分析,比如专业人员进行人工记录或者学生课后问卷打分[1],这些都带有主观因素和滞后性。全国都在推行素质教育,而课堂作为教学最关键且最主要的方式,所以老师对学生的脸部表情的反馈更能够知道该学生对自己的教学是否适用。比如,老师在课堂上看见学生是眼睛张开,嘴角上扬,愉悦地望向自己,他应该就会知道这个学生对自己的教学内容有了理解,那么此刻老师就可以适时地进入下一个讲解,但若是看见学生眉毛紧皱,嘴角下拉,甚至是疲惫的状态,那么老师可以结合自己的多年教学经验得出此刻学生有疑惑或未理解,那么老师即可作调整。但是老师不会一直将注意力放在学生的表情和对其的分析上,也不能全面兼顾到全班所有同学的表情变化,用计算机技术来作为辅助老师对自己的学生的表情识别和记录,对课堂质量做出分析,从而调整教学进度和改善教学方法,那么是非常实时、客观且有意义的事情。
2 基于视频序列的表情识别模型
在基于深度学习方法的静态表情识别[2]学习研究中,虽然取得了良好的识别效果,但是在课堂中学生的表情的发生是一个持续的过程,所以基于静态图像的表情识别忽略了表情的动态信息。为解决这一问题,本文提出了一种特征融合-BiLSTM模型用于视频序列人脸表情识别。该网络模型是融合了提取的空间信息和时序信息,再结合使用BiLSTM。
2.1 BiLSTM
循环神经网络(RNN)和长短期记忆网络(LSTM)[3]两种模型对结果的预测仅仅是依赖当前状态的若干个前序状态,是没有办法做到对后序信息的编码操作。但是,由前序若干状态和后序若干状态共同作为输入对结果的预测会更好。双向循环神经网络(Bi-directional Short-Term Memory,BiLSTM)[4]可满足以上叙述的要求。
前序LSTM 和后序LSTM 共同组合成BiLSTM,其神经元状态不仅和上一刻的本身状态有关,而且和下一刻的自身状态也相关。能够从前序LSTM提取到过去的特征,从后序LSTM 提取到未来的特征。结构如图1 所示。图中圆圈为逐点运作;蓝线为后向传播;绿线为前向传播。从双向层看,它从垂直向和水平向获得信息,最终再将上层的处理信息输出出来。
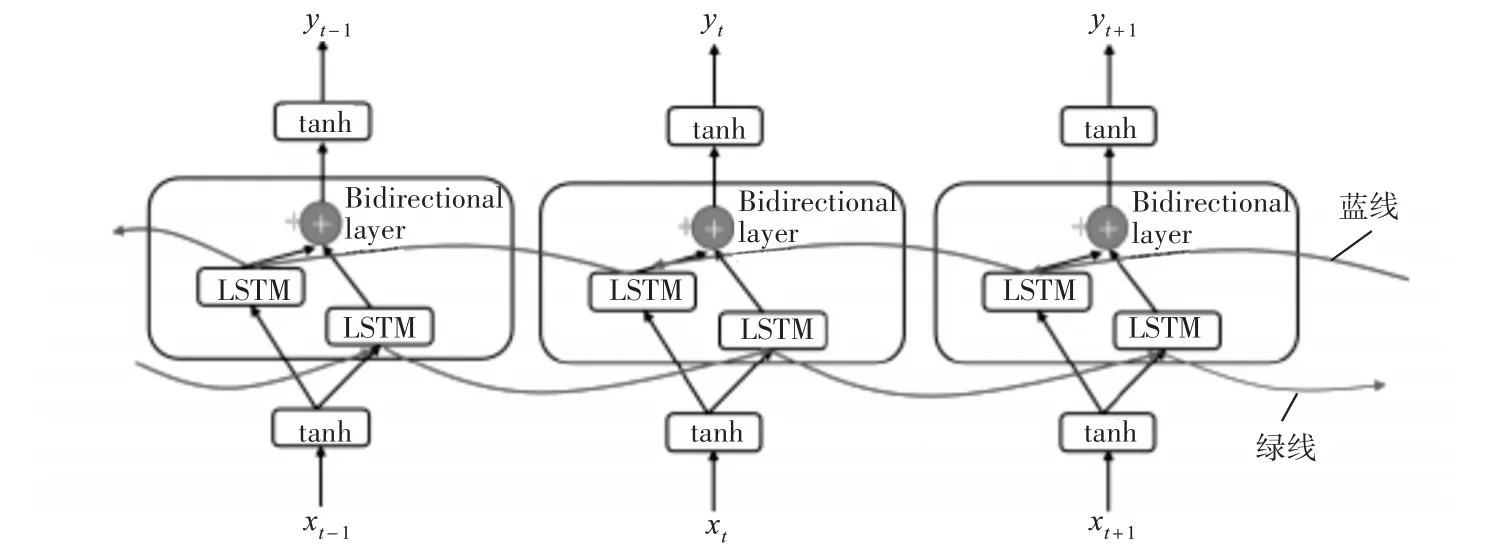
图1 BiLSTM结构
2.2 提取空间特征信息
人脸表情的特征是由表情图像的空间特征提供的。为了能提取出更多的更有效的表情特征,本文使用的空间特征提取网络是静态表情识别网络,如图2 所示。此网络提供了卷积神经网络设计的一个关键点——深度。同时将此网络结合Inception 结构,再进行分解卷积和维度,能较大程度地减少计算成本。实验证明此模型在提取静态表情特征中提供了良好的效果。
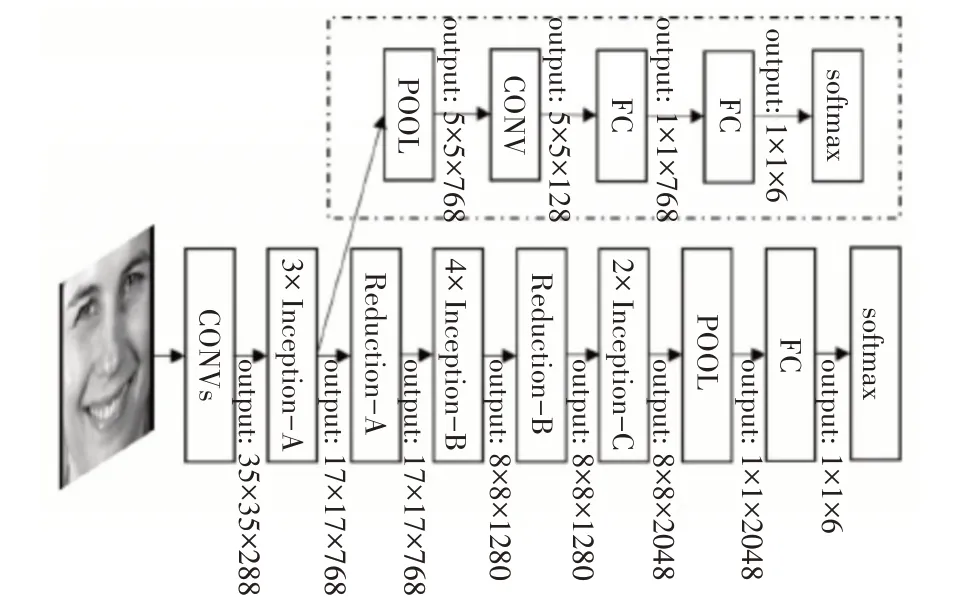
图2 静态表情识别网络
2.3 提取时间序列信息
提取表情动态的特征是由时序信息提取网络完成的,如图3所示。图3的说明如下:输入两张表情序列图片,这种方式的输入可以使用网络提取到短期记忆的带台信息,与上一节所说的空间信息提取不同的是,空间特征提取是给出详细的空间表情特征,此节所说的网络是将表情的时序性放于重心处。所以在时序信息网络的挑选中本文优先使用有最好识别效果的较浅的卷积神经网络。这个结构包含两层Conv,两层最大Pooling,而且在每个卷积层后都使用了批量正则化层(Batch Normalization,BN)[5],批量正则化的优点在于能更快收敛到局部最优。模型的最后是一个全连接层,即FC。

图3 提取表情动态特征
2.4 特征融合-BiLSTM
前两节提取到的表情空间特征和短期时序信息有相同的维度,就可以将两种特征进行融合。融合方法有三种,最大融合、连接融合和相加融合。经过在CK+数据集上进行十字交叉验证法,并重复3次,不同融合方法的识别效果如表1所示,根据结果最终采用连接融合特征。设PA和PB表示提取的空间特征的特征向量和提取的时序信息的特征向量,用L,W和D代表特征向量长、宽和通道数,Q则代表融合后的特征。在式(1)中,pA,PB∈RL×W×D,qcat∈RL×W×2D且1 ≤i≤W,1 ≤j≤W。
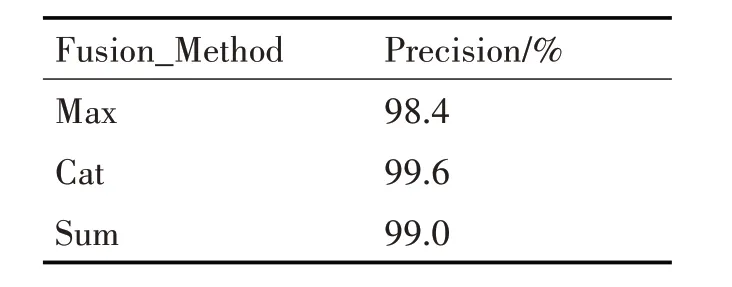
表1 不同融合方式的准确率
上述融合特征之后,两个网络的特征向量就被转换成时间序列。然而。这个是短期的时序信息,我们需要的是整个表情绪里的叠加时序信息,需要采用BiLSTM循环神经网络。整个过程表示如下:
在以上三个公式中,xt表示经过融合特征之后的向量,yt表示输出向量,代表前向传播隐含层和后向传播隐含层,ϑ表示sigmoid 激活函数,e是偏置向量,A、B、C表示权重向量。
2.5 实验结果
本文模型与其他模型分别在CK+数据集上进行对比试验,结果如表2 所示,从表中可看出本文提出的模型比最新的模型的精确度提高了,说明特征融合-BiLSTM使得识别效果得到了提升。
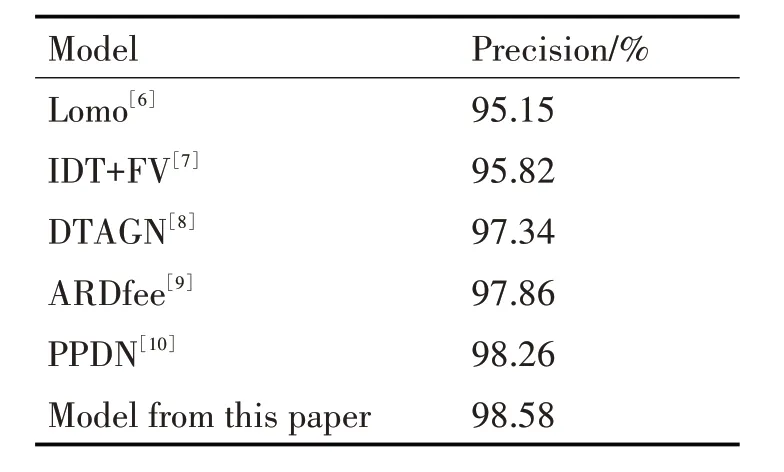
表2 不同模型在CK+数据集上的识别效果
表3 表示本文的特征融合-BiLSTM 模型在数据集CK+上的混淆矩阵。可以看出,可能由于happy 和angry 两个表情特征比较明显,这两种的识别表现良好,而其他的就会较容易出现FN 类型的错误。

表3 特征融合-BiLSTM模型-数据集CK+混淆矩阵
3 课堂质量分析体系
课堂质量分析直接反映学生课堂听讲状态和教师教学的适用性程度。实现课堂质量分析划分为两个部分,首先通过学生的课堂表情识别结果设计出学生表情分数,此表情分数决定听课状态分类,其次能给出一节课中全部学生的听课状态,最终通过与教师评分对比作验证。
3.1 学生表情-学生听课状态划分
经查阅大量表情识别与教学相关的研究[11~15],得知表情体现的表情特征能反映处该表情的情绪,再结合真实的课堂环境,所以得出以下的学生表情-学习情绪的分类,见表4。

表4 学生表情-学习情绪
对照学生表情及表情特征,本文将学习情绪分为7 类,表情识别模型可以为每类学习情绪输出一个置信度,作为这个表情的的可能性,这一可能性作为学生听课状态评分的标准。结合上面表格,去除与课堂无关的表情,将害怕权值设为零;将蔑视作为对听课状态很不好的判断,权值设置为-3;厌恶作为对听课状态不好的判断,权值设为-2;悲伤作为对听课状态较不好的判断,权值设为-1;听课状态较好、好、非常好依次对应生气、惊讶、开心,权值分别为1,2,3。最后得分取值在-3~3 之间,再进行归一化,就可以得到学生a 在时刻t 时的表情分数,见式(5)。
为得到全班所有学生一帧图片的表情分数,进行下一操作:累加所有学生的表情权重并求其平均值,见式(8),snt表示学生一帧画面识别到的学生数量。
根据一节课的总时间,将所有时刻的分数累计取平均值,就可以得到一整节课的学生表情分数,因分布在-1~1之间,为了保证分数在0~10之间,将权值乘上5再加上基础分5分,见式(9)。
3.2 课堂质量分析
本文通过计算出一整节课中识别到的学生表情分数进而对课堂质量作划分,课堂质量分为四个层次,Very Good、Good、Not bad、Bad,见表5。

表5 课堂质量划分
4 实验与结果
为了验证本文提出的基于人脸表情识别的课堂质量分析是否合理,作者选择了高中学校的一节课进行分析,取其中20min 的时长,一帧为间隔将视视频分为14400张图片,获取10000有效图片,并选择其中五名学生进行跟踪,将本文设计评分与教师评分作对比并分析,结果见表6。

表6 教师评分-本文设计评分
使用皮尔逊积矩相关系数来验证教师评分与本文设计评分的相关性。式(14)是皮尔逊积矩相关系数公式,式(10)和式(11)是教师评分和本文设计评分的平均值,式(12)和式(13)是教师评分和本文设计评分的标准差,sn为学生总数,ti是教师评分集合,si是本文设计评分的集合。
据计算,两者相关系数大于零,说明本文设计评分和教师评分是存在相关性的,即本文针对基于人脸表情识别的课堂质量设计评分是合理的。
5 结语
针对目前的课堂质量分析不多的情况,本文将智能视频技术以及人脸表情识别技术应用到课堂质量分析中,为现在的不足提供一个相对可靠的分析依据。第一部分的工作落于对人脸表情识别算法的研究,提出了特征融合-BiLSTM 模型,提高了识别准确率,也为课堂注量分析打下夯实基础;第二部分工作体现在本文提出的课堂质量评分,依据皮尔逊积矩相关系数,验证了其合理性。文中把较好的表情识别作为课堂质量分析的因素是相对可靠的,但是在课堂质量分析中,但还有一些问题需要深挖,比如人体姿态因素、评分应该分学科等。
