基于双重注意力机制和时间因子的深度推荐模型*
2023-07-11吴定谕周从华单田华刘志锋
吴定谕 周从华 单田华 刘志锋
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
推荐系统能够缓解由于互联网快速发展所导致的“信息过载”的问题,帮助用户从大量信息中找出用户所需要的信息。传统推荐系统大多依据用户评分来判断用户喜好实现未评分项目预测,比如最为经典的矩阵分解(Matrix Factorization,MF)模型[1],将用户和项目特征映射成同一隐空间的隐向量。然而,评分仅能大致表现用户对项目的整体态度,无法对用户喜好的原因进行挖掘,例如用户喜欢某间餐厅是因为美食还是因为服务态度好,可解释性较差。另一方面,评分矩阵一般情况下都十分稀疏,进行评分预测的精度较差。
基于以上原因,研究人员将研究重点转移至基于评论文本的推荐模型,相比于评分仅能代表用户的总体态度而言,评论信息能够体现用户喜好的原因,具有较强的可解释性。许多推荐模型应运而生,例如CTR[2]、HFT[3]等,这些模型验证了基于评论的推荐模型的有效性。但是这些以往的工作一般都是使用隐狄利克雷分配模型(LDA)[4]从评论文本中挖掘各种信息[5~7],这种方式忽略了评论上下文的语义信息。文献[8]认为使用LDA 不能对除词语级别以外的主题分布进行挖掘,提出了TopicMF 模型,通过非负矩阵分解得到评论隐藏主题信息,并通过主题分布体现用户商品特性。
由于深度学习对文本信息的强大建模能力,研究人员将深度学习技术应用于基于文本的推荐系统的研究。Zheng[9]等提出DeepCoNN 模型将评论文本划分为用户评论集和项目评论集,使用并行的卷积神经网络提取用户和项目的特征,然后通过因子分解机(FM)[10]耦合两个部分进行建模,对用户评分进行预测,取得了较好的效果。这种使用并行卷积神经网络进行用户和项目建模的思想启发了很多相关研究。Catherine 等[11]针对待预测评分的评论文本的隐表达进行研究,首先对评论进行预测,再基于该预测评论进行评分预测。Wang 等[12]指出卷积神经网络可能会忽略词频带来的影响,提出一种结合主题模型和卷积神经网络的推荐模型,缓解了词频丢失的问题。
尽管上述模型解决了各方面的问题,但是都未能充分挖掘评论信息的价值。首先,每条评论由不同的单词组成,每个单词对评论语义的影响程度是不同的。其次,每个用户或者项目拥有的所有评论对用户和项目本身的重要程度也是不一致的,只有挖掘出重要程度更高的评论才能更好地对用户和项目进行特征建模,只是简单地提取单词和评论信息而不对单词和评论进行差异化处理,可能会曲解评论的含义,忽略重要信息。
为了解决上述问题,提取隐藏的有效信息,本文提出一种基于双重注意力机制和时间因子的深度推荐模型DATCoNN,使用融入双重注意力机制和时间因子的并行卷积神经网络,从单词级别和评论层面充分挖掘重要度信息,更好地对用户和项目进行特征建模,实现评分预测。提升了推荐的精度,并且具有更好的可解释性。
本文进行的主要工作如下:
1)本文提出一种融合双重注意力机制的神经网络推荐模型,从单词层面和评论层面以两种不同的视角提取评论文本中的重要信息。模型采用review-level 建模方式,相较于document-level[13~15]建模的推荐系统具有更好的可解释性。
2)本文在词级别注意力层使用卷积神经网络分别对用户评论和项目评论进行词级别的信息挖掘,能够更好地融合单词上下文信息挖掘单词重要程度,过滤出对评论重要性更高的单词。
3)本文在评论级别注意力层融入时间因子,根据艾宾浩斯提出的记忆曲线遗忘规律,拟合用户对评论序列中信息的记忆程度,能够更好体现评论信息重要度随时间流逝衰减的规律,提升用户和项目特征建模的准确程度。
2 DeepCoNN推荐模型
近年来,许多基于深度学习的文本处理方法被提出,这些方法取得了比传统算法更好的表现,例如fastText,TextCNN 等。于是,研究人员将深度学习对文本处理的优势运用于推荐领域,取得了不错的效果。DeepCoNN 充分利用了深度学习的优势,该模型对用户的评论文本和项目的评论文本分别使用卷积神经网络进行特征提取,挖掘评论文本的深层特征,大大提升了评分预测的准确率。
模型使用并行的卷积神经网络分别对用户评论集和项目评论集进行信息提取。以用户评论集为例,模型使用预训练的词向量作为输入,每一个单词都会通过词向量映射函数f:M→Rd映射为一个d维的向量表示,将用户的所有评论词向量合并为一个文档,总共有n个单词组成,用户u的评论词向量矩阵表示为。

图1 DeepCoNN模型特征提取部分
使用卷积神经网络进行评论特征的提取,卷积核共包含z个神经元,第l个神经元产生的特征如下所示:上式中卷积核为Kj∈Rc×d,其中c代表卷积核的窗口大小,*表示卷积操作,bl为偏置项,使用ReLU函数作为激活函数。
在窗口大小为c的滑动窗口的作用下,第l个神经元的特征为。通过最大池化操作,捕获每个通道最重要的特征,定义如下:
接下来将各通道的计算结果,即z个神经元对应的特征使用拼接得到用户u经过卷积层的结果,记为
将上式结果送入全连接层,其中权重矩阵We∈Rn×k1,偏置项be∈Rk1,用户u在该层的特征提取结果如下式所示:
通过共享层将用户u的特征矩阵和项目i的特征矩阵进行连接得到单一向量f,最终使用因子分解机FM进行用户u对项目i评分的预测。
3 一种新的推荐模型DATCoNN
虽然基于评论文本的深度学习推荐模型Deep-CoNN 评分预测表现突出,但是仍然存在诸多问题。首先,该模型使用了document-level 的建模方式对用户和项目进行特征建模。该建模方式以用户或者项目为单位将所有词向量连接成一个矩阵并通过卷积层进行特征提取,这种做法无视了不同评论之间的界限,将不同时刻、场景、情况下产生的评论混为一谈,可解释性较差,同时会在池化操作时丢失大量有效信息。其次,该模型忽略了评论内部与评论之间的重要性差异,评论中的每个单词对评论含义的表达程度是不同的,每条评论对于对应用户或者项目的重要程度是不同的。无法对用户和项目进行充分表达,导致特征建模效果不理想。因此,本文提出一种基于双重注意力和时间因子的深度推荐模型,对上述问题进行改进。
3.1 模型整体结构
本文提出DATCoNN模型整体结构如图2所示。
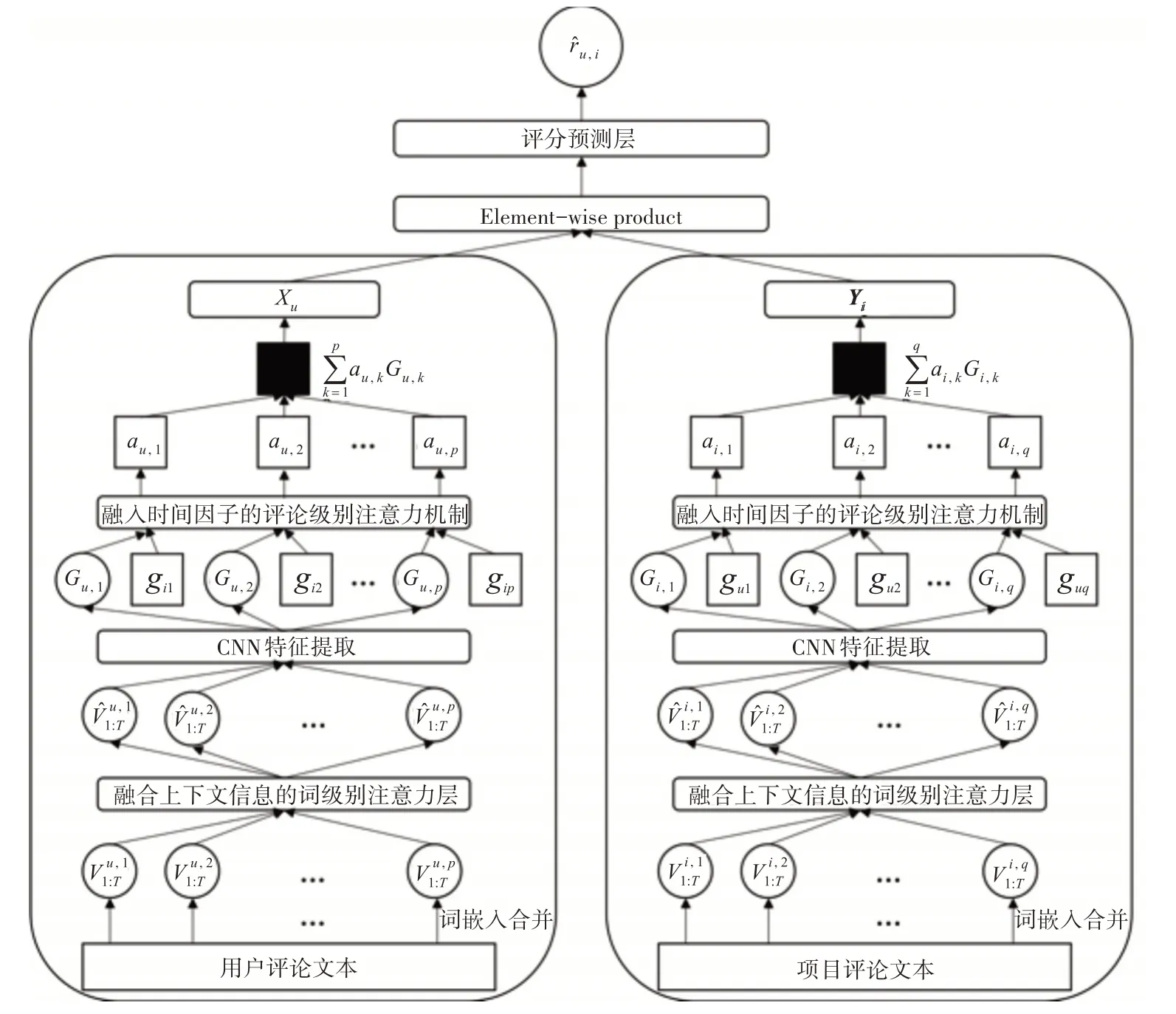
图2 DATCoNN模型整体结构

图3 DATCoNN和各对比算法在三种数据集上的RMSE值

图4 DATCoNN和各对比算法在三种数据集上的MAE值
首先将用户评论文本和项目评论文本中的单词进行词嵌入表示,并以评论为单位合并词向量,得到评论的词向量矩阵。以用户侧特征建模为例,用户u的第k条评论的词向量矩阵表示为。使用基于卷积神经网络的词级别注意力机制层提取评论中各词向量的重要度信息并进行权值赋予。设计一组并行的CNN 结构以评论为单位进行特征提取,解决了document-level 建模方式存在的信息丢失问题,提升了模型的可解释性。在对评论进行深度建模之后输入到评论级别的注意力机制层提取评论的重要度信息,同时使用时间因子拟合实际情况下用户评论重要程度随时间衰减的规律,降低无用评论对用户和项目建模产生的影响。评分预测层利用用户特征和项目特征进行交互建模工作,使用因子分解机FM 充分交互特征向量各维度的一二阶项,实现评分预测。具体而言,用户u和项目i的交互建模如下式所示:
上户式特中征KXuu,∈i表R示s,用项户目u特对征项Y目i∈iR的s,隐用表户示项,目其隐中用表示,⊗符号表示向量间对应元素相乘操作。
最终使用因子分解机FM 进行用户u对项目i评分的预测:
下文主要针对融合上下文信息的词级别注意力层、融入时间因子的评论级别注意力层以及模型训练部分进行详细说明。
3.2 融合上下文信息的词级别注意力机制
受Seo 等[16]研究启发,使用卷积神经网络将词的上下文关系加以融合,可以强化单词与单词之间的耦合关系,集中突出评论中与用户评分关系更大的单词,降低相对无关的单词所持有的权重。另外,使用基于review-level 建模方式进行词级别重要度的挖掘,能够更好的与评论级别的注意力层进行结合,同时提升了模型整体的可解释性。下面以用户侧特征建模经过词级别注意力层为例进行说明。
首先将用户评论矩阵通过一个卷积神经元数为m的卷积神经网络,每一个神经元j都对应一个卷积核。将用户u的第k条评论的词向量矩阵和卷积核Kj进行卷积运算,可以得到第j个神经元所产生的特征为
上式中,将卷积核的窗口大小设置为1,即卷积核Kj∈R1×d,目的是能够更好的对特征进行压缩。*表示卷积运算,bj是偏置项,ReLU是非线性激活函数。
接下来将计算所得的特征输入到两层全连接层,进一步融合各词的上下文信息:
第一层全连接层如上式所示,其中权重矩阵Wd∈RT×r,r表示衰减后的特征维度,bd∈Rr为偏置项,使用ReLU函数进行激活。
第二层全连接层如上式所示,将融合上下文信息后的衰减隐层特征恢复为原有特征维度,其中权重矩阵Wu∈Rr×T,bu∈RT为偏置项,使用sigmoid函数进行激活,计算出用户u的第k条评论中每一个单词的重要度系数fc2。
将重要度系数与用户u的第k条评论的词向量矩阵逐项相乘,为词向量矩阵融入单词级别重要度信息,体现不同单词对该评论的重要程度:
3.3 融入时间因子的评论级别注意力机制
每条评论对用户和项目而言具有不同的重要程度。重要程度高的评论对特征的表达能力更加突出,而重要程度低的评论可能包含无用信息,影响对用户特征的正确表达。为了挖掘用户评论中重要度更高的评论,利用注意力机制计算用户评论重要度是一种行之有效的办法。然而,以上设想未能充分考虑实际情况,没有充分考虑时间因子对评论信息重要度的影响。根据德国心理学家赫尔曼艾宾浩斯的研究结合推荐系统领域知识可以发现评论信息对用户和项目的表达程度会随着时间流逝逐渐衰减。为了描述上述趋势,使用时间衰变函数根据时间戳信息计算时间带来的影响并融入注意力函数能够使评论重要度计算结果更加符合真实情况。Xia 等[17]研究分析发现相比于线性函数、凹函数等其他函数类型,指数函数能够更好地拟合评论重要度的时间衰减效应。
为了描述时间因子对评论对于用户和项目的重要度带来的影响,以用户侧特征建模为例,下述公式中Su表示用户u的评论集序列,该序列长度为p,其中su,k代表用户u的评论集中的第k条评论:
基于用户对进行评论行为的时间点来描述评论对用户的重要程度:
上式中,输出tdu,k表示用户u的第k条评论对用户u时间权重系数,其中λ表示时间衰变速度控制因子,tp表示用户u的评论集序列中的最后一条评论的行为时间,tk表示用户u的评论集序列中第k条评论的行为时间,tp-tk表示了用户历史评价行为时间与最近评价行为时间的时间间隔。
将时间因子融入评论级别注意力层,符合评论对用户或项目重要程度逐渐衰减的实际情况。在此基础上,该层的输入除了用户u第k条评论的特征向量Gu,k还有用户u的ID 嵌入gu,输入用户ID嵌入有助于分辨进行无用评论的用户。该注意力网络具体定义如下:
上式中,H∈Rt为权重向量,HT为该权重向量的转置向量,Wf∈Rt×k1、Wg∈Rt×k2分别是Xu,k和gu的权重矩阵,b1u∈Rt、为偏置项。
使用softmax 函数进行归一化处理,可以得到用户u第k条评论对用户的重要程度:
获得每一条评论对用户的重要度之后,用户u的特征向量表示如下式所示:
使用全连接层对特征向量进行处理,权重矩阵Wo1∈Rs×k1,偏置项bo1∈Rs,最终计算出用户u的特征表达式:
项目侧特征建模与用户侧特征建模流程类似,最终通过全连接层获得的项目i的特征表达式如下式所示:
3.4 模型训练
本文模型主要通过评论文本信息实现评分预测,以平方损失函数作为目标函数,Loss的计算如下式所示:
上式中,Ω 表示整体训练集样本,ru,i和ru,i分别表示用户u对项目i的真实评分。为了优化目标函数,本文使用Adam 优化器进行优化。该优化器能够根据训练情况动态的调整学习速率的大小,模型能省去人工调整学习率的流程并且更快的收敛。
4 实验部分
4.1 实验数据集
为了验证DATCoNN 模型的性能,本文选取了Amazon 提供的三个公共数据集对模型性能进行验证,这三个不同领域数据集分别是Movies_and_TV(AMT)、Toys_and_Games(ATG)、Office Products(AOP)。其中AMT 数据集拥有将近170 万条用户评论,ATG 拥有超过16万条用户评论,而AOP拥有5 万多条用户评论,是一个较小的数据集,实验数据集详细信息如表1所示。
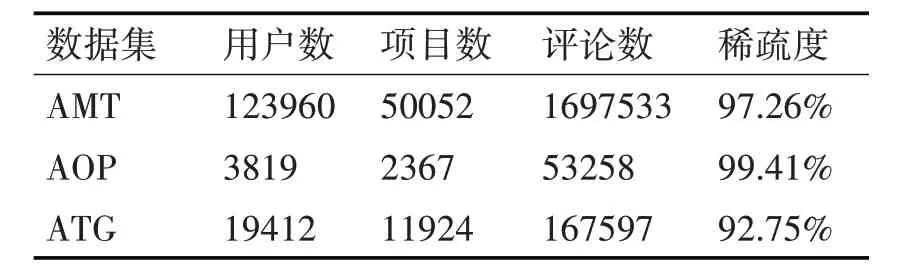
表1 数据集信息

表2 DATCoNN和各对比算法在三种数据集上的的RMSE值

表3 DATCoNN和各对比算法在三种数据集上的MAE值
实验过程中将数据集中数据分成三份,分别是训练集、测试集、验证集,比例为8∶1∶1。由于原始数据集的数据量较多,将本次实验无关的数据全部剔除,仅保留用户ID、项目ID、评论信息、评分信息。
4.2 评价指标
本文使用RMSE 和MAE 作为实验评价指标来评估推荐的精度,该指标是常用的回归模型评价指标,RMSE 和MAE 的值越小预测精度越高,表达式如下式所示:
上式中ru,i表示预测评分值,ru,i表示真实评分值,N表示样本数量。
4.3 实验结果分析
本文设置对比实验如下:
1)横向对比:将DATCoNN 分别三类模型中的代表模型进行直接对比。第一类是基于评分矩阵的模型中的概率矩阵分解模型(PMF),第二类是基于主题建模的推荐模型隐狄利克雷分配模型(LDA)以及协同主题模型(CTR)[18],第三类是深度推荐模型中的协作深度学习模型(CDL)[19]。
2)纵向对比:将DATCoNN 与原始模型Deep-CoNN 进行对比,验证融合双重注意力机制和时间因子对推荐性能的提升。
多次实验进行参数调优,最终确定实验所用最优参数组合如下:词嵌入向量维度300,用户和项目的特征维度为50,学习率设定为0.001,滑动窗口大小c设置为3,卷积核数量为100,模型训练批处理大小为100,Dropout 比率设置为0.5,时间衰变速度控制因子λ设置为0.04。
将本文提出模型DATCoNN与其他对比模型在三组数据集上进行对比实验,实验结果如下:
接下来以更加直观的方式表示不同推荐模型在三种数据集下的对比结果。
从以上实验结果可以看出,在三种不同数据量的数据集上,本文提出的DATCoNN 推荐模型均优于对比推荐模型。在AMT 数据集上,DATCoNN 的RMSE 和MAE 分别为0.87884 和0.79391,相较于表现最好的DeepCoNN 模型分别降低了0.02537 和0.02323;在AOP 数据集上,DATCoNN 的RMSE 和MAE分别为0.90829和0.76741,相较于表现最好的DeepCoNN 模型分别降低了0.01924 和0.02177;在ATG 数据集上,DATCoNN 的RMSE 和MAE 分别为0.76882 和0.74759,相较于表现最好的DeepCoNN模型分别降低了0.02667和0.01623。
横向对比结果表明,基于深度学习的推荐模型能提高特征提取能力进而提升系统的性能,相比传统的推荐模型具有更加优秀的评分预测能力。与DeepCoNN 模型进行纵向对比发现,使用双重注意力机制和时间因子能够更好地挖掘评论中包含的隐藏信息,有效提升了评分预测的准确程度。
5 结语
本文针对现存的使用评论文本进行项评分预测的推荐模型存在的若干问题,提出了一种基于双重注意力机制和时间因子的深度推荐模型。模型改进了DeepCoNN 评论特征的建模方式,并在并行CNN 结构上嵌入两层注意力层挖掘评论重要度信息,使用时间因子进一步拟合用户对项目兴趣程度。在三个公共数据集上进行的对比实验结果表明,改进模型的推荐精度始终优于其他对比模型,并且具有更好的可解释性。本文的后续工作在于研究如何将评分信息更好地融入模型,进一步提升评分预测的精度。
