基于金字塔特征和级联注意力的路面裂缝检测*
2023-07-11苗翔宇刘华军
苗翔宇 刘华军
(南京理工大学计算机科学与工程学院 南京 210014)
1 引言
公路的建设极大地方便了人们的日常出行,行车安全也越来越凸显其重要性,及时修补破损路面是道路管理部门的一项重要工作。因此,快速掌握路面状况,并高效地实现自动化裂缝检测是亟待解决的工程实践问题。传统的路面检测方法是由专业人员人工排查,根据损毁严重程度进行专业的评估,但是这种方式不仅工作量大,而且效率很低,检测成本非常高。
为了更加高效地检测路面裂纹,基于图像处理的方法得到了广泛的应用,常用的传统图像处理方法主要包括阈值分割[1]、边缘检测[2~4]、小波变换[5~6]以及基于形态学[7]的方法。但是由于光照,阴影,背景和纹理这些因素的影响,这些检测的结果往往不尽人意。
近年来,深度学习作为机器学习的一个分支,在各种视觉识别任务取得了良好的表现。深度学习通过神经网络自动学习裂缝图像的特征,不再需要人为地设计特征提取器。随着全卷积神经网络的发展,涌现出一批诸如FCN[8]、U-Net[9]、Segnet[10]、FusioNet[11]、DeepCrack[12]等网络结构,可以实现像素级语义分割,能够进行端到端的裂缝检测。这种像素级的分类任务其难点在于如何提升分类的精度,减少错误分类的误差。因此,本文在金字塔特征融合的基础上加入了多级注意力机制,构建出一个新型的网络结构(Cascaded attentions Networks,CANet),能够有效地提升裂缝图像的识别精度,具体包含如下设计工作:
1)Layer-Attention 模块:该模块利用了注意力机制,可以提升裂缝像素部分的权重,帮助神经网络捕捉到裂缝的特征,提升识别精度。
2)Scale-Attention 模块:该模块同样是基于注意力机制,利用主干网络的不同阶段的特征图生成掩膜强化另一个输出结果,进而提升识别精度。
3)Multi View Enhance 模块:单一尺寸的卷积不能兼顾各种尺寸的裂缝特征,本文使用了一种基于膨胀卷积的多视野融合模块,在不同感受野下提取图像特征,提升了网络对不同尺寸裂缝特征的识别能力。
4)双向融合网络:通过从特征提取浅层到深层,以及从深层到浅层双向融合的方法生成预测结果,同时可以近似得到每一尺度下的Lable,进而有针对性的训练网络,加速网络收敛。
2 模型架构
本文结合裂缝图像的特点,设计了一种基于金字塔特征结构的多尺度融合架构,以Resnext50[13]为基本的特征提取框架,并在此基础上设计了Layer-Attention 模块(LA),Scale-Attention 模块(SA)以及Multi Vision Enhancement模块(MVE),形成一种新型级联注意力网络(Cascaded attentions Networks,CANet)。为了提升网络的训练能力,本文又使用了一种双向融合的方案,使每一个尺度有对应的Lable。
网络的具体结构如图1 所示,上半部分是一个Resnext50 结构,可以按照特征图的尺度分成五个阶段,在后面的四个阶段采用了残差块的结构进行特征提取,四个阶段包含的残差快数量分别为3、4、6、3。
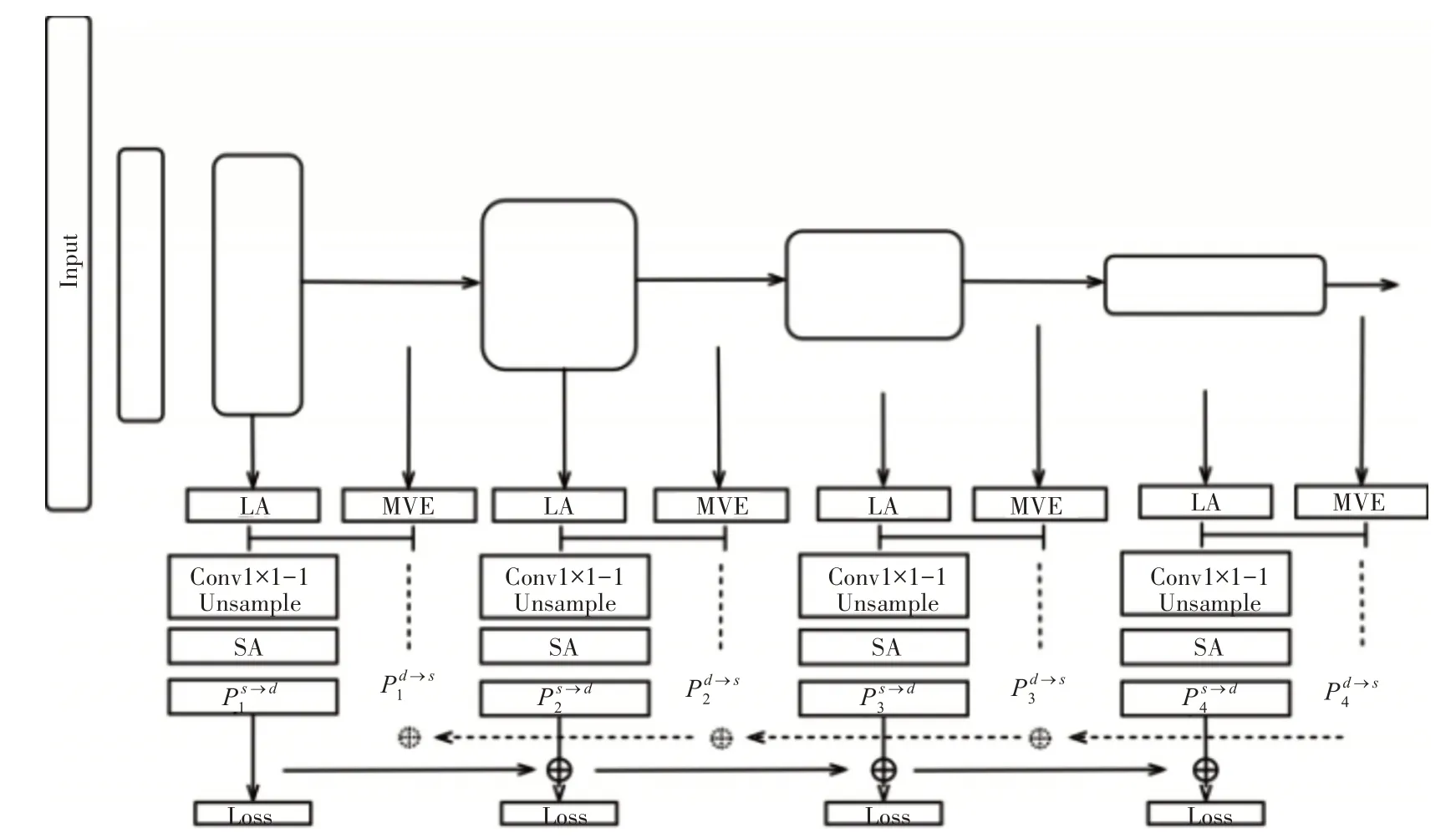
图1 CANet的组成结构
本文在后面的四个阶段中进行了如下操作:首先获取每个阶段的输出并通过MVE 模块进行多感受野特征提取,每个阶段通过LA 模块生成一个对应的掩膜并用来强化MVE 模块生成结果,生成的特征图尺寸分别为(W/4,H/4,32),(W/8,H/8,32),(W/16,H/16,32),(W/32,H/32,32)。本文使用了两个单独分支分别进行Conv1×1-1 卷积和上采样操作,最后通过SA 模块的强化输出两个预测结果和,两个结果叠加即为该尺度下的输出。最后,融合了各尺度下的输出生成最终预测结果。
2.1 多级注意力结构
2.1.1 Layer-Attention模块
为了提升检测的质量,帮助网络准确获取裂缝部分信息,本文提出了一个全新的Attention 模块,如图2所示。
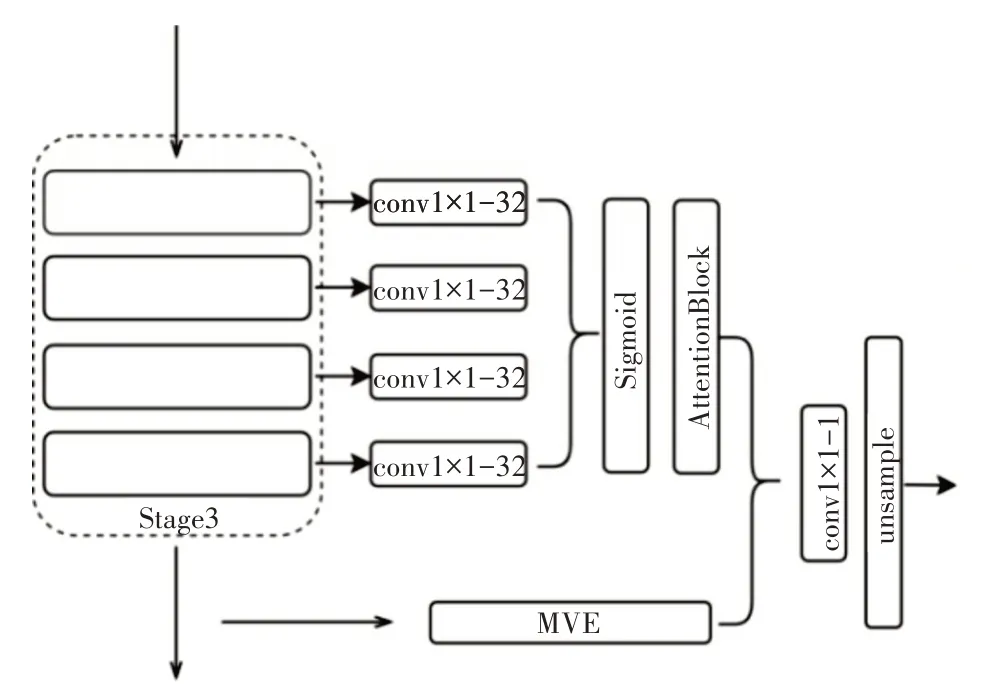
图2 第三阶段的LA模块结构
该模块的主要思路是将Resnext50进行特征提取的过程分成五个阶段,在第二、第三、第四和第五阶段中分别设置了k个残差模块,k∈{3,4,6,3}。在阶段i中,可以获取到ki个大小相同的特征图Xiki,经过多次卷积操作后,裂缝区域被强化,而非裂缝部分作为噪声被削弱,此时得到的特征图可以被近似的视为一种能强化裂缝部分的掩膜,本文从中得到启发,利用每个阶段的前一部分特征图生成一个LMask矩阵,即:
再将生成的LMask用来强化该阶段的输出,在这个过程中,针对于裂缝图像大小分布不均匀,考虑到单一感受野无法更好识别粗细不同的裂缝,本文对每一个阶段的输出结果进行了不同膨胀系数的膨胀卷积操作,即图1 中的MVE 模块,该过程可以表示为
Conv3×3-1表示一个3×3-32 的卷积操作,DConvr表示膨胀系数为r的膨胀卷积操作。本文将每个阶段的输出结果先进行降维操作后,分别进行了膨胀系数为4、8、12 的膨胀卷积,并将卷积后的特征融合。最后,用该阶段生成的LMask强化融合后的特征图,即
Xouti即为该阶段的强化结果并参与到后续的计算中去,关于LA(·)的具体实现方法,在本文中采用了叠加融合的方式,先将多个特征图融合,再使用Sigmoid 函数放缩到[0,1],每个阶段都有对应的特征掩膜,图3 是掩膜可视化效果图,可以看出网络把注意力集中在裂缝像素周围。

图3 不同阶段LMask的可视化效果图
2.1.2 Scale-Attention模块
类比于Layer-Attention 模块,本文在每一个尺度的输出部分也运用了Attention 机制增强检测效果,并把该部分命名为Scale-Attention 模块。从图1可以看出,阶段2、阶段3、阶段4和阶段5的输出,分别经过MVE 模块的多视野卷积,以及Layer-Attention 模块强化,最后结果上采样到原始图片尺寸,可以得到4个输出,如图4。
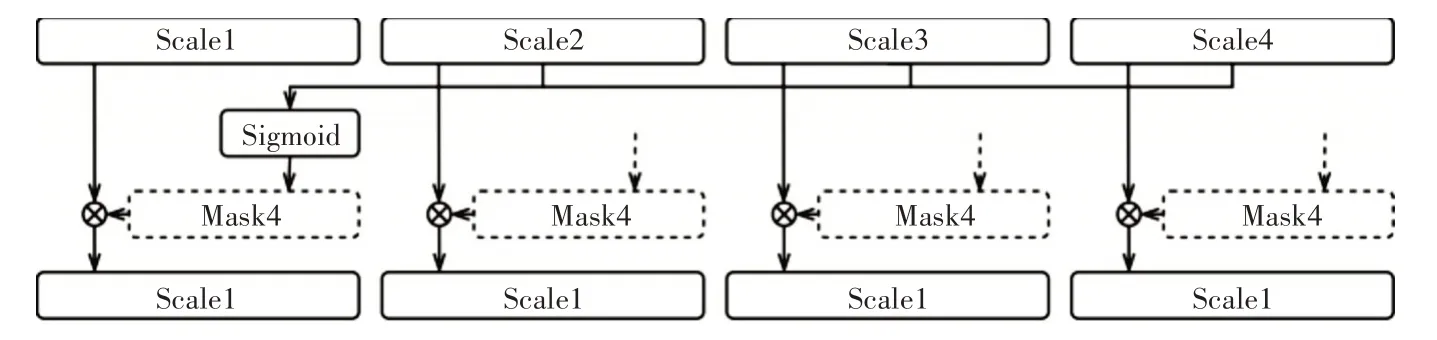
图4 SA模块组成结构
本文利用其中三个特征图生成SMask去强化剩下一个输出,运算过程可以表示为
Xscalei表示该尺度下,经过上采样恢复为原图尺寸大小的特征图,Pi表示在该阶段生成的预测结果。在本文中SA(·)方法的具体实现过程类似于LA 模块中的LA(·)方法,也是将多个特征图叠加融合后用Sigmoid 函数放缩,即可得到该尺度下的掩膜。
这种Attention 机制实际上是一种自我强化的过程,保证了裂缝部分得到强化,同时有效抑制了非裂缝部分,使网络聚焦在特定的特征区域。
2.2 双向融合
HED[14]和DeepCrack[12]网络都是在特征提取的过程中,对不同尺度的输出计算损失后再进行优化,但是这些不同尺度的输出都是直接与GroundTruth 计算损失,实际上不同阶段提取的特征是不同的,因此产生的预测图也是不一样的。应该使不同的阶段预测图与该阶段相对应的Lable进行损失计算,才会让监督学习更合理。即
但是,每一个阶段对应的Lable,即公式中的Yi很难人工标注,只能近似地计算成GroundTruth 减去其他阶段的预测值,可以表示为
其中Yi代表该阶段的Lable 近似值,Y表示GroundTruth,Pj是除了i阶段外的其他预测结果。
此时,损失函数对各层求导相等,逻辑上的意义为各层采用相同的GroundTruth。为此,本文设计了一种双向互补的监督来近似计算Yi即:
s→d表示从特征提取的浅层到深层,d→s则表示从特征提取的深层到浅层,形成双向传递。在同一个尺度下产生两个预测结果,分别是Pi
s→d
和Pid
→s,两者近似等于Yi
s
→d和Yid
→s。因此每一个尺度的预测结果可以表示为
最后本文通过多尺度特征融合的方式得到最终的预测结果,即:
在实验中具体的实现方案是在同一分支上对LA+MVE 模块的输出特征图分别进行了两套步骤相同的卷积上采样以及SA 模块操作,如图1 所示,保证了两个分支互不干扰,分别得到和。
2.3 损失函数
将网络的融合设计为双向传递结构,目的就在于帮助网络在每一个尺度下有相应的Lable针对训练。此时整个网络的损失函数可以表示为
wscale和wfuse调控各尺度和融合后的损失所占比重,在实验中发现两者为0.5 和1.0 时,网络效果最佳。在本文中L(·)方法使用Binary Cross Entropy方法进行计算。在实验过程中,发现裂缝图像的正负样本分布很不均匀,在一张图片中非裂缝像素占据了一张图的绝大部分。
表1 是在两个数据集上各取10 张训练样本计算出的像素组成分析表,从表中数据可以看出,正负样本的差距很大,如果采用相同标准对待正负样本的损失,结果会有偏差。因此本文在Binary Cross Entropy 损失函数的基础上引入了正负样本均衡的机制,即:

表1 训练数据集中的裂缝与非裂缝像素占比
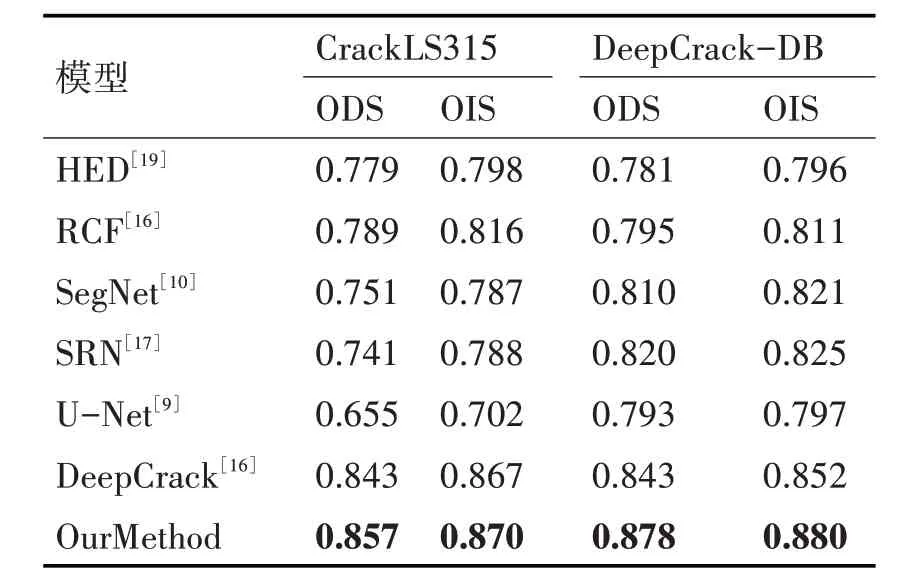
表2 CrackLS315和DeepCrack-DB上各模型的指标
3 实验
3.1 实验数据集
本文在CrackLS315[12]和DeepCrack-DB[15]数据集上分别进行了训练。
CrackLS315 包含315 张包含沥青路面裂缝的图片,每张图片的尺寸为512×512,选取其中的245张经过数据增强后参与训练,剩下的70 张图片其中20张用作验证集,50张用作测试集。
DeepCrack-DB:该数据集包含537 张图片,每张图片的尺寸为544×384,图片中包含各种裂纹,CrackLS315 数据集,该数据集中的裂缝比较粗,选取其中400张经过数据增强后训练,37张作为验证集,剩下的100张作为测试集
为了提升系统的检测能力,本文对这三个数据集进行了数据增强,具体的操作包括对图像进行随机裁切、对称翻转、旋转和Gamma 变换,最终将每个训练集扩充了228倍。
3.2 实验环境及超参数设置
实验环境为Intel(R)Core(TM)i5-8600k CPU,16 GB 内 存,一 块GTX TITAN-X GPU 在Ubuntu16.04系统下,基于pytorch框架编写的网络。
在训练的过程中,Batchsize设置为1,shuffle 设置为True,优化器选用SGD,MOMENTUM 设置为0.9。训练次数设为500,初始学习率为0.001,当迭代次数大于20 时,学习率降为0.0005,当迭代次数大于50 时,学习率降为0.00001,当迭代次数大于100时,降为初始值的0.01倍。
3.3 实验评价标准
为了客观地评估网络的质量,本文根据真正类数(TP),真负类数(TN),假正类数(FP)和假负类数(FN)计算出Precision,Recall 和F1值,这三项指标的计算方法如下:
本文在上述三个指标的基础上,计算了不同阈值下在测试集上求得F1值的最大值,即ODS,同时计算了测试集中每张图片最大F1值的平均数,即OIS,具体的计算方法如下:
ODS 和OIS 能够准确地反映网络的识别能力,可以很好地衡量模型的性能。
3.4 实验对比及结果分析
3.4.1 对比实验
为了验证网络的有效性,本文对比了HED[14]、RCF[16]、SegNet[10]、SRN[17]、U-Net[9]和DeepCrack[16]这几个常见的网络,HED 是一种基于VGG16[18]的网络,它利用VGG16 每个阶段生成的特征图进行多尺度融合,RCF 和SRN 类似于HED,也进行了多尺度融合,是在HED的基础上进行了拓展。SegNet和U-Net是编码解码网络,编码和解码结构对称。
分别将这几种类比网络采用同样的训练策略,在上文的数据集上进行了训练,实验结果如下。
在同种训练条件下,本文设计的网络对于裂缝的检测效果优于现阶段其他的几种网络模型,从图5 的裂缝检测结果生成图可以看出,本文预测的裂缝较其他几种网络的预测结果更加精准,细腻。通过定量分析,在两个数据集上的ODS 和OIS 分别达到的0.857,0.870 和0.878,0.880,超过了前面的几种网络测得的数据,证明了我们所设计的网络的有效性。
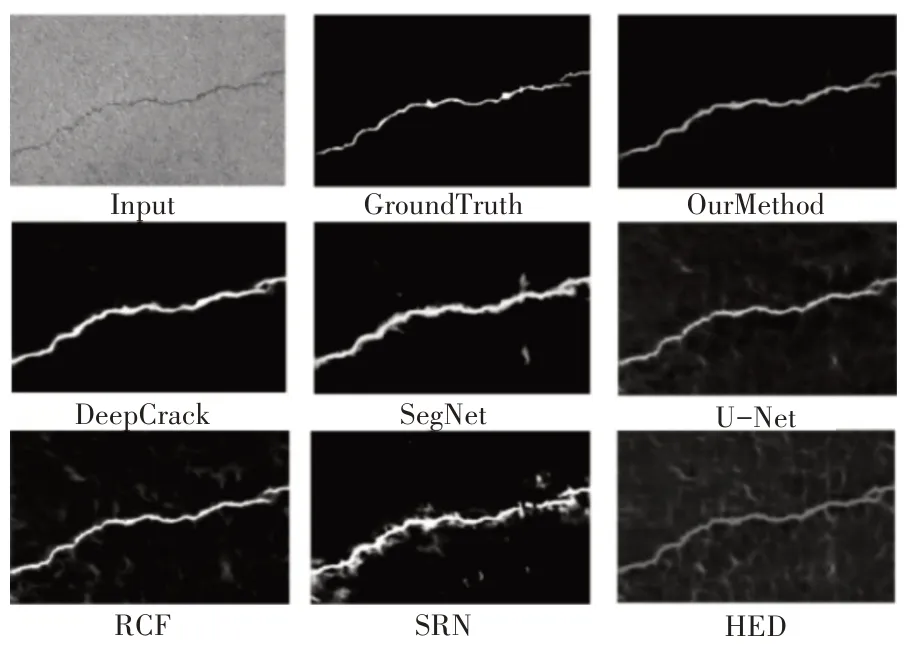
图5 不同模型的生成预测结果
3.4.2 消融实验
为了验证三个模块的提升效果,本文对网络进行了拆分训练。在两个数据集上分别进行了五组实验,第一组不添加任何模块作为对照组,仅对各层输出的结果进行融合后计算出各指标,在第二到第四组实验中,分别添加了LA,SA 和MVE 模块进行测试,最后一组添加所有模块得到最终的检测指标,实验结果如表3。
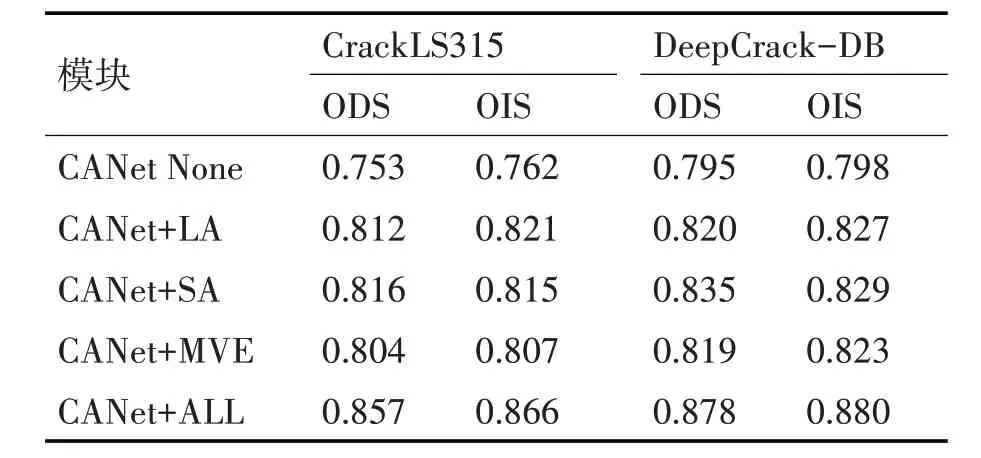
表3 CrackLS315和DeepCrack-DB上各模块的指标
从表3 的数据可以看出,在不添加三种模块的情况下,两个数据集上测出的指标非常低,只有0.7左右。在加入三个模块后,指标迅速提升到0.8 以上。
通过对比MVE 模块和两个Attention 模块对指标提升的数量,LA 模块在两个数据集上的ODS值分别提升了0.059、0.025,SA 模块分别提升了0.063、0.04,而MVE 模块仅提升了0.051、0.024,从这个角度也反映出了Attention 模块具有很显著的提升效果,能够快速提升网络的性能。
4 结语
针对于裂缝检测,为了提升对于裂缝部分的识别能力,本文设计了一种新的网络结构,以Resnext50 作为基础,采用多尺度融合的策略,融合不同阶段的卷积输出生成最终的预测图。
此外,本文在网络中增加了三个模块提升网络性能,其中LA 模块和SA 模块基于Attention 机制,分别在stage 阶段和side 阶段对输出结果进行强化,可以有效提高网络对缝隙的辨识度。另外使用了一种基于膨胀卷积的MVE 模块提升感受野,让网络更容易获取不同尺寸的裂缝特征。
此外,本文使用了一种双向融合的方式,近似获取每个尺度特征图对应的Lable 来求损失,可以加快网络的学习。最终分别在CrackLS315 以及DeepCrack-DB 两个数据集上训练和预测,ODS 指标分别取得了0.873,0.857,0875 的成绩,超过了现阶段的一些网络结构,证明了实验的成功性。
