基于Stacking 融合框架的随钻方位伽马预测*
2023-07-11段友祥
李 娜 沈 楠 段友祥
(中国石油大学(华东)计算机科学与技术学院 青岛 266580)
1 引言
人工智能的发展为多个科技领域的进步带来了诸多契机,对数据预测方法的研究产生了重要影响。近年来机器学习的各种模型呈现爆炸式增长,众多学者专家发现,单一的机器学习模型往往会产生一些欠/过拟合的问题,在此背景下,多模型融合的方法应运而生。融合模型主要包括Bagging、Boosting、Blending 及Stacking 四种,由于其易于理解、效果较好,在电力[1]、金融[2]、故障预测[3]等多方面有广泛的应用。
作为地质导向的关键技术,随钻测井的进步能够为测井人员在钻井实施过程中的决策提供辅助,帮助技术人员准确指导钻头行进方向,保证钻头在目的层穿行,从而提升钻井的钻遇率,提高油气的产量[4]。目前,人工智能与随钻测井的结合越来越紧密,许多国内外学者开展了相关研究:Popa A等[5]通过人工智能和经典模型提出了一种地层动态预测优化水平井布置的方案;Mohamed I M 等[6]利用测井数据,通过训练多种不同的机器学习方法进行地质的分类和预测;Gupta K D 等[7]通过深度神经网络和井眼图像标记油井的剩余深度。
在实时的随钻测井技术中,由于地下向MWD系统传输数据的速率受限,通常仅能接收到上下两道方位的伽马,与完井的四/八道伽马相比,两道伽马所提供的信息较少,更加准确的方位伽马预测能够对后续伽马成像精度、地层识别效果及倾角计算结果有重要的影响,因此对方位伽马的预测是实时随钻测井的一项必要工作。目前在随钻数据的预测主要采用插值方法,由于方位伽马数据具有非线性的特征,该方法并不能准确的描述方位伽马信息。
本文提出一种基于Stacking 融合模型的随钻方位伽马预测模型,以大量的四道伽马数据作为训练集,通过组合多种基学习器提升预测模型的泛化能力,实现预测模型的训练过程。实验表明,本文方法在随钻方位伽马数据的预测中能够达到较高的精度,在随钻测井的前期数据处理中有较好的应用。
2 关键技术理论介绍
2.1 Stacking集成学习
Stacking[8]作为一种集成学习框架,总体分为两层结构:第一层由多种基学习器组成,各基学习器预测结果将作为第二层的输入数据;第二层为元学习器,该层训练模型负责输出最终的预测结果。Stacking的融合模型学习框架如图1所示。
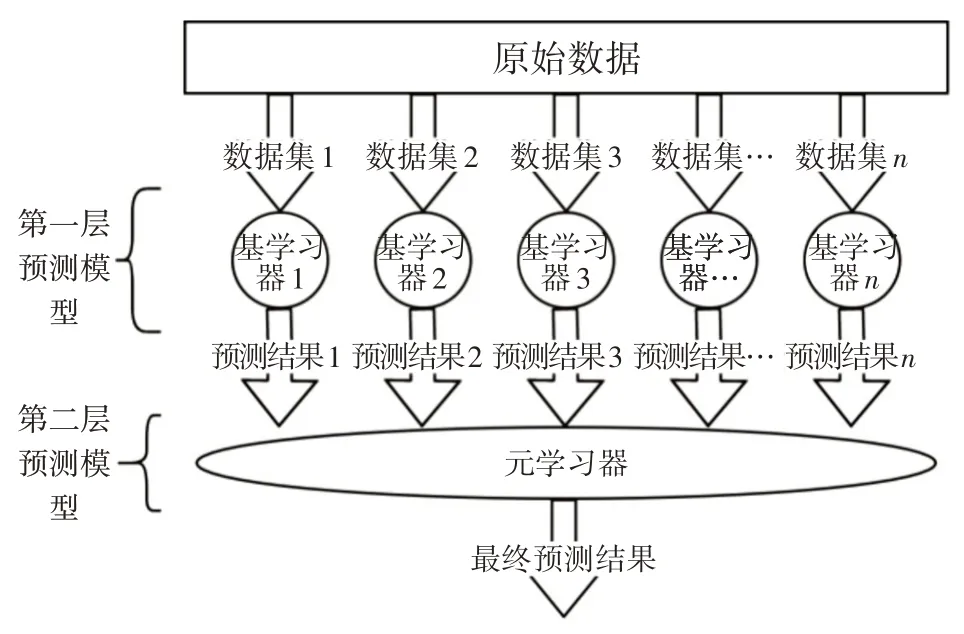
图1 Stacking集成学习框架示意图
其算法基本流程如下:
步骤1:将数据集D={(xi,yi),i=1,2,…,n}划分为大小相同的k个子集D={D1,D2,…Dk}。其中k为基模型个数,xi,yi分别为第i个样本的特征向量和对应的预测值。
步骤2:训练基模型形成新数据集D′。定义基模型Bk对Dk中的样本xi的预测结果为Pki,则有新的数据集D′={(yi,p1i,…,pki),i=1,2,…,n}。
步骤3:基于新的数据集对元学习器预测模型进行训练。
2.2 元学习器介绍
梯度提升决策树(GBDT)由多棵回归决策树组成,拥有较好的泛化能力,在回归预测中具有发现多种特征、提升准确度的优势[9]。GBDT 通常使用加法模型,通过迭代减小数据的误差完成训练,其具体流程如下:
1)初始化损失函数拟合一棵决策树:
2)迭代:
记迭代轮数为k,样本为i,损失函数的负梯度满足式(2):
其中,k=1,2,…,K,i=1,2,…,I。以rki作为模型的残差估计值,利用(xi,rki)拟合一棵回归树,并设叶节点区域为Rkj,j代表回归树叶节点个数。
然后线性搜索估计Rkj的值,从而使损失函数的值尽可能的小,具体表达式如式(3):
3)更新回归树fk(x),得到回归树f(x),具体表达式如式(4):
其中,x∈Rkj。上述流程将输入的训练集数据D={(x1,y1),…,(xI,yI)} ,通过K次迭代,得到最终的强学习器f(x),依据该结果对数据进行回归预测。
2.3 基学习器介绍
1)随机森林
随机森林[10]是一种集成学习的方法,通过大量的决策树分支的投票结果作为最终的输出,具有灵活、准确率高等优点,在医学[11]、油田[12]等多领域有极为广泛的应用。基本训练思路为:通过Bootstrap方法生成多个训练集,并对各个训练集构造决策树;随机选取m个样本属性,依据某种策略选取其中一个属性作为决策树节点的分裂属性;每个节点重复进行分裂,直到到达叶子节点,通过上述步骤建立大量的决策树,从而构造成随机森林。
2)消去树
消去树具有计算简单、计算效率高等优点,引用消去树以达到减少计算图的可到达性,常应用于潮流计算[13]等场景。得到消去树的基本思路为:对于一个稀疏正定矩阵A,将其分解为A=LLT,矩阵L为下三角矩阵。通过广度优先搜索(BFS)矩阵L的有向图,在BFS 过程中,对当前节点搜索最近的节点,并将其定为当前节点的父节点,没有父节点的将作为消去树的根,从而得到消去树。
3)支持向量机
支持向量机(SVM)用于回归,能够避免高维空间的高难度计算,同时适用于解决小样本问题,且具有较强的泛化能力,SVM的回归模型目前广泛应用于故障分析[14]、文本分析[15]等多领域。SVM回归模型的基本原理为:通过放宽预测值的误差,即围绕f(x)规定误差范围并最小化损失,并将SVM 回归模型转换为式(5):
其中,C为正则常数,式(5)包含预测值落入的范围及不敏感损失函数误差的契合度。
4)K近邻
K 近邻(KNN)作为一种基于距离的机器学习算法,具有模型易于理解、对异常值不敏感等优点,常用于解决分类或回归问题,在图像识别[16]等领域有广泛应用。KNN 的基本思想为一个样本i,若与数据集中的k个样本相似,那么将认为这k个样本与样本i属于同一类别,通常在度量样本之间距离时采用欧式距离。
5)长短期记忆网络
长短期记忆网络(LSTM)由于其特殊的门结构,适用于处理具有序列特征的数据,且能够很大程度上避免训练过/欠拟合的问题,目前广泛应用于语音识别[17]、故障检测[18]等领域。LSTM 的遗忘门、输入门、输出门接收上一数据组的输出ht-1及当前的状态xt,同时处理前一记忆单元的状态Ct-1,经过当前记忆单元的内部运算后,产生新的状态Ct向下传递,最后由输出门及非线性函数运算得到输出结果ht。
3 Stacking 融合模型的随钻方位伽马预测模型设计与建立
3.1 框架设计
Stacking集成的学习方式通过组合多个预测模型的信息生成训练集,由元学习器进行组合预测达到融合的目的,这一技术能够有效避免单一模型在训练过程中精度递减等问题,通常能达到比单一模型更理想的效果。第一层预测模型的单一学习器需具有优异的性能,且应组合不同种类学习器,从而获得更多样的第一层训练结果;第二层预测模型选择的元学习器应具有较强的泛化能力。
本文选用随机森林、消去树、支持向量机、K 近邻、长短期记忆网络作为第一层预测模型的基学习器:随机森林具有较强的抗干扰及抗过拟合能力,有较强的泛化能力;消去树性能较好且计算效率高;支持向量机拥有坚实的理论基础,能够快速抓住关键样本的特征;K 近邻原理简单,不需要估计参数;长短期记忆网络善于处理具有序列特征的数据,在训练过程中能避免一定程度的梯度爆炸/消失的问题。在第一层预测模型中,以泊松相关系数对各算法进行相关性分析,从而观测所选算法的差异性,以充分发挥不同类型算法组合的优势,泊松系数的计算公式如式(6),其中xˉ和yˉ为各个向量的平均值:
选用GBDT 作为第二层预测模型的元学习器,该模型具有并行处理的能力,有较好的泛化能力、抗过拟能力及严谨的理论支撑。选用5 折交叉验证,Stacking 的随钻方位伽马预测模型框架设计如图2所示。

图2 Stacking的随钻方位伽马预测模型框架
3.2 训练数据
完井的随钻测井资料往往包含八道完整的伽马数据,将各深度上的八道伽马数据分别拆出第一道+第五道和第三道+第七道作为训练数据及样本标签,具体示意图如图3所示。
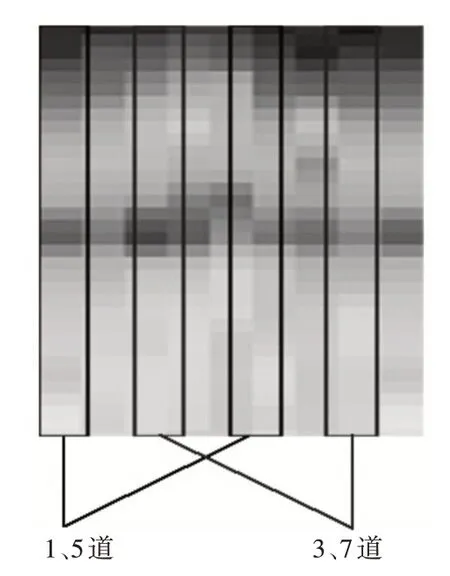
图3 完井训练数据示意图
由于钻井资料较少,且干扰因素较大,需要补充更多的训练数据以增加结果的准确性及可信度,本文采用文献[19]中的随钻方位伽马正演数据计算公式,通过计算机仿真的方法对测井响应进行模拟,构造地层模型,基本计算方法如式(7):
设定正演模型为砂岩和泥岩,相关的地层参数如表1所示。
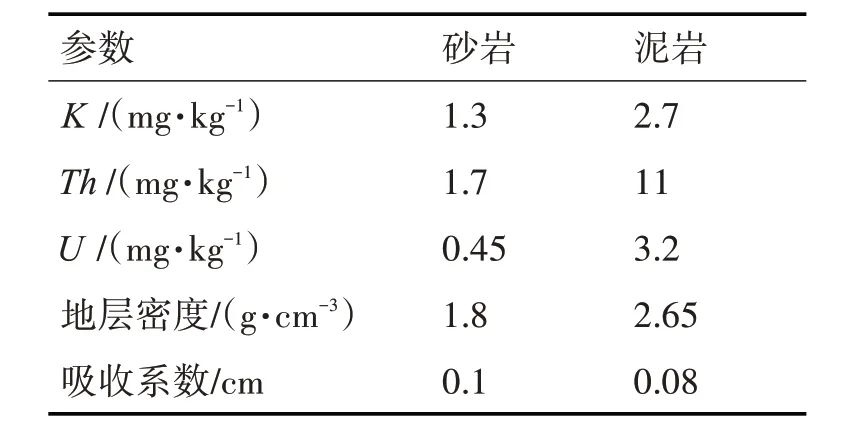
表1 正演地层模型相关参数
4 实例验证
4.1 性能分析
为验证Stacking 集成框架下的随钻方位伽马预测性能,本文将Stacking 模型与各单模型预测的结果及样条插值结果进行对比。数据集以国内X油井的完井资料为例,该井发育良好且具有清晰的地层分界,随钻伽马数据在方位上变化多样。为准确描述各方法间的差异,选取该井中随机深度的数据为例进行预测,结果如图4所示。

图4 各算法预测结果对比
图中Y 轴代表伽马数据的属性值,X 轴代表伽马数据索引。图4(a)~图4(c)分别代表本文方法、样条插值与单一模型(随机森林)对于第3 道伽马数据的预测结果,由图可见,Stacking模型的预测结果与实际数据最吻合,优于单一模型及样条插值。样条插值法仅在整体趋势上与伽马实际数据保持一致;单一模型预测结果与实际数据相近,但在某些数据(如伽马数据索引27 附近)上,仍存在一定的误差;Stacking 融合预测模型的结果与实际数据最为接近,能实现对随钻方位伽马数据的准确预测。
为进一步验证本文方法的有效性,以RMSE、MAE 及MRE 为评价指标,通过计算各误差值验证本文算法与各单一模型算法的性能,具体结果如表2所示。

表2 预测结果的误差分析
由表2 可见,Stacking 融合的伽马数据预测模型性能最好,优于其他单一模型的预测结果。
4.2 实际效果
为验证本文方法在实际生产中的效果,本文对实际井场的实时随钻伽马数据进行预测。实验选用国内东部X油井,该井基于国内自主研发的一体化近钻头随钻地质导向系统,总进尺约860m。截取其中2400m~2460m 数据为例,通过本文方法对实时的上、下两道伽马数据进行预测,最终实际效果如图5所示。
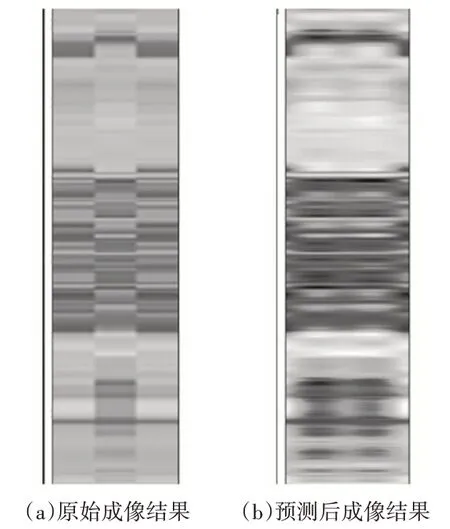
图5 实际中的效果
由图5 可见,通过本文方法对两道伽马数据进行预测处理,得到的伽马成像更加清晰,方位信息更加充足,为后续的地层分析奠定了良好的基础,有利于测井工作的展开。
5 结语
针对实时随钻测井过程中,由于传输速率等问题导致的伽马数据较少,后续地层分析困难的问题,本文提出了基于随钻方位伽马数据的Stacking融合学习预测模型,融合了多种不同类型的单一预测模型,令各模型发挥自己单独优势的同时彼此互补,使随钻方位伽马的预测结果更加准确。通过实验表明,本文方法能够有效地对方位伽马数据进行预测,且效果优于样条插值及单一模型的预测方法。通过对实时的上、下两道伽马进行预测,扩充方位伽马至四道,可以满足后续地层分析对方位伽马数据的要求,为整个地质导向过程提供的技术支持,具有实际应用价值。
