数字普惠金融省域发展特征及影响因素研究
2023-07-11刘原宏杨治辉
刘原宏,杨治辉
(安徽财经大学 统计与应用数学学院,安徽 蚌埠 233000)
0 引言
数字普惠金融是普惠金融在互联网革命下的新产物,其概念是在2016 年杭州G20 峰会上被首次提出的,定义为“一切通过数字普惠金融服务促进普惠金融的行动”。党中央、国务院高度重视发展普惠金融,党的十八届三中全会明确提出发展普惠金融,大力发展普惠金融有利于促进金融业可持续均衡发展,推动大众创业、万众创新,助推经济发展方式转型升级,增进社会公平和社会和谐。总之,无论是站在社会角度还是经济发展角度,数字普惠金融的高质量发展势必是我国金融普惠道路上一股强劲的力量。
现阶段关于数字普惠金融的文献可以概括为两类:一是数字普惠金融作为自变量对其他经济变量或现象影响的研究。现有文献主要从数字普惠金融发展对区域发展不平衡[1]、城乡居民收入差距或减贫效应[2]、企业融资或经营效率[3]、宏观经济高质量发展[4]、创新效应[5]等方面的影响进行研究。二是将数字普惠金融作为因变量研究其本身,现有文献主要是从数字普惠金融发展的区域差异或空间特点和影响因素方面进行分析[6—10]。
另外,现有文献对我国不同地区数字普惠金融发展的空间特点的研究普遍使用空间计量经济学方法。基于此,本文运用大数据分析技术——聚类方法来研究我国不同地区数字普惠金融发展水平所呈现的特征。由于传统的聚类分析中,数据普遍是截面数据,其算法不能应用于面板数据,为此陆续有学者投身于面板数据聚类相关研究中。通过对现有文献的梳理,学者们对面板数据聚类的研究主要集中于相似度度量方法的测度[11—14],而聚类算法普遍采用的是基于层次的聚类算法。
综上,在数字普惠金融影响因素的研究方面,现有研究将数字普惠金融发展作为被解释变量直接研究具体因素对其产生影响的文献较少,且有关因素的选取多为宏观经济发展、城乡居民收入差距、企业创新能力等经济指标,大多忽视了居民意识形态的问题,指标体系构建不够全面,研究方法也多采用传统的参数分析方法。除此之外,现有文献对数字普惠金融区域空间分布特征的研究普遍采用空间计量经济学的研究方法。故本文在因素指标的选取、实证方法的选择上都进行了创新。
1 数字普惠金融时空发展特征
1.1 基于综合距离法的面板数据聚类原理
面板数据聚类的关键在于如何度量个体间的相似度以及采用的聚类算法技术。针对聚类算法的选择,本文沿用学者们常用的系统聚类算法,其中样本间距离采用自定义的综合指标,类间距离采用平均距离法进行系统聚类。提取面板数据的相似特征并计算相似特征的相似距离,其目的可以理解为求解一个N×N的相似矩阵,为一个对称阵,具体可以表示为:
其中,Gi,j表示第i个个体与第j个个体之间的差异程度的“距离”,其值越大表示差异性越大。面板数据区别于截面数据的关键在于其引入了时序特征,因此对Gi,j值的度量不能仅仅局限于简单的绝对数量上的距离测算,还应该充分考虑时序特征对数据产生的波动性影响。故本文从“绝对量”“增量”“增速”和“变异程度”四个角度衡量个体的相似度并基于此合成一个可以反映面板数据特征的综合距离指标,最终用作聚类相似度指标。综合距离指标具体结构及计算公式如下:
表示两个体之间历年指标绝对量上的差距大小,其值越大表示个体间差异越大。
其中,ΔXit=Xit-Xit-1,ΔXjt=Xjt-Xjt-1。表示两个体之间历年指标增长上的差距大小,其值越大表示个体间差异越大。
表示两个体之间历年指标增长率上的差距大小,其值越大表示个体间差异越大。
表示两个体之间历年指标变异程度上的差距大小,其值越大表示个体间差异越大,波动幅度越大。为确保量纲一致,本文对四个子指标进行区间化处理。此外,采用熵值法对各个指标进行赋权。
1.2 基于综合距离法的面板数据聚类实证结果与分析
为了更深入地了解近年来我国数字普惠金融发展状况,找出不同区域在数字普惠金融发展上的差异,以便因地制宜做出宏观政策上的调整,本文利用北京大学数字金融研究中心发布的2013—2020年北京大学数字普惠金融指数[15]进行面板数据聚类分析。根据熵权法赋权结果,绝对量指标、增量指标、增速指标和变异程度指标的权重分别为0.3711、0.1660、0.1907 和0.2722,最终合成综合距离相似度指标。据此,本文用Python编写了相应的面板数据聚类方法的程序进行聚类分析,得到我国31个省份(不含港澳台)的数字普惠金融面板数据的聚类树状图,聚类结果如图1所示。
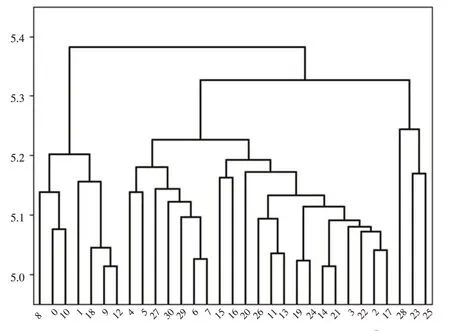
图1 基于综合距离的数字普惠金融发展水平聚类图①图1至图5中的数字0~30分别表示北京、天津、河北、山西、内蒙古、辽宁、吉林、黑龙江、上海、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、重庆、四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆。
由聚类结果图,可以将31 个省份的数字普惠金融发展水平分为3 类,如表1所示。上海、北京、浙江、天津、广东、江苏和福建为一类,内蒙古、辽宁、甘肃、新疆、宁夏、吉林、黑龙江、河南、湖北、海南、陕西、安徽、江西、广西、云南、山东、重庆、山西、四川、河北和湖南为一类,青海、贵州和西藏为一类。第I类的各省份多属于经济比较发达的沿海地区,第III类属于经济较落后的省份,第II类则多属于内陆省份。具体来说,浙江、北京、上海、天津、广东、江苏、福建7个省份历年在绝对量指标上都处于全国领先地位。同时这些省份地区生产总值也在全国领先,可见数字普惠金融的发展水平和地区经济发展水平有较强的正相关关系。此外,青海、贵州和西藏三个省份的数字普惠金融发展水平一直以来在全国各省份中较为落后,但是这三个省份的数字普惠金融发展增量、增长速度、波动幅度却是最大的。

表1 数字普惠金融发展水平聚类结果
1.3 面板数据聚类结果有效性检验
如下页图2至图5所示,从2013—2020年各省份数字普惠金融发展指数的单一相似度指标呈现的聚类结果来看,北京、上海、浙江、广东、江苏、福建、天津、湖北等省份的数字普惠金融指数的绝对量要高于其他省份;但在增量指标上,上海、海南、宁夏、内蒙古、贵州和西藏6个省份的数字普惠金融指数增量与其他省份存在较大差异;在增速指标上,青海、河南、新疆、贵州、西藏、甘肃6 个省份的数字普惠金融指数增速要明显快于其他省份;在变异程度指标上,西藏、河南、辽宁、青海、天津、内蒙古6 个省份的数字普惠金融指数的波动情况较其他省份幅度更大。可见基于单一指标的聚类方法导致聚类结果存在较大的差异性,故单纯考虑某一类距离作为相似度指标是不合理的。因此,在充分考虑数字普惠金融发展指数“绝对量”“增量”“增速”和“变异程度”情况下,表1的分类结果是合理的。

图2 基于绝对量距离的数字普惠金融发展水平聚类图

图3 基于增量距离的数字普惠金融发展水平聚类图

图4 基于增速距离的数字普惠金融发展水平聚类图

图5 基于变异程度距离的数字普惠金融发展水平聚类图
2 数字普惠金融的影响因素
2.1 指标体系构建及数据说明
在影响因素指标选取上,根据现有文献研究成果以及相关理论支撑[6,8,10,16],最终选取我国31 个省份的数字经济发展水平(DE)、居民金融素养(FL)、投资规模(IS)、金融规模(FS)和金融风险(FR)作为影响因素,具体指标见表2。为确保数据的统计口径一致,本文选取2013—2020年数据,数据来源于国家统计局官网、《中国城市统计年鉴》《中国教育统计年鉴》《中国金融统计年鉴》、EPS 数据库。此外为了消除价格波动的影响,对个别指标进行了平减处理。
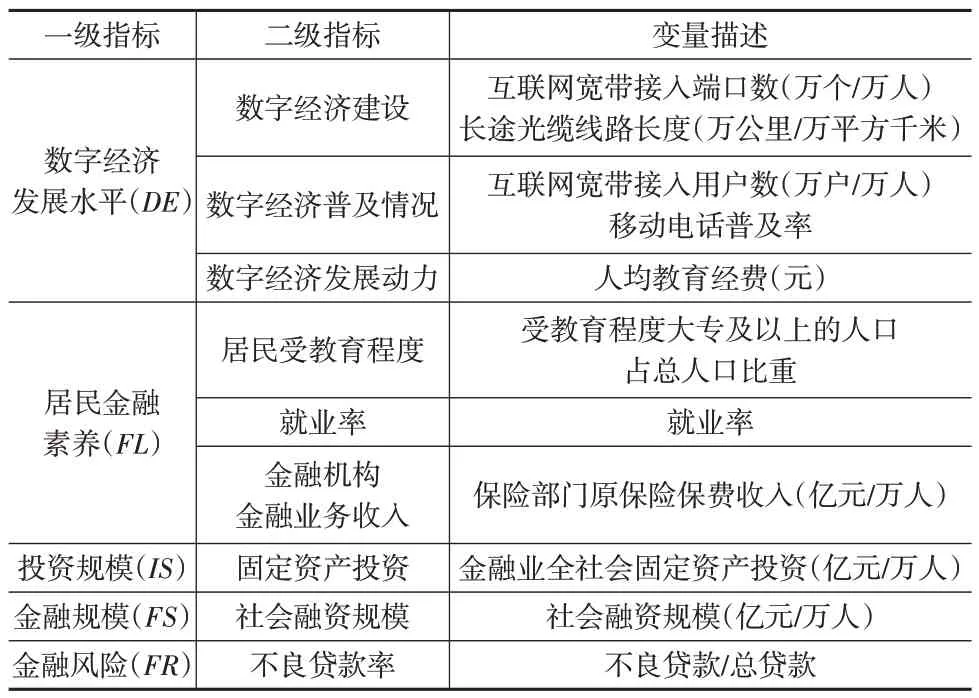
表2 指标体系
对构成各个指标的变量进行无量纲化处理,归一化为取值在0到1之间的数值,使各个指标具有可比性。对于综合指标数字经济发展水平(DE)和居民金融素养(FL)采用主成分分析法进行子指标的赋权。
结合我国数字普惠金融发展现状及相关理论支撑,本文假设数字经济发展水平、居民金融素养、投资规模和金融规模均对数字普惠金融发展具有正向影响,金融风险对数字普惠金融发展具有负向影响。
2.2 面板数据参数模型
在正式建立半参数模型之前需要对半参数模型的非参数部分进行判断,先构建参数面板数据模型判断模型中是否可能存在非线性项。可供选择的线性参数面板模型有:混合面板模型、个体固定效应面板模型、时间固定效应面板模型、双向固定效应面板模型、随机效应模型等。混合面板模型与随机效应面板模型的选择采用LM检验法,固定效应面板模型和随机效应面板模型的选择采用Hausman检验法。模型估计及检验结果如下页表3所示。

表3 普通面板数据回归结果
由检验结果可知LM 检验P 值为0.0000,即拒绝接受建立混合效应模型的原假设,所以在混合效应模型和随机效应模型之间应该选择随机效应模型;Hausman检验结果显示其检验结果P 值为0.0000,即拒绝接受建立随机效应模型的原假设,所以在随机效应模型和固定效应模型之间应该选择固定效应模型,可以用个体固定效应模型进行面板半参数模型非参数部分分析以及判断非参数模型的有效性。个体固定效应回归结果显示,数字经济发展水平、居民金融素养、投资规模、正向化的金融风险及金融规模对数字普惠金融的影响较大且具有正向促进作用,与假设相符。
2.3 半参数面板数据模型
2.3.1 半参数模型的构建
实际分析中可供选择的半参数模型形式多样,包括部分线性模型、部分线性变系数模型、部分函数模型、部分线性可加性模型等经典模型。本文选择使用半参数部分线性模型建模。根据个体固定效应面板模型估计结果,选取未通过显著性检验的指标作为半参数模型的非参数部分,通过显著性检验及与对数字普惠金融影响假设相符的指标作为半参数模型参数部分,分别建立两个具有唯一非参数变量的半参数部分线性模型:
其中,i=1,2,…,n,t=1,2,…,T。DIFIit表示数字普惠金融发展水平并作为两个模型的被解释变量,DEit、FLit和FSit分别表示数字经济发展水平、居民金融素养和金融规模并作为两个模型的解释变量的参数部分,g(FRit)和g(ISit)分别表示金融风险、投资规模并作为两个模型的解释变量的非参数部分,μit和εit分别表示模型的误差项。
相较于普通的参数估计和非参数估计,半参数模型估计的核心问题就是模型中非参数项的估计,本文运用样条估计的方法估计半参数模型中未知参数部分。样条估计的思想为残差平方和最小基础之上附加了条件,即:
因此,在利用样条方法估计半参数模型的非参数部分时,重点就是确定λ值,光滑参数λ值的设定很重要,直接关系着模型的估计效果。本文选择交叉确认法(CV)为模型选择合适的λ值,其思想是寻找λ0值使得CV值最小,公式如下:
此外,本文核函数选择Epanechnikov 核函数,其表达式如下:
其中,I(·)为示性函数,当|x|≤1 时为1,反之为0。相比于高斯核函数,Epanechnikov核函数可以大大减少计算量,提高算法运行速度。
2.3.2 半参数模型实证分析
根据上文构建的面板数据半参数模型和估计方法对2013—2020 年我国省级面板数据进行实证分析,结果如表4所示。

表4 部分线性半参数模型回归结果
由回归结果可知,两个部分线性半参数模型参数部分的系数估计值比较接近,具有较强的一致性,且各个作为参数部分的变量都有很高的显著性水平,P 值几乎均为0.0000,均方误差都较小,且非线性项偏导图显示变量确实存在较为显著的非线性影响,估计效果明显优于参数个体固定效应模型,可见两个部分线性半参数回归模型的估计结果较为可靠。
根据模型一对半参数模型的系数进行分析,在其他条件保持不变的前提下,数字经济发展水平、居民金融素养以及金融规模每增加1个单位,数字普惠金融发展水平分别提高0.9296、0.7903、4.1753个单位。其中金融规模对发展数字普惠金融贡献最大,居民金融素养对发展数字普惠金融的贡献最小,但综合而言本文三个参数因素对数字普惠金融均有很大程度的正向影响。具体来讲:首先,数字普惠金融的发展需要足够的金融体量作为发展支撑。普惠金融是在传统的金融服务中逐步推出的新概念,以传统金融服务为基础,而数字普惠金融是在普惠金融的基础之上新增加了数字概念。由此可见,数字普惠金融的发展是建立在传统金融服务上的,也可以理解为金融规模越大,对数字普惠金融发展越有利。其次,数字普惠金融服务的重点对象是小微企业、农户等群体,这些群体普遍在央行征信数据中质量较差且抵押手段匮乏,这就会导致银行无法通过央行征信报告、抵押品等传统方式进行风险识别。如果依赖人力进行线下走访评估,就会进一步拉高单客运营成本;如果降低风控标准,就会导致风险敞口上升,故居民金融素养的提升在数字普惠金融发展中虽最难改变但却起到重中之重的作用。最后,数字普惠金融区别于传统概念上的普惠金融最重要的一点就是普惠金融的发展以互联网为主要载体,而数字经济这种同样以互联网为载体的新型经济模式使得数字普惠金融能够实现发散式发展并真正深入到基层群众。根据黄益平和黄卓(2018)[17]的研究,以数字技术作为表达的金融科技发展水平的提高可以解决传统普惠金融发展上的诸多问题,其通过移动终端和大数据分析技术降低了金融机构获客和征信的成本。故在不同因素共同作用下,数字经济发展对数字普惠金融影响同样巨大。
如图6所示,模型一的非参数部分正向化的变量——金融风险(FR)对数字普惠金融发展水平的偏导数曲线的趋势是由相对平稳的正向促进作用变成抑制作用。这说明随着金融安全性的增加,数字普惠金融发展水平呈现较为稳定且缓慢上升的态势,但是随着金融安全性的进一步提高,金融安全性对数字普惠金融发展水平的作用开始快速降低甚至起到抑制作用。金融风险不仅意味着损失的可能性,也意味着盈利的可能性,从另外一个角度看,金融风险不仅是损失、问题和危机的来源,也是收益、盈利和发展的来源,金融风险与收益并存。这体现为数字普惠金融发展与金融安全性之间有一定程度的反向抑制关系,金融安全性过高也不利于数字普惠金融的发展。
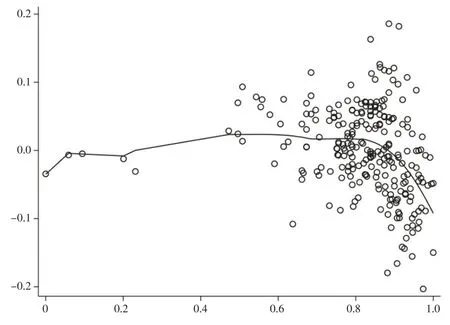
图6 金融安全性对数字普惠金融发展水平的偏导数图
如图7所示,模型二的非参数部分变量——投资规模(IS)对数字普惠金融发展水平的偏导数曲线的趋势由较为平稳的正向促进作用急剧下降为负向抑制作用。投资规模的增加会使得数字普惠金融发展水平稳步上升,但当投资规模达到一定规模时,更多的投资对数字普惠金融发展不再具备促进作用,反而会随着投资规模的进一步加大,其负向作用愈发明显。适当的投资会减少数字普惠金融发展的成本压力,为其高质量发展提供资金支撑,但过多的投资会使得数字普惠金融的产出效率下降,产生投资浪费的现象,不利于社会均衡发展。

图7 金融规模对数字普惠金融发展水平的偏导数图
3 结论与建议
本文以2013—2020 年我国省级层面数据为基础,采用基于综合距离法的面板单指标聚类方法研究数字普惠金融的区域发展特征,并运用半参数模型揭示了我国数字普惠金融发展的影响因素。得出以下结论与建议:
(1)基于综合距离法的面板单指标聚类方法表明我国省域数字普惠金融发展状况可以分为三种类型。经济较发达的沿海地区数字普惠金融发展状况较为相似,而这些城市多属于全国中心城市,经济发展较为领先。经济不发达的西部省份,如西藏、青海、贵州呈现高增长量、高增长速度、高波动率的特征,数字普惠金融发展特点相似性较强。因此,各地方政府部门应该因地制宜,充分考虑当地发展状况,制定相应的政策。
(2)半参数回归模型参数部分回归结果显示,数字经济发展水平、居民金融素养、金融规模对我国数字普惠金融发展具有十分显著的正向线性影响,其中金融规模影响最大,数字经济发展水平次之。因此各地方政府应该适度扩大金融服务规模,高质量发展数字经济,真正实现“数字产业化”和“产业数字化”,加快实体经济与数字经济的融合,为地方经济注入新动力。在居民的意识形态问题上,地方政府可以定期组织针对特殊群体(农户、低收入群体等)的有关金融知识培训活动,提升居民的平均金融素养水平。
(3)半参数回归模型非参数部分偏导数图结果显示,投资规模和金融风险对我国数字普惠金融发展具有非线性影响,投资规模过大或金融安全性过高均会抑制数字普惠金融的发展。因此,在国家层面上,政府应该掌控好投资规模的大小,使投资总量始终保持在合理的水平,把控金融风险。
