稀疏奖励下基于强化学习的无人集群自主决策与智能协同
2023-07-10李超王瑞星黄建忠江飞龙魏雪梅孙延鑫
李超,王瑞星,黄建忠,江飞龙,魏雪梅,孙延鑫
(1.中国兵器工业试验测试研究院 技术中心,陕西 西安 710116;2.南京理工大学 机械工程学院,江苏 南京 210094;3.哈尔滨工业大学 航天学院,黑龙江 哈尔滨 150001)
0 引言
二战结束以来,尽管大规模世界战争未有发生,但局部性战争却从未停止,从朝鲜战争到阿富汗战争再到纳卡战争以及硝烟弥漫的俄乌战场,科技力量带来的加成逐渐显现,尤其是新世纪发生的几次战争中,无人智能装备发挥了重要的作用[1]。
未来,无人智能集群作战将会是典型的作战模式。而无人集群的最终应用离不开无人集群对抗建模及群体智能演化机理、无人集群探测识别与态势感知、无人集群通信、无人集群导航、无人集群自主决策、无人集群运动控制以及无人集群对抗策略迁移与泛化[2]、无人集群试验与评估[3]等技术研究。其中在无人集群自主决策研究领域[4],强化学习技术被广泛使用。
多智能体系统,由一系列相互作用的智能体构成,多个智能体之间通过相互通信、合作、竞争等方式,完成单个智能体不能完成的、大量而又复杂的工作。目前,结合多智能体系统和强化学习方法形成的多智能体强化学习正逐渐成为研究热点[5]。
如图1所示,多智能体强化学习技术框架包含环境、智能体两部分,智能体n感知环境状态,输出状态矩阵sn,输出的状态组成联合状态集 (s1,s2,s3,…,sn),并依据策略网络选择动作an,输出的动作组成联合动作集(a1,a2,a3,…,an),作用于环境,环境依据联合动作给予对应奖励rn组成总奖励集(r1,r2,r3,…,rn)并更新状态[6]。在多智能体与环境交互过程中,奖励为多智能体策略迭代的重要依据。丰富的奖励反馈,可以有效引导多智能体学习到最优动作策略,但在强化学习技术的应用领域中,奖励稀疏性问题广泛存在。尤其随着深度学习技术与强化学习技术的深度融合,深度神经网络被应用到强化学习应用领域之后,因网络训练过程需要大量样本支撑,稀疏奖励问题也就愈加凸显[7]。
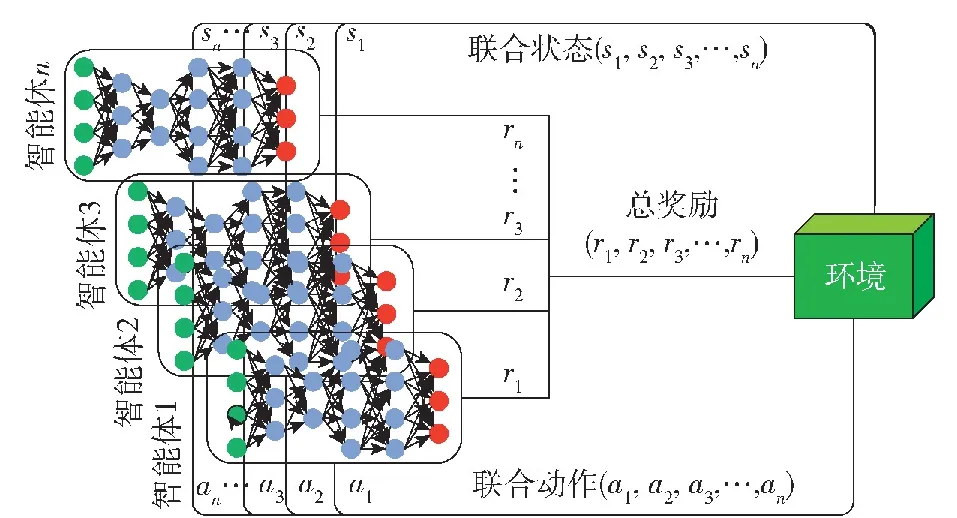
图1 多智能体强化学习原理图Fig.1 Schematic diagram of multi-agent reinforcement learning
针对广泛存在的奖励稀疏性,奖励塑造利用经验知识人工设计奖励函数以扩充奖励体系引导智能体进行最优策略学习[8-9]。课程学习通过不断增加任务难度以改善奖励稀疏造成的网络收敛缓慢问题[10]。事后经验回放是一种从失败经历中提取有效信息的强化学习方法,通过对失败经历进行处理产生奖励信息,解决奖励的稀疏性问题[11]。分层强化学习通过缩小各层策略的动作序列空间,提高解决稀疏奖励问题的能力[12]。现有奖励体制机制研究多针对于单智能体策略学习问题,且仿真或试验的场景设定较为简单,状态-动作空间维度较低[13-15]。
针对基于强化学习的无人集群自主决策与智能协同策略学习这一多智能体问题存在的奖励稀疏性,建立了无人集群攻防对抗任务场景模型,并提出了基于局部回报重塑的奖励机制设定方法,在此基础上叠加优先经验回放(PER),通过程序仿真及演示系统验证,本研究有效地改善了奖励稀疏性,极大提升了策略学习的效率。
1 无人集群对抗模型设计
针对无人集群对抗问题特点,设计的模型框架应包含以下3层内容:
1)场景层:该层主要对无人集群对抗的场景类别和场景特点进行设计。明确场景目标、场景构成,为后续无人集群对抗模型设计奠定基础。
2)单元层:该层主要对对抗场景下单元数量及单元属性进行设计。其中异构无人集群对抗还需对单元种类进行设计,通常异构无人集群对抗可包含探测单元、防御单元和攻击单元等。另外在单元属性方面,可设计生命属性、移动属性、探测属性、攻击属性、防御属性等。
3)规则层:该层应明确集群对抗双方在具体对抗场景下的博弈策略及胜负判别规则。
在模型设计时,场景层、单元层、规则层设计可以划分为场景模型设计和对抗规则设计两大过程,如图2所示。场景模型设计包含场景类别设计、场景特点设计、单元构成设计及单元属性设计,对抗规则设计包含无人集群对抗双方的博弈策略设计以及对抗过程的判别规则设计。
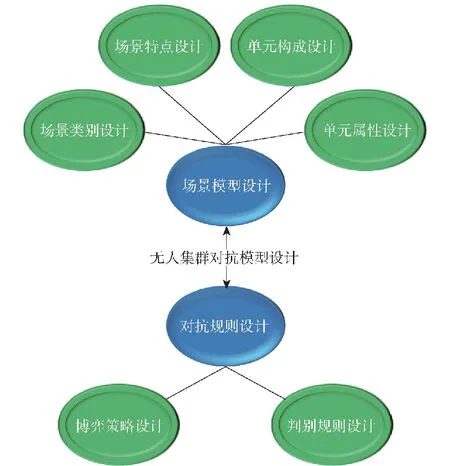
图2 无人集群对抗模型构成Fig.2 Composition of the UAV swarm confrontation model
1.1 无人集群攻防对抗场景模型设计
基于图2所示模型框架,本研究设计了无人集群攻防对抗场景模型,攻防对抗为无人集群对抗典型任务场景。在单元种类方面,设计攻击、探测、防御3种单元。在单元数量方面,攻击单元、防御单元、探测单元分别为6个、4个、2个。在任务目标方面,基于蓝方采用设定策略的前提,通过基于强化学习的自主决策与智能协同技术,使得红方单元学习到比蓝方更优的博弈策略。
图3为无人集群攻防对抗仿真模型红蓝初始站位图,其中正方形框线表示红蓝对抗区域,双方无人集群智能单元在对抗区域两侧一字排开。在仿真示意方面,双方攻击单元、防御单元、探测单元及生命值、防御范围、探测范围等单元属性示意如图3所示[16-18]。图3中,AT、DE、DT分别表示红蓝双方攻击单元、防御单元、探测单元存活数。
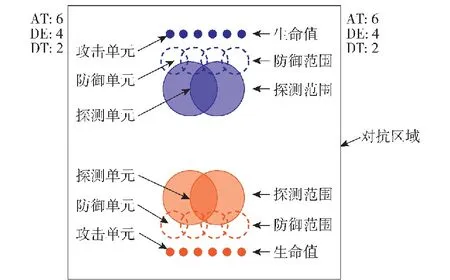
图3 红蓝无人集群攻防对抗仿真模型初始站位图Fig.3 Initial site map of attack-defense confrontation simulation model of the red and blue UAV swarms
1.2 无人集群攻防对抗规则设计
无人集群对抗规则设计包含博弈策略设计及判别规则设计,其中博弈策略设计包含集群对抗双方在任务场景下的博弈对抗策略。针对本研究所设计的无人集群攻防对抗任务场景,红蓝对抗双方的博弈策略如图4所示。
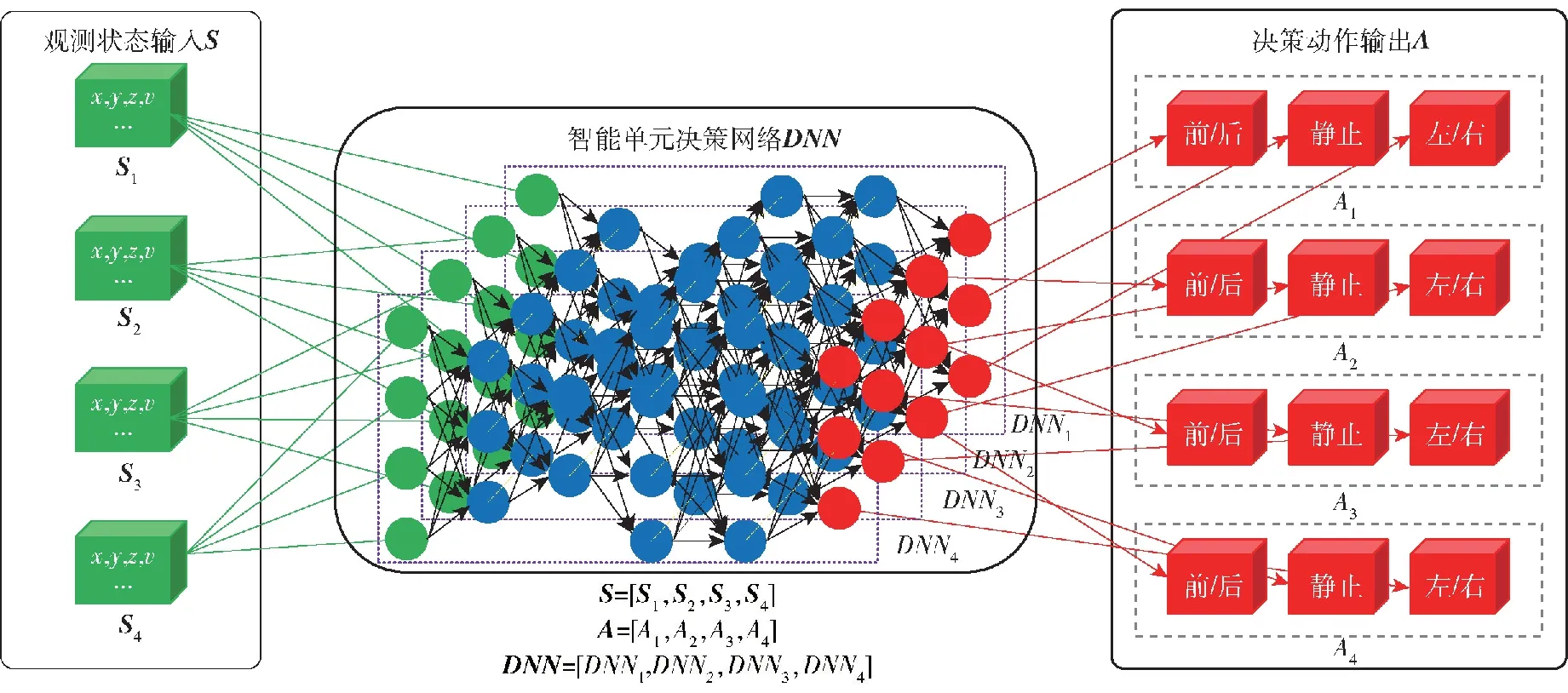
图4 红方智能单元自主决策原理示意图Fig.4 Schematic diagram of the autonomous decision-making principle for the redintelligent units
红方为基于深度神经网络的自主决策单元,如图4所示,若红方无人集群包含4个智能单元,智能单元决策网络DNN则相应设计4个智能体的自主决策DNN1、DNN2、DNN3、DNN4,在网络设计过程中,每个智能体的自主决策在结构上独立,但在参数上存在耦合,从而使得多类多个智能单元具备自主决策能力的同时具备协同能力涌现的潜能。在决策网络输入输出方面,以智能体观测状态如自身/对方位置、速度、数量等参数为状态输入,Sn为第n个智能体观测状态,包含位置(x,y,z)、速度v状态量,多个智能体观测状态组成智能体联合状态集S。以智能体移动/静止状态选择、移动方向为动作输出[19-21],多个智能体动作输出组成智能体联合动作集A。
蓝方单元采用既定博弈策略,通过对无人智能单元集群作战战术战法的深入了解,设计蓝方单元博弈策略。针对防御属性、探测属性、攻击属性,依据各属性范围内有无被防御、被探测、被攻击单元将3种智能单元的移动策略分别归为两类。其中针对防御单元,如图5(a)所示:当单个单元防御范围有被防御单元时,防御单元静止;当多个防御单元防御范围重叠处有被防御单元,其中一个防御单元静止,其余单元被认定为防御范围内无被防御单元;当防御范围内无被防御单元时,趋向最近的需被防御单元。针对探测单元,如图5(b)所示:当探测范围内有被探测单元,探测单元静止;当探测范围内无被探测单元时,如存在未被探测到攻击己方单元的敌方攻击单元,则趋向最近的该类型单元;否则趋向最近的被探测单元。针对进攻单元,如图5(c)所示:当攻击范围内无处于探测单元探测视角下的被攻击单元,则趋向最近的该类型单元;否则,攻击单元静止并转为攻击状态。
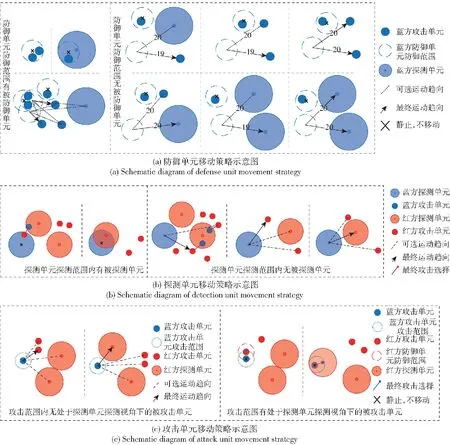
图5 蓝方智能单元博弈对抗策略示意图Fig.5 Schematic diagram of the game confrontation strategy of the blueintelligent units
判别规则设计包含对抗过程有效性判别及对抗终局胜负性判别。有效性判别方面,双方应在对抗区域内、设定属性限制下进行对抗。胜负性判别方面,为考察智能单元自主决策算法的学习效率,在双方单次对局中,设置最大仿真步。未达到最大仿真步时,若一方智能单元中探测或攻击单元被全部消灭,判定该方对局失败。达到最大仿真步时,对局结束,对所有智能单元的剩余总血量进行比较,总血量大的一方对局胜利,相同则判定平局。
2 稀疏奖励解决方法
2.1 基于局部回报重塑的无人攻防集群对抗奖励工程设定
无人集群对抗领域问题在应用强化学习技术时,现有的奖励体系依据对局是否胜利进行奖励反馈,对局胜利给予奖励,对局失败无奖励。上述为稀疏奖励的一种极端形式,名为二元奖励。在该奖励机制下,策略网络训练过程会被严重滞缓甚至策略网络根本无法收敛。
本研究提出基于局部回报重塑的奖励工程设计方法。即首先将任务分解为多个子任务,对应明确任务目标及子目标,在细分的过程中确定任务执行主体与子目标之间的逻辑关系。以异构无人集群对抗场景为例,因不同种类的智能体特点属性不同,在任务中扮演的角色也有所不同。因此可以有针对性地对任务目标进行分解,适配不同种类智能体的功能属性[22]。
针对本文研究的无人集群攻防对抗任务场景,在设定奖励机制的过程中,依据不同种类智能单元的属性特点分别设计奖励函数。针对攻击单元,鼓励攻击、低血量退避、躲避敌方探测单元等行为。针对防御单元,鼓励有效防御行为。针对探测单元,鼓励有效探测、躲避敌方攻击、躲避敌方探测单元等行为。针对所有单元,鼓励尽快结束回合行为,以上各种奖励引导项的最终目标为短时间内消灭对方智能单元从而在单次对局中获胜。上述定性设计结果如图6所示。
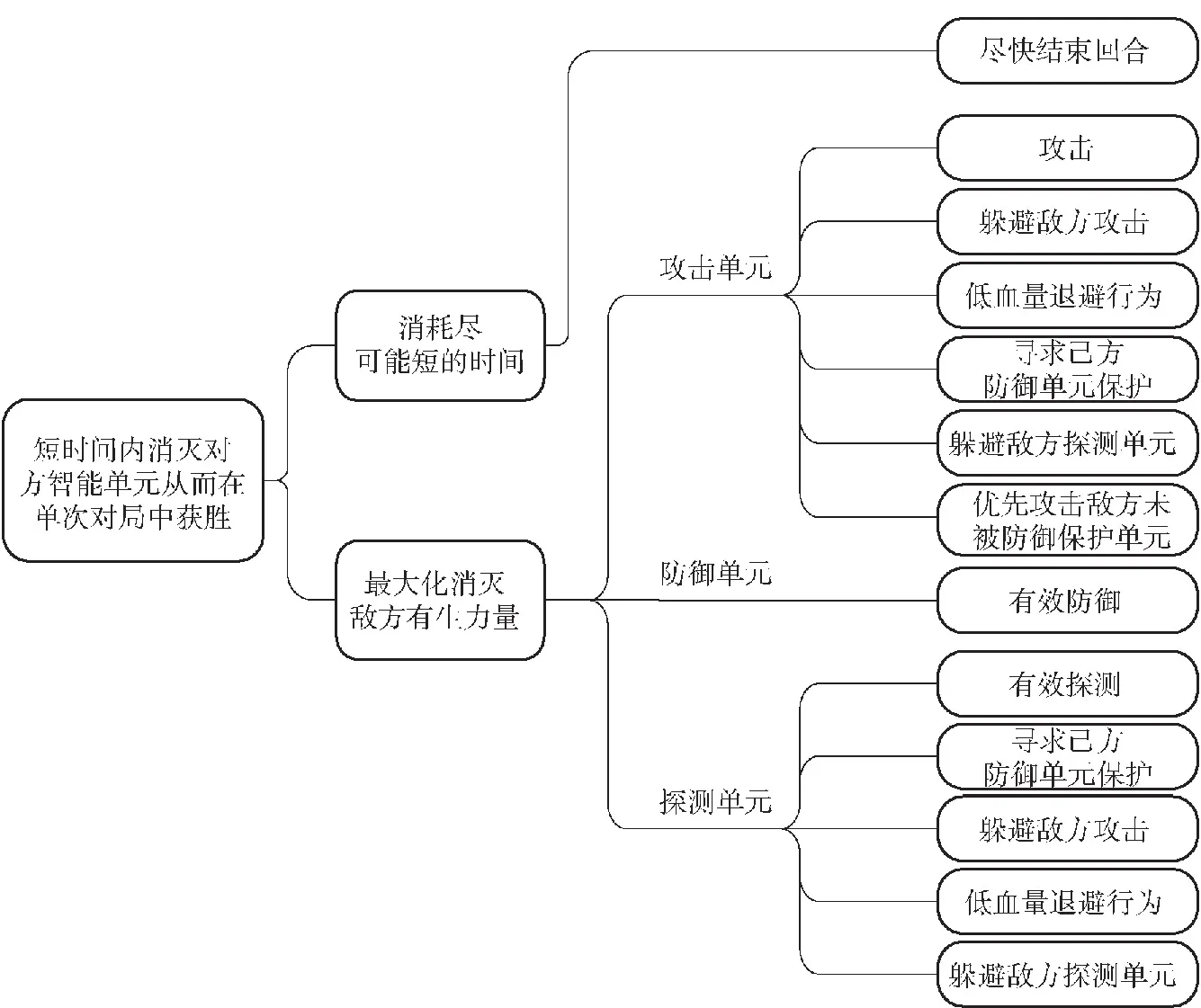
图6 无人集群攻防对抗场景下基于局部回报重塑的奖励工程设定Fig.6 Reward engineering setting based on local reward reshaping in UAV swarm attack-defense confrontation scenarios
定量奖励函数设计方面,目前奖励函数中奖惩数值设计主要依靠经验。本研究场景下的奖励函数为
(1)
(2)
式中:r为单次对局总奖励;ri为第i回合总奖励;rATj为单回合内第j个攻击单元奖惩差;rDEk为单回合内第k个防御单元奖惩差;rDTl为单回合内第l个探测单元奖惩差。rATj计算公式为
(3)
式中:x1~x3为奖励项,值为正;y1~y4、a、b为惩罚项,值为负。rDEk及rDEl奖励函数计算方式同上。
2.2 基于局部回报重塑及PER的无人集群攻防对抗方法框架
通过局部回报重塑的奖励工程设计方法对无人集群攻防对抗场景已有的二元奖励进行扩充,奖励体系得到了丰富。将单次对局下基于局部回报重塑的无人集群对抗所有回合奖励信号进行输出,结果如图7所示。在总数约800个状态动作序列对样本中,只有约12%的状态动作序列对存在奖励信号,其余均无奖励信号,这意味着约88%状态下采取动作的有效性无法进行评判。因此,通过局部回报重塑方法设计的奖励机制奖励稀疏性依旧严峻。
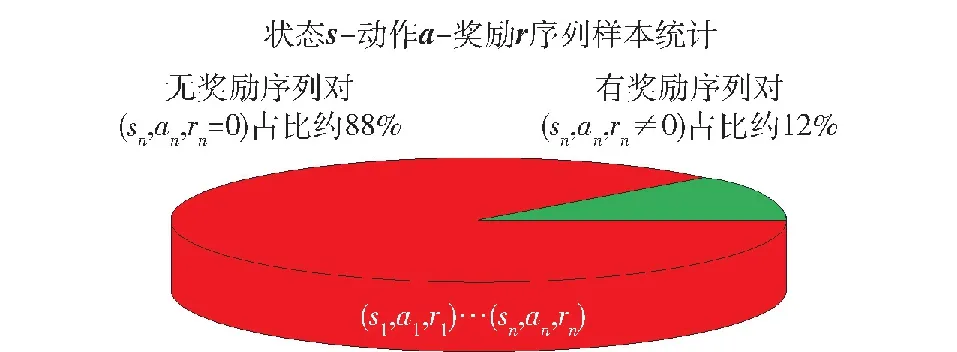
图7 局部回报重塑方法下奖励稀疏性示意Fig.7 Reward sparsity under the local reward reshaping
依据是否存在奖励信号,智能单元与环境交互产生的状态动作序列样本具备不同的重要性。存在奖励信号的状态动作序列对有学习价值,优先级高。而无奖励信号的状态动作序列对无学习价值,优先级低。因此,可采用PER[23]实现对经验样本的差别利用。在回放训练的过程中,通过对有效经验样本进行优先级排序,实现对高价值样本的优先利用,以实现对抗策略的快速有效学习。在算法方面,因本文仿真模型为离散输出,故选择深度强化学习(DQN)算法[24]。采用回放记忆单元存储(s,a,r,s′)序列,其中s为当前回合状态,a为当前回合动作,r为当前回合奖励,s′为下一回合状态,基于PER算法对回放记忆单元进行优先级采样,作为动作值函数逼近网络与目标值网络的训练样本,通过DQN误差函数计算迭代,进行网络参数更新。
综上,若将局部回报重塑方法称为稀疏奖励问题下奖励信号的“开源”,PER的使用则是从“节流”的角度对样本进行了高效利用。通过奖励信号“开源”、“节流”两种手段实现了对稀疏奖励问题的有效解决,最终形成基于局部回报重塑及PER的无人集群对抗自主决策与智能协同策略学习方法框架,如图8所示。首先通过局部回报重塑方法对基于强化学习技术的无人集群对抗问题所固有的二元奖励进行扩充,局部回报重塑很大程度上改善了奖励的稀疏性,但奖励稀疏性依旧严峻,然后依据样本是否存在奖励信号及奖励信号数值进行优先级排序,在样本回放学习过程中进行优先级采样,对高价值样本进行优先学习。最终通过两种方法组合实现稀疏奖励下无人集群自主决策与智能协同对抗策略的高效学习。
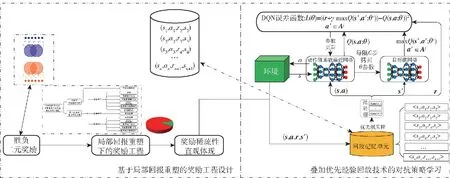
图8 基于局部回报重塑及PER的无人集群对抗自主决策与智能协同策略学习方法框架Fig.8 Framework for autonomous decision-making and intelligent collaboration strategy learning method for UAV swarm confrontation based on local reward reshaping and prioritized experience replay
3 无人集群攻防对抗仿真及演示系统设计
3.1 无人集群攻防对抗程序仿真
在无人集群攻防对抗场景下,将强化学习算法与稀疏奖励方法组合设计进行了程序仿真。
在DQN及局部回报重塑组合算法(简称DQN+局部回报重塑算法)下,通过2 000代训练,红方智能单元策略收敛,胜率约80%,如图9(a)所示。采用DQN改进算法即Double DQN及局部回报重塑组合算法(简称Double DQN+局部回报重塑算法),通过缓解策略学习过程中价值高估问题,训练1 500代后,策略实现了收敛,如图9(b)所示。在上述方法基础上,叠加PER(简称Double DQN+局部回报重塑+PER算法),通过对有效样本的高效利用,训练700代后策略实现收敛,如图9(c)所示。
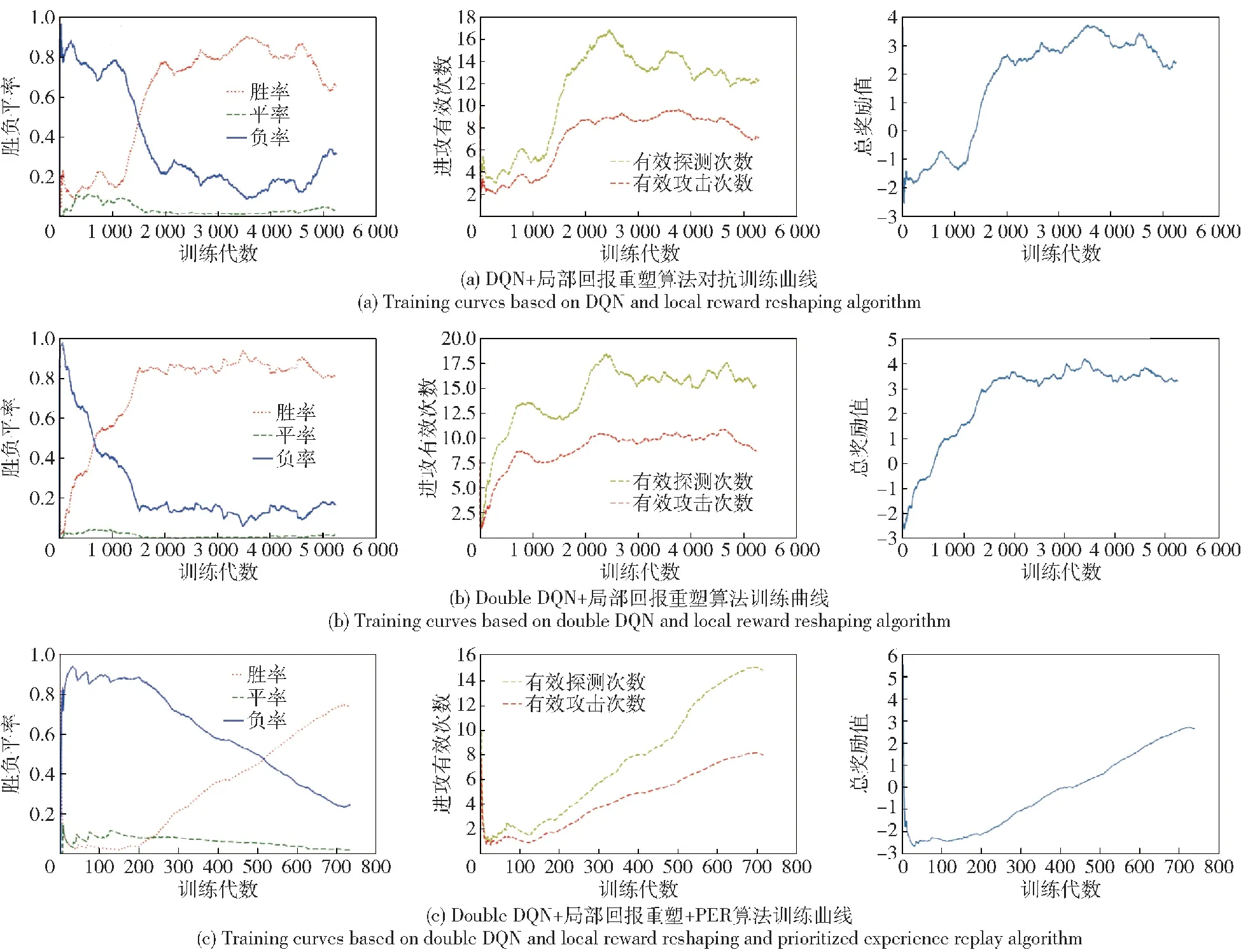
图9 无人集群攻防对抗算法效率对比Fig.9 Efficiency comparison for attack-defense confrontation algorithms of UAV swarms
此外,在进攻有效数据及防御有效数据方面,仿真曲线图均呈现逐渐提升的趋势,证明了算法的有效性,3种算法效率对比如表1所示。

表1 无人集群攻防对抗算法效率对比Table 1 Efficiency comparison forattack-defense confrontation algorithms of UAV swarms
在同样达约80%胜率的对抗能力前提下,DQN+局部回报重塑算法训练了2 000代,Double DQN+局部回报重塑算法训练了1 500代,算法提升25%,Double DQN+局部回报重塑+PER算法训练700代,算法提升65%。
上述为算法在对抗策略宏观层面的表现。在微观层面,即策略收敛后的单次对局中,红方无人智能集群呈现协同对抗态势,如图10所示。攻击单元整体居中,在己方防御单元的防御保护下对处于己方探测单元探测视角内的敌方单元进行饱和攻击;防御单元居阵型前方,集中防御,保护己方攻击单元和探测单元;探测单元居阵型后方,向后退避、向前冲锋行为动态切换,为己方攻击单元提供探测视角的同时,最大化保证自身的生存。不同类型单元根据自身属性特点实现了行为协同、功能互补,同类型单元也呈现出明显的群集优势。

图10 红蓝无人集群攻防对抗仿真对局态势图Fig.10 Situation forattack-defense confrontation simulation of red and blue UVA swarms
3.2 无人集群对抗演示系统
为了直观展示红蓝双方集群对抗过程,设计了无人集群对抗实时演示系统,如图11所示。演示系统中针对无人集群攻防对抗任务场景设计了5个模块,其中实时攻防对抗态势演示模块位于演示面板中央,双方实时对抗过程以回合步为单位进行更新。攻防对抗双方实时胜率演示模块、攻防对抗双方实时有效进攻/防御数据位于演示面板左侧;双方各类型单元实时存活数、双方各类型单元实时总血量位于演示面板右侧;左右侧四大演示模块除攻防对抗双方实时胜率以对局为单位更新外均以回合步为单位更新。
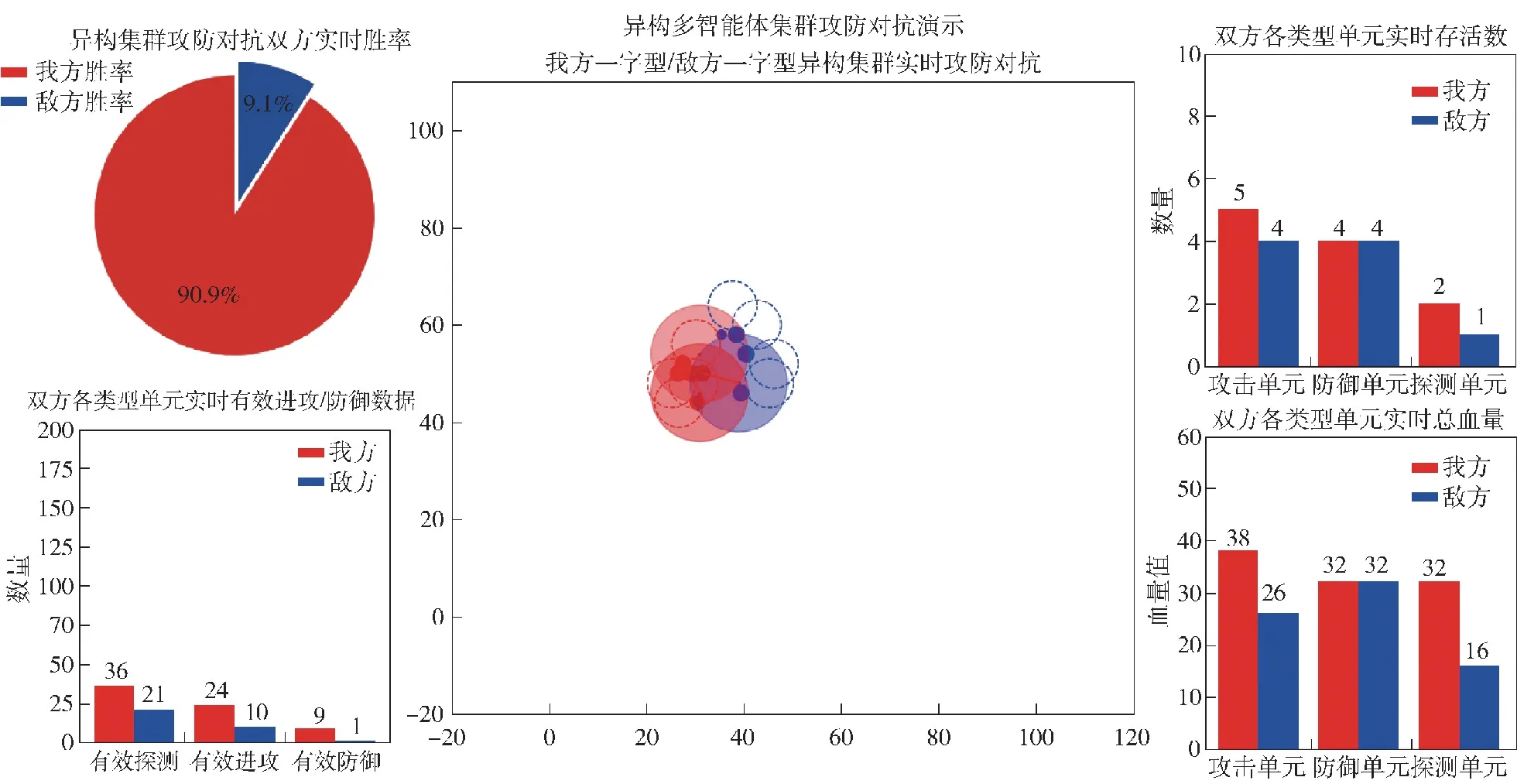
图11 无人集群攻防对抗任务场景演示面板Fig.11 Demonstration panel for attack-defense confrontation scenario of UVA swarms
4 结论
无人集群为无人系统与群体智能的结合,意图通过群体智能算法使多数量无人系统具备自组织能力并实现协同能力涌现。在这一过程中,强化学习技术被广泛采用,稀疏奖励问题广泛存在。本文构建了无人集群对抗模型框架,并以无人集群攻防对抗为具体场景进行了模型设计,通过分析奖励函数机理机制,设计了局部回报重塑方法,并叠加PER方法,最后进行了程序仿真与演示系统设计。经对比证明该方法有效提升了算法效率,后续将在以下方面展开进一步研究:
1)针对稀疏奖励问题,当前方法在智能性、泛化性、设计耗时方面具备提升空间,可进一步研究智能性更强、泛化性更好、设计耗时更短的稀疏奖励算法,促进强化学习技术从理论研究迈向工程应用。
2)当前研究关注自主决策算法,后续可对基于实际动力学模型及态势感知下的自主决策算法展开研究,进一步提升自主决策算法验证过程置信度。
