递归特征消除与极端随机树在铣刀磨损监测中的研究
2023-07-10刘献礼秦怡源岳彩旭魏旭东孙艳明郭斌
刘献礼,秦怡源,岳彩旭,魏旭东,孙艳明,郭斌
(哈尔滨理工大学 先进制造智能化技术教育部重点实验室,哈尔滨 150080)
在金属切削加工过程中,刀具的磨损状态对切屑形态的变化、工件表面质量有着重要的影响,因此刀具磨损一直以来是金属切削过程中普遍存在的问题[1-2]。为保证产品质量与生产效率,有必要对刀具磨损值进行准确监测。为此,诸多学者对刀具磨损的监测[3]问题展开了研究。
针对刀具磨损监测问题,目前较流行的解决方法是通过机器学习算法来建立模型。由于算法模型的输出结果与算法中选取的特征集关系密切,因此在训练算法模型之前先对原始数据集进行特征提取[4]。特征的类别有时域特征、频域特征和时频域特征等。Ou 等[5]通过对原始信号提取阶次特征,建立了SSAE 神经网络模型,实现了对刀具磨损状态的监测。Helmi 等[6]利用传感器采集数据,通过对数据集的时域、频域特征进行提取,实现了电机滚动轴承的故障检测。Junior 等[7]通过对振动信号频谱及时域特征进行分析,实现磨削过程的监测。
在特征提取的初始阶段,无法确定特征的类别对监测结果的影响程度。因此,要尽可能的从原始数据集中提取较多的特征,组成特征集。这将导致该特征集形成的数据矩阵[8]十分复杂,从而使得模型训练的时间大幅度增加。因此需要对提取的特征进行降维。常用的特征降维方式有主成分分析和特征选择两种。主成分分析是将高纬度的特征经过某种函数映射到低纬度作为新的特征。王二化和刘颉[9]利用主成分分析法对铣削振动信号的特征进行降维,再将其输入改进的BP 神经网络模型,实现了对微铣刀磨损的在线检测。特征选择是从高纬度的特征中选择其中的子集作为新的特征集,其方法有递归特征消除算法、离散二进制粒子群算法等。Chen等[10]通过递归特征消除和小波包变换实现了立铣刀颤振的检测。赵明利等[11]通过离散二进制粒子群算法与模糊支持向量机相结合建立模型,实现了对刀具磨损状态的识别。
特征降维后,选择合理的机器学习算法对提高刀具磨损的监测模型有着重要的作用。常用于刀具磨损监测的算法有K 近邻(K-nearest neighbor,KNN)、稀疏贝叶斯学习(Sparse bayesian learning,SBL)、随机森林(Random forest,RF)、支持向量机(Support vector machine,SVM)等。范云龙和陈劲杰[12]通过利用KNN 的相似分类特征,实现对刀具磨损的状态的识别。聂鹏等[13]根据声发射传感器、功率传感器采集信号和稀疏贝叶斯来建立模型,实现对刀具磨损量的预测。赵帅等[14]通过RF 建立电流传感器信号样本和刀具磨损等级的非映射关系,实现对刀具磨损的评估。Lyhuy[15]通过建立SVM 模型实现对刀具磨损状态的识别。
综上所述,本文利用加速度振动传感器、声发射传感器和三向测力仪采集铣削加工过程中的信号,经数据采集卡将信号转化为数据集,并提取数据集的时域特征和频域特征。考虑到数据信息较大、计算成本问题。通过特征选择的方式对特征集降维,利用递归特征消除(Recursive feature elimination,RFE)算法对提取的时域特征和频域特征进行选优,将选出的特征标准化处理。为提高模型准确度及避免陷入过拟合,文中选用极端随机树(Extra trees,ET)算法建立刀具磨损监测模型。ET 是一种集成算法无先验性并适用于大规模训练样本,解决了稀疏贝叶斯算法的先验性问题和SVM 不适用于大规模训练样本的问题。ET 算法具有特征随机、参数随机、模型随机、分裂随机的特性,因此解决了随机森林容易陷入过拟合的问题。并且该算法的训练过程可并行化、速度快,解决了KNN 算法效率较低的问题。本文基于RFE 和ET 提出一种刀具磨损监测方法能够准确地测出刀具磨损值,实现了在加工过程中,整个刀具寿命过程的磨损监测。
1 特征提取与降维
本文采用美国纽约预测与健康管理学会2010 年数控铣床刀具健康预测竞赛的开放数据集。该实验利用加速度振动传感器、声发射传感器和三向测力仪来完成原始数据集的采集和保存[16]。由于原始数据集中含有大量信息,不利于模型的建立。因此,本章节首先对原始数据集的时域特征和频域特征进行提取。为了进一步提高模型准确率、避免维数灾难。将通过特征选择的方式对特征集进行降维。
1.1 特征提取
如图1 所示,该实验分别采集铣削过程中x、y、z这3 个方向的铣削力信号与x、y、z这3 个方向铣削的振动信号,同时通过声发射传感器采集声发射信号,共采集7 种信号。通过数据采集卡将采集的信号转化为数据传到电脑端并保存。原始信号中含有的数据信息杂乱无章,为了便于训练模型,对采集的信号进行时域特征和频域特征[17]的提取。
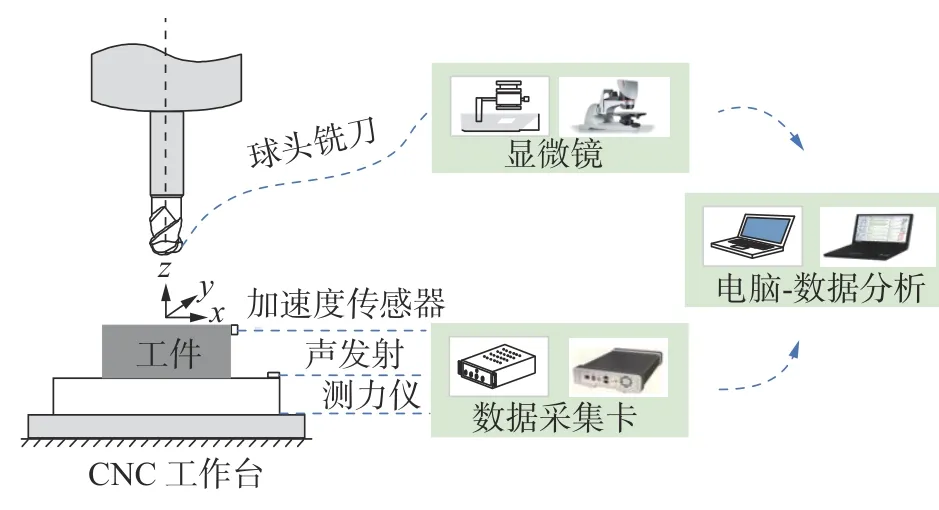
图1 刀具铣削多传感信号采集示意图
本文在时域中每种信号分别提取了13 种特征,分别为均值、均方根、根方差、波形因子、偏度系数、峰度、冲量因数、形状系数、峰值、峰值因子、脉冲因子、偏斜度值和峰度因子。其中x、y、z这3 个方向铣削振动信号和声发射信号所提取的冲量因数特征有明显缺陷,因此剔除所述的4 个特征。在频域中每种信号分别提取了10 种特征,分别为频谱均值、频率平均值、最大频率、频率均方根、根方差、最小频率、频率的峰度值、偏斜度、偏斜系数和频率的峰度因子。文中提取了157 个时域和频域特征。提取的某些数据特征之间具有较强的相关性。为了提高算法准确度,降低运算成本,将通过特征选择的方式来移除相关性较强的特征。
1.2 特征选择
考虑到模型训练的成本问题,同时为了避免监测模型产生过拟合现象。对提取出来的157 个特征进行选优,首先通过基于交叉验证的递归特征消除(Recursive feature elimination cross validation,RFECV)来确定所选特征的最佳数量。其次利用RFE 算法来对特征集进行排序。最终选出所需要的特征子集。
RFE 是最流行的特征选择方法之一[18],通过RFE 可将提取的时域特征和频域特征进行排序,从而选出最优的特征用于训练监测模型,能够大大降低复杂性,方便计算。RFE 算法原理是利用一个基模型来进行多轮训练,每轮训练完成之后去除多个权值系数的特征。将剩下的特征组成一个新的特征集合,再基于新的特征集进行下一轮训练。如此对该过程进行迭代训练,直至找到对磨损值影响最大的数据特征。
1.2.1 确定最佳特征个数
本小节将通过RFECV 来确定所选特征的最佳个数。在RFE 算法中采用不同的基模型,最终所得到的特征集是不同的。本文分别采用逻辑回归(Logistic regression,LR)、分类与回归树(Classification and regression tree,CART)、线性回归(Linear regression,LR)、线性判别分析(Linear discriminant analysis,LDA)这4 种算法作为RFE 的基模型进行特征选择(注:为区分逻辑回归与线性回归缩写,将逻辑回归的缩写记为LR1,线性回归的缩写记为LR2)。因此,得到相应的4 组数量不同的最优特征子集。每组特征个数及评分如图2 所示。

图2 特征数量评分
由图2 可得,基模型为LR1 的RFE 算法其特征数量为5 时得分最高,在其数量超过20 时,得分趋势趋向于平稳。尤其是特征个数超过100 后,得分不再变化。因此,可确定LR1-RFE 所选出的最佳特征数量为5。基模型为CART 的RFE 算法其特征数量为9 时得分最高,特征数量超过9 以后,得分的总体趋势下降。从而确定CART-RFE 最佳特征数量为9。基模型为LR2 的RFR 算法的最佳特征数量为153。特征数量越多时,基模型为LDA 的RFE 算法评分越高。因此,LDA-RFE 最佳特征数量为157。各组所得最佳特征数量如表1 所示。

表1 每组最佳特征数量
1.2.2 特征排序与选取
本节在确定每组最佳特征数量的基础上,对特征进行排序并确定每组所选取的特征。特征排序结果如表2 所示(其中:V为振动信号;F为力信号;AE为声发射信号;x、y、z为方向)。

表2 特征排序
根据表2 可知,采用不同基模型的RFE 算法所得到的特征排名是不同的。LR1-RFE 算法最佳特征数量为5,因此取频率平均值(Vy)、频率平均值(AE)、频率平均值(Fy)、频率平均值(Vx)等排名前五的特征作为最优特征。同理,可得到其余3 组的最优特征,其中基于LR1-RFE 获得的特征子集记为FD1,基于CART-RFE、LR2-RFE 和LDA-RFE获得的特征子集分别记为FD2、FD3 和FD4。
2 RFE 和ET 相结合的监测模型
本章节首先确定极端随机树(ET)算法中的决策树数量,简述ET 算法的流程。并针对数控铣床刀具磨损监测问题,对提出的基于RFE 和ET 模型工作流程进行详细叙述。
2.1 极端随机树(ET)
极端随机树是一种集成算法,由众多决策树构成,与随机森林十分相似。不同的是随机森林属于Bagging 模型,并且随机森林的最优分叉特征属性是在子集内随机得到的。ET 算法的分叉特征属性是完全随机获取的,并非是在子集内得到的,因此不会有过拟合现象的产生。ET 算法内的每一棵决策树所用的训练样本包含了所有的数据样本。理论上讲,该算法内的决策树数量越多,其分类准确率越高。但是决策树数量超出一定程度时会增加计算时间。为有效降低计算成本,且保证模型准确率。本文将采用网格搜索优化参数方法来确定决策树的数量,其结果如表3 所示。
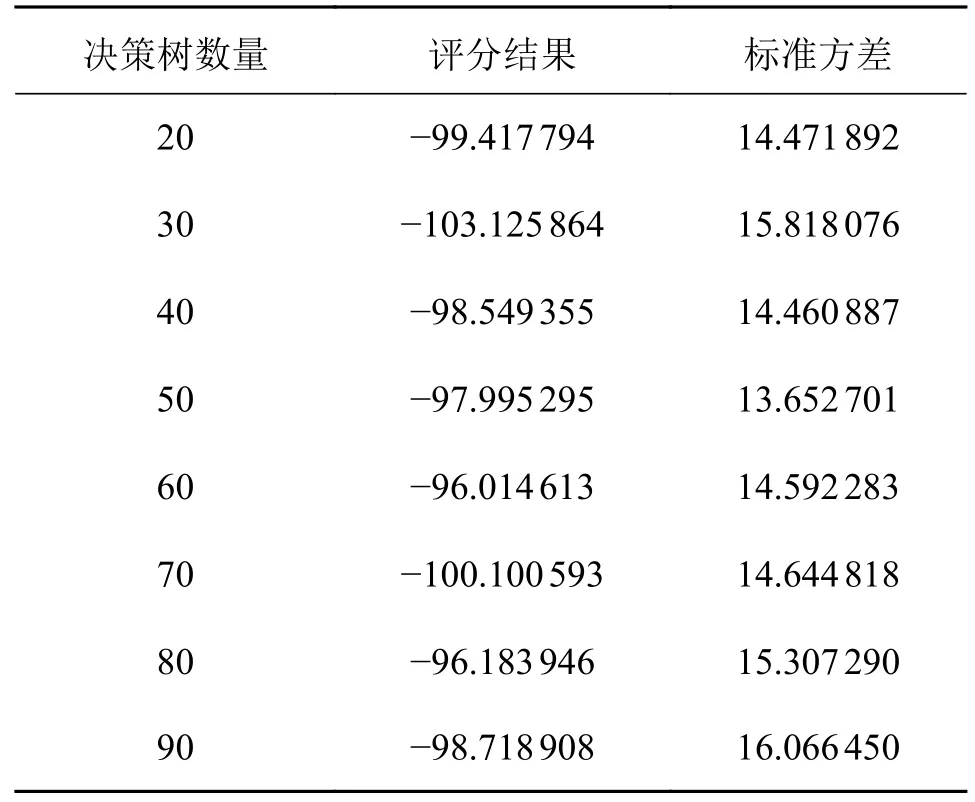
表3 决策树数量评分
如表3 所示,评分结果越高说明ET 算法模型越好。可看出决策树的数量为60 时得分最高,因此,确定了ET 算法中决策树的数量为60。
ET 算法可表示为{T(C,X,D)},其中T为分类器模型,C为基分类器的数量,X为输入样本,D为样本数据集。文中选用得决策树数量为60,所以同一种输出值会出现60 个结果,然后针对每个结果进行投票,最终选取最优的结果进行输出。其流程如下:
1)将数据集D分离,67%数据用于训练记为TD,33%数据用于测试记为SD,将其导入决策树模型,使用全部的TD 对每棵决策树进行独立训练。使用python 语言完成模型训练过程。
2)根据CART 算法生成决策树。在生成模型的过程中,随机从特征集中选取n个子特征用于节点分裂。通过计算信息增益,选出每个节点的最优属性并进行分裂,根据分裂产生的子集再选出最优属性进行分裂,直至决策树生成。
3)将步骤1)和步骤2)循环执行C次,生成C棵决策树和极端随机树。
4)使用建立的模型对样本SD 进行预测,生成预测结果。
2.2 CART-RFE 和ET 监测模型构建
本文提出了一种将RFE 与ET 算法相结合的方法,实现对刀具磨损的有效监测,其流程如图3 所示。首先对振动传感器、声发射传感器和三向测力仪采集的原始信号进行截断处理,通过截断法剔除了每次进刀和退刀过程中形成的无效数据。提取切削过程中平稳信号的时域特征和频域特征。其次将3 把铣刀的157 个特征与对应的磨损值m组成数据集A。将数据集A分离,其中67%作为训练集,33%作为测试集,并采用不同的基模型对RFE 模型开始训练。通过RFE 算法剔除对磨损值m影响较小的特征。对该过程进行迭代,直至每组选出3 个最优的特征。最终将每组选出最优特征与磨损值m分别组成数据集B、数据集C、数据集D、数据集E。将数据集B、C、D、E做标准化处理并进行分离,仍将67%作为训练集,33%作为测试集,将训练集输入到ET 模型中完成训练。采用如表3 所示的10 折交叉验证对模型评估,结果表明:基于CART-RFE 和ET 模型评分最高。因此选用该模型能够准确地输出预测值M。
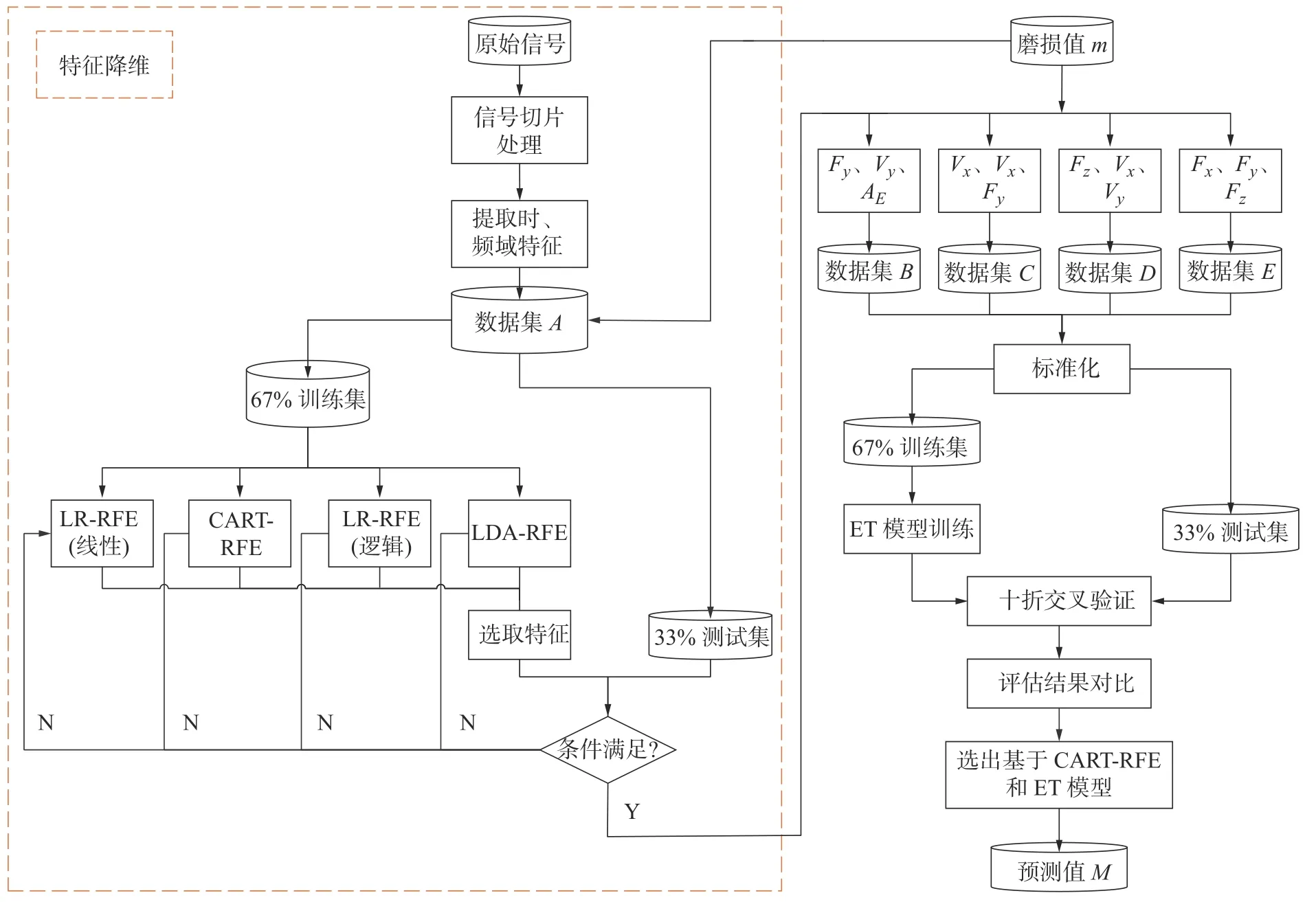
图3 CART-RFE 和ET 模型流程图
3 实验及结果分析
3.1 实验数据
该实验采用的数控铣床主轴转速为10 400 r/min、进给速度为1 555 mm/min、y轴向切削深度(径向)为0.125 mm、z轴向切削深度为0.2 mm。通过kistler 9265B 三向测力仪、加速度振动传感器和声发射传感器采集信号,采样频率为50 kHz,并通过数据采集卡将信号转化为数据传输到电脑端。采集刀具的进给方向x、主轴径向y、主轴轴向z这3 个方向铣削力信号、振动信号及声发射信号,共采集7 组信号。实验对C1、C2、C3、C4、C5、C6 这6 把铣刀进行全寿命周期试验,每把铣刀切削了315 次。使用LEICA MZ12 显微镜对C1、C4、C6 这3 把铣刀的后刀面磨损值进行测量,取每把铣刀3 个切削刃磨损量均值作为刀具磨损结果。实验中特征的提取和模型的建立均是使用python 语言在pycharm 平台上完成的。
3.2 模型训练与拟合
本文选用C1、C4、作为训练集,C6 作为测试集。将选出的4 组最佳特征集分别用于KNN、支持向量回归(Support vector regression,SVC)和ET 算法模型的训练,得出刀具磨损拟合曲线,如图4~ 图7所示。

图4 基于LR1-RFE 分别和3 种算法结合的刀具磨损拟合曲线图
由图4 可看出,LR1-RFE 和ET 相结合模型拟合度最高,达到96.67%。而LR1-RFE 和KNN 相结合与LR1-RFE 和SVC 相结合模型的拟合度分别为95.38%、91.93%。说明用特征集FD1 训练模型时,选用ET 算法建立模型准确度较好。根据图5得出,当选用特征子集FD2 来训练模型时,3 种模型的拟合度明显上升。图5a)~图5c)的拟合度分别为99.33%、96.17%和99.74%。此时,选用ET 算法建立模型的拟合度依然是最高的。在图6 中,LR2-RFE 和SVC 相结合模型的拟合度明显提升,达到98.72%。而LR2-RFE 和KNN 相结合模型的拟合度为99.02%,下降了0.31 个百分点。LR2-RFE 和ET 相结合模型的拟合度为99.82%有微弱的提升。相较于图6,图7 中,LDA-RFE 和ET 相结合模型的拟合度明显下降,其拟合度为98.51%,下降了1.31%。LDA-RFE 和KNN 相结合 与LDA-RFE 和SVC 相结合模型的拟合度基本没有浮动。
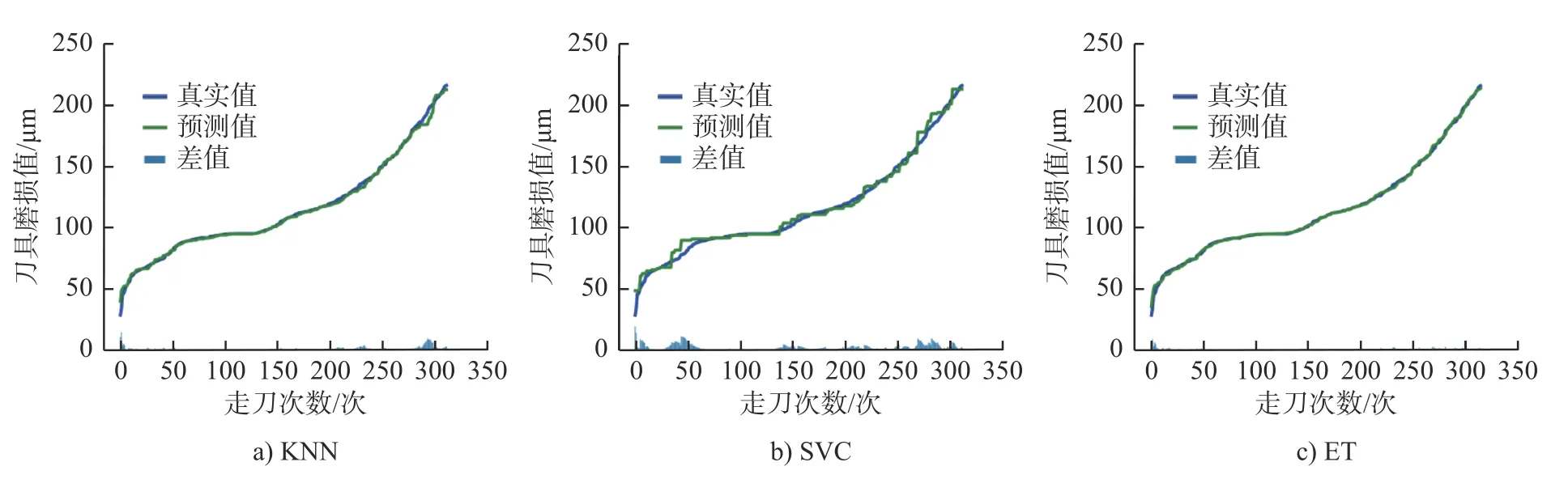
图5 基于CART-RFE 分别和3 种算法结合的刀具磨损拟合曲线图

图6 基于LR2-RFE 分别和3 种算法结合的刀具磨损拟合曲线图
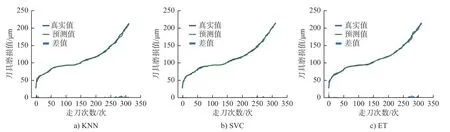
图7 基于LDA-RFE 分别和3 种算法结合的刀具磨损拟合曲线图
3.3 结果分析
通过K 折交叉验证对3 种模型进行评估,其结果的标准差以及训练3 种模型所采用的特征集、对应模型的拟合度等详细数据如表4 所示。

表4 模型拟合度(评估结果的标准差)
根据表4 可得。特征个数越多,RFE 和SVC 相结合模型拟合度与评估结果的标准差越优。说明选用LDA 作为RFE 的基模型时,该模型准确度最高。但LDA-RFE 筛选出的最佳特征集包含了157 个特征,形成的数据矩阵较为复杂,不利于模型训练,并且容易产生过拟合现象。因此,不考虑将该模型用于刀具磨损的监测。对于RFE 和KNN 相结合模型,其拟合度最高和评估结果的标准差最低时,是选用特征集FD2 训练该模型。但同等条件下,RFE 和ET 相结合模型的拟合度及模型评估结果的标准差明显优于RFE 和KNN 相结合模型。由表4最后一列数据可看出,RFE 和ET 相结合模型整体拟合度较好且性能平稳。
不同基模型的RFE 和ET 相结合,最终得到的拟合度和评估结果的标准差是不同的。选用LR2作为RFE 的基模型时,此时RFE 和ET 相结合模型的拟合度和评估结果的标准差是最优。但该模型训练时所用的特征数量达到153 个,导致了模型训练时间和成本上升。而RFE 的基模型为CART 时,模型训练所用的特征数量为9,特征维度大幅度降低,恰好解决模型训练时间和成本问题,并且防止了过拟合现象的产生。CART-RFE 和ET 相结合模型的拟合度达到99.74%。与LR2-RFE 和ET 相结合模型相比该模型的拟合度下降了0.08%。其评估结果的标准差低了1.28。总体来说这种影响可忽略不计。
综上所述,本文提出的CART-RFE 和ET 相结合模型能够准确地测出刀具磨损值。解决了数据维度高、计算时间长等问题,同时避免了过拟合现象的产生。在金属铣削过程中具有良好的应用前景。
4 结论
1)本文针对刀具磨损监测问题,建立了基于CART-RFE 和ET 的刀具磨损监测模型。分别采用逻辑回归、分类与回归树、线性回归、线性判别分析作为递归特征消除算法的基模型,对提取的时域特征和频域特征进行降维。解决了样本数据量大、复杂性高、计算成本高等问题。
2)将选出来的4 组最佳特征集标准化,并分别将其分离为训练集和测试集,使用训练集分别完成不同算法模型的训练。通过K 折交叉验证法对完成训练的模型进行评估,保证每个特征子集参与训练且被测试,降低了泛化误差。
3)通过对比分析拟合曲线图和评估结果的标准差,表明CART-RFE 和ET 相结合模型准确度高且性能平稳。可为金属铣削过程中刀具磨损的监测提供科学合理的技术支持。
