大数据DAG任务流调度平台技术研究与应用
2023-07-10许佳裕


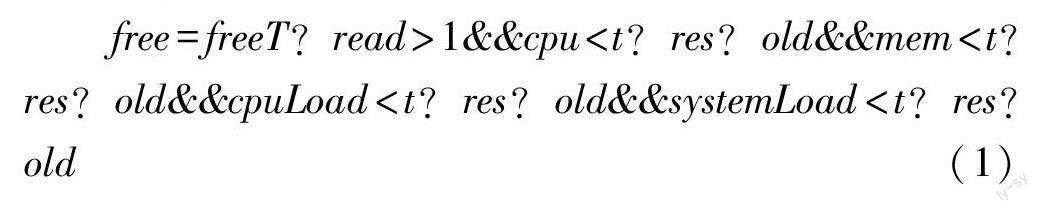
关键词:大数据;DAG有向无环图;调度平台
中图法分类号:TP301 文献标识码:A
1引言
大型商业运营阶段生产的数据类型大多是传统的结构化数据。这些数据基本属于隐私性和安全性等级十分高的贸易、商业、物流,以及保险、股票等传统支撑行业数据。而互联网时代出现的数据类型大多属于非结构化的社交网络数据、电子商务交易数据、图片定位数据,以及商业智能报表、卫星遥感数据、监控录像等非结构化和二维码像素数据。因此,研究大数据任务流调度平台,对于企业内部自建大数据量的实时/离线同步、处理、清洗、治理、流程化、持久化等任务流程,具有重要的成本与运营意义。
2研究现状
此前,传统技术任务调度系统大多是侵入式调度,即需要依赖框架,若将框架拿掉或者换一个框架,则需要重新进行修改,同时部分调度系统虽然为非侵入式,但其机制的设计不足以承担大数据时代数据的变化速度,不适应企业高速发展所需要的弹性、可定制性、独立性。现有的系统和技术已经无法解决当前大数据背景下企业数据量暴增的问题。
3大数据DAG任务流调度平台架构设计
本文详细阐述了大数据DAG任务流调度平台方案,即大数据DAG任务流调度平台技术研究与应用。整体架构设计如图1所示。
该框架在设计上充分考虑了大数据场景,利用去中心化的架构,构建整个调度集群,基于DAG有向无环图,构建整个任务流程体系,核心是使企业实时/离线大数据处理流程更加简易化,各组件模块相互协作共同为此服务。其中用到的关键技术点将展开一一讨论。
3.1协议设计
首先,需要进行通信协议设计,传统的http协议不满足需求,我们需要高效、稳定的通信协议,以解决通信中丢包、粘包、断线重连、消息重发等问题。其次,进行具体的通信协议设计,协议头为15个字节。
该协议保障了传输的稳定性和可扩展性,Proto flag保障协议不被篡改,Real body size和Body size保证拆包、粘包、压缩、加密的处理,Encrypt Flag可支持自定义协议加密算法等。
3.2任务引擎设计
首先需要说明任务引擎在整个架构里面的必要性和重要性,任务引擎为一个单位,可由不同程序不同模塊组成,甚至不同开发语言组成,这种架构所设计的任务引擎具备很强的扩展性和隔离性,如何建立它们之间的关系,是一个难题。其次探讨任务引擎通信的设计,即如何做到不同结构任务引擎之间的关联。
每个任务引擎都有对外握手机制(输入和输出),要实现这一特性,必须定义任务引擎标准,每个任务引擎必须具备引擎名称、输入标准、输出标准等标准信息,才能建立握手机制。之后,引擎之间就具备了信息交换、信息解析的能力,以使用Java语言编写的sql引擎为例讲解标准的定义,sql引擎应具备接收数据源并且执行动作的能力。
3.3任务引擎热加载机制
用户可以进行一个任务引擎(新引擎或迭代引擎)的上传,当上传到worker时,worker会将用户上传的任务引擎做一致性校验( md5/hash).如发现此次上传的引擎较旧引擎无变化,就不进行处理,如有变化,则worker会将旧引擎(oldEngine)标记为删除状态,将指针指向新引擎(newEngine),确保下一次任务使用新引擎,正在执行的旧引擎会在它所有任务完成之后,从标记删除变为物理删除。
3.4 DAG结构
调度系统需要使用DAG(有向无环图)结构,一般情况下,任务都是孤立的,任务之间也无关联性可言,这样的任务调度系统使用场景有限,因此无法实现任务顺序性、任务关联性、任务流程控制等,如何建立任务之间的关系,是一个难题。基于DAG结构设计的任务流程,可以实现整个任务流程体系。
如图2所示,总共有9个任务,每个任务都有关联性和顺序性,保证整个流程任务执行的正确性是关键。
通过图2可以看到,需要1个节点( node)代表任务本身,每个节点存在多条边(edge),每条边存在前后2个节点(beforeNode,afterNode)。
整体执行顺序如图3所示。
3.5资源介质机制
任务引擎除了需要具备握手机制,还要保障其独立性和可扩展性。例如,某个引擎需要以文件内容为输入进行解析,这时引擎如果要获取这个文件,难度较大、效率较低,因为不知道这个文件来源于哪里,此时需要有“人”帮任务引擎准备好它所需要的“物资”,针对这种情况,我们提出资源介质的概念。
用户通过介质人口进行资源上传,用户不用关心当前上传的资源是什么类型的介质,统一上传到调度平台,由调度平台的资源介质中心进行管理分类等操作,当任务引擎需要资源时,通过资源介质出口到各个任务引擎,并自动帮任务引擎准备好这些资源。同样,任务引擎也不关心当前的资源介质,直接使用即可。
3.6调度算法
本文实现的调度算法基于动态负载均衡算法的变种,并基于几个指标来做决定,即内存、cpu、任务数、线程数、系统负载、cpu负载,判断当前是否可以进行调度,最终实现的计算式为:
其中,各字段的含义为ree为最终确定是否空闲可调度标志free Thread为当前系统空闲线程,cpu为cpu使用率,threshold为可配置阈值,mem为系统内存占用,cpuLoad为系统cpu负载程度,systemLoad为系统整体负载程度。
当freeThread大于1,cpu小于threshold,mem小于threshold,cpuLoad小于threshold,systemLoad小于threshold时,ree即为true,空闲状态,可接受任务调度。
其中,cpu负载获取算法为:
主要通过统计cpu rq上task处于runnable的平均时间。同时,根据不同周期,统计出不同的k线。其中,oldLoad为旧负载,newLoad为负载
系统负载获取算法为(1分钟):
其中,old为旧负载,EXPi为l/exp(5 sec/1 min)固定点,FIXEDi为1《11固定点,new为新计算的负载。
至于5分钟和15分钟的计算,将式(4)中的EXP1换成EXP5/EXP15即可。
3.7回调机制
调度系统回调机制十分重要。一般情况下,任务执行完成后,需要通知任务发起者,告诉它任务成功还是失败,面对这种情况,侵入式调度可以很好實现这一特性,调用当前空间用户定义的回调函数即可,但介于侵入式扩展性问题,我们需要设计一个新的调度回调机制。
我们将解决以下问题:各个业务系统回调方式不一致,回调失败的处理,回调性能。
为了让回调机制不受限于某种类型,与业务系统剥离,我们设计了1个统一注册回调接口,回调方式以插件形式注册,支持更多回调方式进行扩展,让用户无需关注回调实现,只需要提交任务时进行注册回调逻辑,设计如下:用户先自定义回调逻辑处理,然后提交任务,等待调度平台任务执行成功或失败,任务执行结束后会通过回调机制进行回调,回调失败会进行重试,整个回调过程为异步操作,保证不阻塞业务,重试会有次数限制,当达到对应次数后,会等待一段时间进行重试。
3.8信号机制
任务引擎会定义1个信号处理函数(标准),该处理函数处理当前任务引擎需要释放的资源,然后一般就做结束进程exit处理,当用户触发停止任务.worker会发送1个中断信号,系统空间会因当前进程信号中断而调用系统内核函数do_signal()、handle_signal()(linux),转向任务引擎空间的信号处理函数(windows为SetConsoleCtrlHandler).此时任务引擎进行善后工作,信号处理函数结束后调用sigreturn()进行系统空间内核善后工作,再返回任务引擎空间继续执行中断前逻辑。
4效果评价
按照上文所述的大数据DAG任务流调度平台方案,我们进行了编码实现,主要分为用户端流程任务配置、大数据端dag流程任务调度、任务进度、任务日志追溯等功能,这里采用的是B/S前后端分离,去中心化架构模式,通过集群负载均衡的方式,支持超大数据的任务调度,并支持任务引擎动态扩展,处理大数据处理过程中非常复杂的任务依赖关系,致力于实现在离线、实时超大量任务流程中的高性能调度和稳定性。另外,我们还实现了告警和消息通知机制,能在任务异常时,及时告知、处理,以挽回损失。
依托大数据DAG流程调度运行过程的示例,流程配置采用非常简单的拖拽配置方式,任务执行过程能按照顺序执行,并且整个执行过程日志均有记录,每个任务引擎也有自己的输入/输出标准,同时能拿到前置任务的输出。整个平台对使用人员而言非常人性化,只需在界面进行配置,任务将会以预期的结果运行。
综合来看,本文研究的大数据DAG任务流调度平台凭借其全方位、高扩展、高性能的架构设计,足以胜任企业内部自建大数据量的实时/离线同步、处理等任务流程,大大提高了整体数据处理、任务调度能力。
5结束语
本文设计并实现了一套大数据DAG任务流调度平台,并通过各个环节的设计,将高性能和高扩展发挥极致,随着互联网的发展,有效解决了企业在现代数字化建设中,将新旧数据(通常为超大数据)处理整合并持续性扩充的难题,通过多维度构建起全方位的调度平台,提高企业经营效率,节约大量人力,减少了企业在数据暴涨时代维护数据的投入。
作者简介:
许佳裕(1993—),大专,助理工程师,研究方向:大数据任务调度、数据清洗、框架设计建设、Lmux内核。
