基于特征值变化的工业过程实时故障检测
2023-07-07郭金玉赵文君
郭金玉 赵文君 李 元
(沈阳化工大学信息工程学院 辽宁 沈阳 110142)
0 引 言
在过程和制造业中,随着现代制造业的快速发展,高质量产品合格率的要求越来越高,保证系统的正常运行成为一项至关重要的任务。虽然操作过程中的标准控制器可以补偿过程中发生的多种干扰,但也存在控制器无法充分处理的变化。由于新仪器和通信技术的发明,可以从工厂装置中收集大量的过程实时数据,从而通过监测收集到的数据来识别过程中的异常情况。因此,多元统计过程监测(Multivariate Statistical Process Monitoring,MSPM)方法[1-3]在过去几十年中得到了发展。
在MSPM方法中,主成分分析[4-6](Principal Component Analysis,PCA)是应用最广泛的一种。它通过构造原始数据最大方差的低空间来压缩数据,然后将监测数据投影到该空间以捕获偏差进行过程监测。与PCA相比,核主元分析(KPCA)可以处理非线性系统[7-10]。它基于核函数原理,通过非线性映射将输入空间投影到高维特征空间,然后在高维空间中对映射数据进行主成分分析进而进行过程监测。但是传统KPCA本身方法的不足,阻碍了对过程数据变化的观察,且由KPCA模型生成的特征值矩阵没有得到足够的重视,如何从动态过程中有效地获取重要信息还需要进一步研究。KPCA通过奇异值分解(Singular Value Decomposition,SVD)对数据进行分解,然后生成特征矩阵,即特征向量和特征值,以表示建模数据的特征,实现对非线性数据降维,剔除变量间的主要相关性,并将新的数据投影到新的空间进行主元分析。从KPCA模型来看,过程数据之间的相关性是由SVD计算的,生成一个负载矩阵和一个对角矩阵。负载矩阵中的列表示从原始空间到新空间的变换方向,而对角矩阵的特征值表示相应的变换尺度。这两个特征矩阵结构简单,包含大量的数据信息,基于这两个矩阵的变化,提出一些过程监控方法。Kano等[11]根据特征值评估差异性提出了一种称为DISSIM的统计监测方法,但他们建立的监测计算公式,难以确定被测个数。基于相似性Johannesmeyer等[12]提出将snapshopt数据与分割的历史数据进行比较,进而对数据进行监测,但是比较对象是T2和Q统计量,它们的计算量比特征矩阵大。
在最近的研究中,实时过程监控在故障检测方面十分重要,这使得在运行期间可以立即识别和纠正故障。Liu等[13]提出了基于时变过程新数据与历史数据的差异性来更新偏最小二乘(PLS)模型的参数。Rashid等[14]利用多维互信息(Multidimensional Mutual Information,MMI)和滑动窗口集成独立分量分析(Independent Component Analysis,ICA),提取非高斯过程特征,增强动态过程监控。Jiang等[15]提出使用核密度估计(Kernel Density Estimation,KDE)来评估ICA模型中各独立分量的重要性,使动态过程中的偏差信息得以突出,称为KDE-DWICA。Yin等[16]提出了一种迭代优化方法来提高系统性能。许多策略被用于增加在线信息的访问,但最广泛使用的是滑动窗口(Moving Window,MW)策略[17-19]。这种策略是一种递归技术,它构建以前的模型,而不是从原始数据构建,它是及时准确地从在线操作过程中获取信息的有效工具。然而,由于控制回路的补偿,MW中的数据趋势将再次趋于平缓,故障信息将被覆盖,因此,MW用于数据采集的方式需要改进。由于过程数据反映了操作系统的状态,过程数据的变化必然反映了监控过程的变化。基于这一思想,本文提出一种基于核主元分析模型所产生的特征值变化的过程监控统计量。与Kano等提出的方法不同,特征矩阵的变化是基于其元素分布的变化来测量的,而且,过程中扰动的开始和结束时间也不是先验的。为了获得数据特征的实时信息,KPCA模型在每一点都进行更新,并收集操作过程中的数据。针对上述问题,本文采用同时包含实时数据和正常数据的组合滑动窗口(Combined Moving Window,CMW)来采集数据,对KPCA进行在线建模,以区分故障数据和正常数据。因此,产生了基于监测特征值变化(Monitors the Variation of Eigenvalues,MVE)的监测统计量进行故障检测。
1 基于组合滑动窗口KPCA工业过程故障检测
1.1 KPCA算法
设X是m×n维数据矩阵,其中:n为样本数;m为变量数。KPCA假设存在一非线性函数φ,用其将矩阵X=[x1,x2,…,xn]∈Rm×n中的向量x映射到高维空间中,从而得到一个新矩阵φ(x)=[φ(x1),φ(x2),…,φ(xn)]∈Rm×v(v>>n)。其中高维空间称为特征空间(Feature space),记为μ。首先对μ中的矩阵φ(x)m×n进行主元分析,假设已对φ(x)进行预处理,即:
(1)
则μ中映射矩阵的协方差矩阵为:
(2)
对特征空间中的协方差矩阵进行特征向量分析,即:
CμP=λP
(3)
式中:λ为协方差矩阵Cμ的特征值;P是特征值对应的特征向量。即
(4)
式中:α=(α1,α2,…,αn),αi为核函数矩阵K的第i个特征向量。
式(3)两边同乘[φ(X)]T可转化为:
[φ(X)]Tφ(X)[φ(X)]Tφ(X)α=λ[φ(X)]Tφ(X)α
(5)
记K=[φ(X)]Tφ(X),式(4)两边同除K可转化为:
Kα=λα
(6)
本文运用高斯核(Gaussian kernel)来计算核矩阵K。
通过KPCA将新来的样本xnew在特征空间中线性表示,即:
(φ(X)α)Tφ(xnew)=αTφ(X)φ(Xnew)=
[α1,α2,…,αn][k(x1,xnew),k(x2,xnew),…,
k(xn,xnew)]T
(7)
然后,采用SPE和T2统计指标用于监视残差空间和主元子空间的变化。
1.2 组合滑动窗口
在实践中,通过控制回路操作系统进行补偿,使异常数据经过一段时间的故障发生后达到一个新的水平。如图1所示,当第一个故障点发生故障时(180点为第一故障点),MW2(180点至380点为滑动窗口2)还可以发现数据的波动,但在400点以后,该变量偏离了原来的范围,而在MW3(600点至800点为滑动窗口3)中则表现出稳定的状态。因此,MW3不能表示数据的偏差。针对这一缺点,本文研究组合移动窗口策略来区分正常数据和故障数据。首先选择一些正常的数据作为基准数据,将其放入窗口中,以识别在线数据的状态。然后利用组合滑动窗口中采集的数据构建实时模型,从生成的特征矩阵中提取变化信息用于监测。
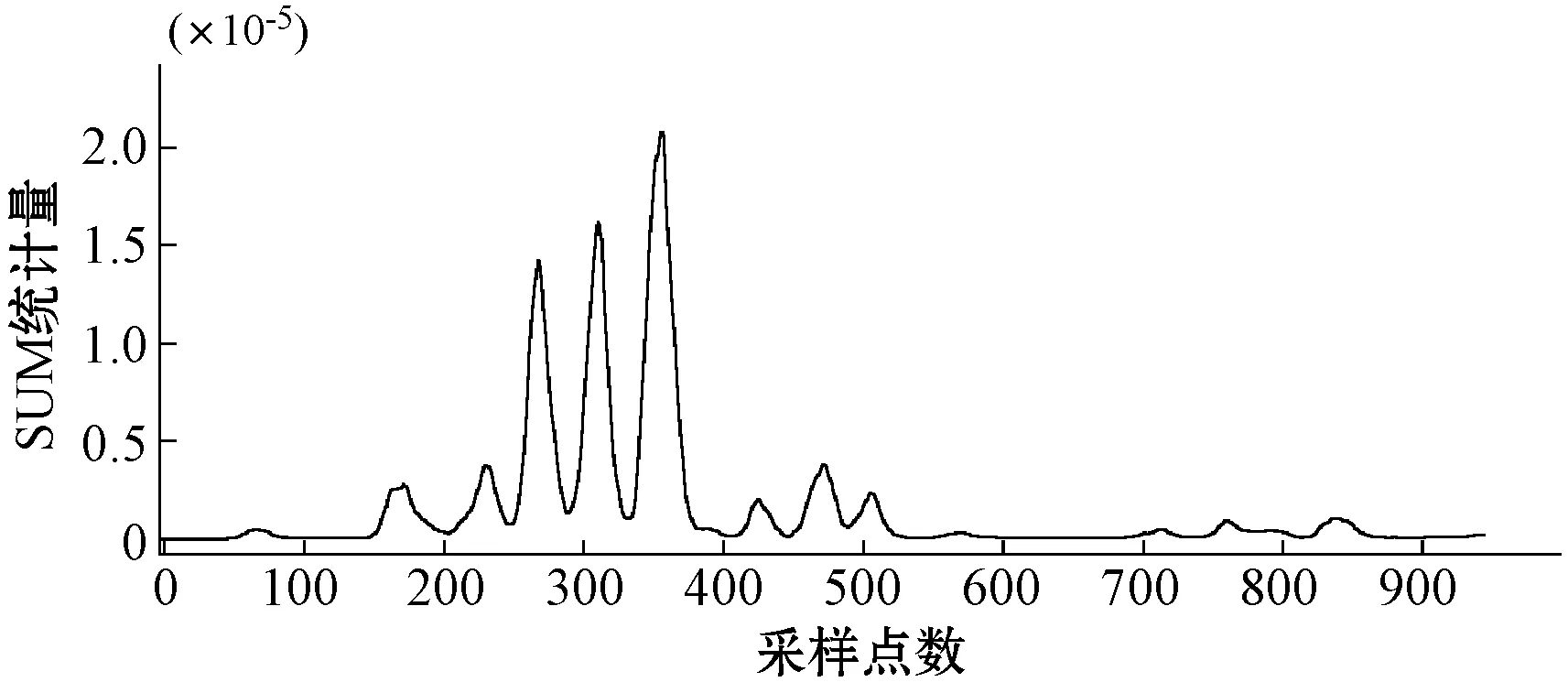
图1 不同时间窗口收集数据的情况
在目前的工作中,CMW中基准数据和监控数据的大小或多或少会对监控结果产生影响。此外,所选负载向量的数量也会影响监控性能。因此,这里讨论了组合窗口大小设置的影响。选取TE过程的8个不同的故障类型进行测试。第一个讨论是关于CMW的大小和基准数据与监测数据的数量选取问题。设置了几个不同的值,表1中列出了相应的监视结果,其中用粗体突出显示了显著改进的监视结果。可以看出,传统的MW,即CMW的基准数据为零,在捕获大部分类型故障的数据特征变化方面存在困难,导致部分类型故障的故障检测率较低,在CMW中保留一些正常数据就可以解决这个问题。同时,监测数据数量和基准数据的设置也会影响监测结果。当基准数据的数量远远大于被监控数据的数量时,就会隐藏被监控数据的变化,从而导致监控性能下降。此外,从表1可以看出,CMW大小的选择对监控性能影响不大。综合考虑,本文将CMW设定为60个样本,其中:15个样本为基准数据;45个样本为当前研究的监测数据。
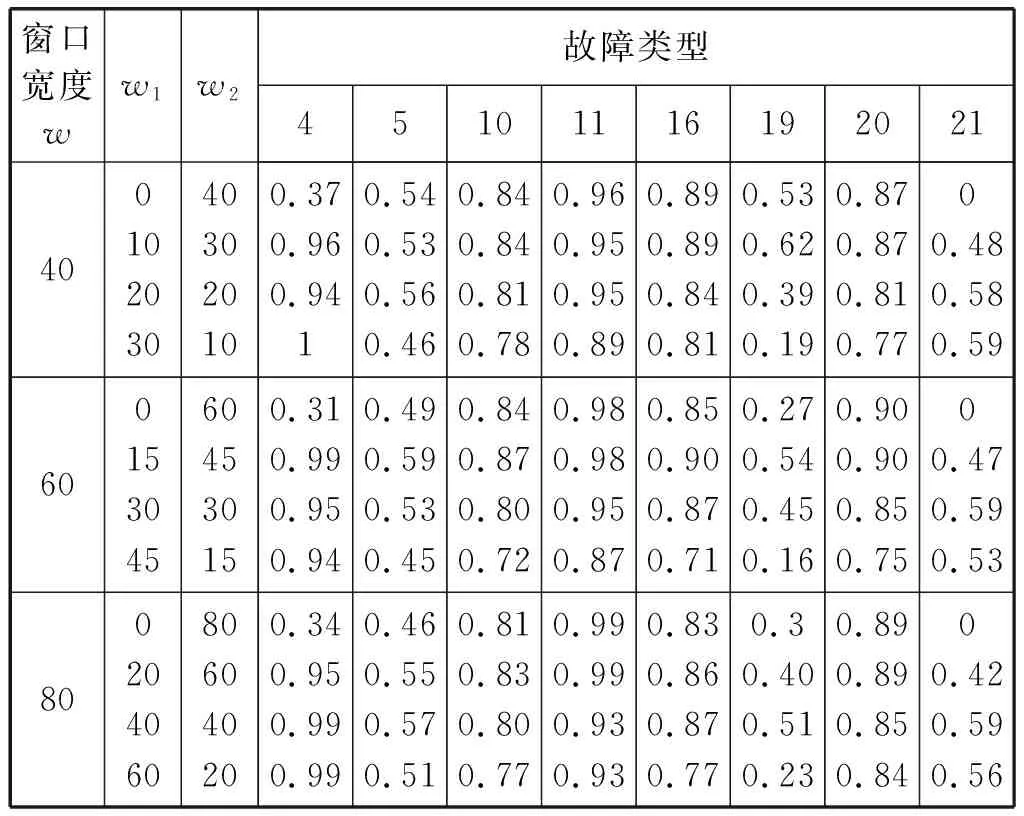
表1 CMW中不同宽度尺寸、不同基准数据与监测数据比值的故障检测率
1.3 基于特征值变化监测统计量的构造
在概率论和统计学中,方差衡量一组数据的分散程度。当数据集中的所有值都相同时,方差为零。相反,当数据散布在均值周围,并且彼此之间存在差异时,就会产生很大的方差。对于KPCA模型,其本质是将低维输入空间中变量之间的非线性关系通过非线性函数映射到高维空间,然后在高维空间中进行PCA,计算建模数据的最大方差。PCA通过SVD分解生成负载矩阵P和对角矩阵Λ。P负责旋转主轴,而对角矩阵Λ中的特征值负责将生成的向量在新构造的空间中标准差缩放为1,当建模数据从聚集状态变为分散状态时,所产生的特征值和特征向量必然是不同的。将这一规律应用到实时建模中,一旦过程中出现故障,工艺数据就会偏离原来的分布区域。如果用这些错误的数据建模,生成的负载矩阵P和对角矩阵Λ将没有意义。为了进一步说明,一个简单的数值例子如下:
(8)
式中:[r1,r2]T服从高斯分布,均值为0,标准差为5;[e1,e2]T服从均值为0、标准差为1的正态分布。共采集了200个样本(正常数据),且生成一个模拟故障案例:从第101个样本到最后,x2增加了0.5×(i-100)的斜坡变化,其中i是采样时刻。
首先,将正常数据和故障数据以均值为零进行缩放,将缩放后的正常数据和故障数据的分布图进行对比,如图2所示。
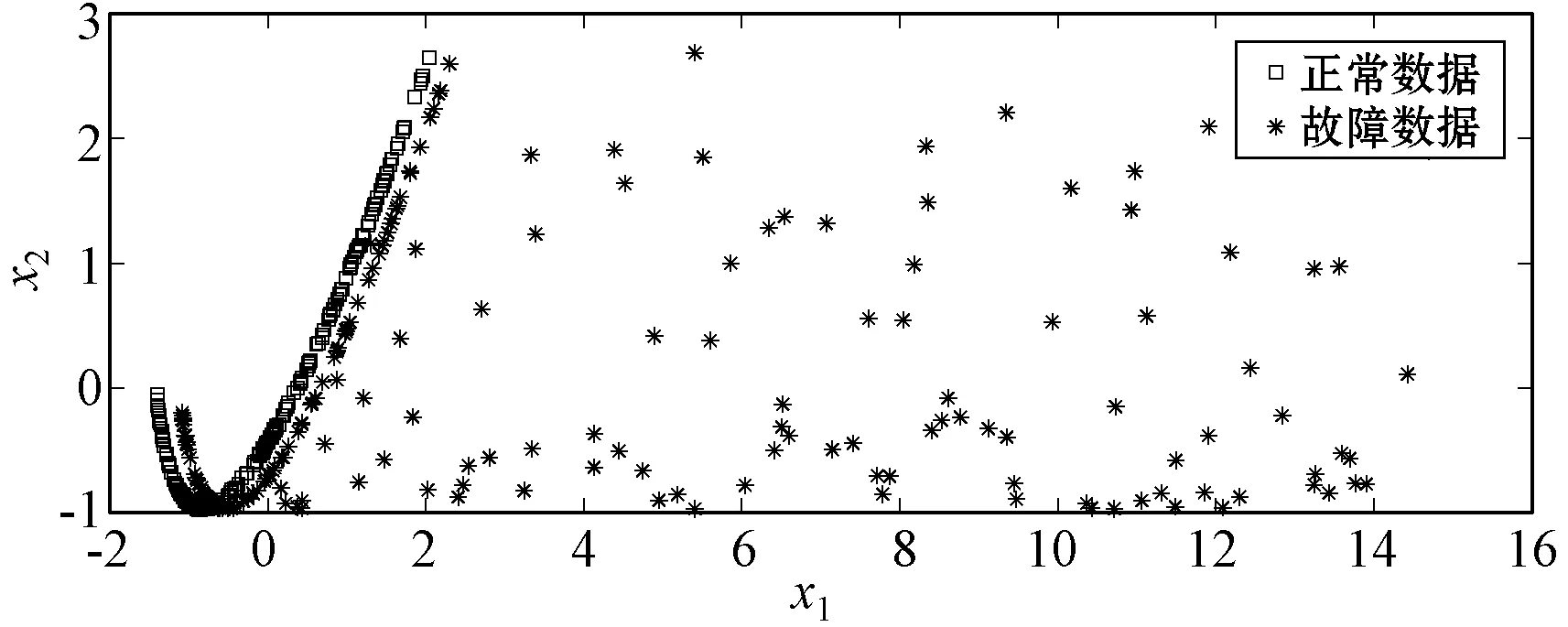
图2 正常数据和故障数据投影分布
可以看出,正常数据比较集中,而故障数据相对分散,且偏离原始数据。然后分别利用这两个数据集构建核主元分析模型,并将其投影到新的空间中,尽管建模数据集完全不同,新空间中的投影数据(包括正常数据和故障数据)却呈现相似的分布。原因是利用KPCA模型的变换方式,为建模数据寻找新的方向,计算新的方差。因此,上述两种KPCA模型中特征矩阵之间存在较大的差异。为了解释这一计算结果,分别在故障发生前和故障发生后的第90个样本和第190个样本两个点上建立核主元分析模型。使用生成的90和190个样本进行建模,生成的特征矩阵如表2-表3所示,对角矩阵中的60列分别列出各自的特征值。可以看出,故障数据模型的特征值明显大于正常数据模型的特征值。因此,可利用负载矩阵P和对角矩阵Λ的变化信息来解释这一现象。

表2 正常数据生成的对角矩阵

表3 故障数据生成的对角矩阵
如前所述,当建模数据显示异常时,特征矩阵将完全不同,可以捕获这种变化信息来构建统计量,用于过程监控。本文提出一种基于特征值变化的方法来测量实时核主成分分析模型中的变化信息。统计量定义如下:
(9)
式中:t为当前时刻,取平方是为了扩大方差。在运行过程中,当过程处于正常状态时,所产生的每个变量的值都会保持稳定,但是一旦发生故障,变量的值就会超出原来的范围。假设负载向量是单位向量,特征值必须增加,以便将产生的向量缩放到方差为1。因此,当过程中出现异常时,特征值会变大。利用这种变化规律构造监控统计量,如式(9)所示。为了判断系统状态,根据核密度估计(KDE)设置99%的置信限。当计算的统计量超过置信极限时,说明该过程处于故障状态。否则,该过程视为正常。
1.4 基于组合滑动窗口KPCA的工业过程故障检测步骤
基于组合滑动窗口的KPCA的工业过程故障检测,主要包括2个步骤:离线建模和在线检测。
离线建模:
(1) 指定组合滑动窗口Xc=[Xa;Xb]的宽度w,其中:Xa∈Rw1×m为基准数据;Xb∈Rw2×m为在线数据,w=w1+w2。
(2) 识别并选择一个普通数据集作为基准数据Xa。
(3) 从正常的监控过程中收集Xb,在组合滑动窗口中形成数据集Xc。
(4) 使用数据集Xc建立KPCA模型,生成特征值。
(5) 根据式(8)计算统计量sum。
(6) 返回到(3),选择在线数据Xb计算下一点的统计量,直到计算出所有的统计量为止。
(7) 使用计算出的统计量估计置信限。
在线监测:
(1) 在时刻t,收集数据Xb=(X1(t),X2(t),…,Xm(t)),形成组合滑动窗口。
(2) 使用数据集Xc构造KPCA模型,生成特征值。
(3) 根据式(9)计算统计量sum(t)。
将统计数据与置信限进行比较。如果统计量sum(t)超过置信限,则过程中发生故障;否则,返回(1)。
2 仿真结果与分析
2.1 数值仿真
本文构造一个数值例子,该数据有3个变量,模型如下:
(10)
式中:[r1,r2,r3]T满足高斯分布,均值为0,标准差为0.01;[e1,e2,e3]T服从均值为0、标准差为1的正态分布。为了便于说明,由式(10)生成500个样本作为正常数据,利用这些数据构造常规的核主元分析模型,并设定99%的置信限进行状态判断。我们根据数值例子创建两种不同的故障。
故障1:变量x3从151时刻到500时刻发生0.05×(i-150)的斜坡变化。
故障2:变量x2从151时刻到350时刻发生阶跃为-0.5的变化。
每个故障类型产生500个样本作为测试数据。这里组合滑动窗口选取15个基准样本,每点采集45个在线样本进行建模。所生成的特征值包含关键信息,一旦在线数据出现异常,特征值将发生明显的变化。因此,我们提取特征值的变化信息,来构造统计量。
本文方法与传统KPCA和基于滑动窗口MVE(MVE-WM)对故障1的监测结果如图3所示。可以看出,传统的KPCA几乎检测不到故障。然而,基于特征值建立的统计量在故障发生后,可以较有效地监测出故障。三种方法对故障2的监测结果如图4所示,传统KPCA的监测图几乎没有显示故障发生的迹象。这是因为核主元选择的缺点造成了信息的丢失。有价值的信息型主元因降维而被弃用。然而,我们提出的组合滑动窗口策略可以有效地检测到这一步的变化,统计量在151时刻之后超过置信限,在样本350时刻之后恢复到正常状态。综上所述,本文提出的统计方法在故障检测方面具有高效、准确的性能。

图3 三种方法对数值例子故障1的检测结果
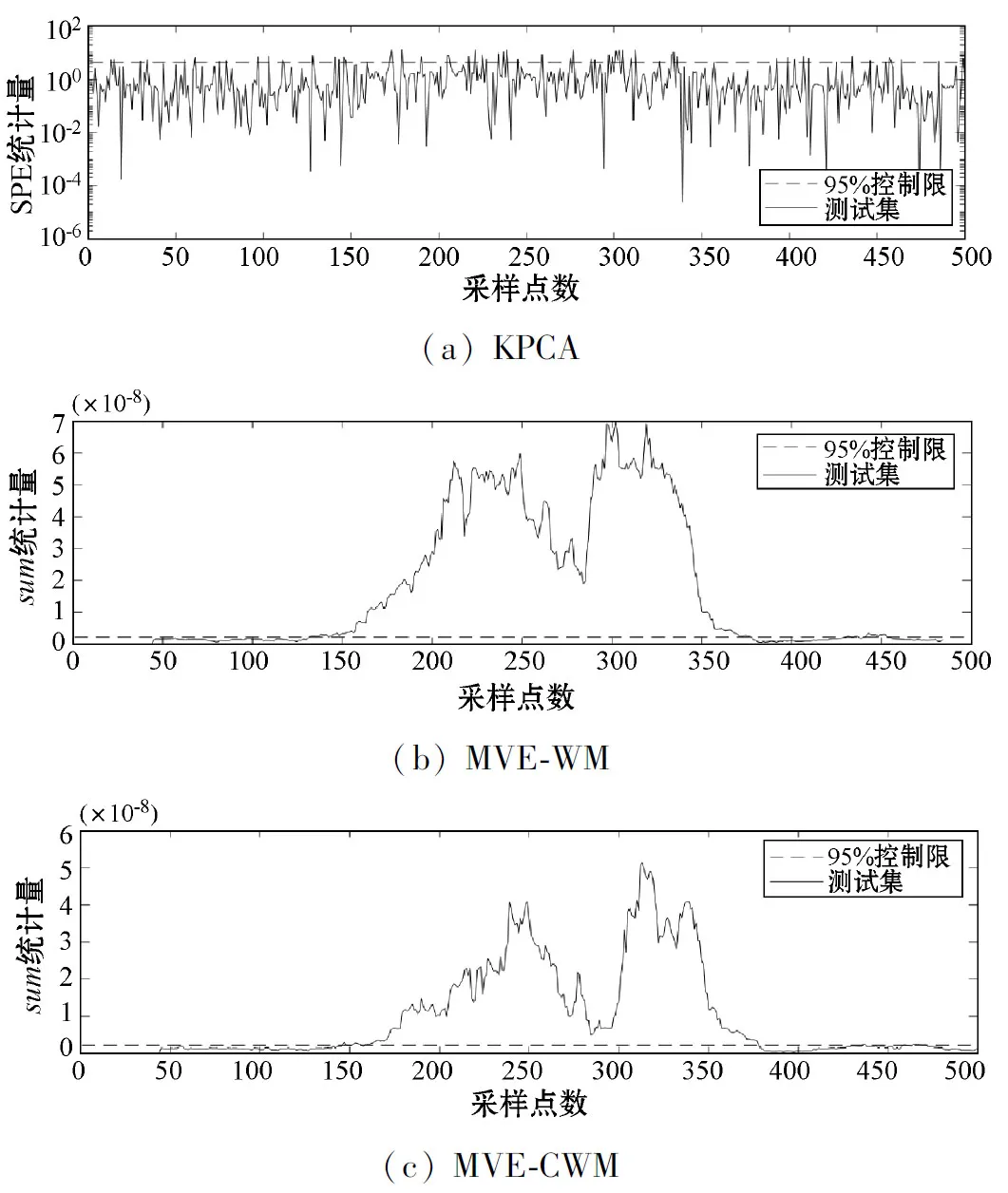
图4 三种方法对数值例子故障2的检测结果
2.2 TE生产过程数据
TE工业生产过程广泛应用于故障检测研究领域[20-21]。TE流程主要有5个操作单元:反应器、产品冷凝器、循环压缩机、汽液分离器和产品汽提器[22-23]。该仿真系统有12个操作变量、22个连续过程测量值和19个成分变量。考虑到过程中变量可能受到任何变化的影响,将TE流程的21个预定义的异常操作事件编入系统,并收集相应的过程。
训练数据集由500个样本组成,而测试数据集由960个样本组成,人为故障是从第161个样本引入的。在21种故障中,选用故障4、11和20来测试本文方法的性能。
在该方法中,组合滑动窗口的大小设置与上述相同,使用15个基准样本和45个在线样本。选用三个过程故障(即选择4、11和20)来验证本文方法的优良性能。故障4是由反应堆冷却水入口温度的扰动引起的。传统的KPCA不能有效地检测该故障,大部分时刻的SPE监测统计量在置信限以下,漏报样本较多,如图5(a)所示。利用滑动窗口策略进行故障检测,如图5(b)所示,该方法能在第200至500个样本左右检测到故障,但稍后监测统计量恢复到正常状态。这是因为系统运行的循环会覆盖故障信息,因此当工艺条件异常时,监控统计量回到置信限以下。但是,从图5(c)可以看出,在第161个样本之后,组合滑动窗口的统计量表现良好,并呈现出相当大的显著优势。考虑到故障的发生增加了组合滑动窗口中数据的分布区域,与负载矩阵相关的统计量sum将会很大,从而将主元量化为单位方差。由此可见,组合滑动窗口策略在整个故障时间内表现出良好的性能。

图5 TE数据故障4的检测
表4分别是故障4、11和20的平均故障检测率。由此可见,所提出基于特征值变化的统计量,表现出有效的监测功能,与传统的KPCA和滑动窗口的表现相比提高了故障检测率,故利用特征矩阵中的变化信息构造统计量的方法具有较好的灵敏度和准确性[24-28]。
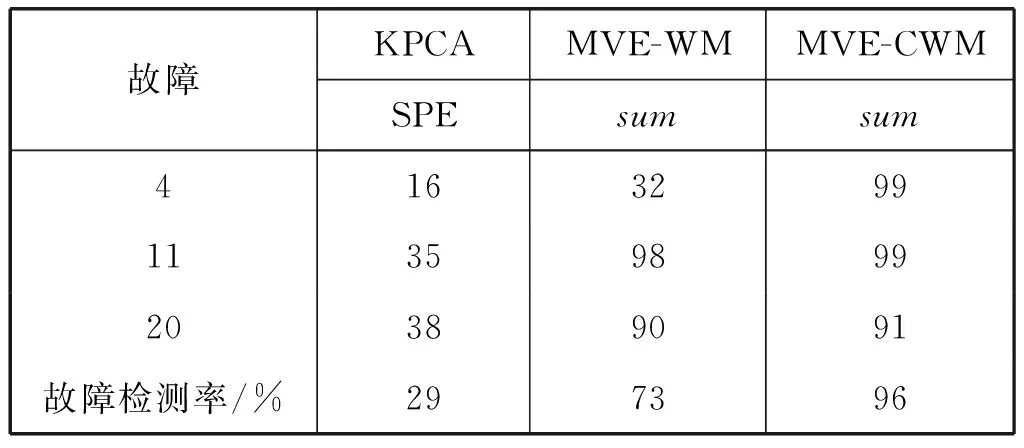
表4 三种方法对TE数据的检测结果对比
3 结 语
为了研究一种结构简单、计算量小、监测性能优越的故障检测方法,提出基于特征值变化的监测统计量。由于实时核主元分析模型产生的特征值揭示了建模数据之间的内在相关性,因此,当采集在线数据的操作系统由于过程故障而产生一定的波动时,这些特征值就会发生变化。提取此特征矩阵的变化信息构造统计量,用于过程监控。为了区分过程中的故障数据,采用包含一些正常样本的改进的组合滑动窗口策略来收集在线数据进行建模。通过一个数值例子和TE过程来验证本文方法的可行性和准确性,并与其他的方法进行比较,表明了本文方法的有效性。本文方法具有通用性和适用性。目前,本文方法仅适用于单个过程,但随着数据存储和数据处理技术的发展,可以从众多过程中及时收集大量的实时数据,为实时监控操作中的产品提供了可能。今后的工作可以侧重于此,并尝试将本文方法应用于其他操作条件。
