半监督全局异构信息保存的网络表示学习
2023-07-07李征
李 征
(常州信息职业技术学院电子工程学院 江苏 常州 213164) (江苏科技大学电子信息学院 江苏 镇江 212003)
0 引 言
网络在各种各样的现实世界场景中无处不在,如社交网络、评论网络和新闻媒体等[1-2]。目前,网络表示学习的基本思想是将网络中的节点映射到低维空间中,同时保持原始网络的结构信息和属性,它可以为许多下游数据挖掘应用提供帮助,如链路预测、节点分类、节点聚类和社区检测[3-4]。
现有的网络表示学习方法有许多是针对同质网络设计的,即不管它们的类型是什么,它对所有的节点和边都一视同仁,例如DeepWalk、LINE、node2vec、GraphSAGE、PRUNE和HARP等,然而,网络通常包含由不同类型的关系连接起来的多种实体,称为异构信息网络(HINs)[5]。由于异构性,传统的网络表现学习方法不能满足异构信息网络的需要,近年来,一些研究论文在异构信息网络的学习表示方面取得了丰硕的进展。Chang等[6]首先利用深度学习和卷积神经网络来获得异构信息网络中的节点表示。Xu等[7]提出基于矩阵分解来获取耦合异构信息网络的结构信息。然而,深层神经网络和矩阵分解方法都存在计算量大的问题。周丽等[8]提出了一种基于文本数据的半监督表示学习方法PTE,该方法将异构信息网络分解为若干个二元网络,然后学习网络表示。蒋宗礼等[9]提出了一种异构跳图模型metapath2vec,将基于元路径的随机游动形式化,构造异构邻域,学习异构信息网络的表示。虽然上述方法能够应用于异构信息网络,但其计算量大,且使用框架有相应的限制,另外无法全方位地保存异构信息。
针对上述分析,提出一种全局异构信息网络表示学习框架,在保持异构信息网络全局结构信息的同时,采用基于元路径的随机游走策略和自编码器来提取语义信息。通过几个异构信息网络挖掘任务验证了本文方法的有效性。
1 方 法
1.1 异构信息网络(HIN)与节点相似度
异构信息网络是指具有多种对象和/或多种链接的网络。在异构信息网络中,G=(V,E),V是节点集,E={(vi,vj)}是边缘集,G是异构信息网络。异构信息网络还具有节点型映射函数φ:V→A和边缘型映射函数ψ:E→R。在此,A和R分别表示预定义节点类型和链接类型的集合。当|A|+|E|>2时,该网络称为异构信息网络;否则,为同构网络。例如,图1所示的电影网络具有三个不同类型的节点:用户(U)、电影(M)和标签(T)。

图1 电影网络结构
异构信息网络中的节点相似性定义为一对节点间的相似性。对于任意一对节点(vi,vj),如果存在一条边满足(vi,vj)∈E,则将vi和vj的一阶相似度定义为1。如图2所示,由实线连接的每个节点对具有一阶相似性。异构信息网络的高阶相似性度量了其邻域结构的成对相似性。给定一个节点对(vi,vj)∈E,如果它们有一个公共的一阶相连的顶点vk满足(vi,vk)∈E以及(vj,vk)∈E,则它们之间存在二阶相似性。因此,vj和vj的表示应该相似。图2中的细虚线圆圈表示节点之间的二阶相似性。此外,可以得到高阶相似性定义。如果从vj到vj存在路径(vi,v2,…,vn,vj)则vi、vj具有n阶相似度。粗虚线圆圈表示网络中的四阶相似性。
1.2 模型概述
本文提出一种半监督的异构信息网络表示学习方法,主要集中在保存语义信息和高阶相似性。SGHIRL的框架如图3所示。整个体系结构由训练数据的准备和表示学习两部分组成。为了保存语义信息和高阶相似性,首先对输入异构信息网络中的路径进行采样,形成路径集。然后需要一个能够将它们编码为低维向量的框架。为此,本文提出使用自动编码器神经网络模型和路径预测任务来分别学习和改进节点的表示。

图3 SGHIRL的结构框架
1.3 训练和准备工作
网络的异构性加快从网络中提取更多的隐含信息。该算法采用元路径来获取异构信息。元路径模式S=(Asub,Rsub)可以用节点序列和边缘序列的形式表示。
(1)
式中:Asub和Rsub是A和R的子集;ai表示特定的节点类型;ri表示边缘类型。给定一个元路径模式,可以将原始的异构信息网络G分解为一个能够保留语义信息的元路径集合Gs。
Gs的邻接矩阵可以表示为Mp∈Rn×n,当且仅当节点i通过元路径样本P与节点j相连时,Mp(i,j)=1。考虑到Mp的构造比较复杂,在实际应用中不需要构造Mp。事实上,对于任意长度lp的路径模式,可以通过维护lp-1邻接查找表来获得lp-1中任意两个给定节点的连通性。
为了提取异构信息,本文采用基于元路径的随机游走策略从异构信息网络中采取路径。对于每个路径P,设置一个指标变量Ip来标明该路径是否是原始网络中的元路径。例如,在图3(a)所示的电影网络中有三种类型的节点:用户(U)、标签(T)和电影(M)。假设选择一个长度为5的元路径模式
算法1基于元路径的数据采样
输入:异构信息网络G=(V,E),元路径模式S,每个节点的行走步数u,负样本数q。
输出:数据集D。
1.初始化D=[];
2.fori= 1:1:udo
3.根据S从网络中对路径P进行采样;
4.将样本(P,1)加入D中;
5.forj=k:1:qdo
6.产生一个负样本P-;
7.将样本(P-,1)加入D中;
8.end for
9.end for
10.returnD
1.4 表示学习框架
选自给定网络中的节点序列或路径,需要一个编码框架将它们编码到一个固定的低维空间。在最近提出的许多模型中,自编码器被证明是最有效的解决方法。一般而言,自编码器由两部分组成:将原始输入编成隐变量表示的编码器和试图从隐变量表示中恢复数据的解码器。给定邻接矩阵xi的第i行,表示节点i,编码器将其映射到低维空间:
(2)
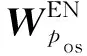
(3)
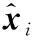
(4)
式中:dist(x,y)表示距离,在实验中首先考虑欧几里得距离。对于元路径中的每个节点,考虑到每个节点的位置和类型不同,使用独立的自动编码器将其映射到低维向量。因此,自编码器部分的代价函数为:
(5)
式中:Pj表示训练数据中的第j条路径,总共np条路径。事实上,大多数网络是稀疏的,这意味着xi中非零元素的数目远远少于零元素的数目。SGHIRL通过获取网络中的高阶相似性来缓解这个问题。此外,在计算自编码器的损耗时,只需关注xi中的非零元素。此时自动编码损失值为:
(6)
式中:⊗为哈达玛积。注意,在这里引入哈达玛积将导致解码器总是输出全为1的向量,从而迫使LAE等于零。本文稍后会讨论如何解决这个问题。对自动编码层进行训练后,可以得到初始节点的表示形式,为[z1,z2,…,zlP]。
实际上,可以通过训练自编码器来获得基础表示。为了保留高阶相似性和语义信息,引入一种中间表示,即路径表示,用来表示细化过程。所提出的SGHIRL训练一个神经网络模型用于二元预测任务,以判别给定节点序列之间是否存在路径。虽然有很多种深层架构可供选择,但本文方法模型能高效率计算,且表达式便于应用。具体而言,SGHIRL采用了一个单隐层前向神经网络,该网络将序列[z1,z2,…,zlP]作为输入,用来预测节点间路径存在的概率。即第一层以多个节点作为输入,然后通过一个非线性映射函数,由隐藏层获得集相似性和语义于一体的路径,表示为:
(7)
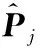
(8)
式中:W[2]表示第二个隐藏层的权重;b[2]表示第二个隐藏层偏移向量。
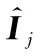
(9)
式中:Ij是训练集的指标变量。
算法(SGHIRL)步骤如算法2所示。
算法2半监督全局异构信息保存网络表示学习(SGHIRL)。
输入:训练数据D,节点集V,元路径模式S,每个节点行走步数u,自编码器lp。
1. 随机初始化参数θ,θ={WEN,WDE,W[1],W[2],b};
2. while目标函数不收敛do
4. 用小批量梯度下降法更新θ;
5. end while
7. for vi:1:V do
8. 获取节点表示zi;

10. end for
1.5 优 化
所提出的SGHIRL学习表示法是将前向神经网络中的自编码器重构损失LAE和预测损失LNN联合最小化,即目标是解决以下优化问题:
(10)
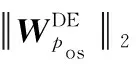
为了将参数W和b进行优化,用小批量梯度下降的反向传播算法对SGHIRL进行训练。首先从异构信息网络中抽取路径并生成(P,Ip)形式的负路径,用来构造训练数据集D。
则可采用式(11)对参数θ进行更新。
(11)
式中:η是学习率。可以通过自编码器获得任意节点的向量表示形式。
2 实验与结果分析
2.1 数据集
为了验证SGHIRL的有效性,本文在四个不同的异构信息网络上进行了实验,包括GPS网络、医学网络、电影评论网络和语言网络。表1总结了这些异构信息网络的统计数据。
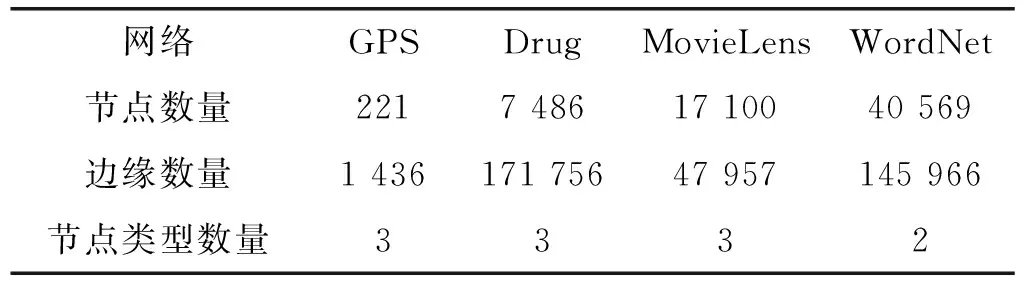
表1 异构信息网络参数统计
(1) GPS:这个数据集记录了164个用户的轨迹,包括5种不同类型的活动。它最初用于构建推荐活动系统。对于每个包含三个元素的元组:用户、位置和活动,假设任何两个对象之间都有一个直接的链接。因此,以用户定位、用户活动和位置活动的形式构建了一个具有边缘的异构网络[9]。
(2) Drug:这是提交给美国食品和药物管理局(FDA)的关于不良事件和用药错误报告的公共信息的子集。完整的数据集在FDA不良事件报告系统(FAERS)上出版。与GPS一样,对于数据集中的每个报告,本文假设使用者、药物和反应是相互关联的。以用户药物、用户反应和药物反应的形式构建一个具有边缘的异构网络[9]。
(3) MovieLens:这是一个典型的网络评论数据集,描述人们如何评价电影,并广泛用于电影推荐服务。根据数据集的组织结构,以电影用户和电影标签的形式构建了一个具有边缘的异构网络[10]。
(4) WordNet:这是一个大型词汇数据库,用于生成词典,并支持自动文本分析。它由同义词集和这些同义词集之间的关系类型组成,是一个具有超边的异构网络[11]。
2.2 对比方法
本文比较了SGHIRL与以下网络表示学习方法的性能:
(1) DeepWalk[12]:从网络生成截短随机游动,并应用skip-Gram模型来学习网络表示。在这里,对整个异构信息网络进行DeepWalk,而忽略了节点的类型。
(2) LINE[13]:LINE分别保留网络中节点的一阶和二阶相似性,并通过skip-gram模型学习网络表示。将一阶和二阶相似性的表示串联起来,同样忽略了节点类型。
(3) node2vec[14]:作为DeepWalk的一种广义方法,node2vec通过参数化随机游动捕捉w-hop邻域内的节点对,从而学习低维度节点向量。此方法无法处理节点类型。
(4) HEBE[15]:HEBE是基于超边的网络表示学习框架,它可以捕获不同类型节点之间的交互情况。
(5) DHNE[16]:DHNE的目标是学习超级网络的低维度表示,并使用深度模型来保持向量空间中的局部和全局相似性。
注意,DeepWalk、LINE和node2vec是为同构网络设计的。为了公平比较,SGHIRL还采用普通随机游走策略从异构信息网络中抽取路径,尽管HEBE和DHNE是为异构网络设计的。
2.3 参数设定
本文为每个数据集在SGHIRL中设计前向自编码器神经网络。针对GPS这个规模较小的数据集,节点表示的维度均设置为64,因此自编码器的输出层尺寸为64×5。权衡参数α通过线性搜索进行调整,取值范围为[0,1],每隔0.1取一个值。对于所有适用的模型,负采样率始终设置为5;学习率η的起始值设置为0.1,并采用Adam自动调整学习率;批的最小值设置为16。在SGHIRL中为每个节点抽取了1 000条路径。为了公平比较,DeepWalk和node2vec中每个节点的行走次数设为125,行走长度为40。为了考察SGHIRL的一般适用性,其随机行走路径模式下的行走长度设为5。以上未提及的其他参数均设为默认值。而针对MovieLens以及WordNet两个规模较大的数据集来说,单一隐层的自编码器计算能力稍显不够,因此根据数据集的规模,可以设置不同层数的隐藏层自动编码器来匹配相应的计算需求,从而进行验证,其各隐藏层节点数与单一隐藏层的节点数相同,相关参数设置与单一隐藏层无异。为了观察自编码器在节点表示学习中的作用,建立一个只包含一个自编码器的SGHIRL模型进行比较。注意,模型的复杂性与自编码器的数量呈线性关系。例如,当采用长度为l的路径模式时,正常SGHIRL参数值如表2所示,忽略偏差参数b。
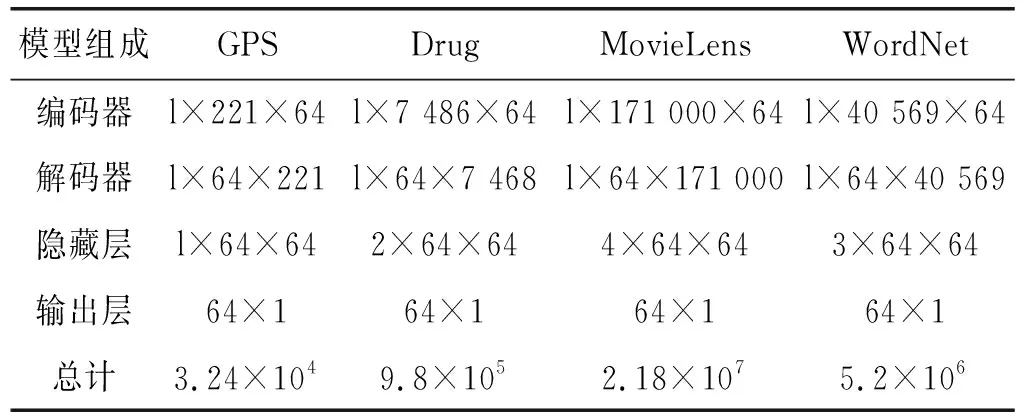
表2 每个数据集上的参数值
通过网络重构、链路预测和节点分类等多个下游任务来评估不同模型的性能。为了确保实验的可靠性,将所有评估重复进行5次,并计算出平均结果。
2.4 网络重构
为了直接评估表示学习算法能在多大程度上保留原始网络的结构信息,本文对所有数据集进行网络重构。使用整个网络以及生成的负样本来训练模型并获得每个节点的表示。特别是对于SGHIRL,将节点反馈给相应类型的自编码器,从而获得表示。如果有多个对应类型的自编码器,取平均值即可。其任务是通过比较两个节点表示之间的相似性来重构原始网络中的边缘。利用余弦相似性来预测原始网络中的边缘。采用AUC[16]进行评价,结果见表3。

表3 AUC在网络重建方面得分
如表3所示,除了随机模式和单个SGHIRL外,在AUC方面,所提出的SGHIRL在四个数据集上的运行结果优于其他所有比较方法。很明显,仅使用单个自编码器来学习节点表示的SGHIRL性能最差。与SGHIRL随机游走模型相比,该结果表明单个SGHIRL的自适应能力受到自编码器的限制。与DHNE和HEBE等异构信息网络表示学习模型相比,SGHIRL+metapath模型在所有数据集上的运行结果相对改进率分别至少为3.43%、2.78%、3.26%和4.32%。结果表明,表示形式的改进对于保存异构信息网络的结构信息具有积极效果。注意,DHNE和本文模型均优于HEBE,这说明高阶相似性在网络表示学习中的重要性。此外,通过比较全部采用随机游走取样策略的DeepWalk、LINE和node2vec,SGHIRL在四个数据集上的精确率分别提高了19.09%、36.11%、2.22%和4.05%,说明了本文模型在异构信息网络中保存异构信息的有效性。此外,观察到具有元路径抽样策略的SGHIRL始终优于随机行走抽样策略,这说明表示学习可以从语义信息中受益。此外,SGHIRL在不同路径模式下的性能表明使用较长的元路径将获得更好的节点表示。
2.5 链接预测
网络表示学习的最原始对象是预测将来哪对节点将形成一条边缘。对于链接预测任务,首先随机均匀地隐藏10%的边缘,剩余网络和生成的无边缘用于训练SGHIRL并获得表示,其任务是使用获得的表示来预测那些隐藏的边缘。与网络重建任务相似,使用余弦相似性来预测边缘,并使用AUC来评估预测性能,结果见表4。

表4 AUC在链接预测方面得分
由于HEBE、DHNE和SGHIRL都利用语义信息进行预测,因此它们的性能相对较好。实验过程中注意到,在这些异构网络表示学习方法中,本文模型的性能最佳,这主要是因为SGHIRL将高阶相似性和语义信息集成在一起。与以前的研究结果一致,证明了保留高阶相似性可以提高链路预测性能,这反映了网络结构信息的重要性。较长的路径架构仍然有助于SGHIRL获得更高的分数。此外,在仅考虑节点相似性的模型,即DeepWalk、LINE、node2vec和SGHIRL+随机行走模型中,本文模型仍然表现最佳。一致认为性能改进的主要原因是SGHIRL中改进的优越性。此外,与SGHIRL+随机游走模型相比SGHIRL+metapath,在四个数据集上的增益达到了6.12%~11.18%,这表明保留语义信息可以提高模型的泛化能力。
2.6 节点分类
在节点分类任务中,为每个节点归为一类或多个类。在MovieLens数据集中,每部电影都有一个或多个流派的标签。而在Wordnet数据集中,每个同义词都有一个正属性。由于只有两个数据集具有类信息,因此在这两个异构信息网络上进行了节点分类实验。最近邻分类器被用来预测将表示学习作为输入的节点的标签。首先,在整个网络上训练模型,得到所有节点的表示。然后将学习到的节点表示按9∶1的比例随机分为训练集和测试集。节点的类属性作为标签。在训练集上拟合一个最近邻分类器,即K=1,然后使用测试集来验证SGHIRL节点表示学习的有效性。表5和表6分别记录了宏观F1和微观F1的平均值。

表5 用于节点分类的MovieLens和WordNet上的宏观F1

表6 用于节点分类的MovieLens和WordNet上的微观F1
从结果来看,SGHIRL在节点分类任务上各方面优于所有对比方法,进一步验证了语义信息和细化过程的有效性。在所有基于随机游走的模型中,DeepWalk和LINE的性能最差,因为它们采用严格的策略来探索网络中的邻域。在探索网络邻域方面具有更灵活策略的Node2vec表现得更好。另外,与SGHIRL和DHNE相比,HEBE表现最差。在WordNet数据集上所有方法中,HEBE的F1得分最低,这意味着数据稀疏性严重损害了HEBE的性能,并且在LINE和DeepWalk中观察到类似的情况。在所有四个数据集上,SGHIRL+随机游走模型始终比HEBE表现得更好,这说明表示精简程序的有效性。
2.7 鲁棒性
进一步进行鲁棒性测试,为了模拟具有不同稀疏度的网络,在四个数据集上将训练率从10%调整到90%,网络的剩余部分用于测试链路预测模型的鲁棒性。本节中使用的路径模式如表7所示,结果如图4所示。

表7 用于稳健性检验的路径架构

图4 四种数据集链路预测的鲁棒性检验
图4描绘了在所有方法上随着训练数据大小的增加而不断改进的AUC模型。注意到SGHIRL+元路径始终优于DHNE和HEBE,这表明当网络稀疏时,高阶相似性非常重要。通过SGHIRL+metapath和SGHIRL+随机游走模型的比较,说明了表示细化的有效性。
2.8 参数灵敏度
本节研究了模型中不同参数对链路预测的敏感性,包括表示尺寸、损失权衡参数α和每个节点的遍历次数。结果如图5所示。
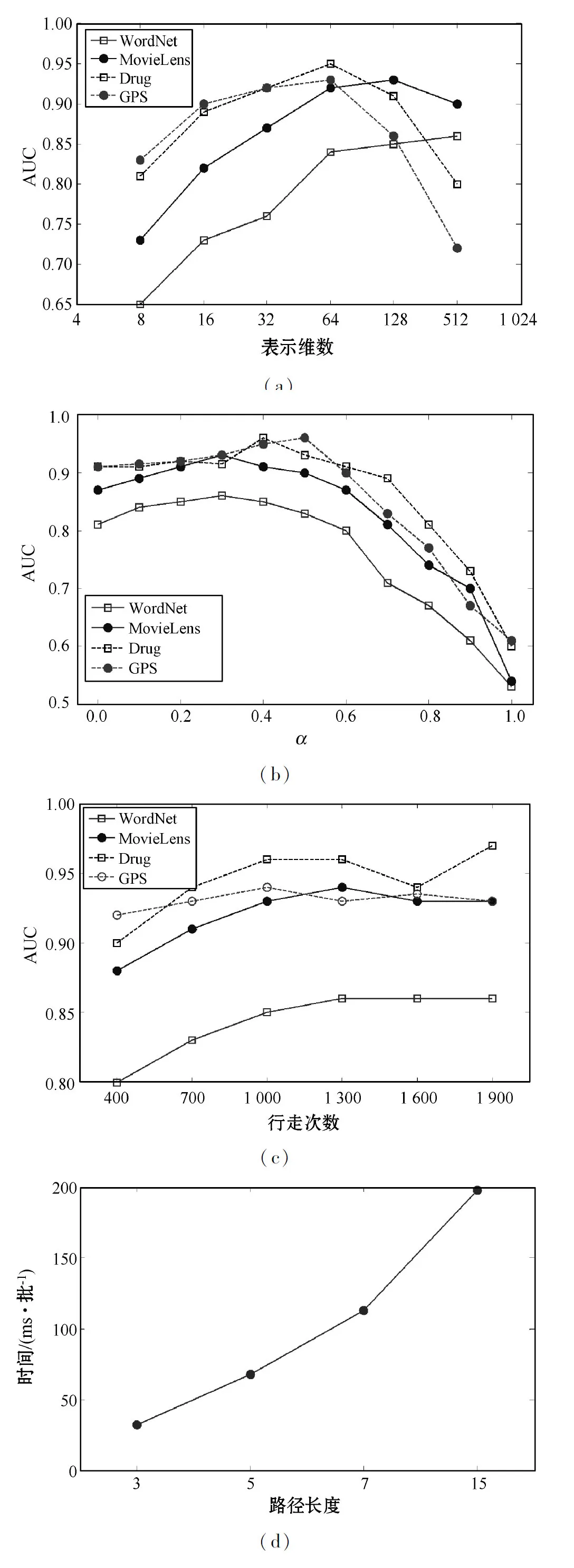
图5 灵敏度测试
从图5(a)可以看出,性能首先随着表示维度的增长而提高,然后达到饱和,原因是SGHIRL需要合适的维度对异构信息进行编码。当表示尺寸大于128时,除WordNet外,AUC开始下降。这是因为较大的尺寸可能会引入一些冗余,但是对于WordNet,较适合采用高维向量表示节点,因为它包含许多节点,而且是一个稀疏网络。
图5(b)描绘了损耗权衡参数α对性能产生的影响。参数α衡量无监督误差LAE和有监督误差LNN。当α为0时,忽略了自编码器的损耗,因此SGHIRL只考虑了路径预测的误差,可以认为该模型主要保留网络中的语义信息。即使在这种情况下,神经网络模型也能取得良好的效果,这也表明了语义信息在网络中的重要性。随着α的增加,性能得到了改善,因为引入的LAE主要影响高阶相似性。该研究结果表明了高阶相似性和语义信息的集成的重要性。但是,当α大于0.5时,这意味着SGHIRL的路径预测误差LNN对模型没有太大影响,而四个数据集的性能都急剧下降。当α为1时,SGHIRL只考虑重构LAE的损失,从而得到的AUC值很低。结果表明自学习是一种合理的无监督编码方法,能同时保留高阶相似性和语义信息的必要性。
图5(c)表示在每个节点上存在的数据和信息产生更多的行走,但增加步行次数所产生的收益也将会达到饱和。为了验证不同长度的路径模式的复杂性,在药物数据集上测量了每批数据的训练时间,如图5(d)所示。可以观察到训练时间与路径模式的长度呈线性关系,证实了之前对模型的参数估计。
3 结 语
传统的网络表示学习模型存在网络信息保存不全面的缺点,为此提出一种半监督全局异构信息保存网络表示学习框架。通过多个异构数据集的验证结果可得出如下结论:
(1) 相较于其他方法,本文模型在异构信息网络中保存异构信息更加有效。
(2) 具有元路径抽样策略的SGHIRL始终优于随机行走抽样策略,这说明表示学习可以从语义信息中受益。此外,SGHIRL在不同路径模式下的性能表明使用较长的元路径将获得更好的节点表示,验证了语义信息和细化过程对改善方法的重要性。
(3) 保留高阶相似性可以提高链路预测性能,这反映了网络结构信息的重要性,另外,保留语义信息可以提高模型的泛化能力。
(4) 自编码器是一种合理的无监督编码方法,能够有效提升方法的应用范围,且同时保留高阶相似性和语义信息,对于性能的提升有着十分重要的作用。
