基于交换改进粒子群算法的云计算任务调度
2023-07-07陈俊仁郭一晶
陈俊仁 郭一晶
(厦门大学嘉庚学院信息科学与技术学院 福建 漳州 363105)
0 引 言
云计算作为一种新型的计算模式,已被互联网用户广泛使用。它是按需为用户动态整合不同计算机虚拟资源以提供数据处理的计算服务系统。对用户而言,其关注的是云计算的服务质量。调查发现,云计算的服务质量最大程度取决于计算服务系统完成用户所提交的任务的耗费时间。所以,提高任务的处理速度是用户最关心的问题。此问题的关键就是寻找一种高效的调度方案使得用户提交的任务处理时间尽量短,实质为云计算的任务调度,属于一种组合优化问题。文献[1]已证明云计算任务调度问题是一个非确定性多项式(Non-deterministic Polynomial,NP)难题。近年来一些学者已采用群体智能算法对该问题进行求解。文献[2]采用遗传算法并结合启发式规则求解多优先队列分布式计算系统的任务调度问题,实验证明该方法可以有效获得可行解,但算法过于复杂,实现难度较大。文献[3]针对基本蚁群算法自身存在的缺陷,设计一种改进蚁群算法,该算法可以减少云计算中任务执行的总完成时间,但算法的迭代过程过于繁杂,其空间复杂度增加。文献[4]提出了一种改进萤火虫算法的云计算作业调度机制,实验证明该方法可以有效减少作业的执行时间,但其目标仅仅针对作业的完成时间,并未考虑资源的使用情况。然而,随着云计算的需求量日益增多,调度方案不仅要考虑如何快速完成多用户提交的云任务,而且还应该关注计算资源的利用率。文献[5]设计一种改进的负载均衡蜜蜂算法,仿真实验说明该算法可以有效减少任务的执行时间并提升资源的负载均衡,但蜜蜂算法自身存在进化后期收敛速度慢、共享机制低效等缺点。文献[6]结合资源的负载均衡和任务的执行时间,设计出一种改进的禁忌搜索启发式调度策略,但算法的整体启发规则较为复杂,操作相对烦琐。文献[7]提出了一种以任务总完成时间、任务平均完成时间和资源负载均衡为目标的遗传算法,实验结果证明算法有效,但因为编码问题,算法进化过程的操作过于繁杂,且可能陷入局部最优。与此同时,粒子群算法(PSO)在多个领域已被证明具有记忆能力、参数少、收敛速度快、实现简单等特点[8-10],并且在云计算任务调度问题上也得到了应用。文献[11]设计了一种针对云任务调度问题的小生境粒子群算法,实验结果表明该算法可缩短任务执行时间并使资源负载均衡。
基于以上考虑,本文根据云计算任务资源分配问题的特点,对基本的交换粒子群算法进行改进。引入进制编码,在其基础上重新定义运算法则,加入自适应概率调整,改进其适应度函数,综合考虑任务完成时间和资源负载均衡等指标,提出了一种新的云计算任务调度算法。
1 云计算任务调度描述
1.1 问题定义
现今,主流的云计算平台大部分采用Map/Reduce的工作方式。该方式适用于处理大规模的数据,可将用户请求的大任务拆分成若干个子任务,再根据指定的策略去调度合适的资源来处理计算这些子任务。换言之,云计算任务调度问题可理解为调度中心调度p个虚拟资源来处理计算q个子任务,即建立虚拟资源与任务之间的映射,使其完成后达到任务总处理时间最少,资源利用率最高。
为简化调度处理流程,现对云计算平台中用户提交的任务及其提供的资源作如下假设:
1) 拆分后的子任务之间无前后执行依赖关系,并且各子任务是相互独立;
2) 一个子任务只由一个虚拟资源连续处理,不考虑中断;
3) 拆分后的子任务数量远远多于平台所提供的资源数量,并且资源处理任务的成本可知。
云计算任务调度的过程如图1所示。

图1 云计算任务调度过程
1.2 任务调度模型
云计算任务调度是由子任务集合、虚拟资源集合以及子任务与虚拟资源之间分配关系的集合构成。可表示为:
D=(ST,VR,MAP)
式中:D表示一个云计算任务调度方案,ST为调度方案D中子任务的集合,VR是调度方案D中虚拟资源的集合,MAP是调度方案D中子任务与虚拟资源之间分配关系的集合。
子任务集合ST表示为ST={st1,st2,…,stq},其中第i个任务表示为sti(1≤i≤q,i∈Z)。虚拟资源集合VR表示为VR={vr1,vr2,…,vrp},vrj(1≤j≤p,j∈Z)表示第j个虚拟资源。子任务与虚拟资源之间分配关系的集合MAP表示为MAP={…,
另外,任务的衡量指标一般采用MI(百万条指令数),本文令Numberi表示子任务sti的待执行机器指令条数,即子任务的大小。资源的指令执行速度采用MIPS(每秒执行的百万条指令数)衡量,Speedj代表虚拟资源vrj的计算性能。ti,j代表子任务sti在虚拟资源vrj上的执行时间。
ti,j=Numberi/Speedj
1≤i≤q,1≤j≤p,i∈Z,j∈Z
(1)
再者,p个虚拟资源处理计算q个子任务的期望计算时间ETC(Expeeted Time to Compute)[12-13]可用矩阵T表示,该矩阵是一个q×p的矩阵,如下:
虚拟资源vrj的执行时间ExeTime为该资源处理计算其分配的所有任务的执行时间之和。
(2)
式中:sti→vrj,sti∈ST表示虚拟资源vrj处理的所有任务,k代表在该资源上执行的任务总数。根据上文的假设,以及各虚拟资源并行计算的特点,可得任务调度方案D的完成时间为最晚完成任务的虚拟机的执行时间[13],表示方式如下:
Makespan=max{ExeTime(j)|j∈Z,1≤j≤p}
(3)
云计算任务调度追求的目标应是寻找一种使总完成时间Makespan最小的调度方案。
2 改进粒子群算法
2.1 离散粒子群算法
粒子群算法(PSO)是由Eberhart和Kennedy在1995年模拟鸟类群体觅食设计出的一种自适应全局优化搜索算法。基本粒子群算法较适合于求解连续空间优化问题,但对于离散空间优化问题,该算法并不适用。2000年Clerc[14]提出了一种以交换离散值向量为基础的粒子群算法,用于求解离散空间优化问题,已被证明成功求解旅行商问题(TSP)。对于本文研究的云计算任务调度问题来说,其结果亦分散在解空间,本质上也属于离散空间组合优化问题,性质与TSP问题相似,但又有区别。TSP问题的解为所有城市访问顺序的排列组合,而云计算任务调度问题的解则为子任务与虚拟资源的映射组合。另外,云计算任务调度求解过程需要考虑资源的负载均衡指标。因此,本文将结合所研究的调度问题特点在基本的交换粒子群算法上做了相应的改进。
2.2 粒子编码
在基本的交换粒子群算法中,粒子是采用整数编码方式,用不同的整数代表不同的城市,并且每个城市只被访问一次,即访问次序与城市是一一对应。然而,在本文研究的问题中,同一个虚拟资源可以执行多个不同的子任务,为一对多的关系。由此可见,整数编码并不适合本文的问题,因此本文结合云计算任务调度的特点,采用“进制编码”对粒子的编码方式进行改进。
对于任何包含q个待处理子任务的云环境来说,本文按1~q的顺序对这q个子任务进行编号。现假设数据中心代理有p个虚拟资源,且有q个子任务待计算处理,则本文按表1所示的方式进行p进制编码。
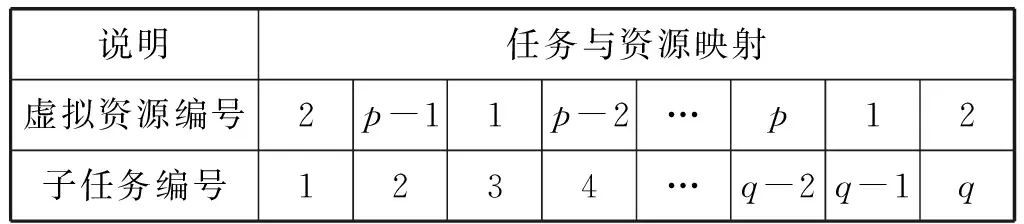
表1 粒子的进制编码
其中,虚拟资源的编号为1至p的整数。一组1至p的组合序列代表该问题解空间里的一个解,即表示一种云计算任务调度方案。
2.3 基于交换的运算法则
传统粒子群算法中的粒子速度和位移更新公式并不适合求解离散空间组合优化问题,故本文采用基于交换的运算。然而,运用原始的交换操作求解本文的问题会存在一定缺陷。因为,不同编号的子任务可能被分配到同一个虚拟资源上执行,此时编码序列中两个任务对应位置上的进制数相同,所以互换位置后编码序列未发生任何改变,即粒子保持不动,从而降低算法的收敛速度。为解决此问题,本文提出的改进算法将重新定义交换子和交换序,并用其来表示粒子的飞行速度。其中,交换子表示在一种调度方案中互换两个子任务的处理虚拟资源,且要求虚拟资源不为同一个,即交换子对应的两个虚拟资源编号不能相等;交换序则由一个或多个交换子组成。为了实现离散值向量间的交换且同时保留粒子群算法思想,本文采用如式(4)所示的粒子速度更新公式,式(5)为粒子的位置更新公式。
(Pi-Xi)⊕β×(Gb-Xi)
(4)
(5)
2.4 适应度函数
在粒子群算法中,适应度函数是衡量粒子离目标远近的标准,一般称之为粒子的适应值。种群中第i个粒子的适应值记为f(Xi)。
由于实际的云计算环境中,不同虚拟资源的计算能力存在一定差异,经常出现算力高的虚拟资源负载过高,其任务队列中等待任务数量过多,而其他虚拟资源则处于空闲状态,因此造成资源使用率不高且负载不均衡,甚至任务的总完成时间较长。为了避免该现象发生,本文对适应度函数做了相应改进,在评价粒子适应值时引进负载均衡指标,即给虚拟资源分配任务时既要追求完成时间短,同时要考虑各虚拟资源的负载情况。
虚拟资源vrj的负载Loadj此处定义为预分配到其上所有子任务的预期执行时间,Loadj越大,表明虚拟资源vrj的负载越高,结合式(2)可得:
Loadj=ExeTime(j)
(6)
定义所有虚拟资源的预期执行时间均值为Loadavg,公式如下所示:
(7)
式中:p为虚拟资源的个数。
对任意云计算任务调度方案的负载均衡评价指标LB定义为所有虚拟资源的预期执行时间的标准差,公式如下:
(8)
其中,调度方案的负载均衡评价指标LB越大,表明该调度方案的负载均衡情况越差。
结合式(3)和式(8),本文定义的适应度函数为:
f(X)=ω1Makespan+ω2BL
(9)
式中:ω1和ω2为权重值,ω1+ω2=1。适应度函数f(X)越小,说明粒子X对应的调度方案越好。
4.1.1 餐饮服务单位的食品安全管理制度齐全,确保食品原料新鲜、加工过程生熟分开,食品烧熟煮透,其加工时食品中心温度应不低于70℃。主要食品安全管理制度应包括但不仅限于以下各项:食品安全岗位责任制;从业人员健康管理制度;从业人员培训管理制度;加工经营场所清洁制度;设施设备清洁、消毒和维修保养制度;食品采购索证索票制度;食品进货查验和台账记录制度;餐厨废弃物处置管理制度;食品安全突发事件应急处置方案;投诉受理制度等相关制度。
2.5 自适应概率调整
云计算任务调度的求解比TSP问题复杂很多。首先,要求各个虚拟资源保持负载均衡;其次,子任务在不同算力的虚拟资源中执行时间差别较大,执行子任务的虚拟资源更换后,可能引起任务的总完成时间发生变化,导致寻找负载均衡且时间短的调度方案难度加大。与此同时,基本交换粒子群算法容易出现粒子聚集现象,导致算法在进化后期陷入局部最优的可能性增加。为此本文引进一种自适应的调整概率对粒子群算法做了改进。算法根据此概率值决定是否对粒子当前所处的位置序列做调整操作。调整过程如下:在粒子的位置序列中随机挑选两个不在同一台虚拟机上计算的子任务,然后互换这两个子任务的处理虚拟机。若互换后该粒子的适应值低于当前种群最优值,则认为此次调整操作有效并把该位置标记成种群当前最优位置。此外,该概率值是根据算法迭代次数、前一代调整概率以及前一代调整的成功次数动态变化,公式如下:
λ=b·[1-nsuc/(apt·m)]
(10)
apt+1=r^(1-t/G)λ
(11)
式中:ap表示调整概率;m表示种群大小;nsuc表示前一代调整的成功次数;b是常数,本文取值为3;λ为调整权重;t为当前的迭代数;G为总迭代次数(进化代数);r∈[0.2,0.5]。从式(10)和式(11)可以看出,迭代初期ap值较小以保持算法的收敛速度;迭代后期ap值增大,交换操作的次数将逐步增多,以此保持粒子的多样性,从而降低陷入局部最优的概率。
2.6 算法流程
本文提出的基于交换的改进粒子群算法,主要包括初始化种群、粒子移动、选择和自适应调整四个过程。具体操作步骤如下。
Step1初始化:输入算法参数,并在问题解空间里随机产生m个粒子的位置序列和速度交换序。
Step2评价粒子:通过适应度函数评价每一个粒子的适应值。
Step3更新极值:1) 比较粒子的适应值和个体本身历史最优值,若前者优于后者,则将个体自身历史最优位置替换成粒子当前的位置序列;2) 比较粒子的适应值和种群当前最优值,如果前者好于后者,则将群体最优位置替换成粒子当前的位置序列。
Step5调整:根据调整概率调整粒子的位置序列,如果新的适应值比种群当前最优值更优,则把种群最优位置设为粒子调整后的位置序列。
Step6终止:重复Step2~Step5,直至满足算法终止条件。
Step7输出:输出种群最优位置对应的调度方案。
3 仿真实验与分析
为了验证基于交换的改进粒子群算法(Improved Discrete PSO,IDPSO)对云计算任务调度的有效性和可行性,本文使用开源的CloudSim云仿真平台进行实验,并在同等实验条件下与Min-Min调度算法、基本的离散粒子群算法(PSO)和基于交换运算法则的粒子群算法(Discrete PSO,DPSO)进行对比实验。
3.1 实验环境
仿真实验环境具体信息如下:处理器为Inter(R) Core(TM) i5-6267U CPU @ 2.90 GHz,内存为8 GB,操作系统为Windows 10,软件平台为Eclipse、CloudSim,编程语言为Java。
CloudSim是一款由Java编写的基于事件的仿真框架,可在一台主机上模拟大规模的集群及任务调度,只需在框架中实现其调度算法并重写相关类,即可完成仿真工作。另外,IDPSO本身具有粒子群算法参数少、迭代流程简便的特点,并且本文采用的进制编码、交换子、交换序及交换操作均可使用基本类型数组存储与运算,总体上实现相对简便。
3.2 参数设置
在云仿真平台中设置虚拟资源的个数为10,其计算能力参数范围为1 024~2 048。子任务数量范围为[100,400],子任务的待执行机器指令条数范围为1 000~10 000。
上述算法中设置的主要参数有,种群大小m为50,惯性权重ω为0.85,学习因子c1和c2均为2,ω1和ω2分别为0.6和0.4。
3.3 结果分析
实验分为4种不同子任务数,任务数分别为100、200、300和400,与之对应的迭代数分别为500、700、1 000和1 500。每组各做50次独立重复实验,取其平均值。实验结果如图2和图3所示。

图2 不同任务数的适应度函数值对比

图3 不同任务数在不同迭代次数下取得的适应值对比
图2为Min-Min算法、PSO、DPSO和IDPSO在相同仿真环境和参数下的适应度函数值对比图。由图可知,在任务数为100和200的情况下,IDPSO取得的结果最好,但其优势仍不够明显。在任务数为300和400时,IDPSO体现出更好的性能,其得到的适应度函数值比DPSO低更多,且都好于Min-Min算法和PSO。特别在400个任务时,其优势更加突出。因此可得,IDPSO总体上取得的结果都优于其他算法,随着任务数增加,其效果越明显,即更适合任务数较多的场景。换句话说,IDPSO在任务数较多时更能找到任务总完成时间短、资源负载均衡的调度方案。
图3中的实验是针对基于交换运算法则的粒子群算法改进前后的收敛对比。可以看出,不同任务数的求解过程中,IDPSO的收敛速度均比DPSO快,在任务数较少时效果较为明显。由此可见,本文采用的进制编码和重新定义的粒子更新运算法则具有一定的优势。同时可得,算法在迭代初期自适应调整概率较小时,不会导致收敛速度变慢。还有,从算法取得的结果来看,DPSO寻优过程较易陷入局部最优,加入自适应概率调整后,IDPSO收敛速度在任务数多的情况下与DPSO相当,但其得到的适应度函数更优,可见自适应概率调整可有效促使IDPSO跳出局部最优。另外,从图3亦可发现IDPSO在不同任务数下的收敛适应值均更小,可见具有鲁棒性。由此可得,IDPSO在云计算任务调度中表现出更快的收敛速度,以及更强的全局搜索能力。
4 结 语
本文在交换的粒子群算法基础上,通过重新定义交换子及粒子的运算法则,引入自适应概率调整,并且以任务调度的总完成时间和资源的负载情况为适应度函数来衡量调度方案的优劣,以此进行云计算任务调度方案优化。仿真实验采用开源的CloudSim平台,并在此平台上进行实例分析。实验结果表明本文提出的算法能够有效地找出云计算任务调度结果,以完成较好的任务调度。通过多组实验对比,可以得出改进后的算法具有收敛速度快和鲁棒性强等特点。然而,本文提出的算法并未对速度更新公式中的几个参数做动态调整,后续的工作中可以对这些参数进行自适应改进,以期更好地提升算法性能,寻找到更优的调度方案。另外,在实际云计算应用中,不仅要考虑任务的总完成时间,还应综合考虑计算成本、带宽、能耗等因素,这将是今后研究的重点。
