基于非平衡问题的卷积神经网络分类模型
2023-07-07矫桂娥张文俊陈一民
矫桂娥 徐 红 张文俊 陈一民
1(上海大学上海电影学院 上海 200072) 2(上海海洋大学信息学院 上海 201306) 3(上海建桥学院信息技术学院 上海 201306)
0 引 言
在现实生活中,数据集的分布都不是理想的均衡分布,更多的是呈现非平衡分布特性。非平衡问题是指在数据集中不同类别的数据分布差异较大,即存在样本数量多的多数类以及样本数量少的少数类。在分类任务中,传统的分类学习器适合类别平衡分布的数据集,而对于存在非平衡问题的数据集,往往受多数类的影响而导致少数类分类出现错误。但实际应用中,少数类样本的有效分类却是极其重要的,比如银行用户诈骗检测、医疗疾病诊断、客户流失检测、设备故障检测等等[1-5]。因此,准确地判别少数类是非平衡分类问题的一项重要研究内容,目前,研究学者对该类问题的解决方法主要集中在数据以及算法两个层面。
在数据层面上,需要对数据进行初步的分析采样,以达到数据分布平衡目的。但是这种简单的方式生成的新样本具有很大的不确定性,生成的少数类样本质量不高,极易产生过拟合问题。为了解决这一问题,Devi等[6]提出了CorrOV-CSEn算法,将过采样与集成算法AdaBoot相结合,欠采样算法通过舍弃部分多数类样本达到样本类别平衡,而过采样算法是依据某些规律增加少数类样本以达到平衡不同类别,但效果欠佳。熊炫睿等[7]提出了SABER采样算法,将簇内样本平均分类错误率考虑到采样算法中。Park等[8]采用融合过采样与欠采样的算法COUSS处理非平衡数据分类问题,但效果不理想。赵锦阳等[9]提出了SCSMOTE方法,通过在少数类样本中选择出合适的首选样本,在样本中心和候选样本中间生成新样本,克服了简单生成新样本的缺陷,可以避免一定的过拟合,但是该方法合成的新样本有一定的重复性,部分样本会变成噪声样本。因此,有部分研究学者在此基础上将SMOTE和欠采样方法相结合,对少数类进行SMOTE过采样,在多数类中进行随机欠采样,该方法不会过多地生成新的少数类样本,从一定层面上降低了样本噪声的影响。于艳丽等[10]提出了基于异类k距离的边界混合采样算法BHSK,首先异类k距离识别边界,再通过支持度将边界数据细分,最后依次采样。Li等[11]提出了根据损失值来确定可以参与训练的样本的采样方法,该方法对数据集中数据依据样本损失值加权,在抽样操作中被选中的概率由样本权重决定。以上这些方法都是在数据层面的调整,让数据在输入分类模型前就分布平衡,因此很多数据集的样本分布规律与生成类过采样算法生成样本所依据的规律并不相关,所以按照这种过采样方法生成的样本会有很大概率生成噪声样本,这样的采样方法非但起不到提高检测少数类精确率的效果,还会对多数类的判别产生混淆影响,从而影响分类效果,并且降低多数类的正确率。
卷积神经网络是深度学习领域中最出色的网络结构,应用在计算机的各领域中,比如图片分类[12]、目标跟踪[13]和自然语言[14]等方面,因此近年来非平衡问题的研究学者也采用卷积神经网络解决此类问题。卷积神经网络模型以损失函数最小为目标,所以在卷积神经网络处理非平衡数据分类问题时,对于不同类别的数据赋予不同的损失权重,以此更新卷积神经网络的损失函数,以达到损失函数最小化的目的。周丽娜等[15]使用卷积神经网络处理文本分类时,采用特征融合结合交叉熵损失函数;Niu等[16]提出了一种代价敏感重构损失函数,并对引入了正则项;张士川等[17]采用代价敏感损失函数结合孪生网络对暗星系进行分类检测;Miao等[18]在软件缺陷检测中采用代价敏感函数,对不同的样本赋予不同的损失权重。以上是在算法层面对非平衡数据分类问题的研究,但是,上述数据预处理算法只是较为适应数据集,并不能与分类模型更好地融合,损失函数也不能与采样函数相结合发挥最佳的效果。为此我们提出了一种卷积神经网络分类模型CNN-EMWRA-WCELF(Convolutional Neural Network-Expectation Maximization Weighted Resampling Algorithm-Weight Cross Entropy Loss Function),模型中有两个关键算法,其中EMWRA算法对数据集进行采样,该算法对EM算法进行了改进优化,巧妙地将加权采样算法融合进了高斯混合模型中,通过本文所提的EMWRA算法对数据进行预处理,明显降低了训练数据集的不平衡程度。由于EMWRA算法在对原始数据的选择上更加注重少数类的分布特征,采样高质量的少数类新样本,避免了生成大量噪声样本的弊端,使模型分类效果更好。另外,通过本文所提的WCELF函数根据训练样本的分类结果和真实标签,反馈模型的损失,以此达到提升非平衡数据分类准确率。CNN-EMWRA-WCELF模型解决了上述改进的非平衡问题的采样数据混淆模型分类等单一算法对非平衡问题的缺点和不足。
1 本文算法
本文中的分类模型采用的是卷积神经网络模型,在数据预处理阶段提出将加权采样算法融合进高斯混合模型中,得到了一种新的EMWRA算法,综合考虑了数据集中的样本分布,对少数类样本进行更精确地过采样,经过卷积神经网络的训练,损失函数WCELF作为衡量模型分类结果和真实标签的差异程度的目标函数,将根据模型对输出的分类结果赋予样本相应的权重损失并反馈给模型,模型依据损失函数进行下一轮的训练,以此逐步提高模型对于非平衡数据的分类准确性。
CNN-EMWRA-WCELF模型如图1所示:对非平衡数据的分类,本文用到的是卷积神经网络模型,在数据预处理阶段,EMWRA算法将数据按照其整体分布划分为小的高斯混合分类簇,并按照每个簇中的样本分布进行加权采样,将各分类簇中的采样集传入卷积神经网络分类模型中进行分类训练,再根据分类结果依照真实分类结果计算损失函数,最后将结果反馈到卷积神经网络中,并以此修改EMWRA采样结果。
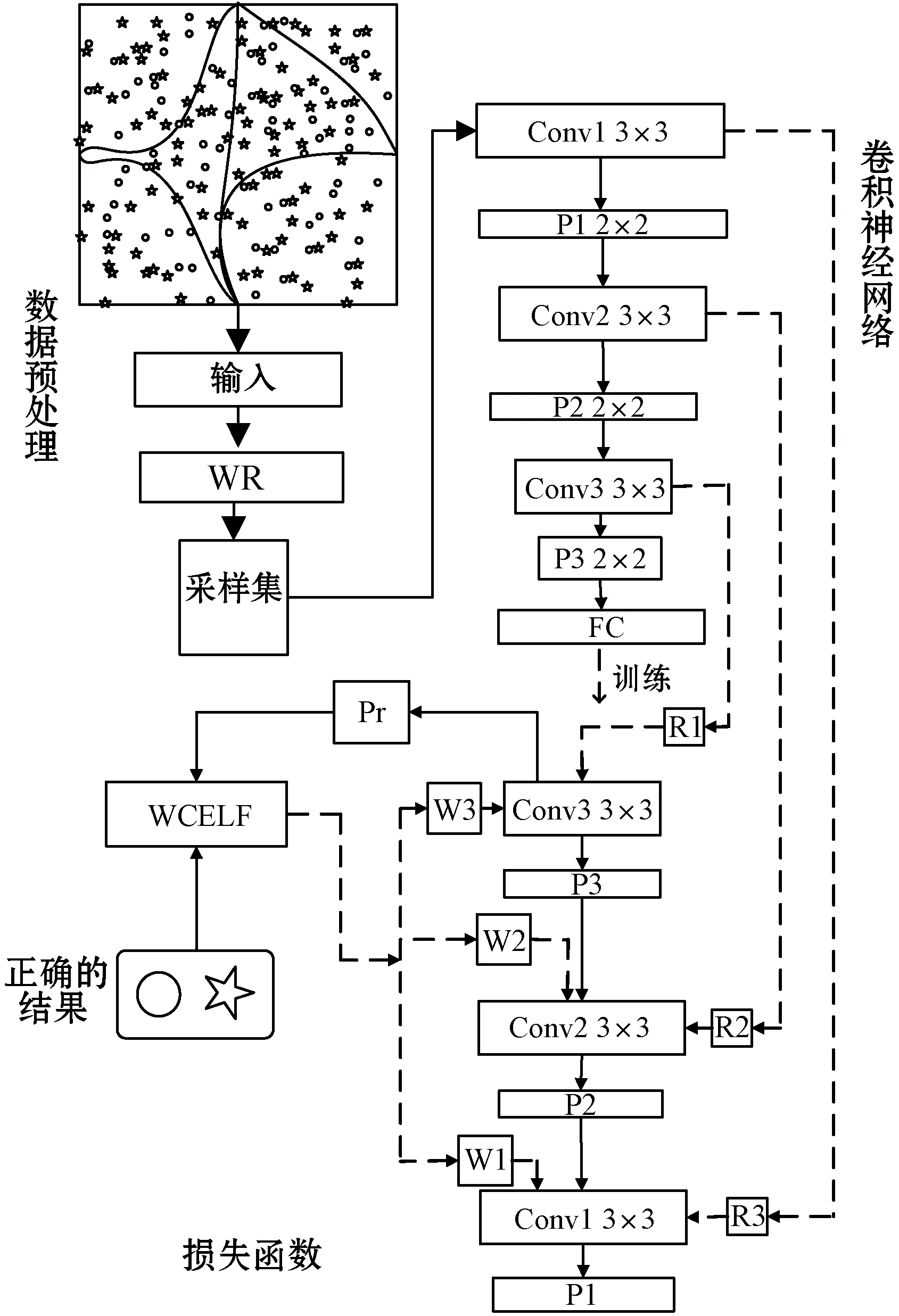
图1 CNN-EMWRA-WCELF模型示意图
本文的EMWRA-WCELF算法的流程如图2所示。可以看出,EMWRA-WCELF具体包括:在训练的初始输入数据集;设定模型训练采样集的大小;高斯混合模型对数据集进行初步分类;根据高斯混合模型原理,通过EM算法求得最佳高斯混合模型的参数,进而得到最佳高斯混合簇;在对每个混合簇进行采样的过程中,会判断簇中的样本分布是否平衡,对样本分布不同的混合簇,有不同的采样方式;在完成对每个混合簇的采样后,将所有的采样结果汇聚到采样集中,分类模型对最终的采样集进行学习训练;WCELF函数根据模型分类结果和样本真实标签,计算损失函数,并反馈给分类模型;如果损失函数上升或者达到了模型训练的最好结果,训练就会停止,将模型的训练参数保存。

图2 EMWRA-WCELF算法流程
1.1 EMWRA
1.1.1 高斯混合模型及核心算法
高斯混合模型[19]是一种概率密度聚类算法,在预测数据分布概率方面有较好的分类效果。高斯混合模型对整个数据集的拟合能力主要依赖于它的构成,高斯混合模型是由多个高斯单模型组成,这一特性可以较好地拟合实际中的数据集,其核心算法是EM算法。EM算法是一类通过迭代进行最大似然估计的优化算法,可以有效地避免数据中的噪声和混合成分所带来的局限性。
因为高斯混合模型的对数据集的整体分布的概括能力,所以我们在采样的初始阶段,用它拟合数据集。设数据集X为n维数据,服从高斯分布,其概率密度函数可表示为:
(1)
式中:μ为数据均值,Σ为n×n协方差矩阵,由此可以将其记录为P(x|μ,Σ)。

(2)
1.1.2EM算法改进提升EMWRA
我们在高斯混合模型核心算法EM基础上对其进行了改进,得到了一种新的算法EMWRA。
在高斯混合模型中,根据数据的先验分布α1,α2,…,αk采样混合样本,我们将混合系数αi表示为采样自第i个高斯混合成分的概率,采样数据集D={d1,d2,…,dn}为在高斯混合模型中采样产生的数据集,设φj∈{1,2,…,k}表示高斯混合簇di的随机变量,其先验概率为P(φj=i)=αi,φj的后验概率根据贝叶斯公式为:
(3)
根据式(2),式(3)可表示为:
(4)
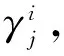
(5)
(6)
(7)
高斯混合算法是高斯混合模型的一种迭代算法,它是根据每个样本点的概率分布对其进行划分,不同于传统的聚类算法根据距离等因素对数据进行类,EM算法是依据它们归属于哪一类而进行划分,所以这种分类策略更适应于复杂数据。
传统加权采样方法是从m个样本集中依据样本权重选择s个样本,每个样本被选中的概率由其相对权重决定,样本ζ被选中的概率如式(8)所示。
(8)
EMWRA在数据预处理阶段,高斯混合模型将数据集划分为一些簇,每个高斯混合分类簇中的数据是不同的。在划分结果中数据可能服从于不同的高斯分布,在每个簇中各类样本的概率分布确定多数类和少数类的交叉情况。
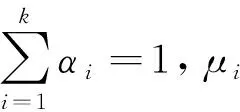
在高斯混合分类簇中,少数类样本的均值μs和多数类样本的均值μd,数据量Q=QS+Qd,样本集的类别分布比例可表示为β=QS/Q。令βi=Qis/Qi,其中i表示是第i个高斯分类簇,i={1,2,…,k}。Qis表示该混合簇中的少数类样本数据量,βi表示高斯混合簇中的非平衡样本比例。
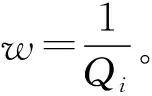
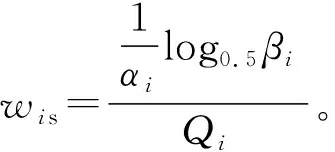
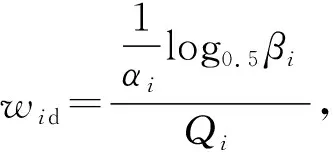
符合情况(2)和(3)的混合簇的样本采样概率计算如式(9)所示。
(9)
每个混合簇采样数量由混合系数αi确定,数据分布不平衡的混合簇中,簇中的少数类样本会依据其权重进行采样。
这样可以根据数据集的整体概率分布,划分出最佳的簇,其中根据αi可以得出整个数据的分布,αi为整个高斯过程的权重,它的大小体现了样本集中的大多数数据的分布范围,可以更加全面地统计样本信息。EMWRA有效避免了对少数类样本进行采样而产生的噪声样本,有效提高了模型对非平衡数据集的分类准确度。
1.2 WCELF函数
为提升卷积神经网络对非平衡数据集的分类性能,在模型的训练过程中,能够根据预测结果与真实标签的差距,得到最佳的模型损失函数,本文提出了一种基于权重交叉熵损失WCELF函数,该损失函数是描述模型分类结果与真实样本标签差距的函数。在二分类任务中,最常用的损失函数是交叉熵损失函数,但是在非平衡分类任务中,该损失函数的效果难以达到最好。因此,我们针对非平衡问题提出了结合样本权重的损失函数WCELF。
交叉熵损失函数[20]一般通用的公式如式(10)所示。
(10)
这里的tθ是样本的真实类别,yθ是模型的预测结果,交叉熵损失函数的大小表示两者的差距。当模型预测值与真实值越接近时,它对应的损失值就越小,分类模型的损失也就越大,值得注意的是,这种损失值的增大是非线性的,由其自身log函数的特性呈现指数增长。
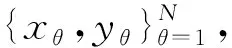
δi=log1.1βi
(11)
式中:βi表示的是样本所在高斯混合簇中的样本分布,在这里i={1,2,…,k}。当该log函数的自变量大于1时,保证了少数类别的权重不过高导致模型分类失衡。
添加了权重的交叉熵损失函数如下:
(12)
WCELF函数根据非平衡数据集的高斯混合簇中的数据分布情况,自适应更新每个高斯混合簇中的样本损失权重。该损失函数在计算训练样本的网络输出值与样本真实标签的同时,考虑样本所在的高斯混合簇,易分类的多数类样本的预测值yp→1,1-yp→0,如此,分类模型的Lwce→0,这确保了多数类的损失相对较少。但是对于部分非正常非平衡高斯混合簇,该簇中的少数类为原始数据集中的多数类,所以该损失函数中δζ会对该高斯混合簇中的多数类赋予一定的代价损失。然而,对于少数类样本预测值yp→0,1-yp→1,且该损失函数考虑到了高斯混合簇中的样本分布δζ,结合EMWRA合理地增加了少数类的代价损失,对非平衡数据分类有积极的影响,但是在提升模型对少数类样本分类精确度的同时,没有降低对多数类数据的分类效果。
损失权重的计算会根据采样值的不同进行自适应更改,根据不同分类簇中的不同样本采样权重,给予不同的损失权重。在此过程中对于部分在高斯混合簇中的非正常不平衡数据集中的多数类,实行同样的少数类损失权重。该损失函数很好地避免了分类模型在平衡少数类样本时,忽略部分易错多数类样本的情况,可以更进一步提升分类模型的准确率。
对该损失函数进行求导可得:
(13)
初始化神经网络模型,按照训练epoch训练数据集,根据输出结果统计样本分类正确率,依照类别权重分别赋予不同样本损失,将损失函数反馈到分类模型中,模型按照式(13)更新得到最佳参数,从而逐步提高分类准确率,最终得到一个最优结果。
2 实验结果与分析
2.1 实验数据集
本文使用kaggle竞赛数据集churn(电信用户流失数据)和Model_churning(银行客户流失数据)进行实验,数据集对客户是否留存进行了分类,这两个数据集属于典型的非平衡问题的数据集。
2.2 评价指标
为更好地处理非平衡数据的分类问题,更全面地衡量模型的分类性能,评价标准既要保证分类的准确率也要保证少数类分类的正确性。本文采用混淆矩阵的三级指标F1调和平均值和G-mean这两个评价标准对模型进行评估,F1的值可以从整体上反映分类的性能,G-mean是用于衡量非平衡数据分类效果的指标。
2.3 实验过程
本文采用PyTorch深度学习框架,搭建卷积神经网络分类学习模型,为降低模型的分类过拟合,在模型训练过程中相对应添加了dropout层,参数为0.5,训练集、验证机与测试集的比例为8∶1∶1,batch_size设置为512。
2.4 实验结果分析
CNN-EMWRA-WCELF卷积神经网络模型的分类结果主要是和整体分类模型的数据分类结果作比较,其中集成学习方法是对结构化数据较为常用的方法,在过往许多kaggle数据比赛成果中,获胜方法都会用到集成学习算法。编码方案采用的是one-hot编码,本文通过竞赛数据集来验证本文提出的卷积神经网络模型CNN-EMWRA-WCELF的分类性能。
在churn和Model_churning两个数据集上,本文对加权损失函数和卷积神经网络在非平衡数据的处理做了对比实验。
损失函数比较结果如图3所示,实线表示交叉熵损失函数,虚线表示WCELF损失函数。损失函数总体都在下降,在银行客户分类中损失函数的差别更为明显,相差在0.2左右。由此可见对损失函数添加类别权重能够很好地降低模型损失,提升模型的分类性能。
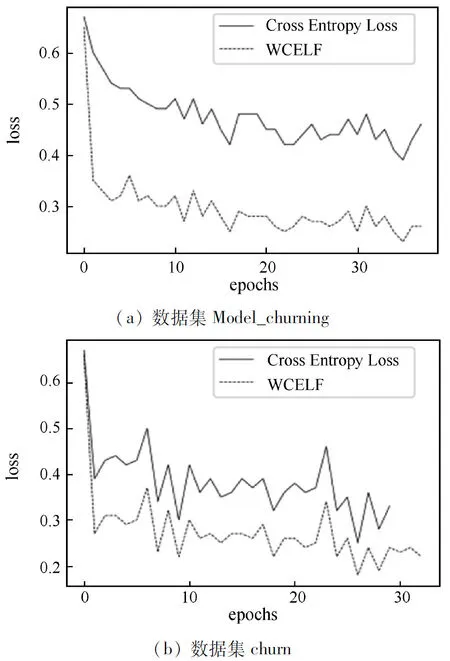
图3 损失函数对比
本文的对照模型是参照文献[7]中的SABER采样算法,分别结合逻辑回归、随机森林,还有集成学习分类模型XGBoost,如LRSABER(逻辑回归SABER分类模型)、RFSABER(随机森林SABER分类模型)、SVMSABER(支持向量机SABER分类模型)、XGBoostSABER(XGBoostSABER分类模型),文献[8]中COUSS采样算法LRCOUSS(逻辑回归COUSS分类模型)、SVMCOUSS(支持向量机COUSS分类模型)等。以上模型都是经典的分类模型,应用范围较广,其中XGBoost模型采用了集成学习思想,这种集弱学习器之长处成强学习器的思想应用在很多数据分析竞赛中,分类效果很好。为体现本文所提算法对神经网络分类性能有所提升,所以本文设置了对卷积网络的对比,首先对比的是在两个数据集上采样算法在分类指标F1和G-mean上的表现,其中CNNSABER(卷积神经网络SABER分类模型)、CNNCOUSS(卷积神经网络COUSS分类模型)和CNNAdaptive-SMOTE(卷积神经网络Adaptive-SMOTE分类模型)是卷积神经网络结合各采样算法的分类模型。表1是上述各分类模型与各采样算法在churn数据集上的分类效果对比。其中CNN-EMWRA-WCELF是本文所提的分类模型。
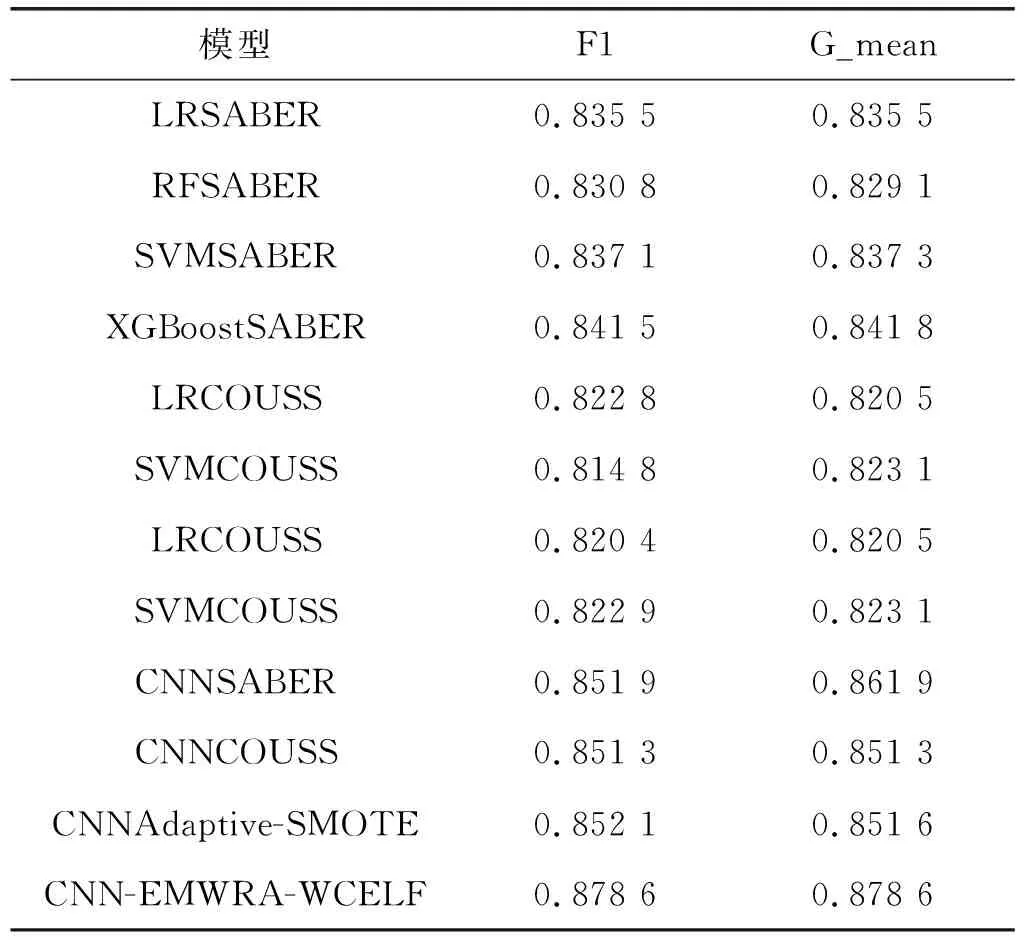
表1 在数据集churn上实验结果
表1中的结果显示了在逻辑回归、支持向量机等传统机器分类模型和卷积神经网络模型结合了SABER和COUSS等采样算法在kaggle电信客户分类数据集上的分类效果。可以得出在F1调和平均值和G-mean值两个评测指标中,卷积神经网络模型的分类性能相比较传统机器学习分类模型有约2%~4%的提升,这个对比结果表明因其高效的特征提取能力,卷积神经网络在数据挖掘和数据分析领域更有优势。在对比采样算法在卷积神经网络模型上的分类效果的三组对比实验中,本文所提采样算法EMWRA让卷积神经网络的分类性能在此基础上又提升了近2%,由这个对比结果可以得出,我们提出的分类模型CNN-EMWRA-WCELF在非平衡数据集中的表现比结合SABER和COUSS等采样算法的分类模型更好。
如表2所示,在银行客户数据集中的结果分析与比较中可以发现,卷积神经网络模型的分类评价指标较传统机器学习如支持向量机等有4%~15%的效果提升,本文的采样算法使得卷积神经网络在评价指标F1和G-mean上提升近2%。而且仅对比卷积神经网络的实验结果也可以看出,简单生成少数类的采样方法算法会产生一些噪声样本,降低模型的分类性能。简单来说,相较于XGBoost等集成分类模型,卷积神经网络模型效果更好一些,而采样算法EMWRA让卷积神经网络的分类性能又提升了2%,在该数据集上CNN-EMWRA-WCELF分类模型的优势更为明显。

表2 在数据集Model_churning上实验对比
3 结 论
在非平衡分类问题的研究中,本文提出的CNN-EMWRA-WCELF分类模型,其中EMWRA是结合高斯混合模型和加权采样的采样方法,该采样算法可以很好地处理样本空间类别重叠的数据集,提升了采样的少数类样本的质量,除此之外还对数据集进行加权采样,使采样集内数据达到类别分布平衡;损失函数WCELF作为衡量模型分类结果和真实标签的差异程度的目标函数,将根据模型对输出的分类结果赋予样本相应的权重损失并反馈给模型,模型依据损失函数进行下一轮的训练,由此可不断提高模型对于非平衡数据的分类准确性。从本文的实验结果来看,卷积神经网络在非平衡数据问题中有着出色的表现,这也验证了近年来研究学者将卷积神经网络应用到非平衡问题中的正确性。除此之外,本文提出的模型整体效果也比其他模型好很多。后续的工作是研究多分类的非平衡分类问题,为处理现实生活中的更多实际问题做出贡献。
