基于语音信号特性的沙漏网络下的人声与伴奏分离算法
2023-07-07龚晓峰雒瑞森
孙 超 余 勤 龚晓峰 雒瑞森
(四川大学电气工程学院 四川 成都 610065)
0 引 言
人工智能的不断发展要求机器能“理解”人类的语言信息,从而使二者间的交互与合作更具便捷性和可操作性。自然语言处理[1]作为二者之间的一种特殊载体,为人工智能领域的发展做出了重要贡献。人声与伴奏分离,是指将混合语音信号中的人声与伴奏分离出来,从而将分离出来的对应源应用于乐器识别、歌词及歌手识别[2]等领域。由于语音信号的构成复杂,所以针对传统语音信号的统计学特征已经不能满足现在工作的需要,近年来,随着神经网络在图像处理领域的成功发展,一些在计算机视觉上效果良好的神经网络也逐步迁移到语音信号处理的领域中来。为了将一维语音信号序列通过神经网络来学习特征信息,可借助短时傅里叶变换(Short Time Fourier Transform,STFT)将一维信号转换成二维频谱图,进而输入到各种神经网络中进行训练和分离。
基于神经网络下的人声与伴奏分离算法主要是从卷积神经网络(Convolution Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)来进行分离的。基于卷积神经网络的算法通过卷积核对语音频谱图来提取谱图的特征信息,用类似于人脑神经元的结构来获得对应谱图的局部感受野,利用得到的人声与伴奏各自有区分度的特征来进行分离。文献[3]利用深度神经网络(Deep Neural Networks,DNNs)来对大量的数据集进行训练,使网络的建模能力增强。文献[4]提出了一种利用卷积神经网络对单通道语音信号进行分离的方法,并且是低延迟的,与多层感知机(Multilayer Perceptron,MLP)相比,缩短了处理时间。对要分离的每个源单独建模一个卷积去噪自动编码器(Convolutional Denoising Autoencoders,CDAEs)[5],并将其他源视为背景噪声等干扰项,也可以解决源分离的任务,并且效果优于前馈神经网络(Feedforward Neural Networks,FNNs)。文献[6]把从医学成像领域设计的U型网络(U-net)迁移到了人声与伴奏分离的任务中,U-net能捕获语音频谱图的精细细节,从而获得高质量的语音信号。由于循环神经网络具有特殊的记忆功能,所以在处理语音信号以及机器翻译等序列型数据上具有优势,文献[7]将循环神经网络和时频掩模二者整合起来,一起来训练神经网络的参数,为分离工作提供了新的思路。董兴宁等[8]利用循环神经网络来处理包含人声和伴奏的混合歌曲,并且设计了在线分离的网页系统。Yuan等[9]将卷积神经网络作为前端来提取语音信号的特征,后端利用循环神经网络来对序列的上下文信息进行建模,分离效果相比单独地利用卷积网络或循环网络有了进一步的提升。
但是大部分的神经网络还比较浅层,对于复杂的语音信号来说,无法提取其内部深层次的语义特征。目前分离工作的主流思路就是利用深度学习的优势,设计更深层次的网络结构,Park等[10]将原本应用于人体姿态估计的沙漏网络[11]迁移到了语音分离的领域,把人体姿态中的不同关节点之间的联系等价成语音信号上下文之间的联系,通过重复的自上而下和自下而上的推理来捕获语音频谱图中的精细细节和全局特征信息,使得迁移后的沙漏网络在人声与伴奏分离的任务上与其他方法相比,达到了最优的效果。
本文在沙漏网络的基础上,结合语音信号的特性,设计一个有助于沙漏网络分离的损失函数,进一步对沙漏网络进行了优化,提出基于语音信号特性的沙漏网络下的人声与伴奏分离算法。在MIR-1K数据集上的结果表明,本文算法超过了原始沙漏网络以及其他方法,并且通过分离后人声和伴奏对应的指标和频谱图来对分离效果进行全面的分析。
1 相关工作
1.1 沙漏神经网络
沙漏神经网络的形状类似于沙漏式,是一种对称的拓扑结构。在人体姿态估计中,重复使用自上而下和自下而上来推断人体的关节点位置,在顶部使用一个跳跃连接,将前后相同分辨率的特征图的信息连接起来,所以沙漏网络可以利用不同尺度下的特征信息和空间信息,充分利用数据带来的各个尺度上的信息。其网络结构如图1所示。在人声与伴奏分离中,这样的拓扑结构可以捕捉语音频谱图中的频率信息和时间信息,获得上下文之间的语义联系。其中图1虚线框为单个沙漏模块,将多个沙漏模块按照端到端的方式连接起来,就构成了堆叠沙漏网络。这种堆叠式的操作可以使前一阶段的沙漏模块得到的信息传递到下一阶段的沙漏模块之中,所以前一阶段的沙漏模块作为下一个沙漏模块的输入可以使整个网络获取语音信号之间的相互关系,从而提升了分离性能。
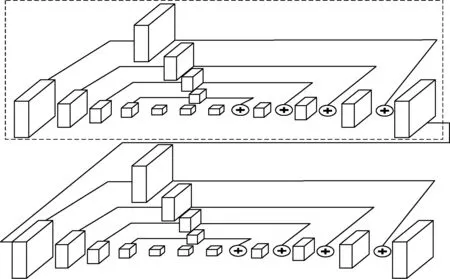
图1 沙漏网络结构
图1虚线框内部为一个四阶的沙漏网络,它是在一阶的基础上嵌套而来的,一阶沙漏网络如图2所示,整体结构分为两个分支,每个分支包含不等的卷积层,随着卷积层的深入来提取语音谱图更深层次的特征信息。假设输入谱图的维度为H×W×M(分别代表图像的高度、宽度、输出通道),上半分支不改变输入谱图的大小(即分辨率仍为H×W),下半分支先通过最大池化进行下采样(/2),使谱图大小减半(即分辨率为((H/2)×(W/2)));再通过最近邻上采样(×2)使谱图恢复成原来大小(即分辨率为H×W)。本文中设置沙漏网络中卷积层的输出通道数(或特征图的数目)统一为256(即M=256)。如图1所示,在沙漏网络中,下半分支通过不断深入的卷积层来提取语音谱图较高层次的特征,上半分支不改变谱图大小,即保留了原有层次的语音特征信息,上下分支最后再通过相加的操作使得不同层次之间的语音信息相融合。
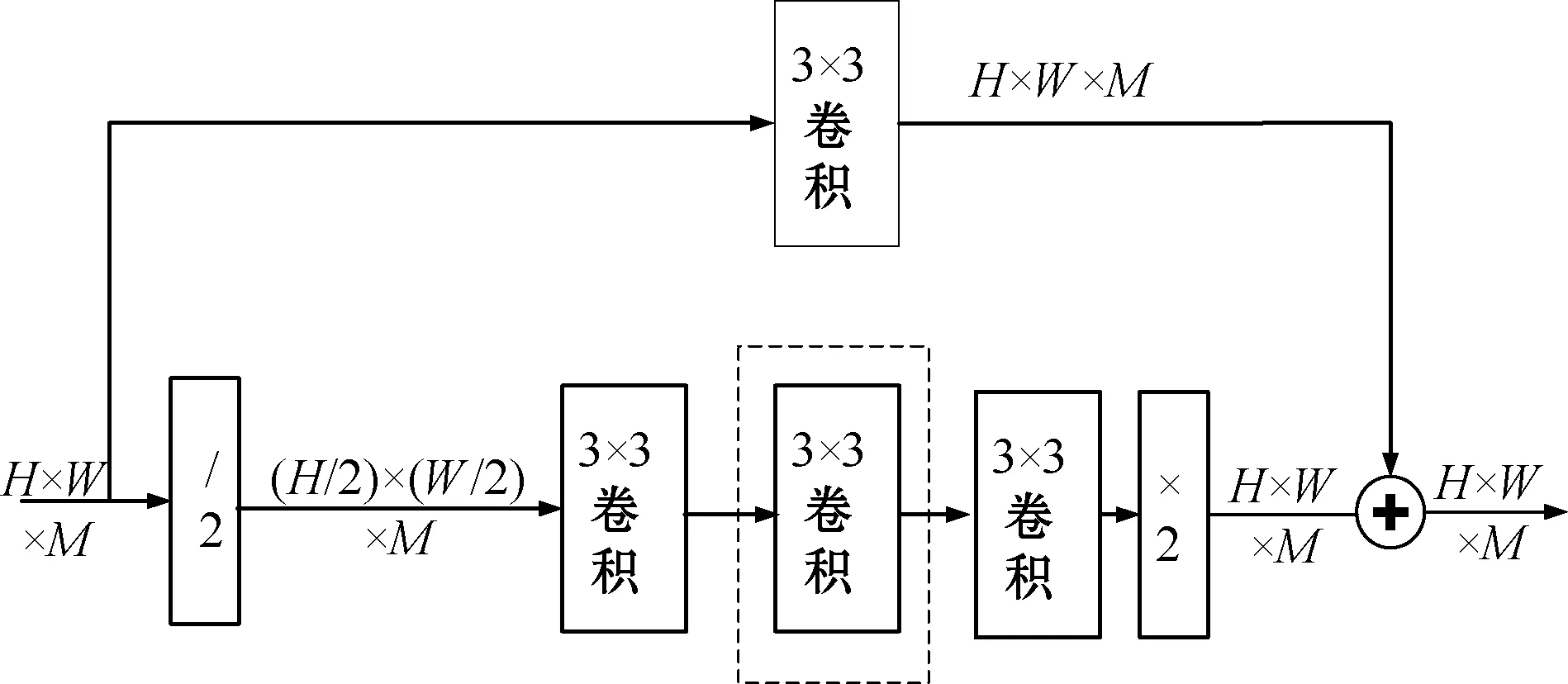
图2 一阶沙漏网络
将一阶沙漏网络下半分支(即图2虚线框内)的卷积结构嵌套成新的一阶沙漏网络,则沙漏网络的阶数会相应升高,称作二阶沙漏网络。对于本文用的四阶沙漏网络,本质上即为四个一阶沙漏网络循环嵌套后的结构,如图3所示。

图3 四阶沙漏网络
1.2 基于语音信号特性的沙漏网络
分离的整体框架如图4所示,我们使用四个四阶沙漏模块堆叠在一起,每个沙漏模块会产生一个损失值,最后将四个损失相加,这种方式也叫做中继监督(Intermediate Supervision)[12]。对于传统的网络来说,损失只是通过对最后的预测值与真实值二者进行均方误差或交叉熵损失等。由于堆叠沙漏网络每个阶段的单独沙漏模块都是独立完整的结构,因此将所有沙漏的损失相加的所预测的精度要远远高于只考虑最后一个沙漏预测的损失值。
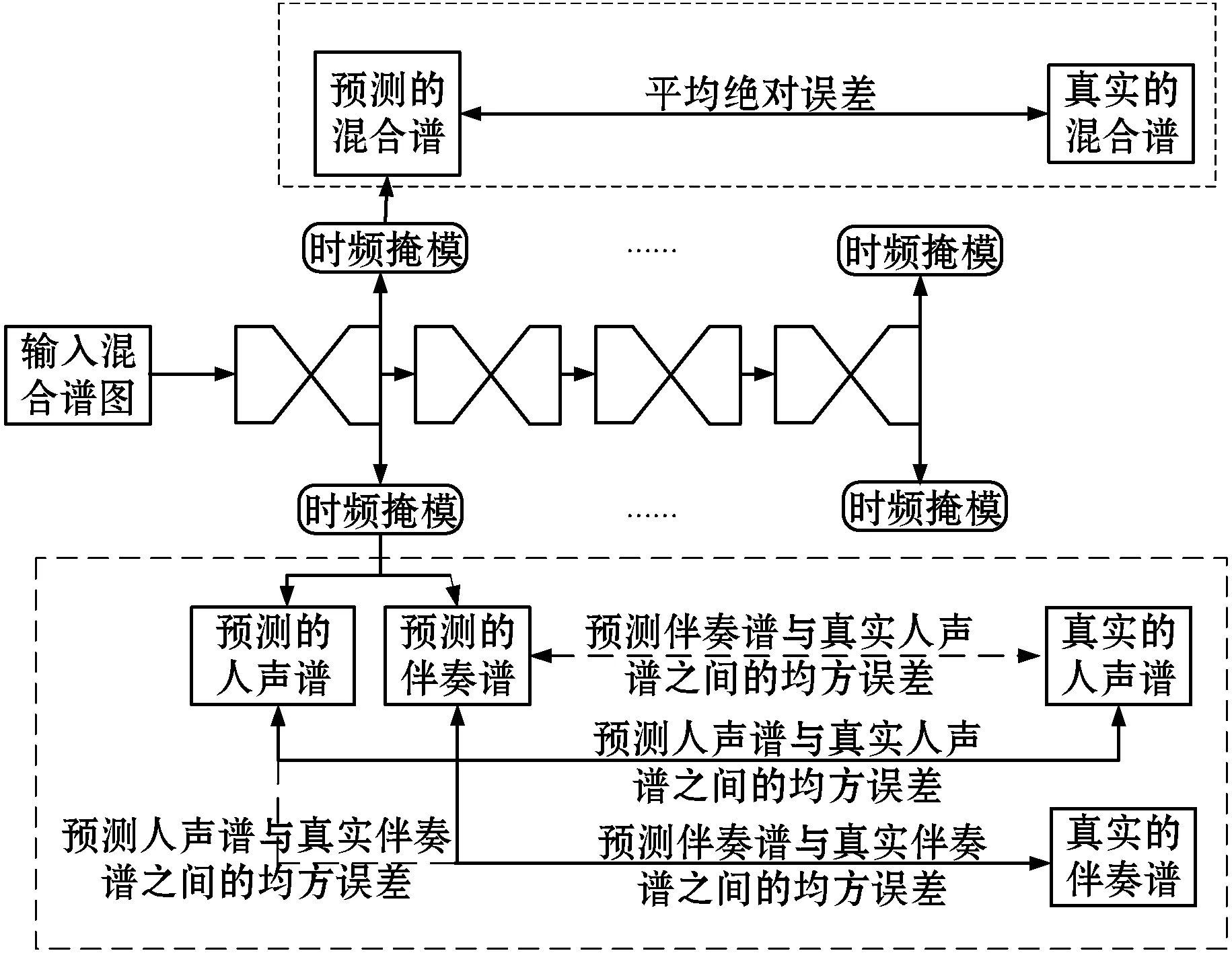
图4 分离的总框架
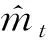
(1)
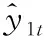
(2)
(3)

(4)
式中:⊙表示矩阵中的元素乘法;L1,1范数是矩阵中各个元素的绝对值之和。由于采用的是4个沙漏模块堆叠而成的结构,故总的损失函数如下:
(5)
式中:j的范围是1~2,对应人声源和伴奏源;k的范围是1~4,分别对应堆叠的四个沙漏模块。
受循环神经网络在人声伴奏分离工作[7,9]的启发,我们针对分离构造了一种新的损失函数,它是在L1,1范数基础上的附加项,如式(6)所示。
(6)
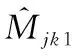
另外,我们还在网络中加入了批处理规范化(Batch Normalization, BN)[14]来调节沙漏神经网络层的输入,稳定沙漏网络训练和学习过程,改善了反向梯度传播。同时在网络中加入Leaky-ReLU作为激活函数,这种激活函数在语音增强和分离等信号处理的领域有着重要的价值。
2 实 验
基于语音信号特性的沙漏网络下的人声与伴奏分离算法是在Python语言下编译的,使用单块型号为Tesla P100的GPU ,深度环境为TensorFlow。
2.1 数据集
我们使用人声与伴奏分离工作上的标准数据集MIR-1K[15],它包括1 000首由110首男性/女性演唱的中国卡拉OK歌曲中提取的4~13 s不等长的音频数据。为了公平比较,我们使用与以前工作相同的男性(Abjones)和女性(Amy)作为训练集,共包含175个音频数据,其余825个音频数据作为测试集。
2.2 评价指标
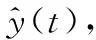
(7)
式中:etarget(t)是预测信号;einterf(t)是干扰信号;enoise(t)是噪声信号;eartif(t)是算法引入的伪像。通过上述分解方法,可以定义评价指标如下:
源-失真比(SDR):
(8)
源-干扰比(SIR):
(9)
源-噪声比(SNR):
(10)
源-算法引入伪像比(SAR):
(11)
标准化的SDR(NSDR)也用于分离性能的评价上,定义如下:
NSDR(Te,To,Tm)=SDR(Te,To)-SDR(Tm,To)
(12)
式中:Te定义为沙漏网络预测的人声/背景音乐;To为原始信号中纯净的人声/背景音乐;Tm为原始混合信号。全局NSDR(GNSDR)、全局SIR(GSIR)和全局SAR(GSAR)分别计算为NSDR、SIR和SAR的加权平均值,其权重为音源长度。另外由于标准数据集不包含噪声项,所以enoise(t)为0。
2.3 实验过程
我们在通过沙漏网络之前,首先要通过傅里叶变换把一维的语音信号转换成二维信号,故要先对语音信号做预处理,统一成大小为512×64的频谱图,主要参数如表1和表2所示。
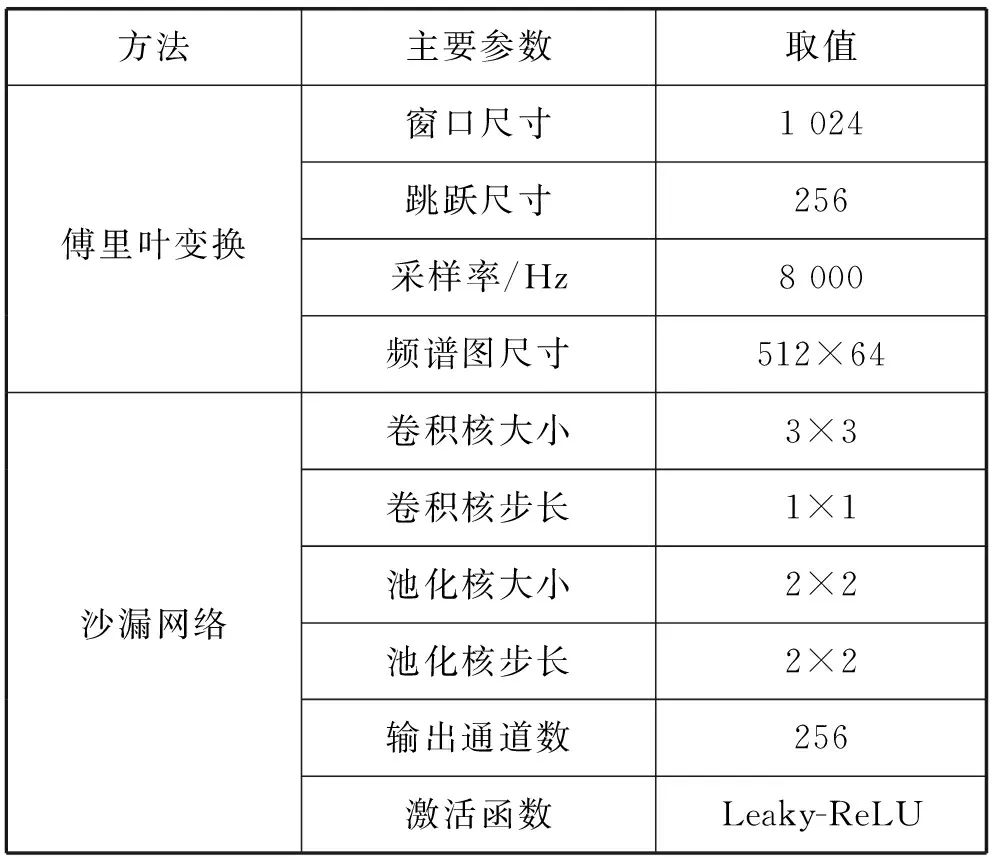
表1 网络主要参数设置
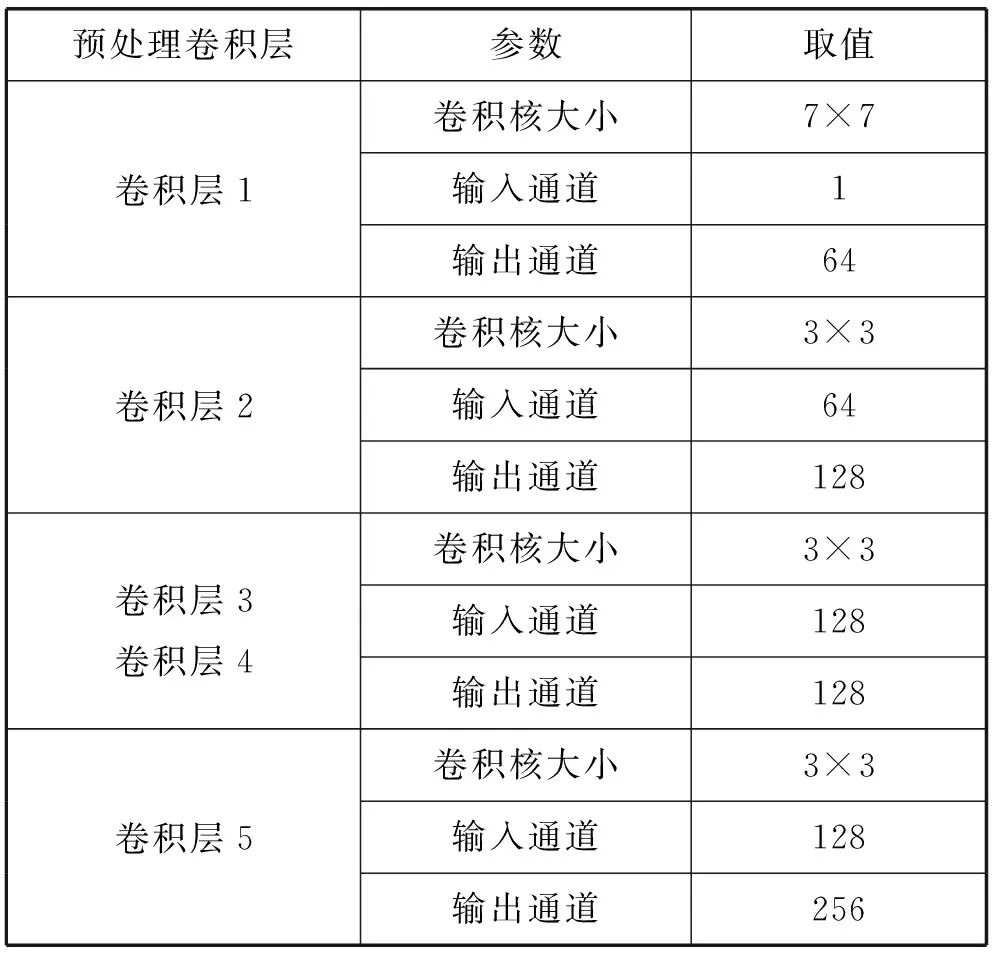
表2 预处理卷积层参数设置
预处理后,我们首先改变了原始的损失函数,进一步添加了符合语音信号特性的附加项,通过损失曲线(图5)可以看出,虽然我们是原有损失函数的附加项,但是反而优化了整个网络的学习过程,使得损失函数的值进一步减小,减小的幅度为原来的1/2左右,并且通过图6和图7可以看出无论是人声还是伴奏的GNSDR、GSIR和GSAR共六项指标的分贝数均为上升,证明分离出来的源的信噪比分贝数更高,即分离出来的源更加纯净。
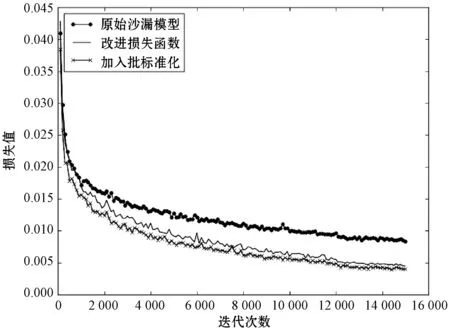
图5 不同改进后的损失函数曲线

图6 分离后的人声在不同模型下的指标
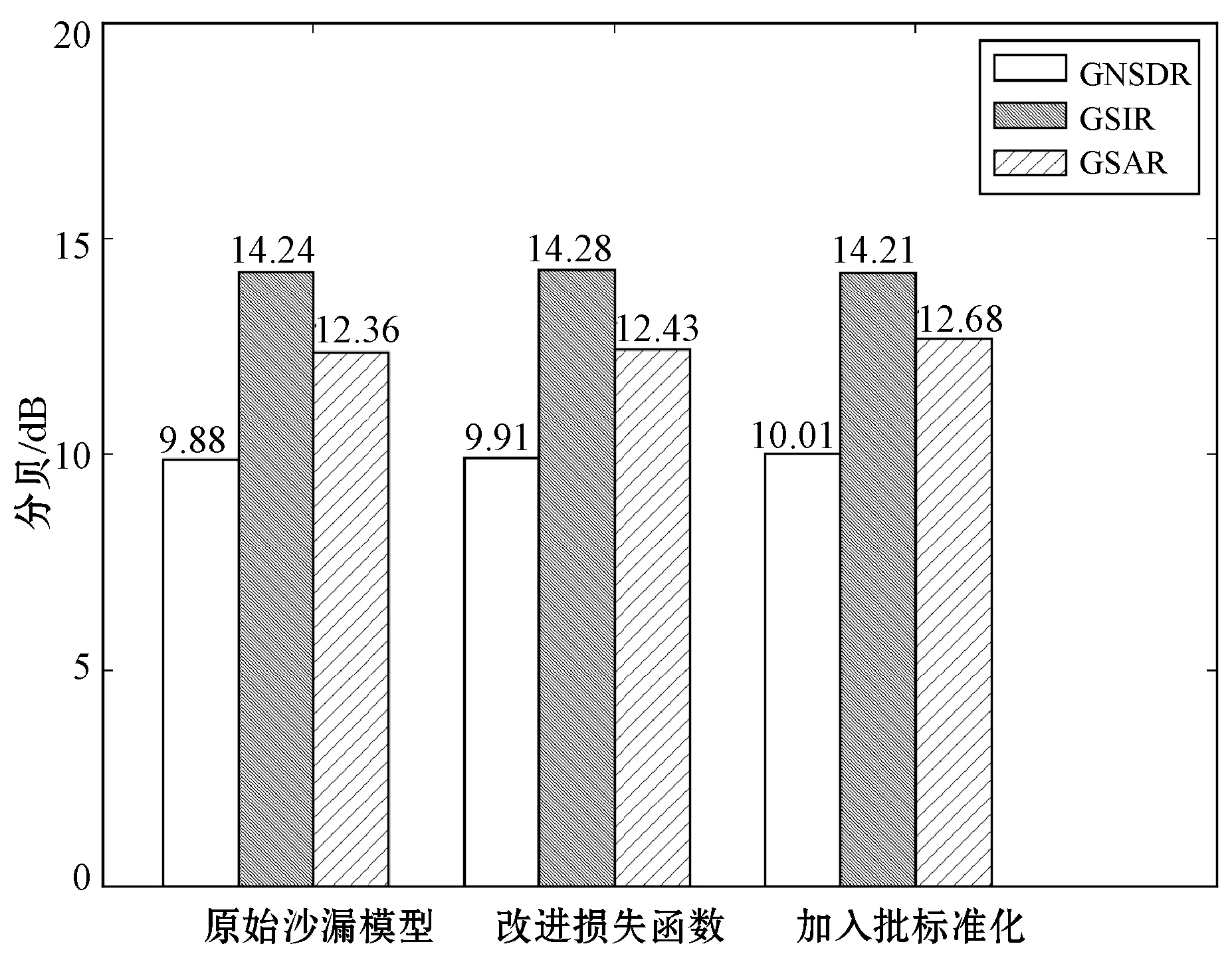
图7 分离后的伴奏在不同模型下的指标
进一步地,我们在改变损失函数基础上又增加了批标准化和Leaky-ReLU激活函数。通过图5的损失曲线可以看出,整个网络的损失值会进一步下降,并且图6和图7对应的评价人声和伴奏分离指标上验证了效果,在人声和伴奏上的GSIR有所下降,但是在0.06~0.07 dB之间,可以忽略不计,此外人声和伴奏的GNSDR和GSAR四项指标均为上升。
2.4 实验结果与分析
最后,将本文算法与目前的分离算法进行了对比,如表3所示,在分离后人声的GNSDR上提高了0.18 dB,GSIR上提高了0.01 dB,GSAR上提高了0.26 dB。如表4所示,在分离后伴奏的GNSDR上提高了0.23 dB,GSIR上提高了0.15 dB,GSAR上提高了0.32 dB。
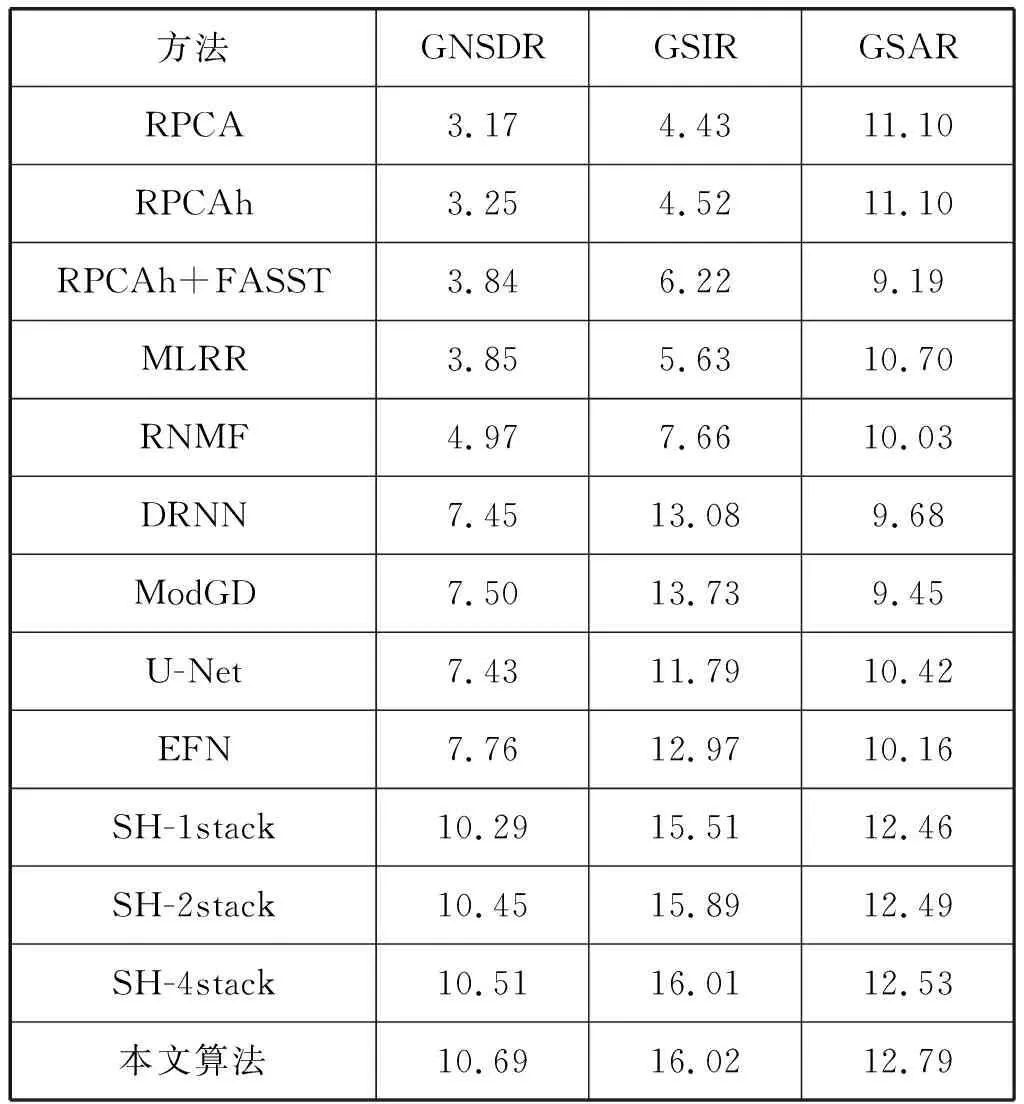
表3 MIR-1K数据集下人声部分不同算法对比 单位:dB
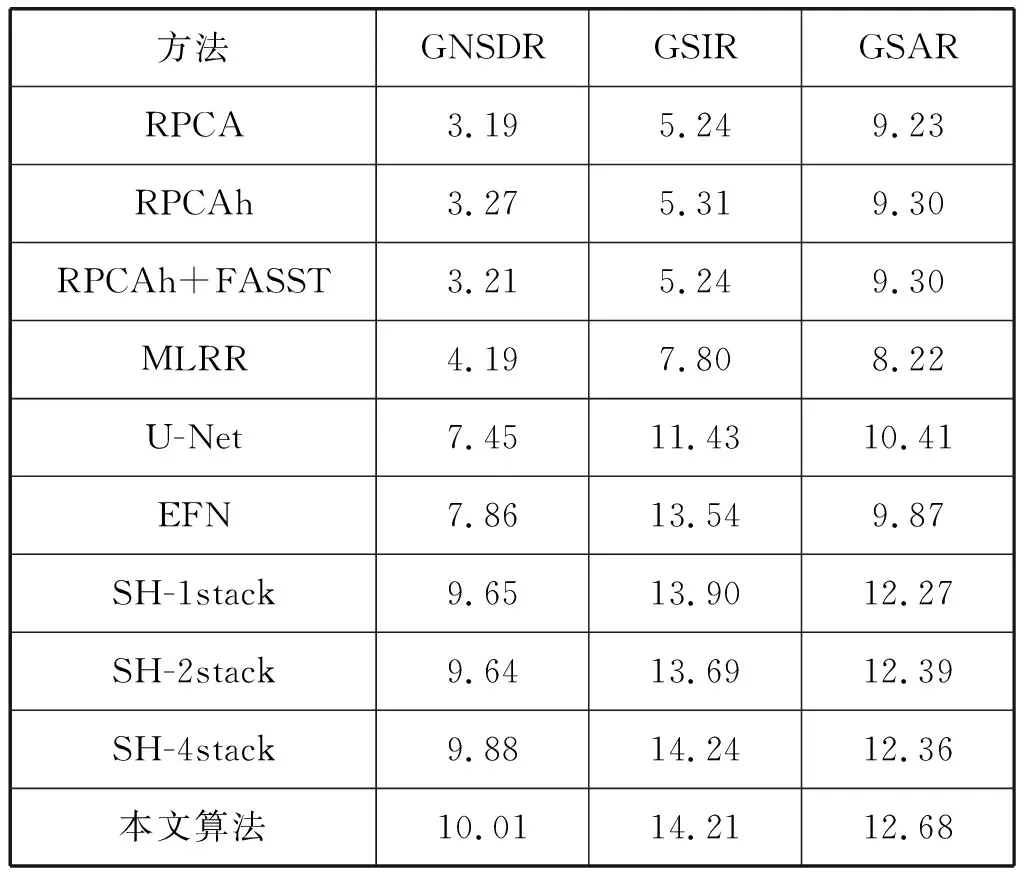
表4 MIR-1K数据集下伴奏部分不同算法对比 单位:dB
可以看出本文算法无论在人声还是伴奏上的分离指标,均比原始沙漏模型有进一步的提高,并且明显优于近年来的其他算法。
我们进一步地输出了原始沙漏模型和本文算法下对应分离出来的人声频谱图和伴奏频谱图,如图8所示。对比本文算法分离出来的人声频谱图(图8(a))和原始沙漏模型分离出来的人声频谱图(图8(c))可得,在0~1.2 s的时间段内的2 000~4 000 Hz的频率范围内,我们产生了更少的伪影;在2.4~4.8 s时间段内捕获了更精细的细节和谐波信号。图8(a)和图8(b)分别是本文算法分离出的人声与伴奏的频谱图;图8(c)和图8(d)分别是原始沙漏模型分离出的人声与伴奏的频谱图;图8(e)和图8(f)分别是真实信号的人声与伴奏的频谱图。
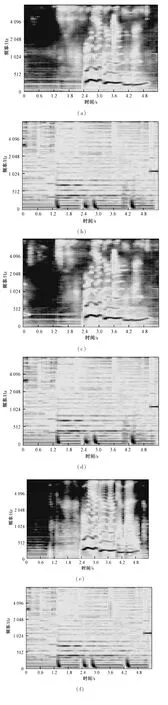
图8 分离算法效果对比
3 结 语
本文提出一种基于语音信号特性的沙漏网络下的人声与伴奏分离算法。针对语音信号的特性,为人声与伴奏的分离构造一种新的损失函数,并且通过在网络中加入了批标准化和Leaky-ReLU激活函数来优化网络结构。在MIR-1K数据集上的实验验证了本文方法的有效性,相比目前其他算法提高了分离性能,减少了不必要的伪影。下一步将考虑不同阶段的沙漏网络之间的关联,从而利用语音信号的时间和空间特征信息,进一步提高分离指标。
