基于蚁群优化ANFIS模型的建筑室温状态和能耗预测
2023-07-07于忠清李劲华
徐 超 于忠清 李劲华
(青岛大学数据科学与软件工程学院 山东 青岛 223800)
0 引 言
建筑是能耗占比最大的领域,我国建筑能耗占比超过了全社会生产所需能耗的1/3[1]。采暖、通风和空调(HVAC)系统能耗占商业建筑能耗一半以上,是建筑能源使用的主要来源。准确的空调运行状态和能耗预测是降低总体能耗的关键。目前关于预测暖通空调系统的能源使用的研究较为广泛,其中使用的方法也层出不穷,包括仿真、优化和基于第一原理的方法。Wei等[2]研究了控制设置与能源消耗以及设施室内空气质量(IAQ)指标之间的关系;文献[3-4]开发了中央电厂暖通空调系统的冷冻机和冰蓄热罐的自适应和预测神经网络模型;Deng等[5]利用深度神经网络(DNN)和粒子群优化算法(PSO)对暖通空调中的能耗模型、室内温度模型和室内湿度模型三种模型进行了建模和优化。
近年来,神经网络模糊推理系统(ANFIS)作为一种更可靠的方法,逐渐被引入到能源管理领域,其独特的建模方法被用来建模具有更高复杂性的非线性关系。除了能源管理领域,ANFIS算法在机械工程、环境工程、空间分析和计算机图形学等方面的应用均表明了其建模方法的优越性[6]。与传统的BP神经网络和浅层神经网络相比,该神经网络采用模糊推理系统来满足数据输入与输出之间的函数映射。
本文研究一种对于暖通空调系统中空气处理单元(AHU)状态和能耗预测的方法。首先,利用提升树(boosting-tree)方法[7]对采集到的AHU实测数据进行参数重要性分析,对实测数据进行降维。通过相关分析[8],确定每个参数对系统状态影响最大的时间增量,将其作为分类学习算法的输入;然后,利用蚁群优化后的模糊神经网络对相关变量与室内温度和总能耗之间的非线性关系进行建模;在算法验证阶段,利用平均绝对误差(MAE)、绝对误差标准差(SDAE)、平均绝对百分比误差(MAPE)和绝对百分比误差标准差(SDAPE)四种指标[9]对ANFIS算法的建模能力进行评价。
1 改进的自适应神经模糊推理系统
1.1 自适应神经模糊推理系统(ANFIS)
Jang[10]于1993年在其文献中首次提出自适应神经模糊推理系统(ANFIS),其由自适应神经网络和模糊逻辑组合形成。自适应神经网络是由节点和定向链路组成的网络结构,整体的输入输出行为由节点连接的可修改参数集合的值决定。模糊推理是利用模糊集理论将给定的输入映射到输出数据集的过程,这种输入-输出的映射关系由一组具有适当隶属函数的模糊IF-THEN规则组成:
规则1:如果x是A1,y是B1,那么f1=p1x+q1y+r1。
规则2:如果x是A2,y是B2,那么f1=p2x+q2y+r2。
其中:A1、A2是x划分的两个模糊集合;B1、B2是y划分的两个模糊集合;{p,q,r}是网络第四层的结论参数;m是规则的条数。
在建立预测模型的学习过程中,函数信号先一直向前遍历,直到第四层,然后通过最小二乘法来估计结论参数(后向参数);然后,在后向遍历中,错误率反向传播,采用蚁群算法来寻找和优化前提参数。它具备了神经网络对非线性系统建模的功能,同时又利用模糊逻辑作为决策工具,解决了神经网络决策过程中的不确定性。
ANFIS网络体系结构一般分为5层,为了便于理解,本文只介绍两个输入v、d和一个输出f下的网络体系结构,基本架构如图1所示。

图1 ANFIS基本结构
第一层:模糊化层。该层的每个输入节点i都是一个生成隶属度的自适应平方节点,平方函数用式(1)和式(2)表示。
O1,i=μV,i(v)j=1,2
(1)
O1,j=μD,j(d)j=1,2
(2)
式中:v和d是系统的输入;O1,i和O1,j表示输出函数;μV,i和μD,j表示隶属函数。如果选择三角隶属函数,则μV,i(v)由式(3)给出。
(3)
式中:{ai,bi,ci}是三角隶属函数的参数,也是系统的前提参数。
第二层:计算激励强度层。输出通过所有输入信号的乘积来计算,用式(4)表示。
O2,i=wi=μV,i(v)·μD,j(d)i=1,2
(4)
式中:wi是规则的激励强度。一般来说,任何执行模糊T-范数运算符都可以作为这一层的节点函数。
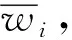
(5)
第四层:规则输出层。该层提供输出值y,这是规则推理的结果,输出见式(6)。
(6)
式中:pi、qi和ri是结果(或后向)参数。
第五层:最终输出层。该层汇总了来自第四层的所有输入,并将模糊分类结果转换为明晰的值。这一层计算所有传入信号的总和(式(7))。
(7)
在众多的应用场景中,ANFIS始终存在着收敛速度慢、反向传播搜索空间大、拟合不充分、预测精度不高等缺点,这就需要技术人员采用合适的进化算法来优化其网络训练过程。本文采用蚁群算法优化ANFIS内部参数,既能保证算法的收敛速度和性能的稳定性,又能避免参数陷入局部最优,大大增强了训练过程的准确性和鲁棒性。
1.2 蚁群优化算法
蚁群优化算法(ACO)[11]是由Dorigo针对模拟退火(AS)的各种改进算法进行总结的基础上提出的一个用于求解旅行商(TSP)等NP难问题的启发式方法。算法的灵感来自于自然界蚁群的觅食行为,这些蚂蚁会在地面上留下信息素,以便为其他蚁群成员标出一些有利的路径,指引后面蚂蚁的觅食行进方向,蚁群优化算法就是利用类似的机制来解决寻优问题[12-13]。
蚁群优化算法的主要过程如下:在每次迭代时,所有在迭代中建立连接的m只蚂蚁都会更新信息素值,也就是说,在旅行商每次经过的每条路径上面都会产生信息素的变化,如连接城市i和j的边的信息素τij更新方法如式(8)所示。
τij(n+1)=(1-ρ)·τij(n)+Δτij
(8)
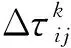
(9)
式中:Q为常数;Lk为蚂蚁k构造的行程长度。
蚂蚁在构建解的过程中,通过随机机制选择下面要访问的城市。当蚂蚁k在城市i中,并构造了部分解sp时,其前往城市j的概率为:
(10)
式中:N(sp)为可行分量的集合,即边(i,l),其中l为蚂蚁k尚未访问过的城市。参数α和β控制信息素相对于启发式信息ηij的相对重要性,由式(11)给出。
(11)
式中:dij为城市i与j之间的距离。
1.3 ACO-ANFIS模型算法
与一般神经网络特性一样,ANFIS训练过程实际上就是找到一组近(最)优的参数组合,从而使得系统预测值与实际值误差最小。如果参数选择不当,会导致整个算法收敛性能低下,训练周期过长。本文利用蚁群优化算法和最小二乘法对ANFIS的前提参数和结论参数进行寻优。
将ANFIS中待优化的前提参数{ai,bi,ci}用其自身的最值(Wmin,Wmax)界定,并等分成div份,每份中的元素用集合Iai、Ibi、Ici表示。每只蚂蚁从集合Iai的第j个元素Iaij出发,在Ibi和Ici集合中寻找一个元素Ibik、Icil作为路径。在蚂蚁进行搜索时,每个集合中的元素选择是相互独立的,每只蚂蚁从第一个元素出发,根据所有参数集合中元素的信息素选择一个元素。当蚂蚁在所有集合中都寻找到了一个元素后,就到达了食物源,各参数的元素组合{Iaij,Ibik,Icil}也就形成了此次寻找食物的路径。之后将选择的路径元素代入网络中,输出此次路径选择的结果和误差,根据误差大小进一步调节各元素信息素,重复此过程,直到满足迭代停止条件。
ACO-ANFIS算法的具体流程如下:
(1) 将输入向量根据各自的隶属度函数进行模糊化处理,将所得的向量作为系统的输入。
(3) 启动蚂蚁。每只蚂蚁从集合Iai的第j元素Iaij出发,按式(10)确定蚂蚁行进路径的概率p,直到所有蚂蚁都到达食物源。

(12)
式中:T和P分别表示实际值和预测值。
(5) 根据式(8)更新路径上的信息素,显然,步骤(4)得到的Fiti越小,该路径上的信息素增加越多。
(6) 若迭代次数Nc>Nmax,则循环结束,输出最优的一组前提参数集合。否则转至步骤(3)更新最优解。
(7) 将前一步所得到的最优参数解作为ANFIS的前提参数,借助ANFIS算法进一步训练网络,直到满足误差精度要求。
用蚁群优化算法和最小二乘法优化ANFIS的前提参数和结论参数,找到两类参数的近最优解,既能保证算法的收敛稳定性,又能避免参数陷入局部最优。这种方法兼具ANFIS的非线性映射能力和蚁群优化算法的全局搜索寻优能力,大大增强了训练过程的准确性和鲁棒性。ACO-ANFIS算法流程如图2所示。

图2 ACO-ANFIS算法流程
2 实验与结果分析
2.1 数据采集和预处理
本文中所使用的数据是从本市某大型医院暖通空调空气处理单元运行机组收集的,采集数据中包含系统运行状态下各设备的特征数据和外部气象数据,数据传感器每隔15 min进行一次当前时刻的数据采集。AHU系统基本原理如图3所示,其中供/回气格栅用于建筑物内的空气循环,冷却管和加热管用于循环水的冷热交换。

图3 AHU基本原理
在建模阶段,将收集到的数据经预处理和随机采样后,分为训练集(数据集80%)和测试集(数据集20%),并由此建立了暖通空调系统能耗预测模型。数据集说明在表1中列出。

表1 数据集说明
在建立预测模型之前,需要对采集的数据进行参数选择以确保所得模型的可理解性、可伸缩性和准确性。表2列出了建模所需的17个模型候选参数。参数选择的方法是对与预测模型输出有关的模型参数进行重要性排序,从而找出与模型输出关系最密切的模型变量并达到数据降维的目的,常用的参数选择算法有包装器(Wrapper)、增强树(Boosting-Tree)和相关性分析算法等,本文采用Boosting-Tree算法来进行参数选择和降维。表3和表4显示了通过增强树算法分析得出的与系统状态和能耗相关性最大的几组参数描述及其对应的等级和特征重要度,将重要度大于40的变量作为系统的最终输入。式(13)给出了参数的特征重要度计算方法,特征i的全局重要度通过特征i在单棵树中的重要度的平均值来衡量。

表2 模型候选参数

表3 能耗预测模型所选择输入参数的特征重要度
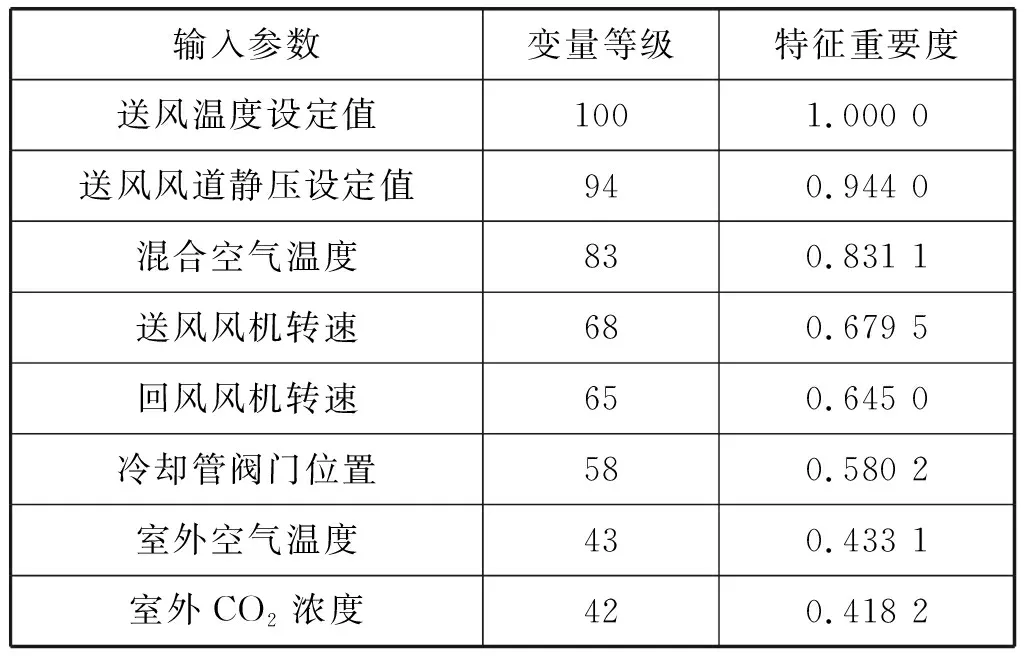
表4 状态模型所选择输入参数的特征重要度
(13)
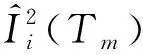
特征i在单棵树中的重要度如下:
(14)
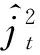
2.2 预测模型制定
由于暖通空调系统状态是动态的,系统当前的状态和能耗受系统参数的过去值影响很大,设计中通过对模型候选参数的相关分析,确定了系统状态和能耗与在不同时间步长下系统输入过去值的关系。采用增强树等相关性分析算法确定每个参数的时滞(即确定与系统能耗关系最大的几组不同时间步长的输入参数),并确定对系统状态影响最大的时间增量。表5和表6分别列出了能耗预测模型和室内温度预测模型最终所选择的带时滞输入参数描述。
表5 t+T时刻能耗预测模型参数描述

表6 t+T时刻室内温度预测模型参数描述
本文所构建的能耗和状态模型如式(15)和式(16)所示。
y(t+T)=f1(y(t),y(t-T),T(t),x1(t+T),
x2(t+T),v3(t-T),v3(t),
v4(t-T),v4(t),u1(t),u2(t))
(15)
T(t+T)=f2(T(t),T(t-T),x1(t+T),
x2(t+T),v5(t),v6(t),v7(t),
v8(t),u3(t),u4(t))
(16)
式中:y(t+T)表示暖通空调系统能耗;T(t+T)表示室内温度。
在实际实验过程中可以发现,利用ACO-ANFIS方法进行曲线拟合时只需60~80次即可保证曲线收敛,而未经优化的ANFIS收敛周期相对要长得多,甚至存在不收敛的状况。图4中分别给出了ANFIS、ACO-ANFIS训练过程中室内温度和能耗的误差曲线。可以看出,相对于原始ANFIS算法而言,ACO-ANFIS算法的收敛过程更快,所需要的迭代次数更少,进一步验证了ACO-ANFIS方法在与同类非线性系统数据拟合算法中的优越性,且拟合精度高的特点也从误差曲线中得以体现。

图4 室内温度和能耗的训练误差曲线
2.3 效果验证
为了评估训练后的ACO-ANFIS算法构建的预测模型性能,利用式(17)-式(20)中定义的四个指标来进行评价:平均绝对误差(MAE)、绝对误差标准差(SDAE)、平均绝对百分比误差(MAPE)和绝对百分比误差标准差(SDAPE)。
(17)
(18)
(19)
(20)
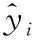
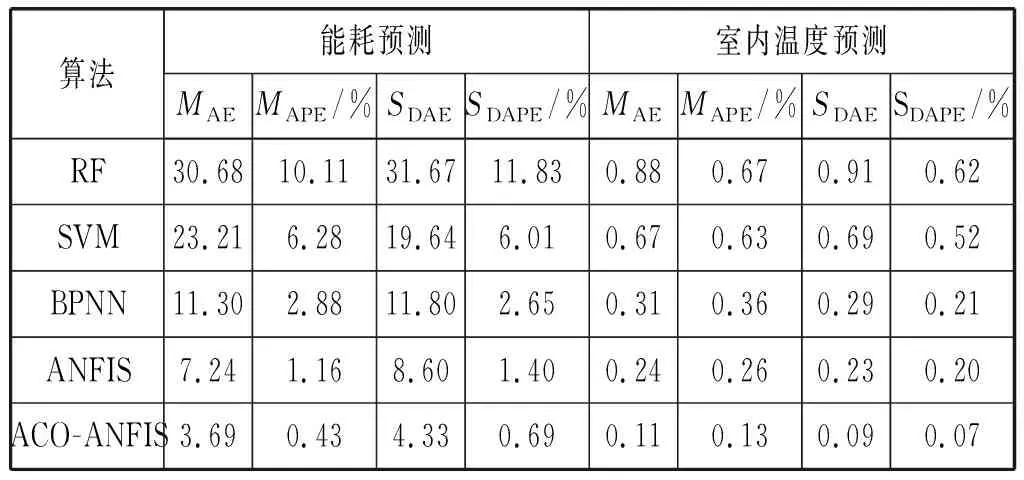
表7 不同预测方法效果对比
图5和图6对比了测试数据集中的100个数据实例的室内温度和能耗的预测值和实际值,可以看出,ACO-ANFIS算法能够成功地识别能耗、室内温度、可控变量和不可控变量之间的非线性关系。通过ACO-ANFIS预测模型得到的预测值更加接近具体能耗的实测值,其预测性能超过传统ANFIS方法。
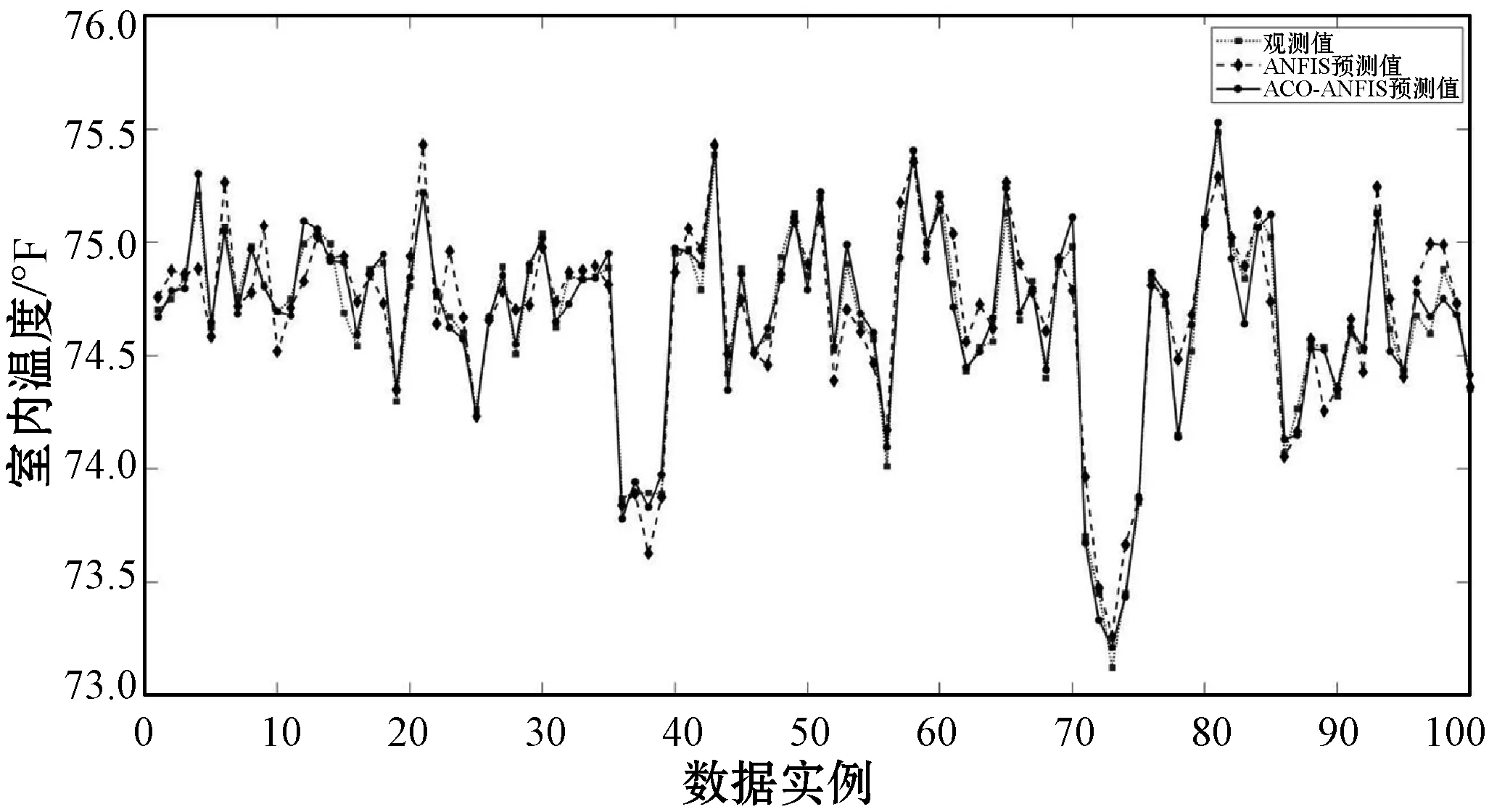
图5 室内温度实际值和预测值对比

图6 能耗的实际值和预测值对比
3 结 语
本文研究一种ACO-ANFIS非线性预测方法,并将该方法应用于建筑能耗预测领域。首先,增强树和相关分析算法确定神经网络训练的输入;其次,利用蚁群优化算法和最小二乘法对训练过程中的前提参数和结论参数进行寻优,通过反向传播误差对参数组进行了一步优化,建立系统参数与状态、能耗之间的非线性模型;最后,利用四种指标对模型预测能力进行评价,从验证结果来看,ACO-ANFIS算法对于空调等非线性系统的建模能力更强,预测精度也明显高于其他方法。
在实际应用中,有些复杂的建筑往往需要考虑更多变的因素,如时变性、随机性和地域气候性等,这就需要更多的优化算法混合来进一步提升ANFIS的预测能力。
