基于随机森林算法对企业信用信息中预警特征识别的研究
2023-07-06周二磊陆进宇马江涛郑岩马晓威
周二磊 陆进宇 马江涛 郑岩 马晓威
近年来,随着国家政务大数据的汇聚,企业的信用信息逐渐丰富,除包括企业基本信息外,逐步将动态经营、监督管理、社会舆情、投诉举报等多个维度信息纳入信用体系,为构建科学、精准的信用预测预警模型奠定基础。为强化信用监管和社会监督,促进企业自律,2021年国家市场监管总局制订《严重违法失信企业名单管理办法》,企业一旦列为严重违法失信企业名单(俗称“黑名单”),将会面临严重后果。因此,有必要对企业提前预警,并对预警特征值定量判断,一方面,有利于监管部门建立科学的评分体系,提升监管的精准度,并在日常监管中重点关注某些市场特征,避免市场上出现大量不稳定因素;另一方面,有利于企业在经营中高度关注预警指标,避免列入“黑名单”。
随机森林算法模型作为集成学习的一种,能够处理高维度数据,较为快速地实现预测功能,且能反映每个特征值的权重,形成“预警性”指标。以往研究中,刘玉航等通过优化参数组合,建立随机森林模型,有效预测食品检验不合格指标并对其分类。张家伟等通过加权策略对过采样和随机森林进行改进,结果显示能够提升少数类样本的分类准确率和整体分类性能。马梦晨等以340所上市公司28个信用风险指标为研究对象,采用不同机器学习算法进行预测,结果显示随机森林预测准确率最高。王朝辉等利用后剪枝的随机森林进行特征选择,并利用改进Q-learning和XGBoost算法,使模型具有更高的分类准确率。杨庆振通过大规模数据训练,利用随机森林算法,对“黑名单”相关的特征值进行抽取和排序。马晓君等在对企业信用评级时提出基于加权随机森林模型,验证得出其评级准确率优于传统的统计模型。现实中企业信用风险数据具有不平衡性,为此,于勤丽等提出一种改进的SMOTE 过采样方法,避免少数类过度聚集在少数类中心,实现对不平衡数据的处理,提升模型训练效果。此外,有关研究表明使用随机森林算法在多种不平衡数据分类场景和其他工程领域应用中取得了良好的效果,模型泛化能力强。
随机森林算法模型在风险预测中的各项评估指标表现较好,且无需过多考虑特征间多重共线性,能够较为快速处理多维度、大批量数据。但现有研究中,多侧重于算法本身的改良,应用的实验数据较少,特征维度较小,缺乏将研究成果运用在更大规模数据、更多维度特征的应用场景。本研究将以河南省市场监管部门归集的50万个企业的数据和80个信用领域的风险指标为来源,通过对不均衡数据的处理,比较随机森林等机器学习算法模型的有效性,从而识别和量化风险指标项,为政府部门的监管执法和企业自律提供有力依据。
一、方法与预处理
(一)随机森林基本原理
随机森林是一种有监督的算法模型,该模型通过建立学习器构建装袋集成,生成若干个训练集;然后对于每个训练集构造决策树作为弱评估器,其分裂节点往往不追求信息增益最大值,而是在特征中随机抽取部分特征并找到最优解实施分裂;最后重复迭代,形成由若干棵决策树组成的森林,按照多数投票机制,将决策树分类结果整合,多数决策树的判定结果就是最终随机森林模型的分类结果。随机森林基于集成思想,可以有效避免过拟合。同时,通过随机森林可以计算出特征值对模型的贡献率,从而得出特征的定量权重。
(二)数据采集
采集河南省市场监督管理局“企业信用风险分类监管平台”中,截止2022年12月31日归集的企业信用数据,从中随机抽取50万个企业的80个完整指标项信息。参照国家市场监管部门对企业信用风险的解释,企业信用风险信息共5类,分别为基本因素,包含企业规模、企业年龄、企业背景等10项基础特征信息,反映基于企业群体特征所表现出的风险因素;动态因素,包含企业准入许可、登记备案、年报公示、经营状况、纳税社保、知识产权等方面的40项行为信息,反映基于行为特征所表现出的风险因素;监管因素,包含行政检查、行政处罚、诉讼信息、经营异常、黑名单、失信被执行人等方面16项信息,反映基于历史监管记录所表现出的风险因素;关联因素,包含企业相关人员违法失信和关联企业违法失信等9项信息,反映基于企业关联关系所表现出的风险因素;社会评价因素,包含投诉举报、舆情评价和社会关注度等5项信息,反映基于社会评价信息所表现出的风险因素。数据来源中50万个企业数据项均为完整字段,无需清洗处理,为数据建模奠定良好基础。
(三)指标项编码
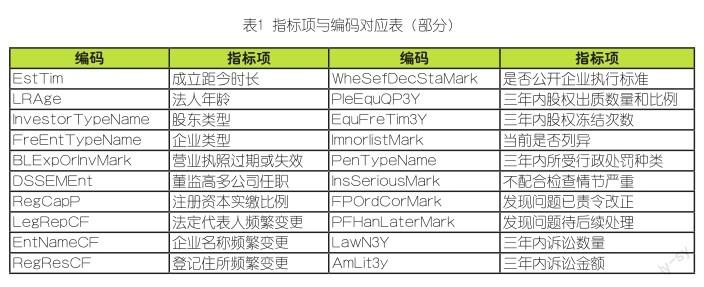
将抽取的数据指标项逐一编码,其中,以“黑名单”作为输出标签,将其余79个信用风险指标项作为样本数据的特征项,如表1所示。
(四)數据预处理
1. 数据分箱
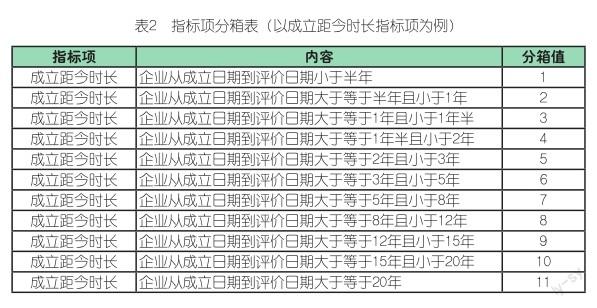
数据分箱(Binning)作为数据预处理的一部分,也被称为离散分箱或数据分段。数据分箱本质就是把数据按特定的规则进行分组,实现数据的离散化,增强数据稳定性,减少过拟合。参照市场监管部门《企业信用风险分类标准》,将80个指标项按照不同的数值进行数据分箱(见表2)。
2. 不平衡数据处理
通过计算,在50万条企业数据中,“黑名单”企业数据仅占3%。因此,该样本数据极不平衡,在数据预处理中采用过采样(SMOTE)方法使数据达到平衡。SMOTE是一种综合采样人工合成数据算法,用于解决数据类别不平衡问题,主要做法是在特征空间中,在少数类临近点之间放置合成点,不断重复直至数据平衡。本次实验中,SMOTE策略设置为0.1。
二、结果与分析
(一)实验仿真
本实验采用Anaconda3中的Jupyter Notebook作为工具,通过调用Scikit-learn库构建算法模型。对随机森林训练时,将79个指标项作为特征值(data)输入,将“黑名单”作为标签输出(target),抽取样本训练模型,对特征进行节点分裂,采用固定随机种子方式(参数random_state=90),生成若干棵决策树,从而生成随机森林。
(二)评估指标
“黑名单”数据属于少数类数据,为检验模型的有效性及泛化能力,通过模型的预测精确度(Precision)、召回率(Recall)及F1值进行分析,观察模型效果。


其中,P代表的是正类样本的数量,N是负类样本的数量。因此,TP(true positive)代表正例预测正确的个数,FP(falsepositive)代表负例预测错误的个数,FN(falsenegative)代表正例预测错误的个数。
(三)随机森林模型的参数优化
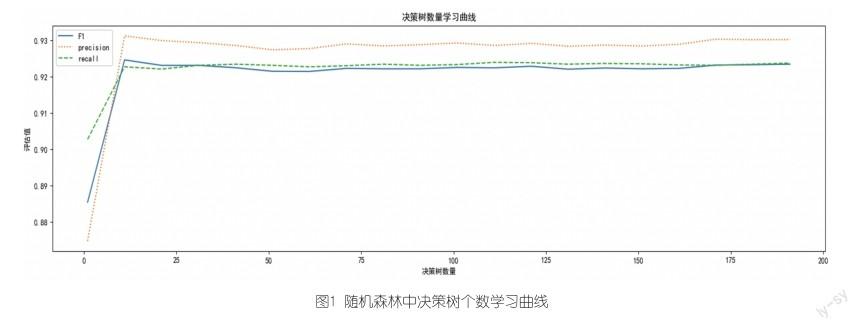
采用学习曲线和网格搜索方式遍历超参数组合,通过十折交叉验证,返回最优参数。第一步,调试决策树个数,学习曲线图如图1,采用F1值为评估标准,得到最佳决策树个数为11,F1值为0.925。
第二步,采用网格搜索方式,以F1值评估为主,精确度、召回率评估为辅,按照“最大深度”、“最大特征”、“分枝后子节点最小样本数”、“分枝节点包含最小样本数”的顺序逐步调整参数。

其中t代表给定的节点,i代表标签的任意分类,c表示叶子节点上标签类别的个数,c-1表示标签的索引,P(i|t)代表标签分类i在节点t上所占的比例。通过网格搜索,推荐采用基尼系數,F1值为0.928。
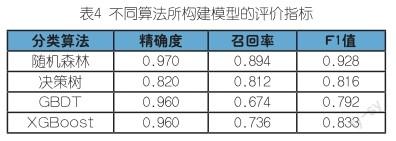
(四)实验对比
将以上训练好的模型,分别与决策树、GBDT、XGBoost算法所构建的模型对比,通过评价指标观察随机森林模型在精确度、召回率、F1值有较高优势。
(五)结果分析
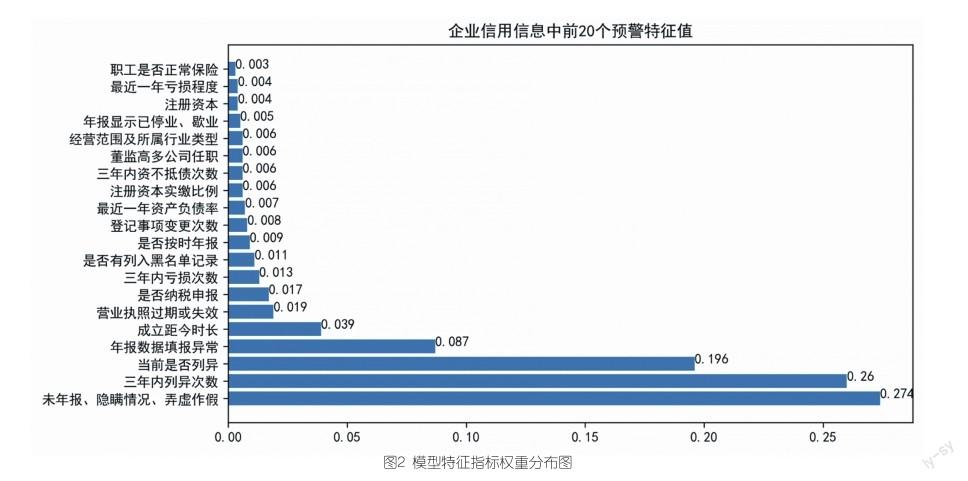
利用已训练好的随机森林,查看每个特征值的贡献率,得出企业信用信息中预警特征权重及排序,图2为排名前20名的预警特征及权重值。
三、结论与讨论
从结果可以看到,“未年报、隐瞒情况、弄虚作假”、“三年内列异次数”、“当前是否列异”、“年报数据填报异常”、“成立距今时长”等5项指标占有较高权重,符合执法监管部门的经验认知。本研究在实际中的意义,一是能够为政府监管部门提供有用信息,构建企业信用风险分类监管评分体系,改变大规模、运动式的监管,提升监管的精准性和科学性,同时辅助监管部门定期发布经营警示性信息,避免市场上出现大量“黑名单”企业;二是辅助企业针对预警特征值,提前感知“危险”因素,调整经营状况,避免造成经济损失。
本研究是以河南省市场监管部门截止2022年12月的企业信用信息作为源数据集,未来能否将模型扩展至更多省份、更长时间跨度,将成为下一步研究的重点。
作者单位:周二磊,河南省政务大数据中心;陆进宇,河南省平台经济发展指导中心;马江涛,郑州轻工业大学计算机与通信工程学院;郑岩,河南省政务大数据中心;马晓威,河南省平台经济发展指导中心。
基金项目:国家市场监督管理总局科研项目:基于大数据技术的食品经营主体风险分类管理关键技术研究(编号:2021MK067);河南省科技攻关项目:食品生产企业信用风险分类和智能识别方法研究(编号:222102310515);河南省市场监督管理局科技计划项目:市场监管大数据分析应用(编号:2021sj119)。
