基于多分支上下文融合的空对地目标检测算法*
2023-07-05何明朱梓涵翟绪龙翟政郝程鹏
何明 ,朱梓涵,,翟绪龙 ,翟政 ,郝程鹏
☞目标特性与探测跟踪技术☜
基于多分支上下文融合的空对地目标检测算法*
何明1,朱梓涵1,2,翟绪龙2,翟政1,郝程鹏3
(1.陆军工程大学 指挥控制工程学院,江苏 南京 210007; 2.联勤保障部队沈阳联勤保障中心,辽宁 沈阳 110000;3.中国科学院声学研究所,北京 100190)
无人机的智能应用是当下研究的热点,为实现高效实时的无人机对地目标检测,提出了一种应用于边缘设备的轻量级空对地目标检测算法MBCF-YOLO。引入深度可分离卷积,优化原有的骨干网络。在颈部网络中添加嵌入循环注意力机制的小目标检测分支,提高对小微目标的检测精度和特征融合的能力。将焦点损失函数与损失秩挖掘结合,改进原有的损失函数,以改善空对地数据集的数据失衡问题。对该算法模型进行了多组对照实验以及实机应用,结果表明,与当前其他算法相比,MBCF-YOLO算法在VisDrone2021数据集上的准确性和延迟之间实现了更好的平衡。
空对地目标检测;网络轻量化;循环注意力机制;小目标检测;特征融合
0 引言
近年来,无人集群技术在军事领域得到了广泛应用,作为实现战场互联的高效节点[1],无人驾驶飞行器(unmanned aerial vehicle,UAV)因其机动灵活且战场生存能力强的优势,成为研究的热点。在2022年2月末爆发的俄乌军事冲突中,大量无人机直接介入侦察遥感、斩首打击、毁伤评估等任务[2],取得了不俗战果,使得军用无人机在战场之外得到了更多的关注。引入机器视觉等新兴传感技术,可进一步发掘UAV的军事应用潜力,由此催生的空对地目标检测任务是当前研究的热点问题[3],该任务可将UAV的拍摄对象(人员,车辆,建筑物等)进行定位和分类,实现后续的目标评估及毁伤打击。
国内外研究者致力于设计高效的目标检测框架结构,如单阶段全卷积模型FCOS[4]、无锚框轻量化模型Nanodet[5]、YOLO-RET[6]等,然而此类模型多是基于COCO、VOC等通用数据集进行训练,对于空对地目标检测这一特定场景仍存在两方面的现实问题:
(1) 硬件成本问题。现有算法模型网络层数较多,参数量较大,而无人机所搭载的边缘设备由于功耗限制,计算能力有限,要达到实时高精度的空对地目标检测仍存在一定难度。
(2) 前背景的不平衡。具体表现为目标尺度的不平衡和样本的不平衡,在空对地目标检测数据集Visdrone2021中,同种类别的物体在不同背景中尺寸变化较大,不同类别的物体样本数量也并不均衡,模型难以对所有前景对象进行训练,以致影响检测精度。为解决上述问题,本文在YOLOv5模型的基础上重新设计适用于无人机设备的多分支上下文融合算法MBCF-YOLO(multi-branch context fusion YOLO),以实现高效实时的空对地目标检测。所做主要工作概括如下:
(1) 针对无人机设备算力有限的问题,引入深度可分离卷积(depthwise separable convolution)和词干采样模块(StemBlock),重新搭建轻量化的骨干网络,优化推理速度保证特征提取能力,实现实时检测。
(2) 针对小微目标检测困难以及物体尺度变化大的问题,在不改变输入图像分辨率,添加了小尺度目标检测头分支,用于放大感受野内的特征图。为了均衡模型参数和预测精度,设计了即插即用的上下文信息融合模块,用于改进模型颈部网络的特征融合性能。
(3) 针对样本数量不均衡的问题,结合焦点损失和损失秩挖掘,构造新的损失函数,用来均衡训练过程中不同类别样本的学习损失,消除样本数量差异造成的偏向性,从而学习到更为本质的特征。
1 相关工作
1.1 模型轻量化
当前关于目标检测轻量化方面的研究主要是针对模型的网络结构。国内外学者通过引入逐点卷积、分组卷积等方式降低运算量,提出了Mobilenet[7]、GhostNet[8]和ShuffleNet[9]等一系列表现优异的轻量化网络模型,但参数的减少容易造成语义特征信息的丢失,因此需要颈部网络对不同阶段提取的特征图进行再处理,实现感受野之间的信息聚合。
1.2 上下文融合
在无人机图像中,大范围的覆盖区域往往包含复杂多样的背景,而卷积神经网络在进行特征提取时,仅针对当前感受野内的像素,很难提取到上下文语义信息和全局特征,近些年注意力机制在计算机视觉任务中表现出优异的性能,如卷积注意力[10](convolutional block attention module,CBAM)、通道注意力[11](channel attention,CA)、坐标注意力(coordinate attention,CA)[12]等机制,在获取全局信息方面有不俗效果。
2 MBCF-YOLO算法
如图1所示,本文所提MBCF-YOLO的整体框架,可分为轻量化骨干网络、上下文融合的颈部网络和多分支检测头3部分。
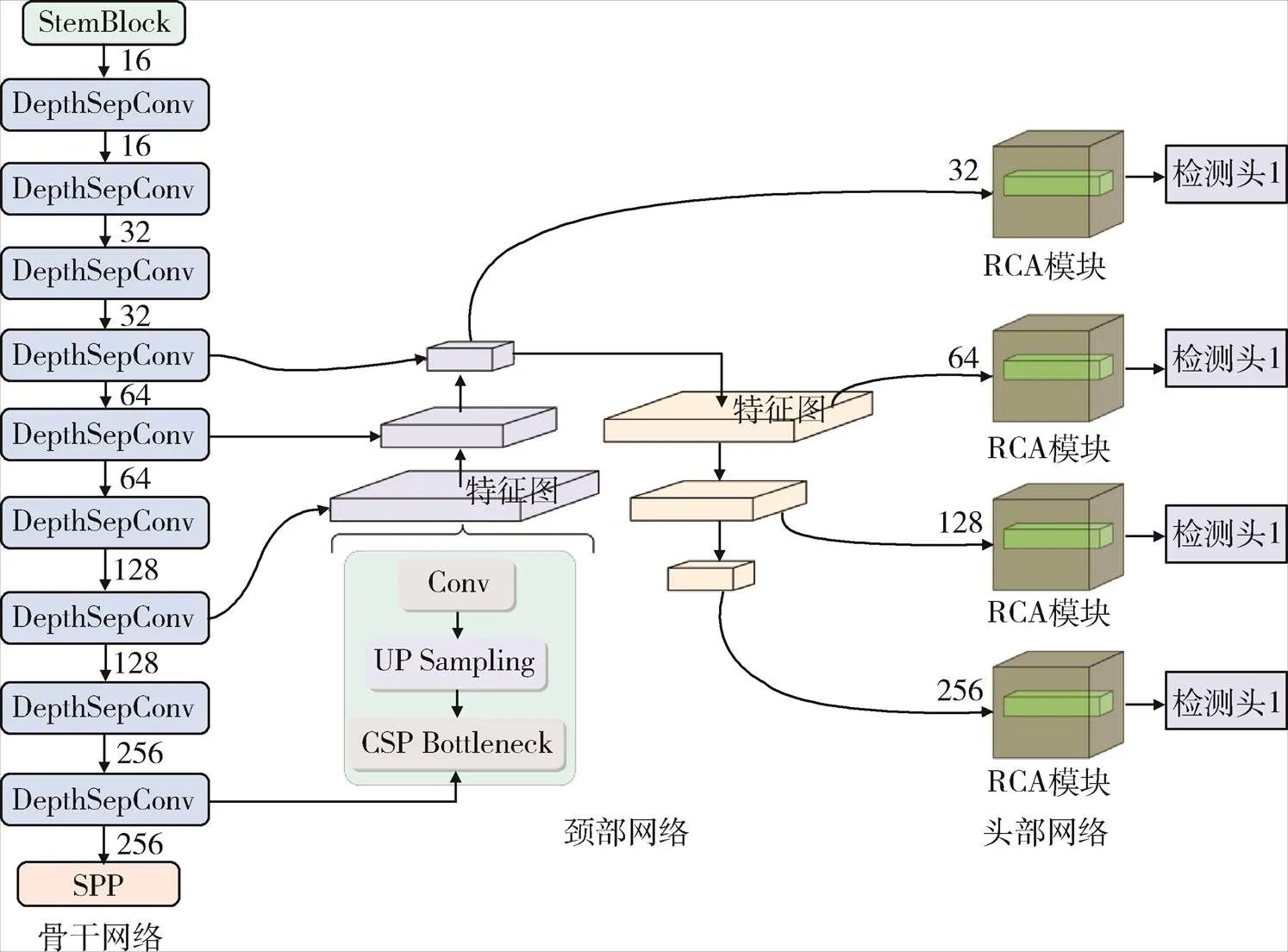
图1 MBCF-YOLO算法框架图
2.1 骨干网络
实践表明,骨干网络是提取数据特征的关键组件,因此设计一个轻量高效的骨干网络至关重要,如图2所示,改进后的骨干网络首先通过词干采样模块进行双重下采样,将两个分支的输出按通道维度进行拼接,通过堆叠的深度可分离卷积模块对特征图的通道逐一运算,而后使用1×1点卷积对不同特征图在相同位置上的信息进行加权操作,从而保证最终输出的特征图在尺度缩小后仍具备足够的语义信息。
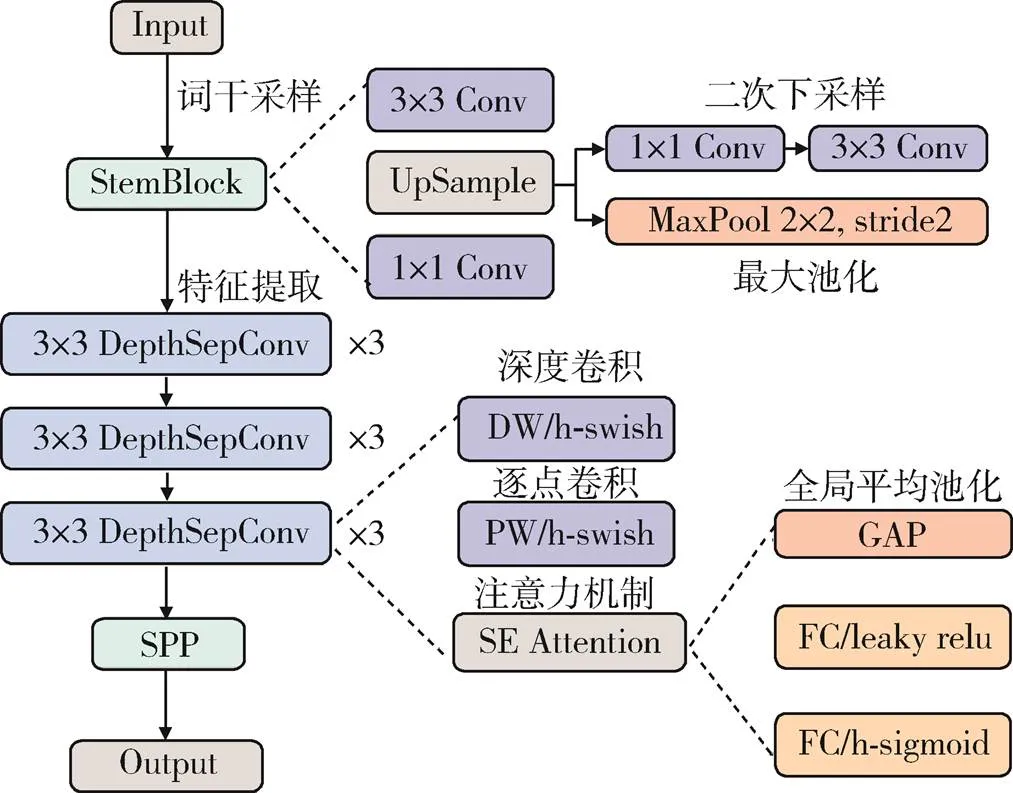
图2 骨干网络示意图
2.2 多分支上下文融合模块
在COCO数据集中以32像素×32像素和96像素×96像素为标准,将图像中的物体分为小、中、大目标。因此在无人机目标检测数据集VisDrone2021中有60%以上的检测对象为小目标。
为提高算法对小物体的检测精度,本文设计了多分支上下文融合机构,核心思想是在颈部网络中增加小目标检测分支,采样更大的特征图并用更小的锚框进行检测,降低背景的影响。同时为了保证精简后网络的信息提取能力,在分支中添加循环自注意力算法以保证检测精度,该算法具体流程如下。
综上所述,本文所提的RCA模块其计算流程如算法1所示。
算法1:RCA模块
#根据得到的权重更新特征图
2.3 损失函数
在VisDrone2021图像数据集中,不同类别目标的数量并不均衡,如行人类别样本数量为79 337,而三轮车类别样本数量为4 812。原有YOLOv5损失函数很难处理此类长尾分布[13]问题。为解决该问题,本文将焦点损失函数[14]和损失秩挖掘[15]结合,使网络更加关注样本较少的类别。


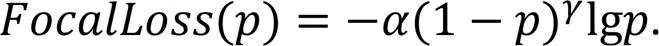


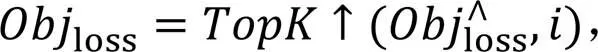
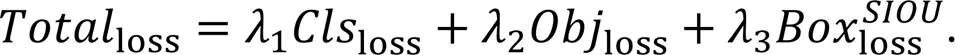
由于MBCF-YOLO在颈部网络添加了检测小微目标的多分支检测头,因此在训练阶段将改进后的损失函数应用于多分支检测头,使其适用于4种不同尺度检测对象的特征映射。
3 实验与结果分析
3.1 数据集
本文采用VisDrone2021数据集[15],用来验证所提MBCF-YOLO算法的综合性能。该数据集共8 629张图像,图像种类有10类,分别为:行人、自行车、人、汽车、卡车、敞篷三轮车、三轮车、面包车、摩托车、公交车。数据集的分配比例是训练集6 471张、验证集548张、测试集1 610张。
3.2 实验环境
本文实验在Windows10 X64操作系统下进行,CPU为Intel i9 10900K@3.20GHz,GPU为NVIDIA RTX3090@24GB,内存为32GB,语言环境为Python 3.8.5,在深度学习框架Pytorch 1.8.0下进行训练。具体的训练参数设置为:训练时输入图像大小为640×640,批处理量(Batchsize)为16,为防止模型过拟合,训练轮数(Epochs)为100,优化方式选择随机梯度下降(SGD),初始学习率为0.01,采用Mosaic操作进行数据增强。
3.3 评价指标
实验采用mAP、模型推理速度GFLOPs等作为模型性能的评价指标。其中mAP值是指在多类目标检测中根据每个类的准确率和召回率所得到的平均精度指标,是目标检测任务的通用评价指标。
3.4 实验结果分析
(1) 网络模型对比实验
为了更好地比较本文所提MBCF-YOLO算法的综合性能,选取规模大小近似的5种网络模型:YOLOv5-Nano、YOLOX-Tiny、YOLOv7-Tiny、Faster R-CNN-1xFPN、RetinaNet-ResNet18进行对比实验,最终结果如表1所示。
结果显示,由于VisDrone2021数据集包含的小微目标数量较多,传统的单阶段目标检测算法如RetinaNet-Resnet18的性能表现并不是很好,在测试集上的mAP值仅有17.7%。而采用无锚框机制的YOLOX-Tiny算法在测试集上的mAP值为16.8%,对小微目标的检测效果一般。YOLOv7-Tiny算法采用了模型缩放等增强机制,因此检测精度值最高,但其优秀的性能表现也需要更高的推理速度。对比来看,本文所提的MBCF-YOLO算法在推理速度仅有2.9GFLOPs的情况下,mAP值达到了22.3%,在参数量、计算量与检测精度之间实现较好平衡。
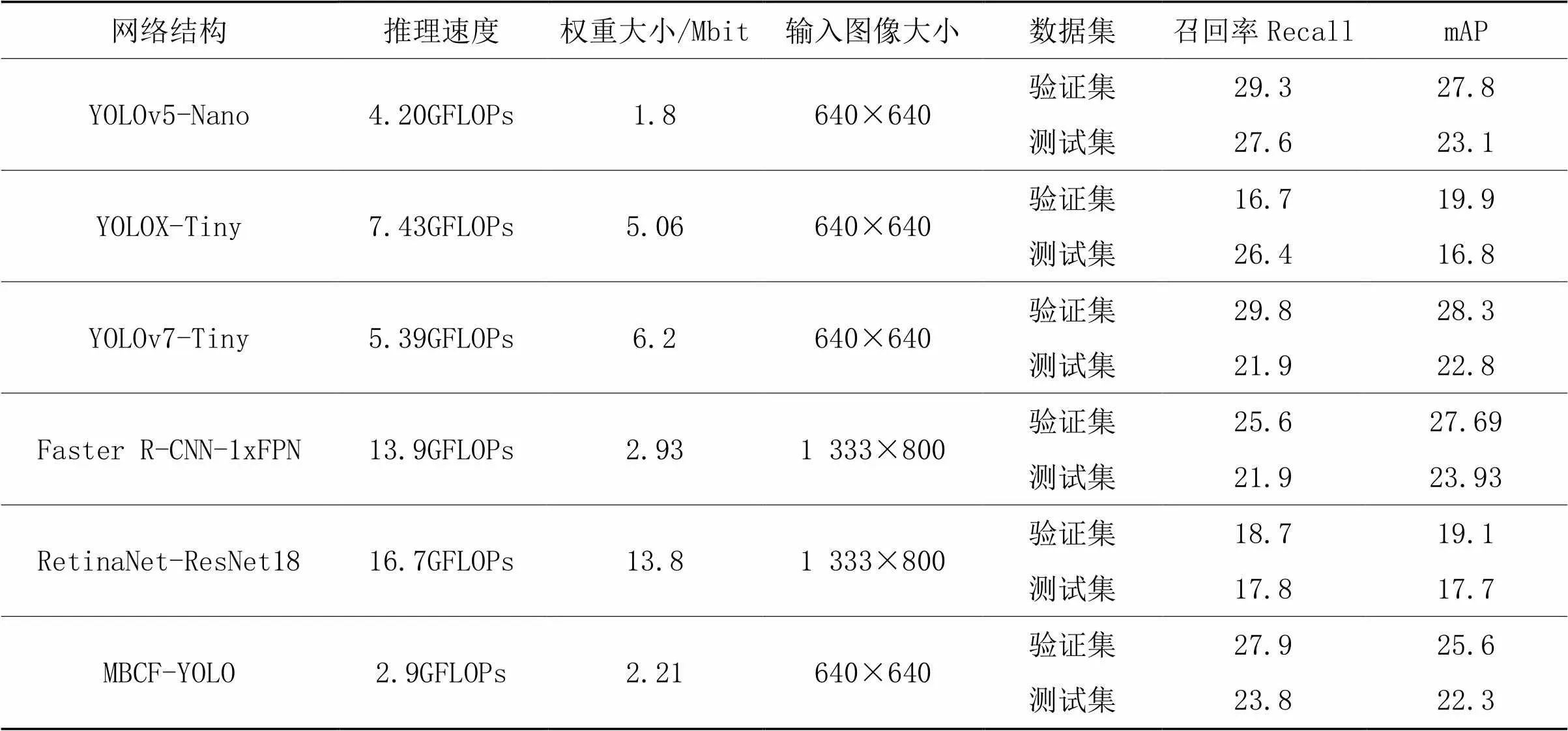
表1 不同网络性能对比
(2) 消融实验
为了验证本文所提出的各个模块的实际作用,本文设置了6组消融实验。具体的设置细节为:实验组1作为对照基线,为原有YOLOv5模型进行网络结构精简后的模型;实验组2、3、4为单模块对比实验,分别在实验1的基础上添加损失秩挖掘函数、RCA模块和小目标检测分支;实验组5在添加小目标检测分支的基础上融入RCA模块,实验组6继续添加改进的损失函数,最终结果如表2所示。
1) 损失函数改进分析


表2 消融实验组性能对比

图3 损失下降对比图
2) RCA模块性能分析
实验组3在添加RCA模块后,性能有了较为明显的提升,为进一步分析该模块作用,本文对实验组1和实验组3不同推理阶段的特征图进行可视化。如图4所示,在模型的骨干网络阶段(阶段0及阶段1),二者的特征图差距不大,均可以提取出图像的浅层特征(颜色、边缘等)。但在特征提取的后期阶段,添加了RCA模块的实验组3可以更好地抽象出图像的高级语义特征,与之相比实验组1则丢失了很多特征信息(阶段4)。
3) 小目标检测分支性能分析
添加小目标检测分支的实验组4性能提升最为明显,说明该模块对于模型精度的贡献率大。图5为实验组4与实验组1对于同一张输入图片的检测结果,可以看出小目标检测分支的添加提高了模型对小微目标的检测能力。

图4 可视化对比图

图5 小目标检测结果对比图
图6为消融实验的P-R曲线图,实验组5、6在逐步添加上述模块后并未取得等效的性能提升,这是由于模型自身结构限制,性能提升有限,但将3种模块集成到精简后的目标检测网络模型后,mAP值提升了近一倍,进一步验证了本文工作的有效性。

图6 P-R曲线对比图
(3) 实机应用
为验证本文所提算法的实际效果,将模型在图7所示的实机平台进行验证,首先通过OPENVINO部署工具应用到Intel J1900工控平台,使用Intel NCS算力扩展设备加速,并由无人机进行视频采集,并通过Qt前端界面实时显示,最终效果如图8所示。

图7 实机实验平台

图8 实机运行效果对比图
图8b)为原有YOLOv5s网络模型的运行结果,其FPS值仅为11。而本文所提的MBCF-YOLO算法其FPS值为23,说明优化后的算法运行速度可满足实际应用需求。
4 结束语
本文提出了一种用于无人机实时检测的空对地目标检测算法MBCF-YOLO。该算法首先针对骨干网络进行优化改进,以提高其运行速度,为保证检测精度,在颈部网络层添加了小目标检测分支和循环注意机制。进一步改进损失函数,以解决数据集分布失衡问题。在VisDrone2021数据集验证算法性能,结果表明,小目标检测分支对算法性能的提升最为明显,循环注意机制以及改进的损失函数对检测精度也有一定正向影响。最后,将MBCF-YOLO算法进行实际部署,进一步验证了该方法的可用性。
[1] LI Kai, NI Wei, TOVAR E, et al. Joint Flight Cruise Control and Data Collection in UAV-Aided Internet of Things: An Onboard Deep Reinforcement Learning Approach[J]. IEEE Internet of Things Journal, 2021, 8(12): 9787-9799.
[2] 禹明刚, 陈瑾, 何明, 等. 基于演化博弈的社团网络无人集群协同机制[J]. 中国科学(技术科学), 2023, 53(2): 221-242.
YU Minggang, CHEN Jin, HE Ming, et al. Cooperative Evolution Mechanism of Multiclustered Unmanned Swarm on Community Networks[J]. Scientia Sinica(Technologica), 2023, 53(2): 221-242.
[3] 王文庆, 庞颖, 刘洋, 等. 双重注意机制的空对地目标智能检测算法[J]. 现代防御技术, 2020, 48(6): 81-88.
WANG Wenqing, PANG Ying, LIU Yang, et al. Air-to-Ground Target Intelligent Detection Algorithm Based on Dual Attention Mechanism[J]. Modern Defence Technology, 2020, 48(6): 81-88.
[4] TIAN Zhi, SHEN Chunhua, CHEN Hao, et al. FCOS: Fully Convolutional One-Stage Object Detection[C]∥2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2019: 9626-9635.
[5] LIU Jianguo, CHEN Yingzhi, YAN Fuwu, et al. Vision-Based Feet Detection Power Liftgate with Deep Learning on Embedded Device[J]. Journal of Physics: Conference Series, 2022, 2302(1): 012010.
[6] GANESH P, CHEN Yao, YANG Yin, et al. YOLO-ReT: Towards High Accuracy Real-time Object Detection on Edge GPUs[C]∥2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Piscataway, NJ, USA: IEEE, 2022: 1311-1321.
[7] CHEN Yinpeng, DAI Xiyang, CHEN Dongdong, et al. Mobile-Former: Bridging MobileNet and Transformer[C]∥2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2022: 5260-5269.
[8] HAN Kai, WANG Yunhe, TIAN Qi, et al. GhostNet: More Features from Cheap Operations[C]∥2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2020: 1577-1586.
[9] MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design[C]∥Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 122-138.
[10] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional Block Attention Module[C]∥Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
[11] GAO Ruxin, WANG Tengfei. Motion Deblurring Algorithm for Wind Power Inspection Images Based on Ghostnet and SE Attention Mechanism[J]. IET Image Processing, 2023, 17(1): 291-300.
[12] HOU Qibin, ZHOU Daquan, FENG Jiashi. Coordinate Attention for Efficient Mobile Network Design[C]∥2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2021: 13708-13717.
[13] JIN S Y, ROYCHOWDHURY A, JIANG Huaizu, et al. Unsupervised Hard Example Mining from Videos for Improved Object Detection[C]∥Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 316-333.
[14] WANG Xiaolong, SHRIVASTAVA A, GUPTA A. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2017: 3039-3048.
[15] YU Hao, ZHANG Zhaoning, QIN Zheng, et al. Loss Rank Mining: A General Hard Example Mining Method for Real-Time Detectors[C]∥2018 International Joint Conference on Neural Networks (IJCNN). Piscataway, NJ, USA: IEEE, 2018: 1-8.
Air-to-Ground Target Detection Algorithm Based on Multi-branch Context Fusion
HEMing1,ZHUZihan1,2,ZHAIXulong2,ZHAIZheng1,HAOChengpeng3
(1.Command & Control Engineering College, Army Engineering University of PLA, Nanjing 210007, China;2.Joint Service Support Force Shenyang Joint Service Support Center, Shenyang 110000, China;3.Institute of Acoustics, Chinese Academy of Sciences, Beijing 100190, China)
The intelligent application of unmanned aerial vehicles (UAVs) is a hot topic in current research. To achieve efficient and real-time air-to-ground target detection for UAVs, this paper proposes a lightweight MBCF-YOLO model for air-to-ground target detection . First, a deep separable convolution to redesign an efficient and lightweight backbone network is introduced. Then, a small target detection branch with embedded recursive attention mechanism is added to the neck network to improve the detection accuracy of small targets and the ability of feature fusion. Finally, the focus loss function is combined with loss rank mining to improve the original loss function to overcome the data imbalance problem of air-to-ground datasets. Several control experiments and real machine applications have been conducted on this algorithm model, and the results show that compared with other current algorithms, the MBCF-YOLO algorithm achieves a better balance between accuracy and latency on the VisDrone 2021 dataset.
air to ground target detection;network lightweight;circulatory attention mechanism;small target detection;feature fusion
2023 -03 -30 ;
2023 -05 -17
江苏省重点研发计划资助项目(BE2021729,SBE2021710041)
何明(1978-),男,新疆石河子人。教授,博士,研究方向为计算机视觉,大数据等。
通信地址:210007 江苏省南京市秦淮区御道街标营2号陆军工程大学 E-mail:heming@aeu.edu.cn
10.3969/j.issn.1009-086x.2023.03.011
V279+.2;TN957.51;TJ8
A
1009-086X(2023)-03-0091-08
何明, 朱梓涵, 翟绪龙, 等.基于多分支上下文融合的空对地目标检测算法[J].现代防御技术,2023,51(3):91-98.
Reference format:HE Ming,ZHU Zihan,ZHAI Xulong,et al.Air-to-Ground Target Detection Algorithm Based on Multi-branch Context Fusion[J].Modern Defence Technology,2023,51(3):91-98.
