基于距离相关系数和Catboost方法的森林蓄积量估测
2023-07-05胡建锦方陆明吴达胜
胡建锦,熊 伟,方陆明,吴达胜
(1. 浙江农林大学 a. 数学与计算机科学学院;b. 浙江省林业智能监测与信息技术研究重点实验室;c. 林业感知技术与智能装备国家林业和草原局重点实验室,浙江 杭州 311300;2. 龙泉市林业局,浙江 龙泉 610100)
森林蓄积量作为林业科学研究和森林环境评价的重要指标,在点评森林资源总量与品质以及对森林运营管理和环境保护中都起到关键作用[1-2]。应对当前气候变化,我国提出到2030年前二氧化碳排放量达到高峰,争取2060年前达到碳中和,其中,森林蓄积量将比2005年增加60 亿m3,蓄积量的增加也提高了森林碳汇能力。所以,精准地估测森林蓄积量是实现我国“双碳”目标的一个重要理论依据。目前森林蓄积量评估大多数是由人工测量得到,估测成本比较大。Landsat-8 是由NASA 发射于2013年具有高分辨率的新型遥感卫星,带有两个传感器(陆地成像仪传感器和热红外传感器),是目前应用比较普遍的遥感卫星之一。当前,随着卫星遥感技术的不断发展,结合地面测量的数据用机器学习模型估测森林蓄积量,是未来森林蓄积量的主流估测方法之一。卫星遥感技术估测森林蓄积量的研究常有两个方面的应用:一是用不同的卫星图像源来做森林蓄积量的估测[3-4];二是使用不同的估测模型,比较成熟的有线性模型算法和非线性模型算法(如人工神经网络[5-6]、随机森林[7-8]、KNN[9]、梯度提升[10]等)。Catboost 算法[11-13]是2017年国际上提出的一个新的开源的机器学习库[14-15],在鲁棒性方面表现优越,它主要减少了对很多超参数调优的需求,并降低了过度拟合的机会,这也使得模型变得更加具有通用性。该算法常应用在工业界,在林业科学领域中的研究还较少。
本研究基于距离相关系数的特征提取方法,采用多源数据,包括Landsat-8 遥感卫星影像数据、森林资源二类调查数据以及数字高程模型(DEM)3 种数据结合,运用Catboost 模型对龙泉市[16-18]区域进行森林蓄积量的估测,在森林蓄积量中给出一种新的估测模型,能为我国实现“双碳”目标提供一定的理论依据。
1 材料与方法
1.1 研究区概况
龙泉市(27°42'~28°20'N,118°42'~119°25'E)是我国著名的青瓷之都、宝剑之邦、灵芝第一乡,也是世界香菇栽培发源地,辖4 个街道8 个镇7 个乡,人口29 万(2017年统计),东西宽约70.25 km,南北长约70.80 km,总面积3 059 km2左右,浙江第二大县级市,还是国家历史文化名城。森林的覆盖率达到84.3%,覆盖面积将近25.72 hm2,森林蓄积量也高达1 912 万m3,生态环境质量上乘。
1.2 研究数据
本研究采用龙泉市多源数据,包括2017年11月份的Landsat-8 对地观测卫星影像数据以及2017年森林资源二类调查数据,还有2009年的数字高程模型(DEM)数据。
本研究把单位蓄积量作为估测指标,森林资源小班作为研究单元,运用前人的研究方法[19-21],把Landsat-8 卫星遥感影像数据进行6 个步骤的预处理(辐射定标、大气校正、正射校正、几何校正、图像融合、镶嵌剪裁),处理结果如图1 所示。

图1 龙泉市Landsat-8 遥感影像预处理结果Fig. 1 Remote sensing in Longquan city
首先从Landsat-8 遥感影像中提取共11 个自变量因子,包含6 个波段数据(B2、B3、B4、B5、B6、B7),以及通过波段计算获得5 个指数数据(归一化植被指数、增强型植被指数、差值植被指数、红色指数、比值植被指数)(表1)。由于第1 波段属于海岸观测波段,在本研究中并不适用且影响作用很小;第8 波段是全色波段纹理数据,不予考虑;第9 波段属于卷云波段,而研究区所使用的一景Landsat-8 影像云量为0,对本研究影响非常小,促使该波段灰度值趋于0。所以将B1、B8、B9 剔除出自变量因子选择的范围。然后从二调数据中获取4 个自变量因子,包括腐殖质厚度、土层厚度、年龄和郁闭度(FU_ZHI_HD、TU_CENG_HD、NL、YU_BI_DU); 最后从DEM 数据中提取3 个自变量因子,分别是坡度、坡向和海拔(PO_DU、PO_XIANG、HAI_BA)。
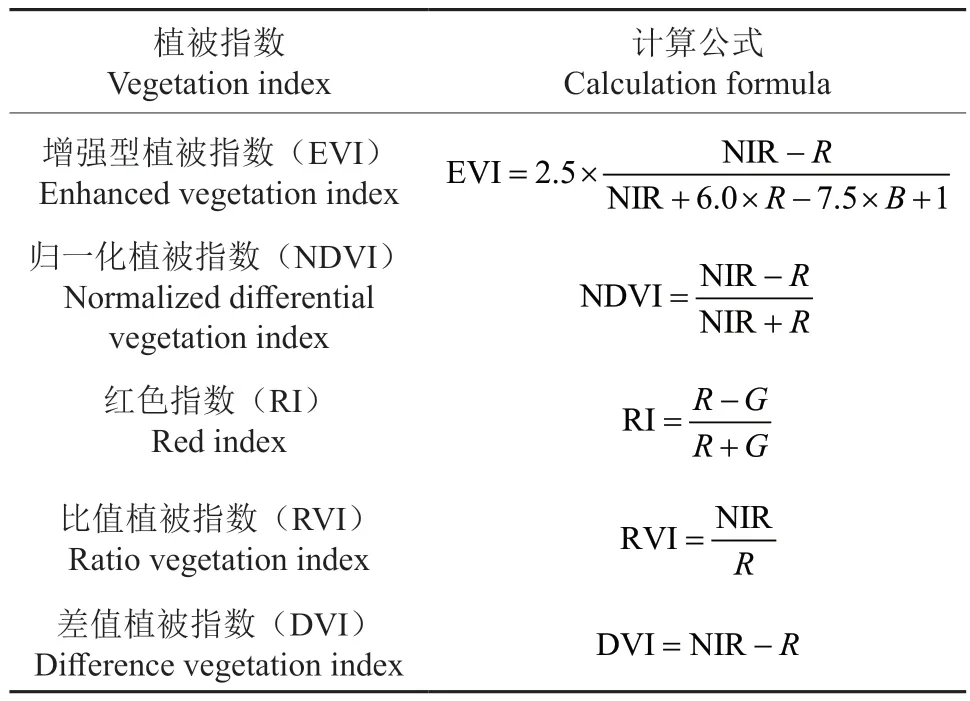
表1 植被指数计算公式Table 1 Formulas of the vegetation index
将收集的18 个自变量因子作为候选数据,加入森林小班样本记录中,选取在数据中占比最多的杉木、针叶混交林、马尾松3 个优势树种作为估测样本。过滤掉蓄积量为0、RVI 指数大于30、EVI 小于0 的小班点以及其他缺少需要信息数据的小班点等,最终剩余23 499 个小班数据,参与之后的估测算法试验。之后随机按照9∶1 的比例对训练集和测试集进行划分,21 349 个小班数据作为训练样本,剩余的2 150 个小班数据作为测试样本进行模型的估测。
1.3 基于距离相关系数特征的选择方法
假如将全部的候选自变量都用来练习模型,则会造成信息冗余,而且促使模型的可解释性减少,因而要对所获取的建模因子进行合理挑选。
当前普遍作为数据特征提取的方法为Pearson相关系数法。但它有一个明显缺陷是作为特征排序机制时,只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson 相关性也可能会接近0。所以,本次研究使用距离相关系数(DC)特征选择方法来提取出优势的特征因子。它不管对变量间线性还是非线性都非常适合,也不受其他参数或者模型的限制。距离相关系数的公式如式(1)所示:
同理计算dcov(u,u)和dcov(v,v)。
1.4 算法模型
KNN 算法是非常成熟的非线性算法之一。该算法通过数据对特征向量空间进行划分,计算出新数据与数据集中心点的距离,该距离是指欧式距离或者曼哈顿距离,根据距离递增次序进行排序,返回K个点的加权值作为预测值。
Bagging 是集成算法中的一个分支,该算法对于回归分析问题,通常使用简单平均法,再对结果进行算术平均得到最终的模型输出。主要思路是:给定大小为M的训练集S,算法从S中自助抽样取出m个大小为M的子集Si作为新的训练集。这m个训练集分布训练出结果,最后取所有结果的平均值或多数投票等策略算出结果。目前,Bagging 算法在机器学习领域已经获得较好的应用表现。
LGBM 集成算法是GBDT 算法实现框架之一。优点是高效率的并行训练,而且训练速度快、内存消耗少、准确率高、支持分布式等。LGBM 在传统的GBDT 算法上进行如下改进:第一,计算是基于Histogram 的决策树;第二,使用单边梯度采样(GOSS),这样降低许多只存在于小梯度上弥散的样本数据,减少时空上的浪费;第三,带深度限制的leaf-wise 的叶子生长策略;第四,直接支持类别特性;第五,支持高效并行和cache 命中率优化等。
Catboost 是GBDT 算法中一种新型的机器学习模型,以对称树为弱学习器,使用GBDT 进行分类。对比之前的GBDT 相关算法,如Gboost 和Adaboost 等,Catboost 算法在准确性和泛化能力方面都有显著提升,特别是在处理大量数据和特征的时候。假设把每次迭代的目标函数定义为:
1)把训练集中每个样本Ni,去掉Ni的训练集独自训练一个模型Mi;
2)用模型Mi计算样本Ni上的梯度估计;
3)提取新模型重新对样本Ni估测,从而得出基学习器;
4)对基学习器加权反复计算,从而获得强学习器。反复进行迭代,目的是减小目标函数hk关于训练数据的损失,即减小模型在训练集的预误差,从而对抗训练集中的噪声点,进而解决预测偏移的问题。
1.5 模型评价指标
本研究运用10 折交叉验证法(10-fold Cross Validation)来评估精度。采用决定系数、平均百分比误差、估测精度、均方误差、平均绝对误差(R2、MAPE、P、MSE、MAE)5 个指标来评价模型。
2 结果与分析
2.1 距离相关系数特征的选择结果
本试验依靠蓄积量和各个特征之间的距离相关系数(DC)关系将所有特征因子进行排序,从首个特征因子开始逐步加入KNN 模型中估测,选取该模型的决定系数(R2)最大时候的特征因子组合。最终结果由8 个特征因子组合,结果见表2。

表2 变量选择结果Table 2 Variable selection results
2.2 蓄积量建模与估测结果分析
2.2.1 4 种方法结果分析
基于距离相关系数筛选的特征因子组合数据作为模型的输入,并且数据都经过归一化处理,单位蓄积量作为模型的输出。在估测评估中,采用KNN 方法、Bagging 方法、LGBM 方法与Catboost 方法进行对比,建模结果见表3 和图2,估测结果见表4 和图3。

表3 4 种方法的蓄积量建模评价指标Table 3 Stock volume modeling evaluation index of the four methods

表4 4 种方法的蓄积量估测评价指标Table 4 Stock volume estimating evaluation index of the four methods
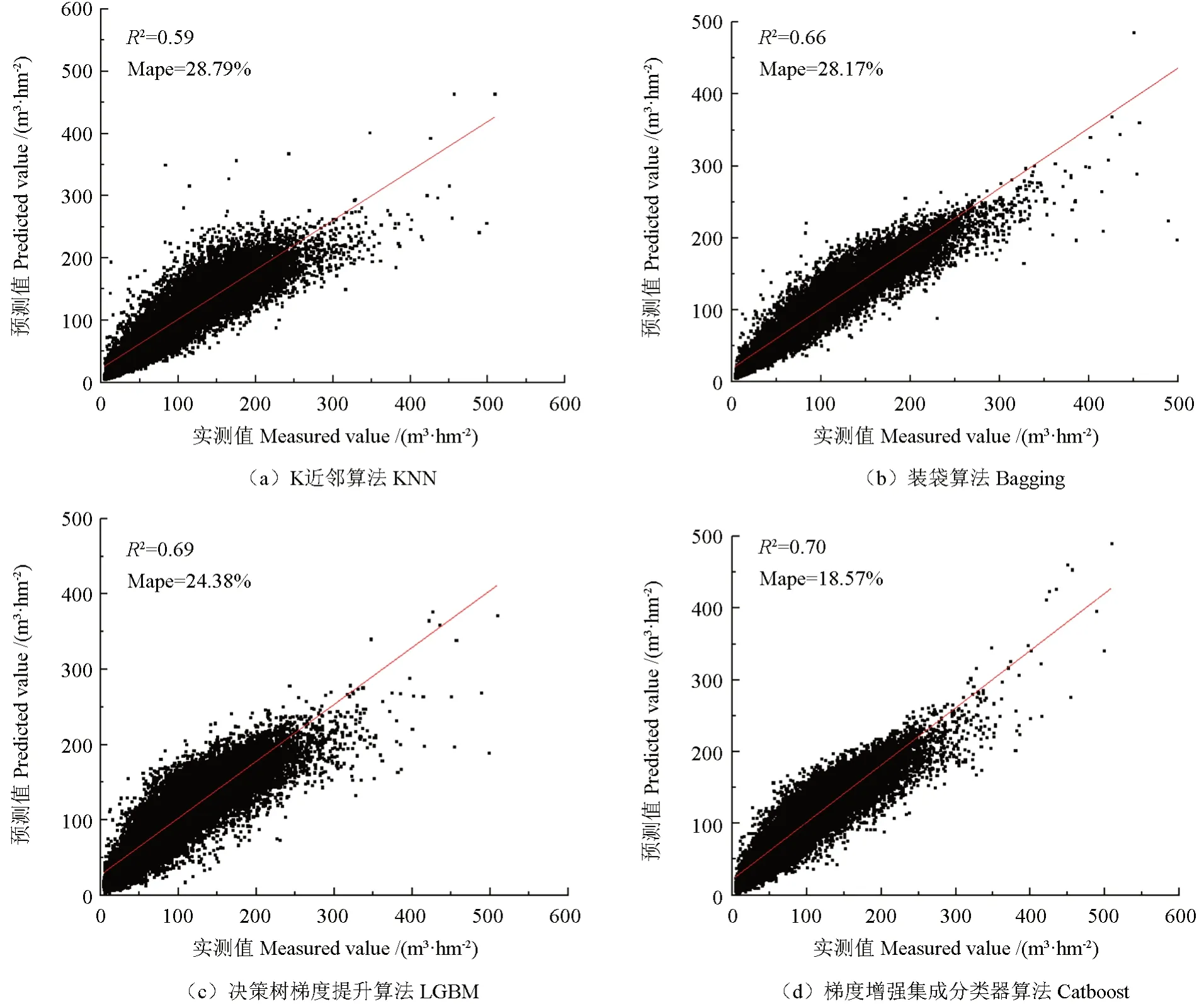
图2 4 种方法的蓄积量建模结果Fig. 2 Volumetric modeling results of the four methods
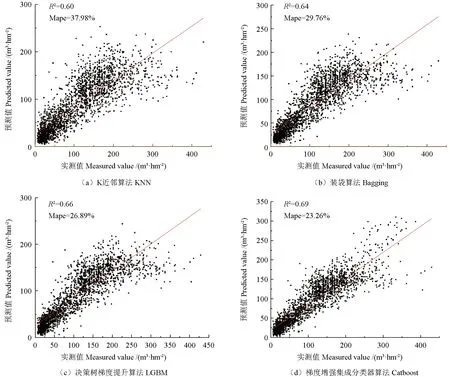
图3 4 种方法的蓄积量估测结果Fig. 3 Predicted volume results of the four methods
图2d 和图3d 是Catboost 蓄积量建模和估测得到的结果模型。由表3 ~4 可知,Catboost 蓄积量建模模型的精度P与估测模型的精度P在这次研究中最佳,分别是81.43%和76.74%。Bagging 方法以及LGBM 方法的建模精度P和估测精度P也非常好,分别达到了71.83%和70.24%与72.63%和70.11%,并且建模精度与估测精度都比传统的KNN 方法表现得更好。与KNN 方法、Bagging 方法、LGBM 3 种模型对比,基于Catboost 方法的森林蓄积量估测在建模和估测结果中的决定系数R2都高于其他3 种模型,分别达到了0.70 和0.69。其中2 种非线性集成算法Bagging 方法的精度P是70.24%,LBGM 算法的精度P是70.11%,最低的是常用模型KNN 方法的精度P(62.02%),说明非线性集成算法在森林蓄积量估测中效果表现更好,特别是Catboost 模型算法在森林蓄积量估测中表现最佳。在模型估测中,4 种方法中3 种集成算法的精度P值都高于70%,对龙泉市的森林蓄积量的估测有较大的实际参考意义。
与前人研究对比,Catboost 方法建模最高精度达到81.43%,估测最高精度达到76.74%,比文献[22]基于SVM 方法的高山松林蓄积量遥感估测研究的估测精度为76.6%和文献[23]基于Landsat-8 遥感影像的森林蓄积量估测的精度74.42%都要高;其中最重要的性能指标的决定系数R2,Catboost建模模型达到0.70,比文献[24]基于Landsat-8 遥感影像的旺业甸林场蓄积量估测模型研究中的随机森林模型的决定系数R2(0.66)更高。
2.2.2 Catboost 方法进行蓄积量建模与估测结果分析
本研究的样本共23 499 个小班数据,按3 种优势树种杉木、针叶混交林和马尾松来划分,获得13 608 个杉木数据、7 567 个针叶混交林数据、2 324 个马尾松数据。之后3 种优势树种分别随机按照9∶1 的比例进行划分训练集和测试集,选取之前表现最好的Catboost 算法模型进行估测,再与未划分树种情况下的最好估测结果进行对比。Catboost 方法建模结果见表5 和图4,估测结果见表6 和图5。
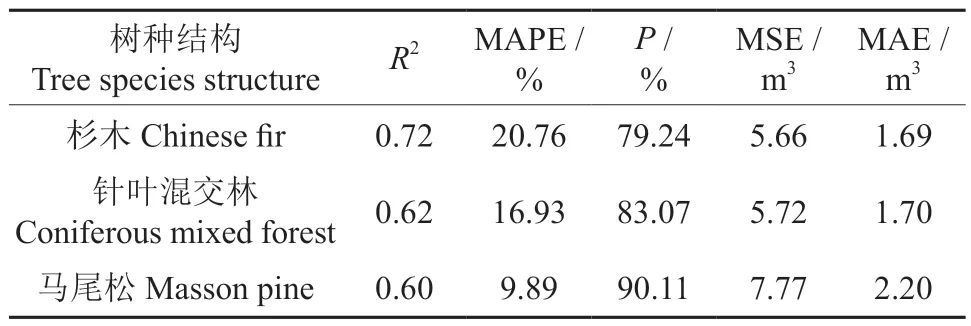
表5 3 个树种基于 Catboost 的蓄积量建模性能指标Table 5 The forest stock estimation performance index of Catboost-based modelling of the three tree species
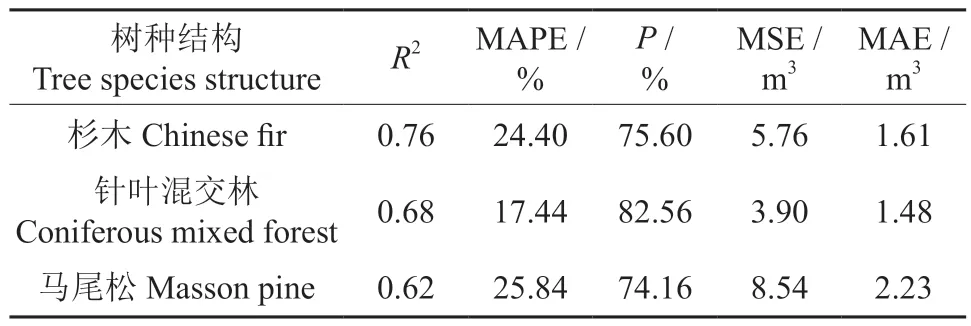
表6 3 种树种基于Catboost 的蓄积量估测性能指标Table 6 The forest stock estimation performance index of Catboost-based modelling of the three tree species

图4 划分杉木、针叶混交林、马尾松情况下的基于Catboost 的蓄积量建模结果Fig. 4 Catboost-based modelling results of estimating forest stock by distinguishing Chinese fir and coniferous mixed forest and Masson pine

图5 划分杉木、针叶混交林、马尾松情况下的基于Catboost 的蓄积量估测结果Fig. 5 Catboost-based estimation results of forest stock by distinguishing Chinese fir and coniferous mixed forest and Masson pine
由于3 种优势树种样本量不同,模型的建模精度和估测精度按数量权重相加得出。其中3 种树种集合的建模精确度为81.43%(表3),估测精度为76.74%(表4)。而分树种各自估测按数量权重相加后建模精度为81.85%,估测精确度为77.75%。区分3 个优势树种情况下,按数量权重相加后建模精确度提升不明显,但是估测精确度提高了1.01%。其中建模精确度表现最好的是马尾松,达到了90.11%,但是估测精确度表现最好的是针叶混交林,达到了82.56%。杉木和马尾松的估测效果稍微差些,这可能是在总样本中3 个优势树种选择的样本分布不一致所导致的。
3 结论与讨论
3.1 结 论
本研究基于龙泉市2017年森林二调小班数据和landsat-8 遥感影像、数字高程模型(DEM)数据,使用距离相关系数方法进行特征提取,并且结合K 最邻近(KNN)方法、装袋(Bagging)方法、决策树梯度提升(LGBM)方法和梯度增强集成分类器(Catboost)方法估测森林蓄积量模型。结果表明,基于距离相关系数的特征提取方法结合Catboost 模型估测森林蓄积量是可行的,并且建模和估测的精确度较KNN 方法、Bagging 方法和LGBM 方法提高显著,进一步表明非线性集成算法和卫星遥感影像结合是对森林蓄积量估测的有效方法之一。其中未区分树种情况下建模精度为81.43%,估测精度为76.74%。而在不同树种按数量权重相加计算情况下,建模精度差别不大,估测精度提高了1.01%,其中针叶混交林表现最好,估测精度达到了82.56%。
3.2 讨 论
运用Catboost 算法作为区域的森林蓄积量估测模型,采用森林资源二类调查数据和Landsat-8遥感影像数据以及数字高程模型,结合距离相关系数方法进行特征提取,可以表现出更好的估测效果,也能更进一步说明非线性的集成算法结合高分遥感影像数据在森林蓄积量估测方面比传统的线性算法有更好的效果。Catboost 模型在实践估测中容易使用,也能在短时间内给森林蓄积量预测提供一种高准确率的可能性,但是每种算法都有优点与不足,本试验只是选取了4种算法作对比,并且本次研究数据只局限在单一的县区,之后可以尝试加入更多的特征因子来作筛选(比如纹理因子等)。后续将基于距离相关系数的特征选择的Catboost 模型算法进行不同地区的森林蓄积量估测,以此来研究验证此方法的普适性,以便更好地指导林业生产实践。
