基于特征增强和损失优化的弱监督目标检测算法
2023-07-03李冰锋段鑫鑫费树岷
李冰锋,段鑫鑫,杨 艺,费树岷
(1.河南理工大学 电气工程与自动化学院,河南 焦作 454000;2.河南省煤矿装备智能检测与控制重点实验室,河南 焦作 454003;3.东南大学 自动化学院,南京 210096)
0 引言
弱监督目标检测是指利用训练样本的图像级标注来训练目标检测器的一类方法[1]。与强监督目标检测的示例级标注相比,图像级标注具有制作成本低廉,获取渠道广泛的优点,这大大减轻了目标检测问题中数据集制作的难度,为基于超大规模数据集的目标检测模型训练提供了很好的前景。因此,弱监督目标检测算法自提出伊始,便吸引了大批学者,目前更是成为了目标检测领域的研究热点之一。
由于示例级标注的缺乏,一种比较流行的解决方案是把弱监督目标检测转化为多示例学习(MIL)问题[2],基于MIL的弱监督目标检测算法,首先将每幅图像视为由多个候选区域组成的示例包,然后分别构建相应的分类器和检测器。其中,分类器用于从候选区域中筛选出置信度最高的部分,检测器则基于选中的候选区域实现目标检测的功能。这其中比较典型的工作是由Bilen等[3]提出的弱监督深度检测网络(WSDDN)。WSDDN通过对图像中不同区域进行加权求和及池化来将图像中最高得分的候选区域边界框作为目标示例边界框的预测结果。但基于MIL的弱监督目标检测本质上是将目标检测问题转化为分类问题,因此极易将图像中最具辨别性区域作为示例目标整体[4-5],从而导致了其定位精度不高。Tang等[6]则在WSDDN的基础上提出了在线示例分类细化的思想(online instance classifier refinement,OICR)。OICR首先将前一个细化分类分支中得分最高的目标区域作为伪初始正样本,并将该初始正样本作为伪监督信息送入下一个细化分类分支来约束其训练过程。通过多次迭代对候选区域边界框进行细化,从而得到更加完整的候选区域边界框。Yang等[7]在OICR的基础上,将边界框回归的思想运用到了弱监督目标检测中,并设计边界框回归分支。但回归分支中候选区域边界框的监督信息源自于OICR最后一个细化分类分支,其受图像中示例目标尺寸和数量以及图像背景的复杂程度影响较大,这进一步限制了目标定位性能的提升。另外,在基于MIL弱监督目标检测的训练过程中,由于采用了伪标注框,因此其极易产生噪声项,这加大了其训练的难度。从优化求解的角度来看,MIL本身是个非凸优化问题[8-11],其求解过程中很容易陷入局部极小值,这导致了弱监督目标检测的精度进一步降低。
针对以上问题,本研究提出了一种基于特征增强和损失优化的弱监督目标检测算法。该算法将弱监督目标检测中最具辨别性区域极易被误判为示例目标整体的问题归结为特征表达不充分问题,并提出一种高效可选择通道注意力模块(efficient selective channel attention block,ESCA_Block)。该模块采用通道选择的方式来提高特征图中局部通道间的信息交互,并在此基础上,为每个通道分配一个合适的权重。该方法会使分类器输出的得分矩阵中,示例目标处的得分得到增强而背景处的得分得到抑制,这有助于挖掘更多的示例目标候选区域,从而使最终的示例目标区域变的更为完整。对于回归分支中伪标注框易受噪声影响的问题,本研究从优化回归损失的角度来改善其性能,并提出一种回归损失的动态优化方法。通过动态权重的引入,网络能自主地减小伪标注边界框的不准确性而给目标定位带来的影响。
1 本文方法
基于卷积神经网络的弱监督目标检测算法网络总体分为特征提取网络、目标候选框生成模块、目标检测子网络3部分,其中,目标检测子网络由一个多示例检测分支、若干个示例分类器细化分支和一个回归分支共同组成。其网络结构如图1所示。特征提取网络采用在ImageNet数据集[12]上预训练的VGG16[13]网络,用于生成输入图像对应特征图。目标候选框生成模块由选择性搜索(SS)算法[14]实现,用于生成图像中的示例候选框。根据生成的特征图及其对应的示例候选框可以生成多个候选特征区域,并将其作为后续目标检测子网络的输入。在目标检测子网络中,所有分支共享相同的输入,其中多示例检测分支用于生成示例候选区域得分矩阵,并基于得分矩阵生成后续示例分类器细化分支的伪标注边界框标注信息。示例分类器细化分支基于上一级分支传入的伪标注边界框标注信息对相关分类器进行迭代优化。而回归分支的伪标注边界框标注信息是由最后一个示例分类器细化分支生成,回归分支来对示例候选区域进行微调。如图1所示,本文中提出的ESCA_Block添加在特征提取网络部分,而回归损失的动态优化则是基于回归分支的预测结果和伪标注边界框标注信息进行网络参数的调整。

图1 弱监督目标检测算法网络结构图Fig.1 Network structure diagram of weakly supervised object detection algorithm
1.1 高效可选择通道注意力模块
在视觉任务中,常在特征提取网络中加入视觉注意力模块,以通过权重分配选择性地突出重要视觉信息,并抑制或弱化不必要信息。本文中提出的ESCA_Block的网络结构如图2所示。

图2 高效可选择通道注意力模块Fig.2 Efficient selective channel attention block
对于任意的输入特征D∈RC×H×W,(其中H×W为其空间尺寸,C为通道数)。ESCA_Block首先在空间维度上对其进行全局平均池化,随后进行降维及矩阵转置得到Ds∈R1×C,该过程的公式化描述如式(1)所示。
Ds=f2(f1(GAP(D)))
(1)
式中:GAP()表示全局平均池化;f1()表示降维操作;f2()表示矩阵转置运算。
Ds整合了输入张量中每个通道的全局空间信息,消除了空间变换对后续操作的影响。但对于Ds而言,由于其每个通道的计算结果来自不同的卷积操作,相邻通道并无明显关联性。若直接在不相关的相邻通道间进行一维卷积运算,会导致卷积核获取不清晰的特征模态,从而影响后续权重分配的准确性。因此,本研究首先设计了一个通道选择模块,并在此基础上进行一维卷积操作,其具体过程如式(2)所示。
(2)
Dd(p0)表示以p0为通道中心的通道可选择一维卷积的输出结果,W(pn)表示一维卷积,pn表示卷积核对应的位置索引,R=[-i,i],i∈N+表示卷积核索引的集合。Ds(p0+pn+Δpn)表示参与一维卷积运算的输入向量,(p0+pn)表示输入向量的原始位置索引,Δpn为位置索引的偏移量,其取值确定了一维卷积中通道选择的偏离程度,Δpn通过一个附加的一维卷积运算学习得到,但一维卷积的输出结果并非整数,这将导致无法在Ds取到相匹配的值。为避免此种情况的出现,对Δpn进行向上向下取整操作,得到2个整数偏移量Δpc=「Δpn⎤和Δpf=⎣Δpn」。采用pc和pf来表示经过通道选择后通道的索引,其表达式如式(3)所示。
(3)
利用线性插值方法,即可估算出Ds(p0+pn+Δpn)的值。表达式如式(4)所示。
Ds(p0+pn+Δpn)=
Ds(pf)+[Ds(pc)-Ds(pf)](Δpn-Δpf)
(4)
最后经过维度转换和sigmoid激活即可得到新的特征图的通道权重分布Dc∈RC×1×1,其表达式如式(5)所示。
Dc=sigmoid(f4(f3(Dd)))
(5)
式中:sigmoid()为归一化指数函数;f3()表示矩阵转置运算;f4()表示升维操作。
经过ESCA_Block通道选择和权重分配后的特征提取网络的最终的输出如式(6)所示。
Do=D⊗Dc
(6)
其中,⊗表示通道权重与特征对应通道进行加权乘积。
1.2 动态优化损失
弱监督目标检测子网络由多示例检测分支[3]、示例分类器细化分支[6]、回归分支[7]3部分组成。其总的损失函数如式(7)所示。
(7)
式中:Lmil表示多示例检测分支的分类损失;Lrefine表示每个示例细化分支的损失;K表示细化次数;Lcls和Lreg分别表示回归分支的分类损失和回归损失。多示例检测分支、示例细化分支的损失函数与参考文献[7]完全一致,不再赘述。
本研究采用的回归损失函数如式(8)所示。
(8)
式中:ti代表回归分支预测框的坐标量;vi代表伪标注边界框的坐标量;x,y,w,h代表目标边界框的中心点横、纵坐标以及目标边界框的宽和高。而smoothL1()表示平滑的L1-smooth损失,其表达式如式(9)所示
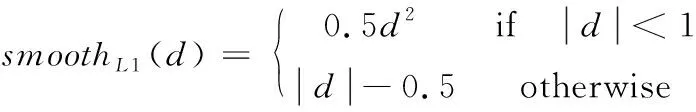
(9)
强监督目标检测中,示例目标的标注边界框是真实(groundtruth)且保持不变的。但如图1所示,在弱监督目标检测中,示例目标区域的伪标注(pseudogroundtruth)边界框来自示例分类器细化分支,在不同训练阶段,示例目标伪标注边界框的位置和尺寸是变化的。以图3为例,在网络训练初期(Steps=2 500和Steps=4 000),伪标注边界框只提供了目标示例最具辨别性局部区域,且标注边界框变化较大。一方面,这将导致回归分支预测到目标边界框拟合到目标的局部区域。另一方面,伪标注边界框持续变化,使得回归分支极易主导本轮次的训练,弱化其他几个分支的训练比重,这将使整个训练过程变得更为复杂。但在网络训练的后期(Steps=10 000和Steps=15 000),伪标注边界框逐渐包围整个目标且变化趋缓,这与强监督目标检测的标注框已基本上保持一致。

图3 不同训练阶段伪标注边界框Fig.3 Pseudo bounding box for different training stages
为协调训练过程中,示例目标伪标注边界框的变化,本研究采用了一种对回归分支权重进行动态优化的方法,权重动态优化的回归损失函数的表达式如式(10)所示。
(10)
式中:f(s)表示动态优化权重;s表示网络训练过程中参数迭代更新的次数。f(s)设计思想源自于图3所展现的伪标注边界框变化过程。其整体思路为:在网络训练的初始阶段,伪标注边界框不准确且尺寸变化剧烈,此时f(s)取值应该较小,以减弱回归分支在本轮训练中所占的比重,这可以使其他分支得到较为充分训练,以提供更准确的伪标注框。
在网络训练的后期,伪标注边界框基本上已经能够包围整个示例目标且变化过程缓慢,故此时f(s)取值应该较大且变化缓慢,加强回归分支在训练过程中所占的比重,从而使网络最终能够得到一个较为准确的示例目标的预测边界框。可见,f(s)取值应该是一个逐渐增大的过程,为简单起见,本研究设计了一种分段线性函数,表达式如式(11)所示。
(11)
其中,s表示网络训练过程中参数迭代更新的次数。c表示伪标注边界框状态切换时参数迭代更新的次数,变量a、b、d分别对应直线的斜率,初始化训练权重,网络训练后期的常量化权重,其三者对应约束关系为as+b=d,三者均大于0。
2 实验及分析
2.1 实验环境和数据集
本研究所采用实验平台的操作系统为Ubuntu18.04;硬件配置为:Intel至强6146 CPU(12核24线程),RTX2080Ti显卡(共6块,单卡显存为12GB);深度学习框架为PyTorch;其他配置包括:Cuda10.2,cuDNN7.6.5,Python3.6。
本研究的数据集采用PASCAL VOC2007[15]、VOC2012[16]两个标准的公共数据集。采用平均准确率(mean average precision,mAP)和正确定位精度(correct localization,CorLoc)来分别衡量目标检测和定位的准确性,其具体计算过程详见文献[17]。训练过程中,示例细化分支的数量K设置为3。网络训练的轮次为75 K次,前55 K次网络训练初始学习率(learning rate)为0.001,50K次后学习率调整为0.000 1。批大小(batch size)设为4,网络训练过程中迭代更新参数的次数为17 500。其他参数与文献[7]相同。
2.2 消融对比实验
为验证本研究提出的ESCA_Block的有效性,将其与ECA-Net[18]、SE-Net[19]以及CBAM[20](convolutional block attention module)在PASCAL VOC2007数据集上进行对比实验。其基础网络框架为OICR-Reg[7]。所有注意力机制均添加在VGG16网络的Conv11和Conv12层后。实验从参数量和浮点运算数(FLOPs)以及mAP和CorLoc指标4个方面进行了对比,其实验结果如表1所示。

表1 不同注意力机制的对比Table 1 Comparison of different attention mechanisms
对比算法中,除CBAM外,其他均为通道注意力,无论是参数量和计算复杂度,都要优于CBAM。在通道注意力中,ESCA_Block的参数量和计算复杂度要优于SE-Net且与ECA-Net基本保持持平。这是因为ESCA_Block和ECA-Net均采用一维卷积来替代SE-Net采用的全连接操作。
从分类和定位精度来看,ESCA_Block的mAP和CorLoc分别达到54.9%和70.5%,远超其他算法。一方面可能是因为SE-Net采用了全连接操作并对通道进行挤压和扩展,从而破坏了通道和权值之间的直接对应关系;另一方面ECA-Net直接对特征图在通道维度上进行一维卷积运算,默认了相邻通道之间关联性的存在。但对于卷积神经网络来讲,特征图的通道间只存在明显的信息冗余。ESCA_Block首次提出了一维卷积通道可选择的思想,通道选择模块的引入,使得一维卷积操作从位置相近上升过度到模态相近。而以模态为单位进行通道权重分配,有利于特征提取网络获取更多的示例特征,从而在后续操作中可以获得更多的正示例区域,以此来更好地挖掘目标示例隐式边界框位置信息。如图4所示,相比于其他注意力ESCA_Block可以使得目标特征更加明显,同时目标区域也更为完整,这证明ESCA_Block的有效性。
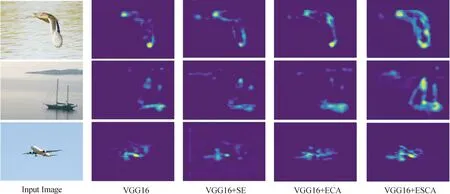
图4 特征图可视化Fig.4 Feature map visualization
本研究还在PASCAL VOC2007数据集上验证了动态优化损失权重中超参数b、c、d对弱监督目标检测的影响,如图5所示。由表可见,以上各超参数均有其有效区间,过大或者过小的取值,都会对其性能产生影响。后续实验中,无特殊说明,b取0.1,c取9 000,d取0.9。

图5 超参数b,c,d不同取值时网络的检测精度Fig.5 The detection accuracy of the network with different values of hyperparameters b,c and d
另外,从表1和图5可以发现,分类精度和定位精度的变化是具有一定的关联性。这说明本研究所提出的2种方法不是相互割裂的,而是一个有机的整体,两者具有相互促进的作用。特征表达能力的提升,有利于得到更加完整的示例目标区域。而更为完整的示例目标区域,提升了回归过程中伪标注边界框的准确性和稳定性。
2.3 不同弱监督目标检测算法对比实验
表2展示了本研究算法和近几年弱监督目标检测算法在PASCAL VOC2007数据集上的性能比较,本研究算法取得了mAP55.9%和CorLoc71.9%的检测精度,优于OICR、W2F、WSOD2、C-MIDN、MIST等近些年主流算法。这再次表明特征表达能力的提升和训练过程中回归分支的权重调整对于弱监督目标检测来讲具有重要意义。同时在PASCAL VOC2012数据集上进行不同算法的比较,结果如表3所示。本研究算法取得了mAP52.9%和CorLoc71.5%的结果,相比于其他弱监督目标检测算法,本研究算法依然取得了最佳效果。表中,OICR-Reg-ESCA和OICR-Reg-DW表示只在OICR-Reg添加ESCA_Block和动态回归权重的结果,Ours表示2种方法共同作用后的结果。表中‘-Reg’表示网络中含有边框回归分支,-Ens’表示采用模型集成的方法。其中不同的对比方法检测结果来自于对应参考文献。文献End-to-end[7]为OICR-Reg的原始版本。

表2 PASCAL VOC 2007测试集上检测结果(%)Table 2 Detection results on PASCAL VOC 2007 dataset (%)

表3 PASCAL VOC 2012测试集下检测结果(%)Table 3 Detection results on PASCAL VOC 2012 dataset (%)
图6展示了本研究算法和OICR-Reg算法在PASCAL VOC2007数据集上的预测结果,其中绿色框表示目标的真实边界框(Ground truth box),红色框是OICR-Reg算法预测边界框,黄色框是本研究算法的预测边界框。可以看出,第1、3、5列检测结果仅定位出目标最具有辨别行部分却忽略了完整的目标部分。而第2、4、6列本研究算法显著的改善了这种问题。

图6 OICR-Reg算法(1,3,5)和本研究算法(2,4,6)的预测边界框Fig.6 Predictive bounding boxes between OICR-Reg algorithm (1,3,5) and the proposed algorithm (2,4,6)
3 结论
本文中提出一种基于特征增强和损失优化的弱监督目标检测算法,实现了利用训练样本的图像级标注来对图像中目标进行检测,有效改善了网络易检测出目标最具辨别性区域的问题。主要结论如下:
1) 提出的高效可选择通道注意力模块在增加极少数参数量的前提下,有效提升了网络的特征提取能力。实验表明,经过对特征图的可视化分析发现目标最具辨别性区域周围特征变得更加明显,验证了该研究提出的注意力模块的有效性。
2) 提出的基于回归分支的动态损失优化方法有效改善了伪标注边界框不准确性对网络性能的影响。实验表明,该研究算法比采用的基础算法的预测边界框具有更高的准确性。
3) 目前该研究算法生成的伪标注数据与人工标注数据存在一定差距,伪标注的准确性直接影响网络最后的检测性能,所以如何提高伪标注的准确性是下一步的研究方向。
