基于改进YOLOv7的融合图像多目标检测方法
2023-07-03张亮亮
薛 震,张亮亮,刘 吉
(1.中北大学 数学学院,太原 030051; 2.中北大学 信息与通信工程学院,太原 030051)
0 引言
在微光环境下的军事侦察、遥感探测、野外救援和视频监控等任务中,由于有效目标区域的丢失,对图像融合、多尺度目标检测和图像到图像的转换等各种视觉任务都具有挑战性。在此情况下,将可见光和红外图像进行融合,可以提供丰富的纹理细节信息和有效的目标区域,便于图像的识别检测。对融合图像进行多目标检测,是指从融合后的图像数据中识别出行人和汽车等目标,同时指出它们的位置和大小。传统的多目标检测算法,多采用人工特征提取的方法,主观性较强且特征单一,难以用于微光等复杂环境下的多目标检测。而基于深度学习的多目标检测算法解决了传统方法需要人工提取特征的问题,通过对大规模数据的自主学习,借助深度卷积神经网络算法自行提取出目标物复杂多样的图像特征信息,使其特征特异性减弱,可同时适用于多种目标的检测,提高了检测算法的有效性和稳定性[1],其中以YOLO(You Only Look Once)系列[2-8]为代表的“一步法”在对目标的实时性检测方面有着卓越的表现。
近年来,关于可见光与红外融合图像的目标检测已取得了一些研究成果。文献[9]综述了已有的红外和可见光图像融合的7类方法(包括基于多尺度变换的、基于稀疏表示的、基于神经网络的、基于子空间的、混合方法等)及其在目标检测与识别、目标追踪、图像增强、遥感等方面的广泛应用;文献[10]提出了一种使用生成对抗网络融合(fusion by a generative adversarial network,FusionGAN)红外和可见光图像信息的方法,结果表明,该方法可以生成清晰的、干净的融合图像,而不受红外信息上采样所引起的噪声的影响;文献[11]研究了可见光与红外图像融合目标检测问题,提出了一种基于YOLO的特征融合目标检测算法,实验结果表明该算法对行人、汽车、摩托车、信号灯等多目标有较高的检测精度;文献[12]针对帧间差法检测融合图像目标时会出现背景噪声的问题,在利用小波变换得到融合图像后,将彩色参考图像与融合图像在YCBCR空间进行颜色传递,提出了一种采用帧间差法和形态学相结合的运动目标检测方法;文献[13]通过引入SENet(squeeze-and-excitation networks)通道注意力模块、优化网络结构等策略提出了一种基于YOLOv5s和可见光与红外图像融合的行人检测方法。
本研究中以YOLOv7算法框架为基础,通过引入BoT(bottleneck transformer)结构,改进损失函数,提出了一种基于改进YOLOv7的融合图像的多目标检测方法,该方法使网络更加关注整体图像信息,有利于网络提取特征,从而提高微光环境下的行人和汽车检测的准确率。
1 目标检测算法
1.1 YOLOv7算法
YOLO系列算法见证了深度学习时代目标检测算法的演化。目前YOLOV7是YOLO系列中最先进的算法,在速度和精度上超越了YOLOX、Scaled-YOLOv4、YOLOv5、DETR、SWIN-L Cascade-Mask R-CNN等目标检测算法。YOLOv7相同体量下比YOLOv5快120%,YOLOv7-E6在V100的GPU上速度达到56 fps,AP达到55.9%[8]。
YOLOv7网络由输入(Input)、主干网络(Backbone)和头部(Head)3部分组成,如图1所示。与YOLOv5不同的是,它将Neck层与Head层合称为Head层,实际上功能未发生改变。各部分的功能与YOLOv5相同,如Backbone用于提取特征,Head用于预测。
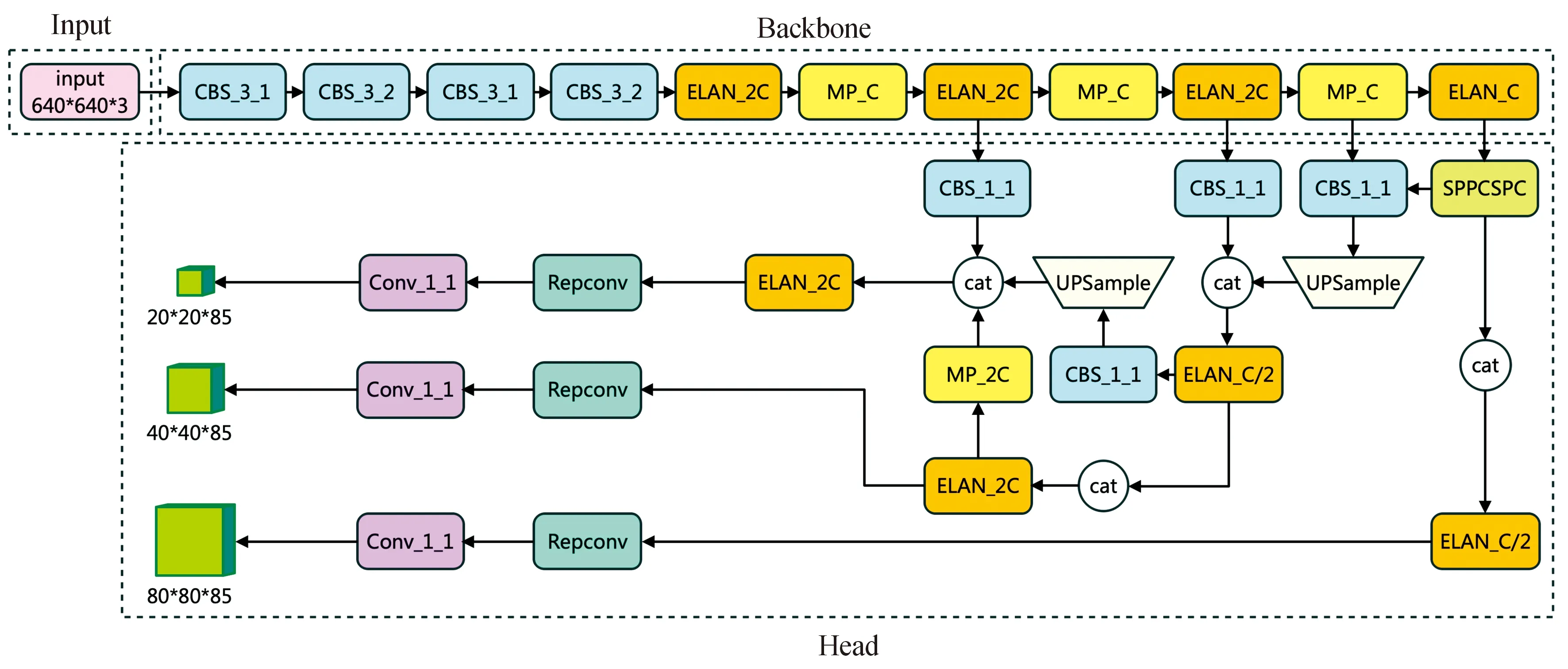
图1 YOLOv7网络结构Fig.1 Architecture of YOLOv7
YOLOv7的Backbone由若干CBS(Conv+BN+SiLU)层、高效层聚合网络(efficient layer aggregation network,ELAN)层和MPConv层构成,Head由SPPCSPC层、若干CBS层、若干Catconv层以及后续输出的重参数化结构Repconv层等组成。首先对输入的图片进行预处理,对齐成640×640大小的RGB图片,然后输入Backbone网络中,根据其输出,在Head层经过Repconv和Conv,输出三层不同大小的feature map,最后得到预测结果。
1.2 改进YOLOv7算法
1.2.1网络结构的改进
自注意力机制[14]为获取全局信息提供了新的思路,使用它会使模型的参数减少,避免了卷积神经网络参数堆叠造成的模型臃肿现象,同时也可以提高精度,在计算机视觉领域使用自注意力机制的一种方法是用多头自注意(multi-head self-attention,MSHA)层替换空间卷积层[15]。
BoTNet是一个引入自注意力机制的概念简单但功能强大的主干架构,广泛应用于图像分类、目标检测和实例分割等计算机视觉任务。BoT块是ResNet瓶颈块的改进模型,将其最后3个3×3空间卷积层替换为MHSA(见图2),以加强网络的特征识别能力,且不会增加太大的计算量[16-17]。将Mask R-CNN模型中的ResNet-50改进为BoTNet-50,超参数不变,在COCO实例分割基准集上的mask AP比原来提升了1.2%,在实例分割和目标检测方面显著改善了基线,同时还减少了参数,从而使延迟最小化[16]。
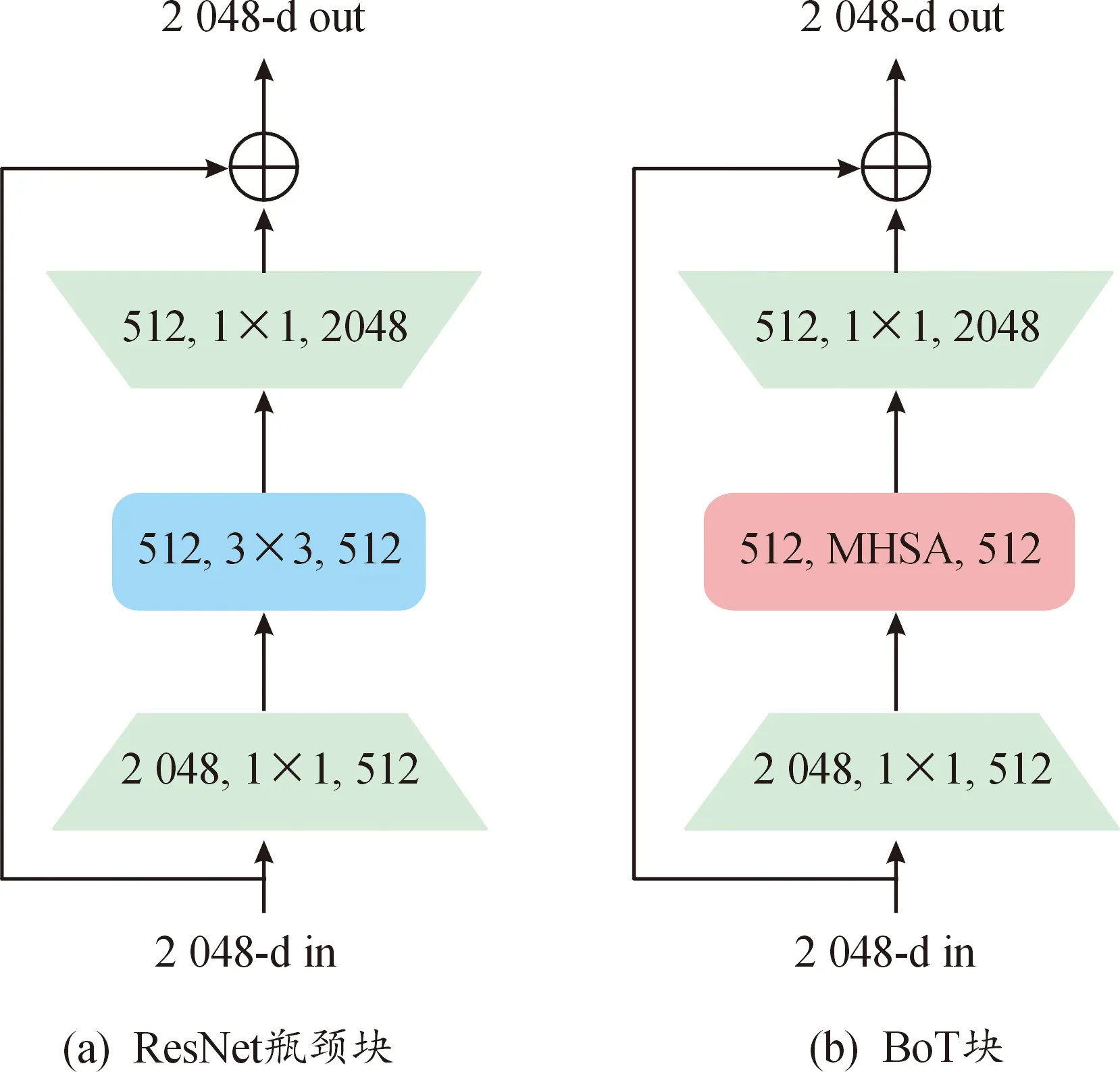
图2 ResNet瓶颈块和BoT块的结构Fig.2 Structure of ResNet bottleneck block and BoT block
本研究中将BoT结构引入YOLOv7,对其网络结构做了如下改进:首先,在Backbone中将CBS层之后和末端的ELAN结构替换为BoT结构,对输入的特征进行全局建模,提高特征提取能力,通过自注意力机制让网络更加关注全局性,提取出更多不同的特征以区分行人、汽车和其他高亮目标的背景信息,提高检测的准确率;其次,在Head层中将全部ELAN结构替换为BoT结构,在减小参数量的同时更好地融合Backbone提取的特征,改进后参数量大小为31.998 MB,较原YOLOv7模型的参数量减少了5.202 MB,得到改进模型BoT-YOLOv7,其网络结构如图3所示。
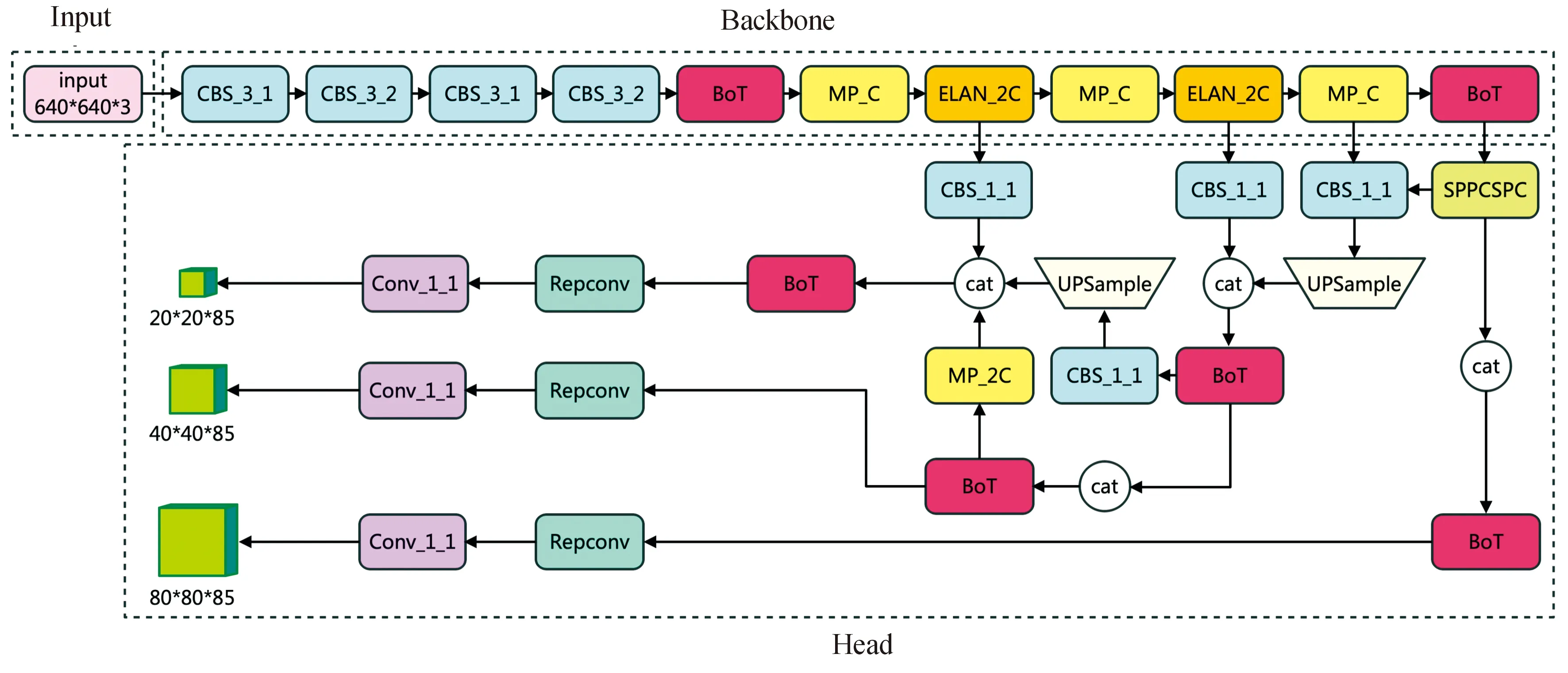
图3 BoT-YOLOv7网络结构Fig.3 Architecture of BoT-YOLOv7
1.2.2损失函数的改进
损失函数的质量直接影响训练速度和探测器性能。YOLOv7包括回归损失(Localization loss)、置信度损失(Confidence loss)和分类损失(Classificationloss)等3种损失,其中回归损失函数采用了CIoU(Complete-IoU),公式为:
(1)
其中:b和bgt分别表示预测框和真实框的中心点,ρ(·,·)表示这2个中心点间的欧氏距离,c是同时包含预测框和真实框的最小外接矩形框的对角线的长度;v用来衡量两个框宽高比的一致性,τ为权重函数,且有:
(2)
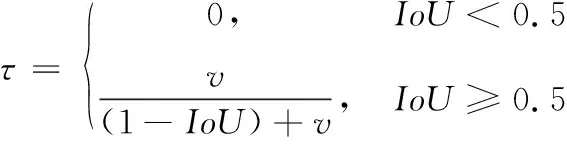
(3)
其中:wgt和hgt分别表示真实框的宽和高;w和h分别表示预测框的宽和高。
IoU、GIoU(Generalized-IoU)和CIoU等损失函数主要从预测框和真实框的重叠区域、距离和长宽比等三方面进行考虑,而未考虑真实框与预测框之间不匹配的方向。该不足导致收敛速度变慢且效率较低,因为预测框可能在训练过程中“四处游荡”难以收敛,并最终产生更差的模型。为此,文献[18]重新定义了惩罚指标,提出了SIoU(Scylla-IoU)损失函数。
SIoU损失包括角度损失(Angle cost)、距离损失(Distance cost)、形状损失(Shape cost)和IoU损失(IoU cost)4部分[18-19]。
角度损失:
(4)
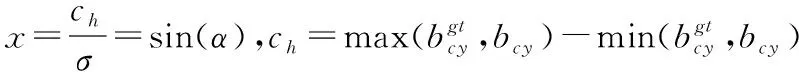
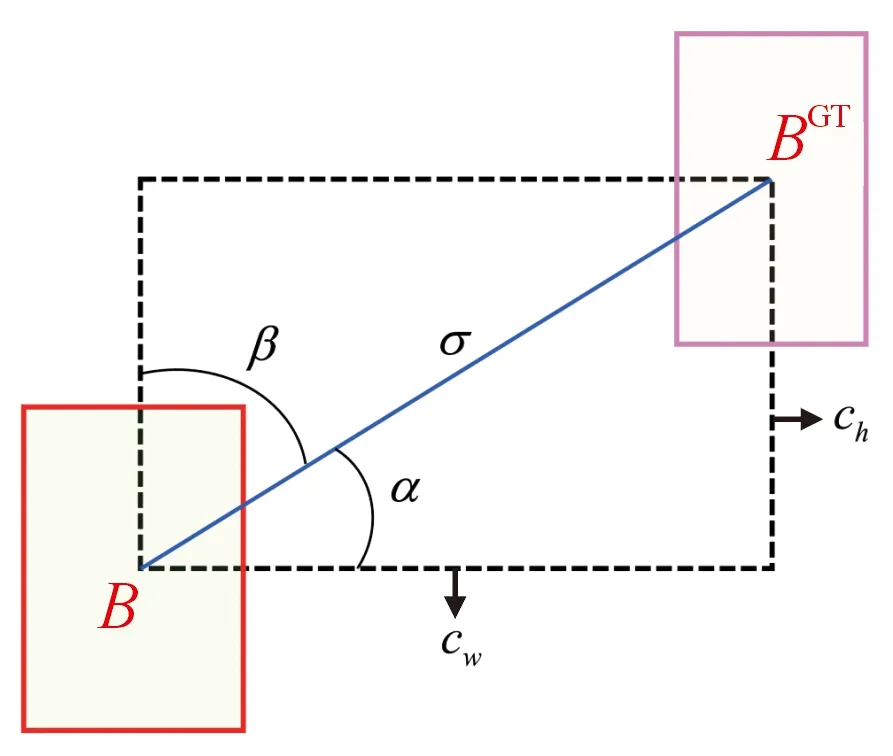
图4 角度损失计算示意图Fig.4 Scheme for calculation of angle cost
在角度损失的基础上,重新定义距离损失:
(5)
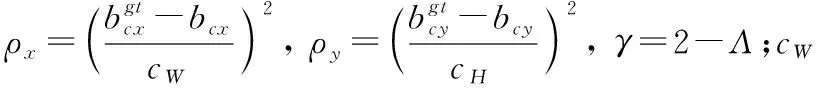
形状损失:
(6)
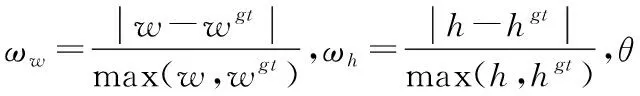
综上可得SIoU损失函数为:
(7)
BoT-YOLOv7使用SIoU损失函数替换YOLOv7算法中的CIoU损失函数,考虑预测框与真实框之间的角度,使用角度损失对两框间的距离重新进行描述,降低自由度,加速网络收敛,从而提升预测精度。
2 实验结果与分析
2.1 实验环境
实验所采用的硬件和软件配置为:CPU为17-12700K 3.6 GHz,GPU为英伟达架构RTX3090TI,CUDA为11.2,Python版本为3.8.5,深度学习框架采用PyTorch搭建,其版本为1.13.0,操作系统采用Windows10。
2.2 实验数据集
为了验证本研究中所提出的BoT-YOLOv7算法的有效性,在公开数据集微光视觉下可见光—红外图像对(visible-infrared paired dataset for low-light vision,LLVIP)[20]和多光谱道路场景(multi-spectral road scenarios,MSRS)上进行训练测试。LLVIP包含15488对图像,其中大多数图像在非常黑暗的场景下拍摄,所有图像在时间和空间上严格对齐。MSRS包含1 444对高质量的对齐图像对,它删除了MFNet数据集[21]中125个未配准的图像对,收集了已配准的729个夜间图像对和715个日间图像对,利用图像增强算法优化了红外图像的对比度和信噪比。
融合图像由生成对抗网络融合(FusionGAN)法[10]得到,它吸收了2种图像的优点,既能保持红外图像的热辐射信息,又能保持可见光图像的清晰外观纹理信息,可以获得对于场景的全面准确的图像描述,降低外界因素对多目标检测的影响,适用于全天候全时段的目标检测任务。FusionGAN的架构主要包含生成器和判别器,如图5所示。
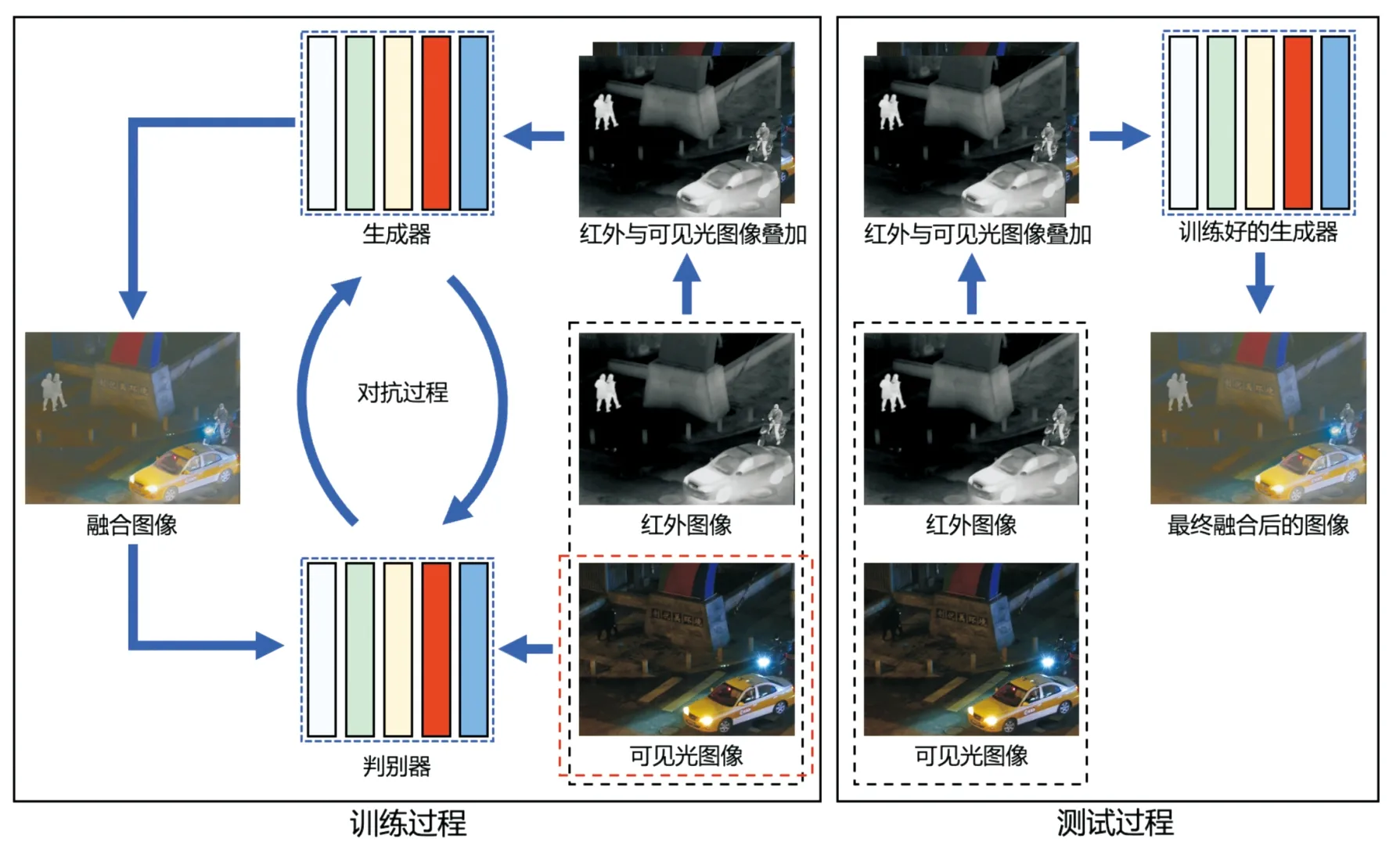
图5 FusionGAN的结构框架Fig.5 Framework of FusionGAN
在图5中,生成器是包含5个卷积层、4个批量归一化层、4个漏式ReLU激活函数和1个tanh激活函数的五层卷积神经网络;判别器也是五层卷积神经网络,它包含4个卷积层以提取输入的特征图、1个线性层用于分类、4个批量归一化层和4个漏式ReLU激活函数[10]。对抗过程中,生成器在保留红外光热辐射信息的同时,不断使融合图像中包含可见光图像中更多、更丰富的纹理细节信息。训练时,先将可见光图像与红外图像叠加在一起输入生成器,再将生成器生成的融合图像与可见光图像一起输入判别器让其区分,最后将判别结果反馈给生成器,形成一个对抗的过程,直至判别器无法区分融合图像与可见光图像时,训练结束。在测试过程中,使用已训练好的生成器去融合可见光与红外图像,得到最终的融合图像[10,22]。
可见光、红外、融合3种类型均包含16 932幅图像,按照7∶2∶1比例将图像随机划分为训练集、验证集和测试集,原始图像大小为640×480。
YOLOv7包含Mosaic数据增强,但由于LLVIP数据集中汽车图片的数据较少,属于不平衡数据,所以利用Copy-Paste方法[23]来增强汽车数据的数量,将数据集扩充为18 406幅图像。
训练时的超参数为:初始学习率为0.01,周期学习率为0.2,权重衰减为0.000 5,动量系数为0.937,迭代轮次(epoch)为300,训练批次为32。
2.3 评价指标
本研究中采用精确率(precision,P)、召回率(Recall,R)、平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)以及帧率(frames per second,FPS)等指标来评价模型性能,计算公式为:
(8)
(9)
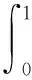
(10)
(11)
其中:TP(true positive)为真正例;FP(false positive)为假正例;FN(false negative)为假负例;C为检测的类别数。AP是P-R曲线下的面积,衡量算法对某类目标的检测精度。AP(i)表示对第i类目标检测的AP值。mAP是各类AP的算术平均值,从整体上评估模型的检测性能,该值越大,模型的检测性能越好。mAP@0.5表示IoU为0.5时的mAP。FPS是每秒钟处理的图像帧数,用来评价目标检测模型的速度。AP、mAP和FPS为评价多目标检测算法准确性和实时性的常用指标。
2.4 消融实验和算法性能对比
为了验证本研究中所提出改进的有效性,在数据集上开展了消融实验,改进用“√”表示,未改进用“-”表示。对融合图像进行检测,结果如表1所示。

表1 YOLOv7算法消融实验Table 1 Ablation study of YOLOv7 algorithm
由表1可以得到如下结论:① 引入BoT结构时,对行人和汽车的检测精度均有所提升,mAP@0.5值提升了3.66%,速度提升了2.13%;② 将回归损失函数改进为SIoU时,mAP@0.5值提升了2.17%,速度细微提升;③ 同时做这2种改进时,对行人的检测精度提升了3.47%,对汽车的检测精度提升了8.46%,平均精度均值和检测速度较原始YOLOv7分别提升了5.83%和4.26%。
为进一步证明改进算法的检测性能,选取Mask R-CNN、YOLOv5、BoT-YOLOv5、YOLOv7等主流算法进行性能比较实验,使用相同的实验环境和训练超参数,结果如表2所示。
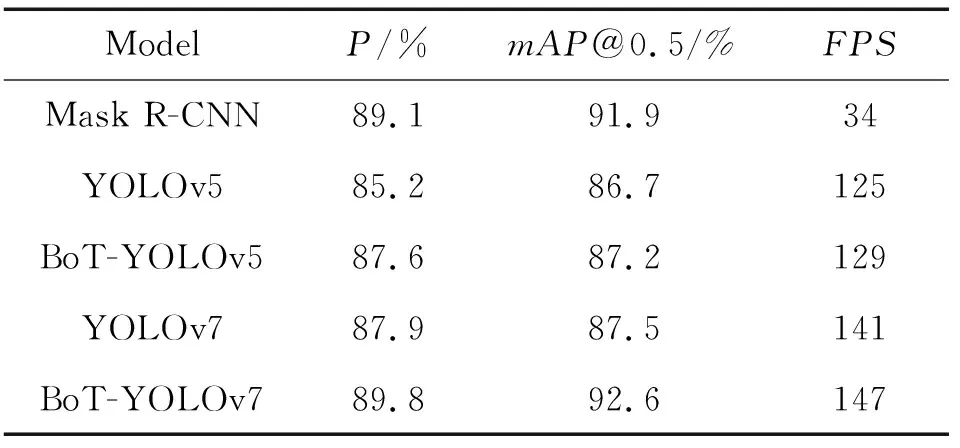
表2 BoT-YOLOv7算法与其他主流算法的性能比较Table 2 Performance comparison between BoT-YOLOv7 model and other state-of-the-art models
由表2可以看出,BoT-YOLOv7算法的检测精度比Mask R-CNN、YOLOv5、BoT-YOLOv5和YOLOv7分别提高了0.76%、6.81%、6.19%、5.83%。BoT-YOLOv7算法的检测速度可以达到147 FPS,分别为Mask R-CNN、YOLOv5、BoT-YOLOv5和YOLOv7的4.32倍、1.18倍、1.14倍和1.04倍。这说明改进算法的检测精度和速度比YOLOv5等主流算法均有提升,可以满足实时检测的要求。
使用BoT-YOLOv7模型分别在可见光(visible)、红外(infrared)和融合(fusion)图像上进行训练,并绘制精度曲线进行定性比较分析。图6给出了BoT-YOLOv7模型对3种类型图像检测的mAP@0.5对比。
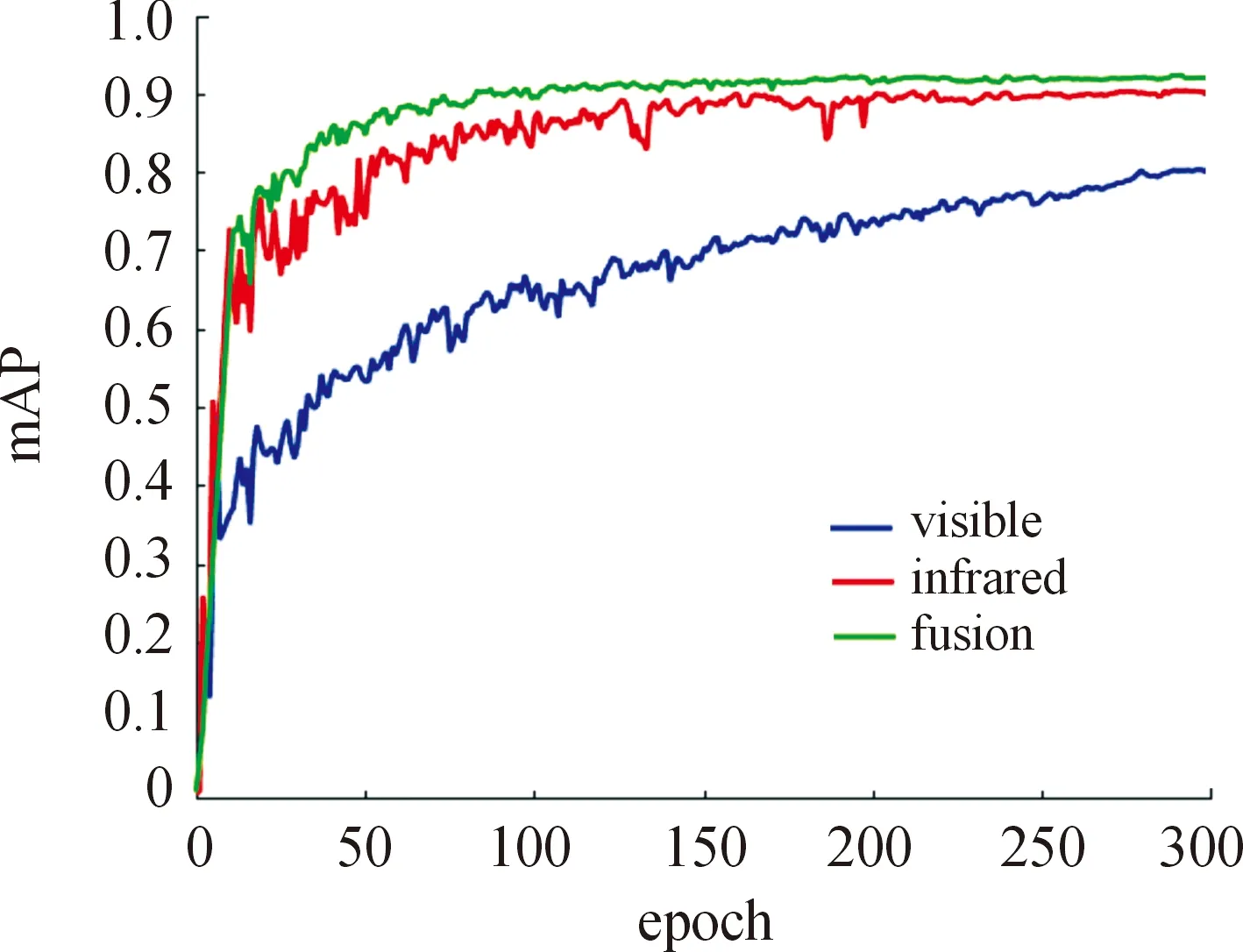
图6 BoT-YOLOv7对三类图像检测的mAP@0.5对比Fig.6 Comparison of mAP@0.5 for three kinds of images with BoT-YOLOv7 algorithm
由图6可以看出,BoT-YOLOv7对融合图像检测的平均精度均值高于可见光和红外图像。这是因为融合图像可以进一步增强目标与背景信息之间的特征差异,从而提升多目标检测的准确性。
2.5 检测结果可视化分析
为了直观比较YOLOv7和BoT-YOLOv7算法对可见光、红外和融合图像的检测效果,从测试集中随机选择了一些图像进行实验验证。图7给出了在公开数据集LLVIP和MSRS上行人和汽车目标的检测结果,其中目标框上的数字表示置信度,从左到右三列分别表示对可见光、红外和融合图像的检测结果。

图7 YOLOv7和BoT-YOLOv7的检测结果对比Fig.7 Visualization detection results comparison between YOLOv7 and BoT-YOLOv7 algorithm
由图7可以看出,使用YOLOv7模型检测时,存在漏检情况:比如图7 (a)中可见光图像漏检一个行人和汽车,红外光图像漏检行人,融合图像漏检一个行人;图7 (c)中可见光图像漏检行人,红外光图像漏检汽车。而相比YOLOv7模型,使用BoT-YOLOv7模型检测时,漏检情况在一定程度上得到改善:比如图7(b)的3类图像均未出现漏检,图7(d)中仅可见光图像出现漏检。除漏检情况得以改善外,改进模型的检测精度均比原始模型高。无论YOLOv7模型,还是BoT-YOLOv7模型,对融合图像检测效果最理想,检测准确率比单独使用可见光或红外图像要高。综上所述,对融合图像使用BoT-YOLOv7模型进行多目标检测时有更好的效果。
3 结论
提出了一种基于改进YOLOv7的微光与红外融合图像的多目标检测方法。改进模型BoT-YOLOv7在保持原始模型YOLOv7高实时性的同时,对融合图像的检测精度高于原始模型YOLOv7,有效提升了微光环境下行人和汽车等多目标检测的精度;改进模型对融合图像检测的平均精度均值高于可见光和红外图像;使用改进模型,漏检和误检情况得到一定程度的改善;改进模型的平均精度均值和检测速度均高于Mask R-CNN、YOLOv5、YOLOv7等主流模型。改进模型可实现对行人、汽车等多目标的快速准确检测,对微光环境下的军事侦察、遥感探测、野外救援和视频监控等任务具有重要的应用价值。
