基于深度强化学习的作战实体智能感知与决策研究
2023-06-27刘网定张国宁郑世明
刘网定,张国宁,郑世明
(陆军指挥学院作战实验室,南京 210045)
0 引言
伴随着前沿智能科技的飞速发展,越来越多的无人装备、智能技术应用于战场,智能化战争初露端倪。现有计算机辅助决策通常是基于规则的决策,智能化程度较低,难以适应未来有人/无人作战新形势的需求,这就需要突破传统靠固定规则推理的方法,探求具备自我学习和动态分析预测能力的方法框架,以求自主而准确地判断战场态势并作出行动决策。
从AlphaGo、星际争霸AI 到AlphaGo Zero,深度强化学习技术在围棋、游戏、自动驾驶、机器人制造等领域取得不断进展,使得智能感知与决策可以达到甚至超越人类水平,例如AlphaGo 依靠深度学习把握了围棋对弈的“直觉”棋感和棋势,通过强化学习实现了自我学习和优化棋招,击败了围棋世界冠军李世石。深度强化学习的机制与方法[1-5],借鉴参考了心理学中的行为主义理论,符合人类的分析决策思维方式,这为解决自主感知与决策问题提供了一种技术框架。本文利用深度学习挖掘态势数据中的隐含特征,全面地抽象到态势感知;再通过强化学习模仿人对事物的认知方式,在无监督的情况下,通过不断地试错,达到对战场态势的累积学习,形成正确的战场认知结论与决策结果。
1 框架构建原理
1.1 强化学习基本结构
强化学习受到人和动物学习中试错法的启发,智能体如何决策(作出行动)来源于环境的反馈,对于正确的行动,环境会给出奖励,对于错误的行动,环境会给出惩罚,智能体根据环境的反馈来调整自己的决策,通过与环境的不断交互与反馈,最终能够得到最优决策方案。强化学习基本结构如图1 所示。
1.2 基于深度强化学习的感知与决策原理
深度强化学习本质是将深度神经网络融入强化学习基本结构之中。针对大规模状态/动作空间问题(包括连续状态/动作空间问题),值表形式的值函数所需要的存储空间远远超过了现代计算机的硬件条件,使得经典的强化学习算法不再适用。在此情况下,可使用深度神经网络对复杂环境状态予以分析表示,解决智能体对环境状态的难以理解问题;使用深度神经网络对强化学习的相关函数(例如价值函数、动作价值函数、策略函数等)进行估计,解决强化学习的维度灾难问题。基于深度强化学习的感知与决策原理如图2 所示。

图2 基于深度强化学习的感知与决策原理示意图Fig.2 Schematic diagram of perception and decision-making principle based on deep reinforcement learning
2 基于深度强化学习的智能感知与决策框架
依据1.2 中的原理,基于深度强化学习的智能感知与决策框架主要由两部分组成,一是智能体对环境的感知部分,此部分基于深度学习构建,二是智能体的行动优化部分,此部分基于强化学习(包含深度神经网络的强化学习)构建;同时,考虑态势数据的预处理与专家知识的利用。因而,基于深度强化学习的智能感知与决策框架包含态势数据预处理、态势感知、行动优化和知识库4 个模块。预处理模块用以对态势数据进行清洗、归一等操作;态势感知模块由多个神经网络融合而成,用以表征战场态势;行动优化模块用以“评判”智能体的行为;战场知识库用以“指导”神经网络模型的构建,提高深度学习与强化学习的学习效率。框架示意图如下页图3 所示。
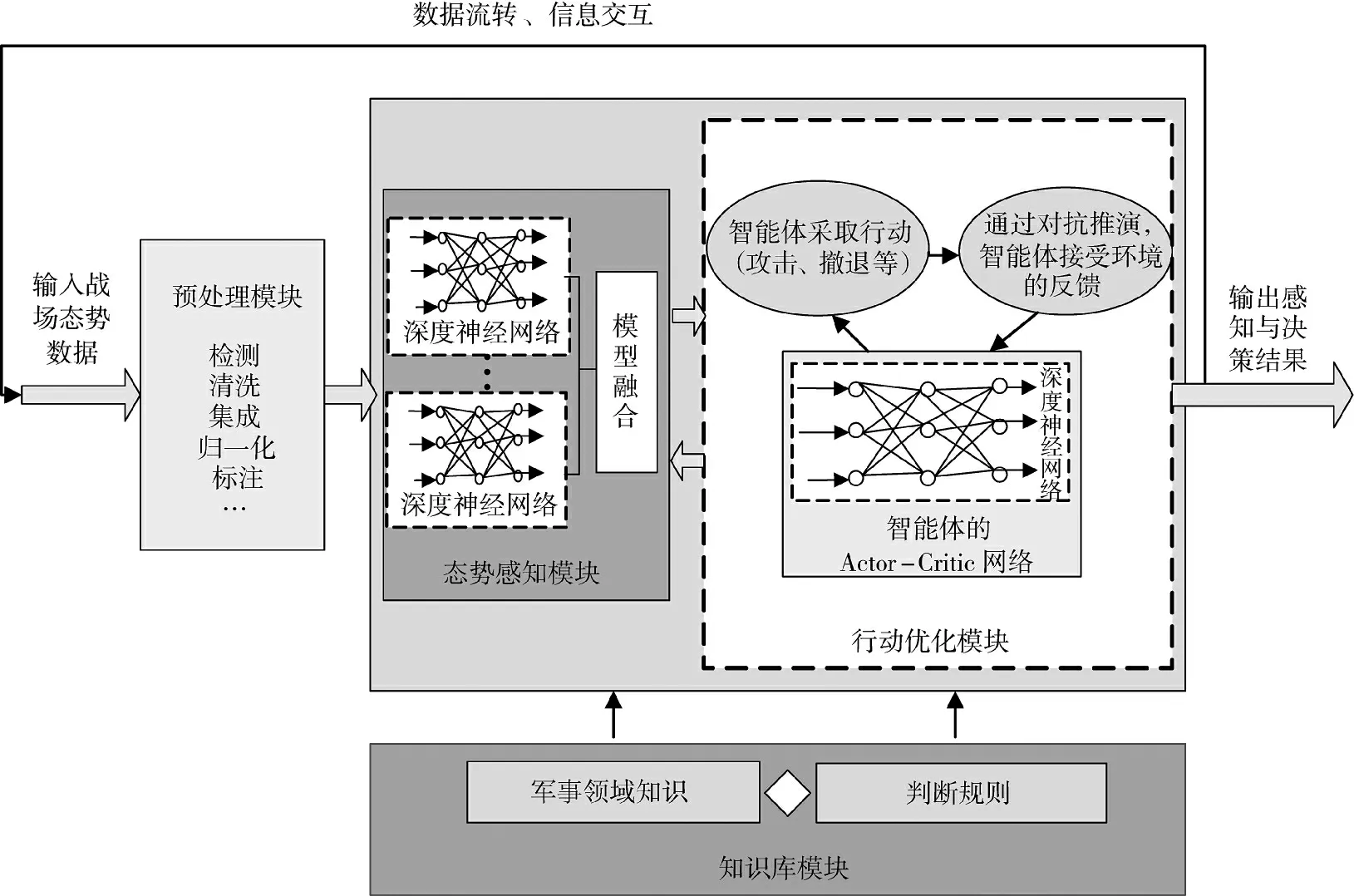
图3 基于深度强化学习的智能感知与决策框架示意图Fig.3 Schematic diagram of intelligent perception and decision-making framework based on deep reinforcement learning
2.1 态势数据预处理模块
战场态势数据一般需进行预处理,以满足深度强化学习算法要求,预处理方法主要包括检测、清洗、集成、归一化、正则化等,但并非所有的态势数据均要通过所有预处理操作,需视具体态势数据的获取、来源、格式等情形而定。例如对于收集到的传感器数据,由于传感器状态信息的量程并不一致,在将数据信息传入网络模型之前,为了提升模型的收敛速度及精度,防止模型出现梯度爆炸,应对传感器信息数据进行归一化处理,统一量程。
2.2 知识库模块
感知和决策的过程都需要知识库予以支撑,在知识库的驱动下,感知信息更为精准,决策依据更为充分,学习的收敛速度会更快,学习的结果会更可靠。知识库包括战场环境知识库、敌我部署知识库、敌我状态知识库以及敌我行动知识库等。知识库中的知识来源于两方面:1)直接存入库中的军事领域专家知识,2)通过不断学习获得的经验知识。
2.3 基于深度学习的态势感知模块
利用深度神经网络的表征能力,可挖掘出态势数据中包含的特征与关系,包括战场上作战实体的属性、状态、类别、运动趋势,不同作战实体间的关系等,形成态势感知表示[6-8]。由于战场态势的复杂性,往往无法用单个深度神经网络进行表征,因而基于指挥员的思维模式,将感知过程和目标进行分层,构建面向态势感知的复合架构深度学习模型。具体构建方法为:
1)通过对战场环境数据的学习,建立环境感知模型;
2)通过对战场上各个作战实体的属性、状态、行动趋势数据的学习,建立实体感知模型;
3)通过对不同作战实体特定时间段中时序状态信息的学习,构建实体间的关系判定模型;
4)以实体感知模型为主体,以实体间的关系判定模型为基本联系,结合环境感知模型,进行模型的融合,生成面向态势感知的复合架构深度学习模型,如图4 所示。
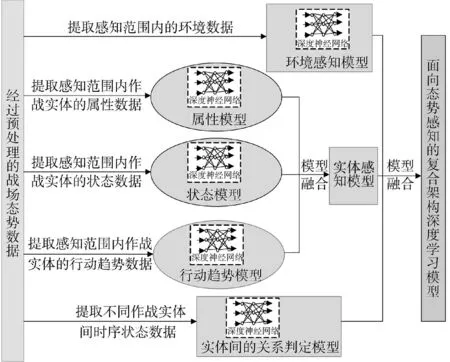
图4 复合架构深度学习感知模型示意图Fig.4 Schematic diagram of composite architecture deep learning perception model
在单个深度学习模型构建过程中,为提高模型的学习效率,可采用条件反射法,将强化学习的行动效果与专家知识、规则融入模型当中。如下式所示:
其中,wij表示神经元j 到神经元i 的连接权;yi、yj为神经元的输出;yj′是基于专家知识与规则的输出,α、β 是表示学习速度的常数。
1)若yi与yj同时被激活,即yi与yj同时为正,那么wij将增大,即此时强化学习的行动得到正的奖励,正确的态势理解结果被予以肯定和保留。
2)若yj′ 与yj同时被激活,即yj′ 与yj同时为正,那么wij将增大,即此时态势理解结论与专家知识、规则相一致,正确的态势理解结果被予以肯定和保留。
3)若yi被激活,而yj处于抑制状态,即yi为正yj为负,那么wij将变小,即此时强化学习的行动得到惩罚,错误的态势理解结果被予以否定。
4)若yi被激活,而yj′处于抑制状态,即yi为正yj′为负,那么wij将变小,即此时态势理解结论与专家知识、规则相悖,错误的态势理解结果被予以否定。
2.4 基于强化学习的行动优化模块
利用深度神经网络对战场态势表征后,并不知道其表征结果如何、与真实结果有多大偏差,利用强化学习的行动反馈机制,可通过智能体的行动去验证与调整表征结果。在此,从单智能体强化学习出发,借鉴强化学习在自动驾驶领域的成熟技术与经验[9-10],构建行动优化Actor-Critic 模型,如图5所示。

图5 行动优化A-C 模型示意图Fig.5 Schematic diagram of A-C model for action optimization
A-C 模型主要由两部分组成,一是Actor(执行器)部分,即智能体将要采取的策略,另一个是Critic(评价器)部分,即智能体得到的行动反馈(值函数),两部分分别通过深度神经网络表示。模型训练时,Actor 与Critic 交互更新,Actor 选择策略,Critic给出评价,最终可得最优行动策略。在战场环境中,利用深度强化学习进行自主感知与决策的单智能体实体,比如无人机、坦克,均为连续动作行动,可采用适合连续动作决策的强化学习算法,如DDPG算法、A3C 算法等。
在行动优化模块中,可采用启发式回报函数设计方法对知识库进行有效利用[11-12]。启发式回报函数设计规则为:
即当s∈S0,或某规则发生时,智能体执行动作a1,回报函数F(s,a,s′)赋值为r,这样便可刺激在某状态集S0或某规则发生情况下智能体执行动作a1。例如,如果(if)敌方作战单元行动速度、力量规模、装备类型、行动方向满足一定条件,根据专家知识,则可判定敌方将要采取何种行动,然后(then)智能体采取相应的对策a=a1,回报函数F(s,a,s′)=r。
3 案例分析
此部分通过仿真实验,结合具体想定,验证深度强化学习在智能感知与决策上的应用效果[13]。
3.1 实验想定
3.1.1 基本情况
红方对阵地防御的蓝方实施进攻作战,其中对红方部队威胁最大的是蓝方坦克部队,为尽快消灭蓝方坦克部队,红方指挥员迅速申请空中火力支援。上级派出无人机突击力量,依靠自身能力突破蓝方残余地面防空火力,对蓝方坦克部队实施攻击。
3.1.2 红蓝双方作战目标
红方作战目标:利用无人机空中优势,快速突破敌防空,消灭蓝方坦克。
蓝方作战目标:使用防空武器击落红方无人机,保护坦克不受其攻击。
3.1.3 红蓝双方兵力
实验设定红方兵力为固定翼无人机1 架,蓝方兵力为坦克排1 个、地空导弹排4 个,具体如表1所示。

表1 红蓝双方兵力Table 1 Forces of red and blue parties
3.2 框架设定
3.2.1 态势数据预处理模块
本实验将红方无人机设定为智能体。实验的每轮训练中,初始态势数据包括:无人机的位置(经度、纬度、高度)、朝向、速度、毁伤程度、作战任务,地空导弹排的位置(经度、纬度)、朝向、速度、毁伤程度、作战任务,坦克排的位置(经度、纬度)、朝向、速度、毁伤程度、作战任务,以及气象条件数据。训练之前,对战场环境中各作战单元的属性、状态、特征进行了编码,并对距离数据进行了归一化预处理。
3.2.2 知识库模块
实验的模型训练与模拟对抗主要运用合成部队层级知识库,包括红蓝双方作战编成、作战编组、兵力部署、毁伤程度、作战行动、作战任务与规则。
3.2.3 态势感知模块
对于实际战场环境,各作战单元的类型、属性、状态数据不可直接获得,一般需通过传感器获得相关数据。比如,通过传感器采集到作战目标图像,再通过感知模块中用于目标识别的深度神经网络,可初步判别出是何种目标。而本实验是仿真实验,各作战实体的类型、属性等数据系统可直接获得,因而态势感知模块的神经网络仅为简单线性函数。
3.2.4 行动优化模块
1)算法选择
此模块采用强化学习的DDPG 算法。DDPG 算法基于Actor-Critic 模型结构,并通过复制一个目标网络作为原网络的逼近对象进行缓慢更新,以保证训练过程的稳定性,如图6 所示。
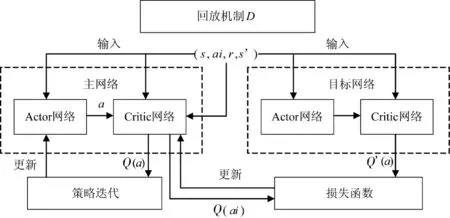
图6 DDPG 算法示意图Fig.6 Schematic diagram of DDPG algorithm
2)动作设定
强化学习模型中智能体无人机的动作值设定为“机动”与“开火”。执行动作函数时,首先检查是否进入任务区,进入任务区,则检查是否发现目标,发现目标进行自动开火;没有进入任务区,则设置无人机“机动”。
3)奖惩设定
智能体无人机的奖惩设定为:
b)根据是否进入目标区域设定回报Ra:进入目标区域,获得正的奖励,Ra=10;否则,Ra=0。
c)根据是否发现打击目标、是否执行了打击任务设定回报Rs:发现目标,获得正的奖励,Rs=50;击毁目标,获得更高的奖励,Rs=150;否则,Rs=0。
d)根据是否被对方击中设定回报Rf:若被对方击中,得到负的奖励,Rf=-100;否则,Rf=0。
3.3 实验结论
训练前,智能体完成任务的概率基本为0;3 000次训练后,对20 次仿真实验进行统计,智能体无人机成功突防并完成打击任务的平均概率提升为51.2%;5 000 次训练后,平均概率提升为88.6%;7 000 次训练后,平均概率提升为93.6%。智能体任务完成率对比情况如表2 所示,每个回合获得的平均奖励值如图7 所示。
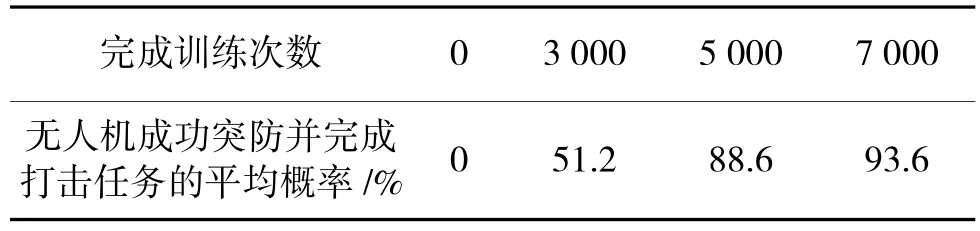
表2 完成任务对比情况表Table 2 Comparison of completed tasks
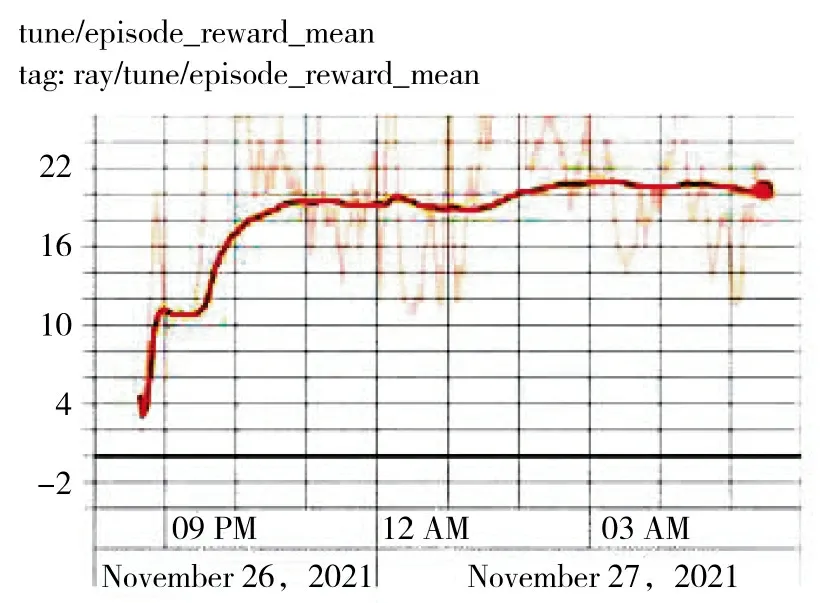
图7 智能体获得的平均奖励值Fig.7 Average reward value obtained by the agent
训练前,智能体无人机对战场态势没有自主感知能力,不知道打击目标在哪里、如何去寻找,其行动显示无规则。训练后,智能体无人机能够掌握对方地面防空武器威胁情况,能够自主确定最佳进攻路线,使其在飞行航线中威胁最小、生存概率最大,如下页图8 所示。
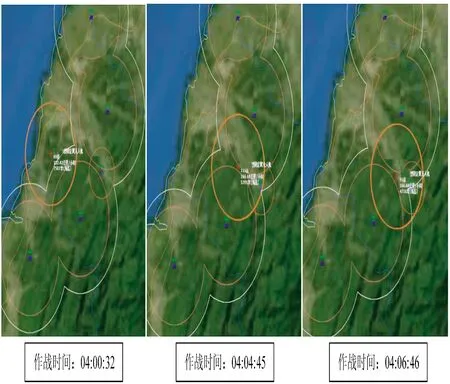
图8 训练后的无人机自主感知与决策效果图Fig.8 Effect diagram of autonomous perception and decision-making of UAV after training
4 结论
深度强化学习被认为是推进机器自主化与智能化最具潜力的技术。本文通过无人机突防仿真实验,展现了深度强化学习技术在作战实体智能感知与决策上的应用效果。推广应用于无人装备,可使其拥有自主感知与决策能力,能够自主进行环境侦察、路径规划、任务规划等活动,自主完成导航、制导、协调、目标识别、捕获、攻击等任务,提升无人装备的智能水平与应用效益。
