基于孪生Transformers 的遥感目标多元变化检测方法*
2023-06-27王得成张宏钢
郭 健,王得成,张宏钢,许 庆
(航天工程大学,北京 101416)
0 引言
变化检测是目前遥感领域重要的研究主题之一,其目的是在同一区域的双时相遥感影像中检测出感兴趣的变化目标。自动变化检测技术可以减少大量的劳动力成本和时间消耗,从而广泛应用于城市规划[1-2]、军事侦察以及自然灾害评估[3-5]。根据变化图中变化像素的表现形式,变化检测可分为二分类和多分类两种。二分类变化检测是指在生成的变化图中用二进制标签(变化和未变化)表示每个对应像素的变化情况[6-7];多分类(又称多元)变化检测生成的变化图中用多元标签表示不同地物的变化情况,提供详细的“从-到”或“消-长”变化信息[8-9]。
随着高分辨率卫星和航空遥感数据的爆炸式增长以及深度学习技术的快速发展,遥感领域的相关问题也得到了有效解决,如建筑物检测、土地分类、地物分割等。但在变化检测中,高分辨率增加了遥感影像的复杂性,模型难以区分场景中的真实变化和无关变化。目前常用的变化检测方法是基于卷积神经网络(CNNs)的深度学习模型,该方法利用卷积层强大的特征提取能力,学习双时相影像的变化特征,并通过上采样恢复到原来的图像尺寸,输出像素级预测结果。例如,DAUDT 等提出了两个孪生全卷积网络用于变化检测,训练过程中分别融合了图像的差分和图像的级联特征,表现出比传统方法更好的性能[10]。最近的研究结果表明,在CNNs 的特征融合阶段加入注意力机制,能够有效改善变化检测结果。例如,ZHANG 等在差异判别网络中将空间注意力和通道注意力模块串联,用来增强对双时相融合特征的变化检测[7];CHEN 等设计了一种金字塔时空注意力模块,建立不同尺度的时空依赖关系,得到较好的变化检测效果[11]。然而,由于卷积运算中感受野的局限性,使得CNNs 无法对双时相影像的远程上下文关系很好地建模,并且深层卷积引起的高计算复杂度导致模型的计算效率降低。因此,基于高分辨率遥感图像的变化检测任务仍然具有挑战性。
近年来,随着Transforemrs 模型在计算机视觉领域的广泛应用,为遥感变化检测提供了新的思路。CHEN 等提出了BIT 检测器将Transformers 和CNNs 网络相融合,利用Transformers 对CNN 提取的变化特征进行建模,虽然改善了检测效果,但在编码阶段仍然没有脱离CNN 的卷积操作,编码效率依然不高[12]。BANDARA 等提出了ChangeFormer 检测器,采用了Transformers 编码器与多层感知机(MLP)解码器相结合的方式,提升了多尺度远程变化检测的效率,但简单的MLP 解码器结构难以适应具有不同类别的复杂多元变化检测任务[13]。
目前大多数方法还是针对二分类变化检测,对于不同类别目标的“消失”“新增”等变化情况鲜有研究。本文针对飞机和舰船两类常见军事目标的变化情况,提出了一种基于孪生Transformers 的多元变化检测方法,对于双时相变化检测任务而言,孪生网络不仅有利于同时提取前后时相的图像特征,还通过权值共享策略减少了模型参数量,以此更加高效地获取变化信息。提出方法的主要贡献为:1)在特征编码阶段利用Transformers 代替了CNNs,更好地对双时相图像的远程语义信息进行建模,提高了模型计算效率;2)设计了融合Transformers 模块,整合了不同深度Transformers 的特征信息,进一步挖掘了Transformers 在遥感变化检测任务中的潜力;3)构建了军事目标变化检测的小型数据集,并且通过对多元目标变化的快速检测,尝试为战场提供稳定可靠的军事侦察情报。
1 视觉Transformers 模型
Transformers 是VASWANI 等在2017 年提出的基于自注意力的深度学习模型,最初在自然语言处理领域用于解决序列到序列任务[14]。Transformers对远距离依赖关系建模的有效性引起了广大学者对其在计算机视觉领域的应用。自首个基于Transformers 的图像分类模型Vision Transformers(ViT)[15]被提出后,用于遥感任务的Transformers 变体层出不穷,如遥感目标检测[16]、语义分割[17]以及遥感图像分类[18]等。
Transformer 模型的成功很大程度上得益于自我注意机制,该机制旨在捕捉序列元素之间的远距离关系,能够在不依赖任何卷积网络的情况下并行处理顺序数据。ViT 利用Transformer 的编码器模块,通过将图像块序列映射到语义标签来执行分类,与通常使用具有局部感受野的过滤器的传统CNN 架构不同,ViT 中的注意力机制使其能够关注图像的不同区域并整合全部图像的信息。图1 为Transformers的基本结构以及其中多头注意力模块(multi-head self-attention,MSA)的原理图。Transformers 由MHSA、多层感知机(multi-layer perceptron,MLP)和两个归一化层(norm)组成,并采用残差连接增强信息交互。Transformers 的核心模块是自注意力(selfattention,SA),自注意力的输入是根据语义tokens计算得到的三元组(query:q,key:k,value:v),其表达式如下:
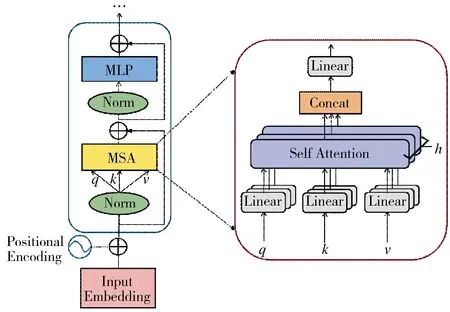
图1 Transformers 和MSA 模块的基本结构图Fig.1 Basic block diagram of Transformers and MSA modules
所谓多头注意力就是指在Transformers 中并行执行多个单独的自注意力模块,在不同的位置联合处理来自不同表示子空间的信息,并将输出连接在一起线性投射出最终的值。其过程如式(3),h 为注意力头的个数;表示MSA 的线性投影矩阵。
视觉Transformers 编码器的输入一般为带有位置信息的图像块向量,它们经过上述Transformers的特征建模后,得到了具有长距离上下文信息的新向量(Tokens),用于提高计算机视觉领域分类、检测和分割等任务的效率。
2 孪生Transformers 的变化检测方法
本文提出的孪生Transformers 变化检测模型主要由3 部分组成:图像块线性映射与位置编码、多级融合Transformers 编码器以及基于轴向注意力的变化图预测,图2 为本文模型的整体结构图。
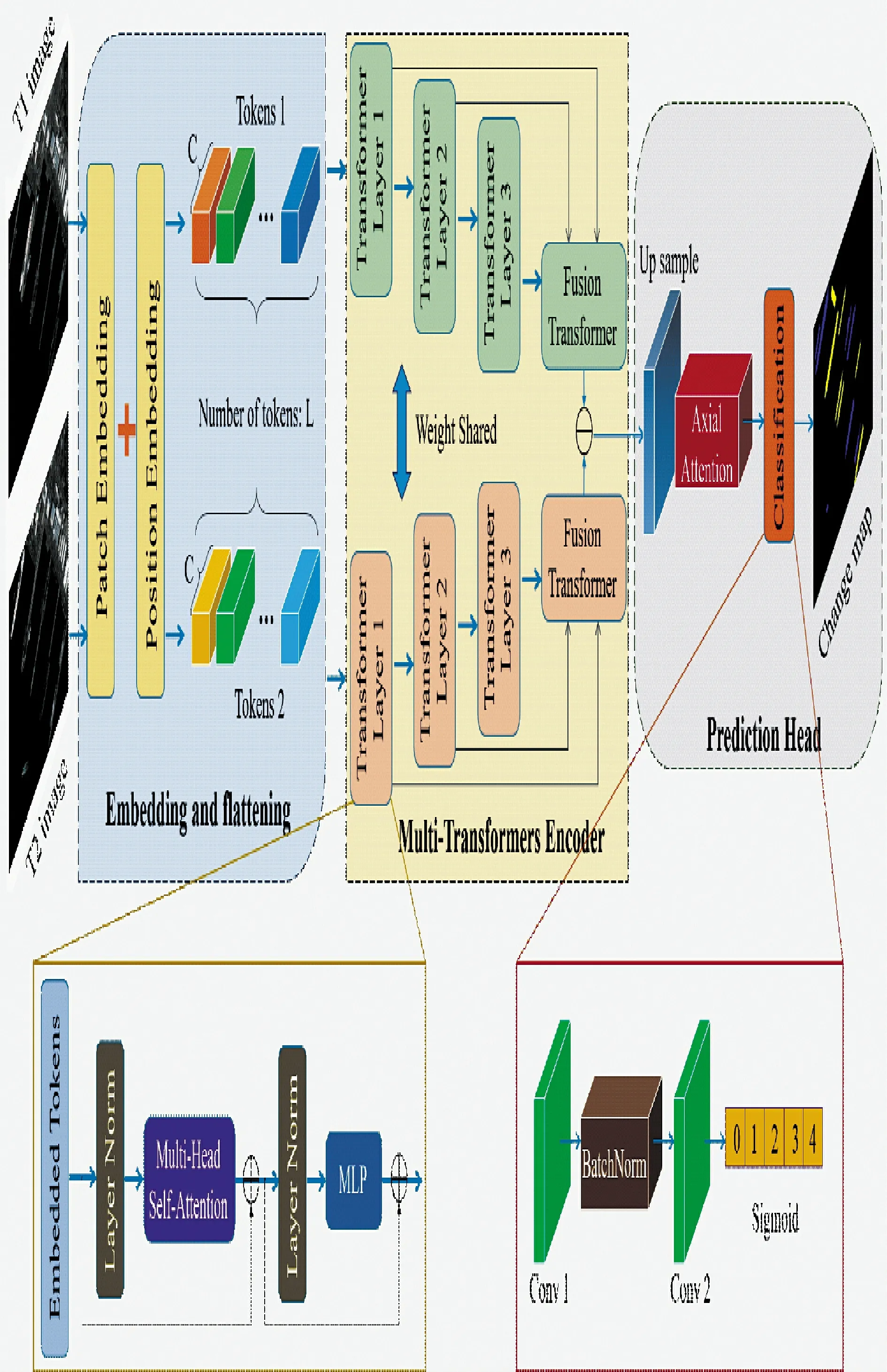
图2 提出的孪生Transformers 变化检测模型结构图Fig.2 Structure diagram of the proposed twin Transformers change detection model
2.1 图像块线性映射与位置编码
在Transformers 进行全局上下文建模之前,首先要将图像转化为序列。类似于自然语言处理中的标记器(tokenizer)将输入的句子转化为几个单词,视觉Transformers 将整个图像拆分为几个视觉tokens 作为编码器的输入。不同于TransCD[19]等方法先将图像经过CNN 提取特征,本文为了节省模型容量,减少不必要的计算成本,直接将输入图像T1和T2转化为带有可学习位置编码的tokens1 和tokens2,该过程可定义如下:
其中,xi表示Ti时刻遥感影像;E 表示线性映射操作,将输入图像(H×W×3)转化为()。如图2 所示,C 是token 的维度,L 是token 的总数。F 函数表示降维和转置操作,将经过线性映射的tokens 转化成(L×C)形状。最后在语义token 中加入可学习的位置编码以保留位置信息。
简言之,输入图像块经过线性映射与位置编码后转化为序列向量,用于输入到Transformers 编码器中进行上下文建模,从而获得具有远距离语义信息的特征向量。
2.2 多级融合Transformers 编码器
为了减少模型参数和显存消耗,本文利用权值共享的孪生Transformers 分别进行双时相遥感影像的特征编码。考虑到一个Transformers 模块难以对复杂语义特征进行上下文建模,因此,本文提出了多级融合的策略,将带有位置信息的图像块向量输入多个Transformers 编码器对不同层级特征建模;把每个Transformers 中的输出向量级联后作为最后一层融合Transformers 的输入,整合不同深度的编码特征;最后,将双时相编码特征逐像素相减得到差异图。其中,多级Transformers 的融合过程如式(5)所示:
式中,Q,K,V 分别为多级Transformers 融合后的query、key 和value;T 为上一层输出的Tokens;l 表示多级Transformers 的层数。因此,本文提出的融合Transformers 是将整个编码器中的所有Transformers层的query、key 和value 整合为包含不同深度信息的Q,K,V,再将其输入到最后的Transformers 层中,进行特征建模。
2.3 基于轴向注意力的变化图预测
经过多级融合Transformers 编码器的特征向量还需要上采样和分类等解码步骤才能获得最终变化图。本文旨在遥感图像中检测飞机和舰船的变化情况,需要对其微小变化十分敏感,而现有的基于CNN 的解码器难以满足较高的精确度。因此,在解码阶段提出了一种基于轴向注意力的变化图预测方法,将编码后的特征向量上采样到与原始图像相同大小,分别经过图像3 个维度上的轴向注意力模块,并与输入向量残差连接,最后经过由两个卷积块构成的轻量级分类器获得每个像素对应的变化类别,从而生成多元变化图。
轴向注意力机制[20]将三维向量的自注意分解为3 个步骤,依次在高度轴和宽度轴以及通道轴上应用一维自注意机制,按顺序组合可以捕获远全局上下文信息。这种做法可以减少计算复杂度,能够在大区域内捕获更远距离的依赖关系。将经过轴向注意力后的特征与之前特征通过残差连接,增强变化特征的同时抑制了无关信息,将原始特征中丰富的语义信息解码到变化图中。基于轴向注意力的上采样过程可以表示如下:
其中,AxH,AxW,AxC分别表示高度、宽度和通道维度的轴向注意力;x 为原始特征;Up 表示上采样模块;Z 为x 经过上采样输出的特征。图3 为轴向注意力的示意图。
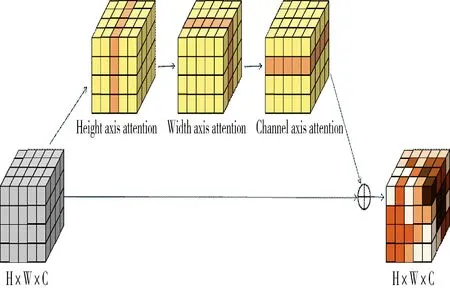
图3 三维轴向注意力模块原理示意图Fig.3 Schematic diagram of 3D axial attention module
通过轴向注意力得到丰富的变化信息,再利用卷积层和Sigmoid 函数将其进行像素分类。在生成的多元变化图中以不同颜色的像素表示飞机和舰船的出现与消失情况,旨在为军事侦察提供快速高效的战场情报。
3 实验过程与结果分析
本章对提出的基于孪生Transformers 的多元变化检测方法进行训练与测试,与其他流行方法进行对比,并根据实验结果展开分析。
模型的实验平台为搭载Titan RTX GPU 和Intel(R)Xeon(R)W-2245 CPU(3.9 GHz,256 GB RAM)的服务器。实验使用Pytorch 深度学习框架,将batchsize 设置为32,训练周期为200 个epoch,训练每个epoch 后验证模型,并将验证集上的最佳模型用于在测试集上评估。训练过程使用带动量的随机梯度下降(SGD)算法对模型进行优化,动量设置为0.99,权重衰减为0.000 5。初始学习率为0.01,随着迭代次数增加,学习率呈线性下降。
3.1 数据集介绍
本文使用的变化检测数据集来自光学卫星“吉林一号”拍摄的双时相遥感影像,主要覆盖北京大兴机场、福克斯空军基地、横须贺海军基地、纽约港口、圣迭戈军事基地5 个场景。标注的变化目标有飞机和舰船两类,变化类型为“未变化”“飞机消失”“飞机出现”“舰船消失”“舰船出现”5 种。每组数据中,前后时相的两张图片各自对应一张标注图,表示发生变化的目标及类别,空间分辨率均为0.5 m~1 m。图4 所示为数据集的部分样本示例,不同颜色像素代表不同类别的变化目标。前两行分别为同一区域前后时刻的遥感影像,最后一行是两种目标的变化参考图。

图4 数据集的部分样本示例图Fig.4 Partial sample example of datasets
由于整张遥感影像较大,为了减轻显存压力,将其剪裁为256×256 大小,以便网络的训练与测试,从中挑选出包含变化像素的图像块作为样本构建数据集。经过剪裁、旋转等数据增强,最终制备的数据集共包含1 511 对双时相影像,其中,训练集、验证集、测试集图像对分别为1 211,240 和150。
3.2 对比方法与评价指标
为了准确评估并比较本文方法的多元变化检测性能,下面介绍几种流行的变化检测方法用于对比实验。
1)U-Net++CD[21]:基于改进U-Net++ 的变化检测模型,将双时相图像级联后输入到U-Net++网络中,在解码器中利用深度监督策略,生成精确的变化图。
2)IFN[7]:一种基于空间和通道注意力的深度监督网络,采用U-Net 作为编码-解码器的基本架构,通过注意力模块增强双时相特征在解码阶段的融合。
3)BIT[12]:基于Transformers 的编码器-解码器变化检测模型,利用Transformers 对CNN 提取的双时相特征进行上下文建模,然后通过转换器解码器提炼原始特征,以预测变化图。
4)ChangeFormer[13]:一种基于分层结构的Transformers 变化检测模型,在孪生网络架构中将多层Transformer 编码器与MLP 解码器相结合,以有效获取多尺度远程准确变化检测所需的详细信息。
本文使用精确度(Pr)、召回率(Re)、交并比(IoU)和F 1 分数4 项指标来评估预测变化图和参考变化图之间的一致性。其中,IoU 是语义分割任务中的常用指标,F 1 分数是衡量二分类模型整体性能的综合指标,在多分类变化检测中计算每个类别的指标后取平均作为最终指标。上述指标的定义如下所示:
其中,TP、FP 和FN 分别代表真阳性、假阳性和假阴性的像素数。
3.3 实验结果分析
本文提出的基于孪生Transformers 的遥感目标多元变化检测方法,与上述4 种对比方法在变化检测数据集中进行了训练与测试,其部分检测结果如图5 所示。通过定性对比实验结果可以看出,本文方法在关于飞机和舰船的变化检测数据集中生成的多元变化图效果最佳,利用远距离上下文的语义信息可以更好地对变化特征进行建模,并且减少对伪变化区域的误判。在4 种对比方法中,U-Net++CD和IFN 是基于CNN 的变化检测模型,而BIT 和ChangeFormer 是基于Transformers 的变化检测模型。在图5 的实验结果中,基于Transformers 模型的结果(图5(d)、图5(e))明显比CNN 模型的结果(图5(f)、图5(g))具有更高的检测精度,这是由于Transformers 具有对远距离语义信息的强大建模能力,使得变化检测中能够获取更多全局特征,改善了CNN感受野的局限性。然而基于Transformers 模型对于部分变化目标的召回率却不如CNN,如图5 最后一个场景中,IFN 方法(e)检测到两艘消失的舰船,而BIT 方法(f)只检测出一艘,并且对于变化目标的形状表示不够准确。相比于4 种对比方法,本文方法得到的实验结果(h)不仅具有更高的检测精度,生成多元变化图中对变化目标的形状描述也具有更好的完整度。

图5 不同方法在本文数据集中变化检测结果图Fig.5 Change detection results of different methods in the proposed dataset
为了准确验证本文模型的变化检测性能,定量评价了上述对比方法和本文方法的相关指标,如下页表1 所示。通过比较可以看出,本文方法在除了“舰船消失”外的所有变化类别中都取得了最优指标,平均IoU 和F1 分数分别达到了68.69%和80.43%。另外,基于Transformers 的3 种模型性能明显优于CNN 模型,其中,ChangeFormer 方法对“舰船消失”类别的变化检测较为敏感。可见Transformers 的远距离建模性能比CNN 更适合于多元变化检测任务,易于捕捉到更加精确的变化目标。
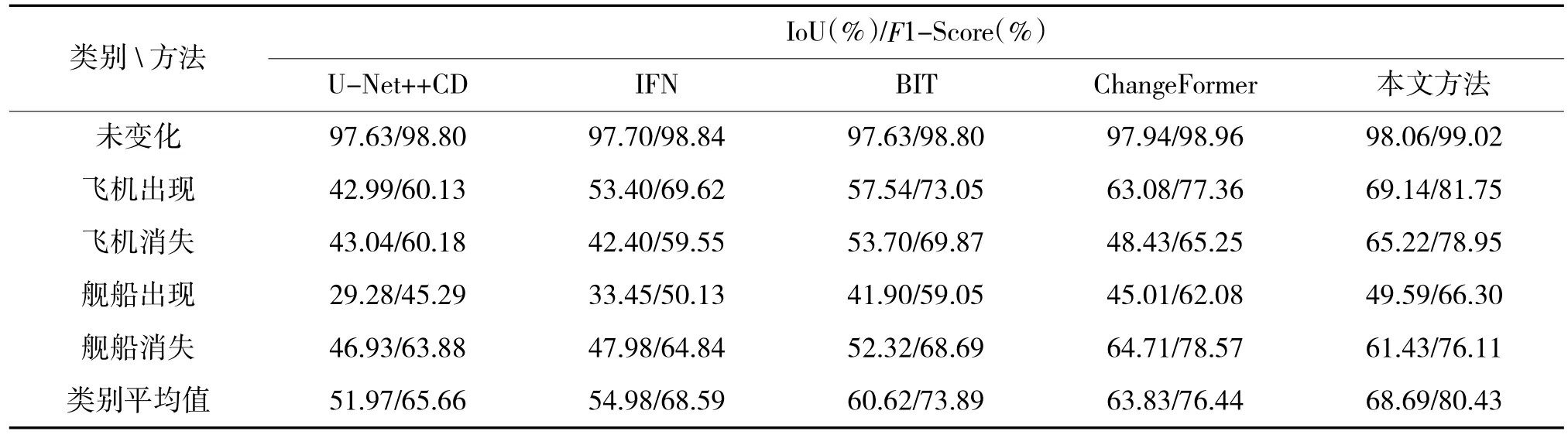
表1 变化检测方法在多元数据集上的评价指标Table 1 Evaluation metrics of change detection methods on the multiple dataset
3.4 消融实验
本文提出的基于孪生Transformers 的多元变化检测方法中主要贡献有两方面:1)在编码阶段构建多级Transformers 融合网络对不同深度特征建模;2)在解码阶段中加入轴向注意力机制生成更精确的多元变化图。为了进一步验证多级Transformers融合以及轴向注意力对于多元变化检测的效果,并确定编码器中Transformers 的层数,在本节中进行了消融实验。
表2 中展示了在编码阶段通过训练不同层数的多级Transformers 后得到的测试结果,Transformers层数分别取2,3,4,5,6,7。可以看出层数越多,模型普遍对于变化检测的召回率越高,而层数越少,模型的准确度越高。当层数为4 时,综合评价指标平均IoU 最高;当层数为6 时,平均F1 分数最高,然而比4 层Transformers 仅高出0.3%,却增加了大量的计算成本。因此,为了准确全面地检测到变化目标,并且能够相对节约计算资源,本文模型的编码阶段最终选择4 层Transformers 融合进行上下文建模。
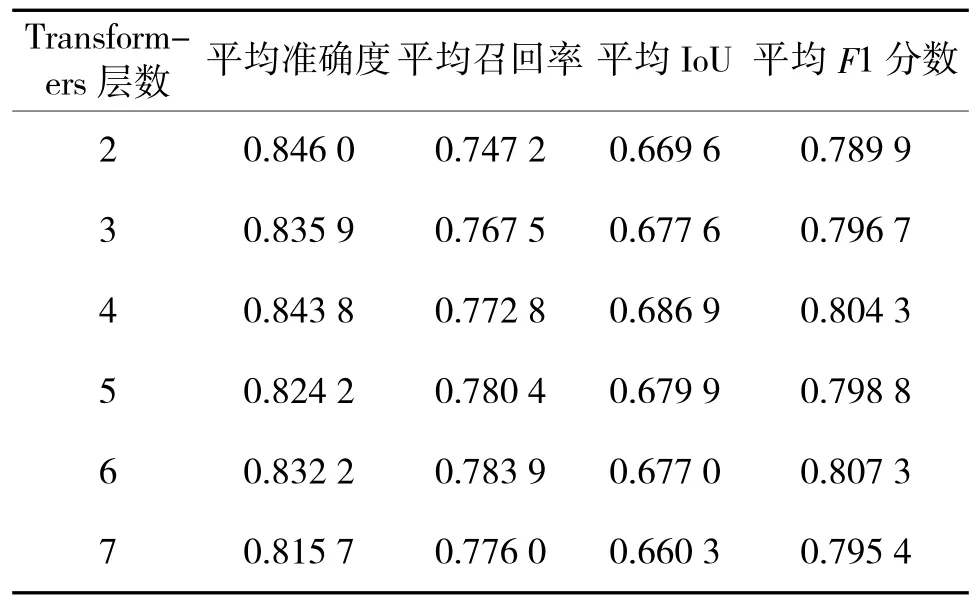
表2 多级Transformers 层数对变化检测结果的影响Table 2 Effect of the number of multi-level transformers layers on the change detection results
在确定Transformers 的层数(L)后,对Transformers 融合机制以及注意力模块的作用进行了验证,结果如表3 所示。从表中可以得出,仅引入Transformers 融合机制后,平均IoU 和F 1 分数分别提升5.13%和5.23%;仅加入轴向注意力模块后,平均IoU 和F 1 分数分别提升7.67%和7.39%;同时增加两者后,模型的变化检测性能大幅提升,平均IoU和F 1 分数分别增加10.32%和9.51%。因此,本文提出的两点贡献对多元变化检测模型的性能提升明显,其中,在解码阶段以残差连接方式加入轴向注意力对于模型效果的提升更为显著。
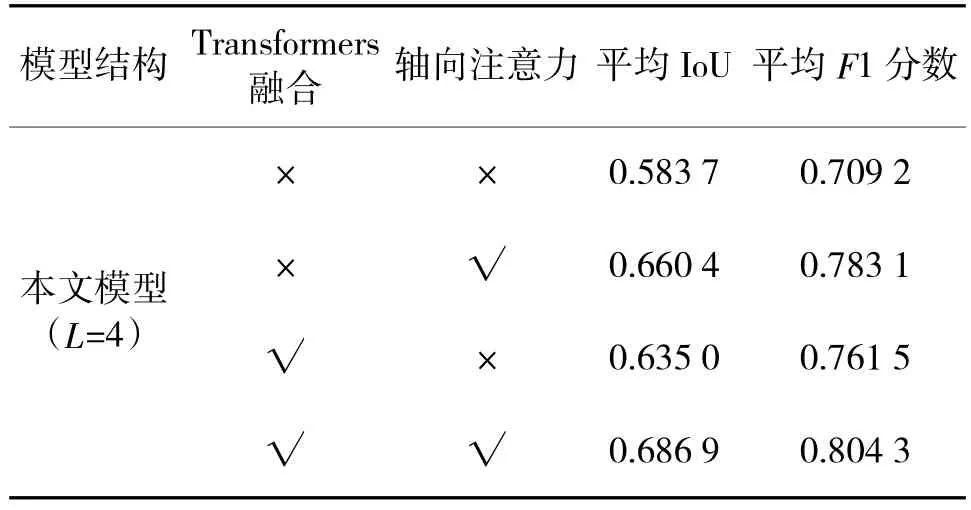
表3 Transformers 融合机制和轴向注意力的消融实验结果Table 3 The ablation experiment results of the Transformers fusion mechanism and axial attention
4 结论
针对双时相遥感影像目标的多元变化检测问题,提出了一种基于孪生Transformers 的多级融合网络。将图像转化为序列向量输入Transformers网络,融合4 个级联的Transformers 对不同深度特征的语义信息进行建模,最后,引入残差连接的轴向注意力模块解码变化目标,生成多元变化图。
本文利用遥感影像构建了包含飞机和舰船军事目标变化情况的数据集,并在变化检测数据集上训练和测试了提出的模型和其他流行的对比方法。经过定量评价和定性分析表明,提出的方法能够有效检测飞机和舰船的变化情况,并生成准确完整的多元变化图,平均IoU 和F 1 分数分别达到68.69%和80.43%,显著优于其他流行方法。通过消融实验,验证了本文提出的多级Transformers 融合策略和基于残差连接的轴向注意力机制的有效性,两种改进的引入使得模型的平均F 1 分数分别增加5.23%和7.39%。目前,基于Transformers 的变化检测模型还在研究初期,如何减少模型参数、提高模型效率将是下一步的研究重点。
