基于Kettle的铁路数据接入的设计与实现
2023-06-26王天举许丹亚尹文志齐晨虹
王天举 许丹亚 尹文志 齐晨虹





摘要:为解决实际业务中的数据接入解析处理等问题,使数据的接入、转换、解析、同步等工作更加高效便捷,文章通过对业务需求的分析和数据接入整合技术的调研,开展对开源ETL工具Kettle的研究。基于对Kettle应用场景和业务数据特点的分析,构建了基于Kettle的业务数据转换同步流程。经实际项目案例验证,该流程与传统方法相比,基于Kettle的数据转换接入流程降低了开发的复杂度提升了工作效率,不仅解决了在实际业务系统中的数据接入转化问题,同时也为其他数据集成工作提供了更多思路。
关键词:接入;转换;解析;集成;流程
中图分类号:TP39 文献标志码:A
0 引言
随着数字时代的到来,数据科学技术不断发展,社会各行各业都越来越重视数据,数据使得行业间的联系更加密切,企业对数据需求即时性的要求也相应提高,基础数据点對点传输、数据更新同步变得尤为重要。数据传输和同步的方法多种多样[1],目前,数据转换、同步的任务一般有两种方式可以选择[2-5]。一种是比较传统的方式,即通过SQL编程或者Java编码来实现,但是编码难度较大,难以快速构建ETL工作环境,具有一定的局限性。另外一种方式是通过数据库软件自带的抽取工具来实现数据转换和同步,但是这种方式灵活性不高,要求数据库必须是指定的类型[6]。
针对上述问题,结合在实际构建数据接入流程所积累的经验,以及数据源多样、数据结构多样、数据量大等特点,本文基于开源工具Kettle构建数据接入转换流程。在实际应用中发现,该方法能够很好地解决传统方式数据接入局限性的问题,能够很好地提高开发速度和工作效率,通过接入流程的设计,提供一种新的数据处理流程的思路与方法。
1 Kettle简介
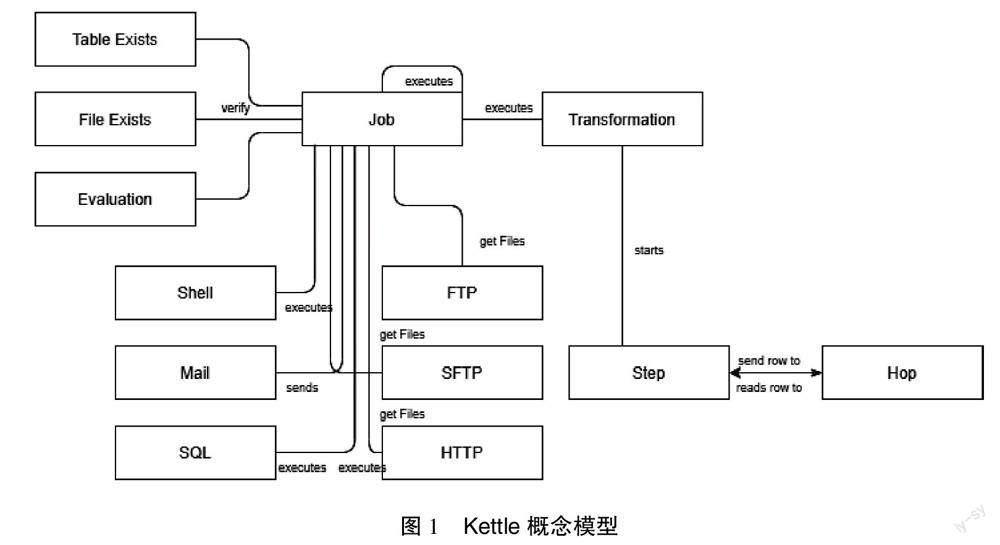
Kettle 是一个数据抽取、转换、装载(Extract-Transform-Load, ETL)工具[7-10],主要用来对不同数据库的数据、不同来源的数据进行处理,提供图形化的用户界面,使用户使用时描述想做什么,而不是想要怎么做。Kettle 有两种脚本文件:Transformation和Job。Transformation是转换,Job是对多个转换构建的整个工作流的抽象和控制[11-14]。Kettle概念模型如图1所示。
2 业务需求介绍
某铁路业务系统需要的业务数据会由业务部门定时放到单位内网FTP服务器上,开发人员定时从FTP服务器上获取数据到本地,并对业务数据进行备份。数据以非标准的XML文件存储,传统开发人员在获取数据之后需要编写大量代码对XML文件进行解码、标准化、解析、入库等操作,实现过程复杂、耗时,且后期维护困难、维护成本较高。
上述问题在系统开发过程中普遍存在。对于不同数据类型的业务数据,开发人员需要开发指定的代码,处理复杂数据类型的需求。这对开发人员的要求比较高。如果有一种可以供不同类型的数据源接入数据,并且操作简单、流程存在一定复用性的方案,那么就可以极大降低开发人员的工作难度和工作量。
3 数据接入流程
结合业务需求分析,本次数据接入主要实现定时数据获取、数据转码、数据标准化、数据解析、数据筛选、数据去重、数据入库等功能。
本文设计了数据定时接入的全部流程,在启动定时任务后,首先从FTP服务器上获取数据文件,完成数据文件的转码工作。转码完成之后,会对XML文件标准化,为后续文件做解析准备。解析完之后,对于不符合要求的字段需要进行数据筛选,完成数据筛选到数据入库之前,需要对解析完的数据同数据库中已经存在的历史数据进行对比,判断库中是否已经存在,从而完成数据筛选操作。数据接入流程如图2所示。
3.1 数据获取
业务部门会定时向开发部门内网FTP服务器上传XML文件。开发人员在获取数据之后,在本地完成业务数据备份,然后清空开发FTP文件夹,为下次数据同步做准备。
3.2 数据转码
获取数据后,开发人员需要对数据进行转码处理,建立满足标准化的文件编码格式,解决数据编码不一致、标准化过程中乱码导致失败的问题。
3.3 数据标准化
转码后的数据,需要得到标准化处理,包括内容的标准化和文件名的标准化。这样才能建立满足解析数据要求的文件标准,解决数据规范不一致、格式不统一的问题。
3.4 数据解析
根据业务系统需求数据类型及数据格式,在对原始数据转码、标准化之后,开发人员还需要使用Kettle设计来解析流程。解析流程需要注意组件之间数据输入、组件功能、各个组件之间的关系等,这也是整个流程的关键。
3.5 数据筛选
开发人员根据实际业务需求,从解析之后的数据中筛选出满足业务系统需求的数据信息,剔除目标数据库中不需要的字段和记录,同时为筛选之后的数据添加上UUID,将其作为唯一标识。这样操作可以解决去除多余数据、将达标数据录入目标数据库中的问题,整个数据筛选工作需要利用Kettle工具筛选组件来完成。
3.6 数据入库
筛选之后的数据,经过以上数据处理逻辑进行处理,可以剔除不符合条件的数据,完成数据的处理及质量检测。
根据以上数据策略步骤,结合实际需求分析,本文设计了如图3所示的数据处理架构,构建了基于Kettle的业务数据同步解析流程环境,形成了由业务数据到目标数据库的持续更新机制。
4 业务应用
基于Kettle的数据接入方法,结合业务数据信息及数据同步环境,本文设计了XML文件类型的数据接入转换流程,通过流程中的数据获取组件、转换组件、标准化脚本程序、筛选组件等,对从FTP服务器上获取的数据解析入库,并对数据准确性和完整性进行校验。同时,为了满足定时增量接入数据的需求,本文设计开发了定时触发执行脚本,以实现数据的增量接入,完成数据的持续更新。
5 基于Kettle的作业应用
从FTP服务器获取的XML文件,其格式和内容如图4所示。对于该文件,在正式处理之前须先预处理,包括数据转码(GB-2312-->UTF-8)、数据标准化(添加后缀名.XML)。如果没有经过预处理操作,Kettle工具就识别不出它是XML文件。
XML文件的解析需求,可以简单描述为<HPXX0000>,将标签内的箭头部分字段下放到<GZLDATA>标签内的所有子标签内;对于<GZLDATA>中的每个子标签,开发人员需要将<HPXX0000>标签内的数据按逗号分隔,使其作为数据表的一列。其 余子标签,先按照分号分割的内容作为数据表的一行记录,之后每一行再和<HPXX0000>标签下方的字段构成一条记录,作为数据表的一行数据。
從文件的内容格式来看,获取的源文件格式并不是一个标准的XML格式文件,该文件是缺乏顶级根标签的,故在数据预处理时需要添加根标签,本文中对XML文件添加的根标签是<root></root>。
基于对原始XML文件数据的分析,本文设计了如图5所示的数据接入处理流程。
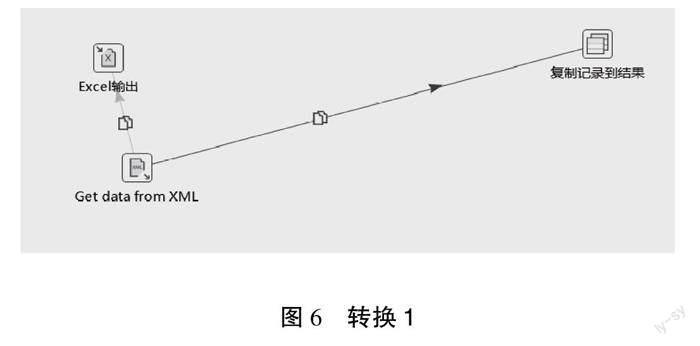
流程在Start之后,首先执行的操作是从FTP服务器上下载文件,该功能只需通过简单配置Kettle组件即可实现。然后是复制文件,这一步主要是解决本地文件备份的问题。因为开发人员从服务器上拉取文件之后会清空服务器文件夹,所以为了完成数据的预处理,项目组开发了.bat文件。数据在完成预处理之后开始解析。转换1操作是通过Kettle自带组件从XML中获取数据,并将其存放到记录中,如图6所示。
Kettle自带组件可以快速从标准XML文件中获取标签内的数据内容。这样不仅极大地提高了处理效率,而且在获取标签内容之后,还便于对后续字段的选择。转换2是从记录中获取数据进行解析。在解析过程中,开发人员首先要对从记录中获取的数据进行字段拆分、列拆分为多行、字段选择等操作,然后通过手动设置的筛选条件完成数据筛选,最后为了保证数据的唯一性,生成UUID作为该记录的主键。转换流程设计如图7所示。
6 定时触发任务
Kettle定时任务有多种实现方式,其中之一是采用Start来定时。采用该方式须保持客户端程序的一直开启,若关闭,Job也会停止。开发人员也可以采用win任务计划定时,该方式是采用.bat脚本和Kitchen结合的方式来实现的。对于Linux平台,开发人员可以采用.sh脚本和Kitchen结合的方式来实现,本文采用的就是第三种定时方式,实现.sh脚本程序如下:
cd /data/kettle/data-integration
export JAVA_HOME=/data/java/jdk1.8.0_141/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
./kitchen.sh -file=/data/kettle/kettle_job/test01.kjb
>>/data/kettle/kettle_log/ceshi_$(date +%Y%m%d).log
7 结语
本文根据实际业务需求,基于ETL工具 Kettle 制定了数据同步流程与策略,并在此基础上构建了基于Kettle的源数据库转换同步环境,设计一种新的数据同步流程,利用该流程实现对运输统计业务数据的高效抽取、筛选、转换和同步。同传统编码方式相比,该方法数据转换不仅能在速度上有大幅度提升,而且在处理复杂度上大大降低,极大地提高了数据接入效率,完全能够满足业务系统对目标数据库的查询、分析需求。同时本项目还制定了定时触发任务,解决了系统后台对作业任务的定时调度问题,最终实现了从数据源库到目标数据库高效自动持续更新的目标。未来,开发人员还将不断完善高数据质量,优化转换作业流程,以便提升数据同步效率,为数据转换、同步及迁移工作提供更多思路。
参考文献
[1]郭德卿,徐国强,李娜.基于Kettle数据传输与同步方法的研究[J].汽车实用技术,2021(8):55-57.
[2]邢晨,史章君.Kettle 3.1数据同步研究[J].软件导刊,2013(6):98-99.
[3]赵亚伟.一种基于Kettle的无损增量数据同步方法研究[J].软件导刊,2019(10):55-58.
[4]赵建勋.基于Kettle的数据整合研究与实践[J].西安文理学院学报,2020(3):28-31,36.
[5]武晋飞.基于Kettle的铁路客运营销数据交换平台的设计与实现[J].铁路计算机应用,2019(11):27-31.
[6]韦亚军,张文文,李冬青.基于Kettle的数据转换同步方法研究[J].软件导刊,2022(8):126-131.
[7]季亚婷,刘乐群.基于KETTLE的高校多源异构数据整合实践[J].合肥师范学院学报,2019(6):59-61.
[8]陈健,左秀然,杨国良.基于KETTLE的医院多源异构数据集成研究及分析[J].中国数字医学,2018(3):35-37.
[9]曾汪旺,谢颖夫,胡光阔.医院多源异构医疗数据整合方法研究[J].中国卫生信息管理杂志,2017(2):197-200,204.
[10]王军.基于kettle的高职学生行为数据集成研究[J].信息与电脑,2020(3):225-227.
[11]張孟春.面向数据集成的分布式ETL研究与设计[J].软件导刊,2017(11):197-199.
[12]程子傲,董博,赵悦,等.基于Kettle的数据交换平台研究与实践[J].辽宁大学学报,2018(1):13-18.
[13]崔有文,周金海.基于KETTLE的数据集成研究[J].计算机技术与发展,2015(4):153-157.
[14]唐紫珺,蒋亮.基于Kettle的数据预处理应用[J].信息技术与信息化,2021(8):128-130.
(编辑 李春燕)
Design and implementation of railway data access based on Kettle
Wang Tianju, Xu Danya, Yin Wenzhi, Qi Chenhong*
(Information Technology Institute, China Railway Zhengzhou Bureau Group Co., Ltd., Zhengzhou 450000, China)
Abstract: In order to solve the problem of actual business data access analysis processing, make data access, conversion, analysis, synchronization work more efficient and convenient, through the analysis of business requirements and data access integration technology research, carry out the open source ETL tool Kettle research, based on the analysis of Kettle application scenarios and business data characteristics, build the business data conversion synchronization process based on Kettle. According to the actual project case verification, compared with the traditional method, the Kettle-based data conversion access process simplifies the complexity of development and improves the work efficiency, which not only solves the data access transformation problem in the actual business system, but also provides more ideas for other data integration work.
Key words: access; transformation; analysis; integrate; technological process
