基于深度强化学习的SDN校园网设计与实现
2023-06-25王玉婷谷广兵孙雨霏卢勇
王玉婷 谷广兵 孙雨霏 卢勇



摘 要:随着校园网技术的发展,网络规模及复杂性不断增加,对网络架构及数据转发策略都提出了新的要求。作为一种新的网络架构,软件定义网络(SDN)将控制面和数据面分离,使其具有比传统网络结构更灵活的网络调度能力和更好的发展应用前景。为了适应校园网络发展的需要,文章提出了一种基于SDN架构的校园网络设计。在新的网络架构中引入SDN控制器,控制器中采用深度强化学习算法,全面考虑网络状态,选择最佳数据传输路径,从而最终实现校园网性能提升。
关键词:校园网;软件定义网络;深度强化学习;网络性能
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)07-0098-04
Abstract: With the development of campus network technology, the scale and the complexity of the network are increasing, which propose new requirements of the network architecture and data transmission strategy. Software Defined Network (SDN), as a new type of network architecture, separates the control plane from the data plane, and makes it have a more flexible network scheduling ability than the traditional network structure and better development and application prospects. In order to meet the needs of campus network development, this paper proposes a campus network design based on the SDN architecture, introduces SDN controller into the new network structure, and uses the Deep Reinforcement Learning algorithm in the controller. It comprehensively considers the network status and selects the best data transmission path to improve the network performance finally.
Keywords: campus network; SDN; Deep Reinforcement Learning; network performance
0 引 言
校园网是学校信息化的基础,由于网络技术的不断发展及校园智能化建设的不断推进,校园网承载着越来越多的设备数量、用户规模和业务种类,必然带来网络结构的复杂化以及对网络性能提出更高的要求,传统技术已经难以适应新的网络需求,同时也为校园网的维护带来了新的挑战。为了解决传统校园网络中存在的弊端以及无法适应新需求的问题,在校园网中引入将控制平面与数据转发平面分离的新型网络架构——软件定义网络(Software Defined Network, SDN)。网络设备(如路由器、交换机等)在新的网络架构中仅对数据包进行快速匹配转发,而控制平面的设备能够掌握网络整体情况,并根据策略对网络进行统一管理,实现网络全局优化。
本文以SDN网络作为校园网基本架构,通过控制平面集中获取网络状态信息,并采取深度强化学习算法,综合考虑网络架构及各链路情况,优化数据包转发路径,满足用户多样要求,提升网络性能,实现校园网智能化部署。
1 软件定义网络框架
软件定义网络是由美国斯坦福大学Clean-Slate课题研究组最先提出[1],该网络为一种新型网络创新架构,实现网络虚拟化。SDN网络重新构建了网络架构,在传统的网络架构中是通过分布式控制来实现数据调配,而新的网络架构中则采用了集中式控制来实现网络数据调配。
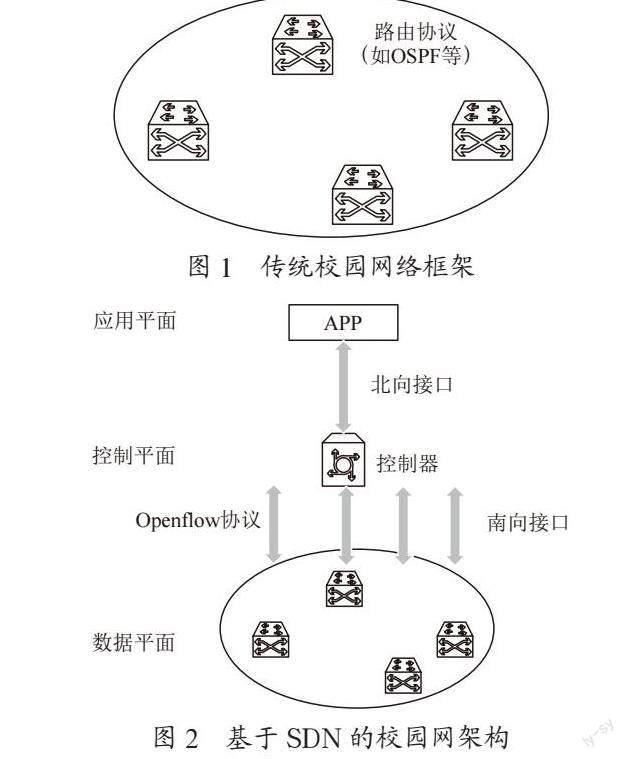
传统校园网络框架如图1所示,该结构下采用的是分布式控制实现数据调配,每台设备独立收集网络信息并根据运行的网络协议(如OSPF、RIP协议等)进行独立计算,选择各自的路径。传统校园网络架构需要在每个网元设备上布置策略来实现,每个网元设备需要收集当前网络状态再依据策略进行数据转发,对大型网络的流量策略进行调整时存在灵活度不足的问题,传统网络协议(如IGP、BGP等)在实现层面上较为复杂,且协议受限于设备厂家,造成网络运维成本大,网络升级速度慢,甚至可能会存在不同厂家设备无法兼容。
SDN網络架构的出现使用可以很好地解决传统校园网络架构存在的问题,为校园网设备的策略管理和运维带来便利。基于SDN的校园网架构如图2所示,网络分为应用、控制及数据平面,控制器通过南向接口收集网络整体信息并制定数据策略,从而实现对网络的集中管理控制。数据平面由只负责数据转发的网络设备构成,仅执行由控制器确定的数据转发。在应用平面可以引入第三方应用,通过设置的开放接口将新应用运用在控制器中,以编程的方式来实现新的网络功能,实现网络能力开放化应用。通过控制器集中算法的优化更新实现灵活分配网络资源,满足业务的各项需求如QoS、时延等,从而达到最优化网络配置的目的。该网络架构有效解决传统架构中不同厂家设备之间的兼容问题,并可以进一步引入云平台等技术,更好地提升网络性能。
2 控制器算法——深度强化学习
在基于SDN的校园网络中控制器实现网络信息收集并确定网络数据调度规则,控制器运行算法直接影响网络数据调度性能,对校园网性能产生影响。本文使用深度强化学习作为控制器中使用算法,该算法根据网络状态及激励来选择合适的策略,从而达到最大化网络性能的目标。
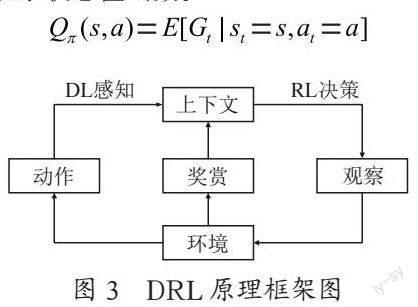
深度强化学习(Deep Reinforcement Learning, DRL)是将具有感知能力的深度学习(Deep Learning, DL)和具有决策能力的强化学习(Reinforcement Learning, RL)相结合[2],目前已在众多领域有着广泛应用如游戏、机器人控制、机器视觉等。DRL是一种端到端的感知系统,能够应用在多种环境中[3],原理框架如图3所示。工作原理为:
1)在时刻t智能体(agent)与环境(environment)进行交互,得到当前的状态(state)。
2)动作(action)的价值函数(value)是基于预期回报来作为评价,并通过相应策略选择该状态下执行的动作。
3)执行动作后,环境产生相应变化,并进入下一观察状态。
重复以上过程直至达到目标的最优策略。
本文基于SDN校园网控制器算法使用的是深度强化学习中的值函数法,该算法是深度强化学习的一个重要分支,通过对执行策略进行赋值(即Q函数),Q函数为状态-动作价值函数,即在某一状态s采取某一动作a,假设一直使用同一个策略π,得到的累计激励的期望值[4]。通过Q值对策略进行评估,每一个新的策略会相应得到一个Q值,当Q值越大,则标明该策略执行得到的效果越好,同时该策略被执行的可能性也越高,同时也可以以该函数来表示agent从初始到终止整个过程中所能获取的奖励值,并以奖励值的期望函数来表示状态值函数。
3 系统设计
3.1 基于SDN的校园网络设计
校园网不同于一般的网络,其具有数据流量大、时间周期性强的特点,如教学楼、办公楼区域在白天工作时间网络流量增长明显,学生公寓一般在中午或晚上休息时间段网络流量大幅度增长[5]。同时在某些特定时间段内网络流量呈现爆发式增长,如开学选课或世界杯期间等时间段内公寓网络流量突发性增加。为适应校园网个性化网络特点,提出基于SDN的校园网络如图4所示,图中实线表示网络数据传输路线,虚线表示网络控制路线。校园网根据使用场景分为教学、办公、公寓及图书馆四个区域,每个场景对网络的要求不同,网络中控制平面与转发平面分离。SDN控制器可以获取全局网络结构和链路情况,综合考虑网络状态信息,并能根据校园网的不同特点及不同场景流量变化需求,统一进行计算和网络资源调配,实现网络资源最优化利用,从而在策略上最优化配置网络完成对校园网中不同区域资源的调配。SDN交换机根据SDN控制器的转发策略,更新转发规则,依据确定的网络策略进行数据链路转发,数据转发效率更高。
3.2 算法设计
SDN校园网部署中SDN控制器采用深度强化学习算法优化网络数据转发策略,综合考虑网络中的数据指标,包括链路传输速率等,对获取的网络信息综合考虑,在此基础上形成适合该网络状态的数据策略。
本文中以SDN控制器为中心,动态捕捉网络内性能变化,并考虑网络处理能力,目标为实现网络的集中控制,优化网络整体性能。该优化算法的参数表达式为{A, S, R},其中A为动作集,S为状态集,R为奖励函数。
动作集A表示在当前状态情况下该网络数据转发路径选择,即当前的网络状态如何进行数据传输的路径选择,实现状态到动作的映射。
A={ai}
其中ai是源交换机i到达目标的路径及其反向路径的集合[6],比如交换机i根据当前的网络状态进行选择,在可供选择的3条路径中匹配路径进行数据转发。
状态集S集合了t时间段内Δt内的所有网络信息,表征当前的网络情况,为策略的选择提供重要的参考依据。
St={rt (ei, j)}
其中rt (ei, j)表示在Δt时间段内交换机i经链路ei, j发送到交换机j的传输速率,传輸速率为网络内数据传输与信息处理速度的重要指标量,且单一的状态信息可以减少获取状态的时间。
奖励函数R为该算法的目标,控制器通过奖励值判断策略执行效果,从而进一步优化策略。如果该动作执行的结果即为目标则给予固定的正向奖励值,若执行结果为非目标则给予负向奖励值。
该算法的实现过程如下所示:
1)构建SDN网络,并发现网络信息;
2)初始化各项参数;
3)对于每一个回合;
4)每一个时间t;
5)对于给定的状态st,基于Q(ε-贪心)算法得到动作at;
6)对于(st,at)获得反馈rt,并由此得到新的状态st+1;
7)将(st,at,rt,st+1)存储到缓冲区域中;
8)以经验驱动方式随机从缓冲区中抽样(sj,aj,rj,sj+1);
9)非终止状态计算目标Q值
10)更新目标Q值的所有参数,使得目标网络参数等于当前网络参数;
11)算法结束。
4 实验与结果
4.1 实验环境
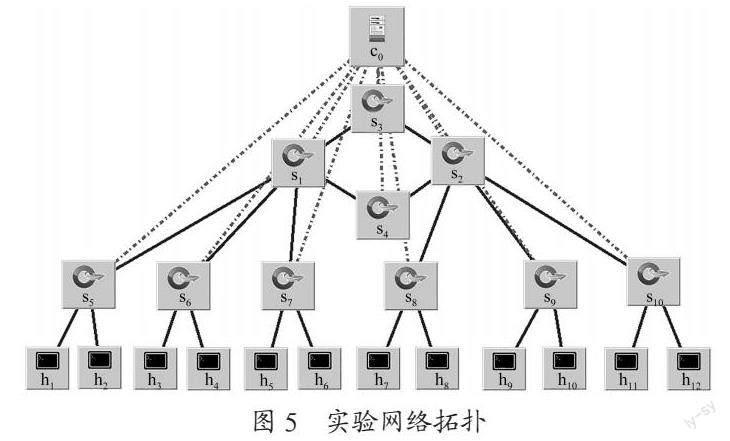
本实验使用Mininet作为网络仿真平台[7]搭建SDN校园网络,控制器采用RYU,在控制器上实现基于深度强化算法的数据转发策略,操作系统为Ubuntu 16.04。实验网络拓扑如图5所示,其中c0为集中控制器采用深度强化学习,掌握网络拓扑结构以及各链路数据传输速率等,集中管理整个网络,实现数据传输路径选择,s1~s4为核心层交换机,s5~s10为接入交换机,h2是校园网的服务器,h1、h3~h12为接入主机,虚线为控制传输线路,实线为数据传输线路。网络中传输的数据为UDP数据包,其中TTL=64。
4.2 实验结果
实验主要测试在图5所示的SDN网络中h2到h1、h3~h12的数据傳输情况,c0控制器上采用基于深度强化学习策略。Mininet中通过python语句生成网络拓扑图,SDN交换机链接至RYU控制器,从图6所示结果可以看出可以按照实验要求搭建所需网络结构,并能在网络节点间进行数据传输。
图7是采用深度强化学习算法的SDN校园网主机h2到h1至h3~h12的传输时延,通过c0控制器部署的方案,根据网络的需要进行数据转发,从数据结果可以看出网络节点之间互相连通,并可以通过集中控制算法实现对各节点的数据转发,完成对整个校园网的连通。
5 结 论
本文在传统校园网网络框架中引入SDN技术,网络中控制平面与数据平面分离,控制器中采用深度强化学习算法,针对网络状态进行有效建模,有效实现网络部署的自动化。该方案克服了硬件的限制,更有利于校园网的维护和管理,同时控制器的算法开发,可以根据校园网情况进行精确分配,使得网络数据管理更加精细,对于大型网络有效节约管理成本,满足校园网智能化管理的需求。
参考文献:
[1] 万昕.关于SDN如何解决传统网络问题的探究 [J].江西通信科技,2013(2):11-13.
[2] 董瑶,葛莹莹,郭鸿湧,等.基于深度强化学习的移动机器人路径规划 [J].计算机工程与应用,2019,55(13):15-19+157.
[3] 陈建平,周鑫,傅启明,等.基于二阶时序差分误差的双网络DQN算法 [J].计算机工程,2020,46(5):78-85+93.
[4] 周志华.机器学习 [M].北京:清华大学出版社,2016:371-390.
[5] 雷翔宇,王苓,张晓敏,等.高校校园网SDN部署研究与实现 [J].信息系统工程,2019(3):130-132.
[6] 丁怀宝.一种基于深度强化学习的SDN路由算法 [J].上海师范大学学报:自然科学版,2021,50(1):128-132.
[7] 杨俊东,尹强,张硕.基于Mininet的SDN仿真与性能分析 [J].信息通信,2017(3):189-191.
作者简介:王玉婷(1991—),女,汉族,安徽池州人,助教,硕士,研究方向:大数据技术、5G技术。
