基于神经网络的3D点云模型识别的方法
2023-06-25吴鹏程李晖王凤聪
吴鹏程 李晖 王凤聪


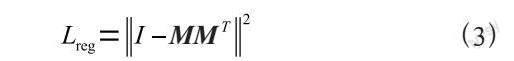



摘 要:针对点云的三维模型识别方法缺乏局部空间特征,从而影响3D模型的类识别的问题,提出一种基于残差模块的卷积神经网络三维模型识别方法。通过引入残差模块,构建深层神经网络增强点云模型的局部信息,提高物体的识别精度。同时,采用了一种获取多尺度局部空间信息的策略,加快了模型的推理能力。实验证明,算法识别准确率达到了91.5%,加快了模型的推理速度,可应用于对点云模型识别有实时性要求的场景,如:流水线上物体的检测等。
关键词:三维模型识别;卷积神经网络;实时性
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)07-0093-05
Abstract: Aiming at the problem that the 3D model recognition method of point cloud lacks local spatial features, which affects the class recognition of 3D model, a convolution neural network 3D model recognition method based on residual module is proposed. By introducing the residual module, a deep neural network is constructed to enhance the local information of the point cloud model and improve the object recognition accuracy. At the same time, a strategy of acquiring multi-scale local spatial information is adopted to accelerate the reasoning ability of the model. The experimental results prove that the recognition accuracy of the algorithm reaches 91.5%, which speeds up the reasoning speed of the model. And it can be applied to scenes that require real-time point cloud model recognition, such as object detection on the pipeline.
Keywords: 3D model recognition; convolution neural network; real time
0 引 言
随着互联网的突飞猛进,信息成为人们认识世界所不可或缺的一种工具,其获取、处理以及应用均取得了快速的发展。在生活中,相比于其他形式,图像所传达的信息更加丰富与具体。因此,人们获取的绝大部分信息都来自所观察到的图片。伴随着三维成像技术的日益发展,人们对机器视觉系统的需求也不再停留于二维图像,对图像信息的提取、对象识别的精度提出了更高的要求。随着科学技术的不断进步,人们发现二维图像并不能表征识别对象的深度信息,当然也就无法对其进行全方位的识别。三维图形识别能够提取物体表面以及对视点变化较为明显的三维特征,从而更全面地感知现实世界,获取更加深层的信息,被广泛应用于医疗、军事、航空航天等领域。随着无人驾驶汽车、智慧城市、智慧医疗以及工业检测等多个领域的快速发展,三维目标识别技术逐渐渗透生活的各个角落。相较于传统的2D图像识别,其更加准确、智能以及全方位。以3D数据作为信息内容的形式变得越来越重要。相信在不远的将来,物体的3D数据的应用将使用为3D数据制作的一些分类算法,去实现特定的目标任务。例如,在混乱的环境中的机器人导航或基于增强现实的智能用户界面等。
近年来,随着3D采集技术以及各种传感器的广泛应用,3D模型的种类以及数量与日俱增,这对于基于卷积神经网络(CNNs)的方法来说是个好消息,因为这些方法目前的性能严重依赖于大量数据的可用性。当前,需要迫切解决的问题就是如何提升3D模型的识别精度。三维模型识别获得了大量研究人员的青睐,为了解决以上问题,大量的研究工作应运而生,主要包括两大类,其中一类是基于传统的研究方法,研究人员利用已有的先验知识手工设计特征描述符去预测三维模型的类别,如热核描述符[1]、三角区域描述符[2]等。此类方法并不适合处理大规模数据集的场景,无法获取3D模型的高层语义,缺乏泛化能力。
由于深度学习框架的优越性能,尤其是在分类、识别等方面所表现出的卓越能力,使得将深度学习框架应用到目标识别中成为可能,并且已经在自然语言处理、机器人、图像识别、医学等领域获得了突破性进展。随着传感器相机的日益普及,3D模型的数量以及总类与日俱增,对于机器视觉系统的研究也不再局限于二维空间图像,人们对于信息的提取以及识别的精度提出了更高的要求。在机器学习领域,三维图像识别的研究吸引了大量研究人员的关注。现有的基于深度学习的3D模型识别方法主要分为三大类:基于直接处理点云的神经网络的方法、基于体像素的方法以及基于多视图的方法。基于多视图的方法[3,4],这类方法首先需要对三维数据进行不同视角投影转换为二维数据,其优势在于可以直接使用经典二维的深度学习框架,具备成熟的理论以及技术支持,同时,融合多方向的视角投影信息来获取3D模型的类别信息进行分类识别。其本质仍然是基于二维图像数据的处理,其并没有考虑3D模型的空间结构信息以及存在着多个视图特征信息冗余的问题,这显然并不是一种理想的处理三维数据的方法。基于体像素的方法[5-8],这类方法将不规则的原始点云数据划分为规则的3D体像素数据,该方法的优点在于可以直接利用三维卷积神经网络去提取三维体像素数据上的特征。经过体像素化之后的三维模型分辨率低,在丢失模型局部细节信息的同时,还会占用大量的内存空间。因此,这也不是所期待的解决方案。当前,3D模型识别的主流方法[9-16]是通过使用神经网络来处理点云数据。PointNet[17]利用多层感知机(Multi-layer Perception, MLP)来提取点的局部特征,通过最大汇聚聚合点的特征,以此来解决点云的排列无序性的特点。PointNet为研究人员打开了神经网络处理点云数据的大门,成了该领域的开山之作,对于后续的研究具有非常重要的参考价值。PointNet++[18]在PointNet的基础上,从不同的层次去提取局部空間信息,提高了识别的精度。多层次的提取信息导致模型的推理速度非常耗时,存在改进空间。Kd-Network[19]通过构建kd-trees对在它们上的点云的细分来共享这些转换的参数,提高了模型的推理速度。以上方法在提取局部空间信息过程中都引入了内部点云的空间信息,这些信息对于3D模型识别而言,显然是冗余的。
由于点的不规则性,如何提取点云的局部特征仍然面临着很大的挑战。在提取点云的高层语义的同时,往往意味着网络模型复杂度的提升;同时,如何提取关键点用于模型识别,也是一个关键的问题。基于此类问题,本文旨在探究一种神经网络模型学习3D点云模型的局部特征,增强网络的类识别能力,减少计算机的工作效率,提高模型的时效性。本文的主要贡献和创新点有:在网络中引入残差模块加深模型深度,充分挖掘3D模型所隐藏的高级语义信息;提出了一种新的提取局部空间信息的策略,网络的推理速度得到了明显提升。
1 点网
三维模型由空间中的一组无序点集 构成,其中n为输入点的数目,ni为任意采样点,其中每个点ni表示为(x, y, z, nx, ny, nz),即三维坐标加上各个方向上的法向量信息。本文提出的深度网络(点網)的输出为所有k个候选类输出k个分数,其中k=40。
1.1 点网的残差模块
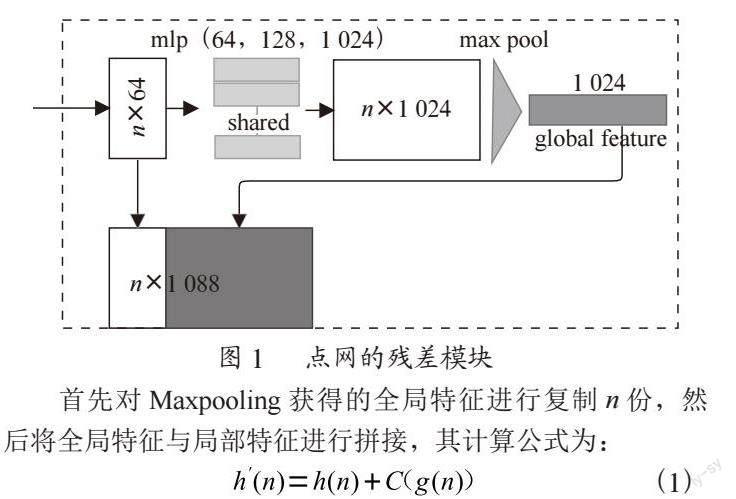
对于一个理想的3D模型识别算法而言,不但要捕捉目标全局空间信息,还要充分挖掘其局部信息,二者相互配合。为了挖掘3D模型所包含的深层次信息,本文构建了一个类似于残差网络的模块,在加深网络层次结构的同时,也可以利用残差网络的特性,避免梯度消失的问题,提高模型的泛化能力。网络结构如图1所示。
首先对Maxpooling获得的全局特征进行复制n份,然后将全局特征与局部特征进行拼接,其计算公式为:
式中,h(n)表示局部特征,C表示复制操作,g(x)表示全局特征,加号表示拼接操作。通过实验证明,这种方法很有效,如表1所示。尽管理论证明随着MLP层数的扩充,其特征会无限接近原始特征,但由于维度的限制,显然其并不能充分地提取点云的局部细粒度信息,而通过残差模块搭建深层次的网络结构,能更充分地提取点云更加深层次的局部细粒度信息,从而提高类的识别精度。
1.2 点网
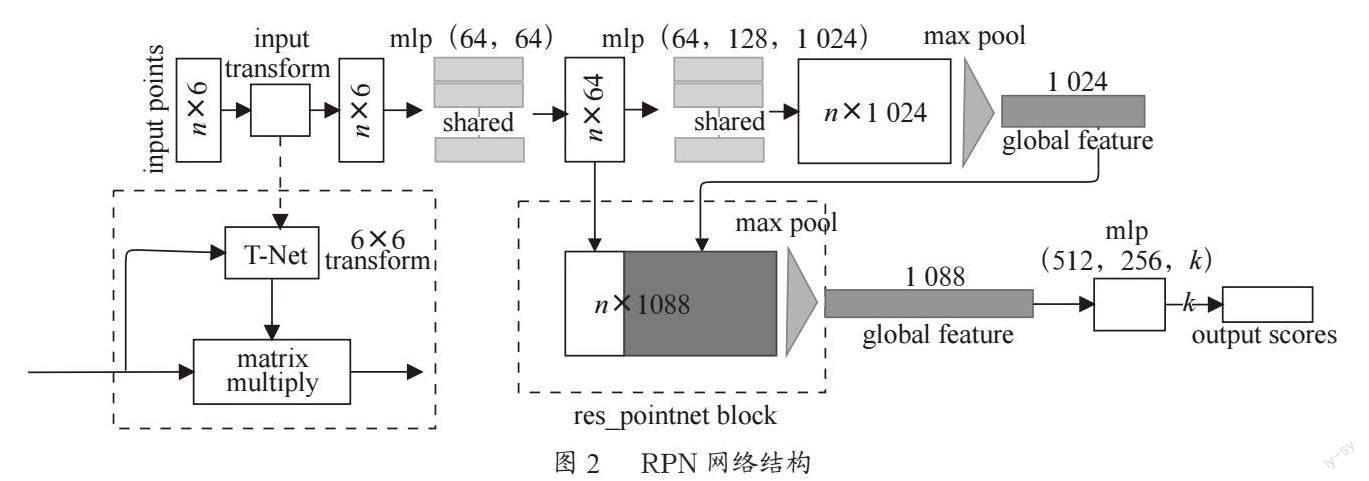
本文在残差模块的基础上构建了点网(Residual Level Point Network, RPN)结构,如图2所示。
图中n为初始值点云的数量,首先经过一个变换矩阵,确保点云经历了刚性变换之后,不改变点云图形的语义标记。然后将经过变换后的点云通过MLP进行升维处理,通过Maxpool操作,聚合点的特征;将提取的全局特征通过残差模块进行拼接,获取深层的点云信息,再次通过Maxpool、MLP,最终通过一个Softmax函数,输出k类的分数,其中k=40。计算公式为:
其中, 和h表示常规的MLP网络,C表示复制操作,Max表示Maxpool,S表示Softmax。
对于MLP网络,将点云的原始特征进行升维,计算公式为:
式中, 表示非线性激活函数——ReLU(),B表示批归一化操作,C表示卷积,s×1表示卷积核大小,θ表示可学习的参数。
对于转换矩阵(图2中input transform模块),直接将其预测的仿射变换矩阵作用于输入点的坐标,以此确保点云通过刚性变换之后的不变性。该微型网络由点的独立特征提取、最大汇聚以及全连接层等基本模块构成,类似于残差级点网。
通过插入一个对齐网络去预测特征变换矩阵,对齐来自不同输入点云的特征。由于特征空间中的变换矩阵维数要远比空间变换矩阵的维数高,因此,通过在Softmax训练损失中添加一个正则化项去降低优化的难度。约束特征变换矩阵接近一个正交矩阵:
其中,M是特征对齐矩阵。正交变换可以确保输入不丢失信息。通过添加正则化项,使得模型优化过程变得更加稳定,提高模型的性能。
2 多尺度空间信息
RPN模型缺乏点云的局部空间信息。由于点云数据呈现空间分布的特性,空间信息的丢失显然会影响网络对于3D模型的识别能力。因此,本文采用逐层次地去获取点云数据的空间信息,即提取多尺度的局部空间信息(MSG)策略。
提取多尺度空间信息的思想很简单。与卷积神经网络的原理类似,先从小的邻域中提取数据的局部特征,然后通过不断堆叠,逐步地扩大感受野。具体来说,首先通过空间的距离度量将点集划分为k个局部区域,然后将这些局部特征进一步分组成更大的单元,并经过处理以产生更高层次的特征。重复这个过程,直到得到整个点集的特征。
首先,需要解决以下两个主要的问题:一是如何划分点集,二是如何去抽象出点集的局部特征。由于划分的点集必须通过跨分区产生共同的结构,可以借鉴卷积中的设置,即共享特征学习的权重。本文选择残差级点网作为局部特征学习器,为了防止局部信息的冗余,仅在最后一层使用残差模块。其次,如何生成点集的重叠分区仍然是一个关键的问题。与固定步长扫描空间的卷积神经网络相比,采用最远点采样(FPS)算法在输入点集中去寻找合适的质心,利用输入数据与欧式距离去共同决定局部接受域,因此更加有效。在欧几里得空间中,定义每个分区为一个包含质心位置以及尺度的邻域球。
本实验共使用了三层的层次结构,对于每一层而言,都是由多个集合的抽象层次构成,如图3所示。对于每一层而言,点云被处理和抽象,以产生一个具有更少点云的新集合。采样层、分组层和点网层共同组成了集合的抽象层次。采样层利用FPS算法从输入数据中选择一组点作为局部区域的质心。分组层则通过球查询的方法去寻找“近邻”点以构造局部区域。点网层使用一个mini残差点网将局部区域模式编码为特征向量。
对于每一个集合的抽象层次的输入都采用来自N个具有d维向量的坐标和X维点特征的点的矩阵K作为输入;同时,以一个具有d维向量坐标和新的 维的特征向量的K′矩阵作为输出,以此来总结局部上下文信息。
2.1 采样层
对于输入点集 ,使用迭代的最远点采样(Farthest Point Sampling, FPS)算法去挑选点的子集 。这样 就是距离集合 的距离最远的点。在保持质心数量一致的前提下,最远点采样相较于随机抽样能更好地覆盖整个点集。
2.2 分组层
该层的输入为N×(d+X)的点集和一组大小为K的质心坐标,输出是为大小 的点集组,其中每组对应一个局部区域,K为是质心点邻域内的点数,其取值不固定,即在不同组中的取值会发生变化。后续的点网层能够将灵活数量的点数转换为固定长度的局部区域特征向量。
为了确保固定的区域尺度,本实验使用球查询的方法去查找位于目标点半径内的所有点,并设置了点数量K的上限。这与寻找固定数量的相邻点的查询方法K近邻搜索不同。球查询的方法使得局部区域特征在空间上更加具有通用性,这对于需要局部模型识别的任务而言尤其重要。
2.3 点网层
该层的输入是数据大小为 的 个局部区域。输出数据大小为 。通过质心以及质心领域的局部特征去提取输出中的每个局部区域。
2.4 一个重要的改进策略
利用上述MSG方案去提取模型空间结构的点云信息,在一定程度上造成了空间信息的冗余,增加了模型运行的时间。为了解决该问题,提出了一个重要的改进策略。在进行层次提取之前,先进行点的碰撞检测,滤除掉被近景点云遮挡的点。如图4所示,图中近景点云会遮挡远景点云,将远景点云定义为“无效点”,这类点对分类结果无影响,但会降低模型的推理速度。通过碰撞检测之后,极大地减少了无效点的数量,这类点对于分类识别而言意义不大,同时有效地提高了计算机的处理效率;保留了点云模型表面的关键点,这些关键点在分类识别任务中承担了至关重要的角色。因此,经过碰撞检测之后并不会影响类型识别的准确率,反而提高了计算机运行的效率。
3 实验结果与分析
3.1 实验环境
本实验所使用的数据集是由普林斯顿大学(Princeton University)公开的标准数据集ModelNet-40[20]。该数据集包含12 311个CAD(computer-aided design)模型,其中训练模型9 843个,测试模型2 468个,共40个类别。
实验环境为Linux Ubuntu 16.04操作系统、Python 3.6、CUDA 10.1、Pytorch 1.6.0。
3.2 网络参数设置
本实验使用基于动量的随机梯度下降算法(Stochastic Gradient Descent, SGD)来优化网络,各参数设置如表2所示。
3.3 实验总结与分析
点云数据碰撞检测前后对比图如图5所示,左图是在MeshLab中观察到的原始点云图像(包含1万多个点),右图是经过碰撞检测之后采样的点云图像(包含1 024个点)。对比两幅图像可以看出,经过碰撞检测之后,点云的数量明显减少的同时,仍能保留物体关键点的信息。
本实验的评估指标为三维模型识别准确率和模型的运行时间。实验结果如表3所示,相比于PointNet识别率提高了2.3%,加入的残差级模块作為对MLP的补充,融合了局部信息与全局信息,提取了更深层次特征;其次通过融合点云的空间信息,并对点云进行碰撞检测,减少了无效点的数量,提高了类的识别精度,运行效率较PointNet++提高了近1/4。
4 结 论
本文构建了一种基于残差级点网的三维模型识别方法,通过残差模块能提取到更深层次的点云局部信息,增强了网络对于模型的识别能力;其次,提出了多尺度提取空间信息的策略,在提取空间信息的同时,加快网络的推理能力。
对于分类而言,可通过跨模态融合的方式去提升识别的精度,即通过对3D点云进行2D纹理渲染,进一步提升模型的识别度,避免因为模型的点云结构类似而出现误识别的现象,这也是非常值得关注的方向。但该类方法最关键的问题在于如何去解决3D点云与2D图像的一致性问题。
参考文献:
[1] SUN J,OVSJANIKOV M,GUIBAS L. A Concise and Provably Informative Multi-Scale Signature Based on Heat Diffusion [J].Computer Graphics Forum,2009,28(5):1383-1392.
[2] OSADA R,FUNKHOUSER T,CHAZELLE B,et al. Shape Distributions [J].ACM Transactions on Graphics,2002,21(4):807-832.
[3] SU H,MAJI S,KALOGERAKIS E,et al. Multi-View Convolutional Neural Networks for 3D Shape Recognition [J/OL].arXiv:1505.00880 [cs.CV].(2015-05-05).https://arxiv.org/abs/1505.00880.
[4] FENG Y F,ZHANG Z Z,ZHAO X B,et al. GVCNN:Group-View Convolutional Neural Networks for 3D Shape Recognition [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake:IEEE,2018:264-272.
[5] MATURANA D,SCHERER S. VoxNet:A 3D Convolutional Neural Network for Real-Time Object Recognition [C]//2015 IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS).Hamburg:IEEE,2015:922-928.
[6] 杨军,王亦民.基于深度卷积神经网络的三维模型识别 [J].重庆邮电大学学报:自然科学版,2019,31(2):253-260.
[7] 杨军,王顺,周鹏.基于深度体素卷积神经网络的三维模型识别分类 [J].光学学报,2019,39(4):314-324.
[8] KLOKOV R,LEMPITSKY V. Escape from Cells:Deep Kd-Networks for the Recognition of 3D Point Cloud Models [C]//2017 IEEE International Conference on Computer Vision(ICCV).Venice:IEEE,2017:863-872.
[9] BRONSTEIN M M,BRUNA J,LECUN Y,et al. Geometric Deep Learning:Going beyond Euclidean Data [J].IEEE Signal Processing Magazine,2017,34(4):18-42.
[10] WANG Y,SUN Y B,LIU Z W,et al. Dynamic graph CNN for learning on Point Clouds [J/OL].arXiv:1801.07829 [cs.CV].(2018-01-24).https://arxiv.org/abs/1801.07829.
[11] ZHANG K G,HAO M,WANG J,et al. Linked Dynamic Graph CNN:Learning on Point Cloud Via Linking Hierarchical Features [J/OL].arXiv:1904.10014 [cs.CV].(2019-04-22).https://arxiv.org/abs/1904.10014.
[12] CHEN C,FRAGONARA L Z,TSOURDOS A. GAPNet:Graph Attention Based Point Neural Network for Exploiting Local Feature of Point Cloud [J/OL].arXiv:1905.08705 [cs.CV].(2019-05-21).https://arxiv.org/abs/1905.08705.
[13] LIU X H,HAN Z Z,LIU Y-S,et al. Point2Sequence:Learning the Shape Representation of 3D Point Clouds with an Attention-Based Sequence to Sequence Network [J/OL].arXiv:1811.02565 [cs.CV].(2019-05-21).https://arxiv.org/abs/1811.02565v2.
[14] LI Y Y,BU R,SUN M C,et al. PointCNN:Convolution on X-Transformed Points [C]//Neural Information Processing Systems.Montréal:Curran Associates,2018:820-830.
[15] XU Y F,FAN T Q,XU M Y,et al. SpiderCNN:Deep Learning on Point Sets with Parameterized Convolutional Filters [J/OL].arXiv:1803.11527 [cs.CV].(2018-03-30).https://arxiv.org/abs/1803.11527v3.
[16] ATZMON M,MARON H,LIPMAN Y. Point Convolutional Neural Networks by Extension Operators [J].ACM Transactions on Graphics (TOG),2018,37(4):1-12.
[17] QI C R,SU H,KAICHUN M,et al. PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:77-85.
[18] QI C R,YI L,SU H,et al. PointNet++:Deep Hierarchical Feature Learning on Point Sets in a Metric Space [J/OL].arXiv:1706.02413 [cs.CV].(2017-06-07).https://arxiv.org/abs/1706.02413.
[19] KLOKOV R,LEMPITSKY V. Escape from Cells:Deep Kd-Networks for the Recognition of 3D Point Cloud Models [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:863-872.
[20] WU Z R,SONG S R,KHOSLA A,et al. 3D ShapeNets:A Deep Representation for Volumetric Shapes [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:1912-1920.
作者簡介:吴鹏程(1994.11—),男,汉族,四川广安人,硕士研究生在读,研究方向:基于点云模型的识别方法研究;李晖(1968.09—),女,汉族,山东蓬莱人,教授,博士,研究方向:网络通信与信号处理、信息安全、自然语言处理;王凤聪(1997.02—),男,汉族,山东聊城人,硕士研究生在读,研究方向:基于图像的目标检测方法研究。
