遥感场景下基于关系挖掘的旋转目标检测算法研究
2023-06-25肖阳李炜
肖阳 李炜


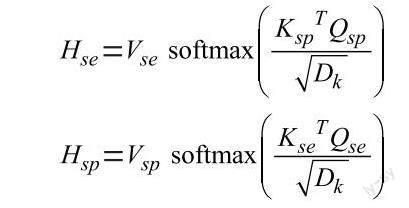


摘 要:与常规场景相比,遥感场景目标检测任务存在图像尺寸大、小目标数量多、检测框有旋转角等难点,这些难点也使得遥感图像中物体间有更多的关系可挖掘。为提升遥感场景下对旋转目标的检测效果,通过添加关系挖掘模块对旋转目标检测算法(Oriented R-CNN for Object Detection, ORCN)进行优化。关系挖掘模块利用动态图神经网络、交叉注意力机制使候选区域的特征、形状信息进行有效交互,丰富候选区域特征的上下文语义。实验结果表明,添加关系挖掘模块后模型在遥感数据集上的DOTA表现提升1.53%,明显优于原检测算法。
关键词:旋转目标检测;遥感图像;图神经网络;交叉注意力机制
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)07-0074-05
Abstract: Compared with the conventional scene, the target detection task in remote sensing scene has difficulties such as large image size, large number of small targets, and detection frame with rotation angle. These difficulties also make more relationships between objects in remote sensing images can be mined. In order to improve the detection effect of rotating targets in remote sensing scenes, the Oriented R-CNN for Object Detection (ORCN) algorithm is optimized by adding a relationship mining module. The relationship mining module uses dynamic graph neural network and cross-attention mechanism to effectively interact the features and shape information of candidate regions, and enrich the context semantics of the features of candidate regions. The experimental results show that the DOTA performance of the model on the remote sensing data set is improved by 1.53% after adding the relationship mining module, which is significantly better than the original detection algorithm.
Keywords: rotating target detection; remote sensing image; graph neural network; cross-attention mechanism
0 引 言
遙感图像目标检测是目标检测任务的一个新兴方向,在航空器场景感知、遥感探测、智能导航中具有广泛的应用价值。同时,遥感图像数据集存在图像尺寸大、小目标数量多、目标方向不确定等特点,相比常规数据集难度更大,具有更高的研究意义。航空场景下小目标(几十甚至几个像素)检测所占比例大,基于卷积的目标检测方法虽然在常规目标检测数据集上表现良好,但层层池化会使小目标信息量进一步减少,难以区分。常规场景中一般通过特征金字塔、扩充目标上下文语义信息的方式加以解决。其中,特征金字塔已广泛迁移至遥感图像目标检测任务中,但由于目标多、朝向自由等特点使得遥感场景下目标间语义关系更加复杂,常规场景中使用的上下文方法往往不能很好地建模其中关系。因此,本文根据遥感目标检测的场景特点,设计关系挖掘模块,利用物体间的关系强化候选区域特征,对遥感目标检测算法进行优化。
1 遥感图像目标检测与关系挖掘
1.1 遥感图像目标检测
航空遥感图像中的目标检测问题,是近年来计算机视觉领域出现的一个极具挑战性的问题。与自然场景不同,遥感图像中的物体通常以任意方向分布,人们采用有向边界框(Oriented Bounding Boxes, OBBs)而不是水平边界框(Horizontal Bounding Boxes, HBBs)进行标注与检测,因此遥感图像目标检测算法也多被视为旋转目标检测问题。为了应对旋转带来的挑战,学界纷纷提出设计良好的有向目标检测器,并在极具挑战性的航空图像数据集[1]上取得不错的效果,主要思路在于提取旋转不变特征[2-5]。在实践中,旋转RoI变换(例如Rotate RoI Pooling[4]和Rotate RoIAlign[2])是提取旋转不变特征的最常用方法,其根据二维平面中候选区域的有向边界框精确地提取区域特征。在旋转问题经过广泛的研究讨论并取得一定的成效后,遥感图像目标检测的其他难点纷纷走入研究视野,其中目标众多、形状各异是最为突出的特点与难点,而目标间蕴含着丰富的上下文信息将会是解决其小目标检测困难的又一突破口。因此,本文提出关系挖掘模块,对遥感场景下物体间的特征和几何形状中蕴含的关系信息进行建模,扩充候选区域的上下文信息,提高检测效果。
1.2 目标检测中的关系挖掘方法
关系挖掘旨在在物体间合理地交互、传播和更新信息,经常应用于一些常见的视觉任务,如分类、目标检测[6]和视觉关系检测[7]等。先前工作[8-11]中的一个常见做法有将手动设计的关系和对象之间的共享属性考虑在内。随着基于深度学习的几何学发展,图结构凭借其灵活的成对交互数据结构,慢慢成为主流的关系建模结构。有的研究手工建立不同类别之间的知识图谱以辅助大规模的目标检测[12],然而,这种方法严重依赖于来自视觉关系数据的归因和注释,物体间的某些空间关系也被忽略。有的工作[13-16]试图从视觉特征中隐式学习区域之间的完全连通图,如使用自适应注意力模块进行对象视觉特征之间的交互。然而,全连通模式合并了来自无关对象和背景的冗余信息,空间关系也未被充分利用。有的工作[17,18]通过手工构造与深度学习相结合的方式建立物体间的稀疏图,并通过图卷积的方式交互信息。但随着图神经网络技术的日益发展,其中使用的图卷积模式并不是信息交互的最优解,关系图结构也在交互过程中趋于固定,缺乏灵活性。因此,本文提出新的关系挖掘模块,新模块利用层层更新的动态图神经网络,结合交叉注意力机制,使候选区域间的语义特征和空间结构信息进行有效交流,同时通过稀疏图结构和注意力掩码技术防止冗余信息的干扰,将有效的关系信息融入特征。
2 关系挖掘模块
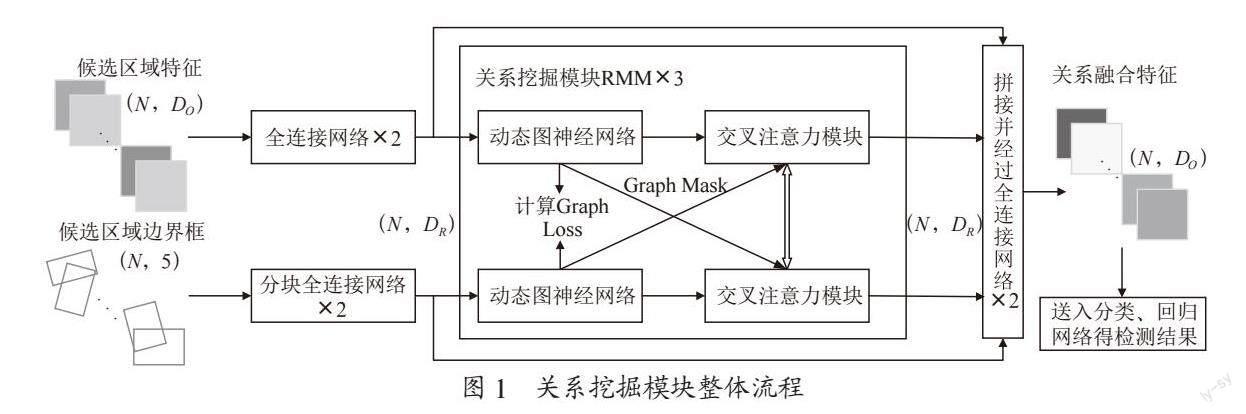
关系挖掘模块(Relation Mining Module, RMM)设置在两阶段目标检测网络的感兴趣区域(Region of Interest, ROI)池化层之后,整体处理流程如图1所示。在两阶段目标检测网络中,ROI池化操作可得到一批候选区域,每个候选区域对应有语义特征信息和空间位置信息,预测头利用其语义特征信息得到最终检测结果。因此,我们的关系挖掘模块将利用候选区域的语义特征信息和空间位置信息对其进行特征更新(新特征包含候选区域在语义特征和空间结构上的上下文信息),以更好地辅助预测头进行分类和定位。
圖1中,N表示候选区域个数,DO表示原语义特征维度,DR表示关系模块内特征维度。在送入关系模块前,本文利用两个全连接网络对语义特征和边界框信息进行维度统一。由于边框信息由中心坐标x、y、边框宽高w、h,以及边框旋转角a三类尺度不同的信息组成,因此使用一层分块全连接网络分别处理三类信息,拼接后再利用一层全连接网络统一维度,得到空间特征。
维度得以统一后,模块利用动态图神经网络对输入特征进行图结构的建立或更新,再按图结构对特征进行图卷积操作,卷积更新后的节点特征能够有效聚合邻居节点信息;随后特征进入交叉注意力模块,先进行自注意力操作,再进行交叉注意力操作,使得语义特征与空间特征得到信息交互,重复三次后完成关系挖掘,与原特征拼接后送入全连接网络恢复特征维度,以供预测头使用。
在关系挖掘过程中,为排除冗余信息的干扰,降低计算量,在交叉注意力模块中进行mask操作,即只有图结构中建立连接的节点才进行注意力运算。与此同时,为使语义特征和空间特征两路关系挖掘模块形成合力,添加Graph Loss损失项,使得两路更易于形成相近的图关系结构。
2.1 动态图神经网络
动态图神经网络对特征的处理流程如图2所示,依次经过图数据构建、图卷积聚合节点特征、全连接层特征变换三部分。
2.1.1 构建图结构
面对N个D维语义/空间特征形成的集合X=[x1, x2,…, xN],xi ∈ RD,我们可以将其视为一张图上的一组无序节点V={v1,v2,…,vN}。对于每个节点vi,我们以K近邻的思路找到K个与它最近的节点形成邻居集合N(vi),并且对所有邻居节点vj ∈ N(vi)添加一条由vj指向vi的边eij。由此我们将特征集合组织成一张有向图数据G=(V, E),其中E表示所有边的集合,这一过程可记为G=Graph(X)。以K近邻的思路建立图数据结构,可以使得节点的特征在相似的节点间进行聚合更新,一方面能够避免其他类别特征的混叠干扰,另一方面可消除类间差异,使得各节点的特征表示趋于类的特征表示。
2.1.2 图卷积聚合节点特征
图卷积模块[19]可以从邻居节点聚合特征的操作使不同的节点相互交换信息。其过程可表述为:
其中,Wagg和Wupdate分别表示聚合和更新操作中的可学习权重。具体来讲,聚合操作将邻居节点特征与本节点进行聚合,更新操作进一步融合聚合后的特征:
具体的更新和聚合操作我们参照最大相关性图卷积方法[20],该图卷积方法形式简洁、计算方便,能在较小的计算复杂度下完成对图节点特征的聚合与更新:
2.1.3 全连接层特征变换
研究表明[20],随着图卷积操作的加深,卷积感受野逐渐增大,图中各个节点会渐渐趋于一致,这种现象被称为过平滑。因此,一般在图卷积操作后接入带有非线性激活函数的全连接网络,使特征处于不断的变换中,延缓过平滑现象的发生,提高图卷积网络的学习空间。
2.2 交叉注意力模块
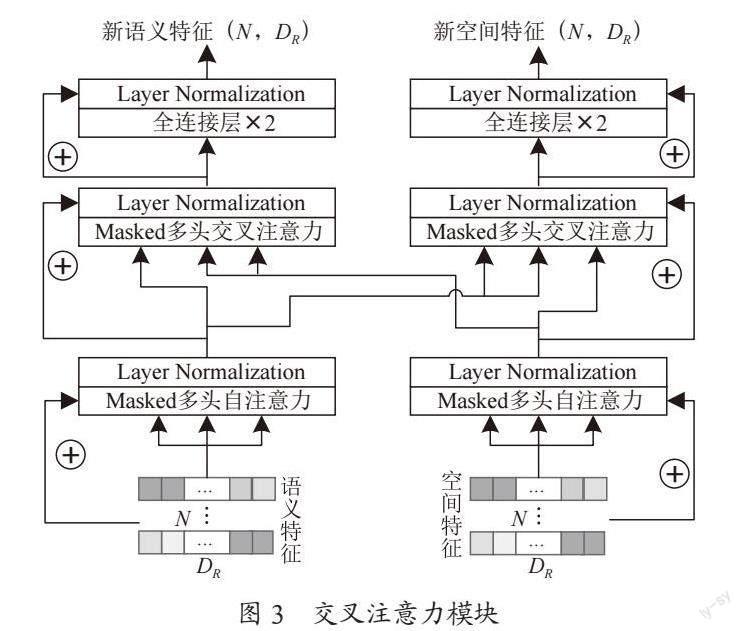
在经过动态图神经网络后,语义和空间两组特征都完成了特征集合内部的信息交互。然而,作为候选区域的两大关键信息,我们希望两组特征之间也能进行有效的交流,互相补足其在关系建立和特征聚合过程中的遗漏。鉴于语义特征和空间特征有着完全不同的表达模式,我们将其间的信息交流视作一个多模态信息融合问题,故引入多模态融合技术:交叉注意力机制,形成交叉注意力模块,如图3所示。
交叉注意力机制是自注意力机制的变体,其与自注意力机制的主要差异在于,自注意力操作中的query、key、value值均源于本身序列,而在交叉注意力机制中,query值来自本身序列,而key、value则由另一模态的序列变换而来,这也是本文交叉注意力模块的核心操作。
其中,se表示语义特征,sp表示空间特征,由于注意力模型通常应用于序列问题而非无序特征的处理,我们对模块进行了一些适应性调整:一是针对无序的特征集合,我们取消了位置编码,但同一位置的空间特征与语义特征依然对应放置,使其在做交叉注意力时依然能维持对应关系;二是对注意力运算添加掩膜mask,即只有图结构中建立连接的节点才能进行注意力运算,自注意力运算时查询本特征集合在动态图卷积过程中形成的图结构,自注意力运算时查询另一特征集合的图结构,避免无关特征影响特征融合的有效性。
2.3 图相似性损失
在动态图神经网络建立图结构的过程中,两类特征集合根据不同的信息建立不同的关系网络,但实际上,两套节点对应的是现实中同一个物体集合,因此其产生的关系虽有差异,但稳定后应是互补而相似的。因此,为了使关系模块更好地收敛,两类特征有效地为同一目标服务,特在损失函数中添加图相似性损失Graph Loss:
其中,Asp表示空间特征建立图结构所对应的邻接矩阵,Ase表示语义特征建立图结构的邻接矩阵。
3 实验与结果分析
将关系模块加入到经典的旋转目标检测算法ORCN[21]中后,我们将其在遥感图像数据集DOTA(Dataset for Object Detection in Aerial Images)[1]上的表现与近年来常用的两阶段旋转目标检测算法(RSDet-II[22]、Oriented RepPoints[23]、SCRDet++[24]、ORCN)进行对比。经多次实验探究,关系模块中主要参数设定如下,模块数量NM=3,特征维度DR=256,K近邻中的K=4,多头注意力的头数量NH=4。为保证实验的有效性,表中所有算法都未单独添加任何检测中的通用trick,并且同在一张GeForce RTX 2080 Ti显卡上,使用同样的backbone(ResNet50)进行训练,每类算法均取其在验证集上mAP最高的回合测试,最终结果如表1所示。加入關系挖掘模块后的ORCN算法比原算法提高了1.53%的精度,并在一些集群出现(SV(Small Vehicle)、LV(Large Vehicle)、SH(Ship))或形状突出(BR(bridge))的类别中有较好的提升效果。
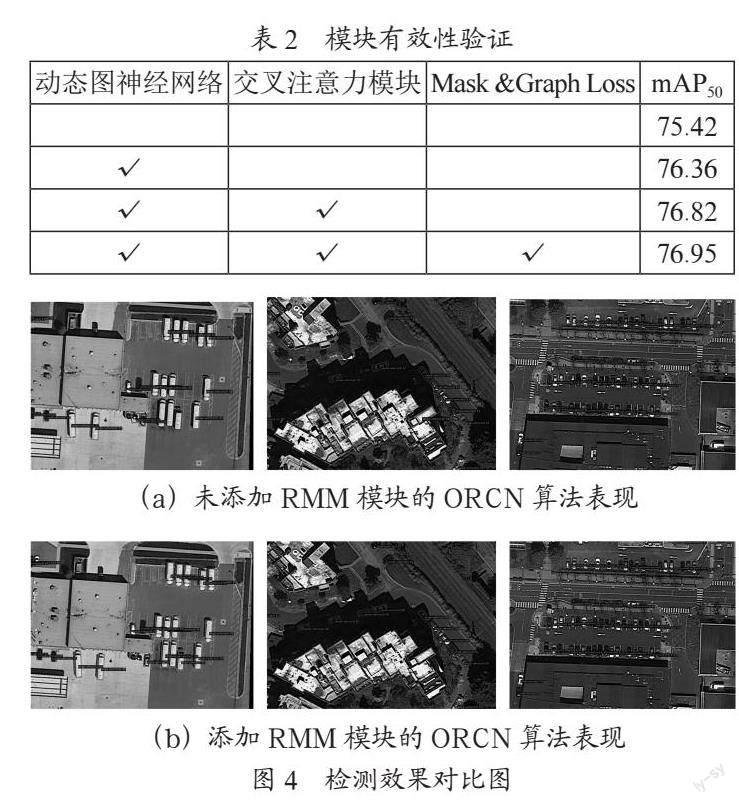
为探究模块各部分的有效性,对动态图神经网络、交叉注意力、注意力mask与Graph Loss三部分进行消融实验,结果如表2所示。可以看出,动态图神经网络有效地挖掘了物体间的语义特征与空间位置关系,精度提升效果较为明显,而交叉注意力模块使得语义特征和空间位置信息在计算过程中即时进行共享交互,进一步提升了其在DOTA数据集上的表现,Mask和Graph Loss的引入对模型表现也有所提升,但更多地起到减少计算量、使训练过程快速收敛的作用。
如图4所示,(a)为ORCN算法检测效果,(b)为添加关系模块RMM后的效果图。可以看出,关系模块的使用有效减少了检测中出现的漏检、误检、定位框偏移的情况,在目标密集出现的情况下,加入关系模块有更好的优化表现。
4 结 论
本文对遥感场景下旋转目标检测任务中的关系挖掘问题进行了研究,对二阶段检测模型中候选区域的语义特征和空间信息进行关系建模,从而增强候选区域的上下文特征,提高检测精度。其中,动态图神经网络即时构造图结构,利用图卷积操作进行特征聚合;交叉注意力模块使候选区域的空间信息和语义信息跨模态交互融合,注意力掩膜和图相似性损失则能减少模型计算量并加速收敛,最终有效建模物体间的关系,丰富特征的上下文信息,获得了优于原方法的精度表现。在未来的工作中,需要进一步降低关系模块中的参数量,提高模型的速度表现。
参考文献:
[1] XIA G S,BAI X,DING J,et al. DOTA: A large-scale dataset for object detection in aerial images [J/OL].arXiv:1711.10398 [cs.CV].[2022-12-23].https://arxiv.org/abs/1711.10398v2 .
[2] DING J,XUE N,LONG Y,et al. Learning RoI transformer for oriented object detection in aerial images [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach:IEEE:2019:2844-2853.
[3] HAN J M,DING J,LI J,et al. Align deep features for oriented object detection [J/OL].arXiv:2008.09397 [cs.CV].[2022-12-25].https://arxiv.org/abs/2008.09397.
[4] MA J,SHAO W,YE H,et al. Arbitrary-oriented scene text detection via rotation proposals [J].IEEE Transactions on Multimedia,2018,20(11):3111-3122.
[5] YANG X,YAN J C,FENG Z M,et al. R3det: Refined single-stage detector with feature refinement for rotating object [J/OL].arXiv:1908.05612 [cs.CV].[2022-12-16].https://arxiv.org/abs/1908.05612v6.
[6] CHEN X L,Li L J,LI F F,et al. Iterative visual reasoning beyond convolutions [J/OL].arXiv:1803.11189 [cs.CV].[2022-12-23].https://arxiv.org/abs/1803.11189.
[7] DAI B,ZHANG Y Q,LIN D H. Detecting Visual Relationships with Deep Relational Networks [J/OL].arXiv:1704.03114 [cs.CV].[2022-12-25].https://arxiv.org/abs/1704.03114v2.
[8] AKATA Z,PERRONNIN F,HARCHAOUI Z,et al. Label-embedding for Attribute-Based Classification [C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland:IEEE,2013:819-826.
[9] ALMAZÁN J,GORDO A,FORNÉS A,et al. Word spotting and recognition with embedded attributes [J].IEEE transactions on pattern analysis and machine intelligence,2014,36(12):2552-2566.
[10] LAMPERT C H,NICKISCH H,HARMELING S. Learning to detect unseen object classes by between-class attribute transfer [C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR).Miami:IEEE,2009:951-958.
[11] MISRA I,GUPTA A,HEBERT M. From red wine to red tomato: Composition with context [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu:IEEE,2017:1160-1169.
[12] JIANG C H,XU H,LIANG X D,et al. Hybrid knowledge routed modules for large-scale object detection [J/OL].arXiv:1810.12681 [cs.CV].[2022-12-15].https://arxiv.org/abs/1810.12681.
[13] LIU Y,WANG R P,SHAN S G,et al. Structure inference net: Object detection using scene-level context and instance-level relationships [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE,2018:6985-6994.
[14] CHEN X L,GUPTA A. Spatial memory for context reasoning in object detection [C]// 2017 IEEE International Conference on Computer Vision (ICCV). Venice:IEEE,2017:4106-4116.
[15] HU H,GU J Y,ZHANG Z,et al. Relation networks for object detection [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE,2018:3588-3597.
[16] WANG X L,GIRSHICK R,GUPTA A,et al. Non-local neural networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE,2018:7794-7803.
[17] FU K,LI J,MA L,et al. Intrinsic relationship reasoning for small object detection [J/OL].arXiv:2009.00833 [cs.CV].[2022-12-18].https://arxiv.org/abs/2009.00833v1.
[18] XU H,JIANG C H,LIANG X D,et al. Spatial-Aware Graph Relation Network for Large-Scale Object Detection [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach:IEEE,2019:9290-9299.
[19] ZHOU Z P,Li X C. Graph convolution: a high-order and adaptive approach [J/OL].arXiv:1706.09916v2 [cs.LG].[2022-12-10].https://arxiv.org/pdf/1706.09916v2.pdf.
[20] LI G H,MULLER M,THABET A,et al. Deepgcns: Can gcns go as deep as cnns?[C]//HYPERLINK "https://ieeexplore.ieee.org/xpl/conhome/8972782/proceeding"2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul:IEEE,2019:9266-9275.
[21] XIE X X,CHENG G,WANG J B,et al. Oriented R-CNN for object detection [C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV).Montreal:IEEE,2021:3500-3509.
[22] QIAN W,YANG X,PENG S L,et al. RSDet++: Point-based modulated loss for more accurate rotated object detection [J].IEEE Transactions on Circuits and Systems for Video Technology,2022,32(11):7869-7879.
[23] LI W T,CHEN Y J,HU K X,et al. Oriented reppoints for aerial object detection [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans:IEEE,2022:1819-1828.
[24] YANG X,YAN J C,LIAO W L,et al. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(2):2384-2399.
作者簡介:肖阳(1998—),男,汉族,辽宁铁岭人,硕士研究生在读,研究方向:航空场景下小目标检测算法;李炜(1990—),男,汉族,四川成都人,副研究员,博士,研究方向:视频图像处理技术、传感器网络技术、视频网络应用技术。
