基于骨骼投影信息的人体行为识别
2023-06-23邓淦森丁文文杨超
邓淦森 丁文文 杨超

摘要:针对复杂环境下深度相机提取人体骨骼信息失效的问题,利用RGB图像提取运动特征,提出结合人体部分重要关节点信息进行行为识别的方法。首先根据人体行为图片捕捉人体各关节点的空间位置信息,建立坐标系描绘出人体骨架,将三视图嵌入二值图像中;利用Lucas-Kanade光流算法得到关节点的运动信息,构成由张量表示的动作序列;估计动作特征描述序列,再映射到格拉斯曼流形上完成人体行为识别和分类。在MSRActinos3D、UCFKinect数据集上的实验结果表明,该方法能够有效识别各种人体行为。
关键词:投影信息;Lucas-Kanade光流算法;字典学习
中图分类号:TP391.41 文献标志码:A
近几年计算机视觉和图像处理高速发展,在人机交互、视频监控、虚拟现实等领域有了广泛的应用。人体行为识别的方法主要是特征提取和深度学习,其中,基于深度学习方法对数据库和硬件设备要求较高,需要大量数据进行参数训练来构建模型;基于特征提取方法,整个建模过程更加节省时间,设备要求较低,早期基于特征提取方法主要依赖于RGB图像进行人体行为识别,提取图像运动区域并确定跟踪目标点。如利用图像中Harris角点作为特征点并结合Lucas-Kanade光流算法跟踪提取运动特征表示动作[1]。为了优化识别效果,确定目标点以及提取特征存在噪声时,直接提取人体行为运动描述符识别人体行为,如利用光流向量沿着动作执行者的边缘建立的局部描述[2],这些方法识别率不高的原因在于获取人体动作行为的RGB图像时存在噪声。深度相机的出现极大地解决了RGB图像提取的问题,深度相机利用自身发射的红外线提取人体行为图片,然而由于黑色物质可吸收红外线,在周围环境比较黑暗的情况下基于RGB图像人体行为识别成为难题。因此直接从RGB图像中提取人体关节点作为人体的直接特征,有助于提高对人体行为识别的准确率,利用关节点3D坐标直方图作为特征描述符,可以更精确的识别人体行为[3];在利用人体关节点行为识别的基础上,可以采用描述符确定骨骼关节之间的距离关系用于手部姿态识别[4]。在此基础上,根据骨架关节的差异,结合动作的静态姿态、运动特性和整体动力学信息设计了一种新的动作特征描述符,提高了识别效果[5]。由于Kinect深度相机可以较好的提取人体关节点,使人体行为识别脱离了特征描述符的概念,完全基于关节点坐标以及人体骨架信息;如利用骨骼投影图特征,得到骨骼关节点的整体分布,最后利用支持向量机(Support Vector Machines,SVM)人体识别[6]。基于文献[2],为了降低不同动作关节点运动轨迹带来的影响,每个动作以臀部或者颈部为骨架中心点的识别算法,有效的提高了行为识别的精度[7];为降低行为识别实验的门槛,仅根据已有人体骨架的简易描绘并利用人体姿态估计技术[8]估计关节点位置信息,利用人体中心投影消除肢体遮挡的影响,最后完成人体行为识别测试[9];在此基础上,将流形与人体行为识别相结合,用分层判别的方法识别人体动作,该方法的鲁棒性较好[10]。而将关节点运动信息编码成可观测张量序列,并对观测序列利用Tucker分解得到线性系统的特征描述符,可以完成行为识别测试[11]。上述文献均利用RGB图像手工提取特征描述符作为动作特征进行人体行为识别,随着卷积神经网络和图卷积神经网络的广泛应用,更进一步提高了人体行为识别的准确率,通过端到端的学习方式对骨骼数据分析和处理,完成人体行为识别任務[12-14]。本文首先利用人体姿态估计技术提取部分关节点坐标,对简易人体运动骨架进行投影;在投影图中利用LK光流算法获得关节点运动信息;利用基于张量的线性系统得到特征描述符,映射到格拉斯曼流形上完成动作分类和识别。
1 重要关节点提取
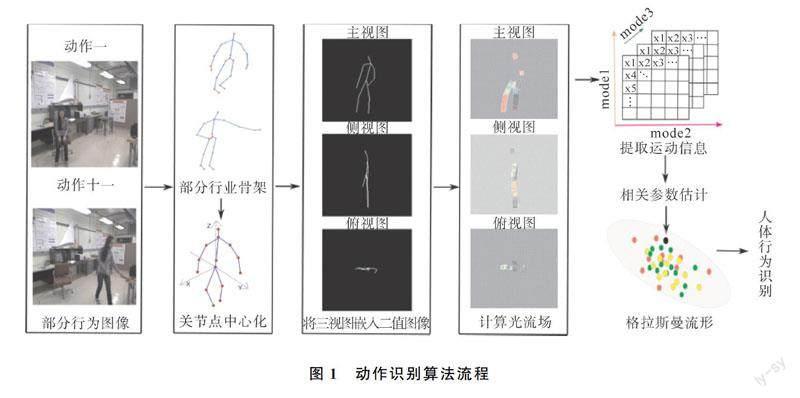
人体骨架信息是人体运动最具代表性、最直接的特征。利用人体姿态估计技术[8]估计出人体部分重要关节点并赋予编号信息:左肩膀(1)、右肩膀(2)、颈部(3)、脊柱(4)、臀部(5)、左肘(6)、右肘(7)、左手(8)、右手(9)、左膝(10)、右膝(11)、左脚(12)、右脚(13)、头部(14)用于行为识别,其中臀部关节点坐标利用右肩膀和左膝所在直线与左肩膀和右膝所在直线近似估计。本文的算法流程如图1所示。
从图像中估计人体骨架关节点后,需要对人体骨架预处理,包括骨架尺度归一化,骨架视角旋转,删除人体部分节点和无效帧的关节点信息,增补丢失关节点等。人体骨架尺度归一化时以脊柱与臀部关节点组成向量的模长等于1(根据经验所设)为标准,对每个关节点坐标按比例缩放,即Pj=Pi/|P4|。如图2中b为绘制简易人体骨架尺度归一化后的图片,a、c分别表示缩放前的人体骨架。
2 基于骨架投影的二值图像
获得关节点运动轨迹的空间分布后,全面提取人体骨架运动信息是行为识别的重要依据。每一帧骨架在XOY,XOZ,YOZ三个平面上投影得到主视图(a),侧视图(b),俯视图(c),如图3所示。
骨架三视图嵌入二值图像,坐标系转换之前如图4所示,坐标系转换后如图5所示。
3 特征提取
利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性找到上一帧跟当前帧之间存在的运动关系,计算出相邻帧之间物体的运动信息。假设相邻帧空间一致即相同表面相邻的点具有相似的运动,利用Lucas-Kanade稀疏光流算法计算二值图像相邻帧的光流场,得到图像中的运动区域和运动骨架在竖直与水平方向的位移大小,可以更好的描述整体骨架的运动情况以及记录每个关节点在光流场中随着每一帧变化的运动信息。如图6所示,以前一帧的关节点作为目标点,记录人体的运动信息。相较于直接提取关节点运动信息通过光流场提取关节点的运动信息,可以更加简洁的表达出关节点的运动方向,以及与各个坐标轴之间的夹角,同时骨架的三视图也将各个关节点之间的空间信息保留下来。
5 实验与讨论
5.1 动作识别数据集
实验环境:联想拯救者,CPU 3.2 GHz,内存16 G,Visual Studio 2012,MatlabR2018b。实验在MSRAction3D和UTKinect数据集上进行,这两个数据集是基于Kinect深度相机拍摄的人体骨骼数据整理而成,利用其中14个人体骨骼重要关节点坐标,对本文所提出方法进行行为识别实验。MSRAction3D数据集共有567个动作样本,20个动作类别,每个动作类别由 10 位演员执行2~3次。UTKinect数据集是得克萨斯州大学奥斯汀分校建立的数据集,由10个人执行10类动作:步行、坐下、站立、拿起、携带、投掷、推动、拉、挥手、拍手。
5.2 MSRAtions3D数据集
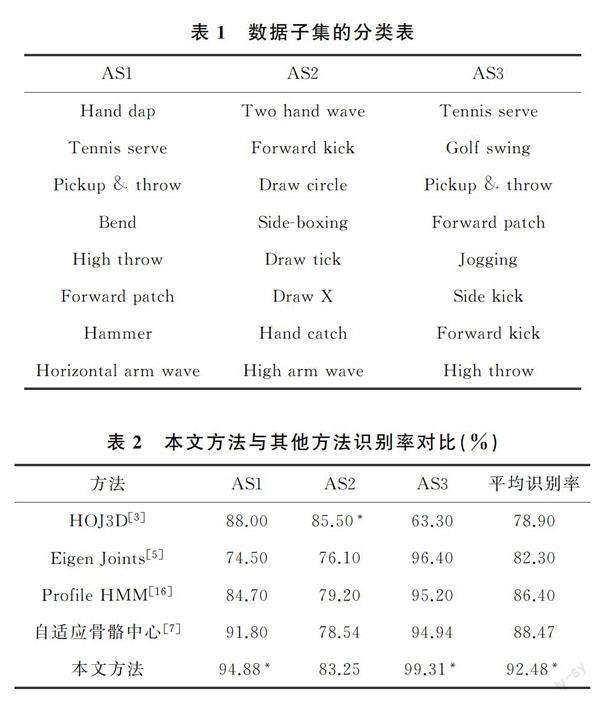
MSRAtions3D数据集在所执行的动作中不与任何对象交互该数据集,由于动作变化较小,许多动作非常相似,用类似于Kinect装置的深度传感器记录数据,将整个数据集划分为AS1、AS2和AS3的子集,每个子集包含8个动作,子集的分类见表1[15]。AS1和AS2组动作涉及相似的运动,而AS3动作更复杂,涉及更多关节的参与。本文分别使用跨主题测试设置识别每个子集,其中一半的受试者用于训练,另一半用于获取测试数据。
首先对每个动作编码提取动作信息并输入基于张量的线性系统,得到系统相关参数的估计,进而得到动作的预测类别,最终得到实验结果[11]。表2是在MSRAtions3D数据集上本文方法的识别率与其他方法进行比较的结果(带*号的为最优结果),可以看出本文方法在AS3复杂动作数据集上具有较高的识别精度,在AS1和AS2子集上也均高于其他方法,并且平均识别率高于92%。
5.3 UTKinect数据集
UTKinect数据集使用固定的深度相机以15fps的帧速率收集数据。这些动作由10个不同的人执行,同一动作每人进行2次,数据集中共包含199个动作序列,6 220帧,序列的持续时间从5帧到120帧。在执行给定动作时会发生明显的变化,例如拾起动作,用一只或两只手执行相同的动作,UTKinect数据集实验时,将所有关节点以Hip和Neck为中心分别归一化,为了便于比较,在UTKinect序列上应用文献[3]提出的实验方案,保留一个序列交叉验证(LOOCV),其中199个序列用于训练,每个测试集中只有一个用于测试。结果见表3,与其他的方法相比,本文方法的识别率是95.98%,分别高于其他相关实验HOJ3D[3]方法,CRF[10]方法5.08%,4.28%,高于自适应骨骼中心[7]算法0.8%,对一些动作如坐、站、捡、搬、拉、挥手等,能够精确识别。
为验证以颈部为中心化后对识别率的影响,数据处理时以Hip为中心点归一化,重复上述的实验步骤。图7是以颈部为中心化的数据实验,平均识别率高于93%,证明该方法具有较高的鲁棒性。但在走、搬、拍手动作上识别率不高,这可能是由于中心化后人体整体移动大范围信息集中于颈部以下。
本文验证了对观测序列Y∈R14×24×M进行Tucker分解后核心张量的Mode3维数对本方法的影响,图8为Mode3对识别率的影响,识别率随着分解后核心张量Z∈R14×24×dMode3的增大呈正相关,当Mode3达到9维时识别率最高,随后达到饱和。
6 结论
本文所提出的人体行为识别算法在MSRAtions3D數据集中AS3子集上有突出的识别优势,说明本文算法针对于一些复杂动作或者一些组合动作具有鲁棒性。本文算法在AS1上识别效果较好,但在AS2子集上仍存在改进的地方,原因可能是AS2子集中大部分动作执行部位偏向于手臂以及手部,并且动作产生的时间较短信息提取不充分,可对该子集部分动作执行插帧操作,提高动作执行帧数。UTKinect数据集对多数动作的识别率达到高度识别,但是对于扔的识别率较低,可能是在提取动作信息时所提取的信息并不能更好的描述该类运动,因此造成识别率较低,后续将根据不同的动作提取具有代表性的特征,也尝试其他对识别率有贡献的张量分解方法。
参考文献
[1]郭瑞峰,贾榕.LK光流法的多信息融合目标跟踪算法研究[J].现代电子技术,2019,42(18):55-59.
[2]KUMAR S S, JOHN M. Human activity recognition using optical flow based feature set[C]// IEEE International Carnahan Conference on Security Technology (ICCST). Orlando, 2016: 138-142.
[3]XIA L, CHEN C C, Aggarwal J K. View invariant human action recognition using histograms of 3D joints[C]// Computer Vision and Pattern Recognition. Providence, 2012: 20-27.
[4]WARCHO D, KAPUS'CIN'SKI T. Human action recognition using bone pair descriptor and distance descriptor[J]. Symmetry, 2020, 12(10): 1580.
[5]YANG X D, TIAN Y L. Effective 3d action recognition using eigenjoints[J]. Journal of Visual Communication and Image Representation, 2014, 25(1): 2-11.
[6]黄潇逸. 基于骨骼关节点投影特征的人体行为识别方法[J]. 现代计算机, 2019(36): 3-7.
[7]冉宪宇, 刘凯, 李光, 等. 自适应骨骼中心的人体行为识别算法[J]. 中国图象图形学报, 2018, 23(4): 519-525.
[8]FANG H S, XIE S, TAI Y W, et al. RMPE: Regional multi-person pose estimation[C]// 2017 IEEE International Conference on Computer Vision Workshops (ICCVW). Venice, 2017: 2334-2343.
[9]郭天晓, 胡庆锐, 李建伟, 等. 基于人体骨架特征编码的健身动作识别方法[J]. 计算机应用, 2021, 41(5): 1458-1464.
[10] HAN L, XU X X, LIANG W, et al. Discriminative human action recognition in the learned hierarchical manifold space[J]. Image and Vision Computing, 2010, 28(5): 836-849.
[11] DING W W, LIU K, BELYAEV E, et al. Tensor-based linear dynamical systems for action recognition from 3D skeletons[J]. Pattern Recognition, 2018, 77: 75-86.
[12] 石耀. 基于骨骼數据的人体行为识别[D]. 北京:北京邮电大学, 2021.
[13] JOHANSSON G. Visual perception of biological motion and a model for its analysis[J]. Perception & Psychophysics, 1973, 14(2): 201-211.
[14] WANG L, HUYNH D Q, KONIUSZ P. A comparative review of recent kinect-based action recognition algorithms[J]. IEEE Transactions on Image Processing, 2019, 29: 15-28.
[15] LI W Q, ZHANG Z Y, LIU Z C. Action recognition based on a bag of 3D points[C]// Computer Vision and Pattern Recognition-workshops. San Francisco, 2010: 9-14.
[16] DING W W, LIU K, FU X J, et al. Profile HMMs for skeleton-based human action recognition[J]. Signal Processing-Image Communication, 2016, 42: 109-119.
Human Behavior Recognition Based on Bone Projection Information
DENG Gan-sen, DING Wen-wen, YANG Chao
(School of Mathematical Sciences, Huabei Normal University, Huaibei 235000, China)
Abstract: Aiming at the problem that the extraction of human skeletal information by depth cameras fails in complex environment, a method was proposed to combine some important joint points information of human body for behavior recognition by using the motion features extracted from RGB images. Firstly, the spatial position information of each joint point of the human body was captured according to the human behavior picture, the coordinate system was established to depict the human skeleton, and the three views were embedded in the binary image. The Lucas-Kanade optical flow algorithm was used to obtain the motion information of the nodes, which constituted a sequence of actions represented by a tensor. Estimated action feature description sequences, which were mapped to the Grassmann manifold for human behavior recognition and classification. The results of experiments on the MSRActinos3D, UCFKinect datasets show that the method can effectively recognize various human behaviors.
Keywords: projection information; Lucas-Kanade optical flow algorithm; dictionary learning
收稿日期:2022-05-27
基金项目:安徽省自然科学基金(批准号:1908085MF186)资助;安徽省高等学校自然科学研究项目(批准号:KJ2019A0956)资助。
通信作者:丁文文,女,博士,副教授,主要研究方向为人工智能。E-mail: dww2048@163.com
