基于半监督多头网络的腰椎CT图像分割
2023-06-23何越杜钦红杜钰堃杨环西永明
何越 杜钦红 杜钰堃 杨环 西永明


摘要:针对医学图像分割任务中医学数据标注困难以及CT图像强度不均匀问题,提出一种基于半监督的多头分割网络SSMH-Net。SSMH-Net网络采用教师—学生训练架构,基于相同的分割模型V-Net,通过指数移动平均算法完成教师与学生模型的交互训练;采用Multi-Head方法估计模型预测的不确定性信息,指导分割模型在更可靠的目标中学习。在CTspine分割数据集上,SSMH-Net网络平均分割Dice系数达到95.70%,表现出较为优异的分割性能。
关键词:椎体分割;半监督学习;注意力模块;V-Net;multi-head
中图分类号:TP391.41
文献标志码:A
文章编号:1006-1037(2023)02-0036-07
doi:10.3969/j.issn.1006-1037.2023.02.07
基金项目:
山东省泰山学者项目(批准号:ts20190985)资助。
通信作者:杨环,女,博士,副教授,主要研究方向为图像/视频处理与分析、视觉感知建模及质量评估、深度学习等。
腰痛是一种常见的脊柱外科疾病,影响约70%~80%的成年人。腰椎病变,如腰椎滑脱、腰椎间盘突出、椎体畸形等,是引起腰痛的主要原因,已成为重大的社会公共卫生问题。计算机断层扫描(Computed Tomography, CT)影像能清楚地显示腰骶椎和周围结构,被广泛应用于腰椎疾病的诊断和治疗。三维CT图像腰椎分割是后续临床治疗的必要前提。目前,外科医生通常采用手工分割CT图像的方法,不仅费时费力,而且不同的标注软件导致分割结果差异。面对腰部疾病的多样化以及发病率高等问题,通过医生手动分割椎体图像的方法已无法满足当下的诊疗需求。因此,开发一种CT影像自动定位和分割腰椎部位的智能方法,对于脊柱疾病的计算机辅助诊断和治疗至关重要。近年来,在医学图像计算机辅助诊断中,用于脑肿瘤,肺结节等医学图像的自动分割取得了重大进展[1-6]。3D DSN[1]采用端到端的三维全卷积架构,在网络中引入深度监督并采用条件随机场实现轮廓优化;RIMNet[2]利用Region-to-image匹配策略,提高了多模态MRI数据之间的利用率。通过小批量随机禁用模态,将多模态数据输入到模型中,提取的特征通过级联进行融合;2D-SCNet[4]是一种基于CNN的同时分割分类的模型,其中特征提取层由分割网络和分类网络共享。异常椎体和正常椎体在形状和结构上的差异很大,大部分通用的图像分割算法无法实现准确的分割。为了提高椎体分割的精度,构建了许多基于级联结构的模型。Sekuboyina 等[7]提出一种多阶段腰椎分割算法,使用多层感知器提取腰椎的感兴趣区域,然后在感兴趣区域内进行实例分割。迭代椎骨实例分割算法利用移动滑动窗口使其包括完整的椎骨区域,然后对椎骨使用实例分割并保存[8]。尽管这些方法都依赖卷积神经网络来分割椎体,但依旧保留检测和分割任务,且使用两个网络。Li等[9]提出一种用于脊椎分割的卷积神经网络,在网络中加入通道注意模块和双重注意模块,使用多尺度卷积块提高网络的预测能力。这些方法在分割椎体部位取得了较好的效果,但是忽略了CT图像中一些软组织和椎体区域灰度类似,因此可能存在错误的将软组织区域分割出来的情况。监督式深度学习常依赖大量用于训练的标记数据集,对于3D医学图像,获取大量体素级标记数据耗时长且困难。因此,半监督深度学习被广泛应用于医学图像分割,这种方法只需获得少量标记图像和大量未标记图像,并能同时用于网络训练,基于自训练的Inf-Net[10]网络利用隐式反向注意和显式边缘关注来提高病变区域的检测;DAN[11]和BUS-GAN[12]使用对抗生成网络,使未标记图像的分割与标记图像的分割相似。一致性正则化在计算机视觉和图像处理中起着至关重要的作用,尤其是在半监督学习中。DTC[13]是一種新的双任务一致性半监督框架,用联合预测目标的像素分割图和水平集函数表示,该模型强制像素级分类任务和水平集回归任务之间的任务一致性,可以更好的捕捉几何活动轮廓和距离信息。然而现有的半监督模型未考虑CT影像中边界模糊和强度分布不均匀的情况,导致无法准确的分割椎体的边缘区域和椎体内部区域,并且未标注数据没有标注指导训练,导致模型训练过程中可能对预测结果产生过度自信,使模型的分割结果较差。本文提出基于不确定性估计的半监督多头分割网络(Semi-Supervised Multi-Head Segmentation Network,SSMH-Net),SSMH-Net模型由两个相同的分割网络分别作为学生和教师网络,通过在分割网络中跳跃连接处加入注意力来关注椎体内部特征。监督学习模型在训练过程中经常对预测分割结果产生过度自信,因此使用Multi-Head方法估计模型的不确定性,同时设计一致性损失函数,用来最小化学生模型和教师模型在不同扰动下对输入的预测差异。
1 不确定性估计引导的半监督多头分割网络
1.1 半监督学习网络模型
为了充分利用未标注的CT图像分割腰椎,SSMH-Net网络采用经典的教师—学生框架,通过预测结果的不确定性信息来指导网络的训练过程。如图1所示,模型包含一个教师网络和一个学生网络,两个网络共享SC-VNet模型结构。SC-VNet采用V-Net网络作为基础网络,并在跳跃连接处加入SC注意力模块。教师网络的权重通过使用学生网络权重的指数移动平均(EMA)更新提高模型的稳定性和鲁棒性。对于标记的3D CT图像,经过学生网络进行监督学习分割,由监督损失Ldice+Lce组合优化,得到预测结果predA。对于未标记的3D CT图像,期望在不同噪声的扰动下学生网络和教师网络的分割结果(即predA和predB)是一致的。为了提升学生模型的学习能力,采用Multi-Head算法[14]计算师生模型的输出一致性,学生网络通过Ldice+Lce(监督损失)和Lcon(无监督一致性损失)的组合进行优化,有效地指导学生网络从教师网络中学习更可靠地目标。
1.2 融合SC注意力的学生模型和教师模型
CT图像中往往存在强度分布不均匀的情况,导致椎体内部模糊,边界不清晰,造成椎体分割精度较低。针对上述问题,本文构建了监督学习模型SC-VNet。在V-Net模型的基础上,添加空间及通道(Spatial and Channel,SC)注意力模块关注椎体内部特征,通过增强通道特征和融合3D空间信息提高分割的准确率。SC模块主要结构如图2所示,图中X(大小为C×H×W×D)作为注意力模块的输入特征信息,SC注意力模块由通道注意力模块和空间注意力模塊组成[15]。通道注意力模块是利用特征的通道间关系来生成通道注意力图,采用全局平均池化Favg(·)压缩输入特征图的空间维度,使用两个全连接层实现权重值在不同的通道中的流动,并通过非线性激活函数(Sigmod)σ1将权重限制到0~1之间。将学习到的通道权重重构为Mc(大小为C×1×1×1),与注意力模块的输入X使用点乘运算得到Xcha。为了充分使用3D空间信息,利用特征的空间关系生成空间注意力。首先输入图像X采用一个大小为1×1×1的3D卷积Fcon(·)进行降维操作。经过非线性激活函数(Sigmod) σ2激活后,将得到的空间权重Ms(大小为1×H×W×D)与注意力模块的输入X使用点乘运算得到Xspa。Xcha,Xspa和X通过相加生成3D通道和空间注意力图X′。
在半监督学习框架中教师模型和学生模型之间的权重通过指数移动平均(EMA)共享[16]。指数移动平均(EMA)是每次梯度更新之后的权值和上一次的权值采用加权平均,而不是每个Epoch之后再进行信息聚合。EMA改变的是分割网络中所有层的输出,而不仅仅是其中某一层的输出,因此EMA可以得到更好的中间表示。EMA权重的更新公式为
其中,t是训练次数;θ′t是教师模型的权重;θt是学生模型的权重;α为 EMA的衰减率,用来控制网络更新速度。与直接使用学生网络的最后参数相比,使用EMA权重通常会产生更准确的网络模型。
1.3 多头输出的不确定性估计算法Multi-Head
由于CT图像椎体内部和外部高度相似性,预测分割结果中容易产生假阴性和假阳性区域。若将没有标注的图像输入到教师网络,得到的目标预测可能是不可信的,因此SSMH-Net模型采用Multi-Head的方法,指导学生网络从更可靠的目标中学习。为方便计算模型的不确定性,将监督分割网络的单个输出层扩展成M个输出层。简单的说,Multi-Head有M个类型相同的输出层(1,2,…,M),但每个输出层都具有不同的权重和初始化,因此每个输出层产生的预测也是不相同的。使用加权损失促进输出层之间的多样性,可以更好地覆盖CT图像的内部和外部区域,有利于捕获推理时的歧义。对于输入图像的每个体素,可以得到一组概率向量。因为预测熵具有固定的范围,可以作为不确定性的度量。在不确定性估计的指导下,设置一个阈值,过滤掉相对不可靠的预测,选择可靠的预测作为学生模型学习的目标
其中,pnumt表示第num类在第t次的输出的概率,mi是M个预测的平均值,num是类别数,不确定性u大小为H×W×D,是预测的体素熵。
1.4 损失函数组合优化
为充分利用3D空间信息,模型使用3D影像作为两个分割网络的输入,其中训练集是由U个标记数据和V个未标记数据组成。标记集为Dl={xi,yi}Ui=1,将未标记的数据集为Du={xi}U+Vi=U+1,其中xi是大小为H×W×D的输入影像,yi∈{0,1}H×W×D是真实标注。
对于有标注的图像,学生网络主要受监督损失的指导,以学习分割任务的可靠表示。模型采用Dice损失Ldice和交叉熵损失Lce的组合作为监督损失Lsup来分割腰椎
其中,δm(a)=1-ε, if a=trueεM-1, else,a代表M个输出层中预测损失最少的输出层;ε为设置的权重;m为多个输出层。
对于没有标注的图像,可以根据半监督学习中的平滑假设,将输入图像加上不同的噪声生成两个图像,通过学生和教师网络得到对应的分割掩码在理论上是相同的,因此模型可以通过最小化一致性损失建立学生模型预测结果predA和教师模型预测结果predB的约束
其中,I(·)为指标函数,阈值在0~1之间;predA和predB分别是学生模型和教师模型在第v个体素上的预测;uv是第v个体素处的不确定性估计;value是选择可靠目标的阈值。通过在训练过程中的一致性损失,学生和教师模型都可以从中学习到更可靠的知识,降低模型的不确定性。
2 实验结果和分析
2.1 数据集和预处理
评估模型所使用的CTspine数据集由36个3D CT成像扫描组成,图像尺寸从512×512×350到512×512×512(体素)不等,每一个3D图像都有一个与图像相同大小的腰椎分割掩码。预处理使用[-700, 1300]HU的软组织CT窗口范围,基于随机扩大边缘(10~20个体素)的分割掩码裁剪腰椎区域为中心的图像,并将所有图像进行零均值归一化和单位方差处理。实验将36次扫描分为30次扫描用于训练和6次扫描用于测试。
2.2 实验设置
实验均采用Pytorch开源框架,使用的显卡型号为NVIDIA A100 GPU;模型采用SGD优化器进行训练,共6 000次迭代,EMA衰减率为0.99;批量大小为2,每次由1个标记图像和1个未标记图像组成;初始学习率设置为0.01,每经过2 500次迭代除以10;将原始图像随机裁剪为128×128×96作为网络模型的输入,并使用滑动窗口策略获得最终的分割结果;SSMH-Net将多头输出M设置为4。
2.3 实验结果
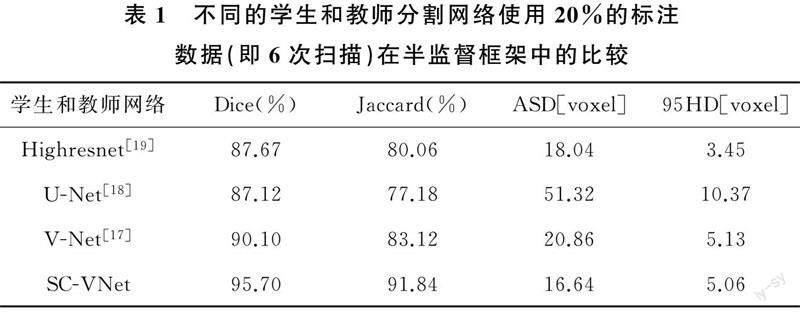
为了评估半监督框架中学生网络和教师网络所使用的完全监督分割网络的准确性,将所提出的半监督框架使用不同的学生和教师网络在3D椎体数据集上训练和测试,包括SV-Net、V-Net[17]、U-Net[18]和Highresnet[19]4种网络。在30次训练扫描中,使用20%的数据(即6次扫描)作为标注数据,其余24次扫描作为未标注数据。其他所使用的实验参数设置完全一致。实验结果见表1,SSMH-Net模型中使用不同的学生和教师网络的分割精度对比,学生和教师网络使用加入SC注意力的V-Net网络在半监督框架中取得95.70%的分割精度,优于其他对比模型。
為了验证SSMH-Net模型的有效性,将SSMH-Net模型与其他半监督分割模型进行比较,包括SASSnet[20]、DTC[13]、MC-Net[21]和SCC[22]。实验时,所有模型都采用20%的标记数据和80%的未标记数据,结果见表2,可知, SSMH-Net模型分割精度较高。由于SSMH-Net仅仅在监督网络SC-VNet的输出层上进行了扩展,相比较其他半监督分割模型,在计算量少的前提下依然获得较好的分割效果。
图3为DTC、SASSnet、MC-Net、SCC和SSMH-Net模型的分割可视化结果,其他模型在多个椎体连接部分产生粘连,特别是SASS-Net。SSMH-Net模型在没有任何形状约束下,依然得到更好的分割结果,具有更少的孤立区域,并且有效地分割一些具有挑战性的区域,见图3中标记部分,说明SSMH-Net模型优于其他网络。
为了验证SSMH-Net模型的鲁棒性,在2018年心房分割挑战赛的基准数据集(LA)上评估该性能。数据集包括100个用于训练的MR成像扫描,各向同性分辨率为0.625×0.625×0.625 mm。模型使用80个样本用于训练,其余20个样本用于测试,SSMH-Net模型与其他方法在同一验证集上的比较结果见表3。可知,SSMH-Net模型在大部分评价指标上优于其他模型。
使用两种比较流行的半监督设置(10%和20%的标注数据)观察所提SSMH-Net模型的数据利用情况,评估结果见表4。可以看出,同样使用10%的标注数据,SSMH-Net模型利用90%的未标注数据比SC-VNet模型分割所得到的Dice结果高5.82%;在20%的标记数据中,SSMH-Net比SC-VNet的 Dice结果高3.67%,表明SSMH-Net模型能更加有效地利用未标记数据来提升模型的分割性能。V-Net和U-Net监督模型使用全部标注数据分割精度分别为96.48%和96.18%,仅仅比使用少量标注数据的SSMH-Net高0.78%和0.48%,表明SSMH-Net在临床应用中有更广阔的潜力。
3 结论
本文提出一种应用于腰椎CT分割领域的SSMH-Net模型,采用基于不确定性估计的半监督深度学习框架,通过对相同输入的图像加入不同的扰动,以达到学生和教师模型分割一致性的目的,最终实现在较少标注数据的同时提高分割精度的效果。SSMH-Net模型采用了Multi-Head方法,通过探索每个目标的不确定性信息计算一致性损失,以此提高分割目标的质量。在标注规模相同的数据集下,与主流分割模型相比,SSMH-Net模型表现出较为优异的分割效果,能够减轻医学图像数据标注,在分割精度上具有较大的临床价值。
参考文献
[1]QI D, HAO C, YUE M J, et al. 3D deeply supervised network for automatic liver segmentation from CT volumes[C]//International Conference on Medical Image Computing and Computer-assisted Intervention. Springer, 2016: 149-157.
[2]DAS P, PAL C, ACHARYYA A, et al. Deep neural network for automated simultaneous intervertebral disc (IVDs) identification and segmentation of multi-modal MR images[J]. Computer Methods and Programs in Biomedicine, 2021, 205: 106074.
[3]DOLZ J, DESROSIERS C, BEN AYED I. IVD-Net: Intervertebral disc localization and segmentation in MRI with a multi-modal UNet[C]//International Workshop and Challenge on Computational Methods and Clinical Applications for Spine Imaging. Springer, 2018: 130-143.
[4]GONG Z, KAN L. Segmentation and classification of renal tumors based on convolutional neural network[J]. Journal of Radiation Research and Applied Sciences, 2021, 14(1): 412-422.
[5]CUI S G, MAO L, JIANG J F, et al. Automatic semantic segmentation of brain gliomas from MRI images using a deep cascaded neural network[J]. Journal of Healthcare Engineering, 2018, 2018.
[6]ZHU W T, LIU C C, FAN W, et al. Deeplung: Deep 3d dual path nets for automated pulmonary nodule detection and classification[C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018: 673-681.
[7]SEKUBOYINA A, VALENTINITSCH A, KIRSCHKE J S, et al. A localisation-segmentation approach for multi-label annotation of lumbar vertebrae using deep nets[DB/OL]. [2022-08-20]. https://arxiv.org/abs/1703.04347.
[8]LESSMANN N, VAN GINNEKEN B, DE JONG P A, et al. Iterative fully convolutional neural networks for automatic vertebra segmentation and identification[J]. Medical Image Analysis, 2019, 53: 142-155.
[9]LI B, LIU C, WU S Y, et al. Verte-Box: A novel convolutional neural network for fully automatic segmentation of vertebrae in CT image[J]. Tomography, 2022, 8(1): 45-58.
[10] FAN D P, ZHOU T, JI G P, et al. Inf-net: Automatic covid-19 lung infection segmentation from CT images[J]. IEEE Transactions on Medical Imaging, 2020, 39(8): 2626-2637.
[11] ZHANG Y, YANG L, CHEN J, et al. Deep adversarial networks for biomedical image segmentation utilizing unannotated images[C]// International Conference on Medical Image Computing and Computer-assisted Intervention. Springer, 2017: 408-416.
[12] HAN L Y, HUANG Y Z, DOU H R, et al. Semi-supervised segmentation of lesion from breast ultrasound images with attentional generative adversarial network[J]. Computer Methods and Programs in Biomedicine, 2020, 189: 105275.
[13] LUO X D, CHEN J N, SONG T, et al. Semi-supervised medical image segmentation through dual-task consistency[C]// 35th AAAI Conference on Artificial Intelligence. 2021: 8801-8809.
[14] RUPPRECHT C, LAINA I, DIPIETRO R, et al. Learning in an uncertain world: Representing ambiguity through multiple hypotheses[C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, 2017: 3591-3600.
[15] CHEN L, ZHANG H W, XIAO J, et al. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning[C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, 2017: 5659-5667.
[16] TARVANINEN A, VALPOLA H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results[C]// 31st Annual Conference on Neural Information Processing Systems (NIPS). Long Beach, 2017.
[17] MILLETARI F, NAVAB N, AHMADI S A. V-net: Fully convolutional neural networks for volumetric medical image segmentation[C]// 4th IEEE International Conference on 3D Vision (3DV). Stanford, 2016: 565-571.
[18] ICEK , ABDULKADIR A, LIENKAMP S.S, et al. 3D U-Net: learning dense volumetric segmentation from sparse annotation[C]// International Conference on Medical Image Computing and Computer-assisted Intervention. Springer, 2016: 424-432.
[19] YANG G S, MANELA J, HAPPOLD M, et al. Hierarchical deep stereo matching on high-resolution images[C]// 32th IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). 2019: 5515-5524.
[20] LI S L, ZHANG C Y, HE X M. Shape-aware semi-supervised 3D semantic segmentation for medical images[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2020: 552-561.
[21] WU Y C, XU M F, GE Z Y, et al. Semi-supervised left atrium segmentation with mutual consistency training[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2021: 297-306.
[22] LIU Y S, WANG W, LUO G N, et al. A contrastive consistency semi-supervised left atrium segmentation model[J]. Computerized Medical Imaging and Graphics, 2022, 99: 102092.
