潜在科研合作机会识别方法研究进展
2023-06-23张雪张志强
张雪 张志强


摘 要:文章梳理了国内外潜在科研合作机会识别相关成果,归纳总结现有识别方法及存在的问题,为学科领域进行前瞻性合作推荐提供参考借鉴。首先对潜在科研合作机会识别的必要性进行归纳总结,其次对相关概念及研究主体类型进行界定,再次在调研国内外相关研究基础上对潜在科研合作机会识别方法进行归纳整理,最后指出现有研究不足并对未来发展提出展望。研究发现:就研究主体类型而言,根据研究目的、研究层次的不同,将研究主体划分为微观、中观、宏观三个维度。就识别方法而言,外部属性信息是潜在科研合作机会识别方法中最直接、最通俗易懂的方法;链路预测是使用最多、应用最为成熟的方法;比较而言,网络学习和机器学习是潜在科研合作机会识别的新方向和新思路。在以上分析基础上,总结了不同方法的不足以及存在的普适性问题,并对未来研究重点进行展望。
关键词:潜在合作机会;外部属性特征;研究内容;链路预测;网络表示学习;机器学习
中图分类号:G304 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2023022
Abstract This Paper sorting out the relevant achievements in the identification of potential cooperation opportunities, this paper summarizes the existing identification methods and problems, providing reference for forward-looking cooperation recommendations in the discipline field. Firstly, this paper summarizes the necessity of identifying potential cooperation opportunities. Secondly, it defines the relevant concepts and entity object types. Thirdly, it summarizes the identification methods of potential cooperation opportunities. Finally, it points out the existing research deficiencies and puts forward prospects for future development. As for the types of entity objects, according to the different research purposes and research levels, entity objects are divided into three dimensions: microscopic, mesoscopic and macroscopic. As for the identification methods, external attribute information is the most direct and easy method in the identification of potential cooperation opportunities; link prediction is the most widely used and most mature method; in comparison, network representation learning and machine learning are new directions and new ideas for identifying potential cooperation opportunities. Based on the above analysis, the deficiencies and universal problems of different types of potential cooperation opportunities identification methods are summarized, and the future research priorities are prospected.
Key words potential cooperation opportunities; external attribute information; research topic; link prediction; network representation learning; machine learning
發现和把握科研合作机会是促进和开展科研合作的基础。随着解决复杂性和挑战性不断提高的综合性、高难度科研任务或科技问题的需求持续增加,跨国家(地区)、跨机构、跨学科等多种形式的合作研究成为科学研究和科技发展的重要途径。为此,从浩瀚资源中快速定位并识别潜在科研合作机会的理论方法研究,就成为了一个前沿性和战略性研究课题。
发现和把握潜在合作机会需要发展和完善(定性和定量相结合的)识别方法。本研究主要关注如何识别不同研究主体间的潜在合作机会,即从方法论的角度出发探讨采用何种方法、手段从研究主体已有的合作模式中进一步挖掘未合作对象间的潜在合作机会。目前学者在该方面已有一些初步探索,其中定性研究方面,领域专家通常参与不同对象间潜在合作机会的预判。但随着数据密集型科研范式的到来,技术领域高度分散,通过人工精准追踪学科领域合作机会的关联与传递,这一传统知识发现模式的可靠性、及时性逐渐降低。定量研究方面,现有研究大多考察了已存在关联关系的合作对象间网络结构演变趋势。对于科技政策制定者或企业来说,虽然衡量过去某个时间段内研究主体间已有合作模式十分重要,但无法提前为潜在合作带来的新挑战做好准备,也无法提前预判未来科学技术变革将在哪些国家、机构、学科间发生,比较而言,挖掘研究主体间潜在合作机会的模式更为关键。整体来看:首先,现有潜在合作机会识别研究多以定性分析为主,定量研究大多分析了目前已产生合作关系的对象间网络结构演化趋势,对尚未产生关联的对象间潜在合作模式的提前识别研究相对较少;其次,对于潜在合作机会识别中所涉及的概念内涵、研究方法等的梳理尚存在清晰性、系统性不足等问题。
基于此,本研究首先对潜在合作机会识别的概念进行界定,进一步从宏观、中观、微观三个维度对研究主体类型进行归纳,以便明晰合作机会识别的服务主体;其次对已有潜在合作机会识别方法进行梳理和总结,以期全面揭示潜在合作机会识别的方法体系,为科研人员根据研究对象、网络拓扑结构特征等从不同层面切入寻找精度最优模型提供参考借鉴。
1 潜在科研合作机会识别概念及研究主体
潜在合作机会识别以研究主体合作网络为基础,节点为不同研究主体,连边为主体间合作关系,其是在学习大量历史资源网络拓扑结构或网络属性特征的基础上挖掘研究主体间可能产生新连边的可能性,进而识别主体间的潜在合作机会。
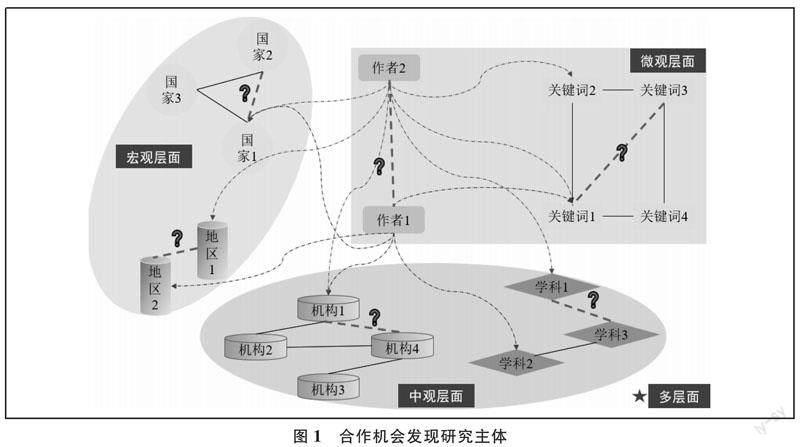
根据研究目的、研究层次的不同,研究主体可进一步划分为基于微观层面的科研人员或关键词合作机会识别、基于中观层面的机构或学科领域合作机会识别、基于宏观层面的国家或地区合作机会识别(各研究主体间关联关系见图1),具体分析如下:
(1)微观层面的分析。这方面的研究一方面侧重于为研究人员选择潜在合作对象。如张金柱和韩涛选用12个共同邻居及其改进指标分析图书情报领域潜在合作关系[1];丁敬达和郭杰综合运用作者研究内容相似度和合作网络结构相似性分析我国生物医学领域潜在合作关系[2];另一方面侧重于从关键词共现角度剖析未来可能产生联系的关键词,进而挖掘潜在主题。如黄璐等运用链路预测指标识别钙钛矿材料领域技术术语加权共现网络中的潜在共现关键词,以期得到未来新兴技术主题[3];Duan和Guan以太阳能领域论文文献关键词共现网络为基础,综合运用链路预测、关键词中介中心性等指标分析关键词潜在融合模式,以期得到未来需关注的主题[4]。微观层面分析中,科研人员潜在合作机会发现研究已较为成熟,而关键词间的预测分析还处于初级阶段,与同词异义、异词同义等问题有关。
(2)中观层面的分析。相关研究一方面侧重于分析不同研究机构间潜在合作趋势。如余传明等基于特征融合的链路预测方法对金融领域机构、区域间潜在合作机会进行识别[4];李鲁莹综合考虑高校的合作机构、学科分布、研究兴趣等属性,挖掘卓越大学联盟与国内外高校潜在合作机会[6]。另一方面侧重于分析不同学科潜在交叉融合趋势,根据选用数据源的不同,又可将其分为:其一,基于论文文献的潜在学科合作机会识别。如岳增慧等以学科引证知识扩散时序演化网络结构信息为基础,采用无权及加权链路预测指标分析社会网络领域潜在学科合作关系[7]。其二,基于专利文献的潜在学科合作机会识别。如Cho等以化学工程领域专利IPC分类号共线网络为基础,采用随机森林模型预测潜在学科合作关系[8];Kwon等结合专利IPC分类号共线网络、网络中心性指标等分析潜在学科合作关系[9];唐影基于图神经网络的链路预测模型预测3D打印技术的潜在学科合作关系[10]。因Web of Science、Scopus等主流数据库目前均并没有对单篇文献进行学科归类,一般通过文献所属期刊学科类别间接表征文献学科分类,但一篇文献对应一个期刊,一个期刊一般归至1-2个学科类别,数据体量过少,故基于论文文献的学科共现网络数据不适用于链路预测等潜在合作机会识别方法。与论文文献相比,每个专利自带多个IPC分类号,有效克服了论文文献的局限性,因此目前以专利文献为数据源分析潜在技术合作机会研究相对较多。
(3)宏观层面的分析。与中观、微观层面分析相比,国家这一对象间潜在合作机会识别研究相对较少,主要研究包括Guan等以国家间原油贸易网络拓扑结构为基础,以每个国家对共同贸易伙伴数量为潜在合作动机,探索国家间潜在贸易合作伙伴关系[11];Guns和Rousseau结合链路预测和机器学习方法挖掘非洲、中东和南亚城市在疟疾和结核病领域潜在合作关系[12]。这方面研究较少的原因是与基于科研人员合作关系网络拓扑结构相比,同样的数据集中,捕捉到的国家或地区节点数量会大量减少,而已有合作机会识别方法主要是学习网络中节点间关联關系,因而节点数量是算法表现优劣的基础。
(4)多层面综合分析。科研人员层面的挖掘有助于发现具有相同研究主题的学者,揭示影响合作的因素如师承关系等;机构层面的挖掘有助于发现对相关主题共同感兴趣或合作密切的科研团体,揭示地理位置等因素是否对合作关系产生影响;国家层面的挖掘则更多聚焦宏观层面,有助于发现国际间潜在合作趋势,揭示国家发展战略规划、经济发展差异等因素对合作的影响。这些研究层次并不是彼此孤立,而是互相关联,若将以上不同层面的研究主体综合分析,则能挖掘出更加丰富的信息。目前学者在该方面研究有一些初步探索,如林原等融合科研人员、机构、关键词3个层面的异质信息构建科研合作网络,采用网络表示学习模型将网络中每个节点表示为低维向量,通过余弦相似度计算向量相似度进而为作者推荐潜在合作者、合作机构、研究主题等[13]。不过融合多种异质信息的研究较少,更多研究在一模网络基础上探究二模合作关系,如分析潜在合作作者及其合作主题、潜在合作机构及其合作者等,该方面研究仍是未来研究方向和重点。
2 潜在科研合作机会识别方法研究
研究主体蕴含丰富的信息,对象间的路径长度也一定程度上反映了节点间的紧密关系,基于这些信息,学者从不同的分析角度探索性地提出一些分析方法,并在实践中得到一定的验证。根据分析方法所基于的研究主体信息不同,本研究将其分为外部属性、研究内容、链路预测、网络表示学习、机器学习共五种方法类型,其中外部属性信息是研究主体最基本的信息,也是合作机会识别方法中最直接、最通俗易懂的方法;链路预测是使用最多、应用最为成熟的方法;网络表示学习和机器学习是合作机会识别的新方向和新思路。
2.1 基于外部属性特征的合作机会识别方法
该方法主要基于节点的外部属性特征来刻画节点间相似性。若节点为作者,则其外部属性特征包括年龄、性别、职业、爱好、所属机构、研究兴趣等;若节点为机构,则其外部属性特征包括机构的类型、地理位置、排名、研究主题等;若节点为具体学科领域,则其外部属性特征包括学科的研究主题、主要发文机构、主要发文作者等。基于外部属性特征的合作机会识别研究一般基于以上信息构建节点向量,然后通过计算向量间余弦相似度分析节点对在合作选择偏好方面的相似程度。运用节点属性特征等外部信息可提高预测结果,但这些信息获取困难,如用户信息涉及隐私问题,因此现有研究很少单独使用节点外部属性特征进行合作机会识别,一般将其与链路预测、机器学习等方法联合使用。如Liben-Nowell和Kleinberg将论文标题、作者机构、地理位置信息等外部属性特征加入作者合作网络中对潜在合作机会识别结果进行微调[14];Ahmed和Elkorany以社交网络Twitter为研究对象,首先抽取出不同类型用户的属性信息和多种网络结构特征,基于此对用户间联系强度关系建模,结果表明结合用户属性相似度可有效提高链路预测效果[15];Abu-Salih等以Twitter用户外部属性特征为研究对象,结合机器学习方法识别用户潜在感兴趣的研究领域[16];汪志兵等融合作者合作网络拓扑结构信息和作者机构属性特征构建潜在合作机会识别模型[17];林原等以“高校—共有机构合作网络”和“机构—发文主题网络”为数据基础,构建综合考量路径相似性和研究主题相似性的加和指标体系,以识别卓越大学联盟与国内外高校潜在合作机会[18]。
该方法与链路预测等方法结合使用可有效提高算法精确度,但外部属性信息的真实性、可靠性常难以保证。更进一步,假若能获得并保证节点信息准确度较高,但如何鉴别哪些信息对链路预测有用,有多大用处,是需要进一步探索的问题。
2.2 基于研究内容相似度的合作机会识别方法
Morris和Yen指出,通过共同的词语联系到一起的文献可能表示共同的研究主题,同理,作者关键词表征作者研究主题,通过挖掘作者关键词耦合强度可测度作者研究主题相似度,从而挖掘潜在合作关系[19]。具体分析步骤为:首先,建立“作者—关键词”二模矩阵,采用TF-IDF等方法计算关键词权重;其次,根据“作者—关键词”矩阵,通过作者间共有关键词耦合强度构建作者相似度矩阵;最后,将作者对相似度值降序排列,过滤已产生合作关系的作者对,剩余即为潜在作者合作关系。若将上述过程中作者替换为机构、国家、学科等主体,则可挖掘出潜在合作机构、合作国家等;若将关键词耦合强度关系替换为作者发文同被引或文献耦合关系,则可从引文角度挖掘潜在合作关系。已有研究包括刘志辉和张志强对比分析作者关键词耦合网络与作者同被引网络,结果表明作者关键词耦合网络能揭示作者之间的隐含关系[20];陈卫静和郑颖基于作者关键词耦合分析法挖掘作者之间潜在合作关系[21];宋艳辉和武夷山对比分析作者文献耦合网络和作者关键词耦合网络在揭示学科领域知识结构方面的异同,结果表明二者不可互相替代,结合分析是探寻学科知识结构的理想方法[22]。
该方法自提出以来推广应用程度并不高,究其原因:一方面只是从内容角度揭示了作者间合作的可能性,而关键词存在很高的主观性,两个不同的词可能蕴含相同词意,相同的词在不同文章中可能表达不同研究内容;另一方面主要依靠人工定性判读识别结果是否可靠,并没有数据支撑识别结果与真实合作关系之间的差异。因此该方面的研究主要与链路预测、机器学习等方法结合使用。
2.3 基于链路预测的合作机会识别方法
链路预测基于马尔可夫链和机器学习,其主要通过对大量网络节点属性特征和网络拓扑结构信息的学习来预测尚未产生连接的两节点间产生连边的可能性。这种预测既包含实际网络中未出现但未来很有可能产生的连接关系,也涵盖实际网络中已存在但尚未被观测到的未知连接。因其易理解、易实施、可量化评估等优点是目前合作机会识别中使用最多的方法,最新出现的网络表示学习、机器学习等方法也大多在其基础上优化改进,故研究着重对该方法的详细分析流程进行介绍。
第一步:根据网络结构特点确定预测指标。
Liben-Nowell和Kleinberg最早基于网络结构特征引入链路预测指标[14],随后吕琳媛将链路预测的相关研究方法引入国内[23]。有研究表明,目前共有30余种不同链路预测指标[24],根据各指标内涵的不同,可将其分为基于网络结构相似性的链路预测指标及基于似然分析的链路预测指标。其中基于结构相似性的链路预测指标计算复杂度低,适用于大规模网络,进一步地,根据各指标依附的网络结构信息的不同,又可将其分为基于节点信息、基于路径信息、基于随机游走三种类型,梳理归纳每种链路预测类型对应的指标及计算方法,具体如下:
(1)基于节点信息的相似性指标。基于节点相似性的链路预测指标构建原则为两个节点间的相似性程度越高,则它们之间产生连接的可能性越大。其中计算最简单、使用频率最高的经典指标为共同邻居指标(Common Neighbor,CN),它指两个节点的共同邻居节点数目,若节点x和节点y未连接,但其共同邻居节点数目越多,则两节点间的相关性越高[25]。为了进一步增强指标的鲁棒性,学者们基于CN指標进行了许多探索工作,改进指标可分为两类:一类是在共同邻居节点基础上纳入考量未连接的两节点度的影响,改进指标包括Salton指标[26]、Jaccard指标[27]、Srensen指标[28]、HPI指标[29]、HDI指标[30]、LHI-I指标[31]等;另一类是在共同邻居节点基础上纳入考量共同邻居节点度的影响,改进指标包括AA指标[32]、RA指标[30]、PA指标[33]等。此外,一些学者认为,处于中心位置的节点可能具有更强的信息传播能力,故利用节点聚类系数、中介中心度、特征向量中心度等信息对经典指标进行改进[34-36](各指标的计算方法及含义见表1)。此类指标在简单高效基础上充分运用网络中节点信息,网络适用范围广,预测精度较高,是目前使用最为广泛的一类指标。
(2)基于路径信息的相似性指标。CN类指标计算复杂度低,但使用信息有限,因而预测精度受到限制。基于此,学者尝试利用节点间路径信息,从另一角度切入提出一系列相似性指标。基于路径相似性的链路预测算法从整体网络出发,其构建原则为考虑所有长度路径的影响,若两节点间最短路径长度越短,只需经过较少节点就能相互访问,说明节点间关系相对密切[36]。经典指标具体如下:局部路径指标(Local Path,LP)在共同邻居的基础上考虑三阶路径的因素[37];Katz指标则在LP指标基础上考虑网络中所有路径对节点、对相似性贡献程度[38];LHI-II指标基于一般等价原理[31](各指标的计算方法及含义见表2)。该类指标以完整的或近似完整的网络拓扑结构信息为基础,虽准确率有普遍提升,但计算复杂度过高,计算耗时,不适合应用于大规模数据集;且往往无法获得完整的网络拓扑结构信息。
(3)基于随机游走的相似性指标。随机游走用来表示任何不规则运动而形成的轨迹[39],基于随机游走的相似性指标根据随机游走模型定义,得到一系列节点对间的概率值,进而将其作为不相邻节点对的相似性得分,得分值越高,则两节点间产生连边的可能性越大。经典指标具体如下:平均通勤时间(Average Commute Time,ACT)通过比较随机游走粒子在节点对间来回游走的平均时间来衡量两个节点间的相似性[40];基于随机游走的余弦相似度(Cos+)在ACT指标基础上计算两节点间余弦相似度[41];有重启的随机游走指标(Random Walk with Restart,RWR)基于谷歌PageRank算法[42];SimRank指标旨在刻画从不相邻节点出发的两个粒子平均花费多长时间相遇[43]。上述指标基于全局网络信息,计算复杂度高,难以推广应用。为了提高模型泛化能力,学者摒弃网络中无用或用途不大的信息,提出基于局部网络信息的指标,如Liu和lü提出只考虑有限步数的局部随机游走指标(Local Random Walk,LRW),接着在LRW指标基础上,将t步及其以前结果加总得到有叠加效应的局部随机游走指标(Superposed Random Walk,SRW)[44](各指标的计算方法及含义见表3)。该类指标对网络拓扑结构和演化机制依赖程度较高,若算法恰好能抓住网络拓扑结构特征,则预测准确率较高;但计算复杂度相较于路径信息指标更高,同样不适用规模较大网络。
基于似然分析的链路预测方法通过计算网络中未连接节点间存在链路的似然值或观察一条链路的加入和移除对网络自身似然的影响来判别该条连接是否存在。该方法新颖性强,但算法复杂,晦涩难懂;另一方面应用性不高,即使是精巧实现的算法,处理几千个节点的网络也会感到吃力。有研究表明,基于节点相似性的链路预测方法优于该方法,同时显示出强大的计算优势[45]。
在真实网络中,首先,有的节点对联系紧密,有的则较为疏远;其次,节点对间关系不是完全对等,如引用关系网络,存在施引文献和参考文献的区别;最后,网络可能由不同类型节点组成,如机构-关键词、作者-主题等。因此基于无权无向同类型节点,又衍生出加权网络、有向网络、二模异构网络或多种关系集成网络,具体的链路预测指标是在上述指标基础上进行推广和改进,此处不再赘述。
第二步:将已有数据集划分为训练集和测试集。
为了比较上述链路预测指标效果优劣,首先将已知连边集合E划分为训练集ET和测试集EP满足条件E=ET∪EP且ET∩EP =■,同时将属于U但不属于E的边称为不存在的边,属于U但不属于ET的边称为未知边。划分数据集的方法包括随机抽样、滚雪球抽样、k-折叠交叉检验等,划分的不同方式代表了链路预测的两种类型:静态链路预测和动态链路预测。其中静态链路预测用来挖掘网络中实际存在但被遗漏或尚未被发现的节点关系,动态链路预测用来发掘当下网络中不存在,但未来可能存在连接的节点关系。
第三步:分别计算测试集和不存在边对应的指标数值。
对链路预测算法的计算过程进行梳理(见图2),可以发现网络中节点总数V=5,E=8,网络中可能的连接数U=5*(5-1)/2=10。为了测试指标的精确性,选择边{AB,AE,AC,BE,BC,CD}为训练集,边{EC,BD}为测试集,分别采用不同指标为每对没有连边的节点对{EC,BD,AD,ED}赋值,将所有未连边的节点对按照分数值从大到小排列。若模型能更多地将测试边{EC,BD}排在不存在的边{AD,ED}之前,则表明模型的预测精度越高。
第四步:衡量链路预测算法精确度。
通过将链路预测算法预测结果与测试边进行对比分析,进而评价算法的优劣。目前常用的评价指标主要包括是三类:
(1)AUC值(Area Under the receiver operation characteristic Curve):該指标从整体上衡量链路预测算法精度,其基本思想可解释为从测试集EP中随机选取一条连接边的预测概率高于不存在边的预测概率的可能性[46]。因从整体上衡量算法的精确度,故区分度比较低,可能出现两个算法准确率相差很大,但AUC值差异很小,甚至可能持平[47]。
(2)精确度(Precision):根据排序结果,有时只关心前L个预测节点对中预测准确的比例,若L个预测节点对中有m个节点对预测准确,则精确度Precision=m/L。该指标大小与参数L有关,为了避免参数L取值主观性过高影响对比结果,一般与AUC值结合使用。
(3)排序分(Ranking Score):该指标主要考虑测试集中节点对在最终排序中的位置。计算公式为:RS=1/|EP|*■■,其中EP是测试集集合,ri是测试边i∈EP在排序中的排名,H=U-ET为测试集中节点对和不存在的节点对集合。
第五步:选择精确度较高指标应用于整个数据集,进行潜在合作机会识别。
任何单一指标所考虑的信息相对有限,不能适应所有网络拓扑结构特征,故不能在所有网络类型中均有较好的准确率。因此一般将多种不同指标应用于训练集和测试集,选择预测精确度最高的指标应用于整个网络,进而分析那些潜在的合作组合。
链路预测方法可用来揭示和预测隐含对象间关系,在合作机会识别领域有很好的应用价值。但在实际应用中也存在部分局限:其一,只能预测训练网络中未连接节点间产生连边的概率,不能预测连接到新增节点的概率。而现实网络中随着时间演进,已有节点间不仅可能产生连接,而且会出现新节点;其二,在动态链路预测中,网络处于不断演化状态,但为了有一个相对较为公平的比较环境,需将待分析节点限定在训练集和测试集共有的节点范围内,忽略新增节点的作用;其三,某个指标在目标网络中表现出较高的预测准确率,但在其它网络中可能表现不佳,故如何吸收各指标不同或互补特征,以提高指标适用性是未来研究的新方向;其四,一方面网络拓扑结构会影响网络演化趋势,另一方面政策干预等外部因素也对链路预测结果产生影响,故该方面仍难以全面捕捉对象间关系及其未来趋势走向。
2.4 基于网络表示学习的合作机会识别方法
随着数据体量激增,链路预测等传统方法应用于网络中大规模节点关系挖掘显得力不从心,因此基于深度学习的网络中节点向量自动表示学习成为研究热点。网络表示学习属于深度学习的范畴,其具体做法为:以包含节点上下文信息的语料为数据基础,首先,结合文本上下文语义信息,通过设计多层神经网络结构,将原始网络中每个节点映射为低维稠密实值向量,且使得该向量形式可在向量空间中具有表示以及推理能力,进而实现数据输入至任务输出的目标;其次,计算节点间的向量空间相似度值并将计算结果降序排列,通过对尚未产生合作关系但相似度较高的节点的进一步挖掘以识别潜在合作关系;最后,若将节点的向量表示结果作为机器学习模型的特征输入,则通过二元运算等方法将单个节点特征向量转换为任意两个节点间的向量表示,接着采用不同机器学习模型对节点间关系进行再次学习。通过上述流程,使得知识发现和知识推理性能显著提升。通过对已有研究梳理,可将目前合作机会识别研究中采用的经典的网络表示学习方法分为两类:一类是基于网络结构信息,一类是融合节点内容特征的局部网络结构信息(具体研究内容见表4)。
网络表示学习方法可降低噪声和冗余信息影响,将网络中节点表示为低维稠密连续向量,有效弥补传统方法高计算复杂度、低并行速度等缺陷。已有网络表示学习方法基于网络结构、节点文本等信息开发出不同算法,但其适用性仍有许多可思考的地方:其一,大多算法未考量高阶网络结构信息,但现实网络中多数节点存在较少连接,如何通过有限信息挖掘这些弱连接节点间的关系需进一步深究;其二,现有研究假设节点文本信息与网络结构信息之间存在联系且二者的融合可提高算法性能,有些情况下确有较高预测精度,但计算复杂度过高。但某些情况下节点文本信息的嵌入反而会降低算法精确度,故对二者融合机制及特征互补性的探究可能会对算法性能提升有显著作用;其三,网络是动态变化的,但现有算法主要针对静态网络拓扑结构信息,或将动态网络划分为不同时间片,在每个时间片上仍使用静态网络表示方法,虽有一定改进,但缺乏对其动态特征本质挖掘,如何捕捉网络后续应用场景仍是重要挑战;其四,网络中往往不仅存在一种类型节点,如何将网络表示学习方法应用到异质网络中也是未来需进一步改进的地方。
2.5 基于机器学习的合作机会识别方法
与机器学习相关的合作机会识别研究主要利用机器学习中的集成学习算法,通过将多种不同链路预测指标、节点属性特征、网络表示向量等融合在一起,能够有效解决单一算法适用性较差这一局限,进一步提高合作机会识别的推荐准确度[24]。具体做法为:首先,将基于节点属性特征、链路预测等方法得到的两个节点之间相似度分值作为该节点对的一个或多个拓扑结构属性特征,再加上节点的度、聚类系数、最短路径等结构特征,共同构成该节点对的输入特征向量,输出特征为节点间是否存在连接,以0、1表征;其次,采用不同的机器学习方法对模型输入、输出特征进行训练学习;最后,遴选性能最优模型并将其应用于尚未产生关联的节点间潜在合作机会识别。如张金柱等采用逻辑回归分类模型学习不同路径权重对于潜在合作关系识别的贡献;谢奕希等以CN、RA、AA、PA指标为基础,提出基于改进逻辑回归模型的链路预测指标融合方法,结果表明融合算法精度高于所有基准指标[56];Guns等采用随机森林算法综合基于节点相似性的链路预测指标,以识别潜在国家合作关系[12,57];Behrouzi等将Jaccard、RA等链路预测指标与聚类系数、特征向量中心度等网络指标共同作为节点间是否存在连接的特征向量,综合采用随机森林、朴素贝叶斯等五种机器学习算法比较识别结果精确度,结果表明机器学习算法均显示出比单一指标更好的性能[58]。通过对已有研究的梳理总结,潜在合作机会识别研究中常用的机器学习算法包括人工神经网络(ANNs)、决策树(DTs)、随机森林(RF)、支持向量机(SVMs)、k近邻算法(KNN)、高斯朴素贝叶斯(GNB)、多项式朴素贝叶斯(MNB)、逻辑回归(LR)等,但并没有研究明确表明何种算法在合作机会识别研究中性能最优,需综合考量具体应用场景具体判别。
因每种单一方法均不能适应所有网络结构特征,故基于机器学习算法集成外部属性特征、链路预测等算法优缺点挖掘潜在合作机会是当下和未来研究的重点方向之一,但机器学习算法种类繁多,如何在众多指标中选择能有效捕捉网络拓扑结构的指标并将其集成新的分析指标是该方法的难点,因此也要求研究者对具体应用场景网络结构进行剖析,以选择最能合理表达网络结构的集成算法。
3 总结与展望
在对潜在合作机会识别概念厘定的基础上,从宏观、中观、微观等层面对研究主体类型进行划分和梳理,再从不同方法的内涵、原理等视角对潜在合作机会识别方法进行系统归纳总结。未来需要从以下方面进一步展开深入研究:
3.1 明晰不同识别方法的适用性
不同方法均有其优势和局限性,如外部属性特征能反映节点真实信息,但获取难度较大且多为非结构化文本信息;研究内容相似度一般以关键词共现网络来表征,未能融合作者、机构等多种异质信息;链路预测方法指标众多,但单一指标只能捕捉网络拓扑结构中的某些信息,且某些指标计算复杂度过高,推广应用价值低;网络表示学习方法虽有效弥补了传统方法高计算复杂度、低并行速度等缺陷,但其原理类似黑箱,可解释性差;比较而言,机器学习方法的机制为集成学习,可整合上述各方法的优点,但集成算法种类繁多,具体选用何种机器学习算法也需深究。综上,已有方法众多,但不可能在实际研究中穷尽所有方法,因此需根据具体应用场景、研究目的、以及对算法复杂度、时间复杂度、算法准确率的要求等选择有针对性的识别方法。
3.2 优化多维识别方法的可扩展性、有效性
首先,已有方法不论是挖掘网络中实际存在,而尚未监测到的连接,还是目前不存在,但未来有很大概率存在的连接,均是对网络中已有节点潜在关系的挖掘。网络是动态变化的,不断有新的节点加入,或旧的节点退出,若将研究对象圈定在不同时间窗口内共有节点范围内,只能预测未连接节点间产生连边的概率,并不能捕捉连接到新增节点的概率。因此开发考量节点动态演化趋势方法是未来的新课题;其次,已有方法往往不能适用网络中大规模节点数目,因此学者通常筛选高被引作者或TOP机构等为研究对象,然而发表文献较少的作者或机构可能更希望得到合作推荐,进而找到潜在合作对象,以提高其学术影响力,故优化已有方法使其可作用于网络中低频节点或边缘节点是未来研究的方向之一;最后,在方法的有效性方面,除了链路预测和机器学习方法将数据集划分为训练集和测试集,从量化角度评估方法的精确度,其余方法更多倾向领域专家定性分析结果的有效性,但随着定量方法挖掘出的潜在合作关系越来越多,人工解读费时费力,可操作性低,因此借鉴定量评估方法首先筛选高价值关系,再辅之专家知识是未来需进一步完善的方法流程。
3.3 扩展合作主体对象的多样性
研究对象方面,科研人员被视为合作的主体,且与其它研究主体相比,由个体组成的科研合作网络节点数目多,更符合已有识别方法对网络结构的要求,因此潜在合作机会识别研究中更多聚焦于挖掘科研人员潜在合作对象,即该方面研究最多,最为成熟。但国家、机构等多层面、多形式的科研合作关系识别从不同维度刻画了合作的形式,同样是合作研究中的重要组成部分。因此,未来可迁移并调整已有识别方法使其助力于国家、机构等研究主体深層合作发展。数据来源方面,现有研究主要以论文数据为载体,部分研究通过专利数据分析技术融合模式。不同数据源具有不同的数据特色,如国家级基金项目在一定程度上更能体现学科领域的最高水平,也较论文数据更能预先捕捉领域发展态势。因此,未来可针对同一研究对象挖掘不同数据源潜在合作机会识别结果的异同,进而分析差异背后的原因,更好辅助于合作推荐。
3.4 挖掘潜在合作机会的动机
以往研究大多将重心聚焦于提高预测方法的准确率、增加节点类型的异质性等方面,对潜在合作机会产生的动力学机制少有探讨,如为什么这些研究主体在未来有潜在合作倾向?这种潜在合作的稳定性、影响力会怎样演变?一方面网络拓扑结构会影响网络演化趋势,另一方面政策干预、人员流动等外部因素也会导致合作倾向性发生转变,因此在识别出潜在合作关系的基础上需要进一步将识别结果与研究主体背景知识相结合,挖掘可解释的合作动因和合作模式,从而为机构或个人等更好开展合作提供有价值的参考意义。更进一步,研究主体潜在合作机会产生与否和政策干预、人员流动等因素之间的具体因果关系值得深究和探讨。因此,在定性分析合作机会产生的动因基础上采用因果推断方法从定量角度剖析二者具体的因果关系,即不仅要基于数据和方法得出结论,更要重视影响因素和结论之间的因果逻辑关系,只有经过严谨的因果分析,推荐的合作模式才更有说服力和影响力。
*本文系四川省科技計划项目“适应新科技革命趋势和规律的科技创新政策与四川科技创新治理机制研究”(项目编号:23RKX0302)研究成果之一。
参考文献:
[1] 张金柱,韩涛.数据规模对合著关系预测的影响研究[J].情报杂志,2016,35(9):80-85.
[2] 丁敬达,郭杰.融合内容相似度和路径相似性的潜在作者合作关系挖掘[J].情报理论与实践,2021,44(1):124-128,123.
[3] 黄璐,朱一鹤,张嶷.基于加权网络链路预测的新兴技术主题识别研究[J].情报学报,2019,38(4):335-341.
[4] Duan Y,Guan Q.Predicting Potential Knowledge Convergence of Solar Energy:Bibliometric Analysis Based on Link Prediction Model[J].Scientometrics,2021,126(5):3749-3773.
[5] 余传明,龚雨田,赵晓莉,等.基于多特征融合的金融领域科研合作推荐研究[J].数据分析与知识发现,2017,1(8):39-47.
[6] 李鲁莹.基于SSCI的卓越大学联盟社会科学领域合作机会发现研究[D].大连:大连理工大学,2019.
[7] 岳增慧,许海云,王倩飞.基于局部信息相似性的学科引证知识扩散动态链路预测研究[J].情报理论与实践,2020,43(2):84-91,99.
[8] Cho J H,Lee J,Sohn S Y.Predicting Future Technological Convergence Patterns Based on Machine Learning Using Link Prediction[J].Scientometrics,2021,126(7):1-17.
[9] Kwon O,An Y,Kim M,et al.Anticipating Technology-driven Industry Convergence: Evidence From Large-scale Patent Analysis[J].Technology Analysis & Strategic Management,2020,32(4):363-378.
[10] 唐影.基于图神经网络的链路预测的技术融合预见研究[D].西安:西安邮电大学,2020.
[11] Guan Q,An H,Gao X,et al.Estimating Potential Trade Links in the International Crude Oil Trade: A Link Prediction Approach[J].Energy,2016,102(102):406-415.
[12] Guns R,Rousseau R.Recommending Research Collaborations Using Link Prediction and Random Forest Classifiers[J].Scientometrics,2014,101(2):1461-1473.
[13] 林原,王凯巧,刘海峰,等.网络表示学习在学者科研合作预测中的应用研究[J].情报学报,2020,39(4):367-373.
[14] Liben Nowell D,Kleinberg J.The Link Prediction Problem for Social Networks[J].Journal of the American Society for Information Science and Technology,2007,58(7):1019-1031.
[15] Ahmed C,ElKorany A.Enhancing Link Prediction in Twitter Using Semantic User Attributes[A].Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining[C].2015:1155-1161.
[16] Abu-Salih B,Wongthongtham P,Chan K Y.Twitter Mining for Ontology-based Domain Discovery Incorporating Machine Learning[J].Journal of Knowledge Management,2018,22(5):949-981.
[17] 汪志兵,韩文民,孙竹梅,等.基于网络拓扑结构与节点属性特征融合的科研合作预测研究[J].情报理论与实践,2019,42(8):116-120,109.
[18] 林原,谢张,李鲁莹,等.卓越大学联盟国内外高校科研合作机会发现[J].情报杂志,2020,39(3):81-86,114.
[19] Morris S A,Yen G G.Crossmaps:Visualization of Overlapping Relationships in Collections of Journal Papers[J].Proceedings of the National Academy of Sciences,2004,101(Suppl 1):5291-5296.
[20] 刘志辉,张志强.作者关键词耦合分析方法及实证研究[J].情报学报,2010,29(2):268-275.
[21] 陈卫静,郑颖.基于作者关键词耦合的潜在合作关系挖掘[J].情报杂志,2013,32(5):127-131.
[22] 宋艳辉,武夷山.作者文献耦合分析与作者关键词耦合分析比较研究:Scientometrics实证分析[J].中国图书馆学报,2014,40(1):25-38.
[23] 吕琳媛.复杂网络链路预测[J].电子科技大学学报,2010,39(5):651-661.
[24] 吕伟民,王小梅,韩涛.结合链路预测和ET机器学习的科研合作推荐方法研究[J].数据分析与知识发现,2017,1(4):38-45.
[25] Lorrain F,White H C.Structural Equivalence of Individuals in Social Networks[J].The Journal of Mathematical Sociology,1971,1(1):49-80.
[26] Salton G,Mcgill M J.Introduction to Modern Information Retrieval[M].Auckland:MuGraw-Hill,1986.
[27] Jaccard P.tude Comparative De La Distribution Florale Dans Une Portion Des Alpes Et Des Jura[J].Bulletin of the Torrey Botanical Club,1901,37:547-579.
[28] Srensen T.A Method of Establishing Groups of Equal Amplitude in Plant Sociology Based on Similarity of Species Content and Its Application to Analyses of the Vegetation on Danish Commons[J].Biologiske Skrifter,1948,5(4):1-34.
[29] Ravasz E,Somera A L,Mongru D A,et al.Hierarchical Organization of Modularity in Metabolic Networks[J].Science,2002,297(5586):1551-1555.
[30] Zhou T,Lü L,Zhang Y C.Predicting Missing Links Via Local Information[J].The European Physical Journal B,2009,71(4):623-630.
[31] Leicht E A,Holme P,Newman M E J.Vertex Similarity in Networks[J].Physical Review E,2006,73(2):1-10.
[32] Adamic L A,Adar E.Friends and Neighbors on the Web[J].Social Networks,2003,25(3):211-230.
[33] Barabási A L,Albert R.Emergence of Scaling in Random Networks[J].Science,1999,286(5439):509-512.
[34] Valverde-Rebaza J C,Roche M,Poncelet P,et al.The Role of Location and Social Strength for Friendship Prediction in Location-based Social Networks[J].Information Processing & Management,2018,54(4):475-489.
[35] 高楊,张燕平,钱付兰,等.结合节点度和节点聚类系数的链路预测算法[J].小型微型计算机系统,2017,38(7):1436-1441.
[36] 陈嘉颖,于炯,杨兴耀,等.基于复杂网络节点重要性的链路预测算法[J].计算机应用,2016,36(12):3251-3255,3268.
[37] Lü L,Jin C H,Zhou T.Similarity Index Based on Local Paths for Link Prediction of Complex Networks[J].Physical Review E,2009,80(4):1-9.
[38] Katz L.A New Status Index Derived From Sociometric Analysis[J].Psychometrika,1953,18(1):39-43.
[39] 吕亚楠.基于网络结构和随机游走理论的链路预测算法研究[D].武汉:武汉理工大学,2019.
[40] Klein D J,Randi M.Resistance Distance[J].Journal of Mathematical Chemistry,1993,12(1):81-95.
[41] Fouss F,Pirotte A,Renders J M,et al.Random-Walk Computation of Similarities Between Nodes of a Graph with Application to Collaborative Recommendation[A].IEEE Transactions on Knowledge and Data Engineering[C].2007,19(3):355-369.
[42] Brin S,Page L.The Anatomy of a Large-scale Hypertextual Web Search Engine[J].Computer Networks and ISDN Systems,1998,30(1-7):107-117.
[43] Jeh G,Widom J.Simrank:A Measure of Structural-Context Similarity[A].Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].2002:538-543.
[44] Liu W,Lü L.Link Prediction Based on Local Random Walk[J].Europhysics Letters,2010,89(5):1-6.
[45] Kim H,Hong S,Kwon O,et al.Concentric Diversification Based on Technological Capabilities:Link Analysis of Products and Technologies[J].Technological Forecasting and Social Change,2017,118:246-257.
[46] 刘海峰.社交网络用户交互模型及行为偏好预测研究[D].北京:北京邮电大学,2014.
[47] 张金柱,胡一鸣.利用链路预测揭示合著网络演化机制[J].情报科学,2017,35(7):75-81.
[48] Perozzi B,Al-Rfou R,Skiena S.Deepwalk:Online Learning of Social Representations[A].Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data mining[C].ACM,2014:701-710.
[49] Tang J,Qu M,Wang M,et al.Line:Large-scale Information Network Embedding[A].Proceedings of the 24th International Conference on World Wide Web[C].2015:1067-1077.
[50] Cao S,Lu W,Xu Q.Grarep:Learning Graph Representations with Global Structural Information[A].Proceedings of the 24th ACM International on Conference on Information and Knowledge Management[C].ACM,2015:891-900.
[51] Grover A,Leskovec J.Node2vec:Scalable Feature Learning for Networks[A].Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].ACM,2016:855-864.
[52] Wang D,Cui P,Zhu W.Structural Deep Network Embedding[A].Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].ACM,2016:1225-1234.
[53] Yang C,Liu Z,Zhao D,et al.Network Representation Learning with Rich Text Information[A].Twenty-Fourth International Joint Conference on Artificial Intelligence[C].IJCAI,2015:2111-2117.
[54] Tu C,Zhang W,Liu Z,et al.Max-Margin Deepwalk:Discriminative Learning of Network Representation[A].Twenty-Fifth International Joint Conference on Artificial Intelligence[C].IJCAI,2016:3889-3895.
[55] Li J,Dani H,Hu X,et al.Attributed Network Embedding for Learning in a Dynamic Environment[A].Proceedings of the 2017 ACM on Conference on Information and Knowledge Management[C].ACM,2017:387-396.
[56] 謝奕希,陈鸿昶,黄瑞阳,等.一种基于改进Logistic模型的链路预测指标融合方法[J].信息工程大学学报,2017,18(6):703-707.
[57] Guns R,Wang L.Detecting the Emergence of New Scientific Collaboration Links in Africa:A Comparison of Expected and Realized Collaboration Intensities[J].Journal of Informetrics,2017,11(3):892-903.
[58] Behrouzi S,Sarmoor Z S,Hajsadeghi K,et al.Predicting Scientific Research Trends Based on Link Prediction in Keyword Networks[J].Journal of Informetrics,2020,14(4):1-16.
作者简介:张雪,女,西安电子科技大学经济与管理学院讲师,研究方向:学科信息学与领域知识发现、科学计量与科技评价;张志强,男,中国科学院成都文献情报中心研究员,中国科学院大学经济与管理学院信息资源管理系教授,博士生导师,研究方向:科技战略与规划、科技政策与管理、科学学、科学计量与科技评价等。
