基于Python爬虫技术的高校网络舆情数据分析研究
2023-06-22丁然

摘 要:高校论坛是学生发表意见和相互交流的一个网络平台,也是高校校园舆情的一个重要信息源头。高校百度贴吧是以在校生为主导群体的在线交流平台,贴吧内信息在一定程度上反映了学生的思想动态和舆论导向,文章以“安徽审计职业学院百度贴吧”为例,分析Python网络爬虫技术的实现原理,爬取贴吧内的文本数据,利用分词、词频统计、词云图制作等技术进行数据分析,提出舆情结论和研究展望,为校园相关部门舆情引导提供帮助和新的思路。
关键词:网络爬虫;Python;舆情
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2023)05-0106-04
Analysis and Research of University Network Public Opinion Data Based on Python Crawler Technology
—Taking“Baidu Post Bar of Anhui Audit College”as an Example
DING Ran
(Anhui Audit College, Hefei 230601, China)
Abstract: University forum is a network platform for students to express their opinions and communicate with each other, which is also an important information source on campus public opinion. Baidu Post Bar in colleges and universities is an online communication platform dominated by internal students. The information in the post bar reflects the ideological dynamics and public opinion orientation of students to a certain extent. This paper takes “Baidu Post Bar in Anhui Audit College” as an example, analyzes the implementation principle of Python Web crawler technology, and climbs the text data in the post bar. It uses word segmentation, word frequency statistics, word cloud image production and other technologies to analyze the data, puts forward public opinion conclusions and research prospects, and provides help and new ideas for the guidance of public opinion of relevant departments on campus.
Keywords: Web crawler; Python; public opinion
0 引 言
随着互联网以及以社交为基础的互联网应用不断迅猛发展,其背后带来的是数据的爆炸式增长[1]。其中,数据量指数级增长,数据结构日趋复杂,数据源涉及各行各业。对于高校而言,网络的普及一方面丰富了学校的教育教学方法,提升了管理者的教育管理水平;另一方面也让网络技术融入了高校大学生的学生和生活中,为其带来便利。
高校大学生是一个思想十分活跃的群体,他们倾向于将自己所见所感在网络上发布,诸如百度贴吧、微博、抖音、微信公众号、微信朋友圈等网络平台。这些网络平台支持的转发、评论、分享等便捷功能,促使并加快了网络数据的增长。在这些网络平台上,有学生发布的大量的信息资源,内容包罗万象、丰富多彩,在一定程度上代表了高校大学生的思想和行为。然而,面对复杂的网络环境、大数据的信息浪潮,大学生在信息甄别能力上还比较薄弱,在强有力的信息冲击下容易迷失自我。最初个人发布的意见,随着意见的扩散和讨论的逐步深入,各种观点的交流与碰撞,就可能转化为大多数人的集体意识,讨论的主题逐渐趋向于特定的焦点,最终形成具有一定规模及明确指向的校園网络舆情,从而对和谐校园的建设产生一定的影响[2]。
1 数据来源
本文以“安徽审计职业学院百度贴吧”为例,对校园贴吧网络舆情数据进行分析研究,掌握校园贴吧网络舆情的现状及发展趋势,进而加强舆情引导,为在校大学生的健康成长提供一个更加良好的网络氛围,促进校园网络建设健康发展。安徽审计职业学院在校大学生人数达7 000余人,校园内学生公寓、普通教室、实训机房、图书馆等学生学习生活场所均已连接互联网,校园内无线网络实现全覆盖,在校生上网条件便利,对于社会发生的热点话题,在校学生可以通过校园百度贴吧网络平台方便迅速地发布意见、表达观点。打开百度官网,进入百度贴吧,搜索“安徽审计职业学院”点击进入贴吧,这时进入“安徽审计学院吧”百度贴吧网页,网页导航栏目主要包括“看帖”“图片”“吧主推荐”“视频”四部分内容,其中“看贴”内容最为丰富,截至2022年3月,共有帖子数90多万。本文通过Python爬虫技术爬取2021年12月17日至2022年3月17日时间段内的发帖内容,具体包括发帖的标题、回复内容、作者名称、发布时间等;再将发帖内容数据存储为Excel表格文件,作为数据源;最后通过Python数据分析技术进行分析。
2 相关理论及技术实现
2.1 网络爬虫理论
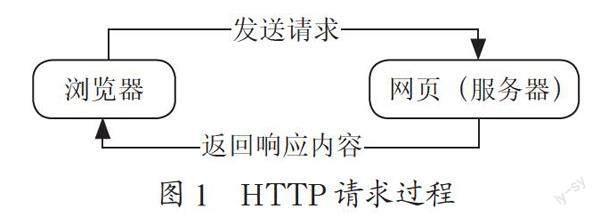
互联网上所有的资源都是通过URL(统一资源定位符,通常所说的网址)作为相关描述放置在服务器上的,网址的访问是通过HTTP协议实现,HTTP协议是超文本传输协议,是一个基于“请求与响应”模式的、无状态的应用层协议[3]。访问网址的基本流程如图1所示。
互联网上大量的资源节点连接在一起,很像一张大大的“蜘蛛网”,网络爬虫就像蜘蛛一样,在网上沿着URL丝线爬行。网络爬虫就是利用软件工具模拟浏览器访问URL,并下载每一个URL对应的网页内容,完成网页数据的收集整理与分析的过程。
网络爬虫需要注意合法性问题,网站上涉及的个人隐私数据是不允许爬取的,更不能将爬取的数据用于商业用途或违反法律规定。在爬取一个网站的数据时,合法性需要遵守。本文爬蟲数据仅用于科学项目研究,主要针对本校大学生在校园贴吧上发布的内容进行舆情分析,未涉及商业用途,也未涉及个人隐私等受法律保护的信息。
2.2 Python技术及应用
Python起源于20世纪90年代,其创始人为荷兰人吉多·范罗苏姆,开始仅是为继承ABC语言而开发的一种新的脚本程序,但时至今日,其以“优雅”“明确”“简单”的优点在业界广受欢迎,已经成为最受欢迎的程序设计语言之一,在IEEE Spectrum 2019-2021编程语言排行榜上,Python连续3年蝉联榜首。Python在网络爬虫方面功能十分强大,它能够模拟浏览器登录、有针对性地爬取网页数据,特别是Python拥有形形色色的爬虫相关库,为网页文档的爬取和处理提供强有力的支持。
在本案例中,硬件环境搭配了高性能的个人计算机,配置标准为:Win 10系统(64位,基于x64的处理器操作系统),8 GB运行内存,Intel Core i7处理器,500 GB硬盘。Python环境配置选择安装Python集成软件Anaconda 3,使用pip install requests(其他re、lxml、pandas、selenium、jieba等库的安装方法相同)命令行安装第三方爬虫库。在爬虫前需要先分析贴吧URL组成,安徽审计职业学院百度贴吧URL为“https://tieba.baidu.com/f?kw=安徽审计学院&ie=utf-8&pn=0”,其中“https://tieba.baidu.com/f?”是每一页的URL固定的开头,“kw=安徽审计学院”为关键字贴吧名称,“ie=utf-8”表示浏览器编码,最后pn=0代表页数,pn=0是第1页,pn=50是第2页,pn=100是第3页,以此类推。分析出URL的组成规律,能够通过遍历的方法爬取贴吧每一页的内容。
在向贴吧URL发送HTTP请求时,需要模拟浏览器进行访问,可以采取发送模拟User-Agent来通过检验,设置请求头代码如下:
header={‘User-Agent:‘Mozilla/5.0Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36}
成功发生请求后,会获取响应,返回网页源代码,由于源网页编码方式为utf-8,与程序处理的编码一致,正常不会出现乱码,如果返回内容出现乱码,需要设置指定的utf-8编码。通过xpath、BeautifulSoup对响应的网页内容进行解析网页,提取出贴吧标题、内容、作者名称等信息;利用pandas库的DataFrame功能进行数据转换;Selenium库模拟浏览器操作实现翻页,数据存储利用xlrd库与xlwt库实现。主要流程如图2所示。
流程中各个功能通过自定义函数进行封装,最后调用各函数实现贴吧数据的爬取。Python在爬取网页数据方面简单轻巧,在数据的处理与可视化分析上也游刃有余,贴吧关键信息分析可以采取分词、统计词频、生成词云图方法,主要利用导入的jieba分词库、wordclound词云库、matplotlib绘图库等第三方库功能实现。
3 校园百度贴吧舆情数据分析
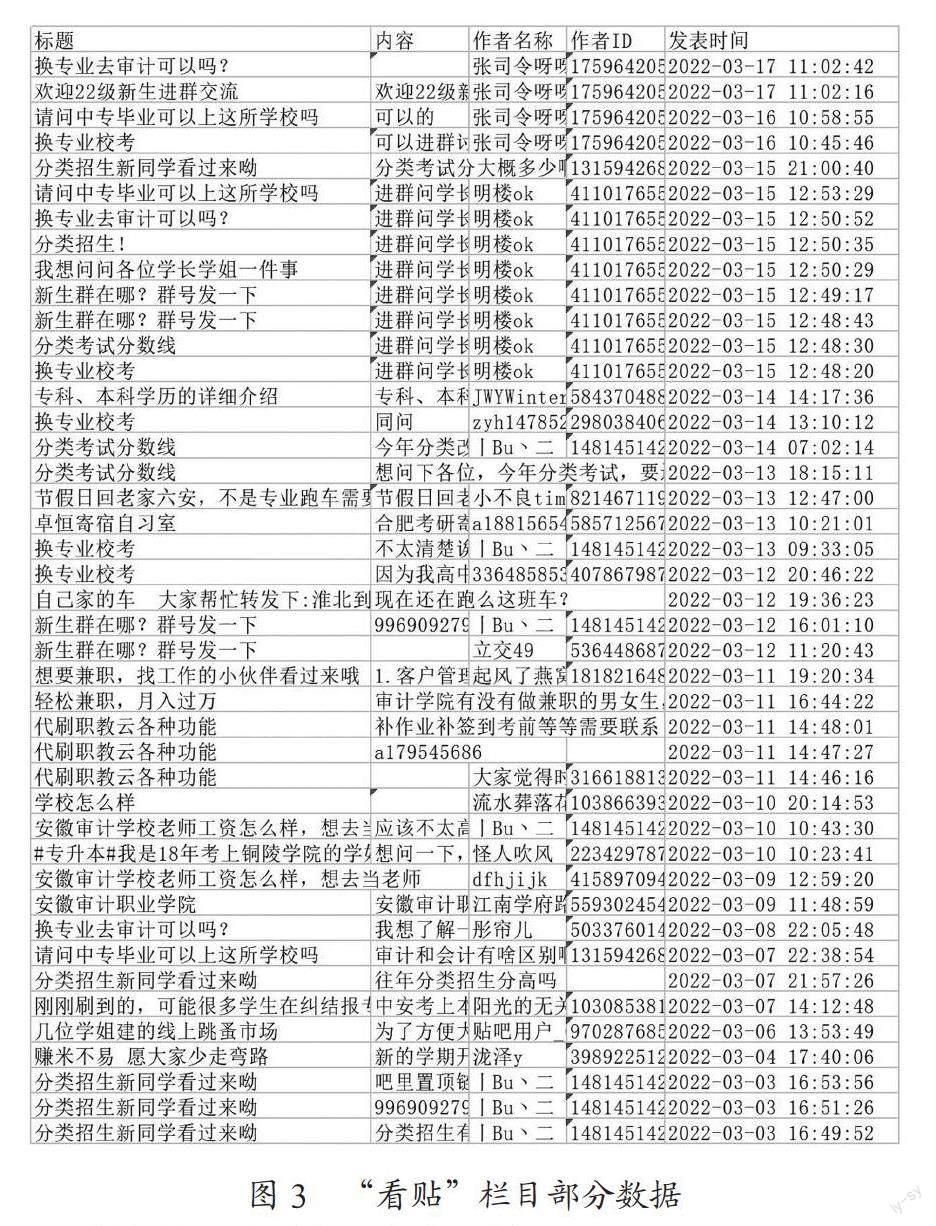
通过对2021年12月17日至2022年3月17日时间段贴吧“看贴”栏目数据进行爬取,数据存储为文件名为data.xlsx的Excel文件,部分数据如图3所示。
通过对“标题”列数据、“内容”列数据分别做词频统计,分别对其文本进行分词,生成可视化词云图。以“标题”列为例,使用pandas读取项目根目录下源数据,再用jieba库对“标题”列数据进行分词。由于文本数据中可能存在一类没有实际意义的词,比如组词“的”,连词“以及”,副词“甚至”,语气词“吧”等被称为“停用词”的无用词,在做分词处理时需要将其过滤掉,因此分词前需要做去除“停用词”操作。“停用词”的去除是一个不断修正的过程,如果一些无用词未在“停用词”词典(根据哈工大停用词表、百度停用词表等目前常用的中文停用词表综合整理得到stoplist.txt)里,需要累加进去。分词操作代码具体如下:
import pandas as pd
import re
import jieba
data = pd.read_excel('./data.xlsx')
data_cut1 = data['标题'].apply(jieba.lcut)
with open('./stoplist.txt','r',encoding = 'utf8') as f:
stop = f.read()
stop = stop.split()
stop = [',',' ']+ stop # 用于多余停用词的删除,如空格,逗号
data_1 = data_cut1.apply(lambda x:[i for i in x if i not in stop])
去除停用词后,对分词的结果做词频统计,代码具体如下:
from tkinter import _flatten
num1 = pd.Series(_flatten(list(data_1))).value_counts()
词云图生成代码具体如下:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
mywc=WordCloud(font_path='C:/Windows/Fonts/STKAITI.TTF',background_color='white')
mywc2 = mywc.fit_words(num1)
plt.imshow(mywc2)
plt.axis('off')
plt.show
生成的詞云图如图4所示。
同理,参照“标题”列数据代码,操作生成“内容”列数据词频统计表和词云图,分别如表2和图5所示。
词云图过滤掉大量的文本信息,对文本中出现频率较高的关键词突出显示,不同的关键词采用不同的颜色和字体大小,通过形成关键词渲染,使浏览者只要一眼扫过就可以领略文本的主旨[4]。由词频统计表和词云图可以看出,在监测周期内,“审计”“安徽”“学校”“学院”等词提及频率最高,是论坛发帖者和参与者关注度较高的话题,这些话题均与学校息息相关;“专业”“专升本”“工作”“兼职”等词提及频率较高,均与学习、升学、求职等日常话题相关。学校学工管理者可以据此了解到学生日常关心的话题是什么,例如,从“兼职”“工作”词频反馈学生关注就业求职方面的话题,“专升本”词频可能反馈出学生对专升本升学有过多讨论,“交流”“微信”“学姐”“学长”词频反馈学生有关交友需求方面的信息等。这些都从侧面反映了学生的舆论倾向。高校校园网络舆情是一种议论,但并不是所有的议论都具有网络舆情的“规格”的,议论借助网络虚拟空间[5]。只有这种议论达到一定规模,并且产生一定影响,才能形成校园网络舆情热点事件。
4 结 论
总体来看,在监测周期内,“安徽审计学院百度贴吧”网络舆情比较稳定,舆情信息贴切学生生活,学生关注的多半是校园、学习、升学、求职等日常校园话题,未出现大规模传播的负面网络舆情事件。一方面可能是学校网络舆情监控比较及时,能够及时监测到贴吧里的不良舆论导向信息,将处于萌芽状态的矛盾及时化解掉,保障了校园网络稳定;另一方面可能是学校扎实推进“三全育人”工作带来的效果延伸,近年来,安徽审计职业学院不断加强在校生网络安全教育、大学生心理健康教育,课程思政教育,有效实现课程思政与学科教学同向同行,这些举措无形中提升了在校学生的思想道德意识,进而规范了网络行为。
只有通过对大规模的样本实验数据分析研究,才有可能客观反映校园网络舆情的实际情况。“安徽审计职业学院百度贴吧”数据并不能代表安徽审计职业学院网络舆情的全部,更不能概括为整个高校校园网络舆情,本文的实验数据是监测周期为3个月之内的贴吧数据,实验数据有限,只是简单探索了Python技术在高校校园百度贴吧数据分析中的简单应用。今后,笔者将持续研究基于爬虫技术的校园百度贴吧舆情数据分析,关注爬虫技术在微博、微信公众号、微信朋友圈等平台的舆情分析应用,结合大数据爬虫技术,进行大规模实验数据的爬取与分析研究,尝试设计基于爬虫技术的校园网络舆情系统。
参考文献:
[1] 席岩,张乃光,王磊,等.基于大数据的用户画像方法研究综述 [J].广播电视信息,2017(10):37-41.
[2] 罗晶.校园舆情分析中的意见挖掘技术研究 [D].南京:东南大学,2015.
[3] 祝瑞,车敏.基于HTTP协议的服务器程序分析 [J].现代电子技术,2012,35(4):117-119+122.
[4] 周毅,宁亮,王鸥,等.基于Python的网络爬虫和反爬虫技术研究 [J].现代信息科技,2021,5(21):149-151.
[5] 胡江春.网络舆情(2007年11月16日—12月15日) [J].中国改革,2008(1):7.
作者简介:丁然(1985.05—),男,汉族,安徽舒城人,讲师,硕士研究生,研究方向:计算机应用、大数据技术。
收稿日期:2022-10-26
基金项目:安徽审计职业学院2020年度院级自然重点科研项目(SJKJ2020A001)
