Transformer优化及其在苹果病虫命名实体识别中的应用
2023-06-20聂炎明黄铝文
蒲 攀 张 越 刘 勇 聂炎明 黄铝文,2
(1.西北农林科技大学信息工程学院, 陕西杨凌 712100; 2.农业农村部农业物联网重点实验室, 陕西杨凌 712100)
0 引言
我国是世界第一大苹果生产国[1],果业病虫害问题对我国苹果产业影响显著,进而直接关系到国家和从业者的经济收益提升。基于知识图谱的问答系统通过对实体间关系描述能够帮助苹果种植人员快速准确获得病虫管理专业知识,命名实体识别作为一种智能化实体抽取方法,是构建高质量苹果知识图谱的关键环节。因此,如何准确识别出苹果病虫领域相关实体对于苹果种植信息化发展具有重要作用。
近年来,命名实体识别技术被广泛应用在农业[2]、医学[3]等领域,文献[4]通过融合ALBERT与规则,针对小麦病虫害16类实体进行识别,其F1值达到94.97%;文献[5]提出基于多核的卷积神经网络,对水产医学领域动物名称、发病部位、病原体等6项实体进行识别,其F1值达到88.48%。虽然已开展了丰富的相关研究工作,然而在现有的农业命名实体识别的研究中仍存在以下问题:对没有明显边界特征的词汇识别率较低,如文献[6-7]中对于病原的识别F1值仅为88%和81.48%;现有研究中常用BiLSTM来捕捉文本长距离依赖信息,但当文本距离过长时,其获取长距离依赖信息的能力会有所下降;对苹果病虫害实体识别方面的研究较少,同时缺乏公开权威的数据集,文献[8]构建了苹果病虫相关的ApdCNER语料库,提出将字典和相似词汇合并到基于字符的模型中,解决实体类别分布不均、别名和稀有实体识别困难的问题,其F1值尽管达到92.14%,但是该方法需要依靠专家手动构建领域字典,容易对一些实体产生遗漏。此外,不同的人对一些相同实体可能也存在不一样的认识标准,进而字典构建的质量将直接影响模型的识别性能。
Transformer可以实现并行化计算,同时处理长序列样本,常用于自然语言处理中的机器翻译[9]、文本生成[10]等领域。但是由于文本信息中不同位置的语义信息差别,其内部的绝对位置编码不能很好地表征位置信息,进而对中文语义信息的提取造成了困难。国内外学者对Transformer的文本性能优化做出了一系列改进。在较长序列建模方面,文献[11]引入段级递归,将绝对位置编码改为相对位置编码,提出了Transfortmer-XL模型。为降低文本分类复杂性,文献[12]使用星型拓扑代替全连通的注意力连接,提出了Star Transformer模型。在命名实体识别领域,文献[13]通过改进的相对位置编码,使用非缩放的点乘注意力,提出TENER模型。
为提高苹果生产领域实体识别的准确性,本文基于以上研究,通过融合文本的位置特征与语义特征,实现一种新的Transformer优化模型。该模型通过结合字向量与词向量以丰富语义信息,平均集成BiLSTM和Transformer,并引入具有方向和距离感知的注意力机制,结合文本上下文依赖特征和位置特征,最后通过条件随机场(Conditional random fields, CRF)得到最优预测序列。
1 材料与方法
1.1 数据来源与标注
实验数据来源于中国农化招商网(http:∥www.1988.tv/bch/list-4.html)爬取的农业知识,在西北农林科技大学国家级苹果试验示范站的植保和栽培专家团队指导和协助下,人工对所爬取数据进行去空格、空行及特殊符号处理,去除重复数据和无效数据。综合《中国苹果病害病原菌物名录》电子版数据,建立苹果病虫知识数据集,其中包含3 928个病虫相关实体。
本文采用“BIO”的标注方式进行实体标注,其中,B标注实体名称的开始,I标注实体名称的内部信息,O标注语料中的非实体部分。实体名称共包括DIS、PES、NAM、PAR、MED、CAU共6种,DIS表示苹果病害名称,PES表示苹果虫害名称,NAM表示苹果病虫害的别称,PAR表示为害部位名称,MED表示防治药剂名称,CAU表示病原名称。将B、I、O三元组与实体名称进行结合,形成标签,可得B-DIS、B-PES、B-NAM、B-PAR、B-MED、B-CAU、I-DIS、I-PES、I-NAM、I-PAR、I-MED、I-CAU、O共计13种实体标签,并以8∶1∶1将数据集分为训练集、测试集和验证集,数据集划分如表1所示。苹果树腐烂病是我国西北地区苹果树常发病害,以苹果树腐烂病为例,依据此标签进行数据标注,标注示例如图1所示。
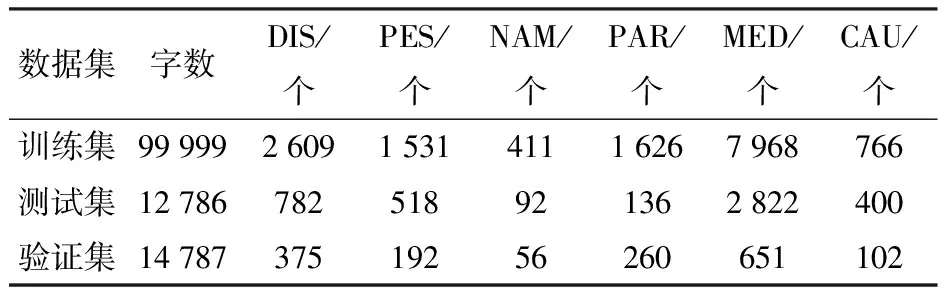
表1 苹果知识数据集Tab.1 Dataset of apple knowledge
1.2 特征分析
与通用语料相比,苹果病虫领域内的实体名称在结构和专业性等方面有明显自身特点,具体体现为以下4方面:
(1)构成成分多。苹果病虫领域的实体命名除了单纯的文字外,还常由数字、特殊符号等多种符号构成,如药剂名称“苏脲1号”、“多菌灵·异菌脲悬浮剂”等。
(2)生僻字较多。在药剂实体和病原实体中常出现生僻字,如药剂“噻霉酮”,病原“河口槭胶锈菌”,从而造成模型在识别上的困难。
(3)嵌套实体较常见。在药剂名称中常出现由多个子实体构成的实体,如“阿维菌素·哒螨灵乳油”易被拆分为“阿维菌素”“哒螨灵”“乳油”,容易干扰模型判断。
(4)一词多义现象较多存在。与其他农业作物病虫害实体不同的是,在中文文本中,“苹果”具有水果名称和商品品牌(手机、服装)多种含义,在苹果病虫领域,“苹果”一词出现在不同位置,代表着不同标签。如“苹果”在“苹果褐斑病”中的正确标签为“B-DIS I-DIS”,在病原实体“苹果星壳孢”中的正确标签应为“B-CAU I-CAU”,但其单独出现时又不是病虫相关实体,其具体标签由上下文语义共同决定,这给模型提取上下文关系带来难度。
2 模型框架
本文所提模型的整体结构包含嵌入层、Transformer层、BiLSTM层、特征融合层和CRF层5部分,其基本构成如图2所示。其中,x1、x2、x3、x4、x5、x6为嵌入层输出;LSTM为长短时记忆网络;BiLSTM为双向长短时记忆网络;Multi-Head Attention为多头注意力机制;Add&Norm为残差和标准化;Feed Forward为前馈神经网络;CRF为条件随机场。

图2 模型结构Fig.2 Model structure
2.1 嵌入层
由于中文分词存在错误拆分的现象[7],如病害名称“斑点落叶病”的分词结果为“斑点/落叶/病”,虫害实体“金纹细蛾”的分词结果为“金/纹/细/蛾”,这些实体的错误拆分会导致模型不能正确获取实体特征[14]。虽有研究表明,在嵌入层中基于字符的模型比基于单词的模型性能要好[15],但在中文里单个字符可表达的语义有限,而通过使用预先训练的词嵌入作为特征可进行改进。本文使用Lattice LSTM[16]模型提供的预训练向量集,同时采用基于字向量与词向量拼接的嵌入方式来增强文本的语义信息。
2.2 Transformer层
在中文命名实体识别任务中,文本的位置与语义密切相关。已有的多数研究更偏重文本的语义特征、偏旁特征或拼音特征,而忽略了文本的位置特征。而传统的Transformer模型在嵌入层引入了绝对位置编码,其计算方式为
Pt,2i=sin(t/10 0002i/d)
(1)
Pt,2i+1=cos(t/10 0002i/d)
(2)
式中t——文本位置
i——维度位置索引
Pt,2i——第t个token在偶数维度的位置编码
Pt,2i+1——第t个token在奇数维度的位置编码
d——输入维度
在传统的Transformer注意力计算方法中,序列中第t个字和第j个字的注意力分数计算公式为
(3)
式中WQ、WK、WV——输入字符的查询向量Q、键向量K、值向量V的权重参数矩阵
X——字嵌入向量
P——位置编码
j——token的索引
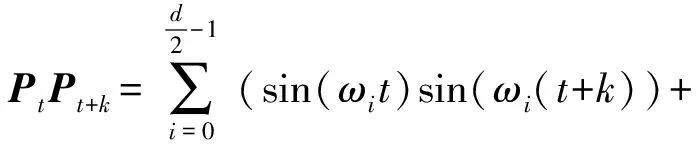
(4)
由三角函数的性质cos(x)=cos(-x)可知,传统计算方式所得出的相对位置信息仅有两个token之间的距离关系,而对于两个token的位置无法判断,例如在“苹果”与“果苹”中,两个字相对位置虽不同,但其位置编码乘积相同,同时这样的位置信息在经过查询向量和键向量的映射后会消失。
为了充分利用中文文本的位置特征,本文改进使用
(Q,K,V)=(HWQ,HWK,HWV)
(5)
(6)
(7)
A(Q,K,V)=softmax(S)V
(8)
式中H——嵌入层输出
u、v——可学习的参数
Rt-j——相对位置编码
St,j——第t、j个token之间相似度得分
Qt,Kj——第t、j个token的查询向量和键向量
A——注意力得分
来计算整体注意力分数,通过式(6)计算位置编码,利用三角函数的性质,通过正弦函数捕捉方向性,余弦函数捕捉字符的绝对位置关系,从而解决传统Transformer模型相对位置信息易丢失的问题。通过式(7)计算输入序列中每个单词之间的相关性得分,式(8)对于输入序列中每个单词之间的相关性得分进行了归一化,使每个字与其他字的注意力权重之和为1。
通过计算每个字与其他字的相关性,即可获得全局特征表示。当实体中的生僻字缺失语义信息时,根据其与前后文本的位置关系,依然可以依据其他文本而获取到。如病原实体中常以“菌”、“壳”、“孢”等字结尾,在实体“河口槭胶锈菌”中,“槭”为生僻字,但由于其后面的“菌”通常是病原中最后一字,且仅相隔两个字,根据其位置信息也可确定其为病原实体的一部分。
2.3 BiLSTM层
通过分析苹果病虫数据集发现,在长句子中常会出现多类实体,且实体长度不一,为害部位大多常以两个字符出现,而部分药剂名称则多达9个字符,如“代森锰锌可湿性粉剂”。使用LSTM[17]不仅可以处理长序列问题,同时解决了RNN在训练时所产生的梯度爆炸或梯度消失现象[18-19],而且能够有效利用上一时刻特征来判断下一时刻特征,因此本文使用LSTM网络实现对局部语义特征的提取。
在命名实体识别任务中,句子的前向信息和后向信息都很关键,而普通LSTM只能捕获前向信息[20]。如病害实体“斑点落叶病”,LSTM提取到“叶”字时需提取到之前的“斑点落”几个字的特征,而无法考虑到与后面“病”字的关系。针对上述问题,本文选择双向LSTM(BiLSTM)[21]结构实现对句子级别的特征提取,以更好地解决苹果领域中一词多义的问题。
2.4 特征融合层
在命名实体识别研究中,许多研究者采用基于CNN、基于LSTM和基于Transformer等方法作为上下文编码器,但是采用单一的编码器通常也会引起特征提取不充分问题。LSTM模型虽然能够在序列信息建模方面凸显优势,却存在冗余信息;Transformer能够关注重点词汇特征和加速训练速度,但存在上下文信息建模不足的缺陷。基于上述情况,本研究使用平均融合法实现对特征的融合,以降低模型陷入局部极小点的可能,进而达到提高识别率的目的。本文设计平均法、投票法、拼接法3种方案,其对应的计算公式分别为
(9)
(10)
H(x)=h(x)⊕f(x)
(11)
式中h(x)、f(x)——Transformer、BiLSTM的输出
N——模型个数
wj——第j个模型的权重
pi,j,k——第j个模型对样本i的预测结果为类别k的概率
2.5 CRF层
BiLSTM与Transformer虽然适合处理长距离的文本信息,但都忽略了标签之间的依赖关系[22],而在命名实体识别任务中,如果不考虑字符标签与相邻标签的相关性则极可能会给出错误标签。CRF[23]能通过训练数据学习到标签之间的约束性[4-5],并通过这种约束性获得一个最优的预测序列,具体约束性主要有以下两点:①句子中的第一个字的标签只能是“B-”或者“O”,不能是“I-”。②语句中的标签“B-label I-label I-label”,“label”应该是相同的命名实体标签,如“褐斑病”的标签应为“B-DIS I-DIS I-DIS”,而在苹果病虫数据集中,当“苹果”后为病害实体时,通常当作一个整体,如“苹果褐斑病”的标签为“B-DIS I-DIS I-DIS I-DIS I-DIS”;“苹果”后为病原实体时,如“苹果链核盘菌”,其标签应为“B-CAU I-CAU I-CAU I-CAU I-CAU I-CAU”。
3 实验与分析
3.1 实验环境搭建和模型参数设置
实验运行系统为Ubuntu 18.04,显卡型号NVIDIA GeForce RTX 3080 Ti,编程语言使用Python 3.7版本,采用Pytorch 1.7.1深度框架完成模型构建和训练评估。在实验过程中,所使用的模型参数,是通过前期的实验参数优化调整所得的最优参数组合:即迭代次数为35,学习率0.000 6,多头注意力数量为4,每个头维度为48,批量大小4,随机失活率0.45。由参数优化实验发现,学习率过大,会造成网络不能收敛,而学习率过小容易陷入局部最优解,进而造成识别效果变差;批量大小设置过小会不利于收敛,过大容易陷入局部最小值;为防止模型过拟合,本文添加了随机失活率来减少神经元之间的复杂关系,以增强模型鲁棒性。本文使用的优化实验参数如表2所示。对实体抽取模型结果和各项性能进行定量分析,所采用的评价指标为精确率、召回率、F1值[24]。

表2 BIO标注的实验参数Tab.2 Experimental parameters of BIO
3.2 实验结果与分析
3.2.1不同模型实验结果对比
为了对比所提方法的识别效果,本文基于相同数据集,选取命名实体识别领域的3种传统常用模型BiLSTM-CRF、Transformer-CRF和TENER模型分别进行了性能对比实验。各个模型的性能结果如表3所示。
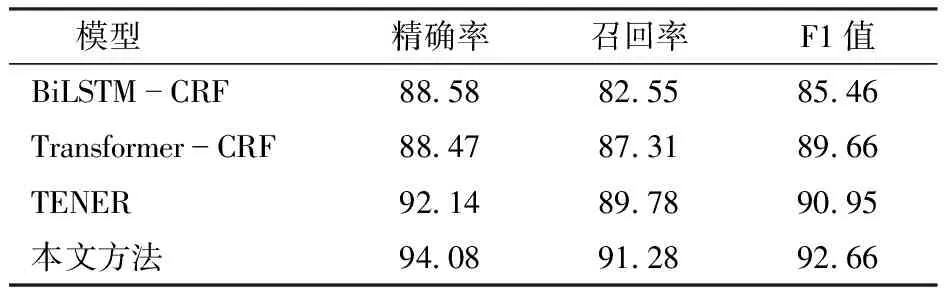
表3 不同模型对比实验结果Tab.3 Comparative experimental results of different models %
从表3可以看出,使用BiLSTM对序列提取特征,F1值仅为85.46%,其可能原因是当文本序列长度过长时BiLSTM对上下文特征的提取能力会下降;而在传统的Transformer模型中,其位置编码信息没有得到充分利用,较于BiLSTM模型其仅在召回率和F1值上有所提高;TENER通过改进位置编码函数,采用非缩放点积的注意力机制,与Transformer相比精确率、召回率和F1值分别提高3.67、2.47、1.29个百分点。本文提出的模型利用了TENER的优势,使用了具有方向和距离感知的注意力机制,充分结合了文本的位置特征,同时通过引入BiLSTM增强了上下文语义特征,使模型对上下文相关性的提取能力有所提高,其精确率、召回率和F1值分别达到94.08%、91.28%和92.66%,在所比较模型中均达到最高。对比结果表明所提方法对于句子语义特征的学习是有效的。
3.2.2不同实体类别实验结果对比
为了验证模型在各类实体上的提取能力,表4列出了所提方法在苹果病虫数据集中对各类实体的识别结果。从表中可知,本文方法对病害名称、虫害名称、为害部位、药品名称、病原5类实体的F1值均在90%以上,但对别名的F1值仅为83.33%,这可能是由于在数据集中别名实体数量较少,同时病害与虫害的别名通常具有相同的边界特征,如病害名称与其别名都常以“病”字结尾,导致模型在判断中容易混淆,造成F1值较低。
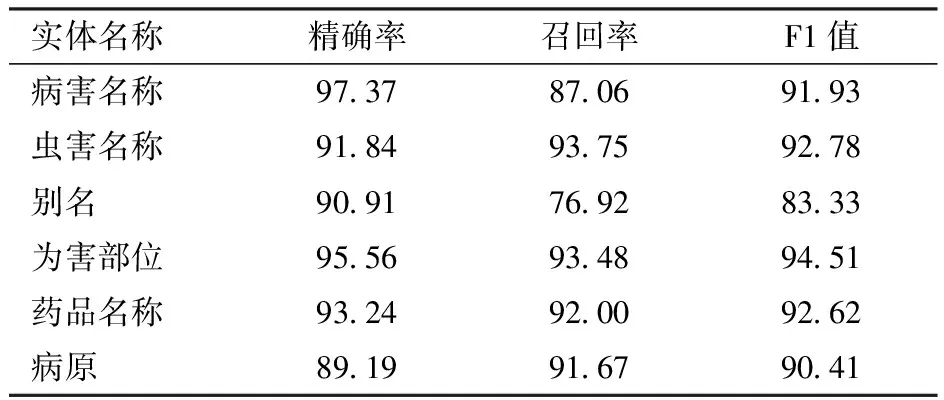
表4 Transformer优化模型在各类实体上的表现Tab.4 Optimized Transformer’s performance on various entities %
图3~5展示了不同模型在各实体上的性能表现对比,本文方法在药品名称(MED)、病害名称(DIS)、病原(CAU)、为害部位(PAR)、别名(NAM)实体上的F1值均优于其他模型。对实体虫害名称(PES)的F1值为92.78%,低于其他模型,原因可能是在虫害实体中,大多以“虫”、“蛾”、“蚜”等特征词作为结尾,但存在部分虫害名称中不存在这些特征词,如“金龟子”,从而导致模型易将这些虫害实体识别错误。参考苹果病虫领域的实体特征,一词多义、生僻字、构成成分多等情况通常多出现在药品名称、病原、别名的实体中,因此,可以说明本文方法能够有效解决苹果病虫领域的命名实体识别问题。
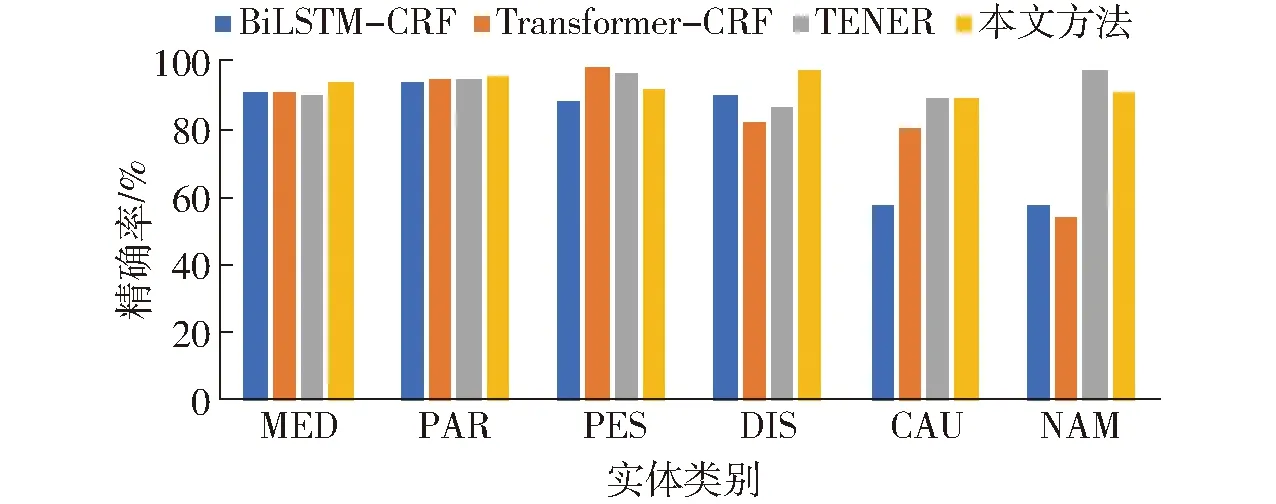
图3 各实体精确率对比Fig.3 Comparison of precision of each entity

图4 各实体召回率对比Fig.4 Comparison of recall rate of each entity
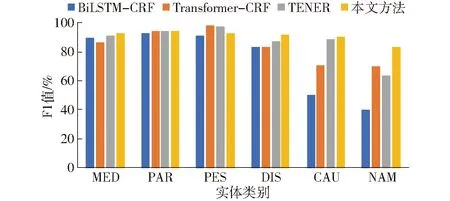
图5 各实体F1值对比Fig.5 Comparison of F1 score of each entities
以上结果表明,本文利用了Transformer中注意力机制,使模型具有更加关注重点词、抑制无用词的特点。采用具有方向和距离感知的注意力机制来充分利用文本位置特征,通过引入BiLSTM来增强上下文信息,在本文所构建的数据集中综合识别能力优于所比较的其他传统模型。
3.2.3Transformer与不同模型融合结果对比
学习任务假设空间往往很大,会有多个假设在训练集上达到同等性能,使用单一学习器可能会出现泛化能力不佳的情况,通过结合多个学习器可以有效降低这一风险。为了得到最佳的模型,本文设计了Transformer分别与RNN、LSTM、BiLSTM和BiGRU进行融合,实验结果如表5所示。
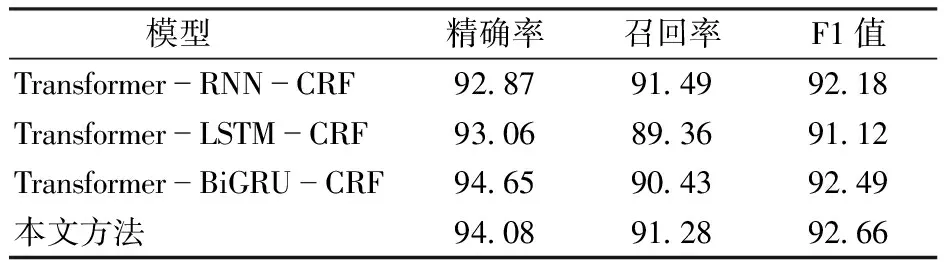
表5 Transformer与不同模型融合结果Tab.5 Transformer integrated with different models %
由表5可以看到,与传统RNN进行融合,模型精确率为92.87%。而LSTM与GRU都属于门控RNN,更适合处理长序列数据,与LSTM融合后的精确率达到93.06%。为了可以更好地捕捉双向的语义依赖,选择分别与BiGRU和BiLSTM模型进行融合,在精确率和F1值上均有提高,结果表明,BiLSTM模型可以更大范围地补充Transformer提取不到的依赖关系和语义特征,因此与BiLSTM融合的效果更好。
3.2.4不同融合方法对模型的影响
为了选择最佳的特征融合方法,本文使用3种不同的融合方法(平均法、投票法、拼接融合法),比较不同融合方法对于模型性能的影响。在不同融合方法下,模型的性能参数结果如表6所示。
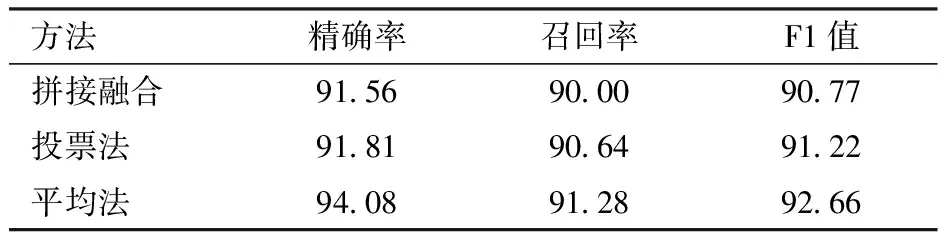
表6 不同融合方法对比
实验表明,使用简单拼接融合效果最差,平均法效果最好,其可能原因是拼接融合将多个特征向量拼接在一起,其中一些特征可能存在多个特征重复出现,导致模型在进行训练时过度依赖重复特征,从而降低模型性能。而由于本文苹果数据集中实体占比较小,投票法可能会受到噪声数据的干扰,从而导致错误的预测结果。平均融合法通过平均多个模型的预测结果,可以减少单个模型的偏差和方差,从而提高整体的准确性。
3.2.5与同领域相似研究比较
文献[9]通过整理苹果病虫领域相关书籍,构建了包含130 448个汉字的苹果病虫害库ApdCNER,共标注相关实体11 876个;本文先通过爬虫技术爬取网页中对苹果病虫害的描述,随后在专家指导下进行修正,构建了苹果病虫语料库,共标注127 572个汉字,包含3 928个实体,与文献[9]相比,本文构建的数据集中各实体数量相对更少,分布更稀疏;在实体的标注方面,文献[9]将苹果相关各实体分为21个类别,更考验模型的提取能力。在本文构建的数据集中根据日常使用情况将实体分为6个类别,更适用于普通问答系统的构建;在模型提取能力方面,文献[9]将苹果数据集中的字典和类似的单词纳入BiLSTM CRF模型,其精确率、召回率和F1值分别为92.29%、91.99%和92.14%,本文所提方法的精确率、召回率和F1值分别为94.08%、91.28%、92.66%,F1值相较提高0.52个百分点,表明了本文方法与当前同领域较先进的模型达到同等性能水平。考虑到所需的样本数量,本方法对小样本量的苹果领域命名实体识别任务具有较高的特征提取能力。
另外,由于与文献[9]采用了不同的实体标注方式,为了排除标注方法的可能影响,本文又使用文献[9]的BMES标注方式对所建数据集进行了实体标注,B表示该汉字是一个词语的开头,E表示该汉字是一个词语的结尾,M表示该汉字是一个词语的中间部分,S则表示该汉字单独构成一个词语,该标注方法对所标注实体增加了对应标签,而对于实体数量较BIO标注并未发生改变。BMES标注后重新训练该模型并对识别性能评估,模型的优化实验参数如表7所示,重新标注后所建模型的精确率为94.40%、召回率为92.21%、F1值达到93.29%。对比3.2.1节使用BIO标注方法的模型运行结果,可以发现两种标注方法的运行效果基本达到相同水平,使用BMES方法更加准确地标注出每个汉字的位置和类型,提供了比BIO方法更多的信息,方便后续进行分词处理,因而是其F1值略有提升的可能原因。对比表7与表2可以看到,模型的优化参数会受标注方式影响。

表7 BMES标注的实验参数Tab.7 Experimental parameters of BMES
最后,为了测试所建模型在实际使用过程中的有效性,通过百度贴吧平台抽取了苹果种植相关的问题,并使用本文模型对文本数据进行了实体识别,结果如表8所示,本模型对实际病虫提问均准确提取出了问题中的实体。
表8 识别结果示例Tab.8 Examples of recognition results
4 结论
(1)针对苹果生产领域存在病虫害相关数据集缺失的问题,本文基于西北农林科技大学在陕西省渭南市白水县的苹果试验示范站所收集的苹果病虫知识,以及通过爬取中国农化招商网,综合《中国苹果病害病原菌物名录》电子版数据,建立了苹果病虫知识数据集。
(2)为提高苹果病虫害实体识别的准确性,本文通过在Transformer中引入具有方向和距离感知的注意力机制,融合BiLSTM提取到的语义特征来提高Transformer在苹果病虫害实体识别领域的识别效果,通过对比BiLSTM-CRF、Transformer-CRF、TENER模型,验证了传统Transformer模型在命名实体识别领域的不足。实验结果表明,本文所提方法在苹果命名实体识别中的F1值可达92.66%。相较于传统的识别方法,其性能进一步提升,对小样本量数据集优势明显。
