基于特征增强的多方位农业问句语义匹配
2023-06-15王奥吴华瑞朱华吉
王奥, 吴华瑞, 朱华吉
1. 广西大学 计算机与电子信息学院,南宁 530004;2. 北京市农林科学院 信息技术研究中心,北京 100097;3. 国家农业信息化工程技术研究中心,北京 100097;4. 农业农村部 数字乡村技术重点实验室,北京 100097
农业复杂交互式问答平台为农户提供专家在线指导、 在线学习、 农业技术交流多种功能[1-2], 在协助用户解决农业生产生活和日常信息需求中发挥着重要作用. 平台农户和专家实时在线互动, 问答文本海量增长, 但经常出现不同表达方式表达相同语义的情况, 相似问题解答消耗大量人力、 物力, 因此构建能够快速准确给出答案的问答系统就显得十分必要. 相似度匹配是语音、 人脸识别[3]、 问答等系统的基础任务, 其相似度计算的精度直接影响问答系统回复的准确率, 利用问句相似度匹配[4]开展高精度的农业智能问答模型研究, 是农业智能化的重要发展方向.
以往的语义匹配研究集中在短语、 语法和词汇匹配, 如文献[5]提出一种语法驱动的文本匹配方法, 通过融合具有鲁棒性的非词汇语法和由对数驱动的词汇语法的线性模型进行文本匹配. 随着深度学习的蓬勃发展[6-8], 语义匹配从基础的文本嵌入到相似度计算, 再到复杂的神经网络, 有效解决了人工设计特征提取量少、 泛化性差的问题. 卜维琼等[9]针对农业领域特征, 提出一种多重信息融合的相似度算法, 首次将深度学习与农业问句匹配结合. 孪生神经网络在文本匹配领域表现出良好的性能[10]. 刘志超等[11]采用孪生神经网络架构, 结合双向长短期神经网络和卷积神经网络进行水稻问句语义匹配. 这种网络结构减少训练模型参数, 提高了训练效率. 金宁等[12]采用孪生神经网络结构, 运用双向长短期记忆网络、 卷积神经网络和密集连接网络从深度语义、 词语共现、 最大匹配度3个层面实现农业短文本匹配, 但是直接进行句子表示的相似度匹配, 忽略了句间交互, 导致交互特征信息的损失, 无法有效学习句子关系特征.
注意力机制[13]可有效解决上述问题, 利用注意力机制对特征信息进行聚合或增强匹配信息, 挖掘丰富的句子关联信息[14-16]. 融入注意力机制的交互模型通过赋予词不同的权重, 能快速获得有效信息, 有效提升文本匹配模型性能, 文献[17]针对农业文本特征, 利用基于协同注意力机制的紧密连接BiGRU(双向门控循环单元)实现农业问句相似度匹配. 在注意力机制基础上从字、 词、 句的角度研究文本相似度计算[18-21], 细粒度对比句子差异能够提高相似度计算的效率和准确率. 但农业文本数据存在词汇总量较少、 专有名词多, 具有冗余性、 稀疏性、 规范性差等特点, 导致传统语义匹配方法提取句子间关联特征信息不够充分, 忽略了句间推理关系. 如何实现农业相似问句语义智能检索仍是农业问答需要解决的一个重要问题.
针对农业文本句子关联特征信息难以深入挖掘, 句子多样性捕获不足等问题, 构建双向长短期循环神经网络提取特征, 融合自注意力机制、 多维注意力机制增强的文本语义推断特征和距离特征, 通过多特征增强聚焦语义特征, 将增强特征嵌入多方位匹配层, 多角度对比句子特征信息, 捕获句子的多样性, 以期实现农业问句精准、 自动的语义匹配.
1 特征增强语义匹配模型
如图1所示, 农业文本专业名词多、 规范性差和高度依赖上下文等特点导致句子交互信息提取不足, 句间关系推理不够深入; 本文构建适用于农业问句文本的特征增强文本匹配模型, 由特征提取层、 特征增强层、 多方位匹配层构成. 特征增强层利用自注意力机制和多维注意力机制提取不同粒度的局部特征, 获取具有丰富语义的交互向量特征. 将两种增强特征信息嵌入多方位匹配函数中, 由3种匹配函数实现文本特征的多角度对比. 作为问答的基础任务, 相似度匹配精度的提升能有效提高问答系统的答案返回效率和准确率. 利用BILSTM(双向长短期记忆网络)提取农业文本输入上下文向量, 获得农业问句文本前后关联语义, 设置2层BILSTM网络, 每层LSTM的隐藏神经单元为128个.
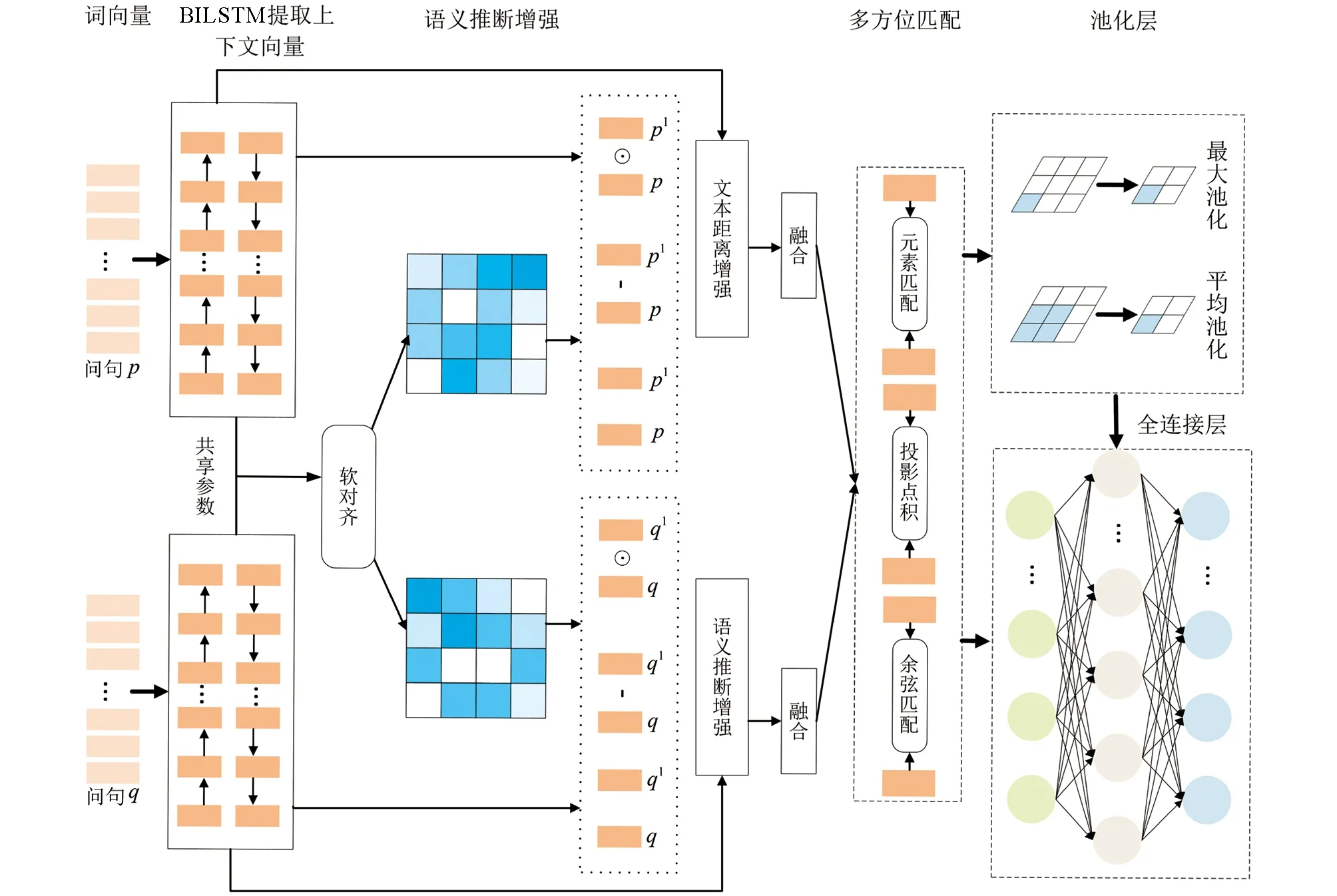
图1 特征增强语义匹配模型架构图
1.1 特征增强层
传统文本匹配模型获取文本特征后直接进行相似度对比, 缺少关联特征信息或挖掘不够深入. 农户提问问句存在文本数据专业名词多、 规范性差等特点, 文本关系特征信息难以挖掘. 利用自注意力机制、 多维注意力机制分别增强语义推理特征和文本距离特征, 准确聚焦语义特征, 合理建模上下文信息, 提高问答匹配精度.
1.1.1 语义推断特征增强
通过自注意力机制计算注意力权重, 获得文本向量间的对齐关系. 公式(1)为权重计算公式, 作为隐藏状态的相似性矩阵.
(1)
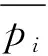
(2)
(3)
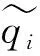
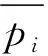
(4)
(5)
1.1.2 文本距离特征增强
农业特定领域中, 农业专业术语比常用词承载了更多信息, 可作为问句中关键词. 循环神经网络提取特征时, 直接提取句子的每个词向量, 忽略了关键词在句子语义表示中的重要作用. 引入多维自注意力机制捕获每个词的上下文表示, 强调关键词的重要性, 增强句子中原始语义特征的提取. 多维自注意力将传统自注意力中的权重向量替换为权重矩阵, 使向量特征获得独自的权重. 注意力权重公式如下:
s(gi,gj)=tanh(giW1+gjW2+b)
(6)
式中,gi,gj为句中的隐藏状态,W1和W2为可学习的权重矩阵,b是大小为隐藏节点个数的偏置.
农业问句文本中词间的距离能代表其相关性, 引入距离感知掩码使相近词获得更多关注, 距离更远的词关注更少. 计算相似度时词间距离越远所加负数越小, 经过softmax函数后, 距离越远的词权重越小, 词间的依赖也随之削弱. 在公式(6)中加上掩码M,M维度为1×1, 矩阵中的值在{0, -∞}之间, 由此构建适用农业问句文本函数(7):
s(gi,gj)=tanh((giW1+gjW2+b))+Mij
(7)
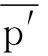
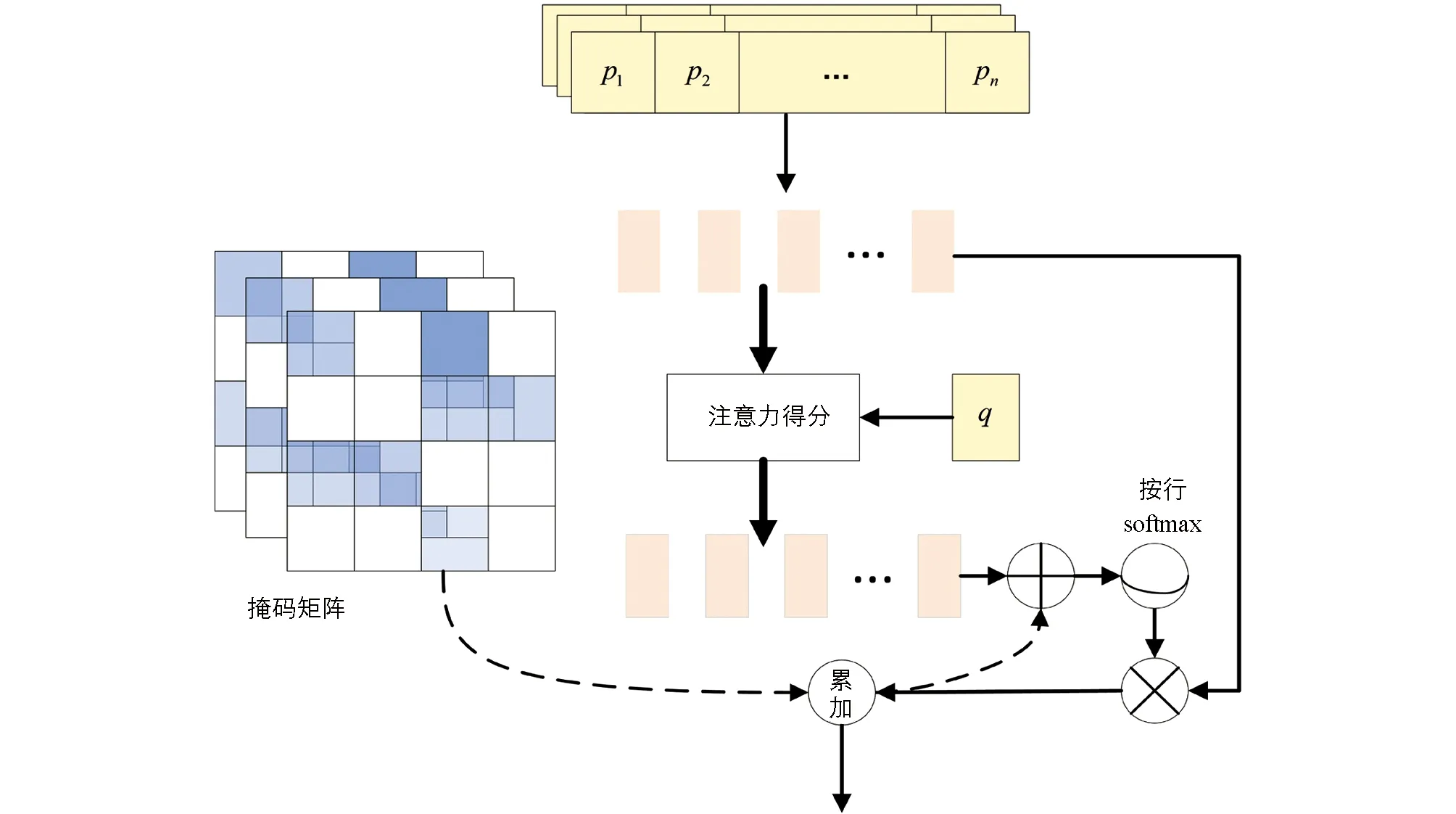
图2 文本距离特征增强
(8)
f(i,j)=-|i-j|
(9)
f(i,j)=-exp|i-j|
(10)
将上述增强特征信息输入特征融合层, 融合增强局部推理特征表示和增强距离感知特征表示, 不仅增强语义特征, 而且保留了句子间的交互特征, 获得具有丰富语义特征信息的对齐特征向量.
1.2 多方位匹配
为了解决农业文本数据的稀疏性和文本词汇总量少导致的句子间关系信息获取不充分的问题, 使用3种匹配函数从不同角度获取更丰富的聚合信息和更准确的句子关系. 余弦相似匹配根据词频对比匹配相似程度, 对单字分组匹配时准确率高.
(11)
(12)
(13)
式中, 特征在所有维度上均减去均值R, 减少余弦匹配因仅进行向量对比的影响.
余弦相似度是对向量空间的度量, 忽略了排序和重叠词影响. 利用投影点积相似度匹配将向量进行投影, 通过点积乘法, 同时进行大小和角度的对比, 考虑整个句子值对相似度的影响. 其中Wp和Wq为可学习参数,σ为sigmoid函数.
m2=σ((vpWp)(vqWq))
(14)
元素匹配则从元素角度比较向量异同. 词在句子中的重要程度不同, 其向量值也不同. 计算向量差异和能更好地学习句间关系. 同时使用3种匹配函数, 从不同角度捕捉句子间的特征关联得到最终的匹配向量.
m3=concat(vp,vq,vp*vq,vp-vq,vp+vq)
(15)
3种输出向量通过平均池化和最大池化聚合全局语义, 导入语义特征, 对最终匹配向量进行聚合. 输入到多层感知机(MLP)分类器, 使用tanh激活函数和softmax函数输出, 模型采用端对端的训练方式, 损失函数为交叉熵损失函数.
2 试验与分析
2.1 试验数据
通过农业领域最大的知识问答社区“中国农技推广信息平台”后台导出涉及5个种类的20 000个问答对来构建农业问句匹配数据集. 采用jieba分词工具加载停用词表, 剔除文本中的停用词、 特殊符号等冗余信息. 人工筛选出信息不完整和无效问答的问句, 标注相似问句, 相同语义的问句占比为54%, 不同语义的问句标注占比为46%, 问答对包含病虫草害、 土壤肥料、 栽培管理、 动物疫病、 养殖管理等5类. 训练集和测试集比例为8∶2, 利用 Adam优化器迭代更新神经网络权重, 采用准确率、 精确率、 召回率和F1值作为评价指标. 表1为训练集样本示例.

表1 训练集样本示例
模型训练迭代次数设置为70, batchsize为110, BiLSTM模型输出特征维度为128维, 全连接层隐藏单元设置为128, 学习率设置为0.001, 问句中有效词语使用300维的词向量表示, 句子最大长度为20, 孪生网络共享参数. 为防止过拟合, 模型使用dropout函数, 随机使神经元失活, dropout设置为0.2.
2.2 试验结果与分析
掩码矩阵由超参数k来决定距离函数的取值, 词距离大于等于k时使用距离掩码限制注意力权重, 如表2所示, 为验证k值对模型性能的影响, 将k值分别设置为0,1,2,3,4,5,6. 分别在农业文本数据和lcqmc数据集上进行试验对比,k为0时, 使用掩码矩阵限制注意力权重, 此时距离当前词较远的词注意力权重较低,k为1时相邻词会得到更多的注意力权重. 试验表明,k为3时性能较好,k继续增大, 对模型性能影响变差, 因此关注距离当前词2或3个词时获取信息更多. 在lacqmc数据集上准确率均在90%以上, 仍不及在农业数据上的表现, 说明模型具有一定的泛用性, 但更适合处理农业文本.

表2 K值对模型性能的影响 %
通过一组试验验证本文模型各个模块的有效性, 删除语义推断增强和文本距离增强得到模型2和模型3. 由表3可知, 正确率和F1值下降了1.7, 1.1个百分点和1.5, 0.9个百分点, 表明单独的特征增强无法充分挖掘农业问句文本的交互信息. 同时删除两种特征增强策略得到模型5, 可以看出两种策略融合更能提高模型的效果. 模型6为共享参数的BILSTM模型, 删除多角度匹配后正确度和F1值下降了0.6, 0.5个百分点, 因为单一角度的匹配无法获取足够的句子多样性. 表4为试验部分预测结果展示, 语义相同的问句标签记为1, 反之标签记为0, 预测与标签值相同时则为预测成功.
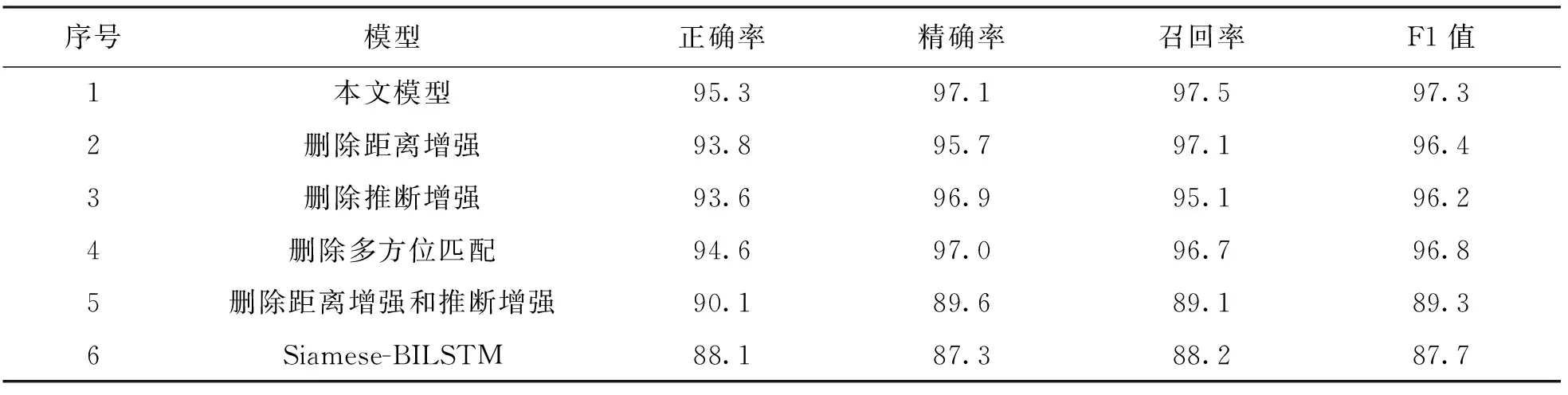
表3 消融试验 %

表4 部分预测结果
图3为来自农业文本数据集的一个实例的注意力权重热力图, 问句1为“土豆早疫病有哪些症状表现?”, 问句2为“土豆早疫病发病原因是什么?”. 图3a是两个句子自注意力的对齐情况, 其中“土豆-土豆”, “早疫病-早疫病”, “症状-发病”有很强的对齐关系, 这些为句子关键词, 可明确表示句子语义, 通过捕捉两句话对齐关系可一定程度上判断词间关系. 图3b是同一问句注意力权重的可视化结果, 可以看出距离更近的词间注意力权重更大, 融合语义推断特征和文本距离特征进一步捕获句子的语义对齐信息, 获取丰富的交互信息, 提升语义匹配任务的性能.
图3 注意权重可视化图
本文与相似度匹配常用5个深度学习模型进行对比, ESIM[22]使用BILSTM提取文本特征, 计算两个句子向量特征的相似度矩阵, 对向量特征加权, 再由一层BILSTM整合向量特征, 获得新的文本向量表示进行相似度匹配; DIIN[23]是一种交互推理网络, 使用密集连接的卷积神经网络在交互空间中分层提取语义特征实现句子对的理解; ABCNN[24]在CNN的基础上引入注意力机制, 在卷积计算和池化计算之前进行注意力权重计算, 判断文本相似情况; BIMPM[25]在BILSTM提取文本特征后, 根据两句话不同的时间进行多角度对比; TextCNN[26]通过不同大小的内核获取句子信息, 使用CNN完成句子的匹配和分类.
表5展示了6种模型针对农业问句数据集的试验结果, 本文模型在正确率、 精确率、 召回率、 F1值均超过了95%, 较对比模型均有明显提升, 对比模型中, ESIM模型4项指标均超过91%. 本文模型F1值较其他模型提高接近5个百分点. 说明该模型能较为全面地捕捉文本间的交互信息, 相似度计算总体性能较好. 以卷积神经网络框架为基础的模型评价指标均低于以循环神经网络框架为基础的模型, 这是由网络结构所决定的, 卷积神经网络结构更擅长局部特征信息的提取, 并非文本序列化方向的特征提取, 且会丢失一些距离较远的文本特征向量. 5种对比模型中ESIM模型召回率为93.8%, 但仍与本文模型有些差距.
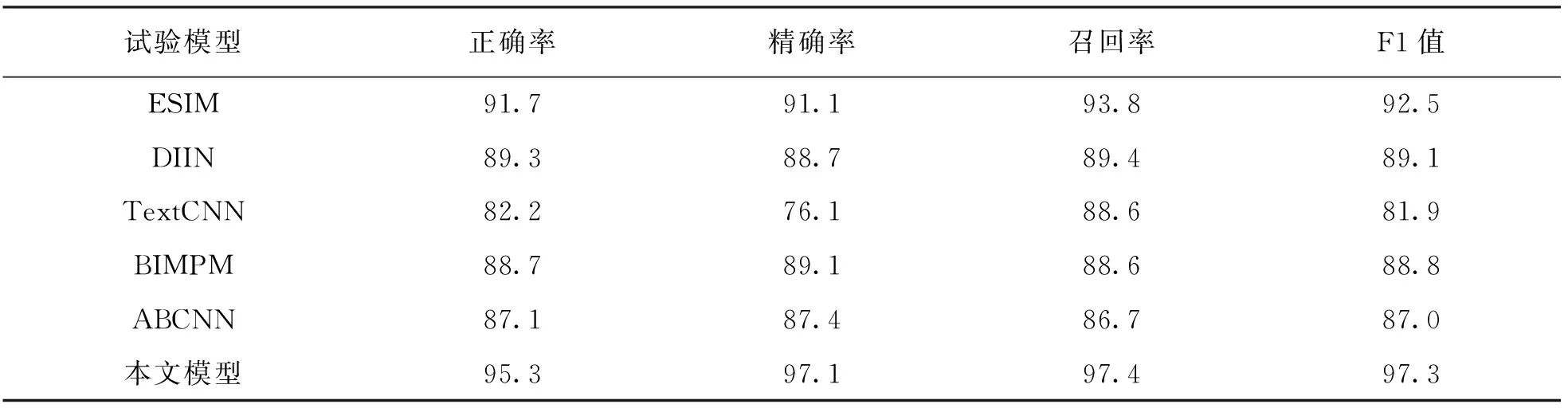
表5 不同模型对比结果 %
如图4, 与ESIM,DIIN,ABCNN,BIMPM,TextCNN 5种文本匹配模型相比, 本文模型在病虫草害、 家畜疫病、 栽培管理、 养殖管理、 土壤肥料5个类别的问句数据集上均有最高的匹配准确率, 整体匹配效果优于对比匹配模型. 在病虫草害和栽培管理两个试验数据量充足的类别上准确率率为95.0%和94.7%, 因为数据集越充分, 对深度学习模型迭代训练的效果提升越高. 在养殖管理和土壤肥料两个数据量较少的类别中也高于其他模型的精确率, 说明本文模型鲁棒性较强, 在数据量不充足时也能有效提取文本特征进行相似度匹配.

图4 不同模型在农业问句数据集不同类别的准确率
3 结 语
为提高农户和农技工作者对农业问题检索的效率, 减轻农业专家回复相似问题的压力及人工回复的延时性, 构建了包含5个类别的农业问句语料库, 提出一种基于多特征增强的农业问句语义匹配模型, 在特征增强层增强语义推断特征和文本距离特征, 深层次挖掘出农业文本交互特征信息, 进一步获取丰富的文本间关联特征信息, 由多方位匹配获取更丰富的聚合信息和句子关系. 试验证明, 在构建的农业问句数据集上较其他模型对语义匹配的计算性能有进一步提升, 实现农业问句快速自动检测, 有效提高农业智能问答中海量问句匹配效率和问答结果的准确率, 进一步发挥智能问答在农技推广领域中的作用. 由于农业具有地域性, 在未来的工作中可考虑开展对方言问句和非规范的口语化问句语义匹配的相关研究.
