红外-可见光图像融合的全天候目标追踪方法
2023-06-15马哲杰王昱霖李平
马哲杰 王昱霖 李平
摘 要: 目前主流的监控视频处理方式仍然是根据光照条件,单独使用可见光或红外光视频。本文提出双流全卷积孪生网络,旨在利用图像融合技术,将可见光与红外光图像各自的优点互补,辅助目标检测与追踪。在特征提取模块,构建以DenseNet为主干的孪生神经网络。在特征融合与重构阶段,使用全卷神经网络构造全局特征和模板特征。在目标追踪阶段,对全局特征和模板特征进行互相关操作,得到跟踪结果。本文方法充分利用双模态视频的深度信息,有效解决极端天气以及夜间光线不足造成的图像采集模糊问题,增强追踪模型在复杂情景下的鲁棒性。
关键词: 计算机视觉; 孪生神经网络; 图像融合; 目标追踪; 红外图像; 可见光图像
中图分类号:TP399 文献标识码:A 文章编号:1006-8228(2023)06-96-07
All-weather tracking method based on infrared-visible image fusion
Ma Zhejie, Wang Yulin, Li Ping
(Department of Computer Science, Hangzhou Dianzi University, Hangzhou, Zhejiang 310018, China)
Abstract: The mainstream surveillance video processing is still using visible or infrared video alone. In this paper, a Two-Stream Fully Convolutional Siamese Network (TFSiamNet) is proposed to assist target detection and tracking. Firstly, in the feature extraction module, a Siamese network with DenseNet is constructed. Secondly, in the feature fusion and reconstruction stage, the fully convolutional layers are used to construct the global feature and template feature. Finally, in the tracking stage, the cross-correlation between the global feature and the template feature is carried out to get the tracking results. The proposed method makes full use of the depth information of the dual-mode video, effectively solves the problem of fuzzy image acquisition caused by extreme weather and insufficient light at night, and enhances the robustness of the tracking model under complex scenarios.
Key words: computer vision; Siamese network; image fusion; target tracking; infrared image; visible image
0 引言
隨着人工智能在我国高速发展以及监控覆盖率稳步提升,计算机视觉在寻人、侦查等安防领域开始广泛应用。利用目标追踪与定位技术进行智慧安防管理已逐渐成为一个热门的研究领域。
目前,红外传感器在监控设备中普遍应用,使得监控设备可以同时采集红外图像和可见光图像组成的双流数据。因此,目标追踪技术主要通过两种方式获取图像数据:利用红外传感器分辨温度差异获得红外图像;利用传统光学成像原理获得可见光图像。红外摄像头基于其光线不敏感的特性,能在夜间和恶劣天气下工作,但是当目标和背景温度相似时,往往会发生热交叉效应,使得跟踪算法难以从背景中发现目标;可见光摄像头具有较高的分辨率,可以更好地展现局部细节,但因其对光线的依赖性,使用场景较为局限。单独使用其中的一种技术,显然都不能很好的满足不同场景下目标的检测与跟踪任务。
本文为了解决以上难点,对可见光图像和红外图像组成的双流数据进行特征级融合,使用可见光-红外双模态融合追踪网络,实现在海量监控视频中对目标人物的匹配与追踪。该模型提取的目标模板特征兼具红外图像和可见光图像两者的优点,有利于提高目标匹配与定位的精度,克服大雾、暴雨、冰雹等极端恶劣天气,以及夜间光线不足造成的图像采集模糊问题,增强模型在复杂情景下的鲁棒性。
1 研究现状
1.1 目标跟踪
目标跟踪是根据时间顺序在不同的视频帧中找相同的目标。现实中由于目标运动的机动性高、随机性强、自然因素干扰等问题,经常使目标跟踪失败。故如何使跟踪算法具有更高的泛化能力和准确率成为国内外许多学者致力研究的课题。
2019年,Danelijan等人在[CVPR]上发表的新成果重叠最大化精确跟踪(简称[ATOM][1])提出了一个新的目标跟踪框架,把目标跟踪划分成目标粗定位和目标形状估计两个阶段。同年,张志鹏教授和鹏厚文先生提出的新概念残差单元[2]为孪生网络的加深提供了可能。在[2020]年,德克萨斯奥斯汀分校和英特尔研究院[3]将基于点的跟踪与检测结合起来,提出一个基于点的联合跟踪与检测框架——CenterTrack,每一个目标都用其边界框中心的一个点来表示,然后按时间顺序跟踪这个中心点,该跟踪器以端到端形式进行训练且可微分。
纵观近年来国内外代表性的研究成果,孪生网络以其在图像匹配问题上的优势逐渐成为研究的热点。相比传统算法通过区域建议来更新矩形框,采用图像匹配作为更新方式的孪生网络在保持准确率的同时,由于轻量级的特点大大加快了跟踪速度。
1.2 图像融合
图像融合是将多幅图像中的信息整合成一幅图像,为应用提供更好的数据源的一项技术。近年来,该领域产生了许多优秀算法。
[2019]年,Li等人[4]提出一种新的深度学习方法:红外与可见光图像融合的体系结构。与传统的卷积网络不同,其编码网络结合了卷积层、融合层和密集块,并设计了两个融合层来融合这些特征。最后通过译码器对融合后的图像进行重构。次年,Li等人[5]提出了一种新的红外和可见光图像融合方法,建立了基于巢穴连接的网络和空间-通道注意模型。基于嵌套连接的网络可以在多尺度上保存输入数据中的大量信息。
2021年,Zhu等人[6]提出了一种新的深度网络结构,称为质量感知特征聚合网([FANet]),用于鲁棒[RGBT]跟踪。与现有的[RGBT]跟踪器[7]不同,[FANet]在每个模态中聚集了层次深度特征,以处理由低光照、变形、背景杂波和遮挡引发的外观显著变化的挑战。特别地,Zhu等人采用最大池化的操作将这些分层多分辨率的特征转化为具有相同分辨率的统一空间,使用[1×1]卷积运算压缩特征维数,实现更有效的分层特征聚合。为了模拟[RGB]和热模态之间的相互作用,他们精心设计了一个自适应聚合子网络,根据不同模态的可靠性对其特征进行集成,从而能够缓解低质量源引入的噪声效应。
红外和可见光图像融合,能够将多源图像融合,提高了成像质量,减少了冗余信息,广泛应用于各种成像设备,以提高机器的视觉能力。融合图像中,对场景的准确、可靠和互补的描述,使这些技术在各个领域得到了广泛的应用。
2 双流全卷积孪生网络模型
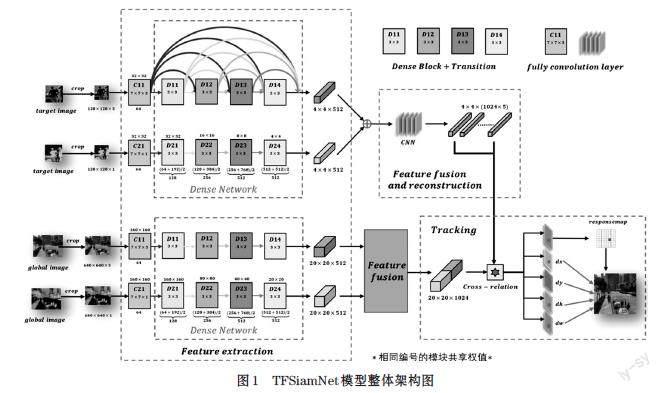
2.1 模型整体架构
本文将图像融合技术与目标追踪技术相结合,以孪生网络为主体架构,选用改进后的[DenseNet-121]网络[8]模型作为骨干网络来提取特征,然后使用全卷积神经网络分别对目标模板特征和全局特征进行特征的融合与重构,最后对融合模板特征和融合全局特征进行互相关操作,得到目标的位置和大小信息。整个模型的架构如图1所示。
首先对同帧同步的双流视频进行帧采样,再选取视频帧序列的首帧图片,手动框选需要追踪的目标,分别将目标与当前帧的可见光与红外光图像输入双流特征提取网络。然后利用特征融合技术将两类图像的红外与可见光特征融合为模板特征和全局特征。在获取图像有效的特征后,采用目标检测技术,利用互相关操作将目标模板特征与视频帧序列特征逐一进行运算,输出目标中心位置及候选框的大小参数,实现对于目标的框选和定位。本文重点在图像特征提取、图像融合模块和目标追踪与匹配模块进行了创新,将会在技术分析部分具体论述模块结构。
2.2 技术分析
2.2.1 特征提取网络设计
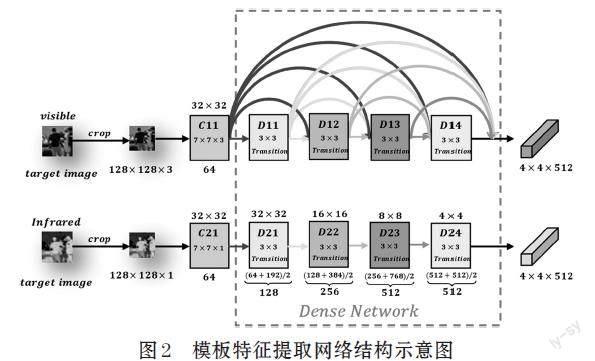
目标跟踪的任务是,在视频的每一帧中匹配和定位目标,因此在特征提取时,需对第一帧图像进行目标框选,得到待追踪目标的模板图像,将视频帧序列的当前帧作为待搜索图像,因为我们处理的是双流视频数据,故以模板图像和待搜索图像均由一组同帧同步的红外光和可见光图像组成。特征提取网络模型由孪生的可见光网络和红外光网络构成。我们以模板特征提取网络为例进行介绍,其内部结构由双流异构三维卷积层和改进的[DenseNet-121]组成,具体结构如图2所示。
在特征提取之前,由于红外光与可见光通道数存在差异,无法直接适应相同结构的网络,为了使后续的[DenseNet]网络更好的进行权值共享,本文设计了一组异构的三维卷积核,分别对两组图像进行初步的特征提取和通道合并。首先将两个原始的模板图像进行尺寸缩放,转化成[128×128×3]和[128×128×1]的标准大小,其中可见光图像通道数为[3],红外光图像通道数为[1]。针对不同通道数的图像,分别采用异构的卷积核进行卷积运算,最后经激活层和最大池化处理,得到初始模板特征。
将初始模板特征分别输入改进的[DensNet-121]网络进行深度特征的提取。在最后一个密集块的输出部分增加过渡层,进行特征降维,可以有效过滤因密集连接产生的冗余信息,且有利于之后的特征融合与重构,最终输出一组[4×4×512]的雙流模板特征。同理,针对全局图像的特征提取,首先将两个原始全局图像缩放为[640×640×3]和[640×640×1]的标准大小,经过类似的计算,最终输出一组[20×20×512]的双流全局特征。
本文使用[DenseNet]作为特征提取的骨干网络,相比[ResNet]具有更高的运行效率,基于其密集连接的网络结构,各层特征重复利用,使其参数存储和计算的开销更小。同时,[Corinna Cortes]等人从理论上证明[9],类似于[DenseNet]的网络结构具有更小的泛化误差界,因此,该网络能较好地满足融合跟踪模型高精度、高实时性的需求。
2.2.2 特征融合与重构
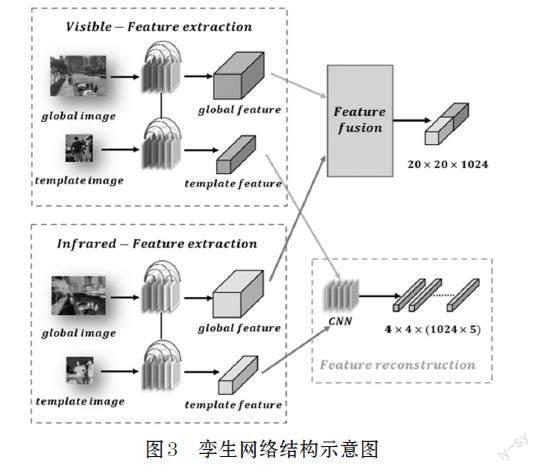
将经过特征提取网络出的模板特征和全局特征分别输入特征融合模块。将可见光全局特征与红外光全局特征拼接,并生成融合全局特征,将可见光全局特征和红外光全局特征经过全卷积网络进行特征融合与重构,生成融合模板特征,并对通道进行切割操作,生成五个维度相同的特征图。
我们知道,红外光图像和可见光图像分别反映出目标、背景等不同方面的特征,因此在特征提取中应针对红外光图像和可见光图像分别设计不同的参数和权重,但对于同类型的模板图像和全局图像,因为其包含的特征类别相似,为更好地保留和反映其相同的特征,同时提高模型的训练速度,我们使用孪生神经网络作为主体架构,分别设计红外光特征提取网络和可见光特征提取网络,两个网络内部共享参数。最终将不同维度的模板特征和全局特征分别进行融合与重构操作,孪生网络及特征的融合与重构如图3所示。
2.2.3 目标追踪
在目标追踪与匹配模块,输入是由目标图像重构的融合模板特征张量和当前帧图像的融合全局特征张量。将待搜索帧的全局图像划分为[17×17]大小的网格,分别将[289]个网格与等分成五维的融合模板特征进行互相关计算,输出[17×17×5]的矩阵,矩阵第一维度为经过[Softmax]计算后得出的当前区域含有目标图像的概率,即全局响应图,后四维分别为在该区域内预测的目标中心点坐标及预测框的宽和高。概率最大的方格即为目标所在的区域,根据矩阵后四维的数据即可确定目标的具体位置,该模块具体流程如图4所示。
2.3 算法流程设计
算法的输入为两组同帧同步的视频帧序列,根据首帧给定的[Groundtruth],得到目标模板图像。经过特征提取、融合重构网络,得到融合模板特征和融合全局特征,将得到的五个相同维度的融合模板特征张量作为一组卷积核,与全局特征张量进行互相关操作,从而得到一个五维的结果张量,检索第一个维度中的最大响应值,从而,定位目标在全局图像中的位置,然后根据该位置所对应的预测框参数,得到该帧图像中的目标位置。
3 模型实现
3.1 图像融合网络的实现
在模型迭代训练过程中,为了使融合生成的图像更好地学习到红外光图像及可见光图像各自的优点,本文设计融合重构网络的损失函数如下:
[Loss=λLSSIM+LTV] ⑴
其中,[LSSIM]表示结构相似度导致的损失值,[LTV]表示总变异度导致的损失值,由于计算得出的[LSSIM]与[LTV]在数量级上存在差异,故采取[λ]平衡两者对损失函数的影响。
3.1.1 [LSSIM]损失函数
结构相似度[SSIM]对于图像的局部结构变化的感知较为敏感,可作为区分图像的重要依据。[SSIM]分别从亮度[(Luminance)]、结构[(Structure)]和对比度[(Constrast)]三方面量化两个图像属性的差异,取值范围为0至1,数值越大,代表图像越相似。用公式可具体表示为:
[SSIM(x,y)=l(x,y)α?s(x,y)β?c(x,y)γ] ⑵
这里取[α、β、γ]的值均为1,并将原始公式进行展开可得:
[SSIM(x,y)=2μxμy+C1μ2x+μ2y+C1×2σxσy+C2σ2x+σ2y+C2×σxy+C3σxσy+C3] ⑶
其中,[μx、μy]表示图像[x、y]的像素平均值,[σx、σy]表示图像[x、y]的像素标准差,[σxy]表示图像[x、y]之间的协方差,[C1、C2、C3]均为常数。取[C2=2C3]并将原式化简:
[SSIM(x,y)=2μxμy+C1μ2x+μ2y+C1×2σxy+C2σ2x+σ2y+C2] ⑷
由于本文的目标是设计专门用于红外和可见光图像融合的损失函数,在实际应用中,因为监控设备采集的图像分辨率较低,局部的亮度差异不显著,所以在这里忽略亮度的影响,取[l(x,y)]值为固定值[1],简化后图像[x、y]的结构相似度可表示为:
[SSIM(x,y)=2σxy+C2σ2x+σ2y+C2] ⑸
由于通常熱辐射信息越丰富则局部像素强度越大,当我们在对行人进行追踪时,趋于关注图像中的热目标,因此可以通过像素强度进行测量。在训练过程中分别对可见光图像、红外光图像进行滑窗搜索,定义滑窗内像素平均强度为:
[X(I|w)=1a?bi=1a?bPi] ⑹
其中,[Pi]表示滑窗内每一个像素点的大小,[a、b]分别表示滑窗的宽和高。
本文定义融合图像的相似度评分为[S(I1,I2,IF|w)],红外光图像的像素平均强度为[X(I1|w)],可见光图像的像素平均强度为[ X(I2|w) ],为使融合后的图像具备更加丰富的热辐射信息,融合图像的相似度评分取像素值较高图像的SSIM值,则相似度评分可具体表示为:
[SI1,I2,IF|w=SSIMI1,IF|wXI1|w>XI2|wSSIMI2,IF|wXI1|w≤ XI2|w] ⑺
结合融合图像的相似度评分,[LSSIM]可最终表示为:
[LSSIM=1-1Nw=1NS(I1,I2,IF|w)] ⑻
3.1.2 [LTV]损失函数
总变异度[TV Loss]表示图像的噪声,使用[LTV]作为损失函数并使其数值不断变小可使图像变得平滑,[LTV]公式可表示为:
[LTV=i,j(||xi,j+1-xij||2+||xi+1,j-xij||2)β2] ⑼
其中,[xi,j+1]、[xij]、[xi+1,j]分别表示不同位置的像素值。本文使用[I1(i,j)]表示红外光图像在[i,j]处的像素值,[IF(i,j)]可见光图像在[i,j]处的像素值,[Δ(i,j)]表示两者的距离:
[Δ(i,j)=I1(i,j)-IF(i,j)] ⑽
为方便计算,本文取[β=2],将式⑽代入式⑼得到最终[LTV]计算公式为:
[LTV=ij([Δ(i,j+1)-Δ(i,j)]+[Δ(i+1,j)-Δ(i,j)])] ⑾
通过不断减小[LTV]值可避免红外光与可见光图像之间像素值的突变,从而使生成的融合特征图像更为平滑。
3.2 目标跟踪网络的实现
迭代训练双流全卷积孪生网络模型,直至模型收敛,其中特征融合模块的参数已预训练完成,设定损失函数如下:
[Loss(Y,m,n,q)]
[=1Ym=117n=117q=15log(1+exp(-yc(m,n,q)?yc(m,n,q)))] ⑿
利用随机梯度下降算法优化模型,通过反向梯度传播更新模型参数直至损失不再显著下降,其中,[Y]为模型最终输出的[feature map],[yc]为[Y]中的值,[yc]为真实标签中的值,若目标中心在[(m,n)]网格内,则[yc(m,n,1)]为[1],此时[yc(m,n,2),…,yc(m,n,5)]分别表示[bounding box]的位置和大小参数[dx,dy,dw,dh],否则[yc (m,n,1)]为0,此时,[yc(m,n,2),…,yc(m,n,5)]无意义。
3.3 模型训练
针对图像融合网络,本文设计了一个端到端的融合框架,其参数的训练在整个模型的训练之前。该体系结构源自鲁棒混合损失函数,该函数由修正的结构相似度损失([LSSIM])和总变异度损失([LTV])组成,可实现自适应融合热辐射和纹理细节并抑制噪声干扰的无监督学习过程。本文使用[TNO]图像数据集[10]和[INO]视频数据集[11]构造[25]对不同场景下的可见光和红外光图像,对图像进行抽样处理,得到[20000]个[128×128]的补丁,从而扩充训练样本,此处不需要进行人工标记,使用[ADAM]优化器对损失函数进行迭代优化,设置学习率[α=10-4]。图像融合模块预训练完成后,对整个跟踪模型进行训练,共训练50个[epoch],每个[epoch]中包含50000对图像,学习率在训练过程中从[10-2]至[10-5]逐渐减小。
本文设计的融合跟踪网络模型在华为云服务器上进行搭建和训练,我们使用[PyTorch 1.6.0]和Cuda 10.2作为实验框架,选用显卡Nvidia TESLA V100进行训练和测试,其具有32GB显存,可高速进行数据计算和处理,实验所用CPU为Intel Xeon E5-2690 V4。
4 模型评估
4.1 评价指标
本文使用平均重叠率(Average Overlap Rate,[AOR])以及[ROC]曲线下的面积(Area Under Curve,AUC)对提出的融合跟踪器性能进行测试。
计算每一帧[groundtrut]h和算法输出[bounding box]的交并比[IoU],定义如下:
[IoUa,b=a∩ba∪b] ⒀
其中,[a]和[b]分别表示预测得到的[bounding box]以及[groundtruth]所对应的框。对所有帧的交并比取平均值得到[AOR]。
根据公式⒀,计算交并比,当大于某个阈值[ρ∈[0,1]]时,认定跟踪成功,从而绘制[ROC]曲线,计算曲线与x,y轴的面积,得到[AUC]。
4.2 实验结果与分析
我们在17组红外-可见光双流视频数据上测试了本文提出的模型与其他跟踪模型的结果[13],具体见表1。比较实验结果可知,我们提出的[TFSiamNet]在各组数据上取得的[AUC]指标均达到较优的结果。其中在五组数据中优于所有比较的跟踪模型,此外,TFSiamNet在14组视频中均排名前三。这证明了本文提出的模型在红外-可见光双流视频融合跟踪中的有效性。
5 结束语
本文提出了一种基于图像融合与目标跟踪的融合跟踪技术,通过对可见光与红外图像深度特征的充分利用,辅助目标跟踪的决策。该模型以孪生网络作为主体架构,利用全卷积网络将红外光特征与可见光特征进行融合,通过端到端的深度融合框架实现无监督学习,自适应的融合热辐射特征和颜色、纹理等可见光特征并进行重构,使生成的融合特征兼具两者优点。最后利用互相关操作在帧图像中分区域匹配与定位目标,在保证较高精度的同时运行速度快,能够较好地满足实时性需求。
本文方法能够充分利用目前较为普及解决由于自然环境等客观因素导致图像不清晰、定位不准确等问题。未来随着社会的发展,将会对智慧安防系统在数据量、精度等方面提出更高的要求,需要系统进一步降低人工的参与度并提升模型效率,以便应对更大规模的数据和更加复杂的场景。因此目标追踪的研究需要进一步深入,而融合追踪将是一个很好的发展方向,具有广阔的研究前景。
参考文献(References):
[1] Danelljan M, Bhat G, Khan F S, et al. Atom: Accurate
Tracking by Overlap Maximization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019:4660-4669
[2] Zhang Z, Peng H. Deeper and Wider Siamese Networks
[3] for Real-Time Visual Tracking[C]//Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019:4591-4600
[4] Zhou X, Koltun V, Kr?henbühl P. Tracking Objects as
Points[C]//European Conference on Computer Vision. Springer, Cham,2020:474-490
[5] Li H, Wu X J. DenseFuse: A Fusion Approach to Infrared
and Visible Images[J]. IEEE Transactions on Image Processing,2018,28(5):2614-2623
[6] Li H, Wu X J, Durrani T. NestFuse: An Infrared and Visible
Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models[J]. IEEE Transactions on Instrumentation and Measurement,2020,69(12):9645-9656
[7] Zhu Y, Li C, Tang J, et al. Quality-Aware Feature
Aggregation Network for Robust RGBT Tracking[J]. IEEE Transactions on Intelligent Vehicles,2020,6(1):121-130
[8] Li C, Liu L, Lu A, et al. Challenge-Aware RGBT Tracking
[C]. European Conference on Computer Vision. Springer, Cham,2020:222-237
[9] Huang G, Liu Z, Van Der Maaten L, et al. Densely
Connected Convolutional Networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2017:4700-4708
[10] Cortes C, Gonzalvo X, Kuznetsov V, et al. Adanet:
Adaptive structural learning of artificial neural networks[C]//International conference on machine learning. PMLR,2017:874-883
[11] Toet A. TNO Image Fusion Dataset(Version 2)[DB/OL].
(2022-10-15)[2022-11-18].https://doi.org/10.6084/m9.figshare.1008029.v2
[12] INO team. INO Videos Analytics Dataset[DB/OL].
[2022-11-18].https://www.ino.ca/en/videoanalytics-dataset/
[13] Zhang X, Ye P, Peng S, et al. SiamFT: An RGB-infrared
fusion tracking method via fully convolutional siamese networks[J]. IEEE Access,2019,7:122122-122133
