深度注意力机制结合临床特征预测肝细胞癌微血管浸润
2023-06-14方威扬阙与清刘子蔚陈超敏
巩 高,曹 石,肖 慧,方威扬,阙与清,刘子蔚,陈超敏
1南方医科大学生物医学工程学院,广东 广州 510515;2南昌大学第一附属医院,江西 南昌 330006;3南方医科大学附属顺德医院,广东 佛山528308
肝细胞癌已经成为世界第六常见的恶性肿瘤,也是癌症死亡的第3大原因[1],术后复发对临床治疗仍是一个重大挑战[2,3]。微血管浸润的存在被证明是与肝切除和肝移植术后早期复发和低生存率相关的独立预后因素[4,5],对于MVI阳性患者,肿瘤复发风险增加4.4倍,扩大切除边缘的肝切除术可通过根除微转移显著提高患者的生存率[6,7]。但是目前MVI只能通过组织病理学结果来最终确定,因此迫切需要在术前基于影像学手段和临床因素分析来对MVI进行分类预测。
近年来,随着医疗影像技术的进步,越来越多的研究者关注术前影像学表征来预测肝细胞癌微血管浸润,但微血管浸润的影像学特征并不明显,目前已有多项研究尝试探索影像学特征以预测MVI[8-10],影像学特征能否正确反映MVI的具体情况存在争议。许多研究者关注肿瘤大小、边缘光滑程度、包膜情况、瘤周强化方式、多灶性、表观扩散系(ADC)等对肝细胞癌微血管浸润的影响[11-13],已经被证明有助于预测MVI。除此之外,还有一些研究者试图研究临床血清指标对MVI的影响[14],取得了前沿性的进展。
放射组学作为一种无创的影像技术,可以采用数字影像中的高维特征进行预测,已被成功应用于MVI的预测。Li等[15]开发了一种基于FDG18 PET/CT的放射组学列线图模型评估极早期和早期肝细胞癌患者微血管浸润的无病生存期(DFS),证明该模型对提高极早期和早期肝细胞癌患者MVI 个体化DFS 有重要价值。Hu等[16]建立基于超声(US)的放射组学评分方法用于肝细胞癌术前微血管浸润的预测,经过实验验证,放射组学评分列线图模型要优于基于AFP和肿瘤大小的临床列线图模型。还有许多研究者通过结合放射组学和临床血液检测指标对MVI进行预测[14,17],取得了一定成效。放射组学在医学领域应用广泛且效果较好,但由于放射组学特征对特征提取和重建参数敏感而且过程繁琐,有待改进。
深度学习作为人工智能领域的一个分支,可以直接从医学影像数据中学习到深度特征,已被证明效果优于传统的放射组学。在肝细胞癌微血管浸润预测方面,深度学习也取得了很好的效果。Wei等[18]回顾性研究多中心(CE-CT)和(EOB-MRI)两种数据类型建立了深度学习模型,并通过注意力图来可视化MVI的高危区域,结果显示基于EOB-MRI的深度学习模型效果要优于基于CE-CT的深度学习模型,两种模型都可以对肝细胞癌患者进行无复发生存期和总生存期的高风险组和低风险组进行分级,取得了良好的效果。Jiang等[19]构建基于CT图像的XGBoost放射组学模型和3D深度学习模型预测MVI,通过对比两种模型效果,深度学习模型更有助于预测MVI。但能否辅助肝癌治疗决策,还需进一步验证。
本项研究旨在探究MRI评估MVI存在的一致性和诊断性能,基于深度学习方法结合注意力机制与临床实验室检测指标建立模型,提高对MVI检测的敏感度和特异度,希望为临床术前准确诊断MVI的存在并进一步制定最佳治疗方案提供参考意见和理论支持,降低医生工作强度,辅助医生做出临床决策。
1 材料和方法
1.1 实验数据
本回顾性实验经南方医科大学附属顺德医院(中国佛山)伦理评审委员会批准(20201124)。所有访问的患者数据均符合数据相关隐私保护,且所有患者的权利未受到侵犯。
数据收集过程:回顾性收集了南方医科大学附属顺德医院的患者,包括经病理证实的单发和多发实性肝癌(图1)。对于图像数据,术前1个月接受增强MRI检查以及MVI检查;对于临床数据,数据排除标准如下:(1)术前给予其他抗肿瘤治疗和肝切除手术;(2)有大血管和肝外转移;(3)用于解释的MRI图像质量不理想。

图1 本研究纳入数据流程图Fig. 1 Flow chart of the enrolled dataset.
1.2 数据获取及预处理
所有肝细胞癌患者的MRI检查均在3.0T MR 的磁共振扫描仪(磁共振采集协议如表1)下进行扫描采集。3个常规腹部MRI序列包括:T1WI、T2WI(伴脂肪抑制的)、扩散加权成像(DWI,b=0)、4个增强MRI序列包括:动脉期(AP,17.5s-)、门静脉期(PP,约80 s)、平衡期(EP,约3 min)、肝胆期(HBP,20 min),两个合成MRI序列:T1mapping-pre、T1mapping-20 min(20 min)。详细MRI参数见表1。数据集中肿瘤区域由两名放射科医生进行手工绘制,并通过一名资深的临床专家进行确认和验证。
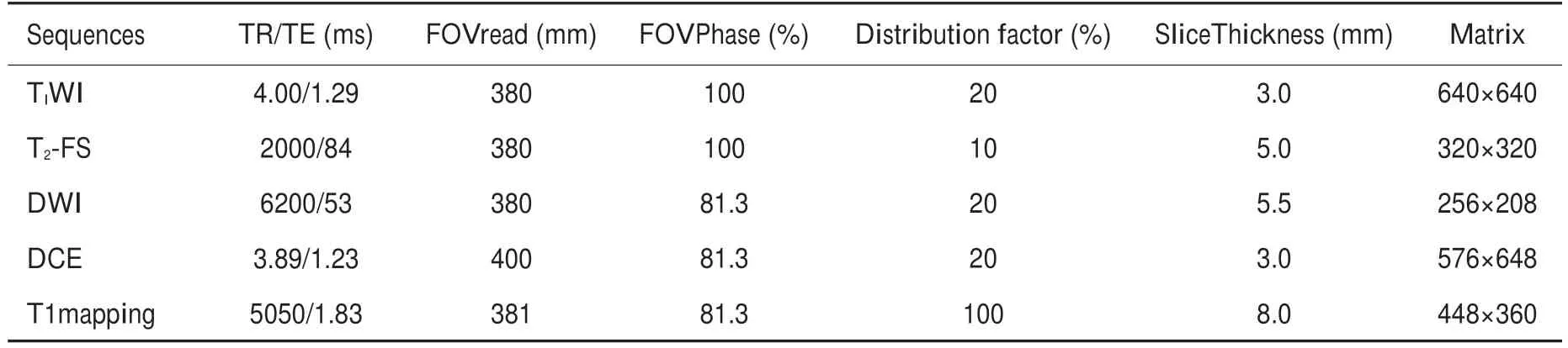
表1 磁共振采集参数Tab.1 MR image acquisition protocols
在模型训练之前,采用图像标准化的方法,消除在医疗环境中由于设备和软件导致MRI图像差异,便于对图像进行识别。由于MRI图像数量不足,需要进行数据增强,增加样本容量,增强数据的多样性,提高模型的泛化能力,防止模型过拟合。增强过程包括在原图像的不同位置进行随机裁剪、或水平或垂直翻转等,裁剪完的图像为新图像,使得图像总数增加,并将所使用的MRI序列和增强后图像数量等信息展示(表2)。
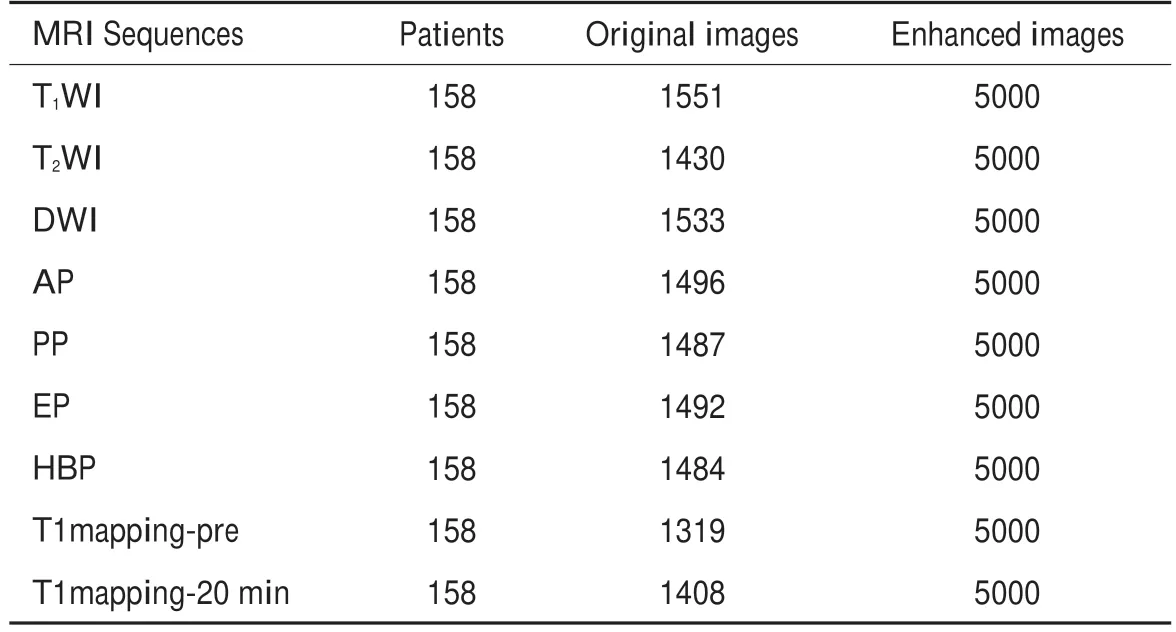
表2 本研究所纳入病例数量信息Tab.2 Numbers of cases and MR images included in this study(n)
临床参数通过收集患者的血液检查信息,术前收集参数包括年龄、性别、甲胎蛋白(AFP)、乙型肝癌病毒(HBV)、丙型肝癌病毒(HCV)、谷丙转氨酶(ALT)、谷草转氨酶(AST)、谷氨酰转肽酶(GGT)、碱性磷酸酶(AKP)、乳酸脱氢酶(LDH)、白蛋白、血清肌酐(SCR)、总胆红素(TBIL)、结合胆红素(DBIL)、C 反应蛋白(CRP)、中性粒细胞/淋巴细胞比值(NLR)、血小板、淋巴细胞、血小板/淋巴细胞比值(PLR)、凝血酶原时间(PT)。
所有的病理检测结果均为两名专业的病理医生完成,并通过一名病理专家进行验证。肝细胞癌患者检测数据包括Edmondson-Steiner分级、组织学类型、细胞类型、包膜浸润状态、MVI、胆管浸润和卫星结节。MVI被定义为肿瘤浸润任何门静脉、肝静脉、或仅在显微镜下可见的内皮敷衬的大囊状血管。MVI的风险等级分为3个级别,分别是M0:无MVI、M1:转移复发低风险、M2转移复发高风险[1],此次研究只分M0和非M0两个级别。
1.3 深度学习模型建立
本章提出了一个结合深度注意力机制与临床特征的肝细胞癌微血管浸润分类预测模型,其框架如图2所示。首先,将MRI序列中感兴趣区域(ROI)输入至特征提取网路中提取图像深度特征;其次,将临床特征进行特征编码,通过自编码器进行特征处理,初步学习临床特征之间的相关关系;最后,利用注意力机制将两个特征进行特征融合并学习特征间的结构关系,输入分类器进行分类。具体包含以下3个部分:深度自注意力特征提取、临床特征编码与提取、交叉注意力特征融合。

图2 深度学习模型结构图Fig. 2 Framework of the proposed method including data preprocessing,clinical feature,attention feature and prediction.Data preprocessing is normalized after data denoising,clipping,rotation and translation.
1.3.1 深度自注意力特征提取 该部分以EfficientNetB0[20]为主干网络,其结构参数如表3。由表3中我们可以看出EfficientNetB0的最后一层特征图分辨率为7×7,通道数为1280,我们去掉其Pooling&FC层,在此基础上引入了自注意力机制模块,可以更好地学习MVI的关键特征,具体连接结构如图3。模型的输入ROI为原始MRI图像经预处理后的图像,最终规定化为224×224大小。

表3 EfficientNetB0的结构参数Tab.3 Network parameters of EfficientNetB0

图3 注意力机制图示Fig. 3 Attention mechanism module.
自注意力模块是该系统的关键部分之一。微血管浸润影像特征不明显,我们需要利用注意力机制的特性帮助网络更好地提取MVI高危区域的影像学特征,从而更好地对MVI进行分类。我们在non-local[21]注意力基础上进行修改得到自注意力模块,这种改进方法可以有效降低模型算法的时间复杂度。注意力模块如图3,具体实现步骤:(1)经过EfficientNetB0提取的特征图,我们通过f(x)、g(x)和h(x)分别其通道数为640,分别得到特征图A(粉红色模块)、B(紫色模块)、C(绿色模块);(2)对特征图A 和B 求dot product 结果,并通过softmax进行归一化得到注意力系数矩阵;(3)对注意力系数矩阵和特征图C求element-wise结果,得到注意力特征矩阵;(4)通过summation运算将初始特征矩阵与注意力特征矩阵相加,得到最终输出。自注意力机制原理如式(1)和(2):
其中,xi和xj为注意力模型的输入,yi为注意力模型的输出,1/C(x)为归一化常数,f(x)和g(x)为核函数,它们的选择不敏感,f(x) 通过dot product实现,g(x)通过1×1卷积实现。为防止网络退化,在模型中加入了shortcut,其中zi为xi和xj的加权输出。
1.3.2 临床特征编码与提取 对输入的临床参数进行one-hot编码[22],并将其进行特征拼接。然后进行特征降维,将降维后的特征输入至自编码器[23]以学习特征之间的隐含关系,从而得到临床特征。之所以使用one-hot编码,是因为临床参数为离散的类别型数据且类型不复杂。自编码器及特征提取实现如图4。

图4 自编码器Fig. 4 The self-encoder module.
在特征拼接的过程中,通常使用的方法是Concatenation进行特征拼接,形成一个新的特征,以提取更多的特征信息。其原理如式(3):
其中,xi,yi分别表示深度特征和临床特征,*表示卷积,K为常数。
1.3.3 交叉注意力特征融合 交叉注意力特征融合模块如图5所示。经过编码和初步学习的临床特征为低层次数字特征,而深度注意力特征为抽象化能力和特征表达能力较强的高层次特征向量,我们需要将其映射至同一维度。具体步骤为:a.我们将提取的临床特征进行特征映射Y=f(X∗W+b),映射后的维度为(H1,W∗),如图5的绿色模块。b.将深度注意力特征图切割为n块,每一块都进行三角编码[24]处理,增加像素的位置信息。然后将经过三角编码的特征块分别进行特征映射,其维度大小为(H2,W∗),如图5中蓝白色块。三角编码原理如式(4):

图5 交叉注意力特征融合Fig. 5 Cross-attentional feature fusion.
其中,d为位置编码向量的维度。c.最后,将每个深度特征小块分别与临床特征求相互注意力,学习深度特征与临床特征间的相互关系以得到融合特征注意力特征块。再次求融合注意力特征块之间的相关关系,最后按位置编码恢复,如图5中的红色块。
具体算法步骤如下:
Step 1.提取映射后的临床特征Y1(H1,W∗);
Step 2.提取经过三角编码和特征映射后的深度特征块:
Y2(H1,W∗),Y2(H2,W∗),…Y2(Hn,W∗)
Step 3.计算深度注意力特征小块和临床特征的融合注意力特征:
Y3(H1,H2)=Y1(H1,W∗)∙Y2(H2,W∗),依次类推
Step 4.计算融合注意力特征块之间的相关关系:
Step 5.按位置编码恢复最终特征Y=Concatenation(Y1,Y2…Yn)
由于MVI特征复杂,仅仅通过一个影像期的数据很难准确判断MVI的状态,需要结合多个MRI序列的影像综合判断,而临床参数的辅助能够进一步提高MVI分类预测的准确度。因此,根据影像数据和临床特征,我们创建了13个模型,其中包括9个单序列模型和4个融合模型:(1)单序列模型为根据某个序列建立而无临床特征 的模型,如T1WI model、T2WI model、DWI model、AP model、PP model、EP model、HBP model、T1mapping-pre model、T1mapping-20 min model;(2)而T1WI&T2WI&DWI fusion model 为同时融合了T1WI、T2WI、DWI 三种MRI 序列且无临床特征的模型,AP&PP&EP&HBP fusion model为同时融合了AP、PP、EP、HBP 四种MRI 序列且无临床特征的模型,T1mapping fusion model 为融合 了T1mapping-pre、T1mapping-20 min 两种MRI 序列且无临床特征的模型;(3)T1mapping-20 min&Clinical fusion model为融合T1mapping-20min序列和临床参数的模型,clinical model为仅融合了临床参数的模型。这样设计的具体原因有:(4)考虑单序列和多序列融合在预测MVI方面的模型差异①对比常规MRI序列(T1WI、T2WI、DWI)、增强MRI 序列(AP、PP、EP、HBP)和合成MRI 序列(T1mapping-pre、T1mapping-20min)预测MVI的效果,从而选择对MVI预测更有效的序列组合②对比加入临床参数前后预测MVI的效果,判断在MVI预测方面,临床特征对影像特征的补充作用程度。
1.4 模型训练
我们使用影像数据和临床参数来评估肝细胞癌微血管浸润的分类预测模型,并且使用5折交叉验证方法对所有的方法进行了评估。交叉验证的设置即使用数据集C中80%数据作为训练,20%作为测试。本实验均使用Python3.9的Pytorch环境来完成。关于网络训练,所有的图像训练均在两个12G的NVIDIA图像处理器上进行。
1.5 MVI高危区域可视化与注意力模型的关注点对比
本研究中采用类激活映射(CAM)深度学习可视化方法,确保我们的模型能够识别出MRI图像中与肝细胞癌微血管浸润最相关的区域,并生成注意力图,显示出最为可疑的区域,以0.5为界限[25,26]。CAM的实现步骤:(1)在CNN 的最后一个卷积层之后,加入一个全局平均池化层。该层将卷积层的特征图进行平均池化,得到一个特征向量;(2)将全局平均池化层的输出作为一个全连接层的输入,该全连接层只有一个节点,用于表示当前图像属于哪个类别的概率;(3)计算该全连接层的梯度相对于卷积层输出的梯度,得到一个权重向量;(4)将卷积层的输出特征图和权重向量进行加权求和,得到一个加权特征图;(5)对加权特征图进行类别标签上采样,得到一个与输入图像相同大小的热力图。该热力图显示了网络对不同区域的关注程度,越亮的区域表示越重要。对于给定的图像,用fk(x,y)代表最后一个卷积层上第k通道(x,y)的激活值。对于第k通道全局平均池化的结果为Fk=∑fk(x,y)。对于类别c,输入到softmax里的是Sc=是Fk对于类别c的重要性(即权重)。CAM可实现如式(5)(6):
定义Mc为类别c的CAM,则
其中,Mc(x,y)代表了像素(x,y)的激活值对图像分类为c的权重,我们可视化权重特征图,即得到注意力图。
此外,虽然在深度学习中经常使用原始图像来更好验证模型的识别度,但MVI的特征较为复杂,原始图像中的其他病灶会干扰肝细胞癌带有微血管浸润的肿瘤边缘的MRI图像特征,因此本研究中采用裁剪后的图像来避免这些特征的丢失。
1.6 模型间对比与预测能力评估
采用准确度(Accuracy)、敏感度(Sensitivity)、特异度(Specificity)、精确度(Precision)、F1指数(F1-score)、ROC 曲线及曲线下面积(AUC)来评价我们的模型。Accuracy、Sensitivity、Specificity、Precision、F1-score的计算如式(7)、(8)、(9)、(10)、(11):
其中,真阳性(TP)是指正确分类的正样本数,即预测为正样本,实际也是正样本;真阴性(TN)是指正确分类的负样本数,即预测为负样本,实际也是负样本;假阳性(FP)是指被错误的标记为正样本的负样本数,即实际为负样本而被预测为正样本;假阴性(FN)是指被错误的标记为负样本的正样本数,即实际为正样本而被预测为负样本。ROC曲线为受试者工作特性曲线,横坐标为假阳性率(FPR),纵坐标为真阳性率(TPR),AUC为ROC曲线与坐标轴围成的面积数值。FPR和TPR的计算如式(12)、(13):
1.7 统计分析方法
采用spss22.0软件包进行统计学分析。采用单因素回归分析和多因素回归分析分别对MVI的临床影响参数进行分析并且计算95%可信区间(95%CI)。通过配对T检验,检测不同模型的显著性差异。所有统计检验均为双侧检验,P≤0.05认为有统计学意义。
2 结果
2.1 基线特征
在训练组/验证组和测试组中,经过组织病理学验证为MVI阳性病变分别为33.33%(42/126)和43.75%(14/32)。在回顾性实验中训练组/验证组和测试组之间MVI均无显著性差异(P>0.05),纳入所有患者的基线特征汇总于表4。

表4 纳入队列的基线特征Tab.4 Baseline characteristics of the included cohort
2.2 MVI风险特征
表4列出了临床数据集中的临床血液检测参数,共有158个病例,以均值和标准差的形式展示不同指标的数值。为了说明测试组和验证组之间的差异,我们利用t检验方法来检验训练组/验证组和测试组之间的显著性关系。结果表明,训练组/验证组和测试组之间无显著性差异(P<0.05),通过此方法能提高我们算法的泛化能力,提供算法改进启示。
此外,后续实验中,我们利用统计学方法筛选临床特征中的MVI风险特征。在19个临床特征中,我们通过单因素二元逻辑回归分析确定了其中有统计学意义的10个MVI风险特征,包括年龄、甲胎蛋白含量、乙型肝癌病毒(HBV)、丙型肝癌病毒(HCV)、白蛋白(Albumin)、总胆红素(TBIL)、结合胆红素(DBIL)、C反应蛋白(CRP)、中性粒细胞/淋巴细胞比值(NLR)、血小板/淋巴细胞比值(PLR)。然后通过多因素二元逻辑回归逐步分析确定了两个独立的危险因素:甲胎蛋白的含量(OR,5.003;95%CI;P<0.05)和中性粒细胞与淋巴细胞的比值(OR,3.236;95%CI;P<0.05)。
2.3 模型间比较的结果
3种不同的MRI序列成功建立Fusion model后使用测试数据集进行评估诊断效果,验证该方法的诊断性能。其中,单独使用临床特征建立clinical model的准确度为77.27%,敏感度为67.56%,特异度为83.18%,AUC为85.80%。而使用T1mapping-20 min和临床特征建立的T1mapping-20 min&Clinical fusion model的效果最优,准确度为83.76%,敏感度为83.78%,特异度为87.02%,AUC为85.01%(表5)。模型间比较ROC曲线如图6所示。

表5 不同模型间对比结果Tab.5 Comparison of the test results of different models

图6 模型间ROC曲线对比Fig. 6 ROC curves for inter-model comparison.A: Comparison of the results of three conventional single-series models. B: Comparison of the results of four dynamically enhanced single-series models. C: Comparison of the results of two mapping single-series models.D:Comparison of the results of four fusion models.
2.4 MVI高风险区域的模型验证
图7 为融合模型检测到的MRI 序列图像中疑似MVI的相关区域。图7A~E为MRI图像中的MVI成像特征,图7F~J为模型检测疑似MVI相关病变的注意力图,标为高亮区域。由图中可以看出深度学习模型的主要关注区域为T2WI图像包膜强化位置、PP图像上的包膜不完整性、AP图像上的瘤周不均匀强化、HBP图像和T1mapping-20min图像上的肿瘤区低信号,模型可以识别出这样明显的MVI 高危区域。然而,深度模型在T1WI图像和T1mapping-pre图像没有捕捉到MVI相关信息。
此外,根据网络可视化注意力图可知,深度注意力模型能够发现肿瘤区域中的坏死病变和脂肪沉积,尤其是患者的HBP图像和T1mapping-20min图像。值得注意的是,根据我们的数据集,MVI阳性患者的病灶要比阴性患者的病灶体积更大,且病灶数量更多(图8),(A)、(B)患者为MVI患者,(C)为非MVI患者。可以看出与(C)患者相比,(A)患者的病灶体积更大,(B)患者的病灶数量更多。

图8 患者不同序列的MRI图像Fig. 8 MRI images of different sequences of a 59-year-old male with MVI(A),a 56-year-old male with MVI(B)and a 66-year-old male with hepatocellular carcinoma without MVI(C).
2.5 消融实验
2.5.1 注意力机制的有效性分析 对比直接融合和交叉注意力特征融合模块的效果,两种模型分别记为M1和M2。消融实验在本文数据集的9个影像期数据上进行。将数据重新分配,抽取其中三分之二,以此增加模型的泛化能力(表6):(1)通过比较影像期M1和M2 的各项指标,我们发现模型M2 在各项指标上的预测性能相较于模型M1 均有所提高。具体来说,准确度提升了3%~9%,敏感度增加了2%~6%,精确度上升了2%~8%,以及F1-score 增长了3%~10%;(2)根根据各影像期的P结果显示,模型M1 和M2 的P-Value 均低于0.05。这意味着在预测MVI时,模型M1和M2在各项评价指标(准确度、敏感度、特异度、精确度和F1-score)上具有显著性差异;(3)对比9个影像期模型M1和M2的各项指标,T1mapping-20min的模型M2除了在准确度(Accuracy)比门静脉期低0.2%,其余各项指标均达最高,即敏感度(Sensitivity)为85.30%、精确度为83.68%、F1-score为84.48%。

表6 在数据集中不同影像期的特征融合方式效果对比Tab.6 Effects of different feature fusion approaches for different image periods in dataset C
2.5.2 自编码器对临床特征筛选的有效性分析 为了说明自编码器对临床特征的筛选的有效性,我们通过对比统计学习方法筛选特征和自编码器筛选特征分别与影像学特征(T1mapping-20 min)融合的模型对MVI预测的效果,通过准确度、敏感度、精确度和F1-score来进行评估,并通过T检验检测不同筛选方法的显著性差异。分别对比了方差分析(ANOVA)、卡方检验(Chi-square Test)、逻辑回归(LR)和自编码器(Self-encoder)4种方法的筛选效果(表7):(1)由P可以看出,3种统计学特征筛选方法与自编码器相比均无显著性差异;(2)自编码器与3种统计学特征筛选方法的相比,准确度、敏感度、精确度和F1-score有1%~5%误差,特别是F1-score,最高达到85.65%;(3)3种统计学特征筛选方法筛选出最终的风险特征个数都为2个,且在参与预测MVI准确度上相差较小。

表7 统计学方法与自编码器特征筛选效果对比Tab.7 Comparison of the effects of statistical methods and autoencoder feature selection
3 讨论
在本次研究中,我们进行了深度学习分析,以MRI的9 个不同序列的图像建立单个序列模型及融合模型对术前MVI进行分类预测。结果显示,T1mapping-20 min序列图像和临床参数的融合模型对MVI分级具有最优的预测能力。在预测MVI的同时,我们采用可视化技术分析模型感兴趣的图像特征,一旦模型确定患者患有MVI阳性,它就告诉临床医生MRI图像的哪个区域引起了模型的注意。并且我们也通过组织病理学对MVI的肿瘤高危区域进行证实,验证了模型定位的准确性。因此,该模型在MVI分级上具有良好的识别能力,也可能为肝细胞癌的个性化治疗提供帮助。
为了更好地实现预测MVI的无创分级,人们做出了许多努力。基于MRI、CT、US和PET/CT等成像方式的放射组学模型在MVI分类预测中取得了良好的成绩,尤其是基于增强技术的MRI(EOB-MRI)成像和高分辨率特性的CE-CT。已有研究表明,肿瘤大小、肿瘤边缘光滑程度、瘤周强化程度、肝胆期瘤周低信号等定性特征均与MVI的阴阳性相关[8,9],基于EOB-MRI的放射组学模型预测结果AUC可达到0.892,基于CE-CT的放射组学模型预测结果AUC可达到0.852[18]。由于US成像对MVI分级不友好[27]和PET/CT技术的高费用[28,29],虽然取得了一定的成绩,但相关研究较少,值得进一步探索。在本文中,我们依据MRI技术、增强MRI技术和合成MRI技术得到的MRI影像,通过结合注意力机制和临床特征建立单序列模型和融合模型。结果表明,融合模型在准确度、敏感度、特异度,AUC等指标上均优于单序列模型,说明融合模型的预测效果远优于单序列模型。而合成MRI序列T1mapping-20 min结合临床参数的使用相比其他所有模型具有更高的敏感度,其原因可能是合成MRI技术T1mapping序列中的T1值的降低能够被神经网络准确捕获[30]。消融实验的结果表明,我们设计的交叉注意力融合模块相比直接融合深度特征和临床特征对MVI的预测效果更佳,模型有具有更高的准确度和F1-score,这也表明交叉注意力融合模块能充分学习到深度特征和临床特征的互补信息,并能利用这些信息提高对MVI的预测效果。此外,我们使用自编码器来学习临床参数之间的关系,并将其结果输入至下游任务。为了说明自编码器的实际效果,我们通过对比三种不同的临床参数筛选方法和自编码器方法的效果,结果表明,三种统计学方法筛选的MVI高危特征个数相同,也与自编码器筛选特征无显著性差异,而自编码器的稳定性更强,无需人工参与,说明自编码器完全可以代替统计学特征筛选方法且能够充分学习MVI风险特征之间的关系,对MVI预测效果更优。我们还发现以合成MRI定量技术建立深度学习融合模型,能够显著提高深度学习模型敏感度但特异度较低。在引入临床特征后,我们发现特异度有显著上升,这些结果表明,合成MRI定量影像技术和深度学习定量分析技术能够显著性筛选出MVI特征,临床参数能够提高模型对MVI的特异度,能够进一步提高了模型的识别能力;另一面也表明临床参数分析对定量影像分析技术在MVI评估中具有潜在的补充作用。由于设计的融合模型是一种端到端的模型,它直接学习MRI影像和临床参数的抽象映射,我们采用可视化技术分析模型感兴趣区域,包括坏死和脂肪沉积等。如图7所示,这些区域被标识为亮色,用于区分网络模型MVI高危区域与其他肿瘤区域的学习能力。这表明深度学习模型在经过大量数据训练后能够掌握MVI相关的知识,并且拥有一定的自主预测能力。尽管不同序列的MRI影像学特征有所不同,但融合模型仍能通过MVI的典型特征,如肿瘤大小,肿瘤形态、肿瘤包膜完整性等,检测出怀疑区域。既体现MRI影像评估MVI的一致性和诊断效果,也进一步表明融合模型掌握了MVI影像学特征,并能够做出适当调整,稳定性更强。
在现有研究的基础上,本文方法具有以下优势:(1)基于EfficientNetB0模型提取特征所需的参数量比其他网络更少,引入注意力机制后能发挥其性能,能在保持高性能预测的前提下减小内存和计算需求,且能适应不同分辨率的医学影像;(2)我们提出的交叉注意力特征融合方法,能够有效识别MVI特征,比直接后端融合的性能有质的提升且模型鲁棒性更强;(3)结合不同模态影像的深度注意力特征与临床特征对MVI进行预测,能够大幅提高模型预测的准确度、敏感度和特异度,临床特征与深度特征在MVI的预测上具有互补作用;(4)通过深度学习可视化技术对疑似MVI高危区域进行可视化,进一步增加了术前准确识别MVI 的可能性。然而,本文方法仍存在一定的局限性。首先,在MVI预测方面,我们采用的数据集来自同一研究中心,纳入的患者群体属于同一机构,没有通过多中心数据进行外部验证。为了平衡数据缺乏问题,我们通过重采样和数据增强的方式增加数据量,但仍需要多个机构的数据进行验证。其次,深度学习模型可视化实验中,我们可以看到模型能够对肝细胞癌疑似MVI高危区域进行判定,但具体位置仍需组织病理学实验进一步验证,组织病理学图像与深度学习模型可视化图像的相互匹配程度仍需后续研究。最后,该深度模型还未进行临床验证,后续需要将其用于预后实验,进一步验证模型的临床实用价值。
总而言之,我们提出的结合深度注意力机制与临床特征的融合模型方法有助于MVI的分类预测,其中基于合成MRI定量技术的融合模型效果总体优于基于常规MRI技术的融合模型和基于增强MRI技术的融合模型。除此之外,深度学习注意力机制和临床特征的加入,有助于提高模型的敏感度和特异度,我们认为这样可以提高MVI分类的准确度。为了更全面准确地预测肝细胞癌患者的复发和预后,需要进一步研究。
猜你喜欢
杂志排行

南方医科大学学报的其它文章
- FARSB stratifies prognosis and cold tumor microenvironment across different cancer types: an integrated single cell and bulk RNA sequencing analysis
- EHHADH是肝细胞癌脂肪酸代谢通路的关键基因:基于转录组分析
- 左归降糖解郁方促进糖尿病并发抑郁症大鼠的海马齿状回神经干细胞的自我更新并激活Shh信号通路
- 芦荟苷可抑制胃癌细胞的增殖和迁移:基于下调STAT3/HMGB1信号通路
- RITA 体外选择性抑制BAP1缺失的皮肤黑色素瘤细胞的生长
- 激活小鼠ZI区GABA 能神经元可促进七氟醚和丙泊酚的麻醉诱导而对麻醉维持及觉醒无影响