面向多点侦察和通信服务的多无人机协同任务分配
2023-06-14姚昌华安蕾刘鑫韩贵真高泽郃
姚昌华 安蕾 刘鑫 韩贵真 高泽郃


摘要针对多无人机对多个异构任务目标进行侦察和通信服务的协同优化问题,通过考虑不同目标的任务要求和价值,以及多机协同增益与任务行为制约关系,构建斯坦伯格博弈模型,将上层无人机建立为博弈领导者,下层无人机建立为博弈的跟随者,并提出一种分布式策略更新迭代算法,实现了多无人机任务分配方案的稳定收敛以及系统任务收益优化.仿真结果显示,所提方法能有效提升多无人机系统同时完成多个任务的效益,并能在不同环境下实现面向异构任务价值的高效协同.
关键词多无人机系统;任务分配;斯坦伯格博弈;迭代算法
中图分类号
TN929.5;V279
文献标志码
A
收稿日期
2021-08-16
资助项目
国家自然科学基金(61971439,61961010);江苏省自然科学基金(BK20191329);中国博士后科学基金(2019T120987);南京信息工程大学人才启动经费(2020r100)
作者简介
姚昌华,男,博士,教授,研究方向为智能无人集群、智能无线通信.ych2347@163.com
安蕾(通信作者),女,硕士生,研究方向为智能无人集群.1178535838@qq.com
0 引言
随着人工智能技术的快速发展,无人机的智能化水平也越来越高,数量众多的无人机组成无人机群以其高度的灵活性、广泛的适应性、可控的经济性,拥有越来越广泛的应用潜力.无人机可以对地面目标近距离地实施选择性和针对性的观测和通信[1].多无人机系统具有容错性强、自适应性好等优势,更适合在复杂环境下执行任务[2].
多无人机执行任务时,必须对其进行任务分配,以提高任务执行效率.无人机集群的任务规划是指根据任务需求、自身特性等对目标任务进行综合调度,从而建立无人机与任务目标之间合理的映射协同关系[3-4].对于异构主体之间的协同问题,已有了一些相关研究,比如:文献[5]采用多架無人机协同辅助实施任务分配和路径优化的分层优化方案,能够解决降低时间和能耗的优化问题;文献[6]针对多无人机作战飞机协同任务分配问题建立了一种扩展的多目标整数规划模型,并采用改进的量子粒子群算法求解最优方案;文献[7]针对任务随机下发场景中由于任务完成时间约束带来的任务完成度低的问题,通过强化学习方法进行无人机的行为决策,达到新任务与正在执行任务的动态分配以提高任务完成度;文献[8]考虑飞行航程和任务分配均衡性,在自适应遗传算法运行过程中对交叉率和变异率进行实时动态调整,以克服标准遗传算法陷入局部最优的缺点;文献[9]针对多目标跟踪任务分配中传感器之间竞争与合作的关系,提出了一种基于博弈理论的多目标跟踪任务传感器资源分配方法;文献[10]考虑在通信带宽有限条件下多无人机组队的任务分配问题,通过协调侦察、执行和评估任务,改进基于一致性的竞拍算法来减少通信负担;文献[11]基于相邻局部通信的分布式拍卖算法,实现了多无人机任务协同分配的优化求解问题;文献[12]采用多无人机辅助移动边缘计算系统联合优化一个有限周期内的无人机轨迹和用户调度;文献[13]考虑任务分配中联盟的构建和无人机资源管理方法,使联盟中各无人机能够以更加平衡的方式消耗资源,提升系统性能;文献[14]综合考虑无人机的物理性能约束,应用基于模拟退火的混合粒子群算法进行任务分配求解;文献[15]建立多任务的分配问题模型,采用多余负载竞拍方案减少非法劣解,通过实数编码建立粒子和实际分配方案之间的映射关系,解决实际分配问题;文献[16]研究了MEC辅助无人机群中所有成员的总延迟的最小化问题,提出卸载模型,缩短了任务的完成时间;文献[17]提出一种动态分散任务分配算法,用于任务分配问题中在线新任务的分配.
上述文献所研究的任务目标大多是同构的[9,12,16-17],未考虑异构的任务价值[10-11,13],也未考虑同时存在多点侦察任务和通信服务.从方法上看,现有多数研究基于集中式分配算法[5-8,14-15],即需要一个中心控制实体来为集群内的所有成员分配任务.这种模式不利于提高无人机集群的鲁棒性和环境适应能力.在无人机集群执行任务过程中,大部分的环境状态都是动态变化的,其任务分配的方案也应该随时优化调整,以有效应对动态环境的变化.集中式任务分配算法存在计算复杂度高、依赖中心节点等问题.研究自适应强的多无人机分布式动态任务分配方法,是多无人机协同任务分配的现实需要,也是难点问题.
本文研究多无人机网络中的任务目标调度问题,构建面向异构任务类型和价值的斯坦伯格(Stackelberg)博弈模型,设计通信和侦察的任务效用函数,并提出分层用户侦察和通信任务调度以及功率控制算法,实现基于无人机自主任务选择的多无人机系统任务分配稳定收敛以及系统任务总收益优化.
1 系统模型和问题建模
1.1 系统模型
无人机通信侦察任务分配系统模型如图1所示,由一个领头无人机(Leader Drone,LD)和随机分布在其周围的N个协同无人机(Collaborative Drone,CD)构成,共同完成多个任务.每一架无人机监测或服务范围内均有随机分布的不同数量的通信和侦察两类任务.每个任务的重要程度或属性不同,其对应的任务价值也不同.各架无人机根据自身位置与目标之间的距离、目标价值、侦察或通信服务所获得的期望收益,以及与其他无人机通信链路之间可能的干扰关系,来自主决定选择任务对象.
令0表示领头无人机,则分布在周围的协同无人机集合表示为A={CD 1,CD 2,…,CD N},领头及协同无人机可调度通信任务目标集合表示为T u,i={1,2,…,m},i∈A∪{0},可调度的侦察任务目标集合表示为T z,i={1,2,…,n}.信道增益为g i,j,j∈T u,i∪T z,i∪{0},并且假定信道增益在任务目标调度和功率调整时期稳定不变.LD和CD的发射功率向量为p=[p 0,p 1,…,p N],背景干扰噪声功率为σ2.CD执行通信侦察任务后,需要将信息上传汇报给领头无人机.侦察任务中,每一架无人机对各个任务目标对象的分辨率r为定值,构建分辨率矩阵.通信任务调度中,当给定LD以及其他CD的调度策略后,CD i服务第k个通信任务目标的下行信噪比为
γk i(p i,p -i)=p ig i,kIk i(p -i), (1)
通信信息上传时的信噪比为
k i(p i,p -i)=p i,0g i,0Ik i(p -i,0), (2)
其中Ik i(p -i)=p 0g 0,k+∑j≠i,j∈Ap jg j ,k+σ2,Ik i(p -i,0)=∑j≠i,j∈Ap j,0g j,0+σ2,p -i=[p 0,p 1,…,p i-1,p i+1,…,p N]表示除CD i以外的所有无人机的功率分配向量.CD i下的通信任务目标同时收到来自邻居CD的同层干扰以及来自LD的跨层干扰.p i,0为通信上传功率值,假定CD到LD通信上传速率为R i,分配带宽为 i,由R i= ilog 21+p i,0g i,0σ2可求得p i,0.另外,LD服务的第l个通信任务目标的下行信噪比可以表示为
γl 0(p 0,p -0)=p 0g 0,lIl 0(p -0)=p 0g 0,l∑j∈Ap jg j,l+σ2.(3)
1.2 斯坦伯格分层博弈模型
在本文多无人机系统协同模型中,任务类型包含通信任务和侦察任务两类.因目标任务的重要程度不同,需要对LD和CD任务执行进行合理规划,任务目标重要程度较高的服务质量(QoS)需要首先得到保障.本文基于任务优先级以及任务目标需求的差异性,采用分层博弈模型来刻画领头无人机和协同无人机之间的任务目标调度和功率分配问题.在该博弈中,先做出决策的一方为领导者(leader),其余观测领导者的决策从而做出行动的一方称为跟随者(follower).本文将上层领头无人机视为领导者,下层协同无人机视为跟随者,利用分层斯坦伯格(Stackelberg)博弈模型刻画LD-CD之间的分层竞争交互关系.目标任务调度中,Stackelberg定义为
G={A,{P 0,C 0},{P i,C i} i∈A,{U 0},{U i} i∈A}, (4)
其中{P 0,C 0}和{P i,C i} i∈A分别表示LD和CD的策略空间,{U 0}和{U i} i∈A分别表示LD和CD执行目标任务效用函数.
对于执行通信服务任务的无人机,无人机效用函数的设计同时考虑了目标任务的满意度和功率消耗.对于给定的通信目标k,LD的效用函数可以表示为
Uk 0(p 0,p -0)=Uk 0(p 0,p -0)-Ck 0(p 0,p -0)=
11+exp(-αk 0(γk 0-βk 0))·v k-μ 0p 0. (5)
该效用函数包含两部分:第一部分为服务通信任务目标对象的收益Uk 0(p 0,p -0) ,被建模为S型函数,代表所服务通信目标任务的满意度;第二部分是代价函数Ck 0(p 0,p -0),表示动态的功率开销,其中的参数α 0和β 0分别为S型函数的陡度和中心值.v k代表通信任务目标k的价值.μ 0为常数,用来权衡服务目标的满意度和功率能量消耗.当给定CD i服务第k个通信任务目标时,其效用函数可以表示为
Uk i(p i,p -i)=Uk i(p i,p -i)-Ck i(p i,p -i)=
11+exp(-αk i(γk i+θk i-βk i))·v k-
μ ip i-λ ig i,0p i-κ ip i,0, (6)
其中,CD i的收益函数部分同时考虑了服务通信任务目标对象的满意度和通信上传的满意度,θ为常数,用于折中通信下行信噪比和上传信噪比.此外α i和β i分别为函数陡度和中心值.CD i代价函数部分同时考虑了执行目标任务的功率消耗、上传通信信息的功率消耗和下层CD i对上层LD通信服务的干扰惩罚.κ i表示上传通信信息功率消耗系数,λ i表示干扰惩罚参数,用于调节跨层干扰对上层服务目标的影响.当CD i增加发射功率时,服务任务目标对象的满意度增加,同时将会对上层LD带来更高的跨层干扰,影响LD服務任务目标的QoS,因此CD i需要进行折中优化.
对于执行侦查服务任务的无人机,无人机侦察效用函数的设计同样包括目标任务的满意度和功率消耗两部分.侦察目标任务调度中,每一架无人机对各个任务目标的分辨率为定值,构建分辨率矩阵.给定LD服务侦察任务目标时,其侦察效用函数可以表示为
Ux 0=Ux 0-Cx 0=
v x1+exp-αx 0 rx 0dx 0 ·p′ 0-βx 0 -δ 0p′ 0. (7)
该效用函数包括两个部分,Ux 0 表示服务侦察任务目标的收益,Cx 0 表示服务侦察目标的代价,即LD图像识别的功率消耗.其中,rx 0 为LD对任务目标的分辨率,dx 0 为LD与任务目标距离,侦察收益建模为S型函数,δ 0为图像识别功率消耗比例常数.当给定CD i服务侦察任务目标x时,其侦察效用函数可以表示为
Ux i=Ux i-Cx i=
v x1+exp-αx i rx idx i τx i p′ i-βx i -
ig i,0(1-τ i)p′ i-δ iτ ip′ i, (8)
其中代价函数部分同时考虑了图像上传的功率消耗和LD识别的功率消耗,p′ i 为每个CD i进行侦察任务的总功率,τ i用于识别计算处理的功率比例,1-τ i表示识别完成后侦察信息上传功率消耗比例, i为侦察信息上传干扰惩罚参数,用来权衡侦察信息上传对领头无人机产生的干扰,δ i为常数,权衡CD i用于拍照的功率消耗,默认δ 0=δ i.
2 斯坦伯格均衡求解
定义符号Φ i={p i,c i},Φ -i={Φ 0,Φ 1,…,Φ i-1,Φ i+1,…,Φ N},Φ m={Φ 1,Φ 2,…,Φ N}.
定义1 (斯坦伯格均衡,Stackelberg Equilibrium,SE)[18] Φ* 0 表示上层博弈最大化效用函数的最佳相应策略,Φ* m 表示下层博弈的最佳响应策略.对于任意的策略组合,均满足以下条件:
U 0(Φ* 0,Φ* m)≥U 0(Φ 0,Φ* m), (9)
U i(Φ* i,Φ* -i)≥U i(Φ i,Φ* -i). (10)
(Φ* 0,Φ* m)称为斯坦伯格均衡.LD最优策略由下层博弈最佳响应策略给定,最大化自身效用函数求解.同理,CD的最优策略是由给定上层博弈的最佳相应策略,最大化自身效用函数求解.通过逆向递推法寻求上下两层子博弈的均衡,如图2所示.
2.1 下层均衡求解
给定上层LD的任务目标选择和发射功率,每一个CD独立地选择最佳策略来最大化自身效用函数,因此,下层子博弈定义为
G={A,{Φ i} i∈A,{U i} i∈A}. (11)
定理1 给定其他无人机的策略Φ -i,CD i最优的通信任务目标选择:
t* i=arg maxg i,kIk i(p -i)+θε ig i,0Ik i(p -i,0)v k. (12)
证明 当给定其他无人机策略Φ -i,令p i,0=ε ip i,Λ i=g i,kIk i(p -i)+θε ig i,0Ik i(p -i,0),CD i服务于任意两个通信任务目标k和l,假定Λk i≥Λl i,v k≥v l,显然,γk i+θk i≥γl i+θl i,然后计算服务不同任务目标的效用差值为
Uk i-Ul i=Uk i-Ul i=
v k1+exp(-α i(γk i+θk i-β i))-
v l1+exp(-α i(γl i+θl i-β i))≥0. (13)
因此,CD i最优通信任务目标t* i=arg maxg i,kIk i(p -i)+θε ig i,0Ik i(p -i,0)v k,定理1得证.
CD i通过定理1确定最优通信任务目标,然后进一步优化发射功率最大化效用函数.为方便求解,令Γ i=γt i i+θt i i,pt i i,0=ε ipt i i,其Ut i i 对p i求偏导得:
dUt i idp i=Ut i i ′(Γ i)d(Γ i)dp i-dC idp i. (14)
令dUt i idp i=0,即得:
Ut i i ′(Γ i)d(Γ i)dp i=dC idp i. (15)
令g i,t iIt i i(Φ -i)+θε ig i,0It i i(Φ -i,0)=1B i,即得:
Ut i i ′(Γ i)=(μ i+κ iε i+λ ig i,0)×B i. (16)
令Ψ(Γ i)=Ut i i ′(Γ i),可得:
Γ i=Ψ-1[Ut i i ′(Γ i)]= Ψ-1[(μ i+κ iε i+λ ig i,0)×B i].(17)
S型函數倒数满足以下关系:
Ut i i ′(Γ i)=α iUt i i(Γ i)[1-Ut i i(Γ i)].(18)
根据式(16)和式(18)可得:
p* i=B iβ i-B iα i×lnA i2-1-A i2-12-1, (19)
其中A i=α i×v t i(μ i+κ iε i+λ ig i,0)×B i.下层调度通信任务目标和上传信息总信噪比和为
Γ i=β i-1α i×lnA i2-1-A i2-12-1.(20)
CD的通信效用函数即可转化为
Ut i i(Γ i)=v t i1+exp(-α i(Γ i-β i))- (μ i+κ iε i+λ ig i,0)·B i·Γ i. (21)
通过式(18)和代价直线是一条过原点的切线[19]可得:
U′ i(Γ i)Γ i=U i(Γ i).(22)
经过运算参数β i可以设置如下:
β i=Γ i-ln(α iΓ i-1)α i. (23)
同理,令p′ i=p i,侦察效用值由式(8)求得,比较所有侦察任务目标效用值,选择最优侦察任务目标x* i.若效用值为负,此时p′ i=0,选择放弃该任务目标的侦察任务.分析通信侦察效用值,确定最优的任务目标选择为c* i.假设对于任意的i,B i·Ψ-1[(μ i+κ iε i+λ ig i,0)×B i]在区间[L i,H i]上为增函数,其中g i,t iIt i i(Φ -i)+θε ig i,0It i i(Φ -i,0)=1B i,L i=min[L1 i,L2 i,…,Lm i],H i=max[H1 i,H2 i,…,Hm i].下层迭代中CD的功率控制形式为pt* i i(k+1)=min[p1 i(k+1),p2 i(k+1),…,pm i(k+1)],其中pt i i(k+1)=Ft i i(p(k)).令F i(p(k))=min[F1 i(p(k)),F2 i(p(k)),…,Fm i(p(k))],最终功率更新迭代和服务任务目标迭代策略为
p* i(k+1)=F i(p(k)), (24)
c* i(k+1)=arg max(Ut* i i,Ux* i i). (25)
下层博弈中,上述任务目标选择和策略更新迭代过程最终收敛在唯一的纳什均衡点.下面引入标准干扰函数相关内容辅助证明.
定义2(唯一性证明)[20] 如果函数F(p)满足以下条件,则该函数为标准干扰函数:
1)非负性:F(p)>0;
2)单调性:对于任意p1>p2,则F(p1)>F(p2);
3)伸缩性:对于任意τ>1,则τF(p)>F(τp).
如果函数F1(p)和F2(p)为标准干扰函数,其组合函数也必然满足标准函数特性;如果博弈参与者最佳响应函数为标准干扰函数,则该博弈必然存在唯一的纳什均衡解.
定理2 下层博弈中CD服务通信任务目标的功率迭代更新为标准干扰函数,即p* i(k+1)=F i(p(k)),将从任意可行的初始值收敛到唯一的纳什均衡点.
证明 对于CD i中任意一个任务目标t i,即pt i i=Ft i i(p),则有
Ft i i(p)=B i·Γ i=B i·Ψ-1[(μ i+κ iε i+λ ig i,0)×B i],
其中g i,t iIt i i(Φ -i)+θε ig i,0It i i(Φ -i,0)=1B i.下层CD策略调整时,由于上层LD的策略是固定不变的,下层其他CD的策略也不会影响当前CD策略,只受其余CD发射功率的影响,因此It i i(Φ -i)=It i i(p -i).
1)非负性:由于背景噪声非零,因此B i>0,非负性满足条件.
2)单调性:如果p1>p2,则It i i(p1 -i)>It i i(p2 -i),It i i(p1 -i,0)>It i i(p2 -i,0),因为函数B i·Ψ-1[(μ i+κ iε i+λ ig i,0)×B i]在区间[L i,H i]上为增函数,其中L i=min[L1 i,L2 i,…,Lm i],H i=max[H1 i,H2 i,…,Hm i],因此Ft i i(p1)>Ft i i(p2),单调性满足条件.
3)伸缩性:对于任意τ>1,则有
Fm i(τp)-τFm i(p)=
1η 1·Ψ-1ω×1η 1-τ1η 2·Ψ-1ω×1η 2<
1η 1·Ψ-1ω×1η 2-τ1η 2·Ψ-1ω×1η 2<0,
其中η 1=g i,mIm i(τp -i)+θε ig i,0Im i(τp -i,0),η 2=g i,mIm i(p -i)+θε ig i,0Im i(p -i,0),ω=μ i+κ iε i+λ ig i,0.因此,伸缩性满足条件.故pt i i(k+1)=Ft i i(p(k))为标准干扰函数.假定第k+1次迭代,服务的通信任务目标为t* i(k+1),功率更新迭代可得:
pt* i i(k+1)=min[p1 i(k+1),p2 i(k+1),…,pm i(k+1)]=
min[F1 i(p(k)),F2 i(p(k)),…,Fm i(p(k))].
因F1 i(p(k)),F2 i(p(k)),…,Fm i(p(k))均为标准干扰函数,由此可得pt* i i(k+1)=F i(p(k))为标准干扰函数,下层子博弈迭代更新函数必然存在唯一的纳什均衡解,得证.
2.2 上层均衡求解
上层子博弈定义为
G={{0},{Φ 0},{U 0}}, (26)
則其LD最优的通信任务目标选择为
t* 0=arg maxg 0,kIk 0(p -0)·v k. (27)
同理,进一步优化发射功率最大化效用函数可得:
p* 0=B 0γ 0=B 0β 0-B 0α 0×lnA 02-1-A 02-12-1, (28)
Ut 0 0(Γ 0)=v t 01+exp(-α 0(γ 0-β 0))-μ 0·B 0·γ 0, (29)
其中B 0=Ik 0(p -0)g 0,k,A 0=α 0·v t 0μ 0·B 0.上层侦察任务目标效用值由式(7)求得,比较所有侦察任务效用值,选择最优侦察任务目标x* 0.类似于下层子博弈的迭代更新,LD的功率迭代更新为
pt* 0 0(k+1)=min[p1 0(k+1),p2 0(k+1),…,pm 0(k+1)]=
min[F1 0(p(k)),F2 0(p(k)),…,Fm 0(p(k))]. (30)
因此,LD服务任务目标和功率更新策略为
p* 0(k+1)=F 0(p(k)), (31)
c* 0(k+1)=arg max(Ut* 0 0,Ux* 0 0).(32)
3 算法流程
子博弈循环采用一般迭代算法求解,达到斯坦伯格均衡迭代结束,上下层目标任务分配不再改变.具体流程如图3所示.
4 仿真分析
对于无人机位置、无人机所服务的通信和侦察任务目标个数、通信和侦察任务目标价值等信息构建场景进行仿真分析,同时通过调整无人机位置,设定不同场景对上下层博弈交互进行迭代更新,验证算法的收敛性.
4.1 参数设置
场景设置参数如下:LD可服务任务目标区域半径为500 m,10个CD随机分布在LD调度范围内,其可服务任务目标半径为80 m,通信和侦察任务随机分布在LD和CD服务范围内.LD可服务的通信任务目标和侦察任务目标均为3个. CD可服务的通信和侦察任务目标个数分别依次为4、5、4、5、4、4、5、3、4、3和3、4、2、4、3、2、4、1、2、2.LD所服务的通信和侦察任务目标价值v=1,CD所服务的通信和侦察任务目标价值相对较低,取值在[0.9,0.95]内随机生成. 其中CD i到任务目标j的信道增益g i,j=d-2 i,j,d-2 i,j表示对应的距离,信号衰减为25 dB.LD所服务通信任务目标信噪比为γ 0=30 dB,CD所服务通信任务目标的信噪比和上传信噪比均在[10,20]dB内随机生成.噪声功率σ2=10-8 mW.参数α i=0.2,θ=1,β i由式(23)确定.通信干扰惩罚和干扰代价参数设置为λ i=108,μ i=1,上传功率消耗参数为κ i=1.侦察任务中LD识别图像功率消耗δ 0=1,CD识别图像功率消耗δ i=1,上传干扰惩罚和上传功率比例参数设置为 i=108,τ i=0.6.表1中给出了LD和CD对侦察任务目标对象的分辨率大小.上述参数在后面仿真中均保持不变.图4中给出两种无人机不同位置下的仿真场景.
4.2 结果分析
图5给出了场景1和场景2中相应的LD和CD的效用迭代更新曲线,每一轮迭代15次,共设置20轮,横坐标为迭代轮数,纵坐标为各无人机效用值.给定上层的目标任务选择后,下层为满足通信任务目标的最小信噪比需求进而优化最小的发射功率,在每一轮的15次迭代的过程中,由于功率在增大,各协同无人机之间的同层干扰逐渐增大,需要不断地增大功率满足信噪比需求,不断迭代直至下层稳定.上层迭代过程中,由于協同无人机的功率在增大,跨层干扰在增大,领头无人机需要增大发射功率满足自身的信噪比需求,直至上层稳定.结合图6中场景1和场景2中相应的LD和CD的各轮目标的迭代变化曲线,分析得出效用曲线中的转折点为无人机依据效用值的变化选择侦察任务目标.从效用的更新曲线来看,上下层博弈交互迭代后最终均能够达到收敛状态,验证了所提算法的收敛性能.
表2中给出了上下层子博弈达到斯坦伯格均衡时无人机最优通信和侦察任务分配结果.各无人机能够自主进行服务通信或侦察目标优化分配.其中,T u,0为领头无人机通信任务目标,T z,0为领头无人机侦察任务目标,T u,1~T u,10为各协同无人机的通信任
务目标,T z,1~T z,10为各协同无人机的侦察任务目标(以T u,0=1为例,表示领头无人机均衡下选择1号通信任务目标).
4.3 系统效用对比
图7a与7b中给出了任务目标调度过程中联合考虑通信和侦察任务、只考虑通信任务和只考虑侦察任务三种状态下的系统效用值变化.在所用算法下,考虑通信任务的收益由于需要满足信噪比需求,功率增大过程中同层和跨层干扰在增大,使得在决策过程中效用值呈现下降的趋势.可以看出,上下层博弈最终收敛至均衡点,所用算法的系统效用值均大于只考虑通信或者侦察单个指标.图7c与7d中联合考虑通信侦察任务下依据所用算法、最大任务目标价值和随机决策三种方法进行任务目标选择,横坐标为迭代轮数,纵坐标为系统效用值,可以看出,所用算法系统效用值均大于依据最大价值选择和随机决策两种方法,并能够有效提高多无人机系统的整体效用.
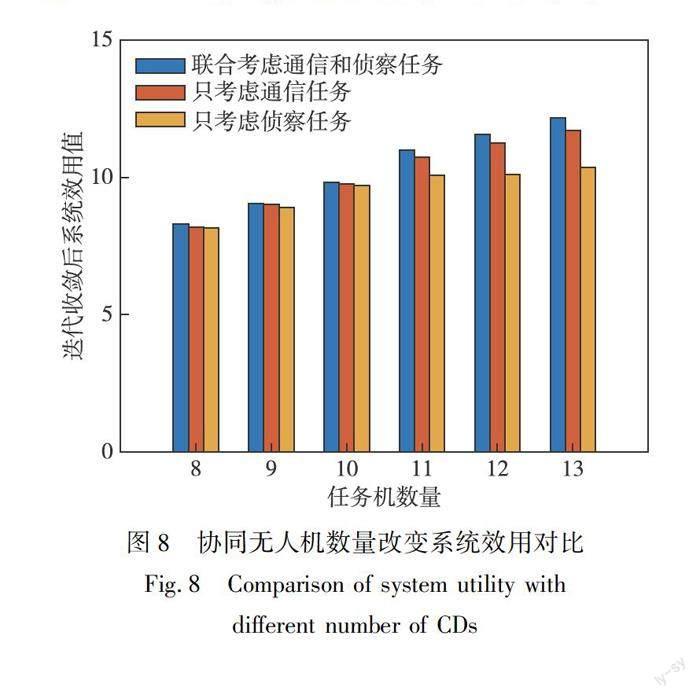
图8分别给出了8、9、10、11、12、13架协同无人机情况下系统的效用值对比.协同无人机数量的改变构成不同的场景,可以看出,上下层博弈交互迭代达到斯坦伯格均衡后,联合考虑通信侦察任务的效用值均大于考虑通信或者侦察单个指标情况.
5 结束语
多无人机通信和侦察任务分配在无人集群网络优化中具有重要的研究意义.本文聚焦于无人机网络中目标调度和功率控制的联合优化,利用分层博弈框架分析领头无人机和协同无人机的决策行为,采用分布式策略迭代更新算法求解Stackelberg均衡,实现无人机最优目标任务调度.对多个场景进行仿真分析,验证了所提算法能够在多无人机系统中实现分布式任务分配的收敛和系统稳定,并有效提高了多无人机系统遂行任务的整体效用.
参考文献
References
[1] 宗群,王丹丹,邵士凯,等.多无人机协同编队飞行控制研究现状及发展[J].哈尔滨工业大学学报,2017,49(3):1-14
ZONG Qun,WANG Dandan,SHAO Shikai,et al.Research status and development of multi UAV coordinated formation flight control[J].Journal of Harbin Institute of Technology,2017,49(3):1-14
[2] 张可为,赵晓林,李宗哲,等.多无人机侦察任务分配方法研究综述[J].电光与控制,2021,28(7):68-72,82
ZHANG Kewei,ZHAO Xiaolin,LI Zongzhe,et al.A review of multi-UAV reconnaissance mission assignment methods[J].Electronics Optics & Control,2021,28(7):68-72,82
[3] Zhang L,Zhu Y A,Shi X C.A hierarchical decision-making method with a fuzzy ant colony algorithm for mission planning of multiple UAVs[J].Information,2020,11(4):226
[4] Huang T Y,Wang Y,Cao X W,et al.Multi-UAV mission planning method[C]//2020 3rd International Conference on Unmanned Systems(ICUS).November 27-28,2020,Harbin,China.IEEE,2020:325-330
[5] Du X Y,Guo Q C,Li H,et al.Multi-UAVs cooperative task assignment and path planning scheme[J].Journal of Physics:Conference Series,2021,1856(1):012016
[6] 赵雪森,王社伟,邵校.基于改进量子粒子群优化算法的多UCAV协同任务分配研究[J].四川兵工学报,2015,36(10):120-124
ZHAO Xuesen,WANG Shewei,SHAO Xiao.Cooperative task allocation for multiple UCAV based on improved quantum-behaved particle swarm optimization algorithm[J].Journal of Sichuan Ordnance,2015,36(10):120-124
[7] 唐峯竹,唐欣,李春海,等.基于深度强化学习的多无人机任务动态分配[J].广西师范大学学报(自然科学版),2021,39(6):63-71
TANG Fengzhu,TANG Xin,LI Chunhai,et al.Dynamic task allocation method for UAVs based on deep reinforcement learning[J].Journal of Guangxi Normal University(Natural Science Edition),2021,39(6):63-71
[8] 王树朋,徐旺,刘湘德,等.基于自适应遗传算法的多无人机协同任务分配[J].电子信息对抗技术,2021,36(1):59-64
WANG Shupeng,XU Wang,LIU Xiangde,et al.Cooperative task assignment for multi-UAV based on adaptive genetic algorithm[J].Electronic Warfare Technology,2021,36(1):59-64
[9] Quan B,Lu X M,Zhang Y M,et al.A multi-objective tracking task assignment algorithm based on game theory[J].Journal of Physics:Conference Series,2021,1802(3):032115
[10] Fu X W,Pan J,Gao X G,et al.Task allocation method for multi-UAV teams with limited communication bandwidth[C]//2018 15th International Conference on Control,Automation,Robotics and Vision(ICARCV).November 18-21,2018,Singapore.IEEE,2018:1874-1878
[11] 邸斌,周锐,丁全心.多无人机分布式协同异构任务分配[J].控制与决策,2013,28(2):274-278
DI Bin,ZHOU Rui,DING Quanxin.Distributed coordinated heterogeneous task allocation for unmanned aerial vehicles[J].Control and Decision,2013,28(2):274-278
[12] 嵇介曲,朱琨,易暢言,等.多无人机辅助移动边缘计算中的任务卸载和轨迹优化[J].物联网学报,2021,5(1):27-35
JI Jiequ,ZHU Kun,YI Changyan,et al.Joint task offloading and trajectory optimization for multi-UAV assisted mobile edge computing[J].Chinese Journal on Internet of Things,2021,5(1):27-35
[13] 陈璞,严飞,刘钊,等.通信约束下异构多无人机任务分配方法[J].航空学报,2021,42(8):306-319
CHEN Pu,YAN Fei,LIU Zhao,et al.Communication-constrained task allocation of heterogeneous UAVs[J].Acta Aeronautica et Astronautica Sinica,2021,42(8):306-319
[14] 潘楠,刘海石,陈启用,等.多基地多目标无人机协同任务规划算法研究[J].现代防御技术,2021,49(2):49-56
PAN Nan,LIU Haishi,CHEN Qiyong,et al.Study on cooperative mission planning algorithm for multi-base and multi-target UAV[J].Modern Defense Technology,2021,49(2):49-56
[15] 蒋硕,袁小平.改进PSO算法在多无人机协同任务分配中的应用[J].计算机应用研究,2019,36(11):3344-3347,3360
JIANG Shuo,YUAN Xiaoping.Application of improved PSO algorithm in multi UAV cooperative task allocation[J].Application Research of Computers,2019,36(11):3344-3347,3360
[16] Chen R F,Cui L,Zhang Y L,et al.Delay optimization with FCFS queuing model in mobile edge computing-assisted UAV swarms:a game-theoretic learning approach[C]//2020 International Conference on Wireless Communications and Signal Processing(WCSP).October 21-23,2020,Nanjing,China.IEEE,2020:245-250
[17] Buckman N,Choi H L,How J P.Partial replanning for decentralized dynamic task allocation[C]//AIAA Scitech 2019 Forum.San Diego,California.Reston,Virginia:AIAA,2019.DOI:10.2514/6.2019-0915
[18] 楊婷婷,宋绯,孙有铭,等.面向异构无人机中继网络的负载均衡:一种分层博弈方法[J].通信技术,2018,51(11):2619-2626
YANG Tingting,SONG Fei,SUN Youming,et al.Load balancing in heterogeneous UAV relay network:a Stackelberg game method[J].Communications Technology,2018,51(11):2619-2626
[19] Xiao M B,Shroff N B,Chong E K P.A utility-based power-control scheme in wireless cellular systems[J].IEEE/ACM Transactions on Networking,2003,11(2):210-221
[20] Sun Y M,Wang J L,Sun F G,et al.Energy-aware joint user scheduling and power control for two-tier femtocell networks:a hierarchical game approach[J].IEEE Systems Journal,2018,12(3):2533-2544
Multi-UAV cooperative task allocation for multi-point
reconnaissance and communication service
YAO Changhua1 AN Lei1 LIU Xin2 HAN Guizhen1 GAO Zehe1
1School of Electronics & Information Engineering,Nanjing University of Information Science & Technology,Nanjing 210044
2College of Information Science and Engineering,Guilin University of Technology,Guilin 541006
Abstract Aiming at the collaborative optimization of multi-UAV reconnaissance and communication service for multiple heterogeneous targets,the Stackelberg game model is constructed by considering the mission requirements and target values,as well as the restriction between multi-UAV coordination gain and task behavior.The upper-level drone is established as the leader of the game,while the lower-level drones are established as the followers of the game,and then a distributed strategy update iterative algorithm is proposed,which realizes the stable convergence of the multi-UAV task allocation scheme and the optimization of the task revenue.Simulation results show that the proposed approach can effectively improve the efficiency of multi-UAV systems to complete multiple tasks at the same time,and can achieve efficient collaboration for the values of heterogeneous tasks in different environments.
Key words multi-UAV system;task allocation;Stackelberg game;iterative algorithm
