ChatGPT在网络安全领域的应用、现状与趋势
2023-06-10翁方宸张玉清
张 弛 翁方宸 张玉清,
1(国家计算机网络入侵防范中心(中国科学院大学) 北京 101408)
2(海南大学网络空间安全学院 海口 570228)
ChatGPT在2022年11月30日正式推出后,短短5天就获得百万注册用户,而在2个月后月活用户已经突破了1亿,其火爆程度令人惊叹.ChatGPT展现出极强的语言理解和文本生成能力,在各行各业受到巨大的关注,并获得普遍正面的评价.
纵观人类社会发展历程,每一次重大技术革新,网络空间安全也将伴随着新技术的出现产生持续动态的变化,以ChatGPT为代表的大型语言模型技术将为网络空间安全引入新的变革.不仅可以依托于ChatGPT强大的能力,应用于安全领域,提升安全领域的整体势能,起到赋能效应,同时在ChatGPT应用过程中也会不断地伴生着新的安全问题产生,存在伴生效应.为了使研究人员对ChatGPT在网络安全领域的进展有更清楚的了解,本文将从ChatGPT在安全领域的赋能效应和安全问题的伴生效应2个方面阐述ChatGPT的安全问题,并对ChatGPT在网络安全领域的未来进行展望.本文的主要工作和贡献如下:
1) 详细介绍了ChatGPT在安全领域的赋能效应,从助力攻击和助力防御2个方面分析了ChatGPT在漏洞挖掘、利用和修复,恶意软件的检测和识别,钓鱼邮件的生成和检测以及安全运营场景下的潜在用途,揭示了ChatGPT在安全领域的重要价值和应用前景.
2) 深入剖析了ChatGPT在安全领域的伴生风险,包括ChatGPT的内容风险和提示注入攻击,并针对风险和攻击进行了详细的分析和探讨,这对于该领域的研究和实践具有重要的参考意义.
3) 从安全赋能和伴生安全2个角度,针对ChatGPT的能力、ChatGPT的应用场景、大型语言模型的安全风险、提示注入攻击、基于语言模型的衍生应用存在的安全风险以及对人工智能失控的担忧6个方面,对ChatGPT在网络安全领域的未来进行详尽讨论和展望,为相关研究人员指出了研究方向.
1 ChatGPT概述
本节将从大型语言模型技术的发展、ChatGPT的模型技术和涌现能力2个方面对ChatGPT进行概述,以便在后文介绍该技术与安全结合的研究成果.
1.1 大型语言模型技术的发展
自从图灵测试被提出以来,自然语言处理(natural language processing, NLP)任务一直是备受关注的研究课题.语言建模作为语言理解和生成的一种主要方法,在过去的20年里得到了广泛的研究,经历了从基于规则语言模型到统计语言模型,再到神经语言模型的技术发展.近年来,通过在大规模语料库中进行预训练,提出了预训练语言模型(pre-training language model, PLM),在各种自然语言处理任务中展现出强大的能力.研究者们在实验中发现,当参数规模超过一定水平时(数千亿或更多),这些扩大的语言模型不仅实现了显著的性能改进,而且还显示了一些在小规模语言模型中没有的特殊能力,如上下文学习.由此便诞生了大型语言模型(large language model, LLM),即大规模的PLM,其在很大程度上扩展了模型大小、预训练数据和总计算量.现有LLM的主流结构可以大致分为编码器-解码器、基于casual掩码的解码器和基于prefix掩码的解码器3大类,OpenAI提出的GPT系列模型采用的是基于casual掩码的解码器结构[1].
1.2 ChatGPT的模型技术和涌现能力
本节将从GPT系列模型的变更以及在GPT-3模型上的3次微调技术,对ChatGPT的涌现能力进行分析.
1.2.1 GPT系列模型
第1代的GPT(generative pre-training)利用大量无标记数据预训练语言模型.其核心思想是通过Transformer的编码器学习上下文信息,通过Transformer的解码器生成下一个词.在训练过程中,GPT-1通过最大化下一个词的概率学习语言模型.随后提出的GPT-2模型和GPT-3模型都进一步扩大了训练数据集和参数规模.GPT-2的参数规模达到了15亿,GPT-3则最多包含了1750亿个参数.随着参数的激增,其涌现出来的能力也越来越强,GPT-3模型在很多NLP任务上都取得了不错的效果,甚至在某些结果上已经十分接近人类[2].虽然随着参数增多,模型能力越来越强,但是其生成的内容并不能真正符合用户的预期,模型可能会生成虚假、有毒或者无用的结果.
1.2.2 GPT-3的微调
为了缓解上述问题,同时增强模型的能力,OpenAI在GPT-3模型上使用3种微调技术:首先使用代码对模型进行微调,增强了模型在代码生成和代码理解上的能力以及加强了逻辑思维能力;与此同时基于指令对模型进行微调,增强了模型的指令遵循能力和在零样本时的能力,并以此发布Codex模型[3];最后基于人类反馈强化学习(reinforcement learning from human feedback, RLHF)对模型进行微调,并提出了InstructGPT模型[4],通过人类的反馈使模型和人类的意图对齐,能够生成更符合人类期望的回复,同时拒绝其知识范围之外的问题.
1.2.3 ChatGPT的能力
ChatGPT和InstructGPT模型一样使用了RLHF技术对原有模型进行微调,但侧重于增强对话能力.ChatGPT从GPT-3模型上获取文本生成、上下文学习和世界知识的能力,从代码训练获得代码生成和代码理解的能力,从指令微调获得指令遵循和泛化能力,最后通过RLHF获取和人类对齐的能力.这些随着模型规模扩大展现出的能力被称为涌现能力,文献[5]分析了这些能力出现的原因.
2 ChatGPT的安全赋能
ChatGPT这类大型语言模型具备强大的通用性能力,因此可应用于安全领域,提升安全领域的潜力.本节将从攻击支持和防御支持2个方面详细介绍ChatGPT在安全领域的应用效果.
2.1 ChatGPT助力攻击
借助ChatGPT的代码生成和理解能力以及其文本生成能力,可以支持攻击,使网络安全形势更加严峻.下面将从漏洞挖掘与利用、恶意软件编写和钓鱼邮件编写3个场景介绍ChatGPT在攻击支持方面的表现.
1) 漏洞挖掘与利用.
ChatGPT可通过分析代码和注释,快速定位目标代码中可能存在的漏洞并生成针对漏洞的攻击代码,使攻击者能更快地设计和实施攻击.图1(a)展示了ChatGPT的漏洞挖掘和利用生成能力.相较于传统依赖特征和规则的漏洞挖掘工具,ChatGPT具有更广泛的安全知识,包括存在漏洞的代码、函数和库文件,同时具有更好的逻辑推理能力,能更深入理解代码间的逻辑.文献[6]使用GPT模型挖掘了213个漏洞,而商业工具仅发现99个.在漏洞利用方面,ChatGPT可帮助资源和知识有限的攻击者快速编写漏洞利用代码,文献[7]展示了ChatGPT在多种场景下进行漏洞利用的能力.

图1 ChatGPT助力攻击
2) 恶意软件编写.
ChatGPT能生成用于实施特定攻击的恶意代码[8].图1(b)展示了使用ChatGPT编写的恶意软件示例.文献[9]利用ChatGPT编写同一恶意代码的多种变体,通过改变API调用和程序逻辑,创建高度隐蔽且难以检测的多态程序.如图1(c)所示,相较于传统的恶意软件在编译后攻击目标和意图确定,基于ChatGPT编写的程序具有高度模块化和适应性,攻击者通过良性可执行文件与ChatGPT交互获取恶意代码动态执行.这种方式在流量上与OpenAI的高信誉域名通信,文件落地后磁盘和内存中不包含可疑逻辑,可规避依赖签名进行检测的安全产品.
3) 钓鱼邮件编写.
ChatGPT可帮助编写钓鱼邮件,其所编写的内容真实性更高,针对性更强,能更好地伪装成受害者信任的个人和组织,提高钓鱼邮件的成功率.同时,借助ChatGPT的能力降低了人工编写的成本.图1(d)为ChatGPT生成的钓鱼邮件文案.DEFCON中研究人员基于GPT模型构建了一个高度自动化的鱼叉钓鱼系统[10].
综上所述,ChatGPT在助力攻击方面:能加速攻防迭代速度,与人工编写相比可批量生成大量多态的恶意软件;能降低攻击者的入门门槛,帮助更快地挖掘和利用漏洞;能提升安全领域的自动化能力,将ChatGPT融入攻击流程,可提高攻击者的攻击效率.
2.2 ChatGPT助力防御
安全作为防御领域,ChatGPT用于提升防御能力也是自然而然的.下面将从漏洞挖掘与修复、恶意软件检测、钓鱼邮件检测和安全运营处理4个场景介绍ChatGPT在防御方面的表现.
1) 漏洞挖掘与修复.
ChatGPT的漏洞挖掘能力可用于防御,企业拥有完善的源码,可以在应用上线前发现更多安全漏洞.如图2(a)所示,ChatGPT不仅挖掘漏洞,相较传统漏洞扫描或静态应用安全测试工具给出的模板化修复方案,它提供更具针对性的修复建议,并通过交互指导漏洞修复过程.文献[11]证明了GPT模型在零样本条件下具备修复软件漏洞能力,无需额外训练.

图2 ChatGPT助力防御
2) 恶意软件检测.
ChatGPT能分析代码工作原理,具有强大的逆向分析能力[12].传统逆向分析恶意软件需知识与经验,耗费人力.使用ChatGPT提高恶意软件分析师工作效率.如图2(b)所示,ChatGPT识别击键窃取代码.卡巴斯基[13]实验证明ChatGPT可批量识别恶意软件.对复杂恶意软件,ChatGPT与分析师交互,获得反馈后更好地逆向分析软件,给分析师提供建设性建议.
3) 钓鱼邮件检测.
ChatGPT通过分析邮件内容检测钓鱼风险.如图2(c)所示,将邮件内容输入ChatGPT,判断邮件是否恶意.相较传统基于规则、特征字或域名的钓鱼邮件检测方案,ChatGPT从内容及意图上能更好地甄别钓鱼邮件.
4) 安全运营处理.
ChatGPT用于安全运营任务,包括日志解析、安全事件响应、安全告警评估等[14].图2(d)展示了ChatGPT安全日志分析能力.安全运营团队面对大量告警,需手动操作工具核查.ChatGPT简化安全流程,让用户直观看到重要安全信息,制定防护对策,提高安全运营效率.
综上所述,ChatGPT在助力防御方面:在代码理解上优于传统基于特征和规则检测方案,能够帮助漏洞的挖掘和恶意软件检测;在内容理解上解决传统方案无法解决的内容理解问题,能够助力基于内容的钓鱼邮件检测以及日志内容的解析;在结果输出上并非输出呆板模块化内容,能与用户交互,帮助用户在漏洞修复、复杂软件逆向以及安全运营处理上更好地理解内容,缩小攻防双方的技术和知识差距,提高防御效率.
3 ChatGPT的伴生安全
ChatGPT在使用过程中不断地伴生着新的安全问题产生.ChatGPT生成的内容存在内容风险,可能出现不安全输出.此外,由于需要与用户进行交互,恶意输入可能导致ChatGPT发生非预期的输出,进而产生提示注入问题.本节将从内容风险和提示注入2个方面详细介绍ChatGPT在应用过程中的伴生风险.
3.1 ChatGPT的内容风险
ChatGPT可以生成各种类型的文本内容,例如邮件、文章或诗歌.它有许多潜在的商业或教育应用,但其所生成的内容存在一定安全风险,使其不适合在无监督的情况下生成内容.下面将从有害(harm)、幻觉(hallucination)、偏见(bias)和隐私(privacy)4个方面探讨ChatGPT所生成内容存在的安全风险.
1) 有害.
ChatGPT需要对齐用户的偏好,而用户可能恶意诱导ChatGPT生成有害的内容,包括色情或暴力内容、骚扰、贬低、仇恨、欺骗或欺诈、侵犯他人隐私以及可能造成高风险的内容[15].ChatGPT既要尽可能地回答用户提出的问题,又要保证回答符合道德伦理,这是一件非常有挑战的事情.
2) 幻觉.
ChatGPT生成的文本可能存在幻觉倾向,即发生与客观事实不符或不合理的现象.需要强调的是,与直觉相反,随着ChatGPT变得越来越真实,幻觉反而变得更加危险.因为ChatGPT越真实用户就越信任,但ChatGPT无法一直提供真实信息.尤其是在医学、金融、法律等非闲聊式场景存在极高的风险.
3) 偏见.
ChatGPT存在偏见,包括“表示偏见”(representation),“分配偏见”(allocation)和“服务质量偏见”(quality of service).这些偏见可能导致ChatGPT对某些群体或个体作出不准确或歧视性的预测或决策.随着ChatGPT逐渐融入到日常生活中,其所产生的偏见会在潜移默化中影响用户的意识形态,进一步加剧社会不平等的现象.
4) 隐私.
ChatGPT从公开可用的数据源中学习,其中可能包含私人数据和商业机密等敏感信息,导致模型在生成内容时可能会泄露隐私数据.意大利个人数据保护局以非法收集个人资料为由宣布将禁用ChatGPT[16].除此之外,在商业公司中,员工使用ChatGPT也会增加商业机密泄露的风险.例如在三星公司引入ChatGPT不到20天的时间,就发生了3次数据外泄事件[17].因此,使用ChatGPT需要格外注意隐私,以确保数据安全.
文献[18]从不同的角度讨论了语言模型在生成有害、幻觉、偏见和隐私方面的内容安全问题.相比传统的语言模型,ChatGPT使用的数据集更大,导致其包含的有毒数据更多,且其生成的内容更符合用户的预期,无疑放大了这些内容风险.正如OpenAI的CEO在ChatGPT发布之初就警告[19],ChatGPT依然存在令人难以置信的局限性,其只是一个前瞻性的展示产品,现在依赖ChatGPT来做任何重要的事情都是错误的.ChatGPT生成内容的风险就像一柄达摩克利斯之剑,时刻提醒着研究人员注意ChatGPT在生成内容时的伴生安全问题.
3.2 ChatGPT的提示注入
ChatGPT这类大型语言模型被训练为遵循人类提供的提示来执行操作.这些提示一般是可信和安全的,旨在指导ChatGPT执行特定任务.但也开辟了提示注入攻击(prompt injection attack)的可能性.根据注入目的不同,提示注入攻击可以分为越狱(jailbreak)、目的劫持(goal hijacking)和提示泄露(prompt leaking)3种类型.根据提示注入的方式,又可以分为直接提示注入和间接提示注入.下面将从越狱、目的劫持和提示泄露,以及间接提示注入3个方面介绍ChatGPT中的提示注入攻击.
1) 越狱.
在ChatGPT中,越狱是指通过精心构造的提示绕过模型的安全和审查措施,引导模型生成本应被开发者限制生成的内容[15].ChatGPT使用文献[20]提出的内容审核工具对ChatGPT所生成的内容进行审核,以防止有害内容和敏感信息的输出.但是,不断有研究者发现绕过这些限制的方法[21-22],如图3(a)所示,ChatGPT在越狱后说出了“毁灭人类”的暴力言论.文献[23]受到传统安全领域的启发,使用混淆、代码注入、有效负载拆分和虚拟化攻击手法,以100%的成功率实现了对ChatGPT的越狱.虽然文献[24-26]提出了许多对抗措施,主要是基于规则或过滤器的方案,GPT-4模型[27]也使用强化学习将模型响应不允许内容请求的倾向降低82%.但是,文献[28]依然实现了基于GPT-4模型的ChatGPT的越狱.

图3 提示注入攻击
2) 目的劫持和提示泄露.
用户会使用指令和数据一起作为提示输入给ChatGPT,但数据中可能会夹杂着恶意指令,实现对原始指令的篡改,引发提示注入的风险.根据篡改的注入目的不同,提示注入攻击可以分为目的劫持和提示泄露2种类型.其中,目的劫持侧重于修改提示以实现恶意输出,而提示泄露则侧重于获取提示本身的信息.
① 目的劫持.如图3(b)所示,攻击者篡改最初的翻译指令以让ChatGPT输出中文.虽然只是在ChatGPT的同一个上下文窗口中自我劫持,但这也是自限性问题.在基于GPT模型的应用中,这类风险会进一步放大.例如,Phithon使用GPT模型实现的评论内容审核机制因为目的劫持被绕过[29],Remoteli.io公司的机器人也因此在公共空间上发表有害信息[30].
② 提示泄露.如图3(c)所示,攻击者篡改最初的翻译指令,让ChatGPT泄露出原始的翻译指令细节.一个好的提示可以引导大型语言模型生成更符合预期的输出,是基于OpenAI API的开发应用中最重要且最机密的部分.但攻击者可以使用提示泄露攻击,复制特定应用程序的提示.例如,安全研究人员Swyx[31]利用提示泄露攻击手法成功获取了Notion AI用于文本润色的初始指令.
在数据中夹杂指令的提示注入与在网络安全领域中常见的其他注入攻击没有太大区别,它是连接指令和数据的结果,而语言模型无法区分它们.因此,攻击者可以在他们控制的数据字段中包含指令,并劫持系统执行恶意的操作.其中,文献[32]在GPT-3模型上取得了58.6%±1.6的目的劫持成功率和23.6%±2.7的提示泄露成功率.
3) 间接提示注入.
ChatGPT可以通过插件的方式获取外部信息,弥补其知识的局限性.然而,当语言模型从外部信息源获取到信息时,这些信息可能包含攻击者预先注入的恶意提示.当这些恶意提示被注入到语言模型的上下文中时,会引发间接提示词注入漏洞.文献[33]提出了6种间接提示词注入场景,并在最新的New Bing中完成了间接提示词注入的攻击示例.在进行代码补全时,Github Copilot也可以通过在关联文件中注入漏洞代码诱导模型生成漏洞代码[34].
提示注入攻击揭示了ChatGPT在与用户交互过程中面对用户恶意提示时的脆弱性.语言模型本身无法判断提示是善意目的还是恶意目的,也无法有效区分提示中的指令和数据内容.语言模型只是根据用户输入的内容预测下一个词.提示注入攻击是一种新型的漏洞,于2022年5月首次披露[35],并在2022年9月公开.随着更多的模型和应用场景被提出,其未来的研究工作还有很多.
4 未来与展望
本节将从安全赋能和伴生安全2个角度讨论和展望ChatGPT在网络安全领域的未来,试图给该领域未来的研究者提供一定的思路.表1示出ChatGPT在安全赋能和安全伴生场景下的挑战与机遇.
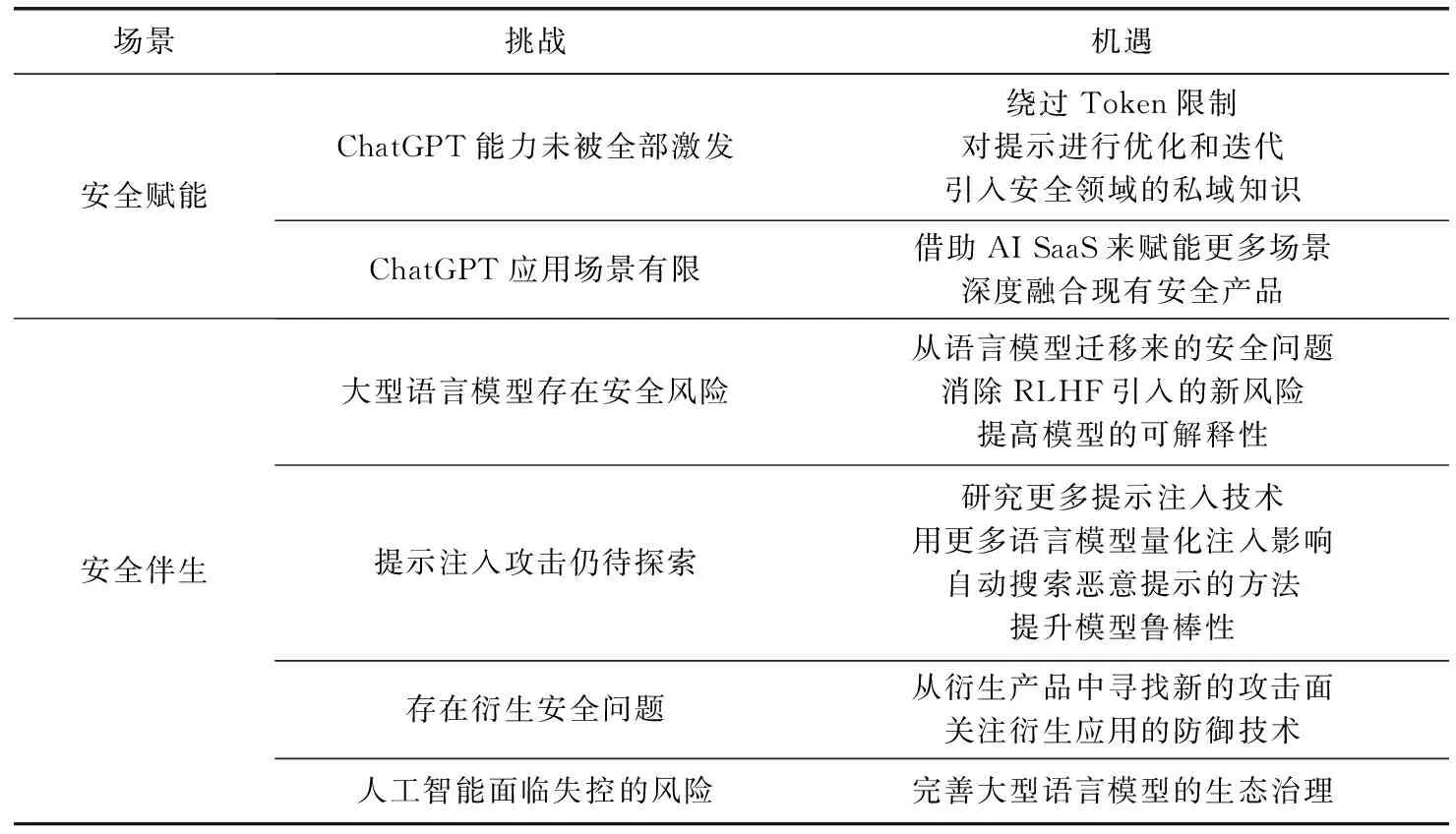
表1 ChatGPT在安全赋能和安全伴生领域的挑战和机遇
4.1 安全赋能
ChatGPT在安全领域的赋能效应不仅取决于其自身能力大小,还取决于所赋能的应用场景.下面将从ChatGPT的能力以及应用场景2个角度对ChatGPT在安全领域的赋能效应进行讨论.
1) ChatGPT的能力未被全部激发.ChatGPT目前的能力还未充分利用,可以优化和迭代出更好的提示,提升ChatGPT生成文本的质量,使之更契合安全任务的需求;可以尝试解决ChatGPT的Token限制,使得ChatGPT能够跨越多个代码文件进行漏洞挖掘,以及对复杂的代码或文本进行理解;也可以微调ChatGPT模型[36]或使用langchain技术[37]搭建本地向量知识库,引用更多安全领域的私域知识.
2) ChatGPT的应用场景有限.ChatGPT这类大型语言模型的应用不仅仅拘泥于一个会话框中,作为第三方软件的形式赋能安全领域,应与安全领域进行更深入的结合.随着越来越多的场景被挖掘,可以使用OpenAI提供的AI SaaS服务,通过API与当前安全工作流进行融合,如完成自动化鱼叉钓鱼攻击[10],协助IDA Pro作逆向分析的插件[12],也可以与微软推出的Security Copilot[38]一样,将大型语言模型深入融入到现有的安全产品中,更深层次地参与到安全赋能工作中.
4.2 伴生安全
ChatGPT从诞生之初到现在不过半年,在不断“狂飙”的背后遗留许多伴生的安全问题亟待解决,也有一些新的伴生风险等待研究人员去发现.下面从大型语言模型的安全风险、提示注入攻击的进一步探索空间、ChatGPT的衍生安全问题和对人工智能失控的担忧4个方面对ChatGPT的伴生风险进行讨论.
1) 大型语言模型存在安全风险.ChatGPT是在GPT系列模型的基础上一步步发展而来,虽然新一代的模型很大程度缓解了前一代的风险,但是也可能依然遗留这部分风险,需要系统地评估,同时也可能引入新的风险:ChatGPT训练数据的增加也导致其内容安全风险增加,它在引入基于人类反馈的强化学习机制时可能引入人为的偏差,同时强化学习中的代理可能表现出对抗性行为;OpenAI在收集用户数据用于新一轮训练时会遭受数据投毒攻击;同时OpenAI的CEO在GPT-4发布后也表示[39],即使是OpenAI的研究者也没弄明白模型为什么做一件事而不做另一件事,即当前语言模型的可解释性工作需要研究者去探索.
2) 提示注入攻击仍待探索.由于无法访问大量真实产品和模型,文献[32-33]仅在设想的场景下搭建环境进行提示注入实验.但随着OPT[40]、LLaMa[41]、Brad[42]和文心一言[43]等更多大型语言模型的推出,可以针对更多模型探索注入技术,量化提示注入攻击的影响;同时可以从传统的网络安全领域的注入攻击中借鉴更多的攻防手法,探索自动搜索更有效的恶意提示注入方法,并进一步研究防止注入的方法,提高模型的鲁棒性.
3) 存在衍生安全问题.引入语言模型的应用程序将引入新的软件攻击面.Remoteio机器人和Notion AI的提示泄露[30-31]揭示了这类应用在真实环境下遭受提示注入攻击的风险.随着未来更多应用场景中引入大型语言模型,可以探索更多不同的提示注入技术.同时,还可以从传统网络安全领域借鉴防御手段,帮助应用在用户输入和模型输入之间构建一道防御屏障.
4) 人工智能面临失控的风险.GPT-4诞生2周后,由埃隆·马斯克(Elon Musk)等数千人签名的公开信[44]呼吁暂停研究比GPT-4更强大的人工系统,表达了人们对这一技术可控性的担忧.随着人工智能技术的迅猛发展,通用人工智能时代的到来已经加速,方滨兴院士[45]也提到ChatGPT虽然只是一个聊天软件,但当机器人接入实体时,还需要警惕这些智能行为体可能对人类造成的危害.在技术高速发展的同时,需要探索和研究对这些技术施加的限制条件、设计何种政策和制度才能有效减缓其失控.
5 结 论
和许多新兴技术一样,以ChatGPT为代表的大型语言模型技术也面临着“科林格里奇困境”,在享受新技术带来红利的同时,也需要关注新技术带来的种种安全问题.本文概述了大型语言模型技术的发展并简介了ChatGPT的技术及其特点,不仅从助力攻击和处理防御的角度讨论ChatGPT的安全赋能效应,还从内容风险和提示注入攻击角度讨论ChatGPT所伴生的安全风险,最后对未来的研究方向作出了展望.
