面向污染场地智能化管控多源异构数据融合方法综述
2023-06-04高明亮蒋卫国李志涛
陈 征,高明亮,蒋卫国,李志涛
(1.生态环境部 土壤与农业农村生态环境监管技术中心,北京 100012; 2.首都师范大学 资源环境与旅游学院,北京 100048; 3.北京师范大学 地理科学学部,北京 100875; 4.中国环境科学研究院,北京 100012)
0 引言
随着物联网、云计算、卫星遥感技术的快速发展,数据呈爆炸式增长,大数据时代到来[1]。遥感技术、人工智能等新技术为污染场地管控带来了新契机。以调研为主的单一来源信息已经无法满足污染场地智能化管控技术的需求,因为海量数据来源各异,数据类型复杂多样,难以直接用于污染场地管控决策,需采用数据融合技术,按照一定规则,对场地数据或敏感受体相关信息进行预处理、特征提取、融合等,以支持最终决策。在充分利用多源数据或关联关系的同时,充分考虑数据的独特性来提高决策的可靠性。多源异构数据融合具有单一来源数据无法比拟的优越性和典型特征[2],如数据的冗余性、互补性、实时性等[3]。目前,数据融合技术受到广泛关注,已成为大数据[4]、数据挖掘、生态[5-6]、环境[7]、地学[8-9]等领域的热门研究课题[10]。充分利用大数据优势及数据挖掘等新技术、新方法,实现污染场地的智能化管控已成为污染场地管控及修复等工作迫在眉睫的需求。数据融合是通过综合来自多个数据源的特征来减少决策中的不确定性,从而改善决策质量。多源异构数据融合是针对多源异构数据的一种处理手段,通过结构化处理、特征识别及知识推理等方法,从原始数据源中得出综合评估和判断,增加数据及结论的置信度,提高决策的可靠性,降低不确定性。
针对污染场地智能化管控对多源异构数据融合的需求,对多源异构数据融合技术及方法进行综述,对其发展方向进行了展望,以期为污染场地多源异构数据融合技术的研发提供理论框架及科学依据,为污染场地智能化管控提供重要的理论基础及技术支撑。
1 污染场地多源异构数据融合概述
数据融合概念始于20世纪70年代初,近年来引起了世界的普遍关注。美国JDL(the Joint Directors of Laboratories)从军事应用角度,将数据融合定义为一种将来自多传感器的数据进行关联与组合,实现较为准确的位置推断及身份估计的技术,可对战场状况、威胁程度及重要水平做出及时完整的评价[11]。针对更普遍的应用场景,一些学者对数据融合的定义做了完善与修订。张新长[12]等将数据融合技术定义为利用计算机对按时序获得的若干观测信息在一定准则下加以自动分析、综合,以完成所需的决策与评估任务而进行的信息处理技术。
1.1 污染场地多源异构数据融合过程
数据融合的本质是一个由底层至顶层对多源数据进行整合、逐层抽象的信息处理过程。多源异构数据存在不同数据结构和冗余特征,在融合前需要执行清洗、去异常值、去重等操作等一系列预处理流程。污染场地多源异构数据融合需要对来自不同传感器(或数据源)的特征描述信息进行分析处理,按照一定规则进行冗余整合、信息互补,对产生冲突的数据进行判别与评估,从而得出对目标的准确判断。典型的数据融合过程如图1所示,包括预处理、特征提取、融合计算、结果输出等步骤。

图1 污染场地多源异构数据融合的基本过程Fig.1 Basic process of multi-source heterogeneous data fusion in contaminated sites
根据污染场地智能化管控中多源异构数据的存储模式和结构特征,主要在栅格结构层面进行数据融合,即对矢量数据和非结构化数据进行栅格化后再进行融合,主要包括以下3个方面的融合:①污染场地多源、多尺度遥感数据融合。②污染场地GIS空间矢量数据与遥感数据融合。③污染场地非结构化数据与空间数据融合。
1.2 污染场地多源数据的融合方法分类
多源异构数据融合方法的分类准则较多,如污染场地多源异构数据融合主要在栅格结构层面进行,宜采用基于数据层级的分类方法[13],将数据融合分为像素级、特征级和决策级3个层次,每个层次可以设计不同的融合方法。
像素级融合。在基于数据层级的数据融合方法分类体系中,像素级融合是最低层次的融合,是直接在预处理后的数据层融合,按照一定的策略逐像元计算得到新的融合图像,在提升数据质量(如分辨率、数据维度等)的同时,最大限度保留图像的原始信息。它对硬件设施要求较高,逐像元融合处理需要对待融合图像进行精确配准,融合结果容易受噪声及预处理效果的影响。常用的像元级融合方法包括代数法、IHS (Intensity-Hue-Saturation)变换、小波变换[14]、主成分(PCA,Principal component analysis)变换、K-T变换(Kautlr-Thomas Transformation,又称穗帽变换)等。
特征级融合。特征级融合是中间层次的融合,按照特定的规则提取目标特征的内在描述,对图像进行特征提取并进行综合处理。特征是图像信息的进一步抽象,因此特征级融合是一种代价处理,为了提取特征信息,压缩数据量,损失了部分细节信息。按特征信息对多源数据进行分类、聚集和综合,产生特征向量,通过多个特征向量的组合增加特征维数,从而提高目标的识别准确率。常用的特征级融合方法包括人工神经网络、特征聚类、卡尔曼滤波、遗传算法等。
决策级融合。决策级融合是最高层次的融合,融合结果可为决策提供依据。通过对污染场地多源异构数据的预处理、特征抽取、识别及判决,建立对观察目标的初步结论。在独立完成决策或分类的基础上将多个识别结果进行融合,做出全局的最优决策。其优点是具有很强的容错性、开放性,处理时间短,数据要求低,分析能力强。但是由于决策是最高层次的抽象,同时判别和估计对预处理及特征提取有较高的要求,因此决策级融合的代价在三个层次中是最高的。常用的决策级融合方法包括贝叶斯方法、D-S证据推理(Dempster-Shafer reasoning)、模糊推理、专家系统等。
此外,污染场地多源异构数据融合方法的分类依据还包括输入数据的关系、输入/输出数据类型、Joint Directors of Laboratories (JDL)定义的层级[15]、结构类型等。污染场地多源异构数据融合方法类型及其特点详见表1。
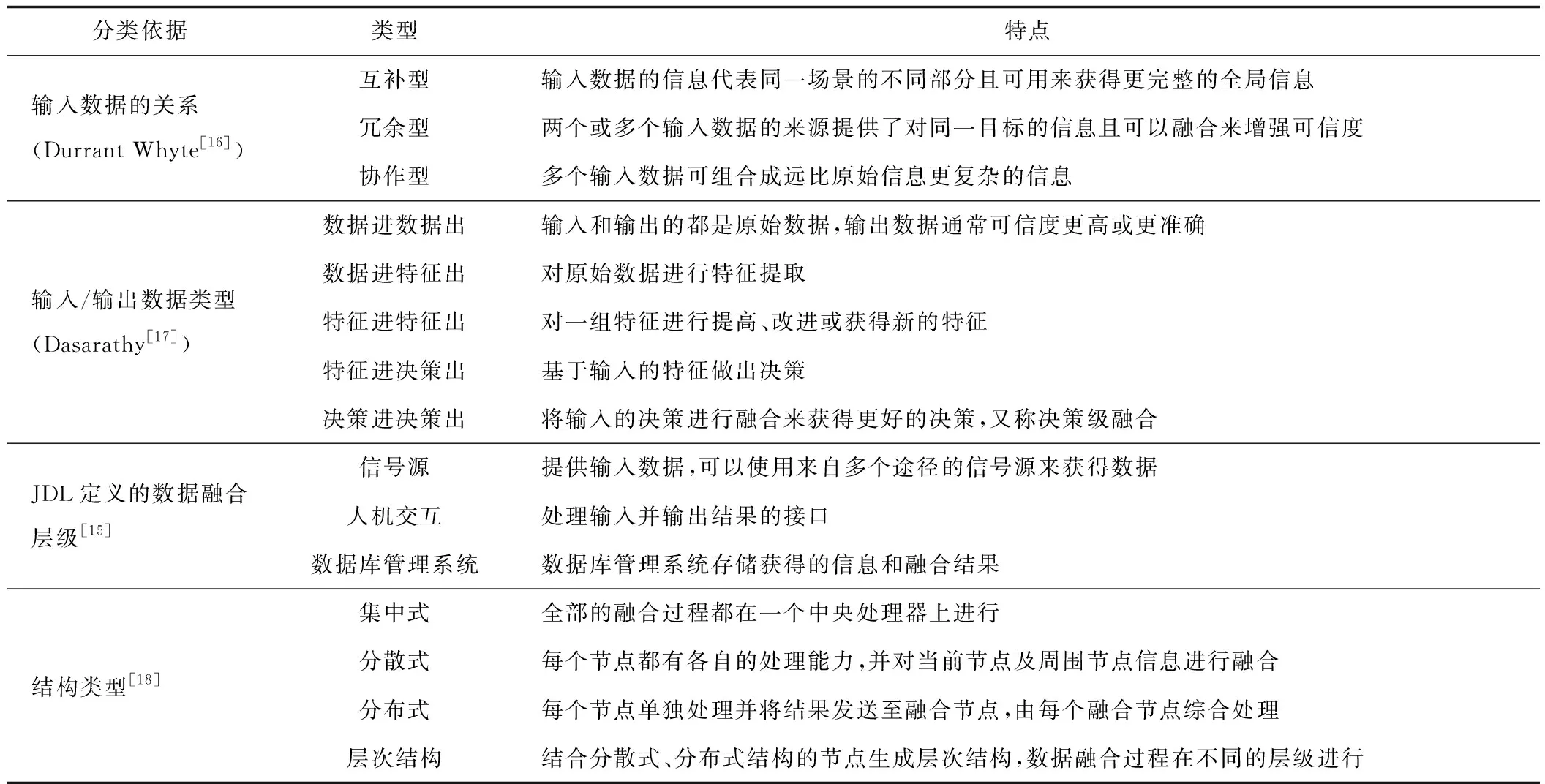
表1 污染场地多源异构数据融合方法分类体系Tab.1 Classification system of multi-source heterogeneous data fusion method for contaminated sites
2 污染场地多源异构数据融合方法
2.1 基于数理统计的污染场地多源异构数据融合方法
基于数理统计的方法主要包括贝叶斯(Bayes)推理、贝叶斯网络[19]、支持向量机(Support Vector Machine,SVM)[20]及证据推理(Evidential Reasoning)等[21]。
基于贝叶斯估计方法。贝叶斯推理是多源异构数据融合最常用的方法之一[22]。其基本原理是利用概率原则组合来自多个传感器的多源信息,并用概率表示每种信息的不确定性,计算在给定条件下某个假设为真的后验概率,在实际情境中按照一定判定策略来做决策。对于数据源提供的属性(证据)B1,B2,…,Bn,逐一计算各属性(证据)在各假设为真的条件下的概率P(Bi|Aj)及n个属性(证据)的联合概率:
P(B1,B2,…,Bn|Aj)=P(B1|Aj)·P(B2|Aj)…P(Bn|Aj)
(1)
利用贝叶斯公式,计算在n个证据为真的条件下假设A的后验概率为:
P(Aj|B1,B2,…,Bn)=P(B1,B2,…,Bn|Aj)·P(Aj)/P(B1,B2,…,Bn)
(2)
在实际情境下,基于式(2)计算结果按照一定的判定策略做辅助决策。
贝叶斯网络是一种用来描述不确定性关系的理论方法[23],基于有向图来描述目标之间的相互关系,用于分析多源异构数据融合中多目标的因果关系及依赖关系。根据贝叶斯定理与特征条件独立性假设进行输入数据的联合概率分布学习与估算,是一种基于独立事件概率的模型,在图论中,贝叶斯的结构主要有3种形式,如图2所示。
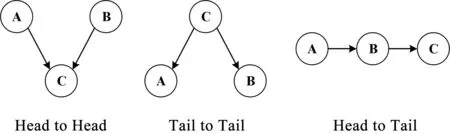
图2 贝叶斯网络的三种典型结构Fig.2 Three typical structures of Bayesian networks
Head to Head:当AB事件同时发生时,C事件发生,则事件同时触发的概率为:
(3)
Tail to Tail:当C已知时,则AB事件独立。
Head to Tail:此时事件同时触发的概率为:
(4)
贝叶斯网络可用于分析数据间的关联关系,如污染场地相关的源、受体、传播途径等量化特征及地理位置信息等。联合概率分布通常只能基于观测数据来求解后验分布,因此对于数据质量要求较高,需要有大量的高质量观测数据才能得到较为准确的推理模型。贝叶斯网络是一种基于独立事件的概率图模型,对于非独立事件在联合概率分布的求解会有较大的误差。
D-S证据推理方法。污染场地监测与管控依赖多种传感器采集的数据,其目的是为了监测多种环境影响及区域响应参数,包含了多种信息源带来的不确定性。因此面向污染场地管控的多源异构数据融合,需要将多源异构信息的不确定性进行综合建模和推理,并输出一个最终决策。D-S证据推理方法通过建立信任函数,利用信任度而非概率来量化不确定信息的可靠性[24],在数据融合过程中不仅要保证证据的客观性,还要重视主观性和综合因素,具有较强的灵活性[25-26]。其基本思路[27]为:建立识别框架→初始信任分配→计算所有假设命题的信任度→证据合成→决策。在进行证据推理过程中需要用到几个重要的证据函数,包括基本概率分配函数、信任函数及似然函数。其中,基本概率分配函数(Basic probability assignment,简称BPA)表征各个证据对命题的信任程度,BPA是否合理对最终结果影响较大。信任函数(Belief function)表征各个证据对命题为真的信任程度。似然函数表征对命题的“非假”信任度,即命题可能成立的不确定性度量,也被称为上限函数。
2.2 基于估计理论的污染场地多源异构数据融合方法
基于估计理论的方法主要包括最小二乘法、加权平均法、卡尔曼滤波(Kalman Filter)等线性估计技术[28-29]及一些非线性估计技术,如高斯滤波方法[30]等。
基于加权平均的方法。加权平均法是数据级融合中最简单易行的方法,在多波段图像(如遥感图像)数据级融合中应用较为广泛。该方法将数据源所提供的一组有冗余信息的数据赋予加权系数后做加权平均处理,如遥感图像处理的多波段运算。
用wi代表赋予数据源ti的权重,则
(5)
得到的结果即为数据融合的结果,这种方法简单直观,但权重赋值取决于提取对象的特征且需要一定先验经验知识,受主观因素影响。
自适应加权平均法采用自适应的方式,通过迭代寻找各数据源的最优权重,替代人工确定权重的过程,在满足总均方误差最小的前提下获得最优的融合结果。
卡尔曼滤波法。多用于动态环境中多传感器、多源信息的实时融合,可有效利用多源异构数据之间的关系,运算效率较高。其核心是计算多源异构数据(或信息)之间的加权平均值。其中,各数据源(信息源)权重与多次测量结果的方差成反比。在实际应用中通过调节各数据源(信息源)的方差值来修正权值,从而得到更可靠的结果。卡尔曼滤波融合算法计算模型为:
(6)
其中,X为状态估计矩阵,A为状态转移矩阵,B为系统控制矩阵(通常为0矩阵),u为系统控制量(通常取0),ω为系统噪声,Z为观测值矩阵,H为系统观测矩阵,ν为观测噪声。采用最小方差估计方法,根据测量值Z估计系统状态矢量X的Kalman滤波方程,状态更新包括时间更新及测量更新两部分。时间更新方程为:
(7)
状态更新方程为:
(8)
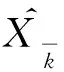
2.3 基于信息论的污染场地多源异构数据融合方法
从信息论观点来解释数据融合的过程——实质上是不确定性减少的过程。在污染场地多源异构数据融合中应用数理统计方法进行特征信息的处理和传递,即基于信息论的多源异构数据融合方法。具有代表性的算法包括模糊集理论(Fuzzy Set Theory,FST)[31]、信息熵(information entropy)[32]等。
模糊集理论。在污染场地多源异构数据融合过程中,融合系统处理的特征和信息存在一定的模糊性,而模糊集理论以其特有的处理模糊问题能力及模糊推理优势,被广泛应用于多源数据融合、资源环境评价[33]等领域。它将一个集合的隶属度定义为一个可能性分布[34],即通过把经典集合中的隶属关系推广到可以取单位区间[0, 1]上的任一值,从而达到定量刻画模糊性对象的目的[35]。
模糊综合评判是一种常用的基于模糊集理论的评价方法,可参考文献[36]。利用模糊综合评判原理进行多源信息融合,具有系统结构简单、计算复杂度低、耗时小、便于实时处理、容易实现等优势,被广泛用于多源异构数据融合应用中。污染场地多源异构数据模糊集融合方法处理流程如图3所示:
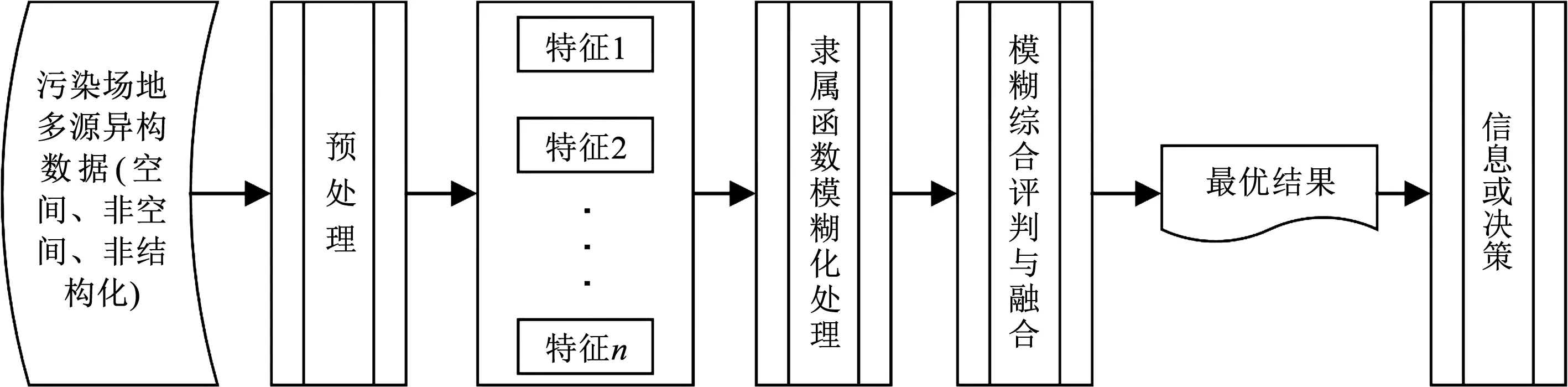
图3 基于模糊集理论的污染场地多源异构数据融合处理流程Fig.3 Multi-source heterogeneous data fusion processing of contaminated sites based on fuzzy set theory
信息熵方法。为了提取污染场地相关的污染源、暴露途径及受体等特征信息,选择数据模型化处理是最好的方式[37]。但是数据信息模型化存在不确定性,常用的解决方法是采用最大熵原理(The Maximum Entropy Principle,MEP)[38]。需要注意的是,这里的“熵”并不是指热力学概念,而是Claude Elwood Shannon提出的信息熵,用来描述信息的不确定程度[39]。一个离散型随机变量X的熵H(X)定义为:
(9)
其中:p(x)表示取值为x的概率,log()为以2或e为底的对数。
对污染场地多源异构数据的融合是对同一表达层次、多源异构信息的合成过程,把输入数据(遥感数据、GIS空间矢量及非结构化数据等)和输出信息(包含污染源、暴露途径及受体等信息)定义为两种不同的信息源,并用两种概率空间上定义的信息熵进行描述。
通常,最大熵模型假设融合模型C是一个条件概率分布P(Y|X),其中X为特征,Y为输出。定义在条件概率分布P(Y|X)熵的条件熵[40]为:
(10)
求解H(P)最大时对应的P(y|x),即求解模型集合C中条件熵最大的模型。最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,可灵活地设置约束条件,通过约束条件的多少来调节模型对未知数据的适应度及对已知数据的拟合程度。
2.4 污染场地多源异构数据融合的人工智能方法
人工神经网络(artificial neural network,ANN)。特指浅层神经网络,即包含一个输入层、一个隐藏层与一个输出层的神经网络模型。其具有完善的容错机制及自学习、自组织、自适应能力,能够模拟复杂的非线性关系映射[8]。人工神经网络的特点和非线性处理能力能够满足污染场地多源异构数据融合应用的要求。在污染场地智能化管控实际情景中,各数据源所提供的环境信息均具有一定程度的不确定性,对其融合过程实际上是一个不确定性推理过程。通过当前系统所接受的样本相似性特征来确定分类标准(主要表现在网络的权值分布上),同时通过学习来获取知识,得到不确定性推理机制。利用人工神经网络的信号处理能力和自动推理功能,实现污染场地多源异构数据融合。
深度学习(深度神经网络)。深度学习是深度神经网络的统称,深度神经网络(Deep Neural Network,DNN)通常包括多个隐藏层,其中较低层的输出作为较高层的输入,因此能够从数据中获取到更多的信息,学习到数据中更有效的特征表示。相较于浅层网络,深度神经网络能够更好地挖掘和表示数据特征,具有更强的泛化性能,近年来在数据融合领域有了较为广泛的应用。根据深度学习在数据融合中参与的阶段,张红[41]等将基于深度学习的数据融合方法分为3类:基于深度学习特征提取的数据融合方法,基于深度学习融合的数据融合方法,基于深度学习全过程的数据融合方法。深度神经网络的作用及各类方法对应的典型应用案例见表2。在污染场地多源异构数据融合应用中宜采用基于深度学习全过程的数据融合方法,在特征提取阶段及数据融合阶段有针对性地采用不同的深度神经网络模型组合[42],从而有效提高融合质量,提升污染场地智能化管控决策精度。目前已有研究[43]表明,可通过神经网络预训练等方式,基于有限的训练样本得到可靠的训练精度,将为多源异构数据融合带来更多的途径和可能性。

表2 基于深度学习的多源异构数据融合方法及典型应用案例Tab.2 Multi-source heterogeneous data fusion method based on in-depth learning and typical application cases
3 结束语与展望
针对污染场地智能化管控需求,对多源异构数据融合方法进行了综述。根据污染场地多源异构数据的特点,介绍了像素级、特征级及决策级等多层级数据融合方法体系,对数据融合方法按照基础理论进行分类并分析了典型方法。无论是基于数理统计、估计理论及信息论的传统数据融合方法,还是基于人工神经网络和深度学习的数据融合方法,均在不同领域得到了广泛应用。但数据融合技术仍存在一些问题,如针对多源异构数据等高维数据在表示方式、组织形式、数据密度(即数据结构)等方面存在差异及异构数据间的交叉、关联、整合与同化存在问题,深度神经网络模型训练过程中需要大量数据作为训练样本,对硬件(计算能力)有较高的需求。因此,对多源异构数据进行特征信息提取并进行融合应用,是数据融合领域亟待进一步研究的方向。此外,深层神经网络模型训练的关键技术方法也在不断迭代更新,除了计算机硬件算力的提升外,让模型在训练过程中自我学习与优化,可大幅提升数据融合模型训练效率,值得深入研究。
