基于CMA-REPS格点预报数据的深度学习风速订正方法
2023-06-01周世杰杨康权
毛 波, 杨 昊,, 周世杰, 杨康权, 陈 敏
(1.成都信息工程大学计算机学院,四川 成都 610225;2.电子科技大学信息与软件工程学院,四川 成都 610054;3.四川省气象台,四川 成都 610072;4.四川省气象局重点实验室,四川 成都 610072)
0 引言
风能作为一种高效清洁的新能源,其巨大的发展潜力引起了国内外广泛的重视。实现准确的风速预测能够有效地提高风能资源的利用率,降低风功率波动对电网稳定性的影响,从而提升风电场的经济效益[1]。集合数值预报模式由于提供了关于天气预报的不确定性信息,相比于单一的确定性数值预报模式,往往能够得到更准确的风速预报结果,现已在全球多个国家的天气业务预报中心实现常规运行[2]。但在实际应用中,由于集合预报模式设计之初的各种不完美以及大气系统的不确定性,集合预报模式一直存在系统性误差,从而造成风速预报的结果出现系统性偏差。为了满足更加精确和可靠的风速预报需求,需要对集合数值预报模式的结果进行偏差订正,以提升模式对风速的预报能力。
目前,受限于风场本身所具有的变性特征,国内对风场集合预报结果偏差订正的方法还是多以传统的统计订正方法为主[3],如集合模式输出统计法[4]和贝叶斯模型平均法[5]。这类订正方法均通过建立线性统计模型来订正风场集合预报的误差,对于风场变化的随机特征,传统的线性统计模型往往不能很好地捕捉其中的非线性关系。随着近年来计算机硬件设备的不断提升以及人工智能技术的蓬勃发展,国内外气象领域的研究人员开始逐步结合机器学习方法或深度学习方法对数值预报模式结果进行偏差订正,实现风速的精细化预报。Lahouar A 等[6]使用随机森林的机器学习方法,建立了提前一小时的风速预测模型。与其他大多数机器学习方法相比,随机森林方法不需要进行调整或优化,结果表明,使用该模型的风速预报精度有显著的提高。孙全德等[7]使用常见的几种机器学习算法(LASSO 回归、随机森林等)对数值天气预报模式ECMWF 预测的华北地区近地面10 m风速进行订正,将订正结果与传统订正方法得到的订正结果进行对比。结果表明,基于机器学习算法的风速订正方法效果均好于传统订正方法,显示了机器学习方法提升数值预报风速预报精度的潜力。但上述机器学习方法仅限于对确定性数值预报的数据进行偏差订正,尚未对集合数值预报模式进行尝试。且机器学习较依赖于复杂的特征工程,将机器学习应用于模式的偏差订正时,需要研究人员具备专业的气象知识和大量的时间,使训练过程成本偏高且十分具有挑战性。
深度学习作为机器学习的一种特定形式,由于不需要进行特征工程,因此在对海量数据进行非线性建模时具有更大的优势。过去十年中,深度学习已在计算机视觉、语音识别及自然语言处理等多个领域取得了丰富的成果,为人类社会的进步和发展带来了极大的帮助。对于大气系统所具有的特殊的高度非线性特征,深度学习现已成为人工智能领域与大气科学领域交叉应用的研究热点和主流发展方向。Stephan Rasp等[8]率先使用深度神经网络在分布回归框架中对集合预报预测的2 m温度进行偏差订正实验,将连续分级概率评分(continuous ranked probability score,CRPS)作为其模型的损失函数。该实验的局限在于只考虑单一站点位置以及单一天气变量的偏差订正,对目前的数值预报模式生成的二维网格数据不具有适用性。对于二维网格数据所具有的空间特性,需考虑使用诸如卷积神经网络[9]等方法来提取其空间特征。受此启发, Grönquist Peter 等[10]基于Unet 模型搭建了集合预报的偏差订正模型,结果表明其模型在CRPS 评分方面相比于传统订正方法取得了超过14%的相对改进。L Han 等[11]基于Unet 提出了一个CU-net(Correction U-net)模型,将格点预报数据的偏差订正问题转化为深度学习中的图像识别问题,对ECMWF-IFS 模式的格点预报数据进行订正,也取得了不错的订正效果。张延彪等[12]为进一步加强CU-net 模型对复杂的气象格点数据的偏差订正能力,引入稠密卷积模块[13](Denseblock)对CU-net 进行改进,构建了Dense-CUnet模型。上述研究虽然都对格点预报数据的偏差订正有较好的效果,但考虑到格点预报数据的空间特征,仍存在一些不足,主要体现在没有考虑模型对格点预报数据的时间维度特征的提取融合。
集合数值预报模式预报的格点数据具有复杂的空间特征和时间特征,属于典型的时空序列数据。对这类数据进行偏差订正的深度学习方法,本文引入时空序列预测问题常用到的ConvLSTM 模型[14]对CMAREPS 预报的近地面(10 m)风速格点数据进行偏差订正,订正的预报时间为24 h、48 h和72 h。将订正结果与CMA-REPS 原始预报数据和Unet 模型得到的结果进行对比,结果表明该模型方法能进一步提升集合数值预报模式风场格点数据的预报精度。
1 模式与方法
1.1 CMA-REPS
CMA-REPS 是中国气象局自主研发的新一代区域集合预报系统,其前身是GRAPES-REPS(global and regional assimilation and prediction enhanced system-regional ensemble prediction system)区域集合预报系统,基于中国自主研究并建立的新一代多尺度通用资料同化与数值天气预报系统-GRAPES 的区域模式发展而来[15-16]。集合预报扰动方法对集合预报的可靠性提升极为重要,当前CMA-REPS 初值扰动采用6 h循环计算方案的GRAPES 模式面集合变换卡尔曼滤波[17];模式扰动采用单一物理过程参数化方案与随机物理过程倾向项(stochastic perturbed parameterization tendencies, SPPT)[18]组合;边界扰动通过提取GRAPESGEPS(global and regional assimilation and prediction enhanced system-global ensemble prediction system)全球集合预报系统扰动成员相比于自身控制预报的扰动测边界,并叠加在CMA-REPS 的控制预报测边界上得到[19]。CMA-REPS 参数配置如表1 所示,其水平分辨率为0.1°,垂直分辨率为50 层,集合预报成员数15个,预报区域为中国区域,预报时效84 h(00 时,12 时(协调世界时)),6 h(06 时,18 时(协调世界时))。CMA-REPS 中的控制预报初值和侧边界来源于NCEPGFS(national centers for environmental prediction-global forecast system)全球模式的预报场;并且CMA-REPS加入了云分析同化技术与条件性台风涡旋重定位技术[20],以期提高短临降水和台风预报能力。CMAREPS 具体参数配置见表1。

表1 CMA-REPS 具体参数配置
1.2 基于ConvLSTM 的风速订正模型
集合数值预报模式的格点预报数据是在时间上连续分布的空间数据[21],具有典型的时空特征。仅靠单一的基于CNN 的深度学习模型如Unet,虽然可以有效地提取格点预报数据复杂的空间分布特征,但无法捕捉数据的时间序列信息。随着深度学习的发展,LSTM(long short-term memory)对于气象要素站点数据的序列预测能力得到了验证。因此,考虑将时间成分纳入深度学习模型(例如通过使用LSTM),可以进一步提高深度学习模型对集合数值预报模式格点预报数据的偏差订正能力。但是,传统的长短期记忆单元无法实现对空间特征的提取。基于此,引入ConvLSTM 模型,尝试对CMA-REPS 预报的近地面(10 m)风速格点数据进行偏差订正。ConvLSTM 模型是Shi 等[14]为解决时空序列预测问题,结合卷积神经网络对数据空间特征的提取与编码能力及长短期记忆网络的序列特征编码特性而提出的。
ConvLSTM 的单元结构图如图1 所示。由图1 可以看到,ConvLSTM 是LSTM 结构的一种变体,通过遗忘门(ft)、输入门(it)和输出门(ot)控制数据在细胞内部的交流。各个门控制数据参与到细胞状态的更新,通过门来选择性地保留或舍弃信息。ConvLSTM 与LSTM 的区别在于ConvLSTM 在“输入到状态”和“状态到状态”两部分都采用卷积运算来代替矩阵乘法,并且其所有的输入X1,…,Xt,细胞输出C1,…,Ct,隐藏状态H1,…,Ht,和遗忘门(ft)、输入门(it)和输出门(ot)都是3 维张量,这样做的好处是在提取序列的空间信息同时,可以去除大量空间冗余特征并且解决数据的时间依赖问题。

图1 ConvLSTM 单元结构图
ConvLSTM 门之间的传递关系如下:
式中it为输入门,ft为遗忘门,Ct为细胞状态,ot为输出门,Ht为隐藏层输出,*表示卷积运算符, 表示Hadamard 乘积,σ为sigmoid 激活函数。遗忘门可以控制信息的遗忘,丢弃被认为冗余的信息,保留有用的信息并将其向后传递;继续传递的信息进到输入门,通过sigmoid 层确定需要更新的信息,并通过tanh 层得到新的细胞信息对细胞进行更新。最后通过输出门中的sigmoid 的信息乘以通过tanh 的记忆细胞的信息得到模型的最终输出。
对于本文的集合数值预报模式风场格点预报数据的偏差订正问题,通过堆叠多个ConvLSTM 网络层搭建偏差订正模型,模型结构如图2 所示。模型输入由Yt和Pt+△t组成,其中Yt是2t、10u、10v和10w这4 个要素在t时刻的实况数据,Pt+△t是2t、10u、10v及10w在t时刻的△t小时集合平均预报数据,△t可取的值有24、48 和72。将实况数据Yt与预报数据Pt+△t拼接在一起,得到的模型输入数据大小为101×101×8。输入数据经过最小最大值归一化后进入两个ConvLSTM2D网络层,最后经过一层全连接层输出偏差订正后的CMA-REPS 的△t预报数据。两层ConvLSTM-2D 网络层卷积核数目均为10,考虑数据本身的特征分布和网格分辨率大小,选用3×3 大小的卷积核以避免丢失局部特征,并且卷积过程中使用填充设置使中间过程生成的特征图大小一致。输出层(全连接层)的神经元个数为1,其激活函数为ReLu,用以提高模型的非线性表达能力。在每个ConvLSTM-2D 网络层后加入批标准化层,通过对每层的输出进行批标准化处理,防止模型出现训练过拟合的同时加速模型训练的收敛过程。
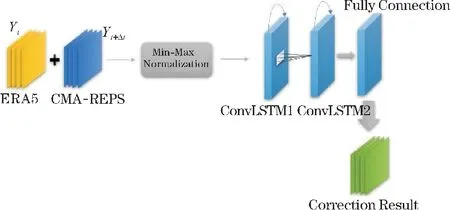
图2 基于ConvLSTM 的风速订正模型结构图
在模型训练过程中,使用Adam[22]作为模型的优化器,其学习率设为0.001,一阶矩估计的指数衰减率设为0.9,二阶矩估计的指数衰减率设为0.999。Adam算法相比于传统的随机梯度下降算法,可以通过计算梯度的阶矩为不同的参数设计独立的自适应性学习率,并且拥有更高效的计算效率。训练的每一批数据大小batchsize 设为10,并选取均方误差(MSE)作为模型的损失函数:
式中yi和分别代表训练集中的观测值和经模型训练后的订正值,n代表训练集样本数量。
2 数据
2.1 数据选取
选取CMA-REPS 预报的格点数据作为预报数据,采用第五代ECMWF 全球再分析产品(ERA5)数据作为格点“实况”数据。其中,CMA-REPS 的格点预报数据的空间分辨率为0.1°×0.1°,网格数为751×501,空间范围为10 °N ~60 °N、70 °E ~145 °E(2022年6月7日之前的空间范围为15 °N ~65 °N、70 °E ~145 °E),起报时间为00UTC 和12UTC,预报时效为0-84 h(逐小时),成员数为15。ERA5 数据的空间分辨率为0.1°×0.1°,网格数为101×101,空间范围为32 °N~42 °N、110 °E ~120 °E。对CMA-REPS 预报的华北地区近地面10 m风速格点数据进行偏差订正,因此需要将CMA-REPS 的格点预报数据裁剪成网格数为101×101,空间范围为华北地区(32 °N ~42 °N、110 °E ~120 °E),并选取预报时效为24 h、48 h以及72 h的2 m气温(2t)、10 m风速(10u:东西风;10v:南北风)的预报数据。两套数据的时间范围均为2019年10月20日至2022年5月1日。
2.2 数据预处理及划分
首先将10 m 纬向风分量(u)和10 m经向风分量(v)合成为10 m风速(w),合成公式:
现在选取的CMA-REPS 预报数据和ERA5 数据包含的气象要素有2t、10u、10v和10w,然后对两套数据进行质量控制,检测数据中是否存在缺失值或异常值。经检测,ERA5 4 个要素的数据均存在缺失值。这是由于ECMWF 数值模式预报资料数量大,存储空间占比高,导致资料在存储过程中出现数据缺失。针对格点预报数据空间上存在连续性的特点,ERA5 缺失值采用相邻非缺失值线性插值方法进行补缺。
为了防止模型训练出现过拟合的现象,提升模型的泛化能力,还需要将所选数据分为训练集、验证集和测试集。由于实验订正的预报时间为24 h、48 h 和72 h,因此将数据分为3 组,每组选取2019年10月20日至2021年4月30日的对应预报时效的数据为训练集,2021年5月1日至2021年10月31日对应预报时效的数据为验证集,2021年11月1日至2022年5月1日对应预报时效的数据为测试集。在单个训练数据集合中,以订正24 h预报数据为例,模型输入数据为起报时间t的ERA5 实况格点数据和CMA-REPS 的24 h预报数据,训练标签为t+24 h的ERA5 实况格点数据。
3 实验和结果
3.1 实验评价指标
采用ConvLSTM 深度学习模型对CMA-REPS 模式预报的华北地区近地面10 m 风场数据(10u、10v和10w)进行偏差订正,订正的预报时效为24 h、48 h和72 h,并将订正结果分别与CMA-REPS 原始预报结果、EMOS 方法订正结果和Unet 模型订正结果进行比较,同时结合ERA5 再分析场对模型的订正能力进行客观检验。对于模型订正性能的衡量,使用均方根误差(RMSE)来评估模型的订正效果。RMSE 的计算公式如下:
式中n代表测试集样本数量,yi和˜yi分别代表测试集的观测值和模型订正值。
3.2 10u 订正结果
图3 显示了CMA-REPS、Unet 模型和ConvLSTM模型对测试集24 h、48 h及72 h预报的10u数据进行偏差订正的RMSE 对比结果。由图3 可以看出,使用ConvLSTM 模型订正的预报结果相比CMA-REPS 原始预报数据和Unet 模型的订正结果要更贴近于实况数据。尤其对24 h预报的10u数据的订正效果最好,ConvLSTM 模型的RMSE 比CMA-REPS 降低36.57%,比Unet 模型降低15.73%。订正效果其次的是对72 h预报的10u数据的订正,RMSE 比CMA-REPS 和Unet 模型分别降低了14.83%和4.91%。对于48 h预报的10u数据的订正,ConvLSTM 模型相比于Unet 模型提升效果微乎其微,RMSE 仅降低0.54%,但相比CMA-REPS原始预报数据,RMSE 降低了6.46%,依旧取得不错的偏差订正效果。
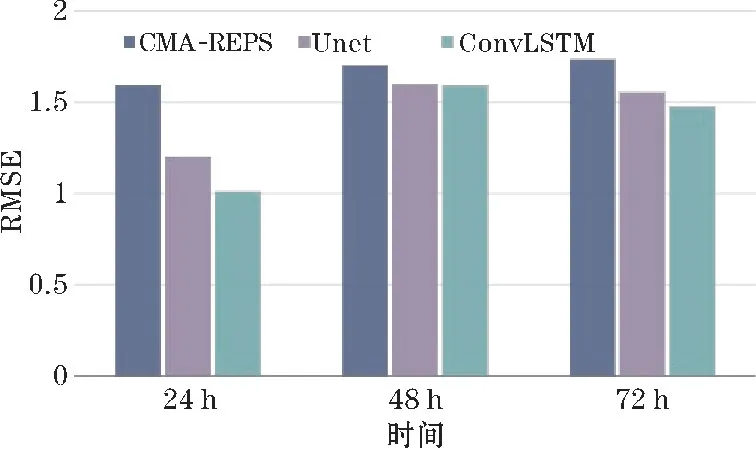
图3 24 h、48 h 及72 h 预报10u 订正前后RMSE 对比图
图4 显示了2022年4月4日00 时24 h预报的10u订正结果,可见CMA-REPS(图4b)原始预报数据整体误差较大,经过Unet 模型(图4c)和ConvLSTM 模型(图4d)订正后误差有明显的改善,并且ConvLSTM 模型订正的结果从整体上更趋近于ERA5(图4a),着重体现在研究区域的东部沿海和北部地区。
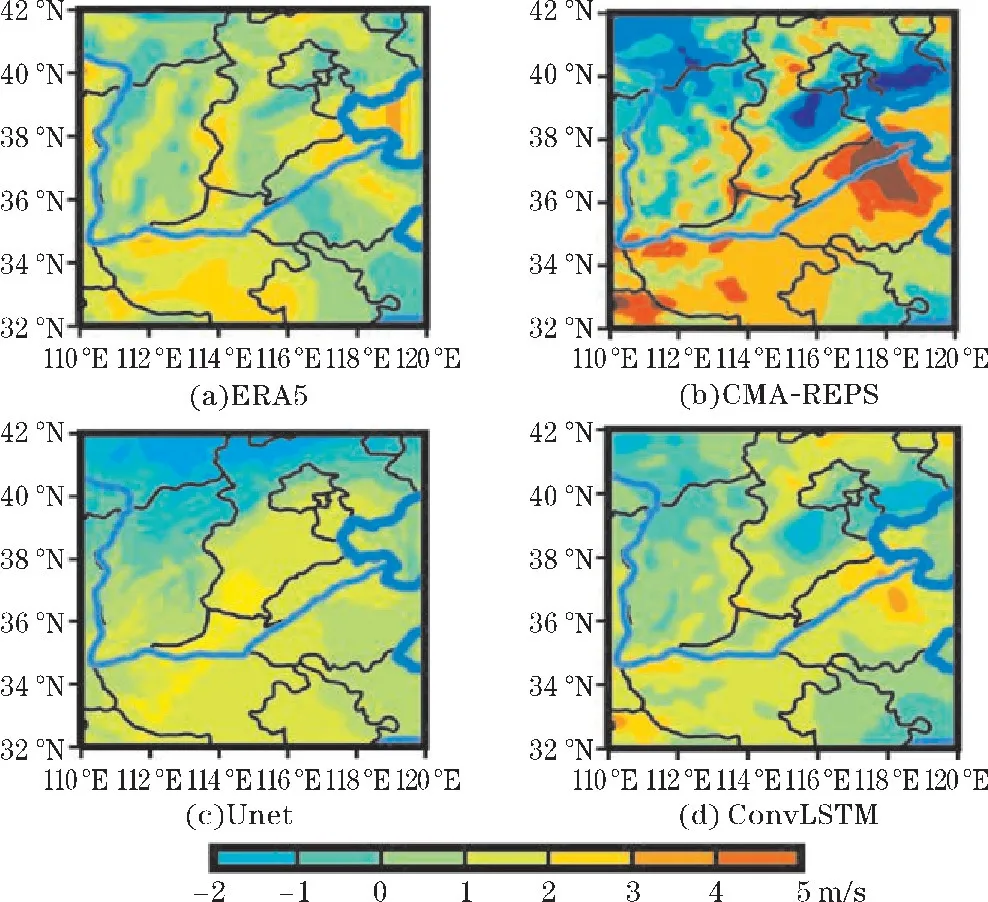
图4 2022年4月4日00 时24 h 预报10u 订正结果
3.3 10v 订正结果
图5 显示了CMA-REPS、Unet 模型和ConvLSTM 模型对测试集24 h、48 h及72 h预报的10v数据进行偏差订正的RMSE 对比结果。可以看出,ConvLSTM 模型得到的预报数据效果更好。其中效果最好的是48 h预报的10v数据,与CMA-REPS 和Unet 模型相比,ConvLSTM 的RMSE 分别下降了38.45%和20.56%。其次是24 h预报的10v数据,RMSE 比CMA-REPS 和Unet 模型分别降低25.16%和12.75%。对于72 h预报的10v偏差订正,Unet模型和ConvLSTM 模型订正的效果提升幅度不大,但总体上偏差订正的结果更趋近于ERA5。

图5 24 h、48 h 及72 h 预报10v 订正前后RMSE 对比图
从2022年3月25日00 时24 h预报的10v订正结果(图6)可以看出,在CMA-REPS 原始预报数据整体偏小的情况下,Unet 模型对研究区域北部地区的偏差订正效果欠佳,而ConvLSTM 模型对其进行偏差订正的结果整体上都具有明显的改善,着重表现在研究区域的中部和北部地区,在东部沿海地区也取得了不错的订正效果。

图6 2022年3月25日00 时24 h 预报10u 订正结果
3.4 10w 订正结果
图7 显示了CMA-REPS、Unet 模型和ConvLSTM模型对测试集24 h、48 h及72 h预报的10w数据进行偏差订正的RMSE 对比结果。从图7 可以看出,ConvLSTM 模型对不同预报时效的10 m风速的订正均有明显的提升,尤其是对48 h预报的10w订正,ConvLSTM 的RMSE 相比CMA-REPS 原始预报数据和Unet 模型降低了28.37%与11.21%。24 h预报的10w经ConvLSTM订正后,相比CMA-REPS 和Unet 模型RMSE 分别降低了19.42%和6.01%。对于72 h预报的10w,经ConvLSTM 订正后的RMSE 比CMA-REPS 降低18.52%,比Unet 模型降低8.19%,整体改善效果与24 h 预报的10w相比相差不大。
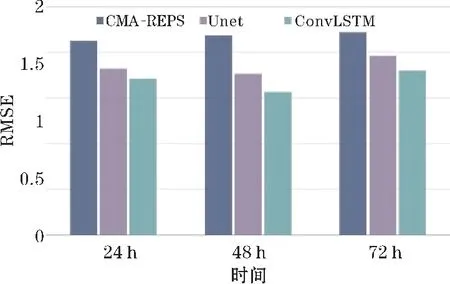
图7 24 h、48 h 及72 h 预报的10w 订正前后RMSE 对比
图8 显示了2022年2月7日00 时的48 h预报的10w订正结果。可以看出,该时刻的CMA-REPS 原始预报数据整体上数值偏大,经Unet 模型偏差订正得到的预报结果虽有所改善,但整体数值上相比于ERA5依旧稍微偏大。融合了时间序列特征编码特性和空间特征提取功能的ConvLSTM 模型偏差订正的结果在整体上与ERA5 更加一致,说明本文提出的ConvLSTM模型可以有效改善CMA-REPS 对10 m风速预测值偏高的情况。
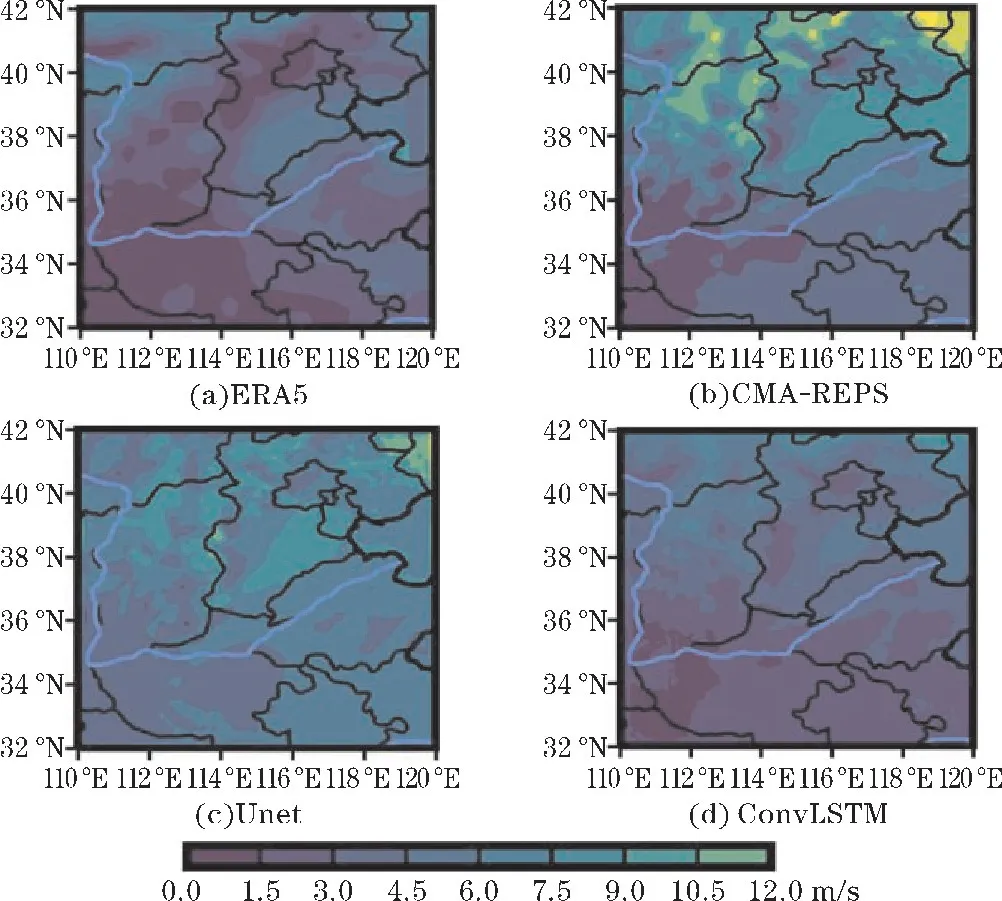
图8 2022年2月7日00 时48 h 预报10w 订正结果
4 结论
基于深度学习方法对中国自主研制的CMA-REPS预测的近地面10 m风场格点数据进行了偏差订正。针对格点预报数据具有的空间和时间双重特征,构建了一种融合时间序列特征编码特性和空间特征提取功能的ConvLSTM 订正模型,并将其订正结果与仅考虑空间特征提取的Unet 模型的订正结果和CMA-REPS原始预报数据进行对比。实验结果表明,ConvLSTM对CMA-REPS 3 个预报时效(24 h、48 h和72 h)的近地面10 m风场预报数据均有明显的正向订正作用,且订正效果均要优于Unet 模型的订正效果,这说明融合格点预报数据的时间序列特性可以帮助深度学习模型进一步提升对格点预报数据的偏差订正能力。另外从3 个个例分析可以看出,在CMA-REPS 原始预报数据整体较离散的情况下,ConvLSTM 可以减小预报数据与实况数据间的误差,有效提升CMA-REPS 对近地面10 m风场数据的预报能力。
随着深度学习技术的不断进步,注意力机制[20]已被证明可以有效提升模型对序列数据的特征提取能力,考虑将注意力机制与ConvLSTM 模型结合可以进一步提升模型的偏差订正效果。另外,将传统集合数值预报模式订正方法如集合模式输出统计(EMOS)与深度学习模型方法融合,也是未来集合数值预报模式偏差订正值得尝试的研究方向。
