基于深度学习和白流量过滤的网络流量检测系统研究
2023-05-30徐磊张志章方圆夏天
徐磊 张志 章方圆 夏天
(温州大学计算机与人工智能学院 浙江省温州市 325600)
截至2020年12月,我国网民规模达9.89 亿,较2020年3月增长8540 万,全国网络普及率将达到70.4%[1]。隐藏在如此惊人的数据背后的,是不计其数的网络应用以及它们产生的网络流量,而大量的网络流量自然会带来大量的安全问题。对于网络管理者而言,如何发现、解决乃至预防这些安全问题成为了他们在新的互联网时代下所要面临的挑战。随着网络攻击技术的日益复杂和隐蔽,一些传统的识别算法逐渐失去了以往的识别效率。本文将寻找合适的方法去识别攻击流量并过滤出其中的白流量,这对于防御网络攻击具有重要实践价值。
1 流量识别背景知识
1.1 网络流量
本文所研究的信息流量实质上是指网络流量,网络流量即在互联网上传播的信息量。网络流量实质上是网络中的对等实体在通信时产生的数据量,这种通信需要收到特定的网络协议的限制,如遵循TCP/IP 体系结构。虽然网络流量划分的理论十分深入,应用的方面也不少,但大多是基于以下这样三个方面:
(1)包级流量分类:重点研究包的性质以及到达情况,如包的数量分配、数据包到达的时间分配等。
(2)流级流量分类:重点研究流量的到达流程以及特征,它们可能为TCP 连接或是UDP 流。通常是指由源IP 地址、源端口、目的IP 地址、目的端口,以及协议所构成的五元组。
(3)流级业务分类:重点研究主机对与主机对之间的应用服务,一般是由源IP 地址、目的IP 地址和协议所构成的三元组,适用于研究较粗粒度的主干网长期服务统计特征。
1.2 机器学习与深度学习
机器学习能够从海量的数据中心通过不断学习而提高机器的识别能力,是一种通过大量历史数据得出相关的经验模型,并对当前问题进行应用于实际进行预测判断的技术。主要包括以下三类:
(1)监督学习:需要对数据进行标记,利用一组已知类别的数据样本调整预测参数,算法通过训练数据学习,并将学习结果应用到当前数据中,此类学习需要以人工为前提。该类算法主要用于解决“分类”或“回归”问题,典型代表有决策树、随机森林[2]、K-近邻算法[3]、支持向量机[4]。
(2)无监督学习:与监督学习不同,无监督学习的输入数据往往没有标签,而是通过自身学习进行分类。主要用于“聚类”问题,典型代表是主成分分析[5]和K-means 算法[6]。
(3)强化学习[7]:强化学习通俗地讲是不断进行“尝试”,通过数据与环境的交互结果,即奖/惩信号作为输入,以此结果动态地改变来适应环境。
深度学习是机器学习的一个分支,其最终目标是让机器能像人类一样进行分析和理解。深度学习的理念来自人工神经网络,通过结合底层特性创建更为抽象的高层特征表示属性类型或特性,并出现了大量数据的分布式特征表示。基于神经网络的深度学习模型中,主要包括输入层、隐藏层、输出层三层,其中隐藏层中又可能包括卷积、池化、全连接等层,可根据不同的网络需求做灵活改变,典型的有循环神经网络、卷积神经网络、长短期记忆递归神经网络[8]。
2 基于深度学习检测的实验方案
2.1 设计孪生神经网络模型
孪生神经网络由两个权重共享的神经网络连体而成,本文使用由两个VGG16 神经网络[9]组合而成的网络。VGG16 是由牛津大学计算机视觉组和Google DeepMind 公司于2014年研发出的深度卷积神经网络,在图像识别方面有很好的效果。
基本的VGG16 的卷积层和池化层可以划分为5 个block,在此之后连接三个全连接层再输出。流程为:
(1)一张原始图片被resize 到(224,224,3);
(2)进行五次卷积和最大池化操作后,输出的特征层为128 通道,输出net 为(7,7,128);
(3)利用卷积的方式模拟全连接层,输出net 为(1,1,4096),进行两次;
(4)利用卷积的方式模拟全连接层,输出net 为(1,1,1000);
最后输出每个类的预测。
而本文所使用的VGG16 是在这个基础上做了一些调整,第五个池化层的池化核为1*1。本文输入的图片被resize 到105*105*3,各层的结构及输出如表1所示,特征处理流程如图1所示。

表1:本文主干网络结构
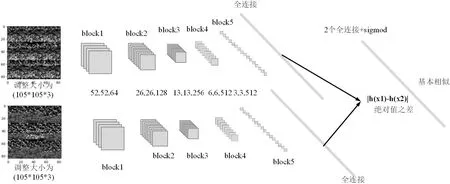
图1:特征处理
2.2 数据集
数据集包括恶意流量和白流量两部分。本文训练模型所使用的恶意流量数据来自Canadian Institute for Cybersecurity于2014年创建的ISCX僵尸网络数据集[10],其中包含七种僵尸网络,大小为4.9GB。白流量是通过Wireshark 在个人PC 的以太网卡上捕获,包括钉钉、爱奇艺、淘宝等常用应用流量共5.1GB。
2.3 数据集预处理
本文的原始数据集为Pcap 格式。Pcap 文件包括文件头,包头和包数据等部分。所使用的数据预处理工具为一个开源工具集USTC-TK2016,预处理的目的是将原始流量数据(Pcap 格式)转换为本文所需的输入数据(PNG 格式),它包括流量拆分、流量清洗、图像生成三个部分。原工具集还有第四步IDX 转化,本文所需数据格式仅为灰度图,因此不进行最后一步操作。
(1)流量拆分:是指对连续的原始流量进行拆分,使之成为离散的流量单元。
(2)流量清洗:是指对流量进行匿名化操作。主要在数据链路层和IP 层进行操作,具体操作为随机化MAC 地址和IP 地址。不过此步骤有可能不执行,例如当流量来自同一网络时,MAC 地址和IP 地址就不再是能够区分流量的特征了,此时便可省略该步骤。
(3)图像生成:要将文件大小统一为784 字节,过长则截取,过短则填充,再转化为28*28 的灰度图。
3 仿真实验与结果分析
3.1 仿真环境
本次实验使用设备操作系统为Windows10,处理器为Intel Core i5-7300,显卡为GTX1050(4GB),内存为16G,开发环境为Pycharm,Python 版本为3.8,学习框架为Pytorch,CUDA 为10.0。
3.2 结果与分析
在使用孪生神经网络完成模型搭建后,将一定数量的某种性质的流量图片作为基准数据集,分别取白流量以及恶意流量转化后的灰度图与基准数据集中的数据进行轮询对比,两次对比结果如图2 和图3所示。

图2:对比结果1

图3:对比结果2
当将两张图片比较后的similarity 值接近0 时,可以判断所要检测的数据为白流量;当similarity 值接近1时,可以判断所要监测的数据为恶意流量。
除孪生神经网络外,本文还用支持向量机算法(SVM)、随机森林算法(RF)对流量进行了训练与识别。所使用的SVM 的kernel 即核函数为RBF,核函数参数gamma 为0.001。所使用的RF 的分类器个数为10;bootstrp 值为True,即对样本集进行有放回抽样来构建树;oob_score 值为False,即不采用袋外样本来评估模型的好坏。
本文对所有算法进行5 轮,并取平均准确率进行了对比。结果显示,SVM、RF、孪生神经网络的平均准确率分别为0.741、0.729、0.944。孪生神经网络的准确率明显高于前两者。为排除非均衡样本的影响,本文又使用了8:2 的正负样本进行了5 轮训练,所得平均准确率为0.941,与均衡样本并无明显差异。这说明孪生神经网络可以很好地规避了数据集非平衡性对分类结果的影响。综上所述,本文使用孪生神经网络作为流量检测系统的核心算法。
4 攻击流量识别系统的设计与实现
本文开发的攻击流量识别系统拟解决的主要问题为识别流量中的攻击流量。系统主要包括流量包上传、数据预处理、流量包检测、结果展示这四个模块,如图4所示。
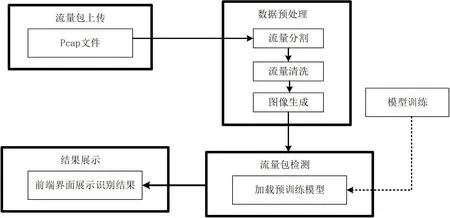
图4:系统组成
(1)流量包上传:能够获取所需检测的流量包的文件路径。
(2)数据预处理:系统获取的原始数据格式是Pcap 格式,需要进行数据预处理工作。结合第三章有关数据处理的叙述,此处需要进行流量拆分、流量清洗、图像生成等操作。
(3)数据包检测:基于功能2 转化后的PNG 格式文件,以及第三章所述的网络模型,运用孪生神经网络对流量包进行检测。
(4)结果展示:在前端界面展示功能(3)中所检测出的结果。
当该系统运行时,可在前端界面将待检测流量包上传到指定文件夹,对上传的Pcap 文件进行流量分割、流量清洁、图像生成等操作后转化成可以放入模型中检测的PNG 格式,再通过加载模型训练得到的预训练模型对转化后的文件进行轮询检测,最终在前端界面展示结果。
一些对于隐私性、稳定性要求比较高的网络,使用实时的入侵检测系统可能会对性能有影响,此时便可使用该系统进行旁路检测,即在网络受到攻击后,通过分析这些保留下来的攻击流量包对流量进行分析,以便今后对网络进行升级保护。一些简单小型网络,1-2 秒内的流量条数在1-400 条不等,该系统可以对流量包进行在线准确检测。
5 结语
本文主要分析了当前网络安全领域所面临的一些亟待解决的问题,例如网络攻击形势日渐严峻等等;并阐述了将机器学习算法应用于流量识别领域的可行性,对比并选出了一种适合于攻击流量识别的算法,并利用这种算法设计出了攻击流量检测系统。
