基于Hadoop的云盘存储系统设计与实现
2023-05-30徐翔张光亚
徐翔 张光亚

关键词:Hadoop;HDFS;云盘;分布式存储
中图分类号:TP317 文献标识码:A
文章编号:1009-3044(2023)03-0078-04
1 引言
随着目前互联网产业的飞速发展,以及通讯设备应用的普及,计算机在人们日常生活中发挥着越来越重要的作用,信息的处理、传输和采集已然成为现代信息技术的三大基石[1]。在未来,随着大数据、物联网、人工智能、5G等技术的不断突破与发展,全球的数据量将越来越大,信息的存储和管理变得复杂,单机硬盘存储已满足不了用户的文件存储和管理需要。
为了适应目前信息化社会对于支持网络和多种数据信息的应用软件的要求,以网络存储为核心的个人云盘存储系统应运而生。云盘存储相对于传统的实体磁盘来说更方便快捷,用户不需要把储存重要资料的实体磁盘带在身上,而可以通过互联网轻松地从云端读取自己所存储的信息,解决了单机硬盘存储量少、管理效率低、网络传输能力差等有关于文件存储的问题。
在云存储服务面向用户使用之前,用户数据的存储存在一定的局限性,例如当用户需要向个人存储系统中存储海量数据文件时,因系统本身没有实现大数据文件优化存储处理的方案,原本的系统存储性能将会很大程度地降低。此时即使对存储服务器进行扩展升级,存储性能也不会有明显的提升。因此,相对于传统的存储服务,云存储无论是对于需要更大存储空间的个人,还是对于寻求高效异地数据备份解决方案的企业都越来越受欢迎。云存储提供了一种以安全可靠的方式存储和迁移数据的方式,它允许个人和企业将他们的文件存储在云服务提供商处,以便他们能够在网络设备上对个人文件进行访问。
基于Hadoop[2-4]的HDFS是谷歌文件系统的开源实现项目,项目成立之后便逐渐成为各个企业或机构的云存储系统解决方案,同时也是当前在云存储领域最重要的研究对象。HDFS[5]在Hadoop集群中担任着集群数据存储重要角色,具有高稳定性与可扩展性等优点,并且能够运行在廉价机器上,一定程度上降低了云存储系统设计的成本。国内互联网巨头百度和阿里巴巴分别在2006年和2012年就对Hadoop进行关注并研发使用,解决了大数据云存储的相关问题,为用户提供了底层的模型计算以及存储服务。
基于Hadoop的HDFS分布式文件系统是当前云存储领域的研究热点[6-8]。本课题研究并设计以Ha? doop为基础的大数据云盘存储系统具有重要意义。
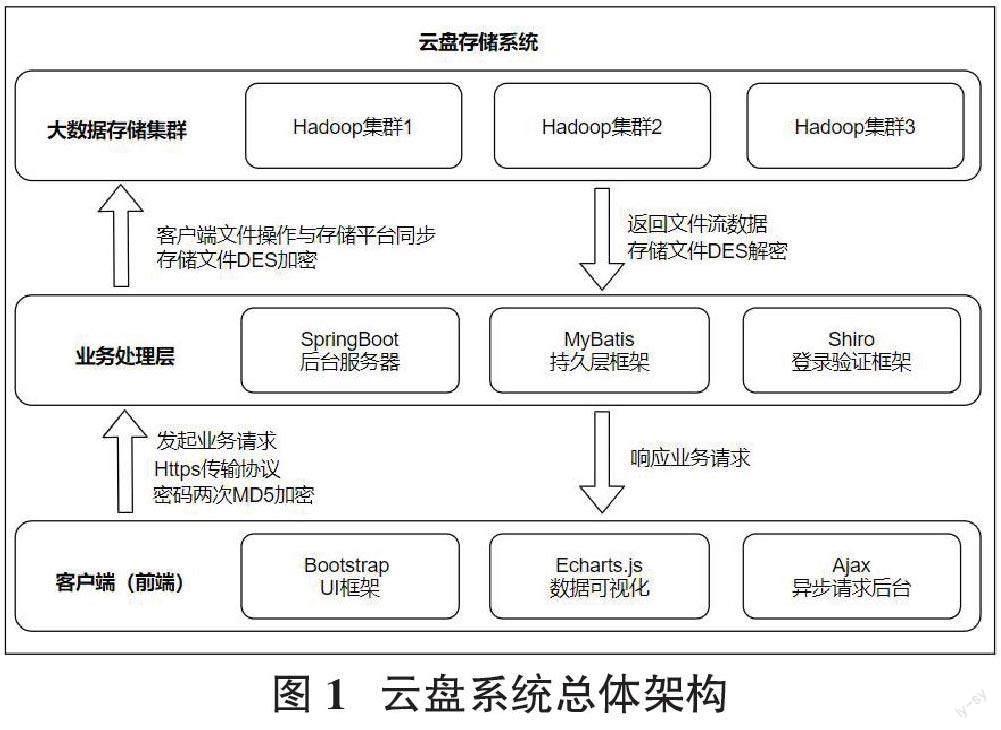
2 云盘系统总体架构
本系统的总体架构分为三部分:客户端、业务逻辑层及大数据存储集群,具体如图1所示。
用户从客户端中向后台服务器发起用户注册与登录请求,验证通过后可以在个人云盘空间内管理自己的目录与文件,可以对目录或文件进行新增、删除、重命名等操作。用户向后台服务器发起的所有请求都需经过安全性的处理,以防网络攻击者窃取用户的个人隐私信息。
業务处理层则用于处理用户发起的具体请求,若业务处理的过程中存在逻辑错误,则会向用户弹出错误提示框,让用户规范自己的相关操作。对于用户上传的文件数据,后台服务器负责将其转化为流数据,并经过加密处理后存入大数据存储集群中。用户的文件存储数据的相关记录将存储至MySQL数据库内。
在大数据存储集群中,由于HDFS集群具有副本机制,每个Hadoop节点都会分别存储一个文件的副本,即一个文件有3个副本,这些副本可以根据特定的算法分配到三个Hadoop节点中,一定程度上避免了数据丢失的情况。故大数据存储集群必须使用三个或三个以上的服务器,从而实现Hadoop全分布式的集群环境。
3 云盘系统实现
3.1 前端Web 页面设计
云盘系统的前端界面采用基于Bootstrap的UI框架,实现用户登录注册界面及云盘系统模板界面。Bootstrap是一个开源的、基于HTML5及CSS3和JS的响应式布局框架,因此它可以很好地兼容电脑端页面与手机Web端页面的布局。在本系统中,考虑同时设计电脑端页面及手机端页面,方便用户在多种形式的设备上使用本系统。
用户在前端对云盘进行的一系列操作将使用经过定制后的Ajax技术,用于异步请求后台资源,并返回固定格式的用户提示框。为了方便用户能够在线读取特定格式的文件内容(如文本、图片等),还引入了基于Bootstrap的文件读取框架。对于数据分析模块,为满足数据可视化需求,引入了较为热门的Echarts.js组件,用以生成数据图表信息。
3.2 后台Web 服务器设计
云盘系统采用SpringBoot作为后台Web服务器基础框架,并使用MVC模式将后台服务器分为接口层(pCeor)nt三rol层ler架) 、构业,务完逻成辑整层个(Se系rv统ice的) 和数数据据传链输路和层交(M互ap。?MyBatis是一个持久层框架,用于建立数据库的访问链接,在此过程中开发者只需关注SQL语句的书写逻辑,方便快捷,且能与SpringBoot完美集成。系统中还采用了Shiro用户登录安全验证框架,它能够轻松地与JavaSE和JavaEE进行集成,用于用户登录时的认证、授权、加密、会话管理等功能。
3.3 数据库设计
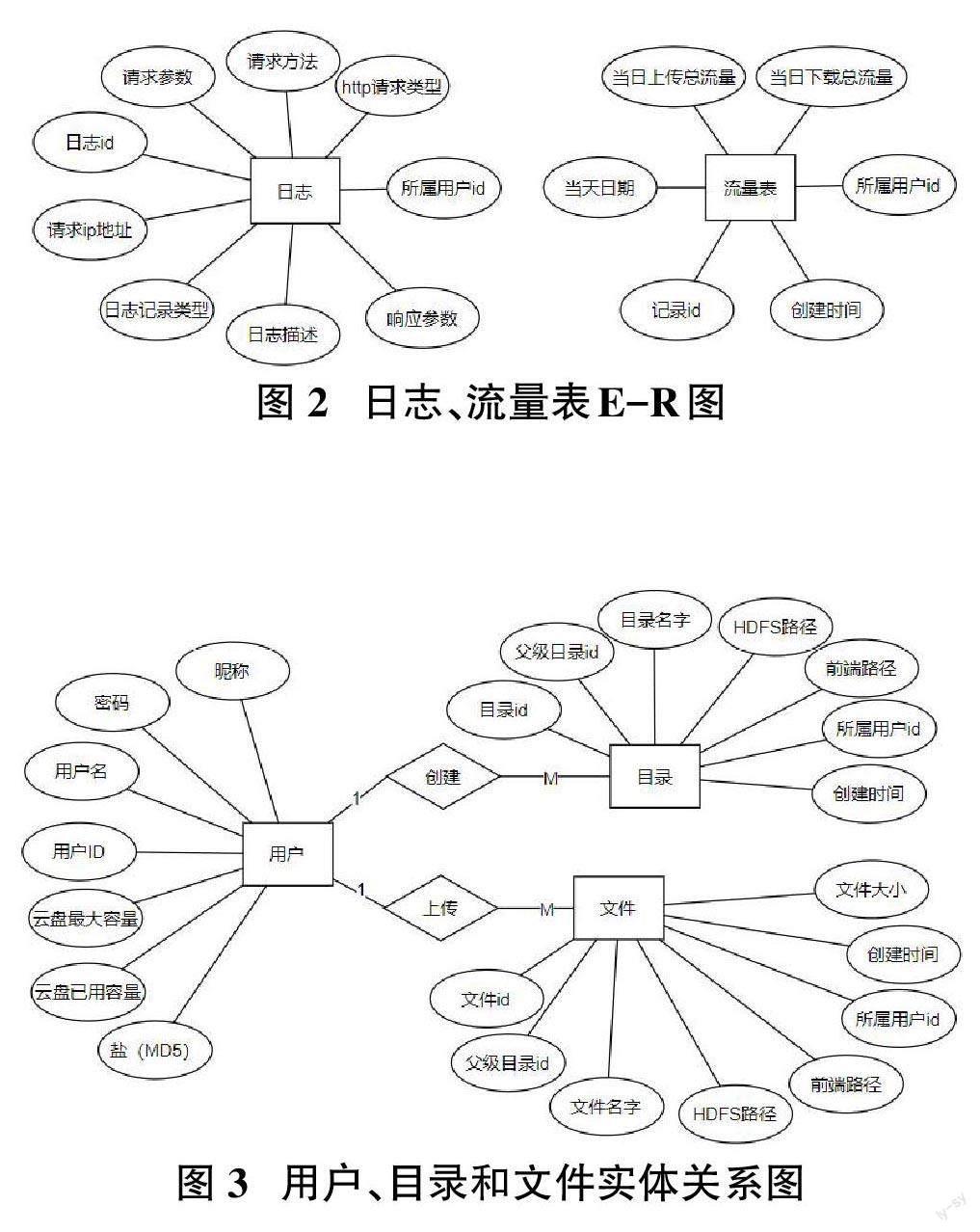
数据库概念设计如图2所示,包含用户、目录和文件实体。每个用户可以创建多个目录及上传多个文件,但是一个目录或文件只能够属于一个用户,因此用户与目录、文件之间都是属于一对多关系。
为了统计用户的相关操作信息以及操作云盘时所产生的流量数据,还需设计日志表实体与流量表实体,实体关系如图3所示。日志实体主要的字段为所属用户ID和响应参数,用于统计用户的相关操作参数,同时也包括用户上传与下载的流量使用参数,日志表为流量统计提供了相关的数据源。流量表实体则是用于记录数据分析后的流量信息,主要字段有所属用户ID、当日上传总流量以及当日下载总流量等。
3.4 基于MapFile 的小文件存储
HDFS设计之初就是为了存储大容量文件,并没有对小文件的存储进行相关的优化。在Hadoop2.0版本之后,HDFS中的每个文件存储数据块以128MB为单位,而用户个人数据文件(以文档、图片等为主)的容量大小远远小于128MB的数据块阈值,这些小文件额外占用了HDFS中更多的容量空间,造成存储空间的浪费。当用户数量增大时,HDFS便迎来了大量小文件存储所造成的存储效率问题。
为了解决HDFS不适合存储小文件的问题,提出了使用基于MapFile的方案来优化小文件的存储,提高存储效率。MapFile基本上由两大部分组成,分别是用于存储数据的Data块,以及存储索引文件的In? dex块。在使用MapFile方案存储小文件时,文件数据将会被分为一个键值对,该键值对中的“键”指的是序列化后的文件名,“值”则是指文件本身的内容。多个文件数据的键值对数据会被合并为一个大文件存储在Data块中,与此同时建立每个文件数据的映射关系,在Index索引块中记录每个文件数据的键值对信息。这样一来,在通过MapFile访问小文件时,可以通过Index索引块快速定位到相关的文件内存位置,提高小文件检索效率。
4 系统测试
4.1 测试环境搭建
4.1.1 Hadoop 集群搭建
为了对系统进行测试,搭建了具有三台服务的Ha? doop集群。服务器采用Linux系统,基本配置相同。为了快速搭建Hadoop集群,首先创建一个模板服务器,然后通过拷贝的方式复制另外两个相同配置的服务器。
模板服务器名称为Hadoop102,默认安装有Java JDK8与Hadoop3.1.3两个必要组件。另外两台服务器名称分别为Hadoop103和Hadoop104。将Hadoop102 中的JDK与Hadoop组件复制给这两个新服务器。为了实现跨服务器传输文件,采用shell语言的rsync命令,其具体作用是把服务器指定目录的所有文件拷貝到另一个服务器。最后,把Hadoop的重要运行节点分配到三台服务器中。在Hadoop全分布式环境中,为了保证集群正常运行,需要启动五个基础节点:Na? NmaemNeodNe(od管e(N理am节e点No)d、eD副at本aN节od点e()工、R作es节ou点rc)eM、Saencaognedr(ar资y?源管理节点)以及Nodemanager(监控资源节点)。其中,每个服务器都必须拥有一个DataNode 与一个Nodemanager节点,以保证每个服务器能够正常运行相关程序。因此,对于另外三个重要节点NameNode、Sec? ondaryNameNode以及ResourceManager,需要分别分配到三个服务器中。服务器的节点分配情况如表1所示。
为了分配服务器节点,需要在各服务器的core- site.xml文件中配置NameNode节点的主机地址,并指定NameNode 启动在Hadoop102 服务器的8020 端口上。NameNode节点关键属性配置如下所示:
在每台服务器的hdfs-site.xml 文件中配置Sec? oNnadmaeryNNoadme节eN点od启e节动点在的H主ado机op地10址4服,并务指器定的S9e8c6o8nd端ar口y?上。关键属性配置如下所示:
在每台服务器的yarn-site.xml 文件中配置Re? saoguerrc节eM点an启ag动er在节H点ad的oo主p1机03地服址务,器并上指。定关Re键so属ur性ceM如a下n?所示:
经过以上合理配置的Hadoop集群即使有一台服务器发生了故障,其他两台服务器仍然保留着重要的数据信息,最大程度上避免数据丢失。
4.1.2 后台Web 服务器搭建
后台服务器将以SpringBoot作为基础框架,以Ma?ven作为项目管理工具。当一个基于Maven的项目创建完成后,需要使用Maven仓库将相关依赖属性添加到pom.xml 文件内。为了让Maven 项目引入Spring? Boot框架,则需要向pom.xml文件中添加如下所示的基础依赖。
引入成功后,使用Java开发工具启动SpringBoot 项目,后台服务器就已具备了基础的Web服务器请求与响应的功能。为了使后台服务器具备上文“技术架构设计”中所描述的相关技术,还需要添加Mybatis框架、shiro框架、Hadoop客户端等依赖,具体的依赖属性配置如下所示。
后台服务器搭建还需要配置HTTPS请求协议,为此首先申请SSL证书。目前较为成熟的云计算服务器腾讯云或阿里云可进行免费申请。获取证书后,将证书相关文件导入SpringBoot项目中,随后通过向ap? plication.yml文件添加相关配置来完成协议的导入。具体导入代码如下所示:
最后,为了解决HTTP协议兼容问题,设置HTTP 页面重定向到HTTPS协议页面中。
4.2 系统实现效果
设计了测试用例对系统登录、新建目录、上传文件、删除文件、下载文件、文件夹重命名等功能进行了测试,系统实现效果如图4所示。
4.3 系统流量统计
为了测试系统的稳定性,对系统进行了为期8天的上线测试,测试用户数量为2-10之间的随机值,系统流量统计情况如图5所示。用户对云盘文件的操作记录将会记录到数据库中的日志表内,当需要进行数据分析时,后台服务器会对日志表的数据进行筛选整理并导出包含序号、用户ID、日期、上传流量和下载流量五列字段的数据集,随后再将数据集上传至HDFS集群中执行MapReduce数据合并分析。分析完毕后,输出结果将自动写入MySQL数据库中的“流量统计表”内。
5 结束语
本文采用分布式文件系统Hadoop设计并实现了云盘存储系统,可实现云端文件的管理和存储功能,包括新建文件夹、删除文件夹、上传文件、下载文件、文件重命名等。本文详细介绍了系统架构、前端页面设计和后台服务器搭建等设计与实现细节信息,为同类系统开发提供了参考。
