基于LDA的电影主题自动分类方法的研究
2023-05-30李璐王妍王艳娥杨倩
李璐 王妍 王艳娥 杨倩
摘要:针对传统采用人工方式对电影主题进行分类存在主观性强、分类标准不统一的问题,提出了一种基于LDA的电影主题自动分类方法,通过对电影简介数据进行建模,计算出电影主题的概率主题模型的联合分布公式,使用Gibbs采样算法求解联合分布公式,得出电影的主题分布及电影主题关键词的分布,并根据这2个分布完成电影主题的自动分类及类别的自动标识,使用电影简介数据对电影主题进行分类实验。实验结果表明,该方法能够对电影主题进行准确分类,精确度达到95%,从根本上消除了人工分类方法中存在的主观性强、分类标准不统一的问题。
关键词:LDA;Gibbs采样;电影主题;自动分类
中图分类号:TP391.4文献标志码:A文章编号:1008-1739(2023)03-58-4

0引言
电影在娱乐、教育及文化传播等领域具有重要作用,对电影进行主题分类,可以加深电影的宣传也方便用户按类别筛选感兴趣的电影。目前电影主题都由导演或制片人设定,由于制片人设定主题的标准不统一,导致电影主题设定存在主观性强、偏差较大的问题,因此采用数理统计、数据挖掘等技术对电影主题进行科学分类已经成为一种趋势[1-2]。传统文本情感分类分为2种:机器学习与语义指向。文献[3]试图根据文档中不同词语的共现频率训练分类器;文献[4]把词语分为正面与负面2类,通过计算文本中所有情感词的正负来判断文档的分类;文献[5]提出的英文文本分类模型,使用词向量构建文本输入框,一定程度上提高了文本分类指标;文献[6]使用音频识别方式进行文本分类。现有研究多数针对挖掘文本本身的好坏程度,忽略主题特征词及隐含主题的选择,主题模型LDA可以挖掘文本隐含主题,提升分类准确率。
1电影主题分类的整体流程
电影主题分类步骤一般可分为3步[7]:一是数据预处理阶段,在数据预处理阶段主要是对电影简介内容分词、去停止词等;二是构建LDA算法模型;三是使用LDA算法模型电影主题分类。电影主题分类步骤如图1所示。

2 LDA主题模型
使用LDA主题模型对电影主题分类的核心思想是:利用电影简介的文本信息挖掘文本与词语之间所隐含的隐含主题,然后利用主题分布刻画电影主题,进而计算电影之间的关系。LDA主题模型利用贝叶斯理论,先假设电影简介内容中的每一个词的先验共轭分布为Dirichlet分布,电影简介样本数据服从多项分布,后验概率也服从Dirichlet分布。通过统计得到词的分布,然后使用Gibbs采样去计算电影主题分布和主题中词的分布[8-9]。
电影主题主旨的概率分布在LDA算法模型中是通过每篇电影中的信息内容简介来表示的,概率分布则是通过电影主题主旨中诸多单词来构成的。所以LDA算法的核心机理如下:
①电影简介内容信息总计篇,包括个主题。
②任意一个长度为的电影简介内容信息都有自身的主题分布规则,服从参数为的Dirichlet多项分布。
③每个主题也有不同的词分布,服从参数为的Dirichlet多项分布。
④整篇电影内容简介中的第个词的描述是通过随机采样生成词来描述的,首先根据主题分布中进行采样主题,其次在被采样的主题中针对词分布采样词。随机采样词结束的条件是篇电影简介内容信息全部执行。
LDA算法的贝叶斯图模型如图2所示。
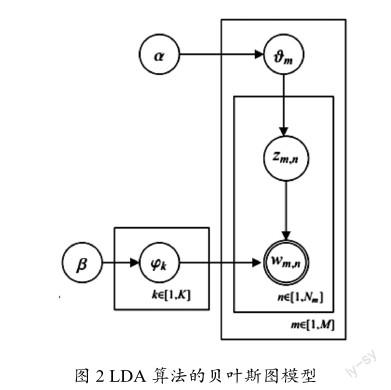
LDA图模型的参数说明如表1所示。

3采用Gibbs采樣求解LDA


4实验结果与分析
电影主题分类的第一步是对数据进行预处理,首先将电影简介内容进行分词操作,常用的分词工具有LTP-cloud、ICTCLAS和Stanford汉语分词工具等,而且该工具包还具有免安装、节省硬件、跨平台和支持多种编程语言的特点,因此本系统使用LTP-cloud作为分词工具。然后去停止词,停止词是指一篇电影简介内容中的“的”“也”“在”“和”等,在自然环境中出现频率非常高,但是对电影内容介绍没有实质影响的那类词。经过前两步预处理后的文本,并不能直接放到计算机中进行计算,还需要把文本编码成计算机可以识别的格式,具体做法是构建词袋模型,把文本中的每一词汇用数字index指代,并把原来的电影简介内容变成一条长数组。电影简介数据如表2所示,该数据集来自于豆瓣电影8 253部电影的简介数据。

将电影简介数据进行预处理,给定主题一个初始值10,主题的取值是一个先验值需要提前给定,接着把预处理好的数据放入搭建好的算法模型中,得出每个电影的主题分布与每个主题的词分布,图3是每个主题对应的词分布,从图中可以看出,每个主题中每个词出现的概率是不一样。图4是电影1~电影10对应的主题分布,从图中可以看出,电影1属于一个主题,电影2,4,5,6,7,8属于一类主题,电影3,9,10属于一类主题。
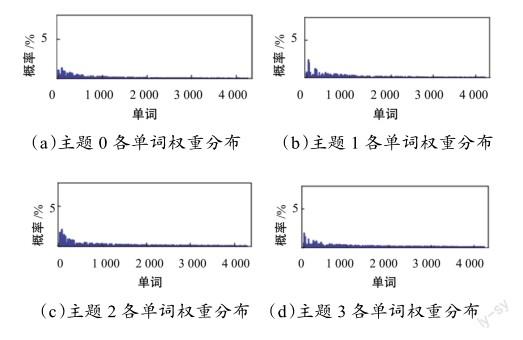

通过豆瓣电影8 253部电影实验数据表明,基于LDA的电影主题自动分类方法是有效的,该模型利用LDA主题模型获得单词的主题分布,计算单词与其上下文词的主题相似度,通过统计得到词的分布,然后使用Gibbs采样去计算电影主题分布和主题中词的分布,能够对电影主题进行准确分类,且分类准确率达到95%,可以从根上上消除人工分类的一些主观性问题。
5结束语
针对传统电影分类存在主观性强、分类标准不统一及分类忽略主题隐藏含义等问题,引入LDA主题模型对豆瓣电影8 253部电影的简介数据进行电影自动分类。首先对电影简介数据去除冗余无用信息进行数据预处理,其次通过对电影简介数据进行建模,计算出电影主题的概率主题模型的联合分布公式,使用Gibbs采样算法对联合分布公式求解,从而得出电影的主题分布及电影主题关键词的分布,并根据这2个分布进行电影无标签数据进行标识,最后使用8 253部电影简介数据分类模型实验,精度达到95以上,可以作为电影自动化分类的研究基础。
参考文献
[1]周强.中国电影分类理念与类型电影特性研究[J].电影文学, 2021(9):39-42.
[2]蔡梦楠.基于分类模型的电影票房影响因素研究[D].南京:南京师范大学,2021.
[3] LINDSAY G W. Feature-based Attention in Convolutional Neural Networks[J/OL].[2022-10-20].https://arxiv. org/abs/1511.06408.
[4] MENG J E, ZHANG Y, WANG N, et al.Attention Pooling-based Convolutional Neural Netwaok for Sentence Modelling[J].Information Science and International Journal, 2016,373(C):388-403.
[5] KIM Y. Convolutional Neural Networks for Sentence Classifica-tion[J/OL].[2022-10-11].https://arxiv.org/abs/1408. 5882.
[6]肖建.基于Spark并行LDA主題模型的研究[D].重庆:重庆大学,2016.
[7]郑涵.基于迁移主题模型的文本分类方法研究[D].烟台:山东工商学院,2021.
[8]胡楚君.基于Hadoop的微博舆情分类的研究与实现[D].北京:北京邮电大学,2016.
[9]郑飞,韦德壕,黄胜.基于LDA和深度学习的文本分类方法[J].计算机工程与设计,2020,41(8):2184-2189.
