基于改进YOLO v5复杂场景下肉鹅姿态的检测算法研究
2023-05-29刘璎瑛曹晅郭彬彬陈慧杰戴子淳龚长万
刘璎瑛,曹晅,郭彬彬,陈慧杰,戴子淳,龚长万
(1.南京农业大学人工智能学院,江苏 南京 210031;2.农业农村部养殖装备重点实验室,江苏 南京 210031;3.江苏省农业科学院畜牧研究所,江苏 南京 210014)
家禽的智能化养殖已逐渐成为福利化养殖的发展需求。家禽的姿态[1]和行为与它们的身体状态和健康状况密切相关,不同的姿态和行为会传递不同的健康信息[2]。肉鹅是群居性家禽,具有合群性[3],其姿态和行为的一致性较强。传统的肉鹅健康状态判断主要通过饲养人员肉眼长期观察肉鹅姿态和行为,根据经验得出结论,主观性强、耗时费力。以计算机视觉和深度学习相结合的方式,应用在肉鹅养殖过程的姿态识别上,养殖管理人员可以通过养殖场的摄像头远程获取自然状态下肉鹅的姿态变化,为后续实现自动监控家禽生长状况及异常行为的预警有重要意义。
伴随着人工智能技术的发展,计算行为学逐渐得到学界的重视[4]。将深度学习[5-6]算法应用于禽畜的姿态和行为识别[7]成为当下研究的热点。Fang等[8]通过构建肉鸡姿态骨架特征点,跟踪其身体特定部位,并结合深度神经网络(DNN)和贝叶斯模型(BM),实现了对肉鸡站立、行走、奔跑、进食、休息等姿态的准确识别。李娜等[9]筛选了7 988幅图片对鸡的采食、趴卧、站立、梳羽、打架和梳羽行为进行标注,利用YOLO v4目标检测模型识别,并采用时间序列分析方法提取持续时间大于30 s的梳羽行为,实现群养鸡只行为的实时自动监测。Shao等[10]建立了人工标注的猪姿态识别数据集,包括站立、俯卧、侧卧、觅食4种猪姿态,使用YOLO v5算法对单个猪目标截取后,利用语义分割和ResNet网络对猪的姿势进行分类,准确率高达92.45%。刘亚楠等[11]利用YOLO v5模型识别母猪、仔猪姿态,并通过加入db4小波的方法,实现了非接触式母猪哺乳行为的判定和哺乳时长的监测。为了提升网络性能,学者们先后提出了SENet(squeeze and excitation networks)[12]、CBAM(convolutional block attention module)[13]、ECA(efficient channel attention)[14]等注意力机制[15-18]。这些研究表明增加注意力机制可以提高网络的检测能力,但尚未有将其应用于畜禽姿态识别和行为分析的相关研究。
YOLO模型是目前工业领域使用最多的检测网络,采用one-stage算法,网络运行速度快,内存占用小。YOLO v5模型是YOLO系列的最新成果,在继承原有YOLO模型优点的基础上,因其更复杂的网络结构和训练策略技巧等使其具有更优的检测精度和更快的推理速度。按照其网络宽度、深度的不同,一共有4个模型,本文选用尺寸最小的YOLO v5模型,易于部署在硬件配置相对简单的养殖场环境。目前将YOLO检测算法应用在鸡、猪等禽畜姿态行为识别的研究较多,但对鹅这种水禽研究较少。夏季高温天气,鹅热应激反应大,通过监测站立、休憩、饮水和梳羽4种姿态可以提前预警,降低死亡率。鹅场内的光照环境复杂,且存在铁丝网、网状地格、遮阳布、饮水器、食盆等干扰物,鹅群易聚集,造成视频中出现较多肉鹅遮挡的场景。故本研究在YOLO v5模型基础上增加了注意力机制模块,改进优化网络结构,并对比分别增加SENet、CBAM、ECA不同注意力模块后网络的检测效果,提高养殖场复杂场景下肉鹅4种姿态的检测能力。同时根据养殖场实际情况,设计了明暗试验和密集场景试验,验证了算法的有效性。改进的YOLO v5模型可以实现养殖场复杂环境下肉鹅姿态准确快速检测,为后续肉鹅行为监控和健康防疫提供数据。
1 材料与方法
1.1 试验数据采集与分析
1.1.1 数据采集从养殖场获取肉鹅视频,视频拍摄于2020年8月,地点在安徽省滁州市全椒县马厂镇。视频来源于安徽天之骄鹅业有限公司的监控摄像头,视频图像分辨率为1 920×1 080,鹅的品种为扬州鹅。根据视频实际情况,从中挑选不同时段的肉鹅活动视频,利用python脚本文件对视频进行抽帧处理,每个视频按照一定的间隔抽帧获取100张彩色RGB图片,经过数据清洗后将原有的MP4格式视频数据转为800张JPG图像,包括400张白天肉鹅图像和400张夜晚肉鹅图像。图像统一编号格式为“00000X.jpg”。
1.1.2 数据集制作肉鹅的姿态十分丰富,并且由于其细长的脖子,不同姿态之间有一定的相似性,常见的有站立、休憩、饮水、吃食、梳羽和展翅等姿态。本研究选取了站立(standing)、休憩(resting)、饮水(drinking)、梳羽(feather preening)这4种常见姿态,其姿态识别分类的评判标准如表1所示。4种肉鹅姿态见图1。利用LabelImg开源标注工具对图片内的肉鹅目标进行人工标注,并将标注结果保存为PASCAL VOC格式,生成的.XML格式文件保存至预先创建的文件夹中。在人眼可区分的情况下,尽可能对图片中的所有肉鹅目标进行标注,对于模糊不清的肉鹅目标采取不标,这样可以避免因目标未标注被当作负样本进而削弱算法区分正负样本能力的影响。真实肉鹅养殖场的环境,存在栏杆遮挡、肉鹅目标露出不全、黏连等情形,对于不同情形利用大小合适的矩形框进行标注。
1.1.3 数据集划分通过python脚本文件,将800张图片及对应标签按照训练验证集∶测试集=9∶1以及训练集:验证集=9∶1的比例,完成了训练集、验证集、测试集的划分。数据集共完成13 487个姿态标注,其中训练集11 438个姿态(站立姿态2 827个,休憩姿态6 481个,饮水姿态408个,梳羽姿态1 722个),验证集1 231个姿态(站立姿态324个,休憩姿态654个,饮水姿态42个,梳羽姿态211个),测试集1 418个姿态(站立姿态351个,休憩姿态766个,饮水姿态50个,梳羽姿态251个)。

表1 肉鹅4种姿态定义Table 1 Definition of the meat goose’s four postures

图1 肉鹅姿态示意图Fig.1 Schematic diagram of meat goose posture
1.2 肉鹅姿态识别模型的建立与训练
1.2.1 实验平台与环境配置本研究基于应用灵活的Pytorch开源框架,采用搭载Windows10 64位操作系统的笔记本进行模型训练,中央处理器(CPU)为Intel(R)Core(TM)i5-8300H CPU@2.30GHz,显卡(GPU)为NVIDIA GeForce GTX 1050Ti,显存8GB,并配置深度学习Conda环境为:Python=3.8.0+torch=1.7.1+torchvision=0.8.2,CUDA版本为10.0。
1.2.2 基于改进YOLO v5的肉鹅姿态识别模型传统的如ResNet等网络只能完成单个目标图像的分类任务,本研究中每张图片中有多只肉鹅目标,对于每只肉鹅目标,都需要实现对其框选和分类,目标检测模型是实现该任务的最佳选择。为了更好适应养殖场的复杂场景,本研究通过加入注意力机制模块对YOLO v5模型进行改进,改进后的模型网络结构如图2所示。YOLO v5模型在网络结构上可以划分为输入端、主干网络(backbone)、颈网络(neck)、输出端4个部分。其主干特征提取网络采用与YOLO v4类似的CSP Darknet,Neck部分采用FPN(feature pyramid networks)结合PAN(path aggregation network)的结构,进行网络的特征融合和加强提取[19-20],自底向上路线的加入弥补加强了定位信息,提升了网络特征融合的能力。在引入注意力模块时,通过对比放置在网络不同位置的效果,最终选定放置在颈网络的尾部,不同注意力模块的结构如图3所示。CBAM模块对于输入的特征,先通过一个共享的多层感知机(multi layer perceptron,MLP)与Sigmoid函数,学习各通道的权重信息,再通过一个卷积核为3×3、 膨胀系数为2的空洞卷积[21]与Sigmoid函数,学习空间上各点的权重信息。SENet模块通过2次全连接层和Sigmoid函数后获得通道权重信息,ECA模块将2次全连接层改为一维卷积,通过Sigmoid函数后获得通道权重信息,具有良好的跨通道信息获取能力[22]。在同一环境下训练及测试YOLO v5模型以及增加注意力机制模块后的YOLO v5+SENet、YOLO v5+CBAM、YOLO v5+ECA模型,通过选取合适的评价指标,对模型进行初步分析。为了更好地验证模型的泛化性,本研究设计了明暗试验和密集场景试验,进一步对模型做出评价,最终挑选出更加准确识别肉鹅站立、休憩、饮水、梳羽这4种常见姿态的模型。肉鹅姿态识别模型的构建流程如图4所示。
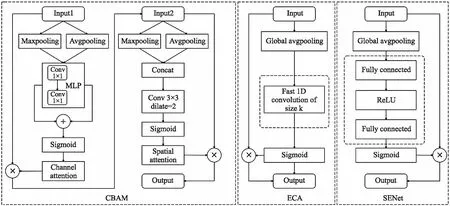
图2 改进的YOLO v5模型网络结构图Fig.2 The network structure diagram of improved YOLO v5 model
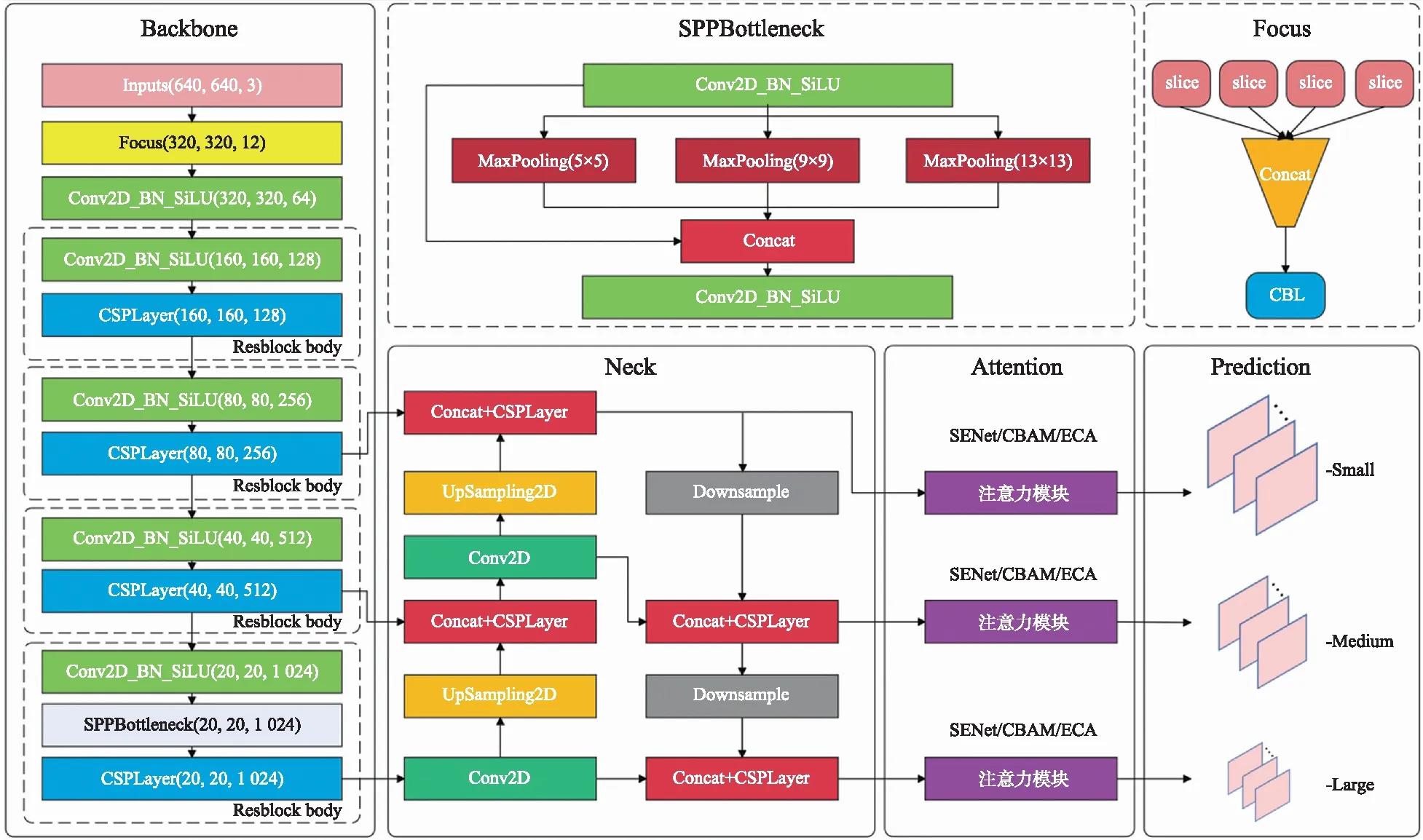
图3 不同注意力模块的结构图Fig.3 Structure diagram of different attention modules

图4 肉鹅姿态识别模型的流程图Fig.4 The flow chart of meat goose posture recognition model
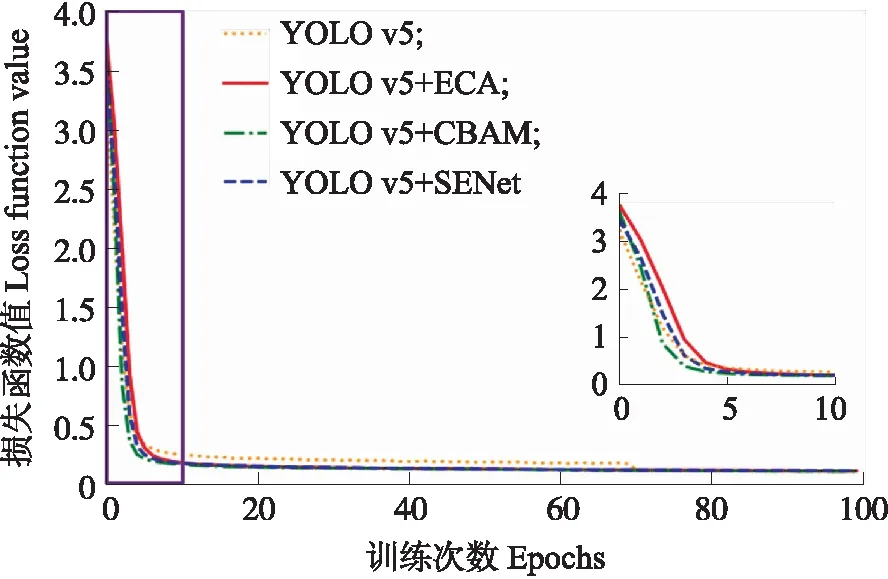
图5 改进前后YOLO v5的训练损失曲线Fig.5 Training loss curve of YOLO v5 beforeand after improvement
1.2.3 训练参数设置在YOLO v5以及改进YOLO v5的训练中,只进行解冻训练,训练的epoch设为100,批次(batch_size)设置为8,总迭代次数为8 100次,初始学习率设置为0.001,最小学习率设置为0.000 01,使用adam优化器,动量参数设置为0.937,使用余弦退火函数动态降低学习率。在改进网络中选择关闭Mosaic数据增强方法。置信度设为0.3,非极大值抑制所用的交并比大小设为0.3。损失函数由3个部分组成:Reg(矩形框回归预测)部分、Obj(置信度预测)部分、Cls(分类预测)部分。Reg部分采用CIOU损失,Obj部分和Cls部分采用BCE Loss(交叉熵损失)。在同一环境下训练,改进前后YOLO v5网络的训练损失曲线如图5所示。
1.2.4 模型评价指标采用精准率(precision,P)表示模型正确识别肉鹅的占比,召回率(recall,R)表示识别图片中肉鹅目标的涵盖程度。采用精度均值(average precision,AP)表示每种肉鹅姿态识别的精度,采用平均精度均值(mean average precision,mAP)表示所有类别肉鹅姿态的平均识别精度。采用参数量(parameters,Params)评价模型的空间复杂度,参数量表征了模型占用显存的大小,指模型各网络层的总字节数。采用计算量(floating point operations,FLOPs)评价模型的时间复杂度,计算量表征了模型运算速度的大小,指浮点运算次数。采用画面每秒传输帧数(frames per second,FPS)和单张图片的检测时间评价模型实际识别肉鹅的速度。相关计算公式如下:
(1)
(2)
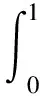
(3)
(4)
式中:TP表示实际为真预测正确的样本数;FP表示实际为假预测正确的样本数;FN表示实际为假预测错误的样本数;C为肉鹅姿态类别总数;k为肉鹅各姿态类别序号。
2 结果与分析
2.1 改进前后模型结果对比
将不同模型在同一硬件环境下检测,改进前、后识别的性能指标对比如表2所示。从表2可以看出,YOLO v5在增加不同的注意力模块后,在P、R、mAP上能够实现一定程度的提升,检测速度也有所提升,而模型的Params和Flops几乎没有增加。当加入ECA注意力模块后,模型识别效果提升最为明显,改进YOLO v5的精准率由原来的83.46%上升到84.68%,提升了1.22%,召回率由原来的84.05%上升到85.88%,提升了1.83%,mAP值由原来的86.66%上升到88.93%,提升了2.27%,FPS也从26.70上升到30.92。总的来说,注意力机制的引入有效提高了模型的检测精度和检测速度,改进后的YOLO v5+ECA模型的检测精度和检测速度最高。

表2 改进前、后YOLO v5模型的肉鹅姿态识别结果Table 2 Meat goose posture recognition results of YOLO v5 model before and after improvement
为了对YOLO v5+ECA模型的检测过程进行可视化解释,采用Grad-CAM[23]可视化方法。它将目标特征图的融合权重表达为梯度,用梯度的全局平均来计算权重,求得各个类别对所有特征图的权重后,再进行加权和得到热力图(heatmap)。热力图可以直观展示模型提取特征时关注的重点,颜色越深,模型关注的越多,红色部分(颜色最深的部分)代表模型关注的重点位置,如图6所示。从图6可以看出,YOLO v5+ECA模型在预测站立和饮水姿态时,更加关注肉鹅的颈部以及足部特征,在预测休憩和梳羽姿态时,更加关注其身体部位。

图6 YOLO v5+ECA模型的预测图像热力图Fig.6 Predicted image heatmap for YOLO v5+ECA model
同样随机挑选测试集中的1张白天图像和1张夜晚图像,利用YOLO v5和YOLO v5+ECA模型分别检测后进行对比,将各类姿态的检测数自动统计并显示在检测后的图片上,如图7所示。从图7可以看出,改进后的YOLO v5+ECA网络的检测精准度更高,检测到的姿态数更多,检测效果更好。
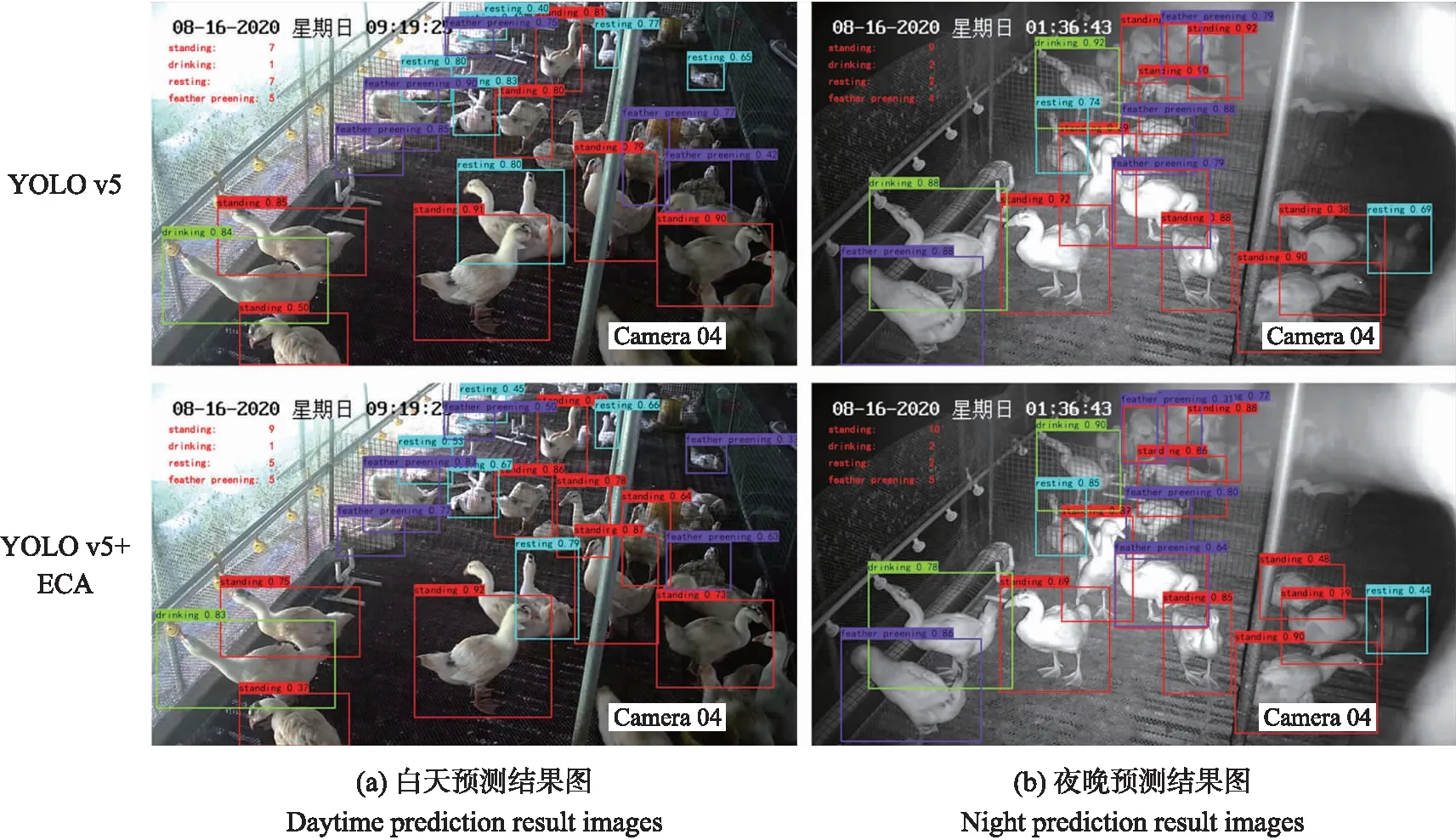
图7 改进前、后YOLO v5模型的预测结果图Fig.7 Prediction result images of YOLO v5 model before and after improvement
2.2 肉鹅不同姿态识别结果对比
为了进一步了解模型对于各姿态类别的识别效果,对改进前、后模型对于不同姿态识别的AP进行分析。从表3可见:站立姿态的识别AP最高达到91.85%,休憩姿态的识别AP最高为93.48%,饮水姿态的识别AP最高为93.00%,而梳羽姿态的识别最高只有80.42%。主要原因是肉鹅的梳羽姿态在特征上与站立和休憩均有一定的重合性,梳羽姿态包括站立时梳羽、休憩时梳羽的情形,并且训练集中站立和休憩姿态的数量要大于梳羽姿态,其中,站立姿态有2 827个,休憩姿态有6 481个,而梳羽姿态只有1 722个。所以在预测时,可能出现将梳羽姿态误判为站立或休憩姿态,从而导致梳羽姿态较低的识别精度。
2.3 鲁棒性试验
2.3.1 明暗试验在大多数传统的算法中,图片亮度的影响一直都是算法检测的一个问题。本研究同样考虑亮度对模型可能带来的影响,自制的训练集中包含400张白天图像和400张夜晚图像。为了测试模型对于亮度的敏感性,将测试集中的白天与夜晚图片分开计算模型的mAP值,相关结果如表4所示。由表4可知,模型在明暗场景的姿态识别情况差异不大,并且加入注意力机制后,模型在白天和夜晚的场景中检测精度均有所上升。

表3 改进前、后YOLO v5模型对于肉鹅不同姿态的平均精度结果对比Table 3 Comparisons of average precision for different goose postures of YOLO v5model before and after improvement %

表4 改进前、后YOLO v5模型的明暗试验识别结果Table 4 The identification results of light and dark experiments of YOLO v5 model before and after improvement %
2.3.2 密集场景试验密集场景试验是对模型小目标检测能力的考验。为了进一步测试改进后的YOLO v5+ECA模型对密集场景肉鹅姿态识别的能力,测试选取1张白天图像,并且这张图片不属于测试集中的原有照片,可以验证模型的泛化能力。YOLO v5和YOLO v5+ECA模型在密集场景中进行肉鹅姿态识别的预测如图8所示,为了直观对比模型的预测表现,图中黄色方框固定选取原图中的一块区域,并将该区域的部分误检漏检情况展示在最右边的灰色方格中。从图8可以看出,在YOLO v5中出现了梳羽姿态误检为站立姿态以及站立姿态漏检的问题,而在改进后的YOLO v5+ECA模型均得到改善,改进后的模型误检和漏检现象减少,模型在密集场景下的表现有所提升。

图8 改进前、后YOLO v5模型的密集场景试验结果Fig.8 Dense scene experimental results of YOLO v5 model before and after improvement
3 结论
本研究基于深度学习的方法,对YOLO v5算法引入注意力机制改进网络结构。通过模型的基本测试以及鲁棒性试验的对比,改进后的YOLO v5+ECA模型能够对肉鹅站立、休憩、饮水、梳羽这4种常见姿态进行较为准确的识别,平均检测精度(mAP)达88.93%,相比YOLO v5提升2.27%,检测速度为每秒30.92帧,提升4.22帧。站立、休憩、饮水的姿态识别AP都达到90%以上,梳羽姿态的识别AP值虽然只达到80.42%,但相比YOLO v5提升了6.07%。明暗试验和密集场景试验证明改进后的YOLO v5+ECA模型在复杂场景下的检测效果好,对光线的适应性强,漏检和误检现象相对较少。
本文的研究虽然有了初步的成果,但仍有不足,今后在以下方面需要进一步的完善与探索:1)由热力图分析出模型提取不同姿态特征的重点,改进肉鹅的图像标注以及实现对更多姿态的识别;2)在肉鹅姿态识别的基础上增加视频跟踪技术,进行行为分析,为肉鹅的健康生长和异常行为预警提供更多数据。
