基于AdaBoost分类器的典型战术数据链信号识别方法
2023-05-25石达宁陈永游李阳雨
石达宁,陈永游,刘 建,陈 韵,李阳雨
(中国航天科工集团8511研究所,江苏 南京 210007)
0 引言
战术数据链是现代作战体系的重要组成部分。它把地理上分散的部队、传感器和武器系统联系起来,实现信息共享,实时掌握战场态势,缩短决策时间,从而提高指挥速度和协同作战能力,可以对敌方实施快速、精确、连续的打击[1]。美国和北约对战术数据链的研究起步较早,主要形成以Link4A、Link11和Link16为代表的典型战术数据链装备,在历次战争中发挥了巨大的作用。
近年来,传统的支持向量机(SVM)和K⁃近邻(KNN)等算法在小样本、非线性及高维特征识别方面取得了一定成果。基于大数据的深度学习方法,如卷积神经网络(CNN)等也为信号类型识别提供了一条新的思路[2]。但是这些识别算法都存在使用单一分类器的问题,无法进行多维度、泛视角识别分类,Ada⁃Boost算法采用自适应的迭代算法,通过组合多个分类器,调整迭代过程中错误样本的权重,可增强分类器的泛化能力以提高训练识别结果的精度和抗噪声性能[3-4]。
本文瞄准数据链巨大的战术应用价值,通过分析与提取数据链信号的时频分布、循环谱的高阶特征,利用AdaBoost算法对数据链信号进行分类识别,进而为数据链信号后续的对抗措施打下基础。
1 典型数据链信号概述
1.1 Link4A
Link4A主要用于舰船对飞机进行控制,工作在UHF 频段,范围为 225.000 ~399.975 MHz[5]。控制站单次发送控制报文的周期恒为32 ms,且分为发射期和接收期。发射期长14 ms,用于控制站发送控制报文。接收期长18 ms,此时控制站等待收信飞机的应答报文。实际上收信飞机发送回复报文只需11.2 ms,小于接收期时长18 ms,二者相差的6.8 ms的时差用于电磁波传输。
Link4A信号的调制方式为2FSK,频偏是±20 kHz,且偏离载频+20 kHz时代表二进制“1”,偏离载频-20 kHz时代表二进制“0”。Link4A信号的数据速率为5 kbps,带宽50 kHz,占用2个25 kHz的标准信道。
1.2 Link11
Link11的工作频段有2个,分别是高频(HF)和甚高 频(UHF),范 围 分 别 是 3~30 MHz、225.000~399.975 MHz[6]。Link11 的主要工作模式为轮询,控制站会按照顺序依次呼叫前哨站,并在消息发送后转为接收状态,等待接收应答消息。
Link11进行数据传输时以帧为单位,1帧包含30 bit。Link11的数据传输速率有2种,分别为每秒75帧的快速率和每秒45.45帧的慢速率。快速率帧长13.33 ms,数据速率 2 250 bps;慢速率帧长 22 ms,数据速率1 364 bps。
Link11通过二次调制的方式生成最终信号。在基带,Link11对编码后数据进行π/4⁃DQPSK调制。在HF波段,Link11通过调幅对信号进行二次调制,具体包括上边带调制、下边带调制和独立边带调制。在UHF波段的二次调制方式则为调频。
1.3 Link16
Link16工作在L频段,设计的理论基础是时分复用技术,时间划分的最小单元是长7.812 5 ms的时隙。Link16中数据以长75 bit的字为单位进行封装且1个时隙内传输字的数量受到限制,分别为3字、6字和12字。相应地,其数据速率有3种,分别为26 880 bps、53 760 bps和 107 520 bps[7]。
Link16的数据的传输模式有单脉冲和双脉冲2种:单脉冲即每个处理后的序列只生成一个脉冲进行传输;双脉冲指每个处理后的序列生成2次脉冲,这2个脉冲分别以不同的载频进行传输。
2 数据链信号图形化特征提取
2.1 数据链信号图形化处理
2.1.1 时频分布
经典的统计信号检测与估计理论中,对信号识别是基于信号各种分离的物理参数,从时、频、空、功率等多种维度,独立或联合地进行信号的识别与判定。这种信号识别处理的方法通常依赖于二维正交变换,将信号从全维度特征空间中,向某个特定方向进行投影,抽取一种维度的信息,但是这种处理方法通常都忽略了信号不同维度特征的耦合性,从而无法提升信号识别维度,即经典的信号识别理论是一种单一维度或单一维度联合的判决过程,没有从高维度整体地识别信号特征。
另一方面,由于数据链信号采用时分多址的方式来进行多战术节点之间的组网信息交互,特别是Link16数据链采用抗截获设计,其波形同时具备扩频与跳频的特征,因此数据链信号被认为是一种非平稳信号,时频分析作为一种有效的非平稳信号处理方法,特别适合对于数据链信号的处理。同时时频分析工具能够提供信号在时、频、功率三个维度的耦合变化情况,提供了信号特征统一化的处理视角,这种特征耦合化在更高维度描述了信号的特征,特别适合于当前的基于深度学习的处理方法。
Wigner⁃Ville分布(WVD)是一种典型的非线性时频分析方法,其公式为:
式中,z(t)为输入信号,τ表示输入信号时间差。WVD具有许多优良的性能,如不会损失信号的幅值与相位信息,对瞬时频率和群延时有清晰的概念[8]。但是存在的不足是不能保证非负性,尤其对多分量信号或具有复杂调制规律的信号会产生严重的交叉项干扰,大量的交叉项会淹没或严重干扰信号的自项,模糊信号的原始特征[8]。数据链信号的WVD如图1所示。

图1 数据链信号的WVD(SNR=20 dB)
短时傅里叶变换(STFT)作为一种时频分析手段,有效改善了WVD的交叉项干扰的问题。STFT的公式可以写为:
式中,z(t)为输入信号,g(t)为窗函数,STFT的实质是将长时间大数据量的独立频谱分析拆分成多帧短时间的谱分析,通过窗函数减少信号帧与帧之间的影响。实际上这种时间上的拆分虽然减少了信号之间的交叉干扰,但是也弱化了信号时间与频率上的联系,可以认为是信号在不同时间窗口的切片,反映整个信号频谱能量随时间变化的过程。数据链信号的STFT如图2所示。

图2 数据链信号的STFT(SNR=20 dB)
2.1.2 循环谱
数据链信号虽然是一种非平稳信号,但是在较长的统计时间内来看又具有一定的周期性,也即数据链信号具有循环平稳性,而循环谱分析针对的是循环平稳信号,因此分析数据链信号的循环谱特征具有一定的优势。相较于时频分析获取信号的“时-频”特征,循环谱分析能够提取信号的“频-频”特征,建立信号频率到循环频率的联系,这在某种程度上能够展现出信号在时频域所不具备的特征。另一方面,传统的循环谱分析也是独立提取频率域或循环频率域的特征,缺乏一定的手段同时分析两者联合的特征,从而无法完全发挥出循环谱分析的所有性能。数据链信号的循环谱如图3所示。

图3 数据链信号的循环谱(SNR=20 dB)
对于一个输入信号x(t),其均值函数mx(t)和自相关函数Rx(t,τ)具有周期性,则可认为具有循环平稳性,也即:
此时就可以定义循环自相关函数为:
式中,α被称为循环频率,而循环自相关函数Rαx(τ)的傅里叶变换就被称为循环自相关函数Sαx(f),用公式表示为:
2.2 特征提取
2.2.1 伪Zernike矩特征
时频谱图和循环谱的多维度联合特征包含在图形的形状、轮廓等特征中,对这些特征的提取是数据链信号能否被识别的关键性因素。伪Zernike矩常用于图像处理中提取颜色、纹理、形状、空间关系等特征[9],本文采用伪Zernike矩对时频谱图和循环谱图的轮廓特征及轮廓包围区域进行特征提取,通过描述谱图图像的全局特征和几何特征对数据链信号进行分类。
伪Zernike矩是一种正交复数矩,如果输入图像函数为f(x,y),则其伪Zernike矩定义为:
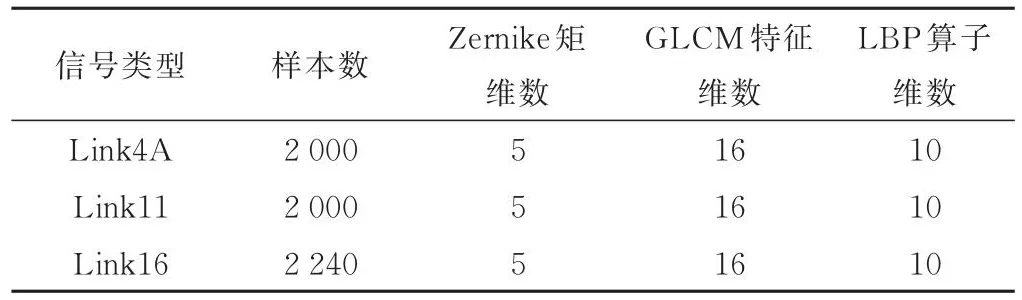
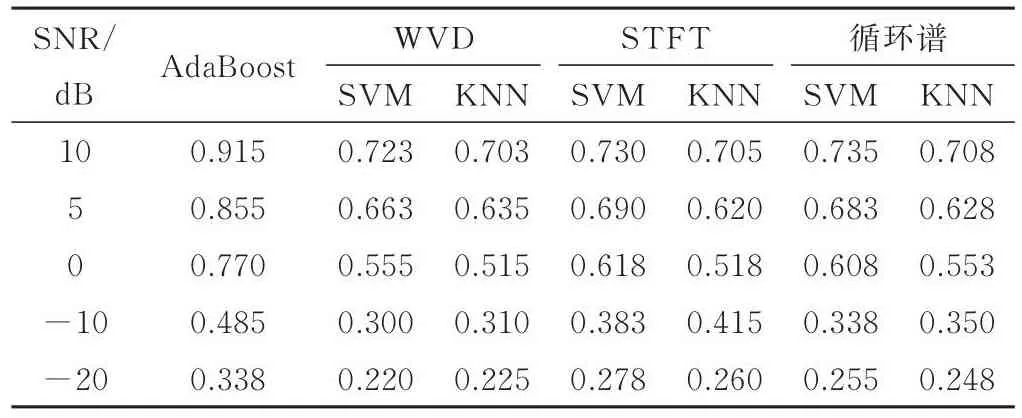
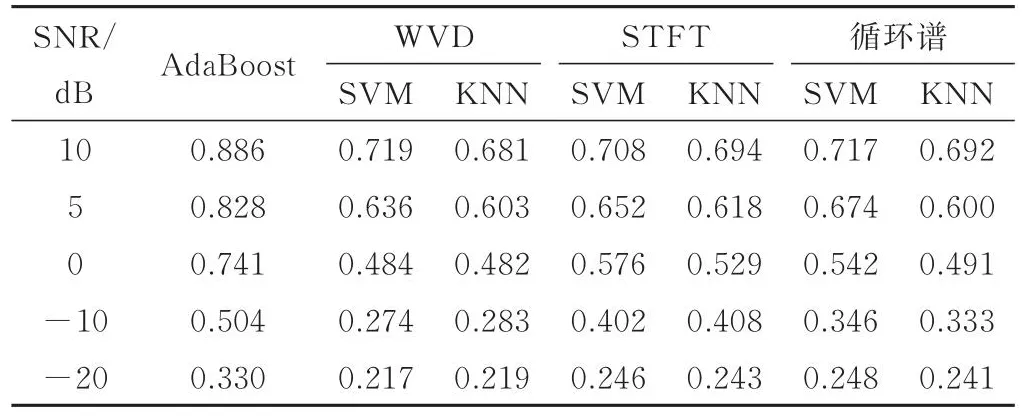
式中,n为正整数,m为整数,且|m| 式中,r=(x2+y2)12,θ=arctan(y/x)。 式(7)说明伪Zernike矩实际上是基于单位距离圆的一组完整正交投影,Rnm(r)是实半径多项式,一般被定义为: 对于一幅数字化的图像来说,其伪Zernike矩可以写为: 式中,I(x,y)为图像当前的像素点。 伪Zernike矩具有很强的图像描述能力,低阶伪Zernike矩一般表示图像的整体信息,而高阶伪Zernike矩描述图像的细节信息[10]。本文考虑采用低阶矩和高阶矩联合的方式,即采用低阶矩Z10,Z31和高阶矩Z43,Z53,Z64组成特征向量用于数据链信号识别。 2.2.2 灰度共生矩阵GLCM特征 灰度共生矩阵(GLCM)是一种纹理统计分析方法,通过描述图像中不同像素点之间的对应关系来表示图像的纹理特征分布,而无论是时频谱还是循环谱,计算当中2个维度的物理参量的交叠混合就反映在谱图的纹理细节中[11],因此可以通过对谱图的灰度共生矩阵提取代表图像的二次特征参数对数据链信号进行识别。GLCM的二次特征参数较多,本文主要选取角二阶矩、相关性、对比度和均匀性这四个统计特征,假设GLCM的元素用p(i,j)来表示,那么这四种统计特征如下。 1) 角二阶矩 角二阶矩被定义为: ASM在数学上表征了GLCM所有元素的平方和,在物理上反映了图像的纹理细节的能量,其值越小纹理就越细。 2) 相关性 相关性被定义为: 式中,μx、μy是均值,σ2x、σ2y是方差,COR反映了图像纹理细节的相似程度。 3) 对比度 对比度被定义为: CON反映了图像的清晰度与纹理细节的锐度。 4) 均匀性 均匀性被定义为: IDM反映了图像局部纹理细节变化的快慢程度。 GLCM还能够反映出图像细节的方向性特征,结合数据链信号可以工作在多频点,甚至Link16信号可以产生频率跳变,但是对于每个截获信号的观测周期内具有频率时间移不变特征,因此其GLCM在方向上必然能够表现出不同的特征。本文选取 0°,90°,180°,360°四个不同方向分别计算GLCM的二次特征,构成一组16维的特征向量用于数据链信号识别。 2.2.3 LBP算子特征 LBP算法的核心思想是用中心像素的灰度值pc作为阈值,与其相邻的像素灰度值pi作比较来表述图像局部纹理特征[12],当统计窗口内其他像素灰度值大于中心像素灰度值时,对应像素位置置1,否则置0,然后根据像素不同位置进行加权求和作为该窗口的LBP值,用公式表示为: 式中,P表示相邻元素个数,R表示临域半径。为了消除图像旋转对LBP算子的影响,引入旋不变LBP,将其定义为: 式中,ROR(x,i)表示将x右移i位。LBP算子中高频次的出现某些描述纹理的重要模式被称为Uniform模式,Uniform 模式 LBP 算子表示为 LBPu2P,R,基于 Uni⁃form模式旋转不变LBP算子LBPriu2P,R被定义为: 本文采用(P,R)取(8,1)的旋转不变Uniform模式LBPriu2P,R算子,计算数据链信号的时频图及循环谱图所得10维特征,用这10维特征构成特征向量进行信号的识别。 AdaBoost算法是一种设计分类器的算法,其基本的思想是设计大量分类能力一般的弱分类器,通过将这些弱分类器组合在一起,构成一个分类能力较强的强分类器[13]。理论分析可以证明,只要弱分类器的分类能力稍强于随机猜测,那么当数量足够多的分类器组合起来成为强分类器时,其分类正确概率就能够接近百分之百[14]。 考虑一个具有n个训练样本的训练集(X1,y1),…,(Xi,yi),…,(Xn,yn),其中Xi为提取样本特征值,yi表示样本标签,如果待分类样本具有M个分类,则表示第j个特征下的所有分类值,其中1≤j≤M。 假设对于j个特征,可以定义弱分类器hj(X)为: 式中,X为某一样本的特征值,Tj表示为弱分类器设计的分类阈值,而pj为弱分类器的调整方向,一般来说调整方向为正反2种方向,也即pj取值为±1。在样本特征被提取出来之后,需要构建最佳的弱分类器,在某些情况下,根据样本的先验信息设计相应的分类器阈值可以使得分类器出现较好的结果,但是由于整个样本的特征训练在某种程度上体现的非线性特征,其表现出一定的非均匀鲁棒性,同时人为干预下的分类器设计使得自主学习退化为有监督学习,在学习效率与使用扩展性方面存在性能损失[15-16],为了解决以上问题,设计弱分类器的自学习调整。 1) 初始化弱分类器参数 假设存在T个弱分类器,则首先设置迭代次数t,t=1,2,…,T。如果有n个正负样本,则初始权重定义为: 2) 计算弱分类器错误率 假设第j个特征为Xj,取出特征Xj下所有样本的样本值,按照从小到大的顺序计算相邻2个样本值的中间值点,将中值点作为弱分类器的阈值,根据式(18)遍历±1的调整方向情况下的所有弱分类器,计算每个弱分类器的错误率ε,用公式表示为: 式中,I(yi≠hj(Xi))相等时为0,不相等时为1。 3) 更新样本权重 根据式(20)计算训练样本集中的所有特征,找出具有最小的错误概率ε的弱分类器,在训练过程中,通过错误概率ε调整样本的权重值,使得所有弱分类器在某种程度上达到最优效果。更新样本权重过程如下所示: 在训练过程中,对正确进行分类的样本值赋予较小的权重,而对错误分类样本赋予较大的权重,通过大量数据样本集的训练将突出具有错误分类的弱分类器的训练,最终获得性能最佳的弱分类器。 在构建了性能最佳的弱分类器的基础上,对得到的T个弱分类器进行线性组合以获得强分类器,用公式表示为: 式中,αt为最佳弱分类器的合成权重,αt是一个与分类器错误概率相关的参数: 最终的强分类器为: 因为本文共从图像中组合提取了31维特征向量,所以本文中T=31。最终强分类器由特征向量中每一维训练得来的共31个弱分类器组成。 总结以上算法流程,如图4所示。 图4 AdaBoost算法流程 为了验证本文所提出的方法,通过仿真计算对类型为Link4A、Link11和Link16的数据集进行识别验证,具体如表1所示,随机选取4/5的样本作为训练集,另外1/5样本作为测试集。 表1 数据集 同时为了使仿真贴近真实情况,对数据集合添加不同信噪比的高斯白噪声,分别选取SNR为-20 dB、-10 dB、0 dB、5 dB和10 dB。在不同信噪比条件下,采用不同特征分析方法对数据链信号进行分析,产生WVD时频图、STFT时频图和循环谱图,并提取伪Zernike矩特征、GLCM特征和LBP算子特征,将特征向量合并分别输入SVM和KNN分类器识别,产生每种类型信号不同信噪比下的识别概率。 对于Link4A信号而言,在信噪比为10 dB时,无论计算WVD/STFT时频图,还是计算循环谱图,均能够达到90%的识别概率;而Link11信号的识别概率稍低,原因是相较于Link4A信号来说,Link11信号采用了二次调制方式,时频图无法进一步深入反映信号在调制域上深层次的特征。该方法对Link16信号的识别效果最差,这是由于Link16信号采用扩跳结合的调制方式,跳速高且每一跳采用MSK调制方式,无论是对这种短时多跳且每跳宽带扩频的信号进行时频分析还是循环谱分析,都难以避免多跳信号之间的交叉干扰,随着每跳调制信息不一致导致的各跳信号之间特征的相互非线性叠加,信号特征进一步模糊化。当信噪比下降到0 dB以下时,无论Link4A、Link11还是Link16信号,其识别概率都将较大地下降,说明此时噪声对信号特征的模糊与退化是识别错误的主要因素,也即信号波形本身的信息量遭到损失,无论采取哪种方法都无法提高识别概率。 经对比发现使用STFT图像特征作为输入的模型识别概率整体效果较好,因此选其作为输入,采用AdaBoost算法通过集成多个弱分类器组成强分类器,实现对三种信号的分类识别。三种信号在各种信噪比条件下的识别概率相较于单独使用SVM或KNN均有明显提升,如表2—4所示,说明本文情境下,Ada⁃Boost算法中的以多个弱分类器联合工作效能高于单独的SVM和KNN分类器。 表2 Link4A信号在不同信噪比条件下的不同识别方法识别概率 表3 Link11信号在不同信噪比条件下的不同识别方法识别概率 表4 Link16信号在不同信噪比条件下的不同识别方法识别概率 本文研究了Link4A、Link11、Link16三种典型战术数据链信号特征,通过计算数据链信号的WVD/STFT时频谱和循环谱,构建了信号多维多域的特征谱图。信号多维谱图能够描述不同域物理参数的耦合特征,反映在图像上面就是不同信号的谱图图像的纹理、形状、轮廓、边沿都具有各自的特征,通过提取谱图图像中的伪Zernike矩、GLCM特征和LBP特征,构成描述不同数据链信号的特征向量,利用AdaBoost算法自适应优化多个弱分类器形成的最佳分类算法对数据链信号进行分类识别,相较于单个分类器的识别结果更优,且识别算法稳定可靠,具有较高的军事使用价值和工程应用价值。3 弱分类器设计的AdaBoost算法
3.1 构建最佳弱分类器
3.2 构建强分类器

4 仿真分析

5 结束语
