基于密度权重的优化差分隐私K-medoids 聚类算法
2023-05-24王圣节巫朝霞
王圣节,巫朝霞
(新疆财经大学 统计与数据科学学院,乌鲁木齐 830012)
0 引言
大数据技术和人工智能飞速发展,海量数据的收集、存储、发布和分析越来越容易[1]。聚类分析作为数据挖掘的主要任务之一,已在许多领域内得到了广泛的应用,如:社交领域、外卖平台、电商网购。然而这些领域内的数据大都包含用户的隐私信息,容易遭受不法分子的攻击进而造成隐私泄露。因此,在聚类分析过程中,如何有效保护用户数据隐私,是当下研究热点,具有现实意义。
针对隐私泄露问题,早期学者提出k-anonymity及其一系列扩展模型,通过对准标识符的泛化处理来实现数据的隐藏,但该类模型容易受到一致性攻击和背景知识攻击,需要针对新型攻击不断完善模型[2]。2006 年,微软研究院的Dwork[3]提出了差分隐私技术(Difference Privacy,DP),不关心攻击者拥有的背景知识。差分隐私建立在严格的数学证明基础之上,通过在原始的查询结果(数值或离散型数值)中添加干扰数据(即噪声),再返回给第三方;加入干扰后,可以在不影响统计分析的前提下,无法定位到具体数据,从而防止个人隐私数据泄露,进而提供了强大的隐私保护。
Avrim 等人[4]最早将差分隐私保护与聚类技术相结合,设计了一种差分隐私K-means(DPKmeans)算法,布置于SulQ 框架平台,通过发布添加合理噪声的相似值来更新查询值;李扬、郝志峰[5]等提出了满足ε-差分隐私保护的IDPK-means 算法,数据集平均划分成p个子集,计算子集加扰后的中心点作为初始中心点,以此提升最终聚类效果;吴伟民[6]等提出了一种基于差分隐私保护的DPDBScan 聚类算法,在添加少量噪声的情况下,保证了隐私安全与聚类效果;傅彦铭[7]等提出一种基于拉普拉斯机制的差分隐私保护k-means++聚类算法(DPk-means++聚类算法),确保算法在不同维度数据集的情况下的聚类可用性和准确性。针对传统聚类算法存在的隐私泄露的风险,郑孝遥、陈冬梅[8]等提出一种基于差分隐私保护的谱聚类算法,以实现社交网络聚类效果和隐私的平衡;高瑜[9]等则针对数据集中噪声点和离群点地对聚类的影响,将差分隐私与K-medoids 算法相结合,提出了一种满足ε-差分隐私保护的聚类算法(DPk-medoids),该算法使用拉普拉斯机制在每次发布真实的中心点之前向中心点添加噪声,然后发布具有隐私保护性质的中心点,在一定程度上保证了个人隐私的安全性和聚类的有效性。
1 预备知识
1.1 差分隐私(Difference Privacy,DP)
差分隐私(Difference Privacy,DP)具有严格的数学定义,是一种通过任何模型、算法添加合理噪声的数据失真隐私保护技术,对可能被恶意攻击造成隐私泄露的关键部分添加干扰噪声,例如模型、算法的输入输出、梯度参数、权重参数、目标函数等,以保证模型、算法的隐私。
定义1(差分隐私[3])假设存在任意一个随机算法M,对于相邻数据集D和D',Pr[ES]表示事件ES的隐私披露风险,Range(M)表示随机算法M的取值范围,Pm为输出结果的所有可能值的集合,Sm为Pm的任意子集,如果算法M 满足式(1):
则称算法M 满足ε-差分隐私。其中数据集D和D'为至多相差一条数据的相邻数据集。ε为隐私预算,ε越小,则算法M 在D和D'输出分布越接近;反之,输出分布相差越大。
定义2(全局敏感度[10])对于任何查询函数f:D→Rd,R表示映射的实空间,d表示函数f的查询维数,输入是一个数据集,输出是d维查询结果。对于任意相邻数据集,则查询函数的全局敏感度,式(2):
定义3(Laplace 机制[10])已知任意查询函数f:D→Rd,给定数据集D,敏感度为Δf,令A表示隐私聚类算法,若A(D)满足式(3):
1.2 差分隐私K-medoids 算法
原有的差分隐私K-medoids 算法在K-medoids聚类过程中对中心点添加少量合适的噪声,使中心点的披露风险满足差分隐私定义,以此为最终的聚类结果提供差分隐私保护。现有应用在用户数据基于差分隐私的K -medoids 聚类算法(DP K -medoids)的具体步骤如下:
Step 1随机选择p个点作为初始聚类中心点,并在每个中心点上加入拉普拉斯噪声;
Step 2计算数据集中每个点与中心点之间的距离,并将该点从其最近的中心点分配给簇,形成k个簇;
Step 3在每个集群中,依次选择一个点来计算用该点替换原始中心点所产生的消耗,并选择一个消耗少于原始中心点的点作为一个新的中心点,并对该点添加噪声;
Step 4重复步骤2 和步骤3,直到迭代次数达到阈值。
2 基于密度权重的差分隐私保护K-medoids算法
2.1 相关概念
假设存在数据集D ={x1,x2,…,xn},是包含n个样本对象的数据集合,每个样本对象存在d维属性特征;数据集被划分为k个簇类,C为簇集合:C ={c1,c2,…,ck}。
定义4数据集D ={x1,x2,…,xn} 中,任意两样本对象xi和xj之间的距离用欧氏距离d(xi,xj),表示简记为dij,公式(4):
其中:i =1,2,…,n;j =1,2,…,n;p =1,2,…,d;xip表示第i个数据对象的第p维属性。
定义5数据集D ={x1,x2,…,xn} 中,所有样本对象的平均距离,公式(5):
其中,n是数据集D中样本点的个数,dij表示数据集中样本点xi到样本点xj之间的欧氏距离。
定义6样本点xi的密度参数是以数据集中任意样本对象xi为中心,AverDis(D)ρ(i)为半径的区域样本对象的总数,公式(6):
当x <0 时,S(x)=1,x≥0 时,S(x)=0。
样本点密度图如图1 所示。

图1 样本点密度Fig.1 Sample point density
定义7设ui是以样本对象xi为中心,AverDis(D)为半径的区域内所有样本对象集,d(xi,xj)<AverDis(D),则式(7):
定义8类簇之间距离si代表样本点xi与另一局部密度较高的样本点xj之间的距离。如果样本点xi的局部密度是最大值,si则定义为max(dij);否则si被定义为min(dij),公式(8):
样本点类簇距离的计算原则如图2 所示。

图2 样本点类簇距离计算原则Fig.2 Calculation principle of cluster distance of sample points
定义9假设数据集D被划分为k个聚类,聚类Cj(j≤k)的中心点为cj,聚类结果的误差平方和是每个聚类的样本与其聚类中心之间的距离的平方和,即式(9):
定义10定义选取中心点的密度权重如式(10):
通过公式(10)可知,样本点xi的密度参数ρi越大,代表点xi周围的样本点越密集,则密度权重wi越大;ui越小表明以样本对象xi为中心,AverDis(D)为半径的区域内样本对象相似程度越高,则密度权重wi越小;类簇之间距离si越大,即代表两个类簇之间距离远,簇中样本点相似程度低,则密度权重wi越大。
2.2 算法思想
为减少DP K-medoids 算法在初始中心点选择的随机性,影响最终聚类结果,引入密度权重这一概念。选取权重最大的样本点作为聚类中心,以此来减少随机选取中心点带来的不确定性,提高聚类效果。算法步骤如下:
第一步,根据公式(6)计算数据集D中所有样本点的密度大小,取密度最高的样本点c1设置成第一个聚类中心,并将该聚类中心c1添加到中心集合C中,此时中心集合C ={c1};然后,将满足定义7中样本点到初始簇中心之间的距离小于AverDis(D)条件的所有样本点添加到当前聚类簇中,并将这些样本点从数据集D中移除;
第二步,根据公式(6)~公式(8)计算剩余样本点的密度ρ(i)、簇间平均距离ui和类簇距离si,根据公式(10)计算剩余样本点的密度权重,选择密度权重系数最大的样本点c2作为第二个聚类中心,将中心点c2添加到中心集合C中,此时中心集合中C={c1,c2};同 样,从 数据集中删除距离小于AverDis(D)的剩余样本点与该初始聚类中心之间的所有样本点;
第三步,重复第二步至数据集D被清空。此时聚类中心集合C ={c1,c2,…,ck},数据集被划分成k个类簇,将得到的聚类数和聚类中心作为输入,对数据集进行DP K-medoids 运算。
2.3 基于密度权重的优化DP K-medoids 算法流程
DP K-medoids 在传统K-medoids 算法的基础上添加了差分隐私保护技术,但也容易受初始中心点、聚类个数等因素影响其聚类效果。当输入数据或参数处理不当时,算法容易陷入局部最优解[11]。因此,本文通过对原有算法在初始中心点及聚类个数的选择上进行改进,选择密度权重较大的样本点作为初始中心点,再将结果产生的中心点与簇类数作为差分隐私的K-medoids 算法的输入参数,避免初始中心点和k值选择的随机性,进而产生具有隐私保护能力的良好聚类结果。
算法流程如下:
输入 初始样本数据集D ={x1,x2,…,xn}
输出 带有差分隐私保护的聚类结果
Step 1输入原始数据集D ={x1,x2,…,xn};
Step 2根据定义7 计算数据集中所有样本点的密度大小,选取密度最大的样本点c1作为第一个聚类中心,添加到中心集合中,C ={c1};
Step 3计算剩余样本点的密度ρ(i)、簇间距离Si、簇内样本点距离和ui;
Step 4确定第二个聚类中心的条件:根据定义11 计算得到剩余样本点的密度权重最大的样本点,将其添加到中心集合中,C ={c1,c2};
Step 5重复Step3~Step4,直至数据集清空,此时C ={c1,c2,…,ck};
Step 6将上述步骤得到的聚类中心和聚类数作为输入;
Step 7对中心集合C ={c1,c2,…,ck} 添加拉普拉斯噪声,式(11):
Step 9对于产生的每个初始簇,计算其簇中每个样本点与簇中其他样本点的距离和,选择距离和最小的样本点,更新为该簇的新中心点,并在新的中心点添加拉普拉斯噪声;
Step 10重复Step9~Step10,当中心点稳定不再发生改变或是达到预设的迭代次数,终止循环;
Step 11输出带有差分隐私保护的聚类。
2.4 安全性分析
在DWDPK-medoids 算法中,通过添加适量服从拉普拉斯分布的噪声对中心点进行隐私保护,使最终的聚类结果满足差分隐私定义。假设M(D)和M(D')代表经过DWDPK-medoids 算法的在数据集D和D'的输出结果,D1和D2是两个只相差一个记录的相邻数据集,S代表一种随机的聚类划分方法,φ(x)为添加噪声之后的聚类结果,则有式(12):
式(12)符合差分隐私的定义。因此,DWDPKmedoids 算法可以提供ε-差分隐私保护。
3 实验结果与分析
3.1 实验环境及数据
通过实验对DWDPK-medoids 算法的可用性进行分析。实验环境为Windows 10 操作系统,Intel(R)Core(TM)i5-6200U CPU @ 2.40 GHz,12 GB机带RAM,采用Python3.6 编程语言,通过Pycharm专业版编辑器进行仿真实验。数据来源于UCI Knowledge Discovery Archive database 官网的真实数据集,见表1。

表1 实验数据集信息Tabl.1 Experimental data set information
3.2 实验评价指标
本文采用戴维森堡丁指数(Davies-Bouldin Index,DBI)指数作为聚类评价有用性指标。通过计算簇与簇之间相似度,再通过计算所有相似度的平均值,衡量整个聚类结果的优劣。如果簇与簇之间的相似度越高(DBI指数高),说明簇与簇之间的距离越小,此时聚类效果就越差,反之越好。
Rij表示簇Ci与簇Cj的相似度,公式(13):
其中,Si代表簇Ci内所有样本点到中心点ci的平均距离,Sij表示第i个簇与第j个簇之间的距离(即两个簇中心之间的距离)。
其中,N是聚类簇数。
3.3 实验结果分析
考虑到不同数据集维度不同,数据大小指标不一样,对数据集做0-1 归一化处理。分别在3 个数据集上运行DPK-medoids 算法以及本文提出的DWDPK-medoids 算法。由于添加服从拉普拉斯分布噪声的随机性,对每个算法进行10 次实验,取其平均值。DB值越小,证明聚类有效性越高。仿真实验结果如图3~图5 所示,横坐标代表隐私预算ε,纵坐标代表聚类效果评价指标DB指数。

图3 Iris 数据集上的DB 指数图Fig.3 DB exponential graph on Iris dataset
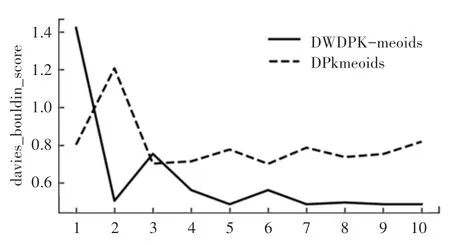
图4 Blood 数据集上的DB 指数图Fig.4 DB exponential graph on blood dataset

图5 Wifi 数据集上的DB 指数图Fig.5 DB exponential graph on wifi dataset
图3 和图4 为小样本数据集下的算法效果,可见在相同隐私预算情况下,DWDPK-medoids 算法的DB指数低于DPK-medoids 算法,聚类效果更加好;在隐私预算ε =2 的情况下,聚类效果开始趋于稳定,此时达到数据可用性和隐私保护平衡的状态。图4 和图5 是Blood 数据集和WiFi 数据集的对比图,数据集越大,DB指数越大,最终的聚类效果越低。图5 的DWDPK-medoids 算法在ε =1 时,整体聚类效果趋于稳定,而DPK-medoids 算法在隐私预算ε =2 时,DB指数开始下降,随着ε的增大,逐渐与DWDPK-medoids 算法DB指数相趋近,表明DWDPK-medoids 算法能够消耗较小的隐私预算达到数据可用性与隐私保护的平衡。
从实验结果可知,DWDPK-medoids 算法在一定程度上的聚类效果优于原有的DPK-medoids 算法。DB 指数越低,则最终聚类结果所分的簇与簇之间距离越大,代表聚类效果越好。
4 结束语
差分隐私与K-medoids 算法相结合在保证聚类效果的前提下,能够有效保护相关数据的安全性。针对DPK-medo-ids 算法在选取初始中心点和聚类个数的随机性和盲目性,本文提出一种基于密度权重的优化差分隐私K-medoids 算法(DWDPKmedoids 算法),通过引入密度权重的相关概念,确定初始聚类中心点以及聚类个数,提高聚类效果。仿真实验结果表明,DWDPK-medoids 算法在多样本和多维度的数据集上具有更高的聚类效果。在今后的研究中,应当针对算法复杂度进行优化,在保障数据隐私的前提下添加少量噪声获得更好的聚类效果。
