一种基于SWF-BERT的软件缺陷报告严重性预测方法
2023-05-23薛诗琦王阿川
薛诗琦,王阿川
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)
1 引 言
在软件开发的整个流程中,大多数软件系统都存在不可避免的缺陷,开发人员通过缺陷报告来记录软件的缺陷信息,并利用Bugzilla和Jira等比较主流的缺陷跟踪系统提取缺陷报告[1].然而,随着每天提交缺陷报告的数量增加,人工识别软件缺陷报告的严重性并手动进行标注是一项耗时耗力的工作[2].因此,如何用更准确且高效的方法来实现严重性预测是当前软件仓库挖掘领域内的一个研究热点,贯穿整个缺陷报告的生命周期.
软件缺陷修复离不开优先级的划分,一般优先级主要分为必须在第一时间修复,在下一次产品发布前修复,延迟修复和不需要修复等4类[3].人们通常认为优先级与严重性等级成正比,优先级越高代表缺陷越严重,应当被立即修复,但是严重性等级与优先级在对应关系上并不总是完全吻合[4].优先级的排序仅仅体现在当前数据集中,具有一定的主观性,并不能说明在其他数据集中存在同样的问题,需要结合缺陷的严重性进行整体的分析.
为了改善软件缺陷报告严重性模型中分类精度较低、特征提取能力不足的问题,本文提出了一种基于BERT句子级别与词级别特征融合的SWF-BERT软件缺陷报告严重性预测模型,主要工作如下:
1)提取缺陷报告中词频最高的前100个单词,筛选出与缺陷严重性相关的特征词并对其进行关键词嵌入操作,将词向量、句子向量、位置向量和关键词向量按位置相加,得到带有软件缺陷严重性特征的词向量.通过引入该领域相关的特征词,使模型在训练过程中将注意力更多地集中在关键信息上,有效提升了标签分类的性能.
2)将BERT模型经过输出层后得到的词嵌入(除[CLS]token外)送入多尺度卷积神经网络结合长短期记忆网络的MC-LSTM模型(Multi-scale CNN combined with LSTM,简称MC-LSTM)中,以加强文本的深层语义和上下文的特征关系.
3)采用BERT模型输出得到的[CLS]句向量经过线性变换的结果与MC-LSTM模型输出经过线性变换得到的结果做可学习的自适应加权融合,进一步增强不同级别融合后的特征抓取能力,提升了模型的预测精度.
2 相关工作
2.1 软件缺陷报告严重性分类
当前,针对软件缺陷报告严重性分类问题,通常采用的文本表征方式可以按照静态表征和动态表征划分[5].早期很多方法基于静态表示,如Tan等人[6]使用One-hot独热编码来预测缺陷严重性,解决了分类器处理离散数据困难的问题,但该方法不考虑词之间的顺序以及容易造成维度灾难.随后,Hamdy等人[7]提出使用词频(TF)和信息增益(IG)的方法进行特征选择,通过统计特征在缺陷报告中出现的次数以及计算在某一类别上的IG值来衡量特征的重要性,一定程度上改善了维度灾难问题,但它没有考虑报告内部特征间的关系.后来,学者们逐渐从原始稀疏的词向量表示过渡到低维空间的密集表示中,这种方式既能表示词本身又考虑了语义间的相似性.Guo等人[8]使用Word2Vec词向量来预测缺陷的严重性,由于加入了对上下文的理解,与之前的词嵌入方法相比,该方法的维度更少、效果更好.Nnamoko等人[9]对Word2Vec模型进行了优化,在缺陷严重性预测中采用Fasttext模型,该模型有着和Word2Vec相同的训练目标,它把一个词表示为多个字符的组合,可以推测出未见过词的意思,缓解了OOV问题.但上述方法是静态表征的方式,词和向量是一对一的关系,多义词的问题仍无法解决且无法针对特定任务做动态优化.
在动态表征中,Kamal等人[10]提出使用GPT-2模型来预测软件缺陷严重性,该模型基于Transformer解码器结构.相比于传统的词向量方法,GPT-2能够利用上文信息进行预测,一定程度上提升了模型预测的精度.Ardimento等人[11]提出采用BERT模型对缺陷严重性进行预测,该模型能够利用上下文的语义关系对被[MASK]掉的token进行预测以及学习句子级的语义特征,在该领域中取得了不错的效果,但语义特征不够丰富.Isotani等人[12]提出一种Sentence-BERT的方法,在BERT模型中通过添加语义相似度从而预测缺陷严重性,更好的捕捉句子之间的关系,有效改善了BERT在语义相似度搜索任务中的不足.本文对BERT模型中句子级别和词级别特征采用自适应加权融合的方法,充分考虑到不同语义层次下的特征信息,增强了模型融合后的特征抓取能力.
2.2 BERT预训练模型
2.2.1 BERT模型
BERT是一个预训练语言模型,它由Transformer的编码器结构组成.而Transformer采用了基于双向上下文依赖的注意力机制,这种机制使句子中每个token在建模时都依赖于序列中其他所有token的语义信息,可以学到文本中token之间的双向上下文关系[13].其中,点乘缩放注意力机制(Scaled Dot-Product Attention)的计算过程见公式(1):
(1)
式中,Q、K、V是经过线性变换后的查询、键、值矩阵.dk代表向量的维度,dk的值是768.
模型在对当前位置的信息进行编码时,会过度将注意力集中于自身的位置,因此提出多头注意力机制(Multi-Head Attention)来解决这一问题.Q、K、V先进行线性变换,再进行点乘缩放操作,得到单个头的输出值,见公式(2):
(2)
将12个注意力的输出结果拼在一起变成768维的向量矩阵,通过线性变换得到多头注意力机制,见公式(3):
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(3)

2.2.2 BERT预训练和微调
BERT是以掩码语言模型(Mask Language Model,MLM)和判断句子对是否连续(Next Sentence Prediction,NSP)为目标的大规模预训练语言模型[14].它由预训练和微调两个阶段组成.
1)预训练
在输入层中,用[MASK]随机屏蔽一部分输入token,对应token位置的嵌入向量经过全连接层映射到词汇表中,经过SoftMax函数预测被[MASK]掉的token在词汇表对应位置的概率值.
2)微调
对于每个任务,只需将自己数据集中的数据转换为BERT模型能够读取的输入和输出形式,并对所有端到端的参数进行微调.在BERT模型最后一层输出得到的[CLS]句向量后经过线性变换就可以用于分类预测.
3 研究方法
本文提出一种基于BERT句子级别与词级别特征融合的SWF-BERT软件缺陷报告严重性预测模型,整体模型结构如图1所示.
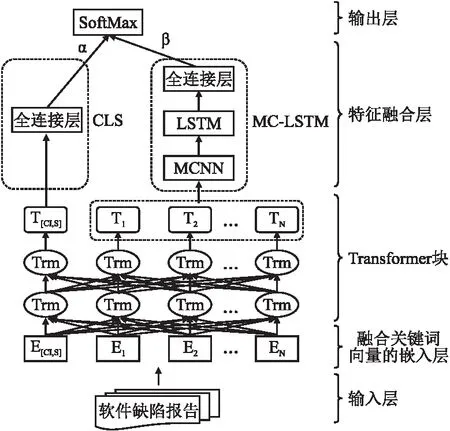
图1 SWF-BERT模型结构图
该模型主要由输入层、融合关键词向量的嵌入层、Transformer块、特征融合层和输出层构成.首先,将缺陷报告中的摘要“summary”和描述“description”合并为一句话,每个文本在句首和句尾分别添加[CLS]和[SEP]token并将字符转为数字序列的形式.然后,在嵌入层中将融合后的特征向量送入Transformer块进行预训练,经过最后输出层得到融合所有单词语义信息的[CLS]句向量和带有上下文及序列信息的词向量.最后,使用BERT预训练模型对软件缺陷严重性任务数据进行微调.在下游任务中对句子向量接入全连接层进行分类,对词级别向量添加MC-LSTM模型并接入全连接层进行分类,两个级别的特征向量做加权融合,经过SoftMax函数用于软件缺陷严重性预测.
3.1 输入层
首先分别将缺陷报告中的文本,例如“undo or revert removes error ticks in editor”,在模型训练之前处理成:“[CLS] undo or revert removes error ticks in editor[SEP]”.其中,“[CLS]”表示起始分隔符,“[SEP]”表示结束分隔符.其次在BERT模型中,通过调用wordpiece方法将所有单词进一步切分成词片,使单词语义更加清晰.例如:将playing分割为play和##ing.最后对文本长度做截断处理,在[SEP]后添加[PAD]填充符.
3.2 融合关键词向量的嵌入层
软件缺陷报告中,关键词的出现很大程度决定了分类标签的属性.为了提高关键词在训练过程中分配更多的权重,本文通过计算报告中单词的词频,分别提取出数据集中词频最高的前100个单词,在这些单词中进一步人工筛选出与缺陷严重性相关的特征.例如Mozilla数据集中,词频最高的前20个单词分别为:mozilla、x、error、window、build、a、debug、crash、make、code、delete、remove、run、search、problem、app、method、failure、object、update.其中mozilla为数据集的名字,x、a这种单个字母无实际含义,window、build、make等词并不具备区分严重性标签的属性,只起到解释说明的作用,本文对这些单词进行删除.
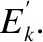
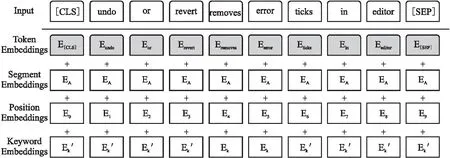
图2 嵌入层结构图
在Mozilla数据集中,与缺陷严重性相关且词频前10名的特征为error、debug、crash、delete、remove、problem、failure、a-
larm、broken、disconnect,其频数分别为4385、2702、2284、1685、1596、1497、1442、1277、859和832;在Eclipse数据集中,与缺陷严重性相关且词频前10名的特征为error、problem、unknown、debug、default、unable、wrong、disable、broken、incorrect,其频数分别为4776、3528、3206、2956、2814、2309、1880、1734、1317和928.
3.3 Transformer块
Transformer块由多头注意力机制和全连接前馈神经网络构成,在每部分使用残差连接和层归一化,将这部分操作整体重复12次堆叠起来,得到每个token的输出向量.为了使词向量更好的适配软件缺陷报告的文本语料,本文用[MASK]随机屏蔽一部分输入token,然后预测那些被屏蔽掉的token进行预训练.
3.4 特征融合层
3.4.1 BERT的缺陷严重性分类
在BERT训练过程中,通常会在第1句前加一个[CLS]token.[CLS]句向量通过自注意力机制来获取句子级别的信息表征(采用加权平均值计算),相比于对所有的token做平均池化操作,它会和其它时间下的每个token做相似度计算用于建立依赖关系,使整个句子的语义更加完整[15].将软件缺陷严重性任务的数据放入预训练模型中,参数随着新的任务不断调整.将最后输出得到的[CLS]句向量接入全连接层,得到的输出结果记为L1,完成句子级别的严重性预测任务.
3.4.2 MC-LSTM的缺陷严重性分类
1)多尺度CNN模型
本文以词级别token的向量为基础,通过在CNN的卷积层上添加不同规模的卷积核,使卷积层的特征尺寸得到扩展,减少卷积层层数的同时可以有效地获取并聚焦重要的多尺度特征,以获得其对应的文本深层语义特征[16],多尺度CNN模型结构如图3所示.
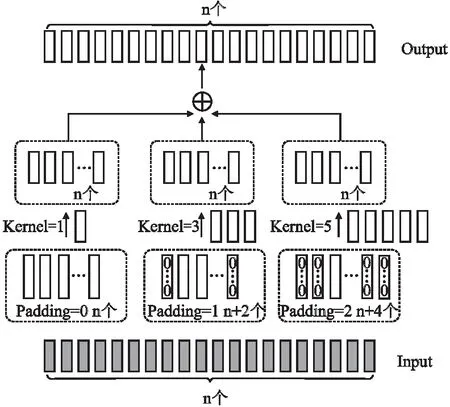
图3 多尺度CNN模型结构图
在卷积层中,对词级别的输出向量采用不同大小的卷积核进行卷积运算,计算见公式(4):
(4)
式中,f表示ReLU激活函数,ωd表示大小为d的卷积核,Vi表示嵌入层中融合后的词向量,bd表示偏置项.对卷积核1、3、5得到的向量按位相加,最终特征向量集合Hd见公式(5):
(5)

最后,将向量Hd送入LSTM模型进行训练.
2)LSTM模型
在多尺度CNN模型后接入长短期记忆循环神经网络LSTM[17],该模型在抓取各特征之间相互关系的同时,能够有效克服梯度消失或梯度爆炸的问题.
设遗忘门的输出为ft,其计算见公式(6):
ft=σ(ωf·[ht-1,xt]+bf)
(6)
记忆门确定从输入中得到的哪些信息被记忆,其计算见公式(7)、公式(8):
it=σ(ωi·[ht-1,xt]+bi)
(7)
(8)
信息的更新过程见公式(9):
(9)
网络单元的输出值见公式(10)、公式(11):
ot=σ(ω0·[ht-1,xt]+b0)
(10)
ht=ot×tanh(Ct)
(11)
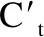
3)MC-LSTM网络模型结构
本文将多尺度CNN与LSTM结合构建MC-LSTM缺陷严重性分类预测模型,先分别利用CNN模型的卷积层(ConvolutionalLayer)对输入数据进行特征提取,再将卷积后不同尺度的特征向量按位相加(Multi-scale Feature Vectors),以扩充词的语义信息.将扩充后的特征向量送入LSTM模型(LSTM Layer)中进一步训练,最后通过全连接层获得的输出结果(Output Layer)记为L2,模型结构如图4所示.

图4 MC-LSTM模型结构图
3.4.3 BERT句子级别与词级别的特征融合方法
本文为句子级别和词级别的特征做可学习的自适应加权融合,进一步增强不同级别融合后的特征抓取能力,见公式(12):
L=α×L1+β×L2
(12)
其中α和β分别为句子级别和词级别所对应的自适应权重,通过在模型中学习从而确定最优值.
3.5 输出层
将融合后的特征向量L使用SoftMax函数计算软件缺陷报告严重性预测值见公式(13):
(13)
式中,Z表示严重性的类别数,Li表示每个单词的向量,使用交叉熵损失函数对模型进行优训练,计算见公式(14):
(14)
式中,y*表示真实标签的分布,yi表示训练样本的预测值.
4 实验与分析
4.1 实验环境及数据集概述
4.1.1 实验环境
本文实验环境:系统为CentOS 8.5,CPU为Intel Core i9-10900X,GPU为GeForce RTX 3080 Ti 12GB,内存大小为32GB,编程语言为Python3.7.3,深度学习框架为Pytorch 1.5.1.
4.1.2 实验数据集
本文采用Zhang等人[18]提供的Mozilla和Eclipse数据集.首先,对数据集中的缺陷报告进行属性增强处理,删除重复以及标签为“Normal”和“Enhancement”的文本数据,并对严重性等级进行标签化.然后,针对部分数据词干提取后会引起OOV问题,采用词频统计的方法,提取报告中出现次数多且具有缺陷严重性相关的单词对它们进行后缀还原处理(如“remov”还原成“remove”,“delet”还原成“delete”等).最后,将缺陷报告中摘要“summary”和描述“description”的文本数据合并为“Text”.
其中,经处理后的Mozilla数据集一共有2623条数据,Blocker、Critical、Major、Minor和Trivial的数量分别是283、508、696、692、444,Eclipse数据集一共有7355条数据,Blocker、Critical、Major、Minor和Trivial的数量分别是728、1435、2977、1383、832,部分数据如表1所示.数据按照8:2的比例划分为训练集和测试集,所有结果采用10次五折交叉验证的平均值.

表1 软件缺陷报告文本示例表
4.1.3 评价指标
本文采用平均准确率(Precision)、平均召回率(Recall)和平均F1值(F1-score)作为评价指标,计算见公式(15)~公式(17):
(15)
(16)
(17)
其中TP表示将属于正类样本正确地划分到正类的样本数目,FN表示将属于正类的样本错误地划分为负类的样本数目,FP表示将属于负类的样本划分为正类的样本数目,TN表示将属于负类的样本划分为负类的样本数目.
4.1.4 模型参数设置
本文中BERT模型选用uncased-BERT-base,为了保证实验结果的准确性和有效性,所设定的参数如表2所示.

表2 实验参数表
4.2 实验结果与分析
4.2.1 关键词嵌入对模型性能的影响
为了验证关键词嵌入操作的有效性,分别对Mozilla和Eclipse数据集添加关键词嵌入操作(Keyword embeddings,简称Key_emb)和未添加关键词操作(Non-keyword embeddings,简称Non-key_emb)进行实验,结果如表3所示.
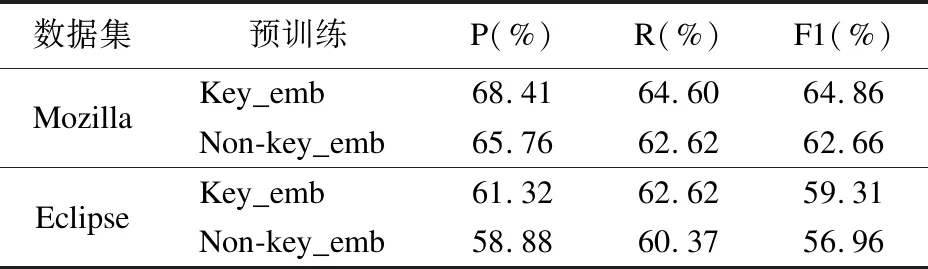
表3 关键词嵌入的对比结果
由表3可知,本文添加关键词嵌入操作后在两个数据集中分类结果均有明显的提高.该方法在Mozilla数据集上的平均准确率、平均召回率、平均F1值分别为68.41%、64.60%、64.86%,比传统BERT预训练模型,分别提升了2.65%、1.98%、2.2%.在Eclipse数据集上的平均准确率、平均召回率、平均F1值分别为61.32%、62.62%、59.31%,比传统BERT预训练模型,分别提升了2.44%、2.25%、2.35%.由此可知,通过在嵌入层中融合关键词特征的语义信息,增加了软件缺陷严重性特征的先验知识,预训练模型可以更好地进行学习,从而提升了分类效果.
4.2.2 不同分类算法的对比
为了验证SWF-BERT的有效性,本文将SWF-BERT模型与5种不同的分类算法进行对比分析.
CNN[19]:选择CNN模型,采用Word2Vec词嵌入模型完成对输入序列的向量化表示,并输出至CNN模型进行训练,实现软件缺陷严重性分类.
CNN-LSTM[19]:选择CNN模型,采用Word2Vec词嵌入模型完成对输入序列的向量化表示,并结合LSTM模型进行训练完成分类.
BERT:选择BERT预训练模型,完成对输入序列的向量化表示,并直接输出至SoftMax层进行分类.
BERT-CNN:BERT和CNN的组合,对缺陷严重性的特征进行提取,最后通过全连接层的输出结果对严重性标签进行分类.
BERT-LSTM:BERT和LSTM的组合,增强缺陷严重性特征间的远距离时序信息,最后通过全连接层的输出结果对严重性进行分类.
实验结果如表4所示,可以看出本文提出的基于句子级与词级别的软件缺陷报告严重性预测方法在两个数据集中平均F1值分别达到了64.86%和59.31%,相较于其他5种分类模型在平均准确率、平均召回率和平均F1值上均有所提升.其中,采用CNN和CNN-LSTM的方法在Mozilla和Eclipse数据集上的平均F1值分别为48%、40%和45%、44%.由于这两种模型在词向量化方面采用的是Word2Vec方法,分词不够准确且不能解决多义词的问题,导致词向量在训练过程中效果不理想,分类结果较差.将预训练语言模型替换为BERT时,平均F1值较CNN和CNN-LSTM模型在两个数据集上分别提升了13.38%、21.38%和11%、12%.原因是BERT在动态表征向量的同时可以根据现有任务对模型进行微调,提升单词在上下文中的语义特征,分类效果较好.当在BERT模型后接入CNN和LSTM模型时,增加了特征的利用率,相较于BERT模型,其平均F1值在两个数据集中分别提升了0.42%、0.14%和0.48%、0.3%.SWF-BERT模型在BERT模型的基础上进一步获取了缺陷严重性相关的特征,将关键词嵌入向量与嵌入层中的其他向量进行融合,使语义信息更加丰富,并对句子级别与词级别的特征做可学习的自适应加权融合操作,从而使模型获得更多的语义信息.在Mozilla数据集上,其平均准确率较其他5种分类算法分别提升了17.41%、27.41%、3.04%、2.72%、2.83%;平均召回率较其他5种分类算法分别提升了16.6%、24.6%、3.39%、3.01%、3.11%;平均F1值较其他5种分类算法分别提升了16.86%、24.86%、3.48%、3.06%、3.34%.在Eclipse数据集上,其平均准确率较其他5种分类算法分别提升了14.32%、16.32%、3.57%、2.97%、3.31%;平均召回率较其他5种分类算法分别提升了14.62%、15.62%、2.83%、2.25%、2.41%;平均F1值较其他5种分类算法分别提升了14.31%、15.31%、3.31%、2.83%、3.01%.

表4 不同分类算法的对比结果
4.2.3 消融实验
为了验证模型各层网络结构对实验结果的影响,在Mozilla和Eclipse数据集中分别对模型各层网络结构进行了消融实验,结果如表5所示.

表5 消融实验的对比结果
对BERT、BERTK、BERTK+C-LSTM、BERTK+MC-LSTM模型和本文方法进行对比,其中BERT表示仅在[CLS]输出向量后接入全连接层进行训练,BERTK表示在BERT的基础上增加关键词嵌入,BERTK+C-LSTM表示在BERTK的基础上,词级别向量后接入单尺度CNN结合LSTM模型并使用全连接层进行训练,BERTK+MC-LSTM表示在BERTK的基础上,词级别向量后接入多尺度CNN结合LSTM模型并使用全连接层进行训练.
实验结果表明,添加关键词嵌入的BERTK模型对比预训练BERT模型,在Mozilla和Eclipse数据集上F1值分别提升了1.39%和0.71%.BERTK+C-LSTM和BERTK+MC-LSTM模型对于BERTK模型,进一步扩充词级别的语义信息和考虑上下文特征间关系,在两个数据集中性能均有不同幅度的提升.当使用SWF-BERT模型方法效果最佳,在两个数据集中平均准确率、平均召回率、平均F1值分别达到了68.41%、64.60%、64.86%和61.32%、62.62%、59.31%,有效证明了融合句子级别与词级别特征方法的可行性,能够将语义信息最大化,很好地提升了模型分类的性能.
4.2.4 实验性能分析
1)损失值和正确率
实验中,Epoch数为15,每个Epoch下(从1~15)对应了测试集的损失值和正确率(Accuracy).在Mozilla数据集中,测试集的损失值为1.4667、1.1836、0.9898、0.9465、0.5671、0.2367、0.1386、0.0723、0.0169、0.0084、0.0078、0.0041、0.0041、0.0041和0.0041,测试集的正确率为43.21%、45.21%、46.21%、46.42%、47.42%、48.42%、49.53%、53.87%、57.77%、61.62%、63.64%、64.64%、64.84%、65.65%和65.65%;在Eclipse数据集中,测试集的损失值为0.8299、0.6793、0.4815、0.3918、0.0532、0.0399、0.0190、0.0068、0.0035、0.0034、0.0033、0.0032、0.0032、0.0032和0.0032,测试集的正确率为35.3%、37.53%、39.84%、41.19%、45.82%、48.86%、49.53%、53.87%、54.87%、55.87%、56.45%、56.5%、56.51%、56.51%和56.51%.
观察数值变化可知,Mozilla数据集的损失值在迅速变小,正确率在缓慢上升,当Epoch为12时,损失值和正确率的值趋于稳定,模型逐渐收敛,最终正确率达到65.65%;Eclipse数据集的损失值在迅速变小,正确率在逐渐上升,当Epoch为11时,损失值和正确率的值趋于稳定,模型逐渐收敛,最终正确率达到56.51%.
2)混淆矩阵
图5和图6分别为Mozilla和Eclipse数据集的混淆矩阵,从图中可以看出标签1、2、3预测为该类别数量的个数比标签4、5的好.其原因可能是标签1、2、3存在缺陷严重性相关的特征数较多,在关键词嵌入时对高频缺陷严重性的单词进行表征并训练,使得语义信息更加丰富,所以分类效果更好.另外数据中存在类别不平衡的问题,在实验中采用交叉熵损失函数,可以缓解此问题.
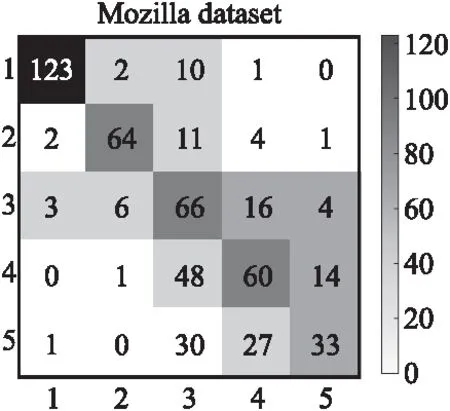
图5 Mozilla数据集的混淆矩阵图
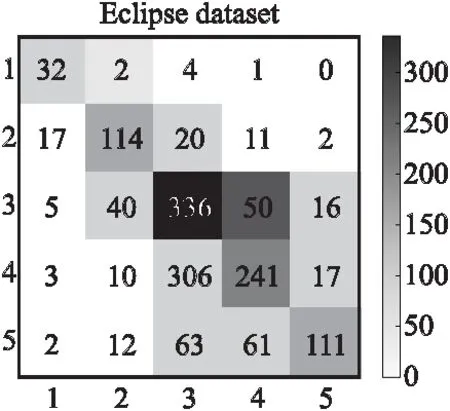
图6 Eclipse数据集的混淆矩阵图
5 结束语
本文提出了一种基于SWF-BERT的软件缺陷报告严重性预测模型.实验结果表明:1)通过在嵌入层中对关键词向量进行融合,使预训练过程中软件缺陷严重性的语义信息更加丰富;2)在BERT词级别的输出向量后接入MC-LSTM模型能够增强特征的深层语义和上下文的学习能力;3)采用BERT模型最后一层输出得到的[CLS]句向量经过线性变换的结果与MC-LSTM模型输出经过线性变换得到的结果做可学习的自适应加权融合,进一步增强了不同级别融合后的语义特征,通过与5种不同的分类算法相比,分类精度得到了提升.
目前,软件缺陷报告严重性分类方法准确率偏低,很大程度受到数据集的影响,未来工作应更加关注数据处理和数据不平衡的问题,从而进一步提升模型的分类性能.
