基于PCA-AWOA-ELM 模型的矿井突水水源识别
2023-05-23于小鸽刘燚菲翟培合
于小鸽 ,刘燚菲 ,翟培合
(1.江西应用技术职业学院,江西 赣州 341000;2.山东科技大学 资源学院, 山东 泰安 271019;3.山东科技大学 地球科学与工程学院, 山东 青岛 266590)
0 引 言
中国是以煤炭能源为主的国家,煤炭在相当长的时期内仍将是我国的主要能源,在历经近一个世纪的开采后,浅部的煤炭资源已开采殆尽,华北型煤田最为突出,大部分矿井已开采至石炭系下部煤层,煤矿受岩溶水威胁尤为严重[1]。据统计,2010-2019年,全国共发生煤矿水害事故182 起,死亡839 人,约是世界上主要采煤国家死亡总人数的4 倍,直接经济损失数十亿元,仅次于瓦斯事故造成的损失[2]。由此可见,煤矿水害是煤矿安全生产中长期存在的、需要不断解决的实际问题。快速、准确识别矿井突水水源成为当前煤矿安全研究的重要课题。
目前,众多学者通过构建高效精准的水源判别模型来指导矿井安全生产。马雷等[3]构建基于GIS的利用水温识别突水水源的模型,该法较好地适用于含水层之间存在较大的地温差(埋深差)情况下的突水水源识别。陈建平[4]基于含水层环境同位素差异研究了隆德矿区煤层识别矿井涌水来源,较好地识别了矿井水源,并估算了混合比例。王心义等[5]建立了距离判别分析模型,针对河南焦作矿区和新安矿区进行突水水源识别,该模型简单有效,具有较强的判别能力,可解决水文地质条件相似矿区的突水水源的判定。陈红江[6]建立多组逐步Bayes 判别模型,张春雷[7]建立Bayes 多类线性判别模型对矿井水源进行识别,计算过程简单、模型结构稳定,克服了距离判别法的缺点,但结构受到样本的限制,且结果易出现分类模糊现象。Fisher 水源判别模型[8-10]建立在有限的工程实例原始数据资料基础上,模型的判别精度受原始资料数据代表性、准确性的影响。神经网络技术[11-13]、支持向量机(SVM)[14-15]、可拓识别方法[16-17]等方法均已在矿井突水水源判别中得到了广泛应用。
笔者以岱庄煤矿为例,为克服ELM 模型泛化能力不足,稳定性较差和过度拟合的问题,构建了主成分分析(Principal Component Analysis,PAC)、自适应鲸鱼优化算法(Ameliorative Whale Optimization Algorithm,AWOA)和极限学习机(Extreme Learning Machine,ELM))相耦合的矿井突水水源识别模型,并与PCA-WOA-ELM 模型、WOA-ELM 模型、ELM模型的判别结果进行对比,结果表明,PCA-AWOAELM 模型识别精度、运行速度、稳定性均明显高于其他三者,为矿井安全生产提供了重要保障。
1 理论与算法
1.1 改进的鲸鱼优化算法
WOA 算法的收敛精度较低且收敛速度较慢,为了克服上述缺陷,引入AWOA 算法对ELM 模型进行优化[18]。
在鲸鱼探索阶段(图1),加入精英个体引导机制。

图1 座头鲸觅食行为示意Fig.1 Schematic diagram of foraging behavior of humpback whales
式中:Xp(t)为第t次迭代时,种群的适应度最优时的个体位置;当前种群最优个体的适应度的值大于上一代种群最优个体适应度的值时,dir为种群搜索因子,·为向量点乘,D=|CXrand(t)-X(t)|,表示个体距离随机个体Xrand的长度;t表示当前迭代次数;A和C表示系数;Xrand表示种群中随机个体的位置向量;X(t)表示鲸鱼个体(解)的位置向量;dir即为单位向量,反之,dir向量每一维的值由下式可得:
式中:Xmax、Xmin为 搜索空间的下界以及上界;r为随机向量。
在鲸鱼气泡网攻击阶段,引入动态混沌权重因子及收敛因子λ,具体步骤如下:
利用ω 及 λ 进行鲸鱼位置优化的公式如下:
式中:ω (t)为区间[0,1]的随机数。
1.2 极限学习机(ELM)理论
极限学习机训练模型如图2 所示,ELM 算法学习步骤[19-20]如下:
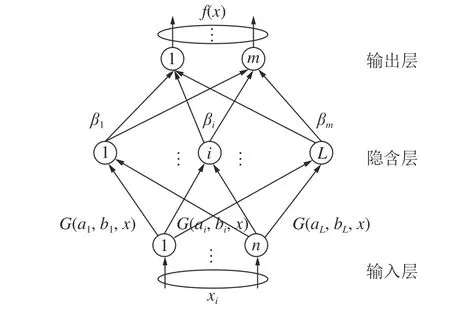
图2 ELM 训练模型Fig.2 ELM training model
1)设定隐含层神经元个数。
2)选择无限可微的隐含层神经元的激活函数,通过激活函数可以将样本映射到另一个特征空间,通过映射得到矩阵H,H表达式如下:
式中,H为隐含层输出矩阵;T为网络的输出矩阵;β为隐含层节点与输出层节点的连接权值矩阵。
3)在新的特征空间下,利用最小二乘法计算输出层最优输出权重 β*:
式中,H+为H的Moore-Penrose 广义逆矩阵。
2 实践应用
2.1 研究区概况
岱庄煤矿位于济宁市区正北约4.0 km 处,北起17 煤层露头,南到济宁市城市规划边界线,西起济宁断层与唐口煤矿相毗邻,东北部与何岗井田接壤,东南部以八里铺断层、许厂煤矿相邻。矿井自上而下主要含水层有第四系砂砾层孔隙含水层、山西组3煤层顶、底板砂岩裂隙含水层、三灰岩溶裂隙含水层、十下灰岩溶裂隙含水层、十三灰岩溶裂隙含水层、奥陶系石灰岩岩溶裂隙含水层,近年矿井涌水量如(图3)所示。

图3 近年矿井涌水量曲线Fig.3 Curve of mine water inflow in recent years
2.2 水质特征
基于48 组实测数据,采用AqQA 对井田内主要充水含水层(三灰含水层(Ⅰ)、十下灰含水层(Ⅱ)、十三灰含水层(Ⅲ),奥灰含水层(Ⅳ))进行水质分析(图4)。从图4 中可以看出,三灰、十下灰、十三灰、奥灰的水质类型相近,按舒卡列夫分类,属SO-4Ca·Mg·Na 型水。
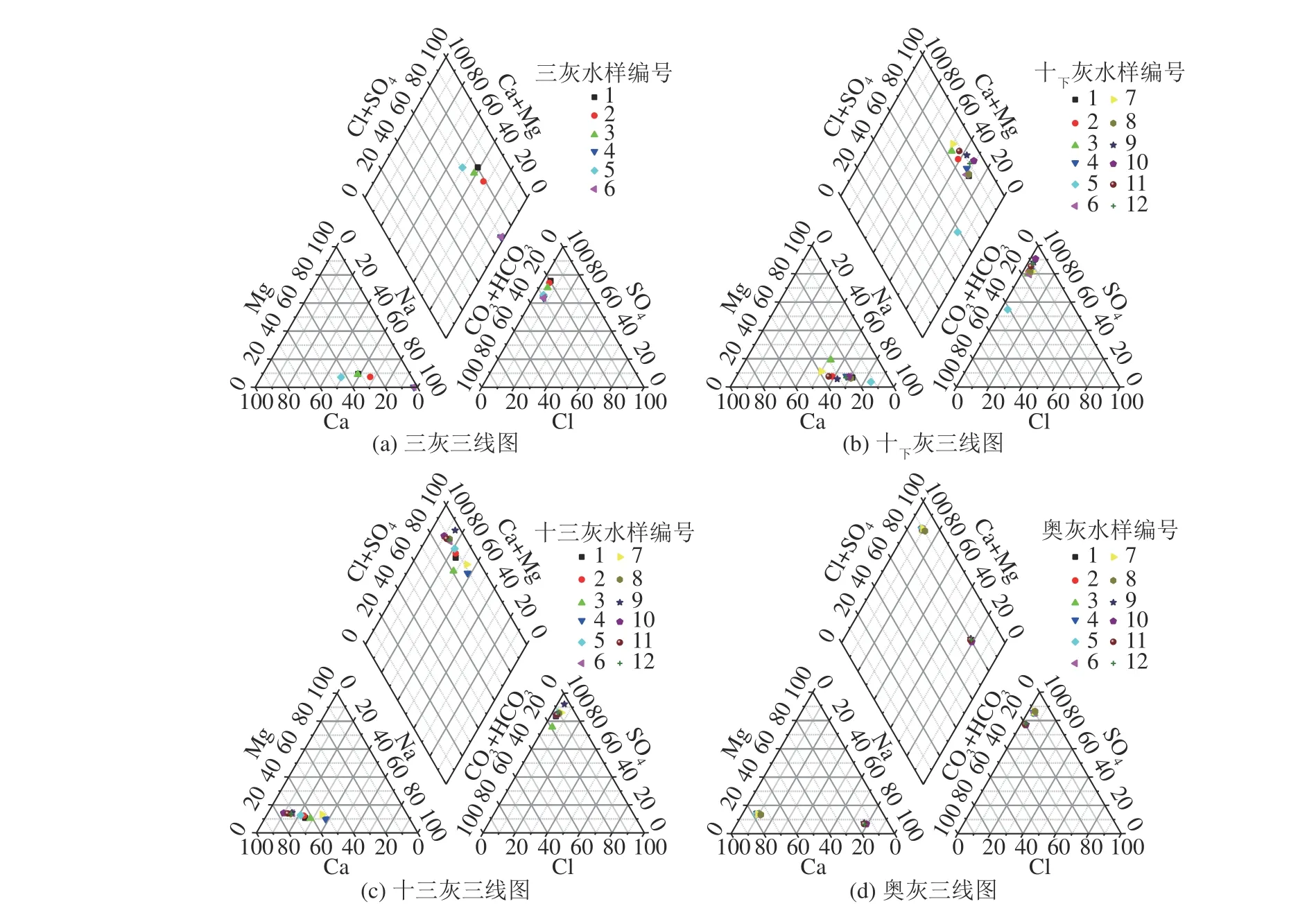
图4 地下水水化学piper 三线图Fig.4 Piper three line diagram of groundwater chemistry
2.3 PCA-AWOA-ELM 水源识别模型
选取岱庄煤矿三灰(Ⅰ)、十下灰(Ⅱ)、十三灰(Ⅲ)、奥灰(Ⅳ)共48 组实测水样数据(38 组训练样本,10 组预测样本),以Na+、Ca2+、Mg2+、Cl-、SO24-、HCO-3六种离子作为判别指标,建立PCA-AWOAELM 模型对矿井突水水源进行判别,流程图如图5所示。训练水样实测数据见表1,预测水样实测数据见表2。

图5 PCA-AWOA-ELM 模型流程Fig.5 Flow chart of PCA-AWOA-ELM model

表1 岱庄煤矿水样实测数据表(训练集)Table 1 Actual measurement data of water samples in Daizhuang Coal Mine (training set)
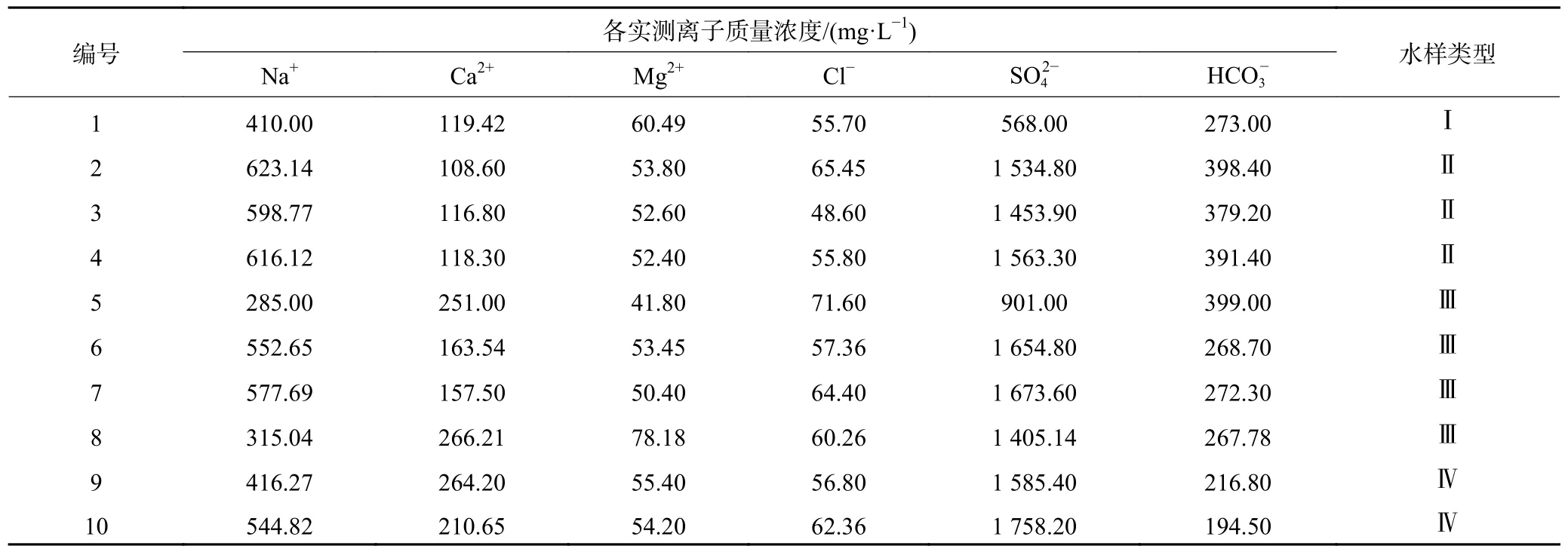
表2 岱庄煤矿水样实测数据表(预测集)Table 2 Measured data of water samples in Daizhuang coal mine (prediction set)
首先,对训练样本实测数据进行主成分分析,笔者使用SPSS.26 软件实现,根据相关性系数表(表3)知,6 种离子间相关性较大,Ca2+和Mg2+,Ca2+、Mg2+与SO24-、Cl-之间的相关性均达到了0.7 以上,S-和Cl-之间的相关性也达0.68,由此看出,样本指标之间的信息出现了较大的重复,对水源判别模型的精度造成影响,故对数据进行主成分分析是十分有必要的。

表3 水化学成分指标相关系数矩阵Table 3 Correlation coefficient matrix of water chemical composition index
按照累计贡献率大于85%的原则,提取3 个主成分(表4),主成分与标准化原始变量间相关关系如下:
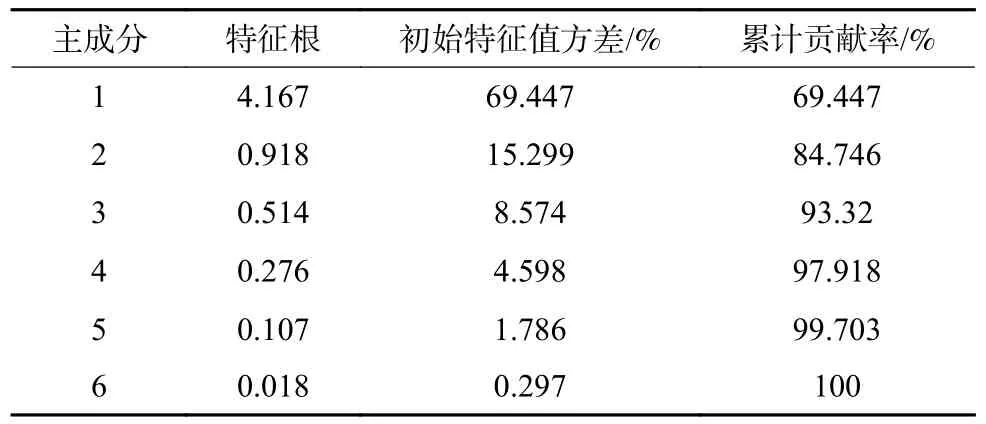
表4 主成分总方差解释Table 4 Explanation of total variance of principal components
设置模型最大迭代次数100,种群规模30,输入层节点数3,输出层节点数4,隐含层神经元个数38 个,网络输出状态为4,将训练好的参数及模型对并测试集进行测试,结果如图6 所示。
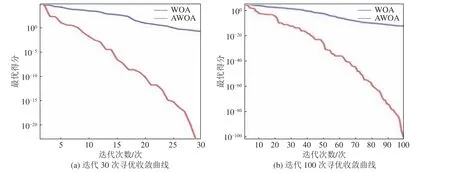
图6 不同迭代次数寻优收敛曲线比较Fig.6 Comparison of convergence curve of different iterations
由图6 寻优收敛能力曲线比较可知,通过自适应权重的鲸鱼优化算法在迭代次数不同的情况下,寻优能力,收敛速度和寻优精度都较鲸鱼优化算法强很多,且稳定性好,因此,在ELM 模型中引入AWOA 优化在水源判别模型中能够以快速且准确的优势取得较好的结果。
将PCA-AWOA-ELM 模型预测结果与PCAWOA-ELM 模型、PCA-ELM 模型和ELM 模型进行对比(图7)可知,PCA-AWOA-ELM 模型的预测精度达到了100%。由图7b 和图7c 对比可知,鲸鱼算法对极限学习机权值和阈值的优化成效很大,改进了极限学习机随机产生权值与阈值而导致的预测性能不稳定,预测结果正确率低,随机性太强的缺点。在图7a 和图7b 的对比中可知,精英引导机制及动态混沌因子的引入,加强了鲸鱼优化算法的寻优能力与精度,从而更好的优化ELM 模型的泛化能力及预测精度。由图8 可知,改进的鲸鱼优化算法在迭代100 次的情况下迭代误差极小,且在迭代63 次处迭代误差达0.01,由此可知改进的鲸鱼优化算法的精度明显提高。综上所知,AWOA-ELM 模型在水源识别的应用上有着泛化能力强,稳定性高,预测精度高的优势。

图7 各模型预测结果对比Fig.7 Comparison of prediction results of various models
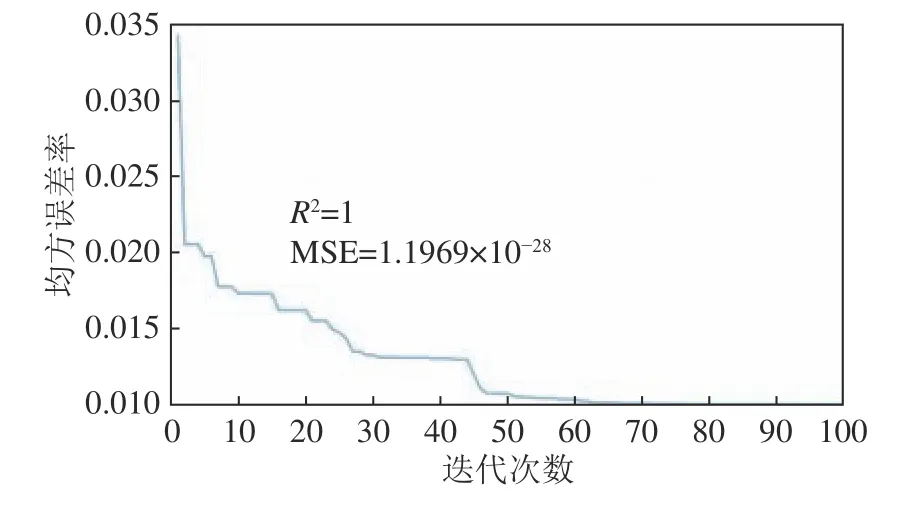
图8 AWOA-ELM 模型迭代误差Fig.8 Iteration error diagram of AWOA-ELM mode
3 结 论
1)运用因子分析进行主成分提取,有效地减少了各指标间的信息重复和AWOA-ELM 模型输入层的个数,提高了算法的运行速度。
2)改进的鲸鱼优化算法克服了极限学习机权值阈值随机取值的缺点,对权值和阈值进行全局寻优挖掘,提高了算法的收敛速度、精度。
3)将PCA-AWOA-ELM 突水水源识别模型应用于岱庄煤矿,并与PCA-WOA-ELM 模型、PCAELM 模型、ELM 模型预测结果进行对比,实践证明,该模型识别精度较高,为矿井安全生产提供了重要保障。
