Mort:面向实时数据分发和传输优化的依赖性任务卸载框架
2023-05-22殷昱煜苟红深李尤慧子黄彬彬万健
殷昱煜 苟红深 李尤慧子 黄彬彬 万健
(杭州电子科技大学计算机学院 杭州 310018)
随着通信技术(如5G)和人工智能等关键技术的发展,边缘计算(edge computing,EC)和物联网(Internet of things,IOT)等大型分布式信息系统的格局和规模发生了显著的变化.根据国际数据中心的《中国物联网连接规模预测,2020—2025》和《2021 年11 月爱立信移动市场报告》显示,截止到2025 年中国物联网总连接量将达到102.7 亿,将占到亚太地区(除日本外)总连接量的84%[1].同时,这些接入设备产生的数据也在急剧增加.预测显示,截止到2027 年末移动网络数据总流量可能达到370 EB[2].这些设备常分布于不同的地理位置,在多个方面存在差异(异构):1)底层芯片,如EMPC(economic embedded multi-chip package),MCU(microcontroller unit),FPGA(field programmable gate array),DSP(digital signal processor);2)计算能力;3)上层操作系统,如HelloX,Android IOT/Brillo,Windows 10 IOT Core,Ubuntu Core 16,FreeRTOS,TinyOS;4)网络通信协议,如MQTT(message queuing telemetry transport),NB-IOT(narrow band IOT),ZigBee,CoAP(constrained application protocol),5G.随着边缘业务日趋繁杂,其应用程序也变得复杂,如虚拟/增强现实[3]、智慧交通[4]等.它们的计算需求较大、延迟敏感,普通边缘设备不能提供其计算需要的资源,而云计算时延太高[5].因此,EC 和IOT 面临2 个问题亟需解决:1)设备软硬件异构性带来的通信难问题,繁杂的协议使得数据共享和隐私保护等操作变得困难;2)低成本和对丰富的计算资源需求之间的平衡问题.低廉的设备成本促进了EC 和IOT 的发展,但却难以完全满足现阶段的计算需求.
通信难问题主要是因为统一规范的缺失,发布订阅系统(publish/subscribe system,PSS)[6]常常作为一种解决方案.PSS 是一种数据共享的模式和规范,它并不限制底层采用何种方式进行通信.在一般的实现中PSS 采用TCP/IP 方式,也可以使用如NB-IOT,ZigBee,WIFI 等常见方式.PSS 一般由发布者、订阅者和事件服务组成,采用以数据为中心的数据分发模式,可以实现大规模分布式系统中各实体间数据的分发.在这种模式下,发布者将数据封装成事件,订阅者订阅自己感兴趣的事件,事件服务则负责将各事件分发给订阅者.在分发过程中,不用关心具体的实体(异构性),发布者和订阅者无需相互感知和连接,其交互完全匿名,具有灵活性、去耦合、异步通信等重要特点.PSS 在大型分布式消息系统中越来越受到重视,如基于千兆网的自动驾驶应用[7]、物联网数据共享应用[8]、电力物联网的应用[9]和机器人通信[10].
对于计算资源不足的问题,学界常常采用任务卸载.任务卸载是指将边缘终端的计算任务卸载到边缘服务器等资源丰富的计算节点上,从而同时满足计算能力和时延要求.任务卸载可以分为2 个子领域[11]:独立性任务卸载(independent task offloading)和依赖性任务卸(dependent task offloading).独立性任务是指任务之间没有数据依赖关系,彼此独立.独立性任务卸载研究的问题往往是在一系列约束条件下,如计算能力、截至时间、电池容量等,如何将持续到达(或已经到达)的多个任务合理地卸载到附近资源丰富的计算节点上,以获得最大的收益(或减少损失),如文献[12]的执行时间和电池优化、文献[13]的计算资源优化等.依赖性任务是指任务之间存在输入输出的依赖关系.同独立性任务卸载相比,依赖性任务卸载问题还需要考虑任务之间的执行顺序.对依赖性任务卸载的研究主要集中在仿生[14]、深度强化学习[15-17]等智能算法和数学优化[18]、启发式[19-20]等传统优化方法上.
在EC 和IOT 中,异构性带来的通信难等问题可以通过借助发布订阅模式提供统一的数据共享规范来解决.计算资源的匮乏可以采用任务卸载,由边缘计算节点分担计算需求,同时降低延迟.然而,当发布订阅系统和任务卸载结合时会产生新的问题,如现有的任务卸载算法不能很好地应用在发布订阅系统中.发布订阅模式下的边缘业务/应用具有3 个特点:1)由多个子任务构成,任务之间有依赖关系;2)任务具有周期性,在一段时间内重复执行单一功能,没有明确的完成时间;3)任务执行中,往往存在大量的数据分发.因为具有周期性、高频数据分发等特点,大量现有基于完成时间的任务卸载算法无法很好地应对这类场景.可以重复执行这些基于完成时间的任务卸载算法来模拟周期性,但会不可避免地引入调度等额外开销.在此类应用中,数据传输带来的开销变得不可忽视,因此本文聚焦于PSS 下基于数据传输优化的依赖性任务卸载问题,并设计实现了框架Mort 来解决该问题.
针对依赖性和执行周期性的特点,Mort 实现了基于静态代码分析的任务分解和基于协程(可以理解为一种能够保存CPU 上下文的函数)的调度模型.底层操作系统更强调通用性,它的调度策略更多的是考虑进程(线程)间的公平性,而无关上层业务.这些子任务间存在依赖关系,执行时有先后次序,若次序靠后的任务先被调度执行,就会浪费此次调度机会和CPU 时间.因此需要一种方式控制这些任务按照依赖次序调度以减少执行周期时间.本文中的任务以协程的方式实现,从而可以在应用层进行调度控制.虽然通过同步或设置进程优先级似乎也能达到同样的效果,但同步操作依旧不能避免操作系统的错误调度,而优先级设置则更多是一种对操作系统的建议,不会得到明确的保证.
针对高频率数据分发特点,为减少网络带宽资源的消耗和网络拥堵的可能,Mort 实现了2 个任务卸载算法:基于分组的任务卸载(grouping-based task offloading,GBTO)与基于分组和资源融合的任务卸载(grouping and fusion-based task offloading,GFBTO).GBTO 采用分组策略,在邻近的计算节点中选择满足任务资源需求的节点,并尽可能将任务卸载到其所需数据的源头.考虑到满足依赖关系的多个任务卸载到同一个计算节点后可以共享计算资源,由此本文在GBTO 的基础上提出基于路径归并的计算资源优化算法GFBTO,进一步减少带宽资源的消耗.然而,应用GFBTO 会使得计算节点的负载变高,在某些场景中可能会降低系统响应性.因此GBTO 适用于CPU 密集型任务组,而GFBTO 更加适合I/O 密集型任务组.GFBTO 算法能够将更多的任务卸载到同一个计算节点,这些任务可以在应用层得到调度,使得其执行周期变短,也适合于时间敏感型任务.无论是GBTO 还是GFBTO 都更倾向于把任务卸载到其输入源处,尽可能地让数据在本地处理(哪里产生哪里处理),尽可能地减少数据在网络中传输,同时也减少了由于数据传输带来的网络延迟,任务能更加及时地计算出结果.为了更好地使用这2 种算法,Mort 会根据各计算节点CPU、I/O 利用率和任务组的I/O 密集型任务的占比来选择合适的卸载算法.本文的主要贡献总结为4 个方面:
1)设计实现了任务卸载及管理框架Mort.针对PSS 中任务的依赖性、周期执行性和高频率数据分发特性,Mort 采用了任务分解、任务卸载和协程调度3 个步骤,增加了任务并行度、减少了网络数据传输量和减少了任务调度开销.
2)将面向发布订阅系统的任务卸载数据传输优化问题建模为非线性整数规划问题,并设计了一种基于数据依赖分组策略的优化算法GBTO 来解决它.
3)进一步挖掘任务间依赖特性,在GBTO 基础上设计了一种基于路径归并算法GFBTO.该算法使得卸载到同一计算节点的属于同一任务组的任务间能共享计算资源.与GBTO 相比,GFBTO 使得同一个计算节点上卸载的任务数量增加,提高了计算节点的负载,但同时也增加了任务并行度和减少了操作系统的调度切换开销.因此GBTO 更适合CPU 密集型任务,而GFBTO 更适合I/O 密集型和时间敏感型任务.
4)针对GBTO 和GFBTO,设计了仿真和真实场景实验.在仿真实验中,GBTO 和GFBTO 的数据传输分别能达到OPT 的80%和90%左右,且GBTO 比Greedy高出约50%.在真实场景中,设计了一个分布式的文本统计作业,分别应用GBTO,GFBTO,Greedy 算法卸载,其结果与仿真实验一致,并且,Mort 本身引入的开销仅约为2%.
1 任务卸载相关工作
1.1 独立性任务卸载
设计了一个在线近似算法,并证明了其近似比为2(1+ε)ln(1+d).在动态的移动边缘计算环境中,
独立性任务是指卸载的任务之间没有任何关系,相互独立.数十年来,独立性任务卸载领域已有大量成果,它们可以被分为2 类:离线算法[12-13,21-25]和在线算法[11,26-30].离线算法需要知道所有任务的信息,然后统一卸载任务最大化目标.文献[21,23-24]主要关注如何最小化卸载时服务的响应时间.文献[21]注意到服务响应时间可能受设备之间连接性的影响,为协调分配,设计了一个分布式卸载算法;文献[23]提出一个2 层的缓存迭代更新算法来解决该问题,而且还能有效减少卸载过程中的数据传输;文献[24]则是任务卸载和服务缓存在线联合优化机制,将任务卸载和服务缓存联合优化问题解耦为任务卸载和服务缓存2 个子问题.在线算法不需要提前知道任务的信息,它们可以在任意时刻到来.文献[11]从最大化服务提供方收益的角度考虑,利用原始对偶方法文献[30]考虑IOT 设备的计算任务卸载问题,并基于强化学习设计了一个任务卸载的框架.
文献[11-13,21-30]所述工作主要面向独立性任务,它们假设任务以时间次序到达(在线)或已经到达(离线),其目标是最小化任务完成时间或最大化资源收益等.而在具有依赖性、执行周期性和高频率数据分发等特点的任务卸载问题中,这些算法的作用并不明显.
1.2 依赖性任务卸载
依赖性任务是指待卸载的任务之间存在输入的依赖关系[31].依赖性关系卸载问题是典型的DAG 调度问题,属于NP-Hard,相关工作较少.一些工作借助智能算法尝试解决该问题[14-16].面对复杂的依赖性组合优化问题,文献[14]采用了基于队列优化的粒子群算法来减少整个任务的完成时间和执行开销.与文献[14]不同,文献[15]提出了PTRE(priority-topologyrelative-entropy)算法,将任务DAG 转化为任务向量序列,从而采用基于深度强化学习的图映射框架来达到目标.文献[16]将资源受限的边缘计算环境下的多作业卸载问题建模为马尔可夫模型,并利用深度强化学习算法减少其传输和计算开销.智能算法在很多NP-Hard 问题上表现优秀,然而其耗时较长且没有理论保证其性能.更多的工作尝试利用数学优化、改进的贪心策略或者精巧的启发函数来近似求解.在最小化任务完成时间方面,文献[19]考虑一个应用由多个任务构成,结合服务端的函数配置和任务卸载,设计了一个近似算法,但它却忽视了边缘服务器的计算能力.借助DAG 中的关键路径思想,文献[32]提出了HEFT 启发式算法以减少任务的最早完成时间.注意到在卸载过程中,边缘服务器和移动设备侧重的点不同,文献[33]提出一个启发式算法,尽可能地提高服务器的资源利用率,减少移动设备的能量消耗.文献[34]认为简单地将任务分配到远端云上,其无线通信开销可能比其收益更大,因此设计算法HTA2,以减少异构移动系统中的能源开销.另外一些工作[35-37]则综合考虑任务的完成时间和能量消耗.文献[35]提出 MAUI,即提供细粒度的应用代码到远端服务器的部署,能够在运行时决策将其代码卸载到何处,并最大化节省能量和减少时间消耗.文献[36]从软件提供方角度出发,考虑最小化远端计算开销和移动设备能量消耗,并控制服务响应在一定合理的延迟内,设计了一个多项式时间算法DTP.文献[37]的目标同样是节省能量开销、计算开销和减少延迟,它设计了一个 3 阶段算法 SDR-AO-ST(semidefinite relaxaion,alternating optimization,and sequential tuning),能够有效减少系统开销.
文献[14-16,19,32-37]所述的工作都假设任务有确切的执行时间,数据传输是单次的.然而,发布订阅系统中的任务不仅具有依赖关系,还具有周期性,没有明确的结束时间,执行中往往存在大量数据分发.针对周期性和大量数据分发的优化不仅可以优化带宽资源(减少数据在网络中的传输),还能降低等待网络数据带来的高延迟(通过将任务卸载到数据源处),然而上述工作没能考虑这些问题.因此本文基于PSS 设计了面向数据传输优化的卸载算法.
2 Mort 架构
为高效地完成业务解析、任务卸载、任务管理以及数据分发等操作,本文设计了Mort,图1 是它的架构.本节介绍其中主要的组件和系统工作流程.

Fig.1 Mort architecture图 1 Mort 架构
2.1 作业分解/任务构造组件
用户通过用户接口编写代码和作业描述文件.作业分解组件借助这些信息构建有向循环图(directed acyclic graph,DAG)任务组实例,如图2 所示,其中的dij,rtj分别表示数据依赖和计算资源需求.某些任务除了依赖本组其他任务外还可能需要外部的数据,因此在构建任务组时会创建虚拟任务.该组件构造的DAG 任务组实例会提供给卸载算法组件.
2.2 卸载算法组件

Fig.2 Job decomposition图 2 作业分解
卸载算法组件会结合邻近可达计算节点的状态信息(由任务管理组件提供)和任务组实例,执行GBTO 或者GFBTO 算法,生成详细的任务卸载计划.随后管理组件依照该计划将任务部署到具体的计算节点上.
2.3 任务管理组件
任务管理组件会维护网络中所有可达计算节点的状态,包括计算节点的资源信息、其上运行任务的权限和状态等信息,为实际的任务卸载提供数据支撑.同时,通过该组件还可以管理各任务的运行状态.
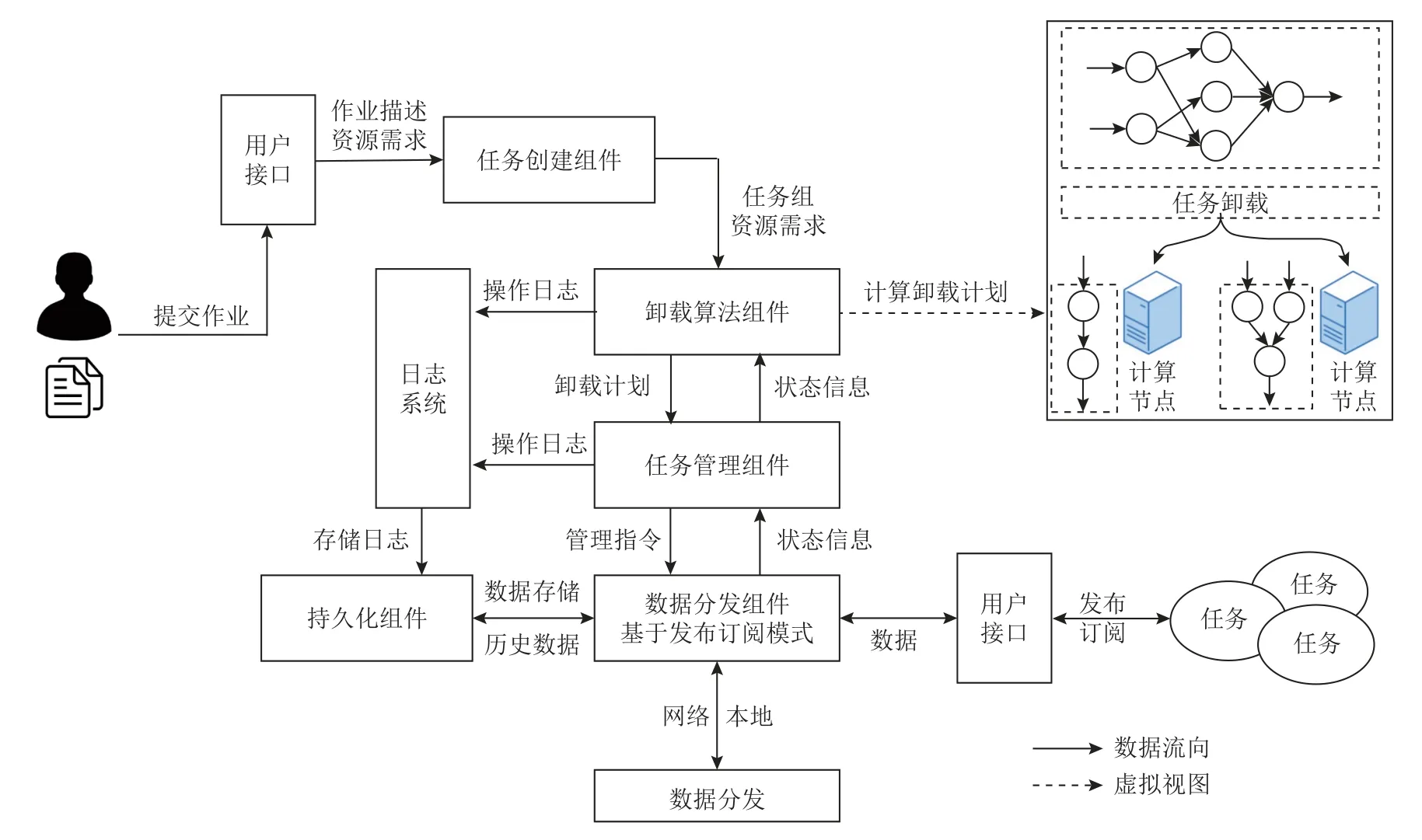
Fig.3 System workflow图 3 系统工作流
2.4 数据分发组件
该组件基于发布订阅模型实现,为其他组件提供数据服务.它主要提供2 个功能:1)同步网络中边缘计算节点的状态信息;2)完成数据的分发.
2.5 持久化组件
持久化组件主要是将设备实时产生的数据持久化.数据持久化能为历史数据服务提供支持,而且当网络不稳定时还能在一定程度上提高系统的服务质量(quality of service,QoS).
2.6 样例分析
本节以一个例子介绍Mort 在实际场景中是如何实施的,如图3 所示.考虑这样一个简单例子,城市规划中,红绿灯时长分配对路段交通拥堵有很大影响,极端情况下可能在几个路段间引起连锁反应.在智慧城市中,可以根据路口人流量、车流量、天气等情况动态改变时长.对于这类动态检测及控制应用,卸载时需要考虑到数据传输的开销、计算节点的负载等以尽量减少单次计算的时间,因此选择合适的计算节点尤为重要.
智能红绿灯场景中,可以将作业构造成4 个子任务:人流量检测任务、车流量检测任务、天气检测任务和决策任务.城市管理人员将Mort 部署在城市的每一个计算节点上,他们可以在任意一个节点提交作业描述文件.任务构造组件读取描述文件后将构造这4 个子任务,并将它们传递给任务管理组件.任务管理组件会结合任务类型和邻近节点状态选择合适的卸载算法,将任务组和相关信息传递给卸载算法组件制定卸载计划.卸载算法组件执行相关卸载算法后将卸载计划返回给任务管理组件,任务管理组件再通过数据分发组件将任务分发到各个计算节点执行.任务执行过程中需要订阅的数据和发布的数据由数据分发组件在各个节点间传输.任务执行过程中产生的数据和操作记录等信息可能会记录在持久化组件中以供后续分析使用.
数据传输以发布订阅方式进行,且只会发生在计算节点之间.任务卸载到计算节点后,在其生命周期内按照“订阅到数据—计算—发布数据”这样的方式循环执行.在任务组构造过程中会为用户端构造一个任务用来订阅计算结果.
3 Mort 实现
本节将详细介绍Mort 主要组成部分的实现.
3.1 作业分解/任务构造组件
作业分解/任务构造组件通过源代码静态分析得出任务间的依赖关系(通过订阅发布的数据类型和一些其他的控制流接口),再结合作业描述文件进一步构造任务组实例.
静态代码分析通常有控制流分析[38]和数据流分析[39]两种,本文采用数据流分析方式.通过分析追踪各份源代码中函数调用情况和参数传递信息来建立各任务之间的依赖关系.这里结合一个例子阐述其实现方式.假设有一项作业由TaskA,TaskB,TaskC这3 个子任务构成.如图4 左边,任务TaskA和TaskB分别订阅Topic_V1(由任务TaskV1发布)和Topic_V2(由任务TaskV2发布)数据类型,同时发布Topic_A和Topic_B数据类型.任务TaskC同时订阅Topic_A和Topic_B数据类型.TaskA,TaskB,TaskC这3 个任务分别调用函数Task::RegTask(name,…)注册自身信息,调用函数Task::RegSub(topic_list)注册订阅数据类型,调用函数Task::RegPub(topic_list)注册发布数据类型.如图4 中间,分析A代码时,能够构建TaskA与TaskV1的数据流关系(通过查询任务管理组件获取TaskV1到TaskA的数据量和频率);分析B代码时,能够构建TaskB与TaskV2的数据流关系;分析C代码时,能够部分构建TaskA,TaskB,TaskC之间的数据流关系.如图4 右边(任务TaskV1和TaskV2不属于本次任务组,所以用深色标识),融合TaskA,TaskB,TaskC时,可以完整构建任务DAG 数据流,此时再结合作业描述文件获取各个任务的资源需求等信息,任务组DAG 就能够构建完成.在融合时,各任务只能依赖已卸载或存在本任务组中的任务,不能循环依赖.当这些步骤执行后,任务组构建完成.
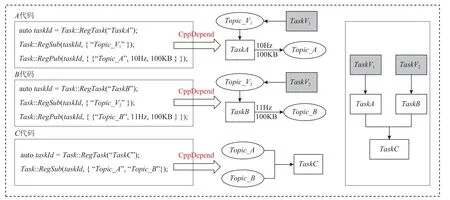
Fig.4 Static program analysis to build task group图 4 静态代码分析构造任务组
3.2 任务管理组件实现
任务管理组件主要负责响应系统环境的变化、接收用户命令、执行卸载算法组件给出的卸载计划以及调度卸载后被抽象成协程的任务,如图5 所示.
在PSS 中,数据的发布和订阅需要授权[40].Mort 的权限验证模块使用了基于属性的访问控制(attributed based access control,ABAC)技术,并增加了地理位置、资源利用率等动态属性.当系统环境等上下文变化时,可能会引起权限的变化,而且用户也可以通过用户接口显式地改变某些属性值或权限.为进一步对数据传输提供保护,还可以将数据加密后进行传输,或为计算节点引入证书等方法.

Fig.5 Task management component logic implementation图 5 任务管理组件逻辑实现
每一个计算节点上都会部署Mort.为了使这些节点上的任务管理组件信息同步,Mort 启动后会在数据分发组件中维护/right,/state,/cmd 这3 个数据域,分别用来同步权限、节点/任务状态和来自其他节点的命令等信息.该组件还包含一个冲突处理模块,主要负责处理同步导致的节点状态的不一致.不一致主要是因为多个用户同时设置不同的权限或命令而引发的冲突.对于这2 种冲突,会根据用户权限(higher-prior win)、操作先后次序(first-commit win)等情况判定和记录日志后续恢复等措施解决.
任务卸载后,从任务管理组件的角度来看(任务视图),一个进程包含多个线程,一个线程包含多个协程,在线程调度协程时(执行视图),它首先会处理新到来 的命令(函 数process)、更新权 限(函 数updateRight),然后分发数据.在分发数据阶段,每个任务都被抽象成了发布者或订阅者,订阅者响应数据到来事件,发布者产生过期事件(按一定频率发布数据).分发数据主要是处理这2 种事件和权限鉴定.其中函数resume、函数execute、函数suspend操作是协程的调度操作.函数resume表示恢复当前协程的CPU 上下文;函数execute则是读取或者发布数据;而函数suspend是保存当前协程的CPU 上下文,让出CPU.
3.3 数据分发组件实现
该组件负责接收发布者的数据、将数据分发给订阅者和接收/分发来自任务管理组件的命令等功能.数据分发组件的实现采用的是OMG(object management group)发布的DDS(data distribution service)规范[41],业界也有很多成熟的实现,如FastDDS[42].Mort 除了基于DDS 实现了分布式网络分发之外,还针对本地数据分发做了优化,如分发到本地的数据不再走网络部分,而采用进程间共享内存或进程内共享(被绑定在一起的属于同一任务组的任务间共享)内存的方式.
3.4 卸载算法组件实现
卸载算法组件负责在构造的任务组上执行卸载算法从而给出具体的卸载计划.下面阐述其具体实现.
3.4.1 卸载算法组件建模
1)作业及任务模型
如图2 所示,用户作业由M个依赖性子任务组成,记为J={t1,t2,…,tM}.每个子任务可以表示为ti={di*,rti},其中di*=(dij)是一个向量,表示任务之间的数据依赖:如果任务ti不依赖tj(tj不需要传输数据给ti),则有dij=0;反之,任务ti依赖tj,则依赖数据量为dij(单位:bps).一般地,这些子任务还可能依赖外部的任务,如图2 中构造的3 个虚拟任务rt0,rt1,rt2.这3 个任务不属于该次作业,而是之前已卸载的任务,现存在于某些计算节点上.rt也是一个向量,rt=(rti)i=1,2,…,M.rti表示该任务i的资源需求,为简单起见,此处指CPU 核数.本文任务模型中,用户作业指移动边缘计算中的业务作业,其包含的任务无明确的执行时间,它们可能会滞留计算节点重复执行.每个任务不能再次划分,且只能分配到一个计算节点.
2)计算节点及卸载模型
假设当前网络中有N个计算节点,记为C={c1,c2,…,cN},且每一个计算节点当前有rcj个空闲的CPU 核.设Aij=1 表示将任务i卸载到计算节点j,卸载到每个计算节点的任务不能超过该节点的CPU 空闲容量,因此有
假设网络中的计算节点总能容纳所有的任务(不考虑等待的时间),而且每个任务在其生命周期内只能卸载到一个计算节点上,所以对于本次作业的所有任务有
需要注意,该模型的任务组中的任务可能依赖之前已经卸载了的外部任务.这些约束需要结合实际情况考虑.假设 S是在之前就已经被分配任务的集合,且对应的计算节点集合为 P,有
本文中的计算节点包括2 个部分:边缘服务器和计算存储资源相对丰富的边缘设备,它们一般负责与一定区域的边缘设备和传感器交互,包括数据共享和命令传送.
3)问题模型众多边缘设备和传感器在高速、大量地产生原始数据,这些数据稍后在网络中共享、处理.卸载任务时考虑数据的传输优化可以有效地减少整个网络中数据的传输量.因此本工作中的卸载算法需要解决的问题是:给定一组依赖性任务J={t1,t2,…,tM}(包括它们的CPU 需求和数据依赖)和一组边缘计算节点C={c1,c2,…,cN}(包括它们的CPU 空闲容量),如何将这些任务卸载到这些计算节点上,使得整个网络中传输的数据最小,即卸载后任务本地处理的数据量最大

Fig.6 Illustration of algorithm 1图 6 算法 1 的图解
这是一个非线性整数规划模型,可以将整数约束用等价的二次项替换,从而达到松弛变量的效果.因此,式(2)可以改为
许多工作已经证明,在异构环境中的DAG 调度是NP-hard[43],式(6)(7)描述的模型同样是一个NPhard 问题.
3.4.2 GBTO 算法实现
本节提出了一个基于分组的任务卸载算法GBTO近似地解决该问题,并给出复杂度说明.该算法分为2 个部分:预处理和任务卸载.
1)预处理
在预处理中,借鉴了字符串匹配算法KMP 的思想,尽量挖掘对象自身的模式来加速后面的卸载过程,图6 和算法1 描述了其细节.
图6 中,圆形表示任务,圆形中间的rti表示该任务的CPU 需求,圆形上边的数字表示任务编号,而箭头上边的dij表示任务之间数据传输量.在预处理时,首先求得任务组的拓扑序列,该操作由算法1 中的函数topologicalS equence完成.然后从后往前遍历拓扑序列,根据其数据依赖的大小主动选择一个它的直接前驱任务并为一组(如图6 中的虚线有向箭头和算法1 中的行②~⑮,其中函数merge表示集合的并集操作).待所有任务选择完之后,整个作业就被分为了若干组(如图6 中被分成了3 组:[0,2,4,5,7],[1,3,6],[8]),这些组稍后会作为一个整体考虑.每一个组都有一个领头任务(不算虚拟任务,如图6 中的虚边框任务2 和任务3),它记录着该组的所有数据依赖量D和资源需求量RT.虚拟任务不参与分组.
算法1.GBTO 预处理.
2)任务卸载
预处理过程构造了若干个初始任务组,该阶段将以它们为单位进行2 步骤卸载.图7 和算法2 详细描述了此过程.
①预卸载(如图7 的左半部分,算法2 行②~⑭).每一个组的领头任务尝试卸载本组任务到各个计算节点cj,并记录其收益Profitj,即该组任务卸载到计算节点cj上时能保留的依赖数据总量.卸载时可能会出现RT>rcj的情况,即节点不能容纳该组的所有任务.此时领头任务将依据组内拓扑序列从后向前依次模拟移除任务,直到剩下的任务可以被该节点容纳,同时在可被卸载的节点中记录能取得的最大收益,即Profitimax.
② 正式卸载(图7 的右半部分,算法2 行⑮~㉚).待所有组预卸载之后,从中选取收益最大的组进行正式卸载(算法2 行⑮,图7 中则是组1 在pro fit1取得最大).被选中的组在卸载之前先移除前一步骤中模拟移除的任务.这些被移除的任务会根据实际情况或加入现存的组或构造新的任务组.具体地,对于每一个被移除的任务,在还未卸载的前驱中选择依赖数据量最大的前驱,然后并入该前驱所属的组.如果没有这样的前驱存在,则该任务独自构成一新组(算法2 行⑯~⑳,而图7 中则是组1 移除了1 个任务,该任务被并入到了组2).正式卸载某一组后需修改计算节点容量,以及计算节点访问标志,后续剩余组更新时,只需要重新计算发生变化的节点即可(算法2 行㉕,及图7 中组2 需要重新计算其Pro fit1).最后重复执行算法2 行②~㉕过程,直到所有任务卸载完成.

Fig.7 Illustration of algorithm 2图 7 算法 2 的图解
算法2.GBTO 任务卸载.
①预处理过程.比较耗时的2 个操作为计算任务的拓扑序列和递归分组.拓扑排序在任务构造时已经完成,故此处不用计算.合并函数merge是线性的,时间复杂度为O(M),且是本地执行,不需要额外的空间,空间复杂度为O(M).
②任务卸载阶段.假设预处理将任务分为了H 组,则在第1 次预卸载过程中需要执行H×N次尝试.后面的预卸载中,每组只需要重新计算发生变化的计算节点即可,因此,总共的时间复杂度为
其中H ∈[1,M],而在绝大多数情况下 H接近1,因此GBTO 最坏时间复杂度为O(N×M2),空间复杂度为O(M).
3.4.3 GFBTO 算法实现
GBTO 算法会依据任务组的CPU 需求判断能否将该组任务分配到某个计算节点上,而计算组CPU总需求时只是将组内各任务的CPU 需求简单相加.在一个任务组中,任务之间的关系可以分为2 类:一类是有(直接/间接)前驱后继关系;一类是无依赖关系.一个任务只有在它的所有前驱任务执行完获取到输入数据后才能运行.因此具有前驱后继关系的任务间没有并行的必要性,而无依赖关系的多个任务却可以.如图8 所示,若让该任务组内无依赖关系的任务并行,则需要的CPU 可以从9 减少至5(其中数字表示CPU 需求).引入CPU 资源融合操作后,能减少组CPU 需求,能让更多有依赖关系的任务卸载到同一节点,就能进一步减少网络中的数据传输.采用资源融合策略后,计算节点的负载会变高,可能会增加CPU 密集型任务的响应时间,因此,GBTO 和GFBTO 的适用场景不同.任务管理组件会检测各计算节点的状态,同时会给出使用何种算法的建议.
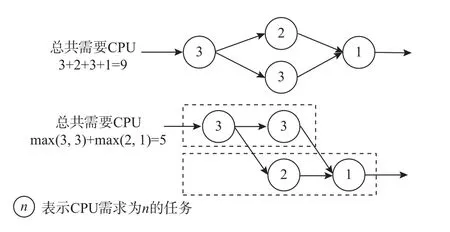
Fig.8 CPU merge图 8 CPU 融合
GFBTO 算法的难点在于如何快速确定一组任务中的CPU 最大并行数.针对这一难点本文设计了一个基于路径归并的资源融合(road merging-based resource fusion,RMBRF)近似算法.图9 和算法3~5 详细展示了其过程.
GBTO 算法中,一组任务卸载时,会根据组内信息判断其是否卸载,而RMBRF 通过拓扑排序、路径加入和路径传播3 个步骤重新计算了组CPU 总需求信息.后2 个步骤细节为:
1)路径加入
从任务组的前若干个任务执行开始,到所有任务执行完成(或所有任务都得到执行1 次)会存在多条数据流向,每一条都是一个依赖路径,图9 中的每一个标有数字序列的矩形框就是一条路径.算法3 执行时,会记录从某一个任务往后存在的所有路径,即算法3 中的路径集合Lcur.路径是从后向前传播的,当前任务需要选择一条路径加入,该路径通过调用函数theBestRoad得到.函数theBestRoad依照如下原则选择路径:计算每一条路径中的最大CPU 需求(算法4 行①~④),然后比较当前任务的CPU 需求和所有路径中的最大CPU 需求,若当前任务CPU 需求较大,则选择CPU 需求最小的路径加入,否则选最大的加入(算法4 行⑤~⑨).这一策略使得当前任务加入某一条路径后,所有路径最大总CPU 增长最小.
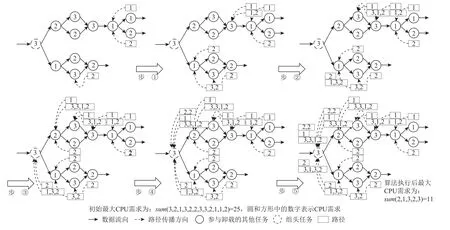
Fig.9 Road merging-based resource fusion(algorithm 3)图 9 基于路径归并的资源融合(算法 3)
2)路径传播
类似地,由于存在多个前驱任务,当前任务还需要选择将某一条路径向前传播给哪一个前驱.该前驱通过调用函数theBestFather(算法5)得到.函数theBestFather中选择前驱结点,采用和函数theBestRoad一样的策略,不同的是此时根据单条路径从前驱节点集合中选择单个任务.图9 的步骤①~④清晰地描述了路径加入和路径传播2 个过程,但求出的结果不是最优,而是近似最优.
算法3.RMBRF.
算法4.theBestRoad.
算法5.theBestFather.
3)GFBTO 复杂度分析
在GBTO 算法的基础上,GFBTO 增加了RMBRF操作.RMBRF 包含拓扑排序、路径加入和路径传播3 个步骤.设任务组中边集为E,则拓扑排序在任务构造期间已经求得,此处不需要再次计算.而路径加入和路径传播只会访问每条边1 次、每个顶点1 次,因此,时间复杂度均为O(M+|E|).同时,每个结点和边也只会存储1 次,因此空间复杂度同样是O(M+|E|).
3.4.4 卸载算法的选择
GFBTO 算法倾向于将更多的任务卸载到同一个计算节点,如果这些任务的计算占比很大,CPU 则会疲于上下文切换,各个任务的有效执行时间将减少,不利于低延时的任务.因此GFBTO 算法会倾向于将I/O 密集型任务放在一起,在部分任务等待I/O 时CPU也能得到更好的利用.
然而,精确地衡量一个任务的计算与I/O 占比很难,Mort 从2 个方面进行估计:1)源代码静态分析.4.1 节介绍了如何从源代码中得到任务组DAG,在DAG 中很容易得知一个任务的输入和输出,因此Mort假设,一个有更多输入源或输出源的任务的I/O 占比更高.2)计算节点状态监控.源代码分析的结果可能存在偏差,为了能够监控和均衡这一偏差,任务管理组件会实时收集节点的CPU 和I/O 利用率.
结合以上2 点,Mort 采用如下的方式选择卸载算法:计算多输入、多输出任务在整个任务组中的占比,若占比超过一定阈值(默认70%,是一个经验值,即预估一个作业有70%的时间处于I/O,当处于I/O的时间较多时,更多的线程/协程能有效利用CPU,该值可以配置)就选择GFBTO,否则选择GBTO.同时依照节点的CPU 利用率对节点进行排序,GFBTO 从高到低选择节点进行卸载,GBTO 由低到高选择节点进行卸载.
以上2 点考虑目前只用于选择卸载算法,不作为算法运行时的参考因素,不影响算法执行结果.
4 仿真实验
本节将进行仿真实验,比较Greedy(采用降序首次适应思想实现的贪心算法)、GBTO、GFBTO、OPT(采用LINGO 18 数学优化软件求解3.4 节数学模型的最优解)之间的性能.
4.1 仿真实验设置
1)计算节点分布数据集
计算节点分布数据集[44]开放了共享单车骑行数据集,将之处理后得到单车停靠坐标分布图(共400多万个点).将其按密度划分为多个区域(半径200 m),每个区域部署1 个计算节点,从而得到97 个计算节点,如图10 所示.圆形小点为单车停靠点(其中有大量圆形小点的点坐标重叠),星型为部署的计算节点.为确保任务能一次性卸载到这些节点上,节点的总计算能力与作业总计算需求成正相关,且每个节点的计算能力占比与其管理的点的数量占比正相关.共享单车停靠坐标,可能是人类活动的热点区域,也可能是城市公共智能设施倾斜的地方,大量的原始数据会在这里产生,因此计算节点适合布置在这些地方.
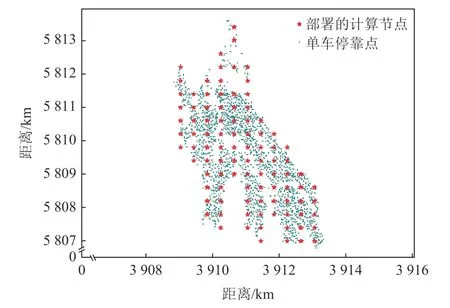
Fig.10 Distribution of computing nodes图 10 计算节点分布
2)任务数据集
任务数据集采用的是阿里巴巴2018 年公开的集群作业数据集[45].数据集中包含上千万个作业,每个作业由1~30 个任务组成.实验时将数十数百个原始作业融合成一个大型的作业,使其具有上百或上千个任务.每个任务的CPU 需求参照数据集中的数据,并适当地缩小,其范围为1~3(具有1 个CPU 需求的任务占比60%,具有2 个CPU 需求的任务占比30%,具有3 个CPU 需求的任务占比10%).本文假设任务之间的数据依赖量均匀分布,其范围为64~8 192 bps.

Fig.11 Data profits and simulated task distribution mode for simulation experiment图 11 仿真实验中数据收益与虚拟任务分布模式
4.2 仿真实验结果分析
4.2.1 变化虚拟任务分布模式
图11 中任务数量固定为200,计算节点数目固定为90,只需改变虚拟任务的分布模式.第1 个(ATCP)是虚拟任务更倾向于分配到计算能力强的计算节点上;第2 个(ATCP-R)是虚拟任务更倾向于分配到计算能力弱的计算节点上;第3 个则是采用随机分布(Random).很 明显,在ATCP 中GFBTO 的结果超过了OPT,原因有2 点:1)GFBTO 算法采用了资源融合策略.资源融合使得每个计算节点能够容纳更多的任务,而OPT 模型并没有资源合并操作.2)虚拟任务被优先分配到了计算能力强的节点上.结合第1 点,这使得GFBTO 算法执行时会更少地移除任务(因为融合后,有充足的CPU 资源),也就能保留更多的组内任务,前驱任务产生的数据也就尽可能地被本地消耗,而不用传输到网络中去.在ATCP-R实验组中,Greedy 效果尤其差.这是由于大多虚拟任务分配在计算能力差的计算节点上,而贪心策略看重当前次的收益使得这些节点的空间被浪费,陷入了较小的局部极值.
4.2.2 变化任务数量
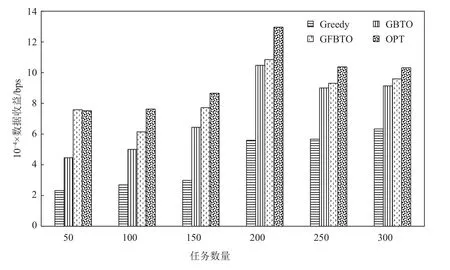
Fig.12 Data profits and task amount图 12 数据收益与任务数量
图12 中计算节点数目固定为90,虚拟任务分配方式固定为随机分配,任务数量从50 增加到300.可以看到,随着任务数量的增加,各算法的结果都有所增加,这是因为任务增多,总的数据量也相应增加.与其他实验组规律比较,不同的有2 组,分别是任务数量为50 和200 时的对比组.任务数量为50 时,GFBTO 超过了OPT,可能的原因是,此时任务数相对于计算节点数目较少,资源融合后资源较充足,更多有依赖关系的任务被卸载到同一计算节点,与4.2.1 节中的ATCP 组相同.任务数为200 时,各算法结果都相对较高,经查阅原始数据发现,GFBTO 的各任务的平均数据量比其他组高约20%.该实验中,各算法结果规律同4.2.1 节中的Random 组类似.
4.2.3 变化计算节点数量
图13 中,任务数量固定为200,虚拟任务分布为随机分配,而计算节点的数量从30 增加到80.该实验最能体现算法的不同:在计算节点较少时,可选择的也少;更多有依赖关系的任务被集中在一起,各个算法的差异也就越小.而随着计算节点数量的增加,选择变多,算法之间的策略差异被放大.可以看到随着选择变多,所有算法情况都在变糟,但GBTO 和GFBTO 表现很稳定,受影响较小.

Fig.13 Data profits and computing nodes amount for simulation experiment图 13 仿真实验中数据收益与计算节点数量
实验结果表明,任务在本地的数据消耗量方面,GBTO 平均高出Greedy 65%上下,GFBTO 在GBTO的基础上平均提升了约10%,而且GBTO 和GFBTO分别达到了OPT 的82%和94%左右.
5 真实场景实验
本节构造了一个文本统计与分析应用在真实的硬件环境中测试算法的性能.
5.1 场景实验设置
1)软硬件平台

Fig.14 Hardware platforms图 14 硬件平台
本实验选择了4 个树莓派4B(ARM-Cortex-A72,64b 1.5GHz,4-core,4GB)、1 个树莓派3B(ARM-Cortex-A53,64b,1.4GHz,4-core,1GB)和1 台PC(Intel i5-10500,3.10 GHz,3.10 GHz,6-core,8GB)作为计算节点,如图14 所示.实验中将设备分别编号:计算节点node 0(树莓派3B),计算节点node 1~node 4(都是树莓派4B),计算节点node 5(PC).为确保所有任务都能够被卸载,各计算节点的计算能力都按其本身的CPU 核数成比例放大.每个机器都以Ubuntu20.04 LTS 作为操作系统,并部署了Mort.实验过程中,各任务将以50 Hz 的速度在300MB 局域网内发布数据.

Fig.15 Real scenario experiment task instance图 15 真实场景实验作业用例
2)作业数据集
如图15 所示,本文构造了一个文本统计与分析应用.该应用由多个任务组成,每个任务负责统计某个区间内数字出现的频率.RawData1 和RawData2 分别是一个1MB 的文本文件,F1~F6是应用包含的子任务.应用中,F1统计文本中[0,100)间的数;F2统计[100,199)间的数;而F3统计大于199 的数;F4统计3个区间中的偶数;F5统计3 个区间中的奇数;F6融合所有的结果.各任务统计过程中会将结果发布出去.图15 中任务上边数字表示每个任务的CPU 需求,C*表示全局数据域中的具有 C*数据类型的数据域.
5.2 场景实验结果分析

Fig.16 Data profits and computing nodes amount for scenario experiment图 16 场景实验中的数据收益与计算节点数量
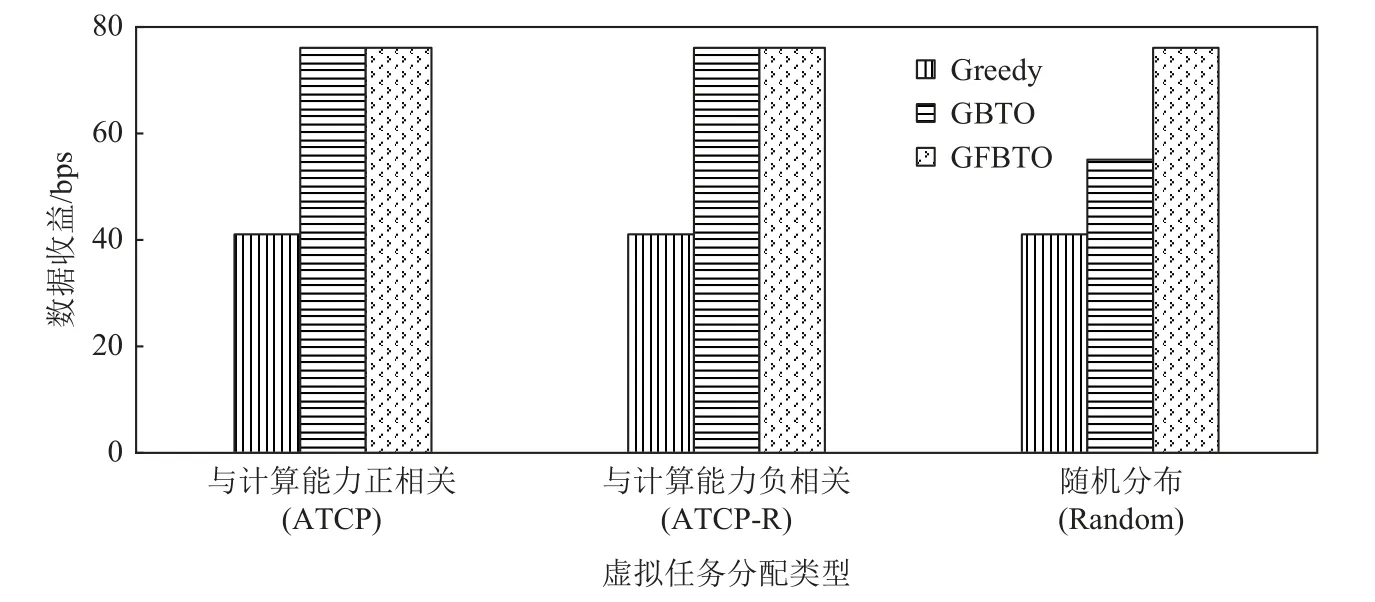
Fig.17 Data profits and simulated task distribution mode for scenario experiment图 17 场景实验中数据收益与虚拟任务分布模式

Fig.18 Mort performance图 18 Mort 性能表现
实验中分别将node 4 和node 5 作为RawData1 和RawData2 的数据源传感器.实验时,node 0 从node 4 上读取RawData1 的数据,node 2 从node 5 上读取RawData2的数据.图16 和图17 展示了3 种算法的效果和仿真实验一致.图18 是按照GBTO 算法生成的执行计划将各个任务分配到2 个计算节点上(node 0:F1,F2,F3,F4,F5,F6;node2:F2,F3,并 且RawData1 在node 0 上,RawData2 在node 2 上)Mort 的各项性能表现.图18(a)(b)分别是2 个计算节点上订阅到的数据延迟统计.对于node 0,C2,C4,C5 这3 种数据类型来自网络,平均延迟约为6.34 ms,而剩下的则是本地处理的数据类型,平均延迟约为0.410 ms;对于node 2,C1 是网络中的数据类型,订阅平均延迟为3.650 ms,C2 是本地处理的数据类型,平均延迟为0.4 ms.图18(c)(d)是2 个计算节点的订阅数据的丢包率,其丢包率都为0,其含有小数是因为计算时浮点数特性造成的.图18(e)则是Mort 运行前、运行时、运行后CPU 负载变化.node 0 共运行了4 个发布者和7 个订阅者;node 2 共运行了2 个订阅者和4 个发布者.可以看到2 个节点分别在第3 秒和第9 秒时启动Mort,CPU 使用率约有14%的增幅。从Mort 的运行机制分析,负载的大幅升高主要有3 个原因:1)初始化,包括状态集初始化、访问控制初始化、持久化组件初始化、本地数据域初始化等.2)服务发现,服务分发组件会主动发现网络中其他Mort 实例.3)任务构造和卸载,初始化操作完成后,Mort 会处理用户应用(如果存在),包括任务构造和卸载.从第12 秒和第16 秒开始,2 个节点的CPU 使用率大幅下降,比初始时仅高了约2%。这一阶段,Mort 主要是完成数据分发和状态维护等工作.在第59 秒时关闭Mort.实验表明,Mort 生命周期内,计算节点的负载绝大多数时间处于较低水平.
6 结 论
本文设计并实现了任务卸载及管理框架Mort,主要是解决发布订阅系统中的数据共享问题.任务来自上层业务,需要先对业务进行任务分解.对于任务分解,采用静态代码分析方法追踪函数调用和参数信息,从而构建DAG 任务组.对于任务卸载,将问题建模成优化网络数据传输的非线性整数规划问题.在偏向于CPU 密集型任务和计算节点负载高场景中,设计了GBTO 算法.在偏向于I/O 密集型任务和时间敏感场景中,设计了GFBTO 算法.仿真和实验表明,GBTO 和GFBTO 算法能达到最优值的80%和90%左右,且引入的Mort 负载只有约2%.目前,在计算任务卸载计划中,无论采用GBTO 还是GFBTO,主要依据经验(历史数据分析),未来工作中将探索更好的方式,并考虑包含其他的优秀卸载算法,拓宽使用场景.
Mort 的任务管理组件本质上属于分布式节点协调模块,其还存在改进之处,如冲突处理.学界已有很多工作,未来考虑将它们融入组件中.此外,在数据隐私保护方面,Mort 目前提供了基于属性的访问控制方式,后续可以引入证书等机制,从计算节点方面进一步提升其安全性.
作者贡献声明:殷昱煜提供研究思路、审阅论文并提供修改意见;苟红深完成相关实验及论文撰写,并和李尤慧子共同确定算法思路及论文修订;黄彬彬和万健审阅论文并提出修改意见.
