居民社区在线聊天热点话题的情感分析研究
2023-05-19蔡云戈范永胜
蔡云戈,范永胜,冯 骥
(重庆师范大学 计算机与信息科学学院,重庆 401331)
0 引 言
截至2021年12月,第49次《中国互联网络发展状况统计报告》指出以QQ为代表的即时通信应用类用户规模达10.07亿,在整体网民中占比97.5%[1]。同年六月在STATISTA发布的《China:reasons for using social networks on mobile phones》调查报告中指出,休闲聊天是中国网民使用社交媒体的主要原因[2]。对居民社区而言,生活社区在线交流群(如QQ群和微信群等在线交流工具)是居民快速便捷向物业或相关部门反映民生诉求、解决相应问题的关键场所。但存在人员多、发言门槛低及素质参差不齐等因素造成消息密度大与信息内容杂等问题,使得民生问题得不到有效关注,热点问题得不到及时解决,从而导致居民负向情绪加剧,邻里冲突、维权受阻与矛盾激化等现象[3]时有产生。因此,从纷繁复杂的聊天数据中快速获取并分析人们对热点问题的情感倾向成为居民、政府部门、学者等各方关注的焦点。基于此,在收集了大量的社区聊天信息的前提下,进行了一次有意义的尝试研究,该研究主要贡献如下:
(1)针对目前对于民生领域居民社区群聊关注较少的问题,该研究通过追踪搜集大量居民社区在线聊天信息,构建生活社区群聊数据集,并对数据进行了情感与热点话题的综合分析;
(2)针对在中文社区群聊领域,因涉及隐私暂无公开标注的数据集可用于情感分类模型的有效训练的问题,构建了社区领域情感词典,并结合基于注意力机制[4]的双向长短期记忆网络(Attention-based Bidirectional Long-Short Term Memory Network,Att_BiLSTM)[5]情感分类模型实现了对社区群聊文本的半监督情感倾向计算;
(3)结合生活社区热点话题验证了话题与情感间的相关性,并举例展示了两类社区居民关注的话题、发言数量和长度等特征,发现各社区集中讨论的时间点与其从事职业具有密切关系。相关分析结果可为有关管理部门及人员提供切实有效的参考依据。
1 研究现状
针对这样的在线聊天文本,目前已有研究者们从话题与情感两方面开展了相应研究。
在国外,Pellert等人[6]使用奥地利不同数据源在Twitter及学生聊天群等多平台中搜集新冠疫情期间相关内容进行情感分析,通过可视化界面展示了疫情期间各类情感变化与内容分布;Ng等人[7]从参与度、情绪与话题讨论等五个维度出发,采用MPQA词典检测群内人员对舆论和权威信息的态度,分析新加坡某群聊中人们在新冠疫情期间对错误消息传播的反应;Saha等人[8]在全球最受欢迎的即时通信应用WhatsApp中,分析了数千个讨论印度政治的群组有关恐怖言论的用词特性、主题分布及传播特征,对恐怖信息进行了有效的舆情检测,在一定程度避免了恐怖言论的恶性传播。
在国内,张大勇等人[9]以微信群为例分析了群体互动行为特征,结果表明带有情绪诱导和相关利益引导的标题可引起更多用户的互动;汪鸿沁泠等人[10]从话题交流强度、成员活跃度及话轮密度三个维度对群聊文本的话题进行强度计算与演化分析,得到群聊话题演化的生命周期规律及热点结构;吴旭等人[11]综合话题序列、群聊内容等因素提出了多策略话题检测模型,扩大了话题检测所能应对消息类型的广度,提升了舆情分析效率。
国内外学者对于社区群聊展开的研究进行了广泛的探索,但对于民生领域的关注相对较少。为此,笔者通过对社区群聊的半监督情感倾向计算,结合相关性及可视化分析方法得到社区居民对不同话题的情感倾向及发言特征,以期提升管理者对民生诉求的关注度,辅助相关人员高效管理社区,提高社区居住幸福感[12]。
2 数据处理流程及相关模型介绍
2.1 数据处理流程
社区群聊内因发言人群素质差异大、口语化严重、话题跳跃度高等特性,相较于普通文本的数据处理流程,需要针对具体细节做出相应修改,如新增生活社区情感词典等,以提高后续对数据的处理效率及情感分类准确性。
为此,构建了如图1所示的社区情感与热点话题关联性分析处理技术流图,其大致可分为3个主要过程。
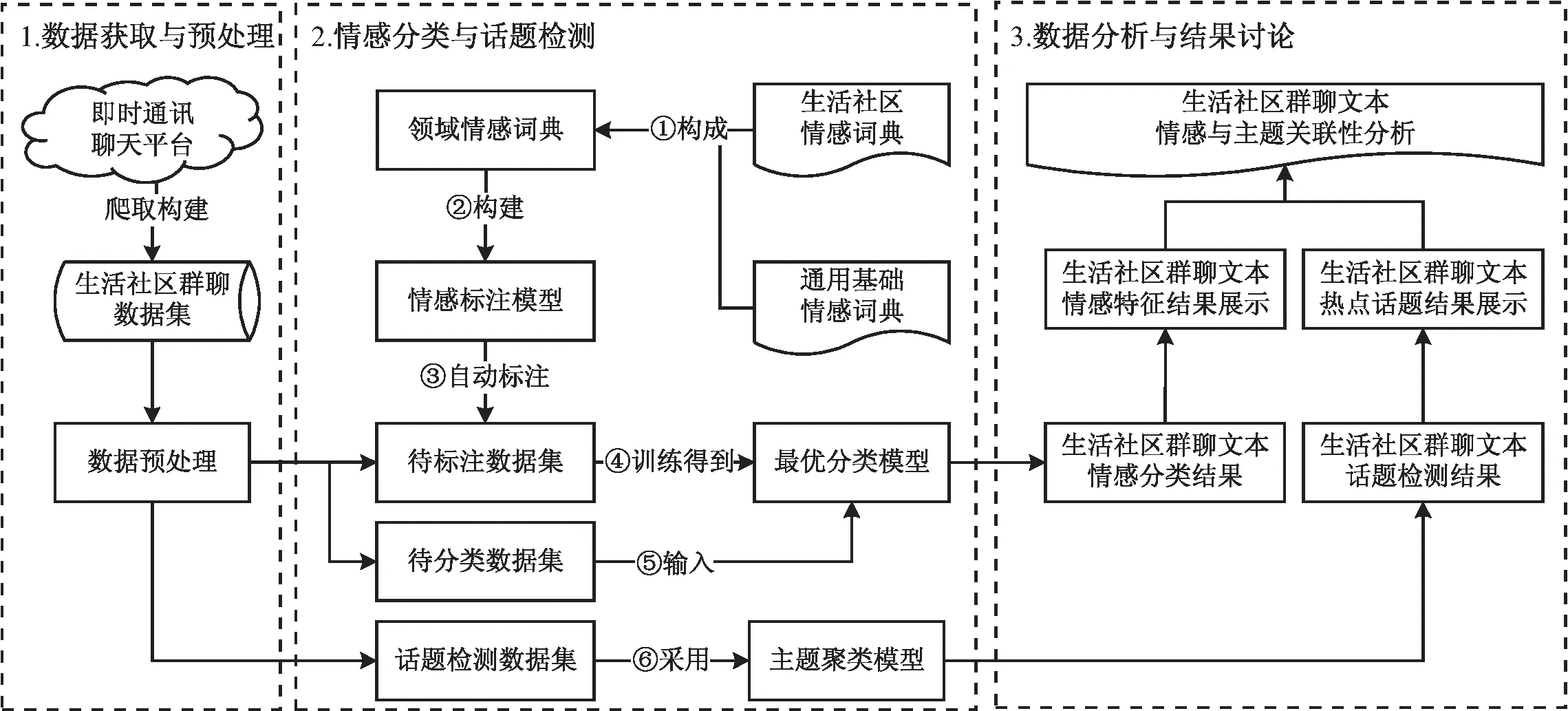
图1 社区情感与热点话题关联性分析处理技术流图
(1)数据获取与预处理。
在数据获取阶段,通过即时通讯软件的相关聊天平台收集了2020年10月至2022年5月期间几十个不同平台的生活社区群聊数据共1 038 604条,从中提取聊天成员、聊天时间和聊天内容等信息构建生活社区群聊原始数据集。在数据预处理阶段,经过表1中的相应方式对异常数据进行处理,最终得到有效数据727 023条。使用全部数据构建话题检测数据,从有效数据中随机抽取10%构建待标注数据集,剩余90%组成待分类数据集。

表1 异常数据处理
(2)情感分类与话题检测。
对于情感分类而言,具体步骤如下:①基于TF-IDF与SO-PMI算法[13]对有效数据进行种子情感词获取与生活社区情感词典的构建;②结合通用情感词典,构建领域情感词典,并依据词本身是否积极以及其前后所使用的修饰词来决定其加权的正负和权重这一规则构建情感标注模型,完成对待标注数据集的情感标注;③采用经标注后的数据对各分类模型进行训练与评估,依据实验结果验证标注数据质量,并选择最优分类模型完成剩余待分类数据集的情感分类。
对于话题检测而言,具体步骤如下:①在话题检测数据集中按照社区群类型分别通过隐狄利克雷分布(Latent Dirichlet Allocation,LDA)[14]主题聚类模型进行话题检测;②结合可视化结果分析得到最优话题数和相关特征词。
(3)数据分析与结果讨论。
依据上述情感分类与话题检测结果对相应特征进行可视化分析,再结合二者进行相关性分析[15]。
2.2 相关模型简介
2.2.1 分类模型简介
该文分别采用如下6种分类模型进行了对比实验,各模型原理及优缺点总结如表2所示。
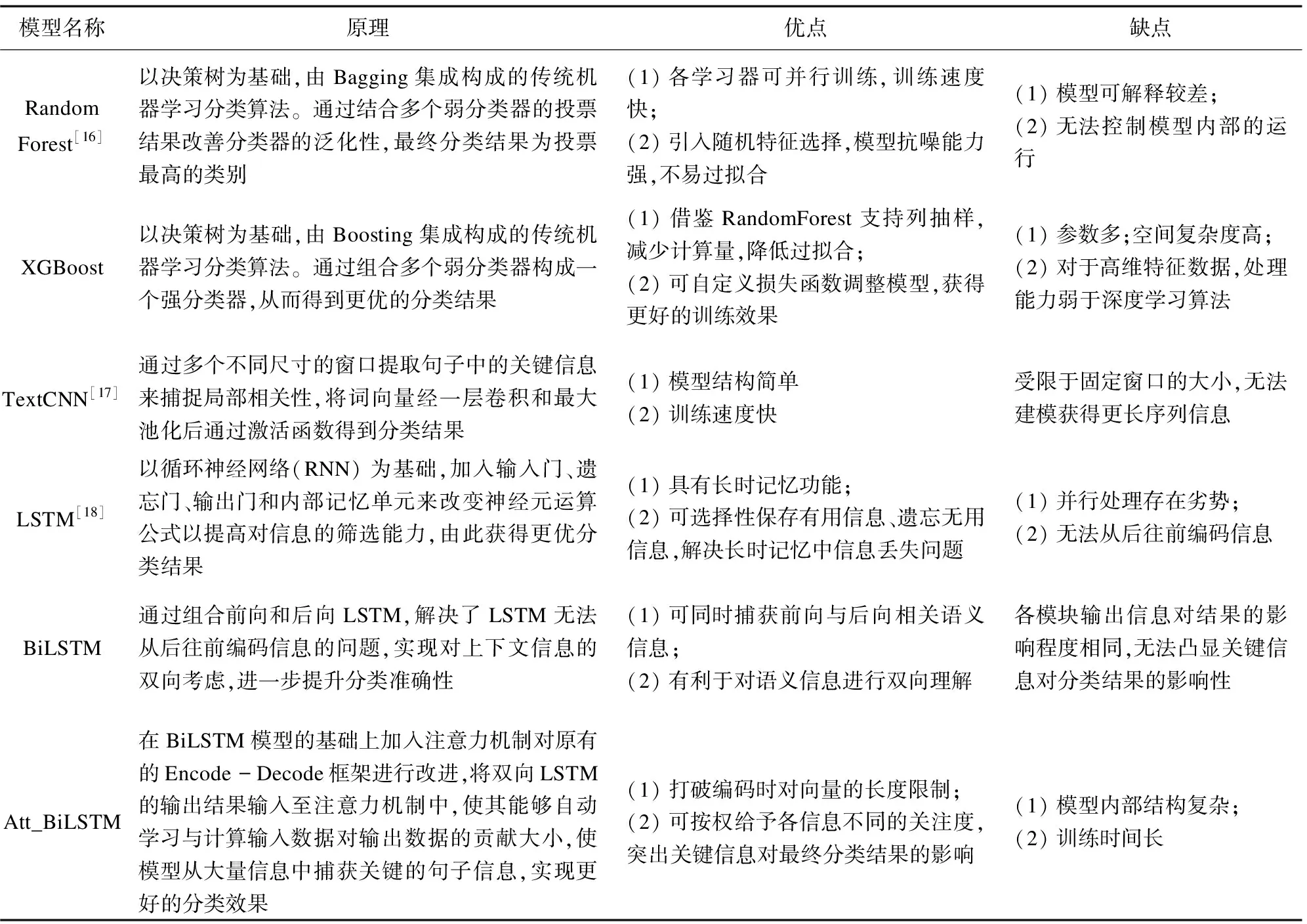
表2 分类模型
其中Att_BiLSTM模型结构如图2所示。
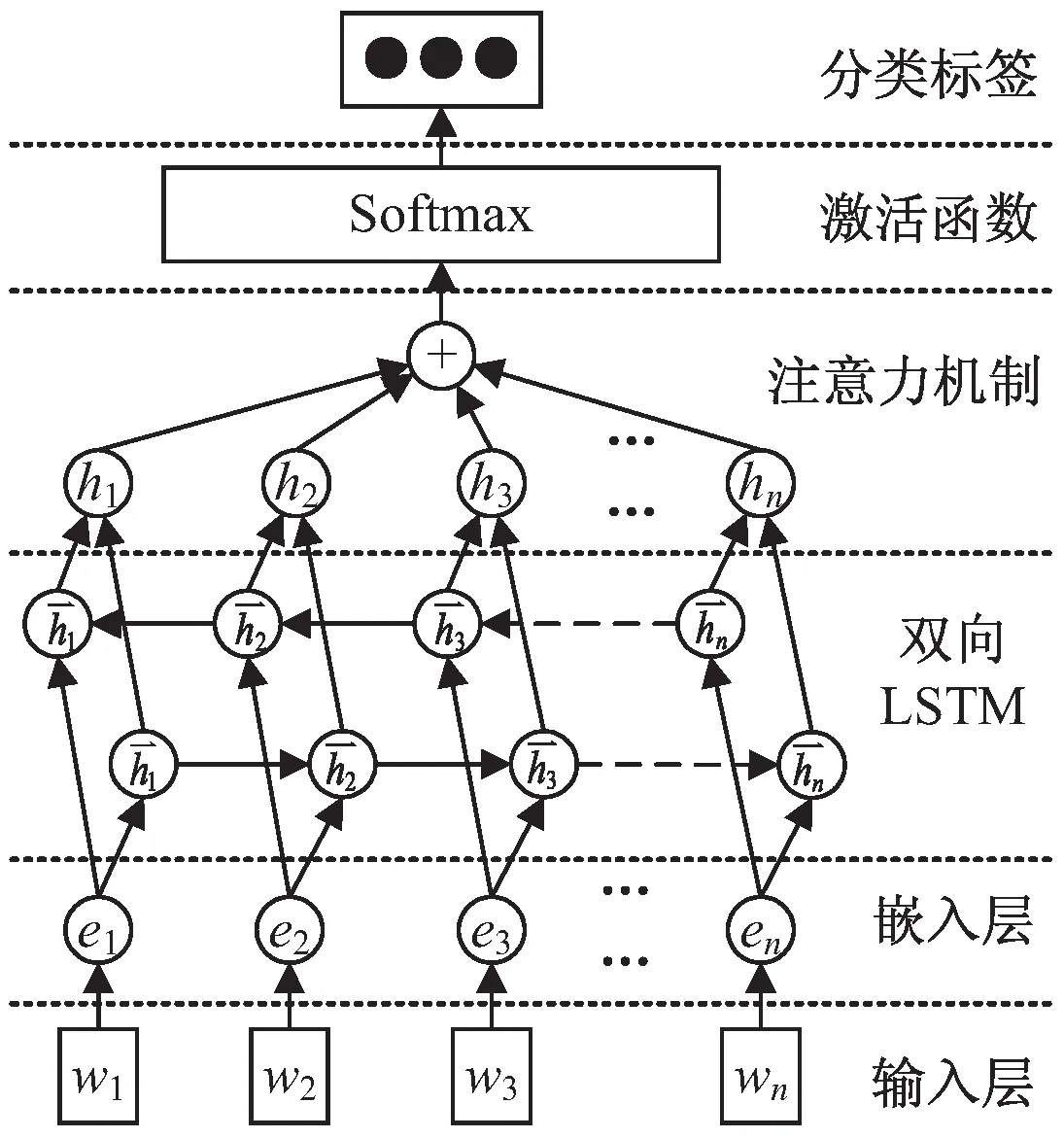
图2 Att_BiLSTM模型结构
2.2.2 主题聚类模型简介
该文采用LDA主题模型识别不同社区间热点话题的差异。LDA主题模型属于无监督学习模型,由文档、主题和词语构成的三层贝叶斯概率模型组成,通过概率统计方法对文档中选出的关键词语进行主题归纳,具有结构简单、训练速度快且聚类效果直观等优点。为获得最佳聚类效果,该文通过多次迭代,动态调整参数和观测pyLDAvis可视化效果确定最佳话题聚类数并挖掘热点话题特征词。
2.2.3 评价指标
(1)分类模型评价指标。
该文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及调和平均值(F1)的加权平均(Weighted average)计算方法作为模型评价指标,各指标计算方法如式(1)至式(4)所示。
(1)
(2)
(3)
(4)
其中,TP为正例预测为正例的样本数;TN为反例预测为反例的样本数;FP为反例预测为正例的样本数;FN为正例预测为反例的样本数;n代表类别数;i代表第i类样本;Wi代表第i类样本的总数在总样本中的占比权重。
(2)相关性评价指标。
卡方检验是以卡方分布为基础的一种检验方法,经常用于检测多个定类变量间是否存在相关性。在检验之前需做出零假设即假设两个变量呈统计独立性。其次对两定类变量建立列联表,若列联表共有r行c列,则样本自由度df与各字段的期望频数E如式(5)和式(6)所示。
df=(r-1)(c-1)
(5)
(6)
其中,N代表样本总个数,O代表指定位置下的实际观测值,i与j分别代表第i行与第j列,nc与nr分别用于遍历第i行所有列的值与遍历第j列下所有行的值。
接着,依据式(7)计算各字段皮尔逊卡方值χ2,当两定类变量间关联程度越强时,皮尔逊卡方值χ2也会越大。
(7)
最后,通过卡方值和自由度查表得出卡方分配右尾概率P是否位于拒绝域内,可判断显著性水平。当P<0.05时,得到拒绝原假设,两分类变量间存在显著性差异的结论,即证明两个分类变量间具有相关性。
3 实验过程
3.1 实验环境
为验证算法有效性,基于如下环境开展实验。(1)硬件环境:11th Gen Intel(R) Core(TM) i5-11400F CPU(频率为2.60 GHz),显卡为NVIDIA GeForce RTX 3080 GPU,内存为32.0 GB;(2)开发环境:实验均在Windows 10操作系统、PyTorch 1.11.0、CUDA 11.3和Python3.8环境下运行。
3.2 实验数据
经2.1小节中相关预处理操作后,通过情感标注模型对待标注数据集进行数据标注,可得到情感分类模型训练数据,如表3所示。
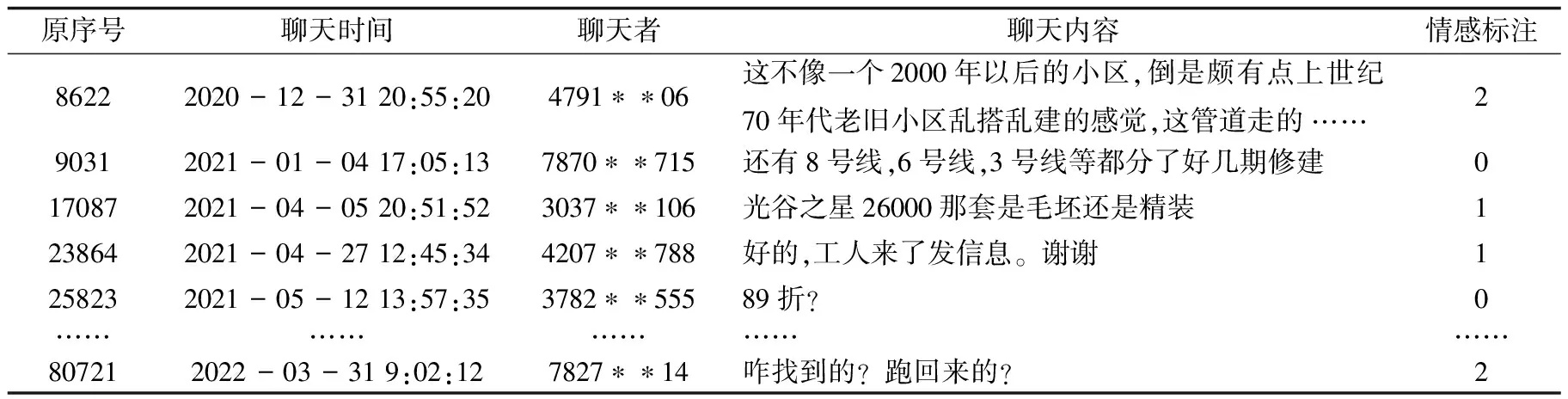
表3 情感分类模型部分训练数据示例
3.3 实验结果
对情感分类数据集中72 703条数据按照6∶2∶2的比例划分为训练集、验证集与测试集。并采用Att_BiLSTM等多个分类模型进行实验后,各模型在测试集上的实验结果如表4所示。实验结果证明了Att_BiLSTM模型在此领域各项指标均表现最优。
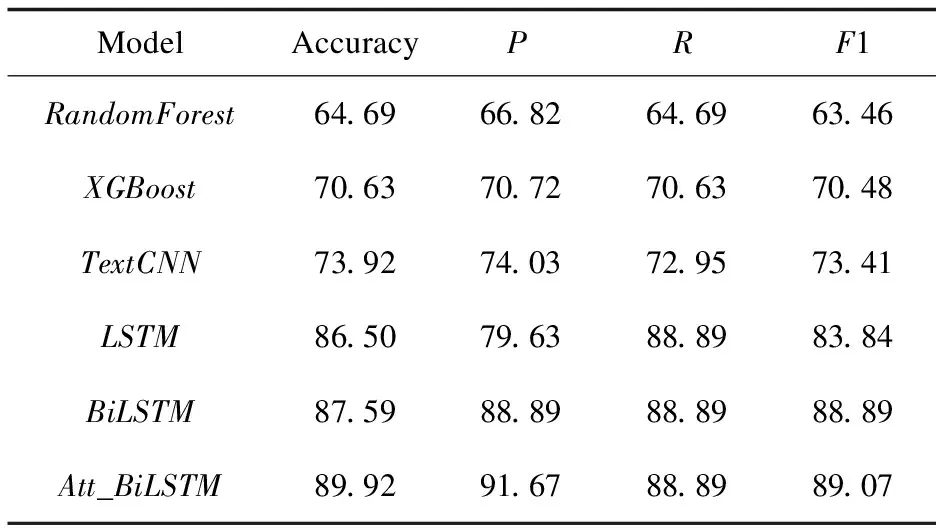
表4 情感分类模型实验结果对比
为了更好展现生活社区中居民的情感趋势与热点话题之间的联系,选取2021年期间两个典型社区A(工业区)与B(文化区)的相关数据进行情感特征分析与热点话题检测。
4 结果分析
4.1 发言长度与情感极性分析
经统计2021年A社区发言总数为46 974条,B社区发言总数为6 103条,A社区活跃度远高于B社区。对两社区各类情感发言数及每条文本平均长度进行统计,结果如表5所示。
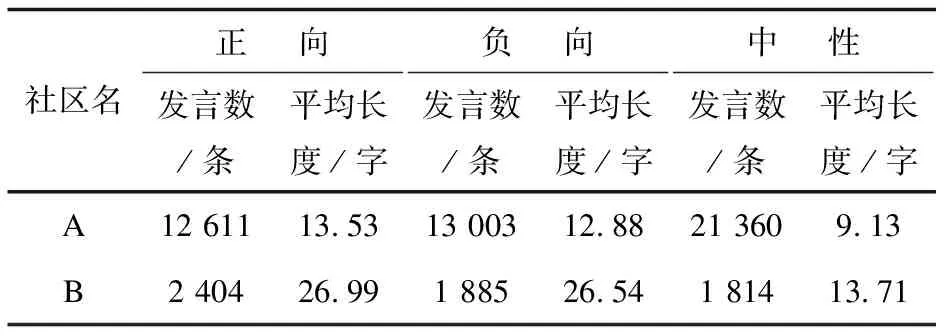
表5 发言数与各类情感平均文本长度统计
由表5可知在A社区内,中性发言占比达45.47%,远高于正向与负向情感的发言量;而B社区内各类情感所对应的发言量较为平均,其中正向发言占比最高,约为39.39%。就发言长度而言,B社区三类情感下的平均发言长度均明显高于A社区。进一步对各类情感下发言条数及每条发言对应使用的词语长度进行统计分析,可得到图3中所示结果。
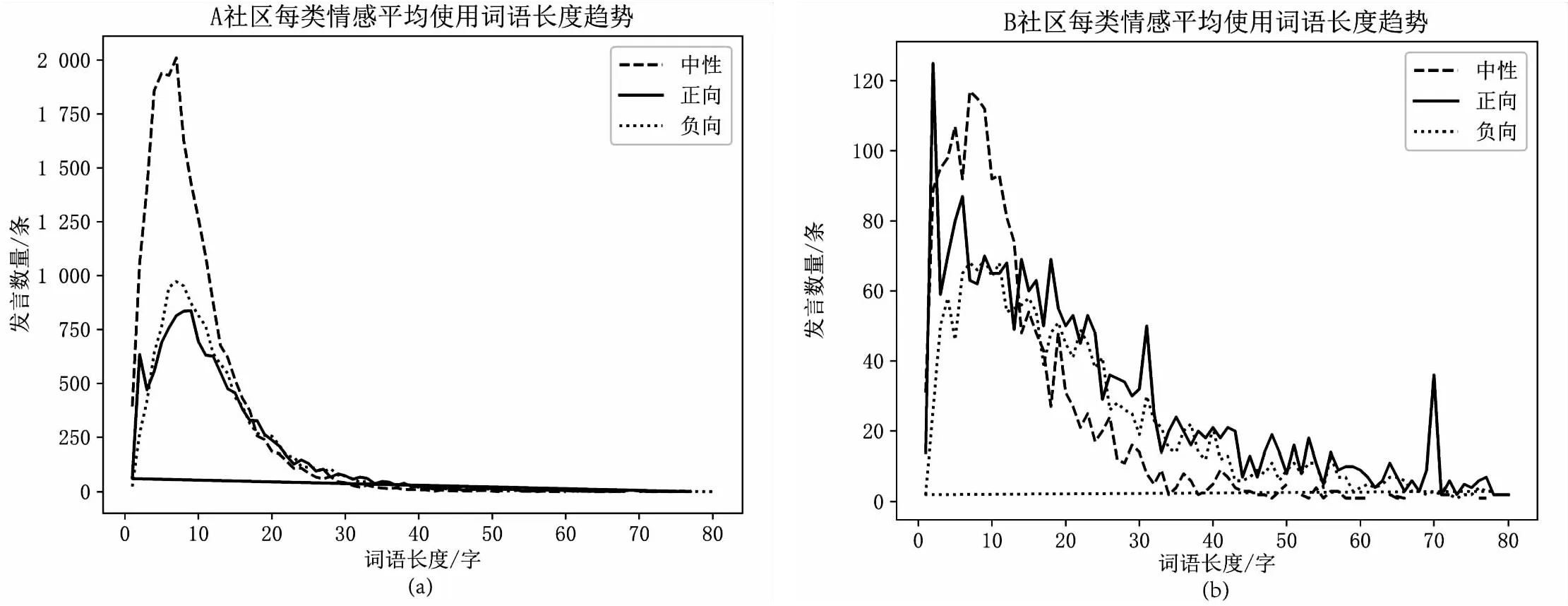
图3 A与B社区内发言词语长度与发言条数统计
由图3可知,多数群聊文本的词语长度集中在1~20个汉字之间,长度越长对应的发言量越少。对于A社区而言,词语长度在2~11个汉字间时,中性情感发言量远高于正负向情感发言,在词语长度大于20之后,发言的情感走向就难以区分;对于B社区而言,当词语长度在1~15区间内时,表现出的情感倾向基本与A社区相同,但当词语长度大于15后,B社区内的发言就带有明显的个人情感倾向。
4.2 发言周期性特性分析
按照以天为周期与以季度为周期对发言量进行统计分析,可得图4中所示结果。
从图4(a)与图4(b)中可看出,两社区聊天量在一天中的时间点分布存在很大不同。虽然在1~7点间两者群内活跃度均为一天之中的最低点,这也符合大多数中国居民的日常作息时间。但A社区在14~19点间的聊天量几乎是该时段B社区聊天量的3倍,而B社区在20~24点与8~13点间的聊天量接近于A社区的2倍,这表明社区类型和居民工作类型与聊天时间具有紧密联系。工业区上班族大多倾向于在下午参与群内讨论,而多数学校工作者习惯于利用晚上和中午休息的时间解决生活中的问题,生活与工作间具有较明显的界限。
从图4(c)和图4(d)可知,在全年周期分布上两社区群均在第二、三季度即夏季和秋季活跃度最高,表明居民在该时段更关注社区事务。而第一季度是中国传统节假日安排较为集中的时段,大多数居民会利用假期放松或将投入家庭生活之中,对社区事务的关注度也因此降低,所以两社区该时段内的活跃度均为全年最低。
4.3 热点话题分析
采用LDA主题模型对社区文本进行话题聚类,根据迭代实验及可视化结果分析确定A和B社区最优主题聚类数为5,话题聚类结果如图5所示。图中圆圈的大小代表各类话题所出现的频率,依据话题频率由高至低的顺序对话题进行编号。各圆圈间的距离采用JSD(Jensen-Shannon Divergence)距离计算得到,可直观表达各话题间差异程度。
依据上述话题聚类结果,分别对两社区各话题下的特征词进行分析,筛选各话题内排名前12的特征词,并定义各话题中心词,得到如表6所示结果。
从表6中可知A社区全年超半数的话题讨论集中在买房投资之下,讨论量占比达55.65%;其次是对楼盘开发与学区政策等话题的讨论,这说明在经济发达的工业区,房子的户型和位置、各大楼盘的开发商管理和房屋售价等与房子相关的问题是关注的热点,因此建议管理部门从购房政策等角度入手,关注居民购房售房等问题;而生活压力相对较缓的B社区,接近半数的话题讨论量均与求助帮忙话题相关,其次是社区管理和事件投诉相关话题,说明B社区内邻里关系更加紧密和谐,居民更关注当前住房的生活质量、关心社区管理及社区内停水停电、设施破损等相关的民生问题。因此,对于此类社区,管理部门应注重社区基础设施的建设与维护,通过保障居民的衣食住行来减少居民在事件投诉话题下的讨论量。

表6 A和B社区各主题特征词展示
4.4 情感倾向与主题相关性分析
依据上述分析,统计两社区中各类主题对应的情感分布情况可得表7所示结果。
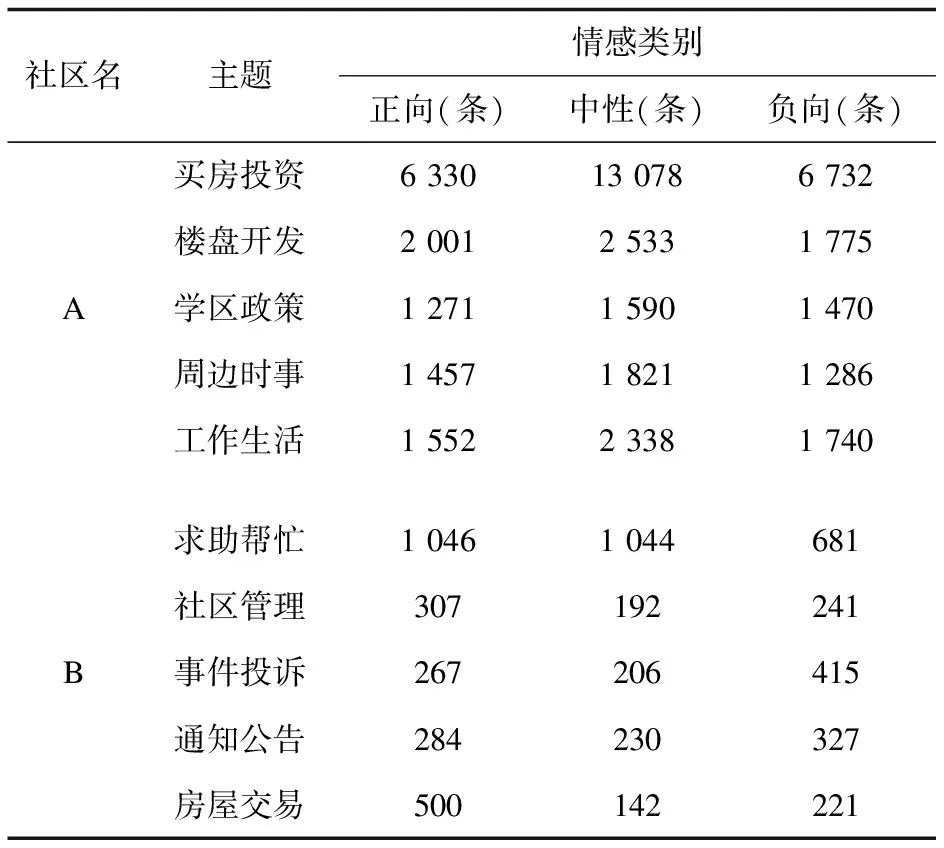
表7 主题情感分布
由表7中可知,A社区居民在“买房投资”话题下,中性情感的占比约为正向和负向情感的2倍,其余话题下三类情感的发言数量基本持平,中性情感略微突出,由此可看出在A社区内,居民参与各类话题讨论时大多持理性态度,对各类热点话题参与度较高且讨论的话题相对广泛自由;但对于B社区而言,各类话题下情感倾向更具有典型性,在“求助帮忙”“社区管理”和“房屋交易”话题下,B社区居民的正向及中性情感明显高于负向情感,但在“事件投诉”和“通知公告”话题下,居民更多展现出的是负向情感,特别是在“事件投诉”话题下,负向情感的发言量约为正向或中性情感的2倍。
因此,为了进一步验证话题类别与情感类别间是否存在相关性,依据表7对A、B社区分别进行卡方检验。给定原假设为话题类别与情感类别间不存在相关性,经检验后可得到表8所示结果。因P<0.05,依据卡方分布的规则可知在99%的情况下拒绝原假设,即话题与情感间具有显著性差异,可说明话题类别与情感类别间存在相关性。

表8 A与B社区话题与情感卡方检验结果
5 结束语
在收集了大量的社区居民在线聊天信息的基础上,结合生活社区领域情感词典,采用Att_BiLSTM情感分类模型实现对社区群聊的半监督情感倾向计算,经LDA主题模型分析生活社区热点话题后发现,热点话题与情感类别间具有相关性,如“买房投资”话题中50%的讨论倾向于中性情感,而“事件投诉”和“通知公告”等话题下负向情感占比是正向与中性情感的2倍。与此同时在参与讨论的时间分布上,居民在夏秋季对社区事物的关注高于其他时段,不同类型社区的居民一天内参与话题讨论的时间点与其从事职业具有密切关系,如工业区居民在14~19点之间群内讨论量占全天的53.64%,而文化区居民该时段的聊天量占比仅为17.96%。因此,有关部门可根据社区类型与居民讨论话题,在居民参与社区事务讨论的高峰时段对相关热点话题进行关注或介入,由此更好地获悉居民社区中所面对的民生问题,把握亟需关注的热点,为社区内创造良好沟通环境,及时解决居民诉求,提升社区居民幸福感。
